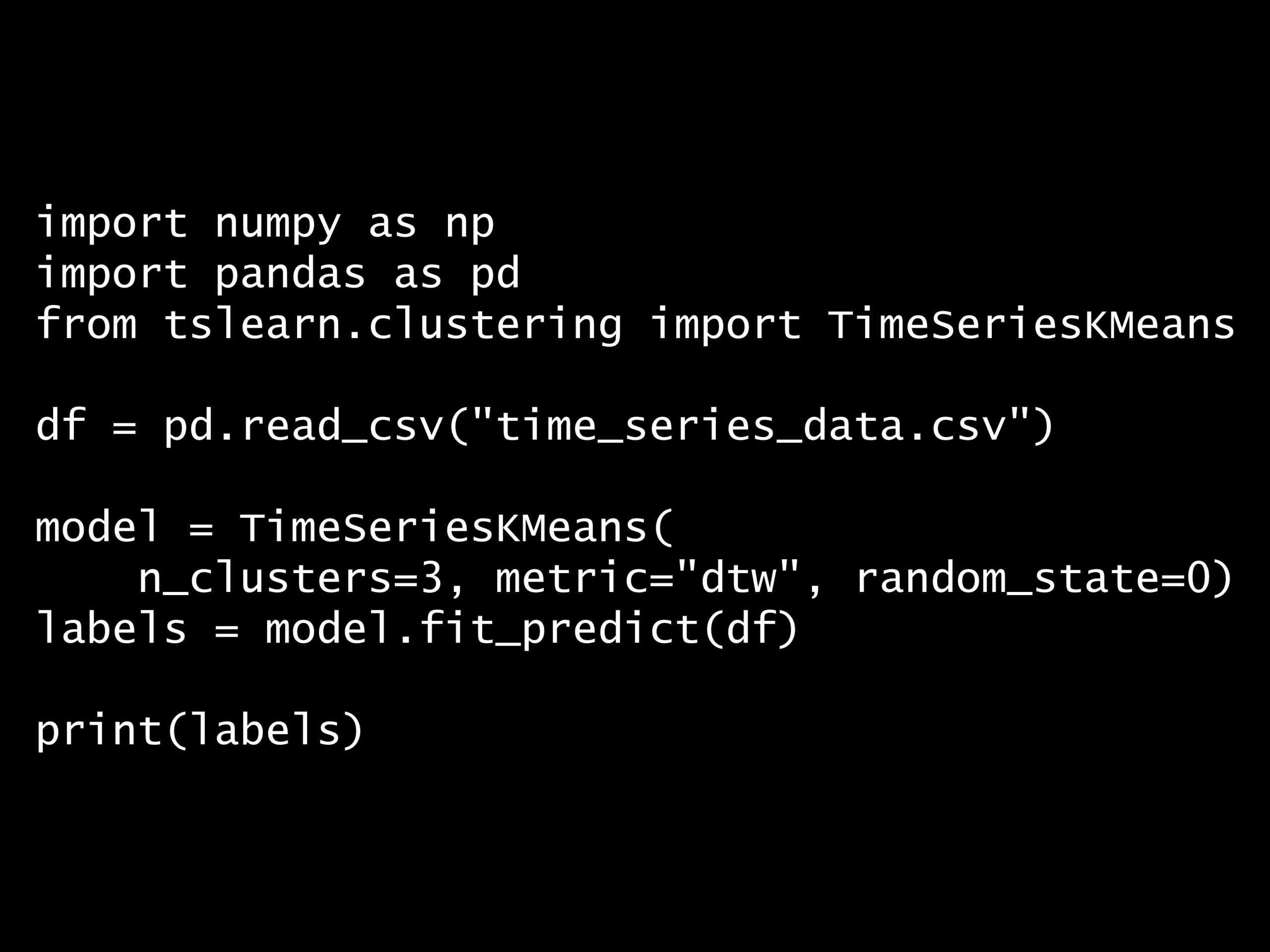
問題 答え 解説 次の Python コードのクラスタリング手法は? Python コード: import numpy as np import pandas as pd from tslearn.clustering ...
ビジネスの現場では、限られたリソースを最大限に活用し、利益を最大化することが常に求められます。 そのため、意思決定を行う際には、投入したコストと得られる成果のバランスを評価することが不可欠です。ここで重要になるのが、費用...
