東京商工会議所 豊島支部 主催 全3回シリーズ「中小企業のための生成AI活用実践講座」 【第1回】生成AIで売上を伸ばす 〜基本から、集客・販促・接客・売上分析まで〜 【参加費無料 / ZOOM配信にて開催】 開催日時:...
2026年7月29日(水)・30日(木)にオンラインで開催される「ものづくり現場AI/DX DAY 2026 summer [for Leaders]」に、株式会社セールスアナリティクス代表取締役/Chief Data ...
ついにシリーズ最終回です。 第1回で欠損のメカニズム(MCAR / MAR / MNAR)を紹介し、削除戦略(第3〜4回)、単変量補完(第5〜7回)、時系列補完(第8回)、KNN補完(第9回)と進んできました。 第1回:...
研修で必ず出てくる話があります。 「アイスクリームが売れる時期は、水難事故も増える。 でもアイスが事故を起こしているわけではない。 どちらも気温のせいで増えている」 聞けば誰でも分かる話です。 ところが、この知識が会議で...
第5〜7回の単変量補完では「その列の情報だけ」を使い、第8回では時系列特有の前後関係を使いました。 第5回:単変量補完① — 定数・任意値での補完(pandas と SimpleImputer) https://www....
問題 答え 解説 次の Python コードで比較している EWMA(指数加重移動平均)は、通常の移動平均(SMA)と比べてどのような特徴がありますか? Python コード: import numpy as np, p...
予測モデルの判断について「理由を説明できるようにしよう」という話は、すっかり定着しました。 しかし、中身がブラックボックスのままでは現場が納得しない。だから、なぜその予測になったのかを示せるようにする。 ここまでは、多く...
