

RだろうがPythonだろうが、データフレームを再構築することは少なくないでしょう。
例えば……
- 縦持ち(Long)のデータフレームを、横持ち(Wide)のデータフレームに再構築
- 横持ち(Wide)のデータフレームを、縦持ち(Long)のデータフレームに再構築
なんのこっちゃ…… と思われている方もいるかもしれませんが、データ分析などをしていると、このような再構築が必要になるケースが少なくありません。
今回は、「便利だけど分かりにくいデータフレームを再構築するPandasのMelt()関数のお話し」というお話しをします。
その中で、縦持ちのデータフレーム(Long DataFrame)や横持ちのデータフレーム(Wide DataFrame)というデータフレームが、どういったものなのかのお話しもします。
melt()関数 と pivot()関数
pivot()関数 に馴染みある方も多いと思います。
melt ()関数はpivot()関数 の逆のことをします。
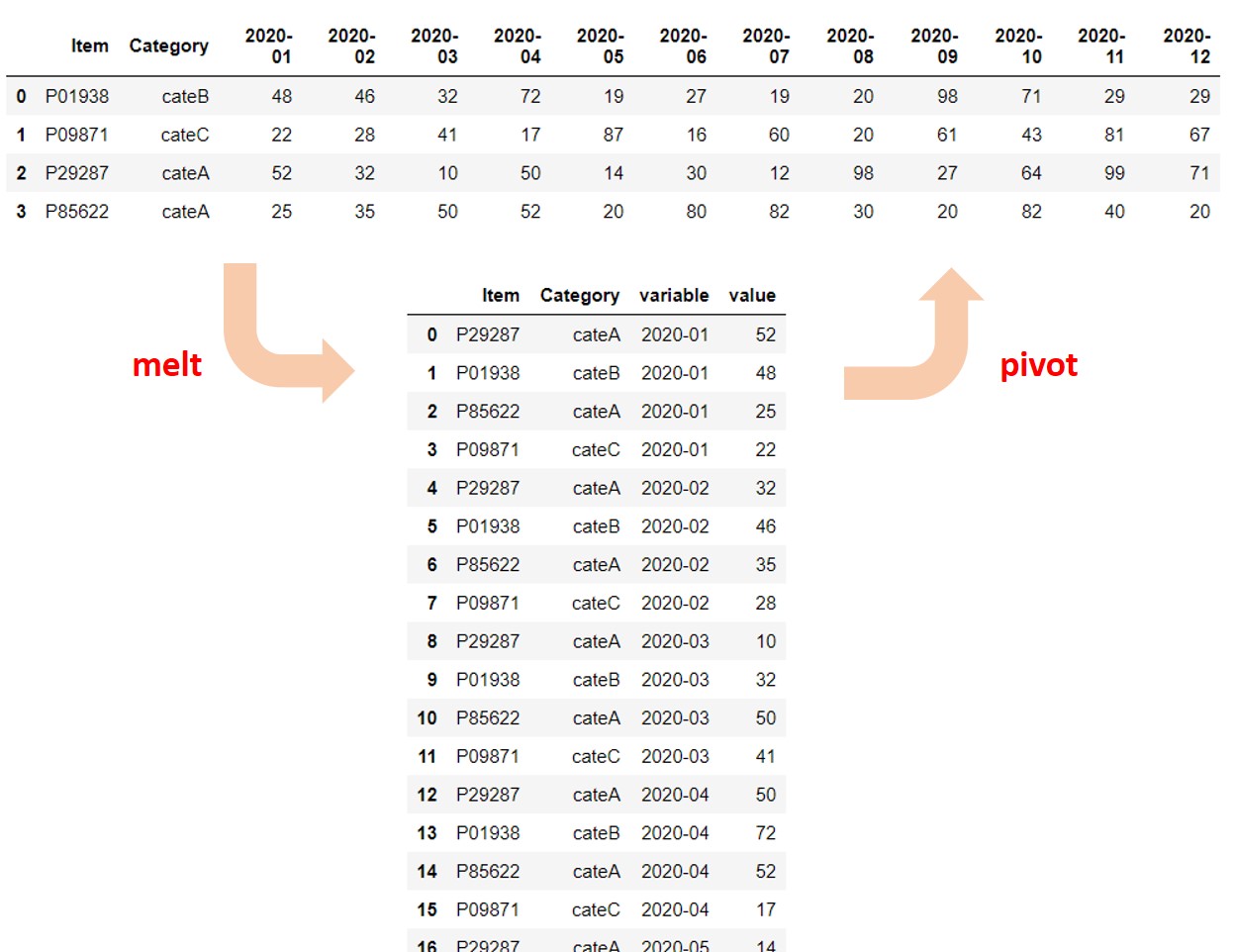
pivot したものを melt するともとに戻ります。同様に、melt したものをpivot するともとに戻ります。
上の図から分かる通り、 melt()関数を使うことで、横持ちのデータフレーム(Wide DataFrame)を、縦持ちのデータフレーム(Long DataFrame)に再構築することができます。
pivot()関数を使うことで、縦持ちのデータフレーム(Long DataFrame)を、横持ちのデータフレーム(Wide DataFrame)に再構築することができます。
melt() 関数
最初に、melt()関数そのものの説明を簡単にします。
pandas.melt(df,
id_vars=None,
value_vars=None,
var_name=None,
value_name='value',
col_level=None)
- df:対象となるデータフレーム
- id_vars:IDとして利用する変数(カラム)
- value_vars:melt する変数(カラム)、無指定の場合はid_vars以外の変数全部
- var_name:variable変数の変数(カラム)名、無指定の場合はvariableが変数(カラム)名になる
- value_name:value変数の変数(カラム)名、無指定の場合はvalueが変数(カラム)名になる
- col_level:meltする変数(カラム)のレベル指定
melt を和訳すると「溶ける」となっています。データセット(データフレーム)のどの変数を残し、どの変数をmeltするのか、という指定をする必要があります。
もう少し説明を加えます。
