商工会議所で、スモールビジネスでもできるAIを使ったデータ活用術のお話しを、こっそりします。 タイトル: 〜小さな工夫で大きな成果!〜 「スモールビジネスで使える簡単データ活用術」 開催日: 2026年6月25日(木)1...
「これからはChatGPTがあれば、誰でも分析ができる時代だ」 そんな声が経営層から現場まで広がっています。 前回の記事では、生成AIが中小企業にもたらす逆転のチャンスについて取り上げ、確かに分析のハードルが大きく下がっ...
第3回・第4回では「欠損のある行や列を削除する」戦略を紹介しました。 今回からはいよいよ、欠損値処理のもう一つの大きな柱である 補完(imputation) に入っていきます。 補完にはさまざまな方法がありますが、まず押...
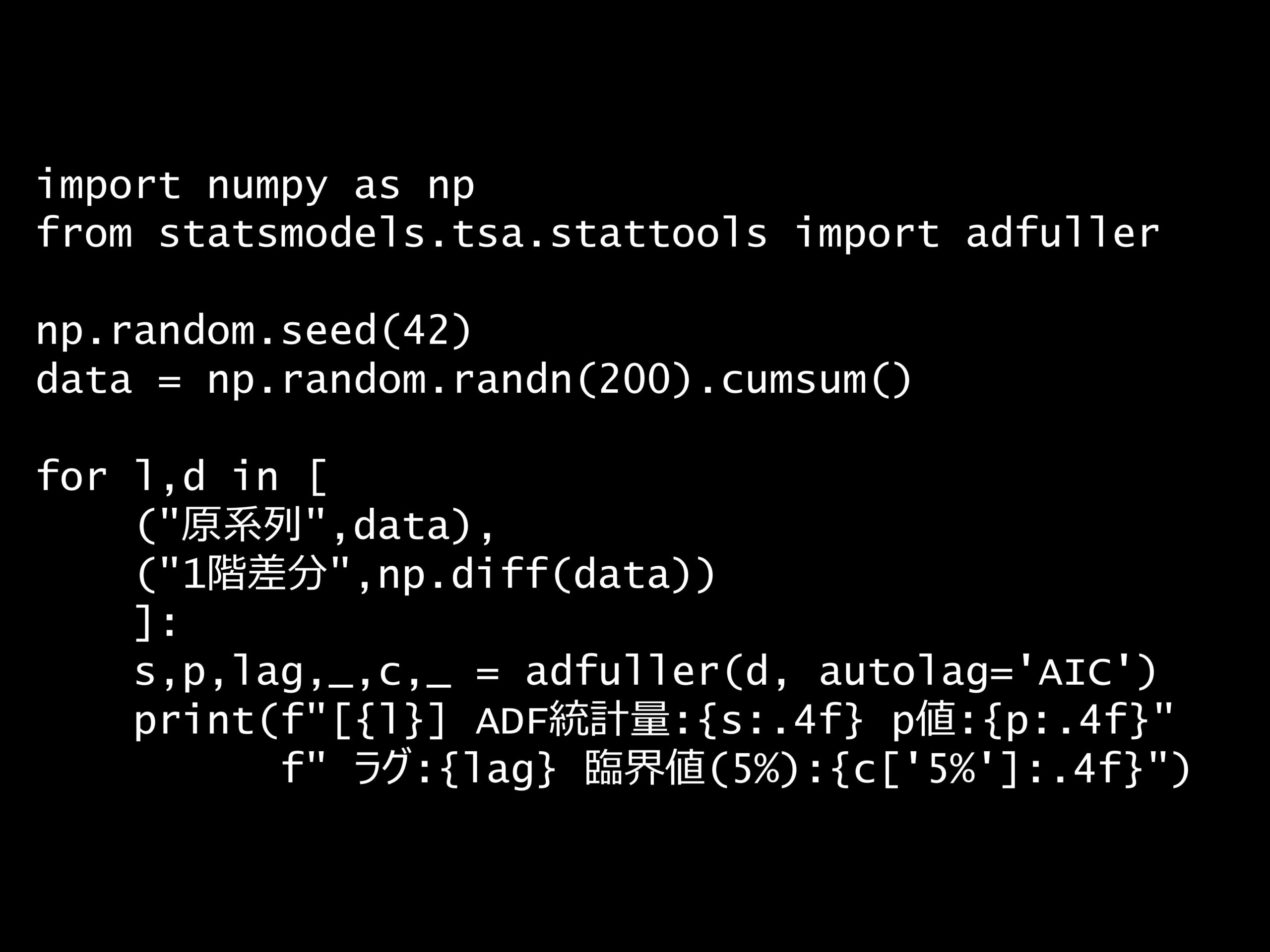
問題 答え 解説 次の Python コードの検定における帰無仮説は何ですか? Python コード: import numpy as np from statsmodels.tsa.stattools import a...