ここまでの第5〜7回では、Titanic データのような 順序を持たないデータ の補完を扱ってきました。 第5回:単変量補完① — 定数・任意値での補完(pandas と SimpleImputer) https://w...
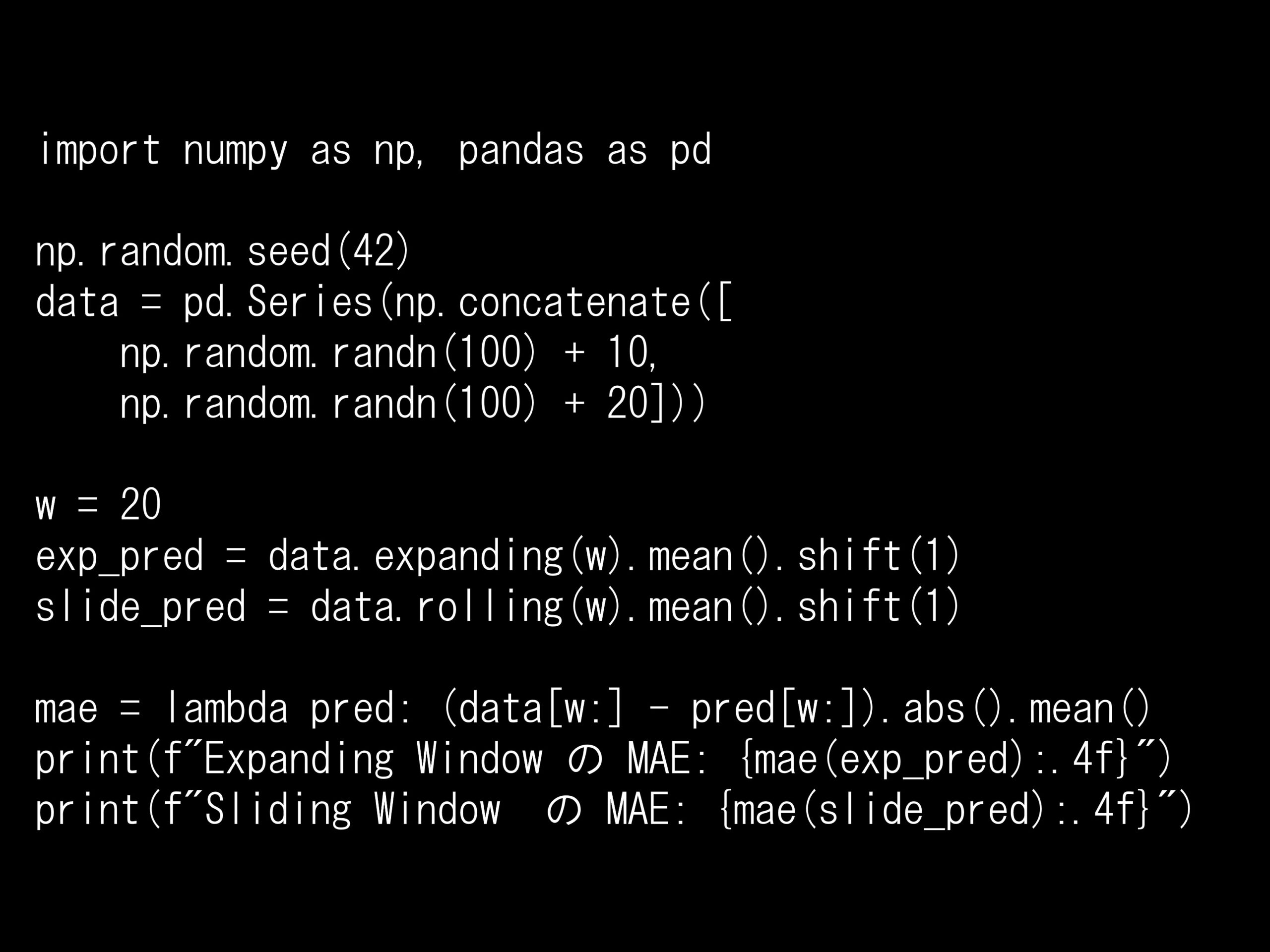
問題 答え 解説 次の Python コードは Expanding Window と Sliding Window の予測精度を比較しています。2つの手法の本質的な違いは何ですか? Python コード: import ...
予測モデルがはじき出した結果は、専用の手法で分析すれば、その理由まで読み解けます。 「収入に対して借入が多いから」 「この商談は競合が強いから」 たしかに、もっともな説明です。 けれども、その説明を聞いたあと、私たちの心...
精度95%の高性能な予測モデルが、現場で使われないまま放置されている。 その隣で、精度80%ほどの、少し見劣りするモデルが、すんなり受け入れられて活躍している。 こんな逆転劇が、実際のビジネスの現場ではしばしば起こります...
私たちは予測モデルに対して、「なぜそう判断したのか、根拠を示しなさい」と当然のように求めます。 理由を語れないモデルは信用できない、ブラックボックスのままでは任せられない、と。 ところが、ここで一度、その問いを自分たちに...
第6回の最後に、平均値・中央値補完には「分散が縮小し、分布が不自然に歪む」という重要な副作用があることをいお話ししました。 すべての欠損を1つの代表値で埋めるため、その値の周辺にデータが人工的に集中してしまうためです。 ...