melt()関数を使うと、対象となるデータフレーム(df)が、次の3つの変数(もしくは、変数グループ)で再構築されます。
- id_vars
- variable
- value
id_varsに指定した変数(カラム)は、melt されずに再構築されたデータフレームにそのまま残ります。
ここからややこしい説明になります。
values_varsに指定した変数(カラム)の「変数(カラム)名」は値として扱われ、variable変数の値になります。var_nameで、variable変数の変数(カラム)名を定義します。
values_varsに指定した変数(カラム)の「値」は、value変数の値になります。value_nameで、value_name変数の変数(カラム)名を定義します。
実際にデータを使って説明していきます。
Wide DataFrame をいきなり melt する
先ず、横持ちのデータフレーム(Wide DataFrame)を作ります。
以下、コードです。
# Pandasライブラリー
import pandas as pd
# データセット構築
data_wide = pd.DataFrame({"Item":["P29287","P01938","P85622","P09871"],
"Category":["cateA","cateB","cateA","cateC"],
"2020-01":[52,48,25,22],
"2020-02":[32,46,35,28],
"2020-03":[10,32,50,41],
"2020-04":[50,72,52,17],
"2020-05":[14,19,20,87],
"2020-06":[30,27,80,16],
"2020-07":[12,19,82,60],
"2020-08":[98,20,30,20],
"2020-09":[27,98,20,61],
"2020-10":[64,71,82,43],
"2020-11":[99,29,40,81],
"2020-12":[71,29,20,67]
})
# データセットの確認
data_wide
以下、実行結果です。

変数は……
- Item:商品コード
- Category:商品カテゴリー
- 2020-1:2020年1月の売上
- 2020-2:2020年2月の売上
- 2020-3:2020年3月の売上
(以後続く)
見た通り、横に長いデータセット(データフレーム)です。
この横に長いデータセット(データフレーム)に対し、いきなり何も考えずにシンプルに melt()関数を使ってみます。
以下、コードです。
data_wide.melt()
以下、実行結果です。
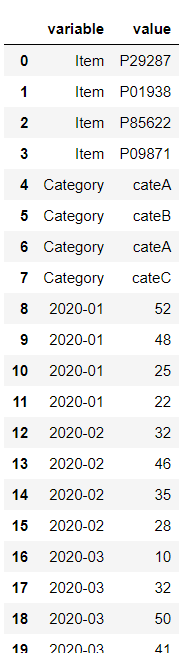