「データ分析は専門家がいる大企業の話で、うちのような中小企業には縁がない」 そんな声を、これまで多くの経営者から聞いてきました。 確かに、これまでデータ活用には専門人材の採用、高額なツールの導入、長期間の体制整備が必要で...
Tebiki株式会社主催(協賛:Sansan株式会社)のオンラインイベントで、製造業におけるAI活用のお話しをします。 製造業AI変革の全体設計図~現場からバックオフィスまで、今押さえるべきAI活用と実践~ 開催日:20...
第3回では、行を削除する リストワイズ削除(CCA)についてお話ししました。 今回はもう2つの削除戦略である、列(特徴量)を削除する 方法と、分析ごとに使えるデータを最大化する ペアワイズ削除を取り上げます。 行を削除す...
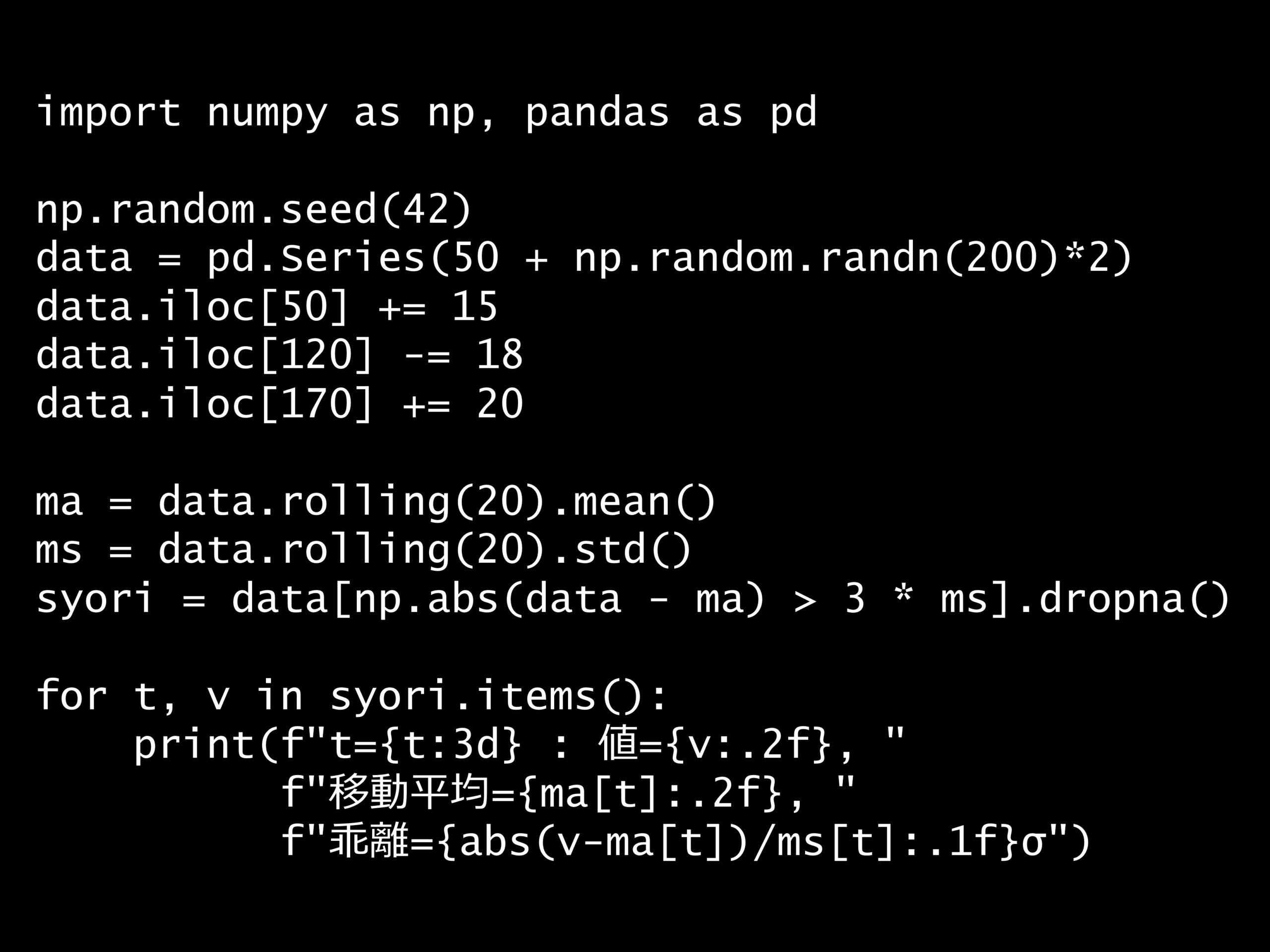
