

とある動画配信サービスの運営チームの事例です。
サービスには数万人の月額会員がいますが、毎月一定数の会員が解約(離脱)しています。
新規会員を1人獲得するコストは、既存会員を1人引き留めるコストの5倍以上と言われており、離脱を事前に予測し、解約しそうな会員に対して先手を打つことは、ビジネス上きわめて重要です。
今回の前編では、この課題に分類モデルで挑む第一歩として、ロジスティック回帰のモデル構築から、混同行列を使った評価指標の正しい読み方までを体験します。
Contents
- 準備
- ライブラリのインポート
- 会員データの読み込み
- 探索的データ分析 ── 離脱者と継続者の「違い」を目で見る
- 箱ひげ図で2グループを比較する
- 相関係数で離脱との関連を数値化する
- データの前処理と分割
- 訓練データとテストデータに分割する
- データの標準化
- ロジスティック回帰モデルの構築
- ロジスティック回帰の数式を確認する
- モデルを構築して予測する
- 係数から離脱要因を読み解く
- 混同行列 ── 予測の「中身」を4つの箱で見る
- 混同行列とは何か
- 混同行列を可視化する
- 評価指標を正しく理解する ── 「正解率の罠」に注意
- なぜ正解率だけでは危険なのか
- 適合率・再現率・F1スコア
- 精度指標をまとめて計算する
- 分類レポートでクラスごとに確認する
- まとめ
準備
ライブラリのインポート
今回使用するライブラリをまとめてインポートします。
分類モデルの構築(LogisticRegression)と評価(confusion_matrix, classification_report など)に必要なツールを読み込みます。
以下、コードです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
confusion_matrix, classification_report,
roc_auc_score, accuracy_score,
precision_score, recall_score, f1_score
)
sklearn.metricsには分類モデル専用の評価指標が多数用意されており、混同行列やROC曲線なども簡単に描くことができます。
会員データの読み込み
サンプルデータとして、動画配信サービスの3000人分の会員データを使います。
各会員について属性情報(契約月数、月額プラン、年齢)と利用状況(視聴時間、ログイン日数など)を記録し、最終的に「離脱したかどうか」のラベルがついたデータです。離脱率は約30%です。
サンプルデータは、以下からダウンロードできます。
members_data.csv
以下、コードです。
# データの読み込み
df = pd.read_csv('members_data.csv')
print(f"会員データ: {len(df)} × {len(df.columns)} columns")
print(f"\n離脱率: {df['churn'].mean():.1%}")
print(f"(継続: {(df['churn']==0).sum()}, 離脱: {(df['churn']==1).sum()})")
print(f"\n最初の5人分:")
print(df.head())
以下、実行結果です。
会員データ: 3000 × 9 columns 離脱率: 30.6% (継続: 2082, 離脱: 918) 最初の5人分: contract_months monthly_plan age watch_hours login_days \ 0 8 1200 22 1.401587 11 1 54 1200 40 3.557839 10 2 23 800 38 10.461294 16 3 16 1200 46 0.303220 14 4 3 1200 25 4.372440 13 favorite_count inquiry_count watch_decrease_rate churn 0 5 0 0.928041 1 1 9 0 -20.682194 0 2 17 2 -1.782878 0 3 8 1 23.058519 1 4 8 0 -8.213625 1