縦持ちのデータフレーム(Long DataFrame)になっています。
簡単に説明します。
id_varsに指定した変数(カラム)はないので、再構築されたデータフレームに残る変数(カラム)はありません。
要するに、変数すべてが melt されます。
var_nameで何も指定していないので、variable変数の変数(カラム)名はデフォルトの「variable」になります。
value_nameで何も指定していないので、value_name変数の変数(カラム)名はデフォルトの「value」になります。
id_vars で残す変数を指定する
横持ちのデータフレーム(Wide DataFrame)を縦持ちの状態にするとき、通常は、変数の一部を変数として残したり、もしくは、特定の変数を melt し縦持ちにしたりします。
例えば、次の2つの変数を残し、残りの「2020-1」「2020-2」…を melt し縦持ちにしてみます。
- Item:商品コード
- Category:商品カテゴリー
以下、コードです。
data_wide.melt(id_vars=["Item","Category"])
以下、実行結果です。
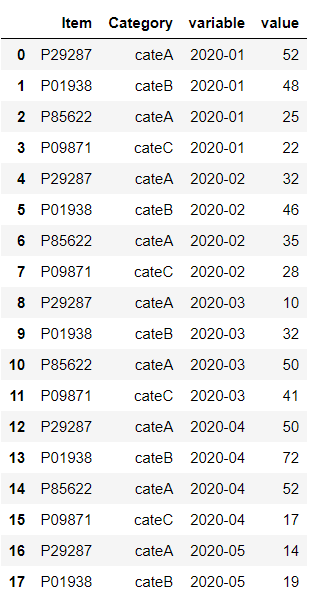
縦持ちのデータフレーム(Long DataFrame)になりました。
いかがでしょうか? 先ほどの縦持ちのデータフレーム(Long DataFrame)よりも、いい感じになっているのではないでしょうか。
id_vars と values_vars を指定する
次に、残す変数(id_vars )と melt し縦持ちにする変数(values_vars)を指定して、melt()関数を実施してみます。
以下、コードです。
data_wide.melt(id_vars=["Item"],
value_vars=["2020-01",
"2020-02",
"2020-03",
"2020-04",
"2020-05",
"2020-06"])
以下、実行結果です。
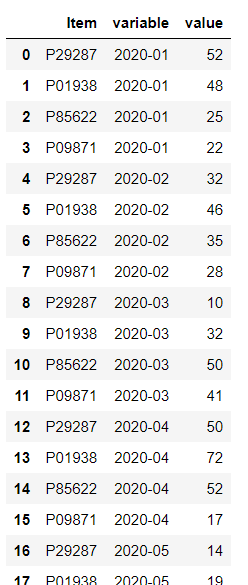
変数(カラム)名を付けてみましょう。
以下、コードです。
data_wide.melt(id_vars=["Item"],
value_vars=["2020-01",
"2020-02",
"2020-03",
"2020-04",
"2020-05",
"2020-06"],
var_name="M",
value_name="Sales")
以下、実行結果です。
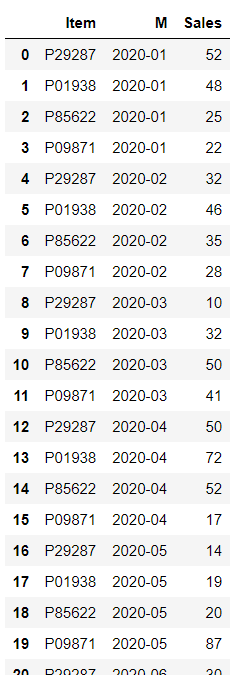
なんとなく、melt()関数の動きが見えてきたのではないでしょうか。
おまけの pivot処理