問題 答え 解説 次の Python コードが行っている処理の目的は何ですか? Python コード: import numpy as np, pandas as pd np.random.seed(42) data =...
「ChatGPTに聞けば、データ分析が誰でもできる時代になった」 そんな声が聞かれるようになって久しい今、多くのビジネスパーソンが期待と戸惑いの間で揺れています。 実際に生成AIを業務に取り入れた企業からは、「業務効率が...
第2回までで、欠損値の検出と可視化ができるようになりました。 次のステップは、いよいよ「実際にどう処理するか」です。 欠損値への対処法は大きく分けて 削除(deletion) と 補完(imputation) の2種類が...
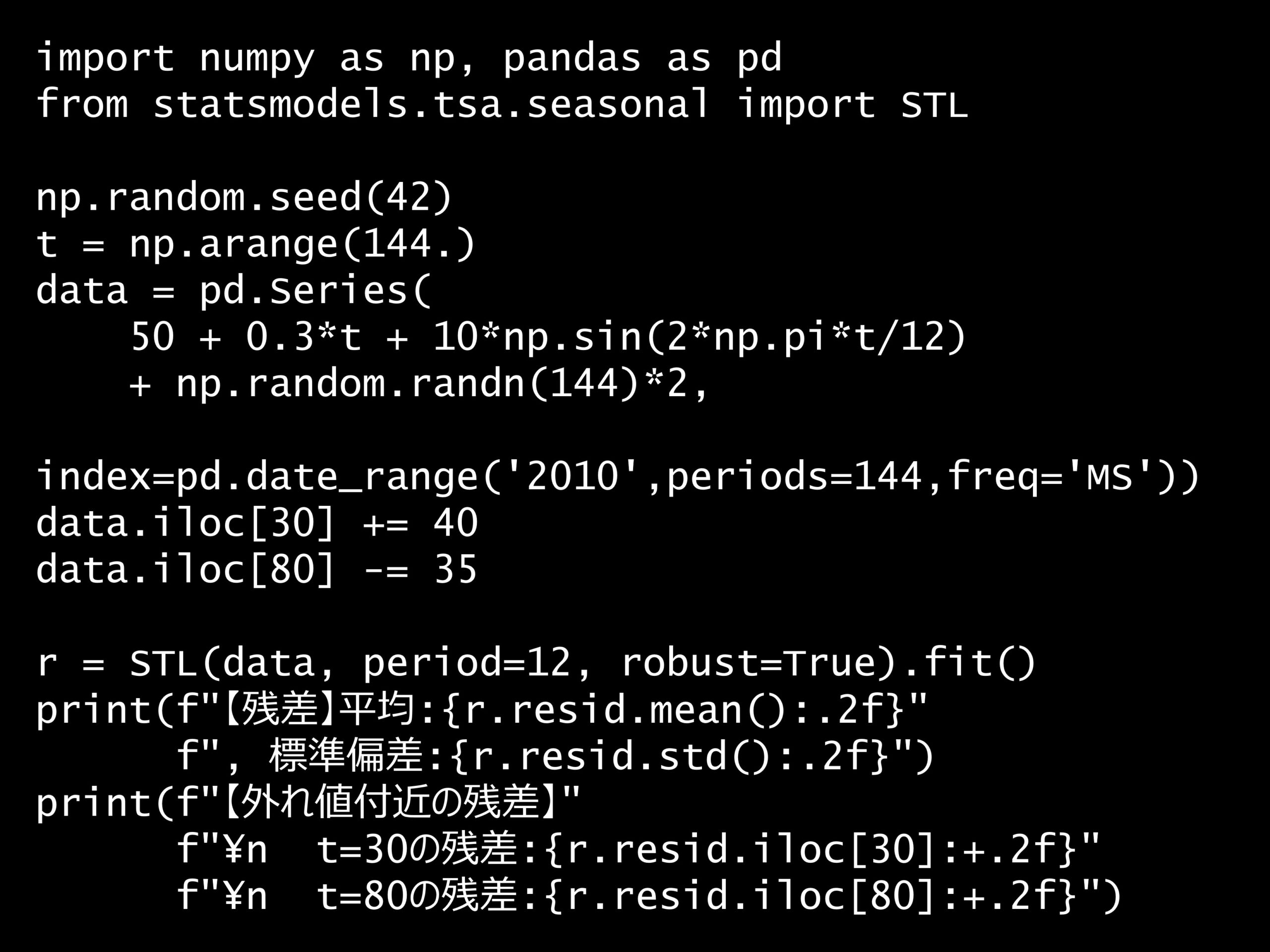
問題 答え 解説 次の Python コードで使用している STL 分解にはどのような利点がありますか? Python コード: import numpy as np, pandas as pd from statsmo...
ある企業で、こんな話を聞いたことがあります。 3年前、社内のデータサイエンティストが時間をかけて需要予測モデルを構築しました。 当時は画期的で、現場からも高く評価された。発注判断の一部に組み込まれ、業務に定着した。 それ...
前回(第1回)では、欠損値には MCAR・MAR・MNAR という3つのメカニズムがあり、それぞれに応じた処理が必要だ、という話をしました。 欠損値処理シリーズ 第1回:欠損値とは何か — MCAR / MAR / MN...