以下、変数の意味です。
- contract_months: 継続月数
- monthly_plan: 月額プラン(800/1200/1800円)
- age: 年齢
- watch_hours: 月間視聴時間
- login_days: 月内ログイン日数
- favorite_count: お気に入り登録数
- inquiry_count: 問い合わせ件数
- watch_decrease_rate: 視聴時間の減少率
- churn: 離脱フラグ(1=離脱、0=継続)
目的変数はchurn(離脱フラグ)です。
データの全体像を基本統計量で把握します。
print("【基本統計量】")
print(df.describe().round(1))
以下、実行結果です。
【基本統計量】
contract_months monthly_plan age watch_hours login_days \
count 3000.0 3000.0 3000.0 3000.0 3000.0
mean 17.0 1154.7 34.7 15.1 12.0
std 15.9 366.5 11.3 14.7 3.5
min 1.0 800.0 18.0 0.0 2.0
25% 5.0 800.0 26.0 4.3 10.0
50% 12.0 1200.0 34.0 10.5 12.0
75% 25.0 1200.0 43.0 21.3 14.0
max 60.0 1800.0 70.0 80.0 25.0
favorite_count inquiry_count watch_decrease_rate churn
count 3000.0 3000.0 3000.0 3000.0
mean 8.0 0.5 0.3 0.3
std 2.8 0.7 20.2 0.5
min 0.0 0.0 -50.0 0.0
25% 6.0 0.0 -13.8 0.0
50% 8.0 0.0 0.1 0.0
75% 10.0 1.0 14.2 1.0
max 20.0 4.0 70.7 1.0
探索的データ分析 ── 離脱者と継続者の「違い」を目で見る
箱ひげ図で2グループを比較する
離脱/継続の2グループで各変数の分布を比較する箱ひげ図を描きます。
グループ間に明確な違いがある変数は、モデルが離脱を予測するための「手がかり」になると期待できます。
以下、コードです。
# 4行×2列のプロット領域を用意
fig, axes = plt.subplots(4, 2, figsize=(8, 10))
# 2次元のaxesを1次元に並べ替え
axes = axes.flatten()
# 目的変数を除く特徴量の列名一覧
feature_cols = [c for c in df.columns if c != 'churn']
# 各特徴量について、離脱/継続ごとの箱ひげ図を描画
for i, col in enumerate(feature_cols):
# 箱ひげ図の描画
df.boxplot(
column=col, by='churn', ax=axes[i], # churnでグループ化
boxprops=dict(color='#2E86AB'), # 箱の色
medianprops=dict(color='#E94F37') # 中央値ラインの色
)
axes[i].set_title(col, fontsize=11)
axes[i].set_xlabel('')
axes[i].set_xticklabels(['継続', '離脱'])
plt.suptitle('離脱/継続グループの比較', fontsize=14, y=1.02)
plt.tight_layout()
plt.show()
以下、実行結果です。
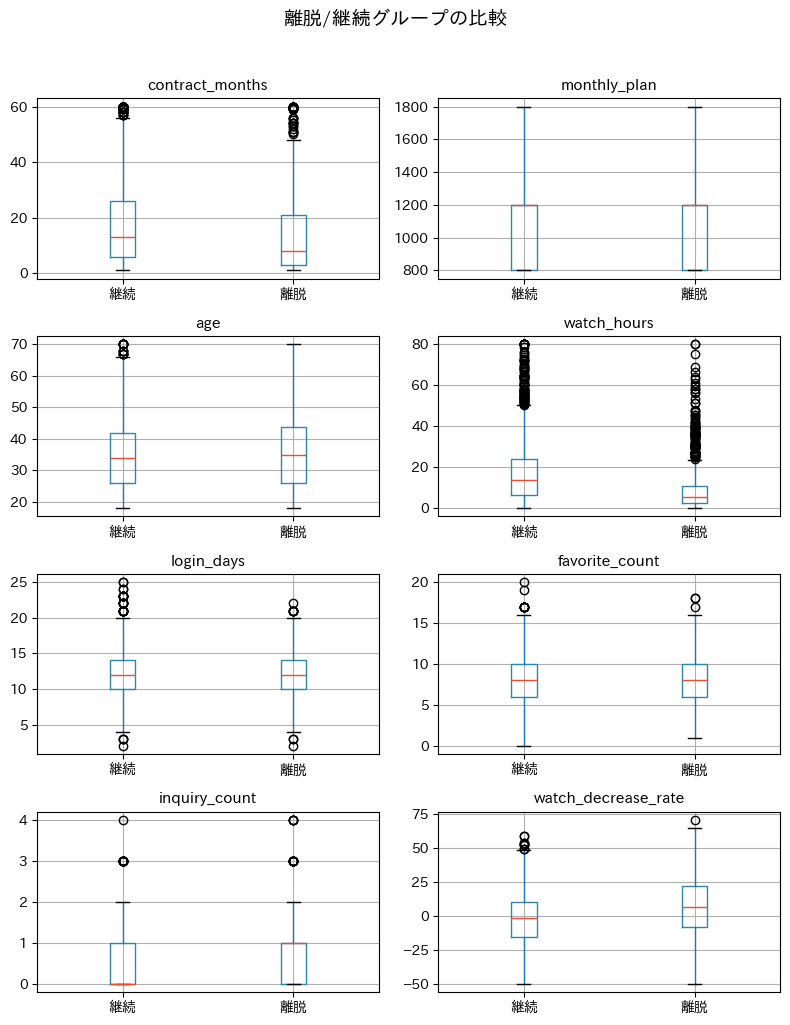
箱ひげ図から、離脱グループと継続グループの違いが見えてきます。
離脱会員は月間視聴時間(watch_hours)が低く、直近30日の視聴減少率(watch_decrease_rate)が高い傾向があるはずです。
一方で、年齢(age)や月額プラン(monthly_plan)にはあまり差がないかもしれません。
