2025/7/28 に第一出版社からよくわかる因果推論が出版予定です。 2026年3月19日に第一出版から、『よくわかる因果推論: もう惑わされない! 身近な事例から学ぶ原因と結果のとらえ方』が出版されます。 本書は、「...
需要予測の話をすると、必ずと言っていいほど出てくる問いがあります。 「で、結局いくつ売れるの?」 経営層も、営業部長も、発注担当者も、みんなこの問いを投げかけます。 当然の問いに聞こえますし、この問いに「1,000個です...
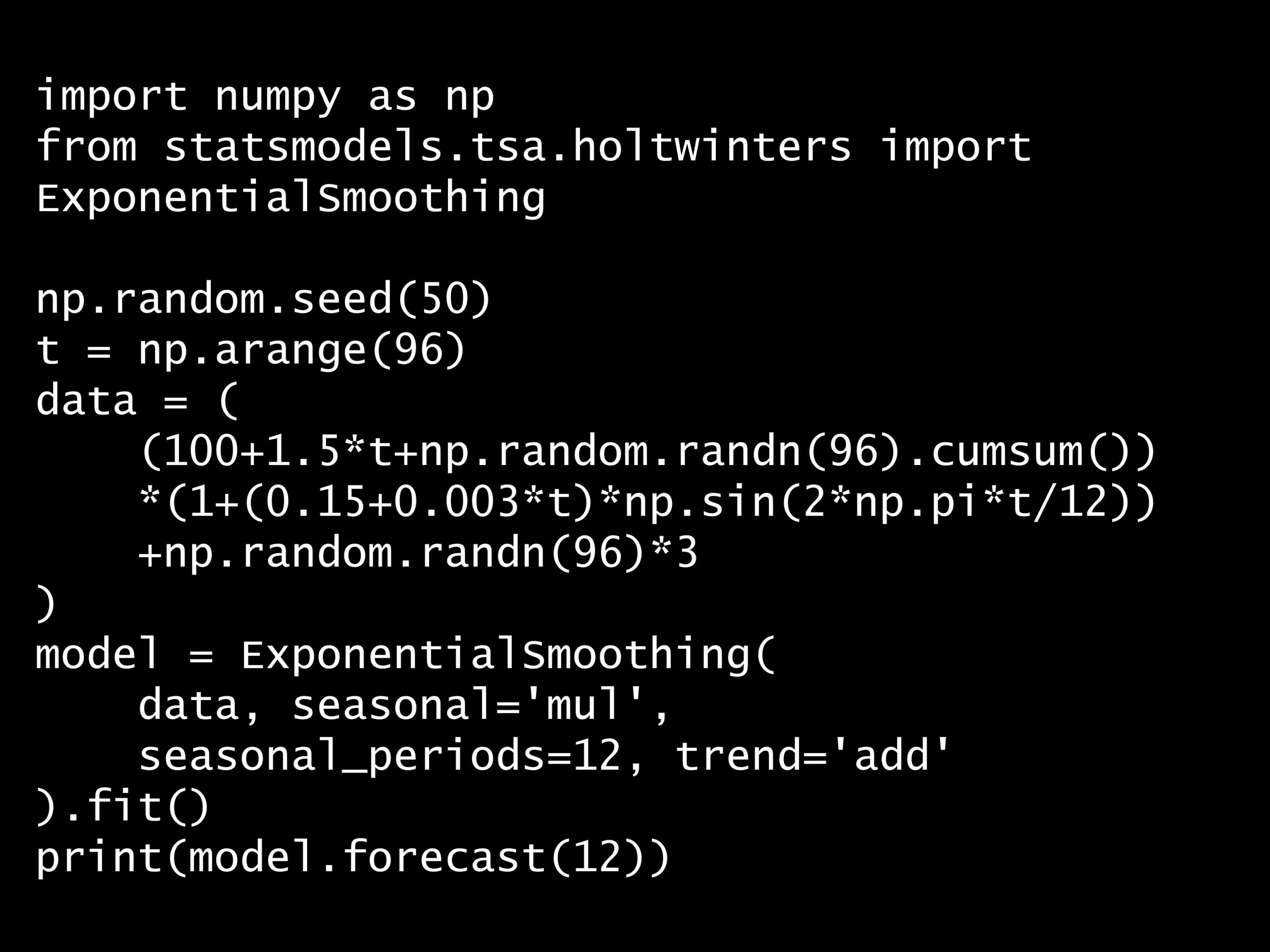
問題 答え 解説 次の Python コードのモデルが捉えようとしているものは何ですか? Python コード: import numpy as np from statsmodels.tsa.holtwinters i...