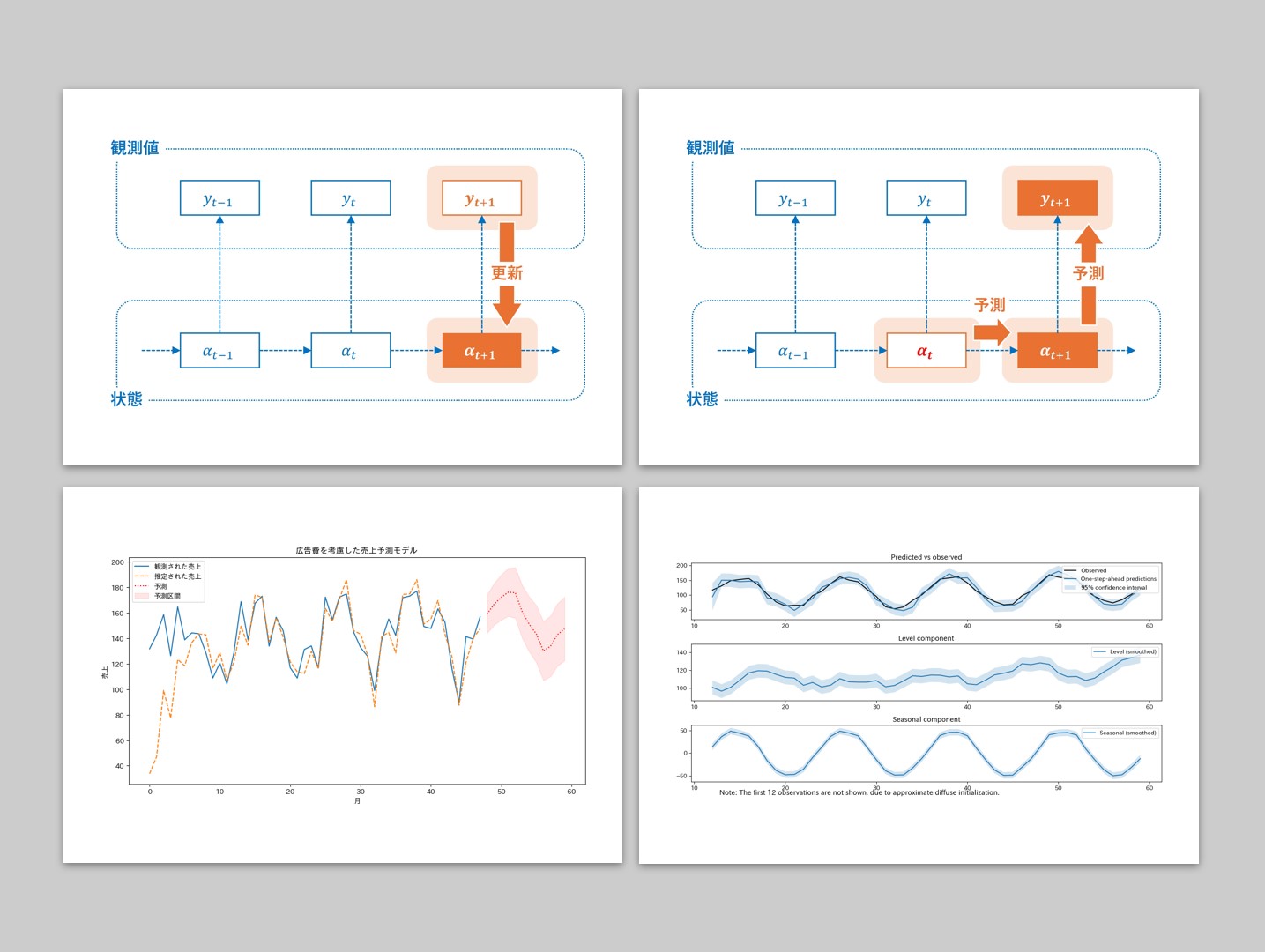
状態空間モデルは、観測できない状態を時系列データの背後にある要素として捉え、データからその状態を推定する強力なツールです。 今回は、ローカルレベルモデルや季節性を含むモデルなど、具体的なビジネスシナリオを通じて、Pyth...