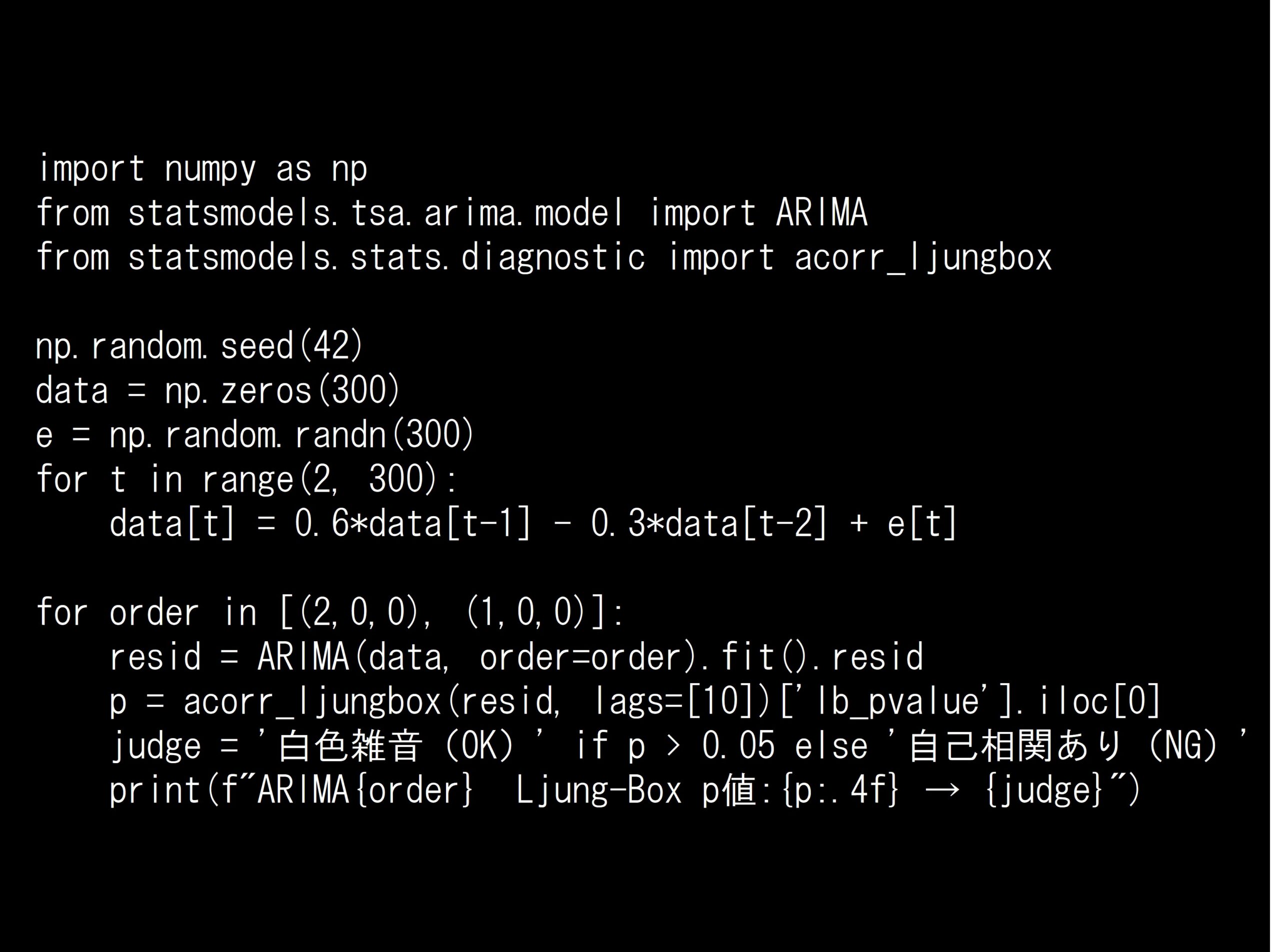
問題 答え 解説 次の Python コードの Ljung-Box 検定は何を確認していますか? Python コード: import numpy as np from statsmodels.tsa.arima.mod...
「精度の高い予測モデルができました」と報告を受けても…… いざ「なぜ、その予測になったの?」と尋ねると答えが返ってこない。 そんな経験はないでしょうか。 よく当たるモデルほど中身が複雑な「ブラック...