このような「効きそうな変数」の見当をつけておくことは、モデルの結果を解釈する際にも役立ちます。
相関係数で離脱との関連を数値化する
各変数と離脱の相関を数値で確認します。
相関係数が正の変数は「値が大きいほど離脱しやすい」、負の変数は「値が大きいほど継続しやすい」ことを意味します。
以下、コードです。
# 離脱との相関を計算し、降順にソート
corr_with_churn = df.corr()['churn'].drop('churn').sort_values()
# 相関の大きさと方向を表示
print("【離脱との相関(ポイントバイシリアル相関)】")
for var, r in corr_with_churn.items():
direction = "離脱↑" if r > 0 else "離脱↓"
print(f" {var:18s}: r = {r:+.3f} ({direction})")
以下、実行結果です。
【離脱との相関(ポイントバイシリアル相関)】 watch_hours : r = -0.245 (離脱↓) contract_months : r = -0.109 (離脱↓) favorite_count : r = -0.068 (離脱↓) login_days : r = -0.020 (離脱↓) monthly_plan : r = -0.017 (離脱↓) age : r = +0.033 (離脱↑) inquiry_count : r = +0.131 (離脱↑) watch_decrease_rate: r = +0.192 (離脱↑)
月間視聴時間(watch_hours)や継続月数(contract_months)は負の相関(利用が多いほど継続)、直近の視聴減少率(watch_decrease_rate)や問い合わせ回数(inquiry_count)は正の相関(増えると離脱)という結果が予想されます。
ただし、この相関は単純な二変量の関係であり、複数の要因を同時に考慮したロジスティック回帰の結果とは異なる場合があります。
データの前処理と分割
訓練データとテストデータに分割する
データを訓練データ(80%)とテストデータ(20%)に分割します。
ここで重要なのは stratify=y の指定です。
これにより、訓練データとテストデータの離脱率が元データとほぼ同じになるよう層化抽出されます。
以下、コードです。
# 説明変数と目的変数
X = df.drop('churn', axis=1)
y = df['churn']
# 訓練データ(80%)とテストデータ(20%)に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42,
stratify=y
)
print(f"訓練データ: {len(X_train)}人")
print(f"テストデータ: {len(X_test)}人")
print(f"\n訓練データの離脱率: {y_train.mean():.1%}")
print(f"テストデータの離脱率: {y_test.mean():.1%}")
以下、実行結果です。
訓練データ: 2400人 テストデータ: 600人 訓練データの離脱率: 30.6% テストデータの離脱率: 30.7%
訓練データとテストデータの離脱率がほぼ同じ値(約30%)になっています。
stratify=y を指定しないと、偶然テストデータに離脱者が偏って含まれたりして、評価が不安定になるおそれがあります。
クラスが不均衡なデータでは、層化抽出は必須の前処理です。
データの標準化
ロジスティック回帰のためにデータを標準化します。
標準化は訓練データで計算した平均・標準偏差をテストデータにも適用する点が重要です。
以下、コードです。
# 標準化スカラーのインスタンスを作成 scaler = StandardScaler() # 訓練データで学習+変換 X_train_scaled = scaler.fit_transform(X_train) # テストデータは変換のみ X_test_scaled = scaler.transform(X_test)
fit_transform (学習を行い、その後に変換を実施)は訓練データにのみ使い、テストデータには transform (変換のみ)だけを使うのがルールです。