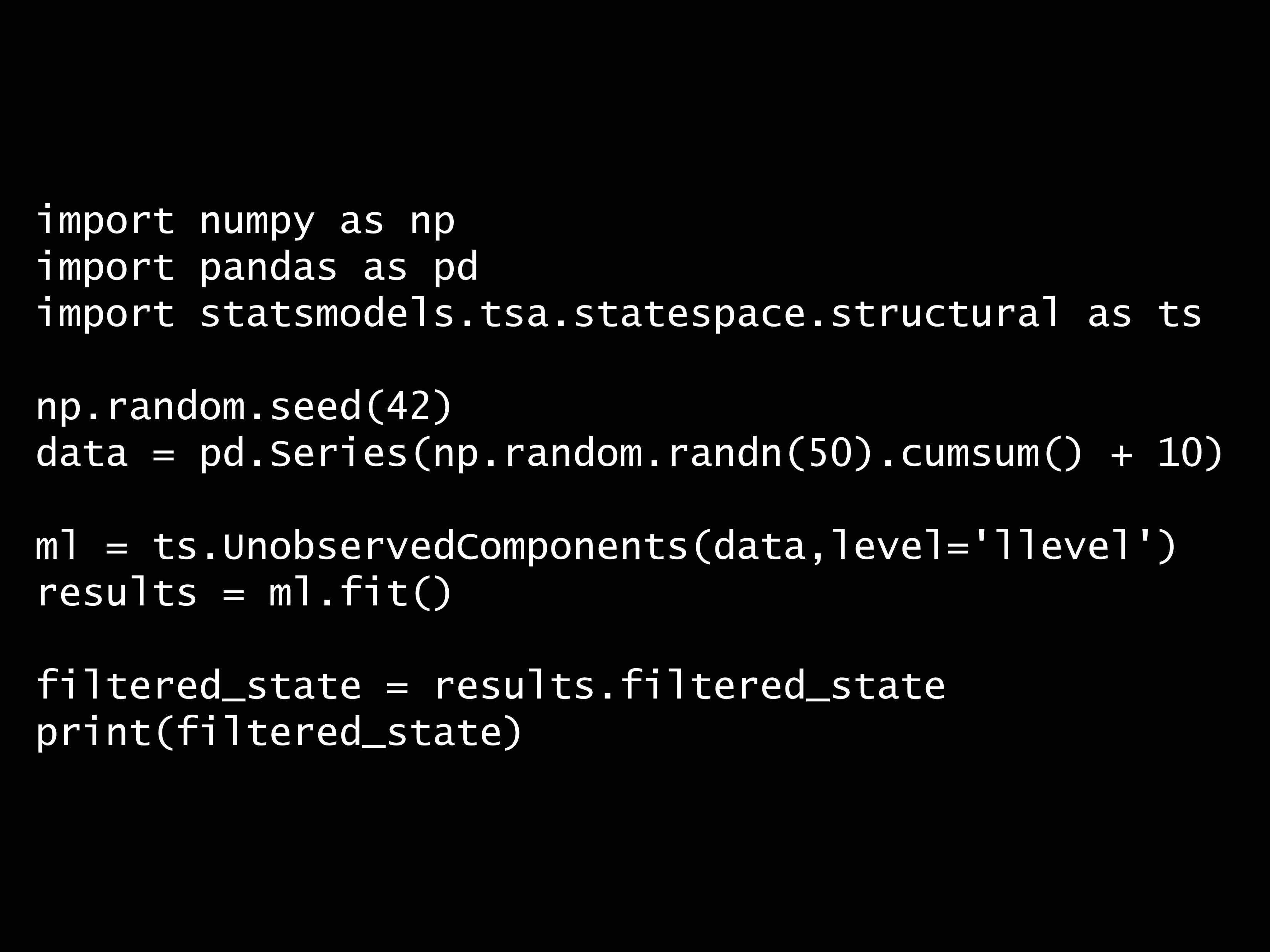
問題 答え 解説 次の Python コードの出力は? Python コード: import numpy as np import pandas as pd import statsmodels.tsa.statespa...
データの海から生産性の宝を掘り当てることが、データサイエンスの力で実現できます。 今、ビジネスの最前線で起きている静かなちょっとしたことをご紹介します。 製造、小売、物流、金融、農業の5つの業界の最新事例を通じて、データ...
「データは21世紀の石油」と言われる時代。 しかし、その恩恵を受けているのは大企業だけではありません。 今、スモールビジネスにもデータサイエンスの波が押し寄せています。 売上アップ、顧客満足度向上、経費削減…… データの...
ビジネスの世界では、データは新しい原油と言われています。 しかし、大量のデータを有意義な洞察に変換することは、多くの企業にとって依然として課題となっています。 ここで力を発揮するのが、効果的に設計されたBI(ビジネスイン...