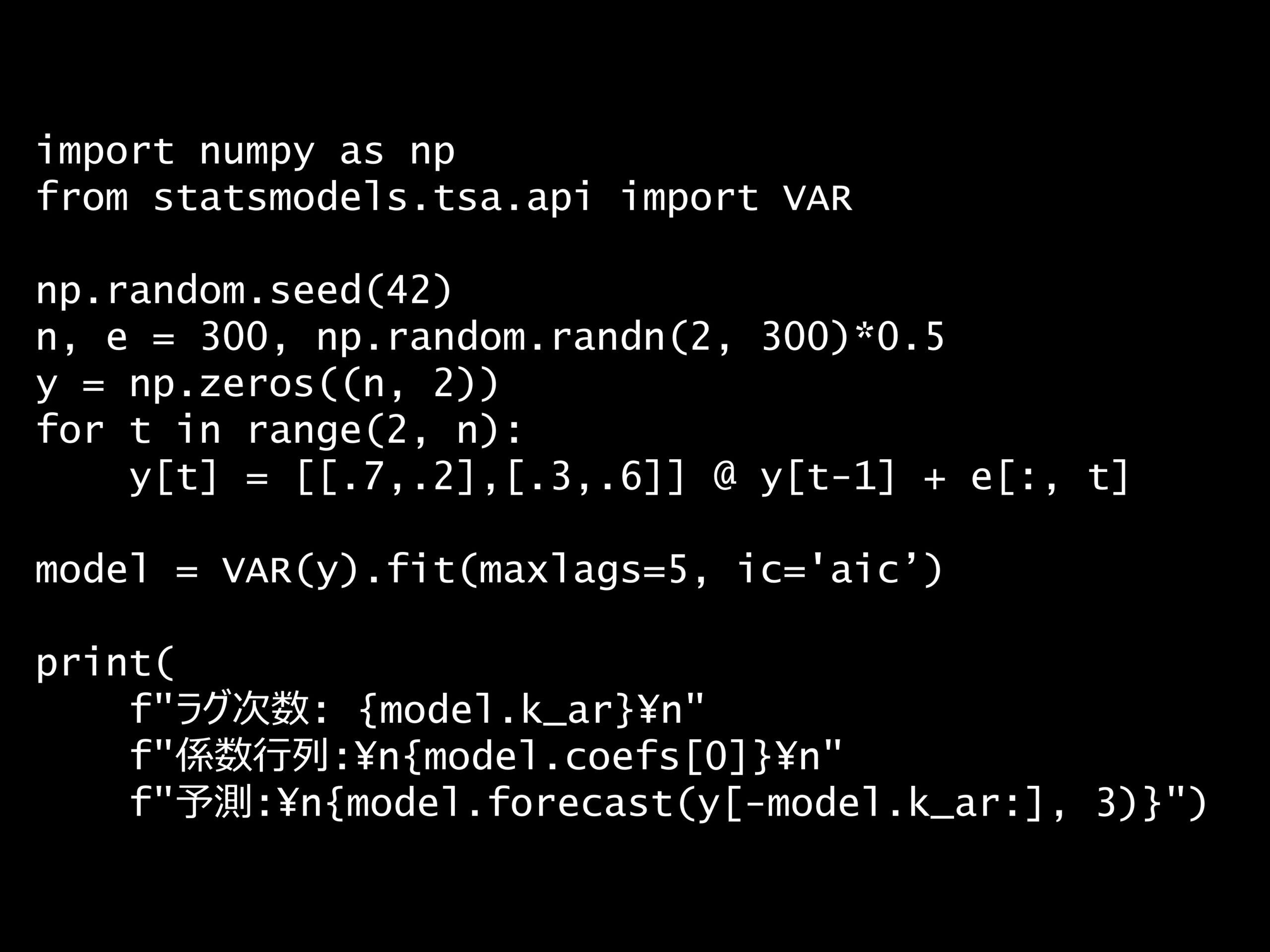
問題 答え 解説 次の Python コードのモデルの特徴は何ですか? Python コード: import numpy as np from statsmodels.tsa.api import VAR np.rand...
予測モデルを導入した組織には、ほぼ例外なく訪れる局面があります。 「今月の予測精度はどうだったか」を追いかける会議が始まる瞬間です。 最初は健全な取り組みに見えます。 予測モデルを運用しているのだから、その精度を定期的に...
機械学習モデルの精度がなかなか上がらない、と悩んだ経験はありませんか? データを集め、特徴量を整え、ハイパーパラメータも調整したのに結果が伸びない原因が、実は 欠損値(missing values) の扱い方にあった、と...