前回の記事では、curve_fit() を使ってデータにフィッティング(曲線あてはめ)を行う方法を紹介しました。 curve_fitでデータにフィッティングしてみよう(scipy.optimize.curve_fit) ...
「来月の売上、いくらになりそう?」 経営者やマネジメント層なら、この質問を部下に投げかけたことが一度はあるはずです。 そして、営業や企画の担当者なら、この質問を受けて言葉に詰まった経験があるのではないでしょうか。 この問...
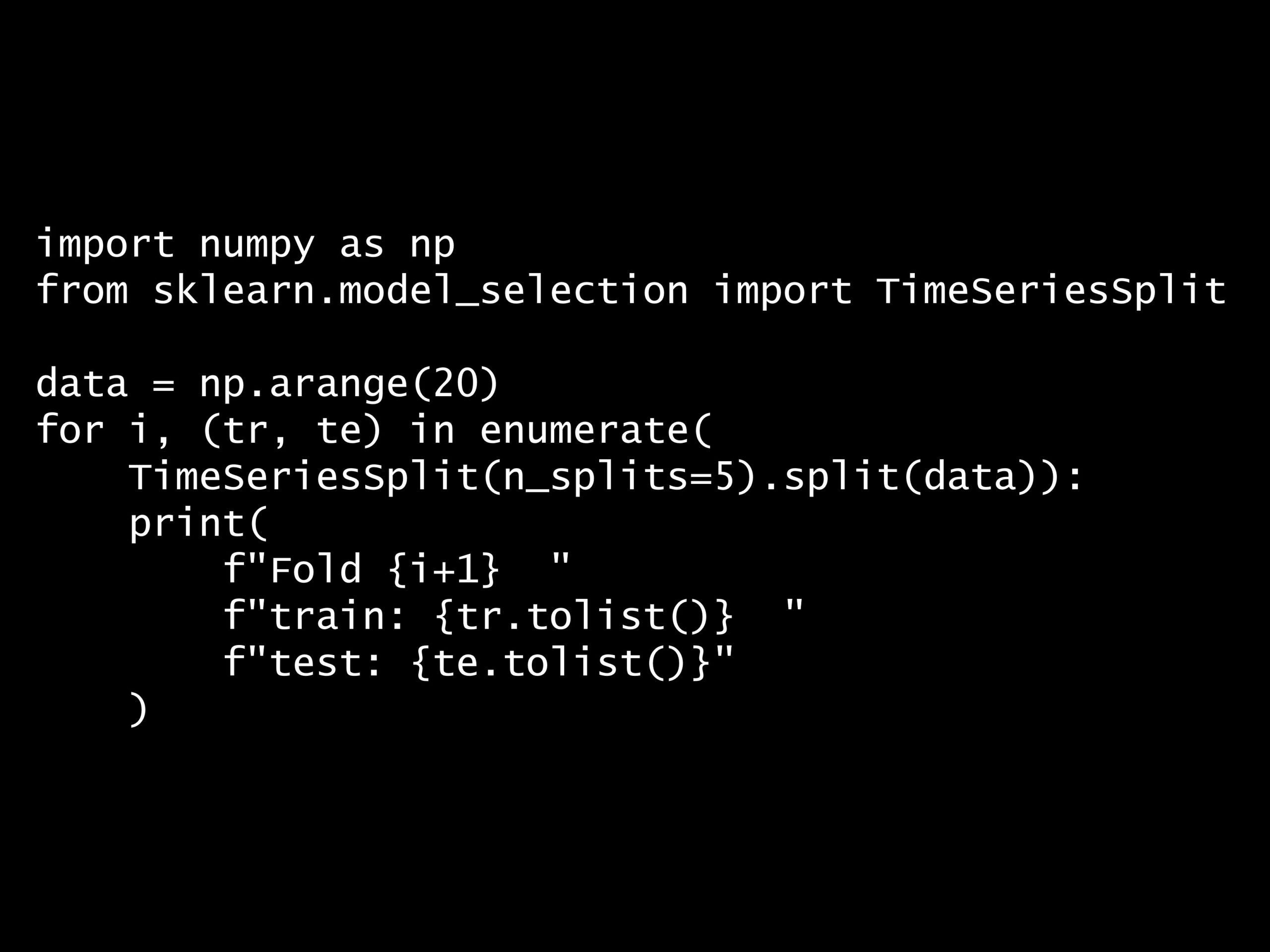
問題 答え 解説 次の Python コードでどのようなデータ分割をしていますか? Python コード: import numpy as np from sklearn.model_selection import T...