最後に、縦持ちのデータフレーム(Long DataFrame)を、横持ちのデータフレーム(Wide DataFrame)に再構築してみます。
ここでは、pivot() 関数そのものの説明はいたしません。別の機会にします。ただ、コードと実行結果を見て頂くと、何となく分かるかと思います(たぶん)。
先ず、縦持ちのデータセット(データフレーム)を作ります。先ほど melt()関数で構築したものです。
以下、コードです。
data_long = data_wide.melt(id_vars=["Item","Category"]) data_long
以下、実行結果です。
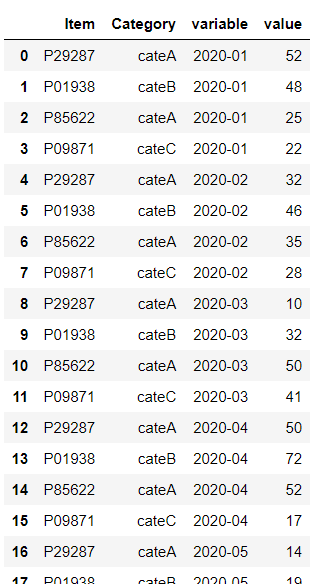
では、元に戻してみます。
以下、コードです。
data_long_pivoted = data_long.pivot(index = ["Item","Category"],
columns='variable',
values='value')
data_long_pivoted
以下、実行結果です。
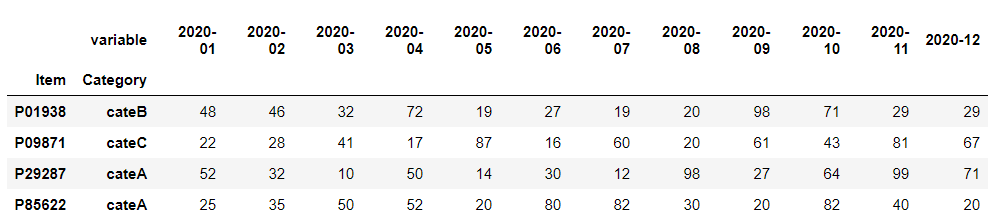
index 部分が気持ち悪い状態になっていますね。ちょっと整えます。
以下、コードです。
data_long_pivoted = data_long_pivoted.reset_index() data_long_pivoted.columns.name = None data_long_pivoted
以下、実行結果です。
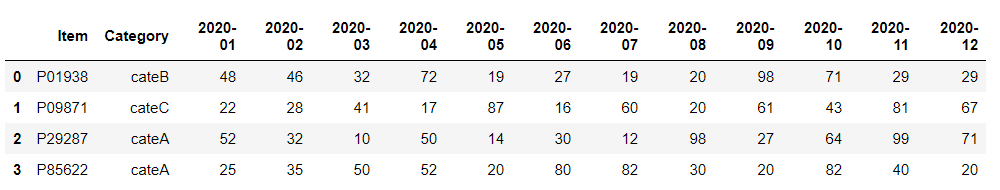
元に戻りました。
まとめ
今回は、「便利だけど分かりにくいデータフレームを再構築するPandasのMelt()関数のお話し」というお話しをしました。
RだろうがPythonだろうが、データフレームを再構築することは少なくないでしょう。
例えば……
- 縦持ち(Long)のデータフレームを、横持ち(Wide)のデータフレームに再構築
- 横持ち(Wide)のデータフレームを、縦持ち(Long)のデータフレームに再構築
pivot() 関数と melt() 関数を使うと、比較的簡単に実施できます。
melt() 関数を使うことで、横持ちのデータフレーム(Wide DataFrame)を、縦持ちのデータフレーム(Long DataFrame)に再構築することができます。
pivot() 関数 を使うことで、縦持ちのデータフレーム(Long DataFrame)を、横持ちのデータフレーム(Wide DataFrame)に再構築することができます。
melt() 関数は pivot() 関数の逆のことをします。pivot() 関数の説明は、別の機会にします。