ロジスティック回帰モデルの構築
ロジスティック回帰の数式を確認する
目的変数が0か1の二値をとる場合、「ある事象が起こる確率 p」をモデル化したいのですが、
確率は0〜1の範囲にしか取れません。
そこで、確率 p をオッズ比 \displaystyle \frac{p}{1-p} に変換し、さらにその対数(ログオッズまたはロジット)を取ります。
$$
\log\left(\frac{p}{1-p}\right) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p
$$
この式の右辺は通常の重回帰分析と同じ形をしています。左辺のロジット変換により、右辺が任意の実数値を取っても、確率 p は0〜1の範囲に収まります。逆に解くと、
$$
p = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x_1 + \cdots + \beta_p x_p)}}
$$
これがシグモイド関数と呼ばれる形で、S字のカーブを描きます。入力値(右辺の線形結合)が大きくなるほど確率は1に近づき、小さくなるほど0に近づきます。
モデルを構築して予測する
ロジスティック回帰モデルを構築し、テストデータで予測を行います。
predict はラベル(0/1)を、predict_proba は離脱確率(0〜1の連続値)の予測値を返します。
以下、コードです。
# ロジスティック回帰モデルの構築
model_lr = LogisticRegression(random_state=42, max_iter=1000)
model_lr.fit(X_train_scaled, y_train)
# テストデータで予測
# ラベル(0 or 1)
y_pred = model_lr.predict(X_test_scaled)
# 離脱確率
y_prob = model_lr.predict_proba(X_test_scaled)[:, 1]
print("【ロジスティック回帰の予測結果(最初の10人)】")
result_df = pd.DataFrame({
'churn_prob': y_prob[:10].round(3),
'pred': y_pred[:10],
'actual': y_test.values[:10]
})
print(result_df.to_string(index=False))
以下、実行結果です。
【ロジスティック回帰の予測結果(最初の10人)】
churn_prob pred actual
0.230 0 0
0.225 0 0
0.287 0 0
0.425 0 0
0.217 0 0
0.084 0 0
0.149 0 0
0.330 0 0
0.213 0 0
0.449 0 1
各会員について「離脱確率」(churn_prob)と「予測ラベル」(pred)と「実際のラベル」(actual)が並んで表示されます。
デフォルトでは確率が0.5以上なら離脱(1)、未満なら継続(0)と予測します。
離脱確率が0.3の会員は「30%の確率で離脱する」と推定されたことを意味し、この確率値そのものがビジネスで活用できます。
たとえば「離脱確率が高い順にクーポンを配布する」といった施策が考えられます。
実務では、この閾値(0.5)をビジネスの要件に合わせて調整することがよくあります。
係数から離脱要因を読み解く
ロジスティック回帰の係数を確認します。
標準化データで学習しているため、係数の絶対値が大きい変数ほど離脱/継続の判断に大きな影響を与えています。
以下、コードです。
# 係数をデータフレームにまとめる
coef_df = pd.DataFrame({
'feature': X.columns,
'coef': model_lr.coef_[0]
}).sort_values('coef')
print("【ロジスティック回帰の係数(標準化データ)】")
for _, row in coef_df.iterrows():