前回の記事では、minimize() を使って最適化問題を解く方法を紹介しました。 scipy.optimizeで最適化問題を解く入門 今回は、その応用とも言える 「カーブフィッティング(曲線あてはめ)」 を紹介します。...
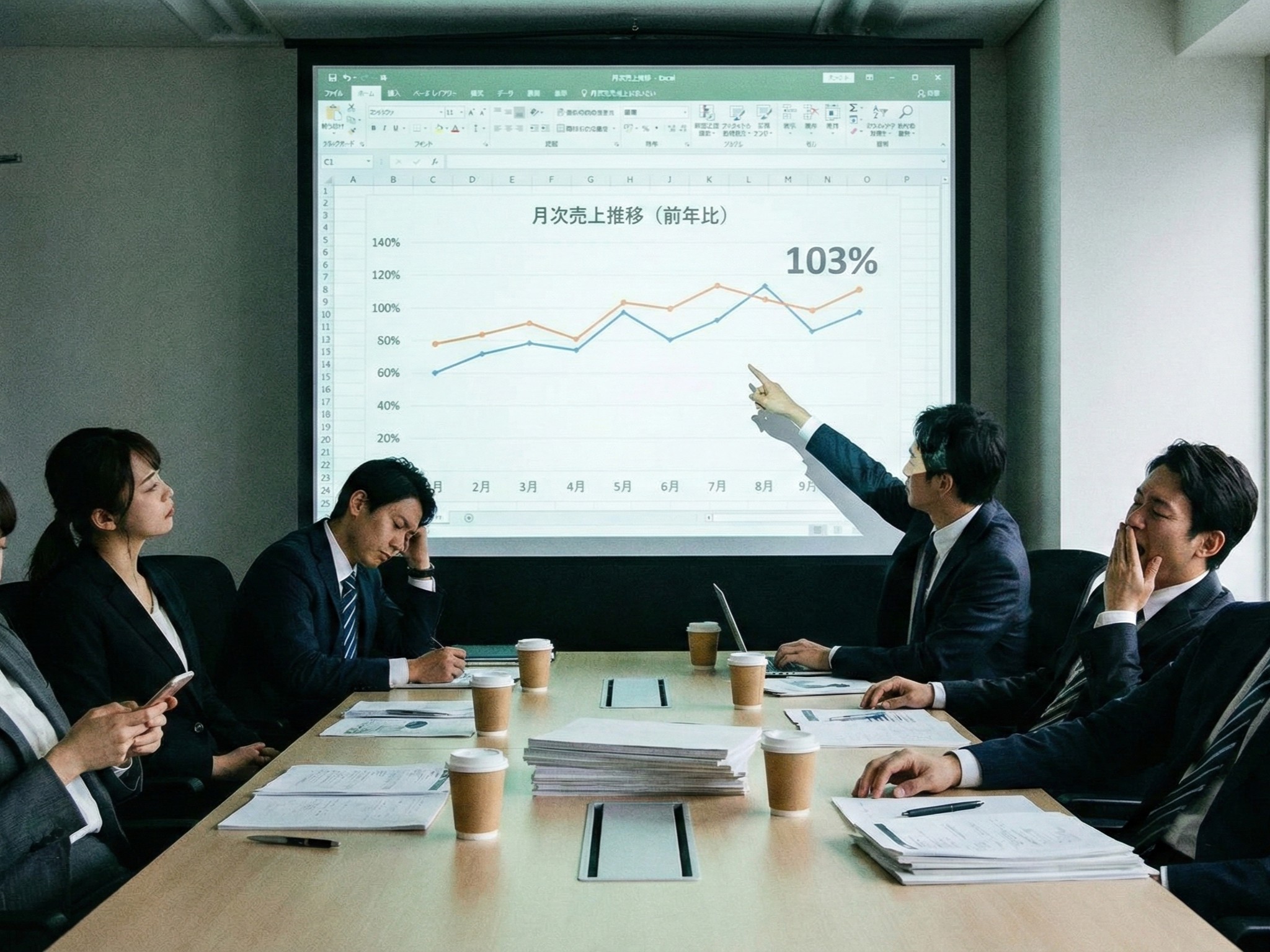
毎月の営業会議や経営会議で、こんな場面に心当たりはないでしょうか。 担当者がExcelやBIダッシュボードなどで作った売上の折れ線グラフをスクリーンに映し出します。 横軸は月、縦軸は売上金額。 前年同月の線と今年の線が並...
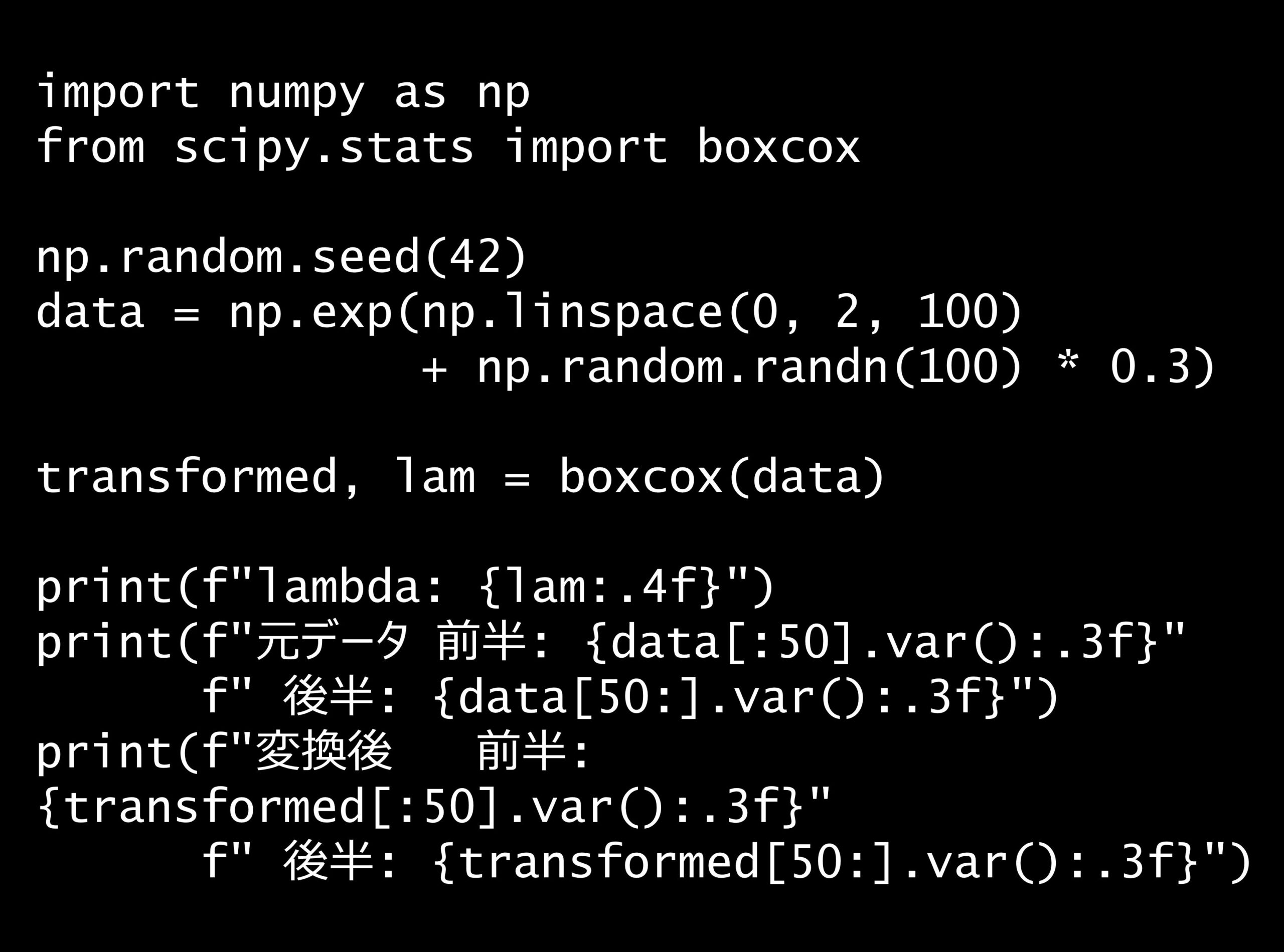
問題 答え 解説 次の Python コードで行っている変換の目的は何ですか? Python コード: import numpy as np from scipy.stats import boxcox np.rando...