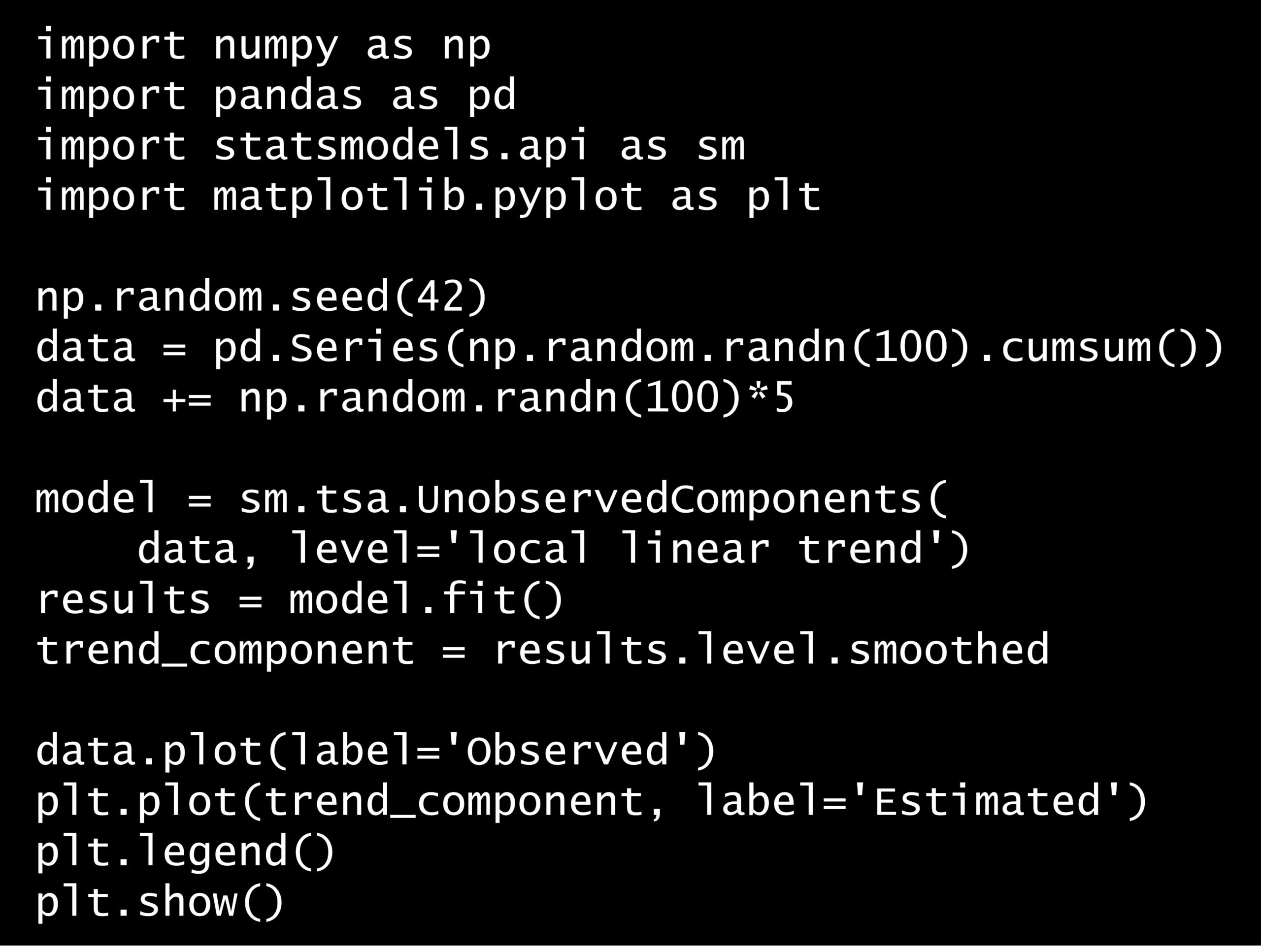
問題 答え 解説 次の Python コードで推定しているのは何ですか? Python コード: import numpy as np import pandas as pd import statsmodels.api...
近年、機械学習がビジネスの様々な分野で活用されており、データを使った意思決定の重要性はますます高まっています。 しかし、機械学習を成功させるためには、データをどのように準備するかが極めて重要です。その中でも「データ処理」...
Pythonでのデータサイエンスや開発を効率的に行うためには、適切な環境構築が欠かせません。 Miniforgeは、Conda環境をシンプルかつ軽量に提供してくれるツールであり、特に余計なパッケージを省いた環境を構築した...
計算結果をわかりやすく表示することは、ビジネスや教育、技術計算の場面で非常に重要です。特に複雑な数式や計算過程を伝えるとき、視覚的に見やすい形式で表示することが理解を助け、コミュニケーションを円滑にします。ここで役立つの...
近年、「データサイエンス」という言葉が当たり前のように使われるようになりつつあり、ビジネスの世界にも浸透しつつあります。 実際、多くの企業がデータ活用に取り組んでいますが、実は思わぬ落とし穴が待ち受けています。 驚くべき...
問題 答え 解説 次の Python コードの検定の目的は何ですか? Python コード: import pandas as pd import numpy as np import statsmodels.tsa.s...