direction = "→ 離脱↑" if row['coef'] > 0 else "→ 継続↑"
print(
f" {row['feature']:18s}: "
f"{row['coef']:+.4f} {direction}"
)
以下、実行結果です。
【ロジスティック回帰の係数(標準化データ)】 watch_hours : -0.7398 → 継続↑ contract_months : -0.3078 → 継続↑ favorite_count : -0.1505 → 継続↑ login_days : -0.0719 → 継続↑ monthly_plan : -0.0235 → 継続↑ age : +0.0512 → 離脱↑ inquiry_count : +0.3141 → 離脱↑ watch_decrease_rate: +0.4347 → 離脱↑
係数がプラスの変数は「値が増えるほど離脱しやすい」、マイナスの変数は「値が増えるほど継続しやすい」ことを意味します。
たとえば問い合わせ回数(inquiry_count)や視聴減少率(watch_decrease_rate)のプラス係数は「不満のシグナル」、月間視聴時間(watch_hours)やログイン日数(login_days )のマイナス係数は「エンゲージメントの高さ」を反映しています。
混同行列 ── 予測の「中身」を4つの箱で見る
混同行列とは何か
分類モデルの評価で最も基本的なツールが混同行列(Confusion Matrix)です。
予測結果を4つのセルに分類した表で、モデルの「どこが得意で、どこが苦手か」が一目でわかります。
| 予測: 離脱 | 予測: 継続 | |
|---|---|---|
| 実際: 離脱 | TP(真陽性) | FN(偽陰性) |
| 実際: 継続 | FP(偽陽性) |
この4つのセルをビジネスの文脈で理解しておきましょう。
- TP(真陽性):離脱を正しく離脱と予測。引き留め施策を打てる。
- TN(真陰性):継続を正しく継続と予測。何もしなくてOK。
- FP(偽陽性):実際は継続なのに離脱と予測。不要なクーポンを配るコストが発生するが、致命的ではない。
- FN(偽陰性):実際は離脱するのに継続と予測。見逃し。引き留め施策を打てないまま会員を失うビジネス上最も痛いミスです。
混同行列を可視化する
ロジスティック回帰の混同行列を計算し、ヒートマップで可視化します。
以下、コードです。
# 混同行列の作成
cm = confusion_matrix(y_test, y_pred)
# 混同行列の可視化
plt.figure(figsize=(7, 5))
# 混同行列のヒートマップを描画
sns.heatmap(
cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['継続', '離脱'],
yticklabels=['継続', '離脱'],
annot_kws={'size': 16}
)
plt.xlabel('予測', fontsize=12)
plt.ylabel('実際', fontsize=12)
plt.title('混同行列(ロジスティック回帰)', fontsize=14)
plt.tight_layout()
plt.show()
以下、実行結果です。
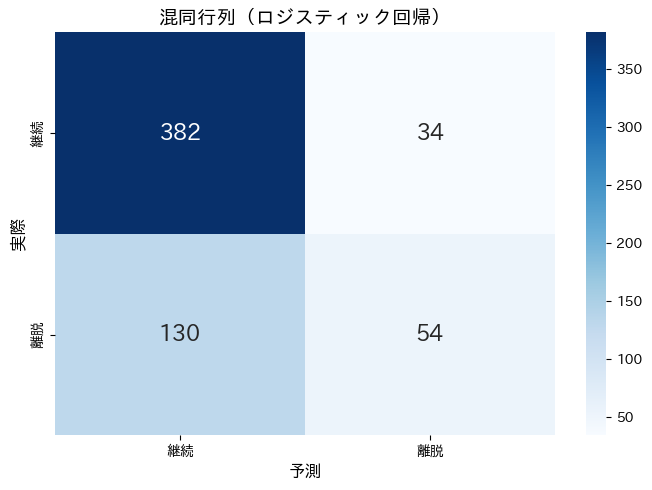
4つのセルの数値が表示されます。
- 左上 – 真陰性 (TN): 382 — 継続を正しく継続と予測
- 右上 – 偽陽性 (FP): 34 — 継続なのに離脱と予測(過剰反応)
- 左下 – 偽陰性 (FN): 130 — 離脱なのに継続と予測(見逃し)
- 右下 – 真陽性 (TP): 54 — 離脱を正しく離脱と予測
FP(偽陽性)は「実際には継続する会員に不要なクーポンを配る」コストが発生しますが、FN(偽陰性)は「離脱する会員を見逃す」という直接的な損失につながります。
どちらを重視すべきかは、ビジネスの状況(クーポンのコスト vs 会員喪失の損失)によって変わります。
この「ビジネスに応じた評価指標の選び方」こそが、分類モデルで最も重要な判断のひとつです。