データサイエンスや機械学習の世界では、「最適な値を見つける」 という作業が頻繁に登場します。 たとえば…… 広告費をどう配分すれば利益が最大になるか? 機械学習モデルの誤差を最小にするパラメータは何か? ……といった問題...
需要予測モデルを導入するとき、多くの企業が力を注ぐのは「いかに当たるモデルを作るか」です。 アルゴリズムの選定、学習データの整備、精度検証の設計。 どれも大切なステップですが、ここに一つ、ほとんどの企業が見落としている論...
問題 答え 解説 次の Python コードは何を行っていますか? Python コード: import numpy as np import pmdarima as pm np.random.seed(42) data...
前回の前編では、ロジスティック回帰で離脱予測モデルを構築し、混同行列と精度指標まで見ました。 今回の後編では決定木とランダムフォレストの2手法を追加し、ROC曲線で3モデルを横断比較します。 さらに「閾値の調整」で適合率...
とある動画配信サービスの運営チームの事例です。 サービスには数万人の月額会員がいますが、毎月一定数の会員が解約(離脱)しています。 新規会員を1人獲得するコストは、既存会員を1人引き留めるコストの5倍以上と言われており、...
前回(前編)、ドラッグストアの150店舗データに全変数を投入した重回帰分析を行い、「有意でない変数が混在している」「偏回帰係数をそのまま比較できない」「新しいデータへの予測力が未検証」という3つの問題点を特定しました。 ...
あなたは全国にドラッグストアを展開する企業の経営企画部に配属されました。 あなたは上司から…… 「来年の新規出店候補が10ヵ所ある。 どこに出店すれば売上が見込めるか、 データに基づいて優先順位をつけてほしい。」 「...