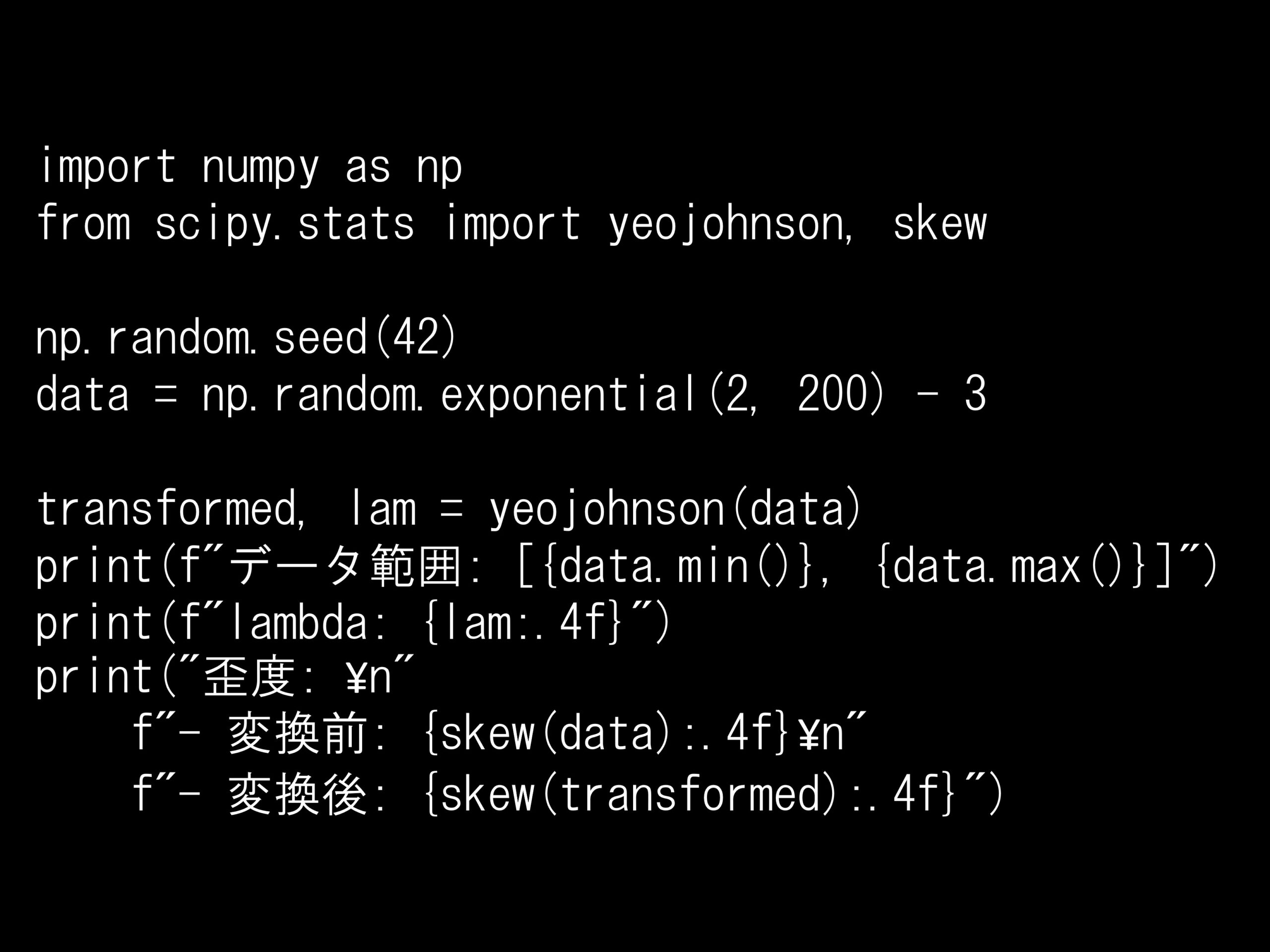
問題 答え 解説 次の Python コードで使用しているヨー=ジョンソン変換は、ボックス=コックス変換と比べてどのような違いがありますか? Python コード: import numpy as np from sci...









![【登壇・参加無料】(2026/7/30)<br>ものづくり現場AI/DX DAY 2026 summer [for Leaders]<br>― AI/DXを“試す段階”から、“成果を出す段階”へ ―](https://www.salesanalytics.co.jp/wp-content/uploads/2026/07/784271698085abd9fb5f8ec0961ca531.jpg)