データ分析って難しそう…… そう思っていませんでしょうか? 実は、あなたも知らないうちにデータ探偵の素質を持っているかもしれません。 日々の業務で直感的に行っている「状況把握」や「問題解決」、それ...
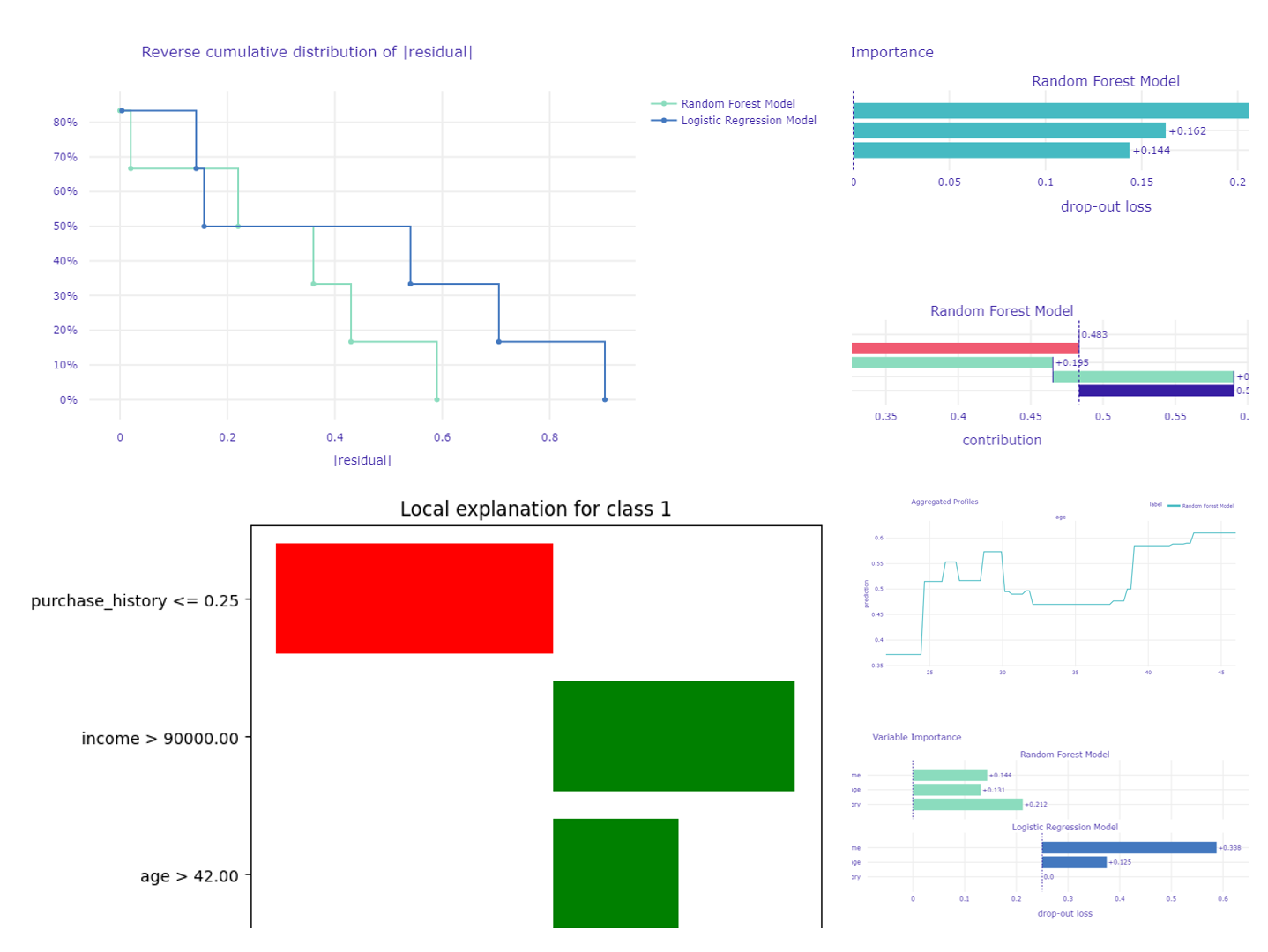
機械学習やAIが私たちの生活やビジネスにますます浸透している一方で、それらの技術がどのように判断や予測を行っているのかを理解することが求められています。 この理解が不十分だと、AIの予測や判断がブラックボックスのように感...
現代のビジネス環境では、データに基づく意思決定が求められています。 AI(人工知能)や機械学習を活用することで、企業は以前では考えられなかったような高度な予測や分析を行うことができるようになりました。 しかし、その一方で...