評価指標を正しく理解する ── 「正解率の罠」に注意
なぜ正解率だけでは危険なのか
混同行列から、さまざまな精度指標を計算できます。まず正解率(Accuracy)を見てみましょう。
$$
\text{正解率} = \frac{TP + TN}{TP + FP + FN + TN}
$$
正解率は「全体のうち正しく予測できた割合」であり、直感的でわかりやすい指標です。
しかし、ここに大きな落とし穴があります。
仮に全員を「継続」と予測しても、離脱率が30%なら正解率は70%になってしまいます。
一見すると「70%の正解率」は悪くないように見えますが、この予測は離脱者を1人も見つけられていません。
つまり、クラスが不均衡なデータでは、正解率だけでモデルの良し悪しを判断するのは危険です。
適合率・再現率・F1スコア
そこで、離脱クラスに焦点を当てた指標が必要になります。
適合率(Precision)
$$\text{適合率} = \frac{TP}{TP + FP}$$
「離脱と予測した人のうち、本当に離脱した人の割合」です。クーポン配布の無駄打ちを減らしたいときに重視します。
再現率(Recall)
$$\text{再現率} = \frac{TP}{TP + FN}$$
「実際に離脱した人のうち、離脱と予測できた人の割合」です。見逃しを減らしたいときに重視します。
F1スコア
$$\text{F1スコア} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}$$
適合率と再現率のバランスを取った指標です。
どちらを重視すべきかはビジネス次第です。
離脱予測の場合、一般的にはFN(見逃し)のコストが大きいため、再現率を優先することが多いです。
ただし、再現率を上げすぎると適合率が下がる(本当は継続する会員にも大量のクーポンを配ることになる)というトレードオフがあるため、F1スコアでバランスを確認することが重要です。
精度指標をまとめて計算する
ロジスティック回帰の各種精度指標を計算します。
AUC(ROC曲線下面積)は、モデル全体の識別力を0〜1で評価する指標で、1に近いほどモデルの識別力が高いことを意味します。
以下、コードです。
print("【ロジスティック回帰の精度指標】")
print(f"正解率 (Accuracy): {accuracy_score(y_test, y_pred):.3f}")
print(f"適合率 (Precision): {precision_score(y_test, y_pred):.3f}")
print(f"再現率 (Recall): {recall_score(y_test, y_pred):.3f}")
print(f"F1スコア: {f1_score(y_test, y_pred):.3f}")
print(f"AUC: {roc_auc_score(y_test, y_prob):.3f}")
以下、実行結果です。
【ロジスティック回帰の精度指標】 正解率 (Accuracy): 0.727 適合率 (Precision): 0.614 再現率 (Recall): 0.293 F1スコア: 0.397 AUC: 0.731
今回構築したロジスティックモデルは、全体としてはまずまずの識別力を持ちますが、離脱者の取りこぼしが多い状態です。
指標ごとに解釈いたします。
- 正解率 0.727:全体の約73%を正しく分類できています。継続者が多いので、継続を当てやすいモデルでも正解率は高く見えやすいため、単独では十分な評価になりにくい指標です。
- 適合率 0.614:「離脱」と予測した中の約61%が実際に離脱します。営業・CSのリソースを離脱予測者に集中させる際、空振り(誤って継続者に対応する)をある程度抑えられている水準といえます。
- 再現率 0.293:実際の離脱者のうち約29%しか拾えていません。離脱者の見逃しが多く、チャーン抑止を主目的とする運用では改善余地が大きいです。
- F1スコア 0.397:適合率と再現率のバランス指標としては低めです。現状は適合率寄りで、再現率がボトルネックになっています。
- AUC 0.731:スコアの順位付け能力は良好です。確率スコアで並べたときに、離脱者が継続者より高スコアを取る確率が約73%であり、しきい値最適化や上位n%抽出の運用には有効です。
総合すると、モデルは「誰を優先対応すべきか」を順位付けする力(AUC)は十分ありますが、現在のデフォルトしきい値では離脱者の検知(再現率)が不足しています。
分類レポートでクラスごとに確認する
scikit-learnのclassification_reportで、継続クラスと離脱クラスそれぞれの精度指標をまとめて確認します。
以下、コードです。
print("【分類レポート】")
print(
classification_report(
y_test, y_pred,
target_names=['継続', '離脱']
)
)
以下、実行結果です。
【分類レポート】
precision recall f1-score support
継続 0.75 0.92 0.82 416
離脱 0.61 0.29 0.40 184
accuracy 0.73 600
macro avg 0.68 0.61 0.61 600
weighted avg 0.71 0.73 0.69 600
classification_report はクラスごとの精度指標をまとめて表示してくれる便利な関数です。
support 列は各クラスの実際のデータ数です。
macro avg は各クラスの指標の単純平均、weighted avg はデータ数で重み付けした平均です。
クラス不均衡のあるデータでは weighted avg の方が実態に近い値になりますが、少数クラス(離脱)の性能を見逃しやすいため、必ず「離脱」行の再現率も個別に確認するようにしましょう。
指標ごとに解釈いたします。
継続クラス(0)の指標
精度(precision)0.75、再現率(recall)0.92、F1 0.82と高く、継続者を見逃しにくく、かつ継続と予測した際の的中率も十分です。データ内で継続者が多数派であることと、モデルが継続側に寄った判断をしていることがうかがえます。
離脱クラス(1)の指標
精度0.61は、離脱と予測したうち約6割が実際に離脱であることを示し、過度な空振りは抑えられています。しかし再現率0.29と低く、実際の離脱者の約3割しか捉えられていません。F1が0.40にとどまるのは、この再現率の低さがボトルネックになっているためです。離脱者検知を重視する運用では改善余地が大きいといえます。
全体指標
accuracy 0.73は悪くありませんが、クラス不均衡の影響を受けやすいため単独評価には注意が必要です。macro avg(各クラスを同等重みで平均)はprecision 0.68、recall 0.61、F1 0.61で、特にrecallが伸びていない点が課題です。weighted avgは多数派の継続クラスの良好な成績に引っ張られ、0.69前後に収まっています。
総合すると、モデルは「間違って離脱と判定する」リスクは一定程度抑えつつ、離脱者の取りこぼしが多い状態です。
まとめ
今回の前編では、動画配信サービスの会員データを題材に、以下のステップを体験しました。
| ステップ | やったこと | 得られた知見 |
|---|---|---|
| データの理解 | 基本統計量と離脱率の確認 | クラスの不均衡(離脱≈30%)の把握 |
| EDA | 箱ひげ図 + 相関係数 | 離脱者は視聴時間が少なく、問い合わせが多い傾向 |
| 前処理 | 層化抽出 + 標準化 | データリーケージ防止の作法 |
| モデル構築 | ロジスティック回帰 | 離脱確率の推定と係数による要因分析 |
| 混同行列 | TP/FP/FN/TNの4分類 | FN(見逃し)のビジネスコストの理解 |
| 精度指標 | Accuracy/Precision/Recall/F1/AUC |
前編で最も重要なのは、「正解率だけでモデルを評価してはいけない」という気づきです。
不均衡データでは、再現率(見逃しの少なさ)や適合率(無駄打ちの少なさ)など、ビジネスの目的に合った指標を選ぶ必要があります。
次回の後編では、決定木とランダムフォレストという2つの手法を追加でモデルを構築し、ROC曲線による3モデルの比較、変数重要度の分析などまで行います。