
時系列データを手にしたとき、どのようなデータなのか外れ値や変化点を眺めるのもいいですが、やっぱり予測をしたくなります。
時系列解析のモデルと聞くと難しそうなイメージがあるますが、正直イメージ通りです。
そのような中、あまり数理的なバックボーンが無くても使えるものとして、Facebookによって開発されたProphetモデルというものがあります。非常に使い勝手がよく、高度な数理的な前提知識なく使えます。
このFacebookのProphetとAR-Net(Auto-Regressive Neural Network for time-series)に触発されて作られたのが、NeuralProphetです。FacebookのProphetと同じぐらい手軽に使えます。違いは、Deep Learningの技術を使っていることです。ユーザは、それほどDeep Learningを意識する必要はありません。
今回は、FacebookのProphetとNeuralProphetを使い簡単な予測モデルの作り方を説明します。
手の込んだ予測モデルにはなっていません。非常に簡単な作り方でモデルを作っています。遊びですので、興味のある方はチャレンジしてみてください。
Contents
- 時系列解析と言えばARIMAモデル
- Facebookによって開発されたProphetモデル
- NeuralProphet ≒ FacebookのProphet × Deep Learning
- NeuralProphetは解釈性を持ち合わせたDeep Learning?
- 必要なライブラリー
- PyStanのインストール
- Prophetのインストール
- PyTorchのインストール
- NeuralProphetのインストール
- 必要なライブラリーの読み込み(ロード)
- データセット
- グラフで確認
- Peyton ManningのWikipediaのPV(ページビュー)数
- Airline Passengers(飛行機乗客数)
- 予測モデルの構築と検証
- Peyton ManningのWikipediaのPV(ページビュー)数
- FacebookのProphetのケース
- NeuralProphetのケース
- Airline Passengers(飛行機乗客数)
- FacebookのProphetのケース
- NeuralProphetのケース
- 今回のまとめ
時系列解析と言えばARIMAモデル
時系列データの数値予測をするとき、ARIMAモデルや状態空間モデルなどの数理統計学の世界の数理モデルを使う人も多いでしょう。
ARIMAモデルは、日本や米国、欧州などの各国で経済指標などで伝統的に活用されている、実務上手堅い数理モデルです。
HyndmanのRのパッケージforecastが有名で、自動でARIMAモデルを構築するAuto-ARIMAという機能が付いています。最近では、PyhtonにもAuto-ARIMAを実施できるパッケージpmdarimaが登場しています。
Facebookによって開発されたProphetモデル
ARIMAモデルで十分と言えば十分なのですが、Facebookによって開発されたProphetモデルも大人気です。RでもPythonでも使えます。
ARIMAモデルはパラメトリックな線形回帰モデルのため非常に解釈性に優れています。
FacebookのProphetモデルは、GAM(一般化加法モデル)をベースにしたノンパラメトリックなモデル、もしくはセミパラメトリックなモデルのため、ARIMAモデルほど解釈性に優れていませんが、アウトプットを見て頂くと分かる通り、解釈性は悪くはありません。
FacebookのProphetモデルの最大の利点は、手軽に時系列の予測モデルを構築することができ、それなりの予測精度を出せる点です。
そこに、最近NeuralProphetというものが登場しました。
NeuralProphet ≒ FacebookのProphet × Deep Learning
NeuralProphetを、一行で記載すると以下のようになります。
NeuralProphet ≒ FacebookのProphet × Deep Learning(AR-Net)
FacebookのProphetモデルはStanを活用していますが、NeuralProphetはPyTorchを活用しています。
ここでは、StanやPyTorchの説明はいたしません。Stanは、簡単に言うとベイズ統計モデリングツールです。PyTorchは、簡単に言うとDeep Learning ライブラリーです。
違いは、StanベースかPyTorchベースか、ということになります。
NeuralProphetは解釈性を持ち合わせたDeep Learning?

NeuralProphetは、Deep Learningの技術を使いながら、FacebookのProphet並みの解釈性を維持したライブラリーです。
使い方は、FacebookのProphetと非常に似ています。
通常、Deep Learningの技術を使った予測モデルは、予測精度は高いが解釈性が低くなる、という欠点を持っています。構築された予測モデルがブラックボックス化するためです。
NeuralProphetは、FacebookのProphetと同程度の解釈性を持ち合わせています。
前置きが長くなりましたが、さっそく2つの数理モデルで構築した予測モデルを比較してみたいと思います。
必要なライブラリー
次のProphetとNeuralProphetのライブラリーを使います。まだインストールされていない方は、以下を参考にインストールして頂ければと思います。
なお、PyStanやPyTorchのインストールも忘れないようにお願いします。
PyStanのインストール
既にインストールされている方は、飛ばしてください。
Windows環境の場合
事前にMicrosoft Visual C++ 再頒布可能パッケージ(Visual Studio 2015、2017、2019、2022)をインストールしておく必要があります。以下のサイトからMicrosoft Visual C++をダウンロードしPCにインストールして頂ければと思います。
Microsoft Visual C++ のダウンロード サイト
https://docs.microsoft.com/ja-jp/cpp/windows/latest-supported-vc-redist
(x86が32ビット版Windows用、x64が64ビット版Windows用)
PyStanのインストールです。
pipでインストールする場合は以下です。
pip install pystan==2.19.1.1
Prophetのインストール
PyStanがインストールされている方は、Prophetのインストールをします。
conda install -c conda-forge prophet
もし上手くいかな場合には、condaをアップデートしてから際チャレンジして頂ければと思います。
# condaのアップデート conda update conda
それでも上手くいかない場合には、pipでインストールしてみてください。
pip install prophet
PyTorchのインストール
PyTorchのインストールです。既にインストールされている方は、飛ばしてください。
# PyTorchのインストール conda install pytorch torchvision -c pytorch
もし上手くいかない場合には、公式のホームページ(https://pytorch.org/)で、インストールするPCなどの環境を設定すると、適切なコードを教えてくれます。そのコードをコピペして利用します。
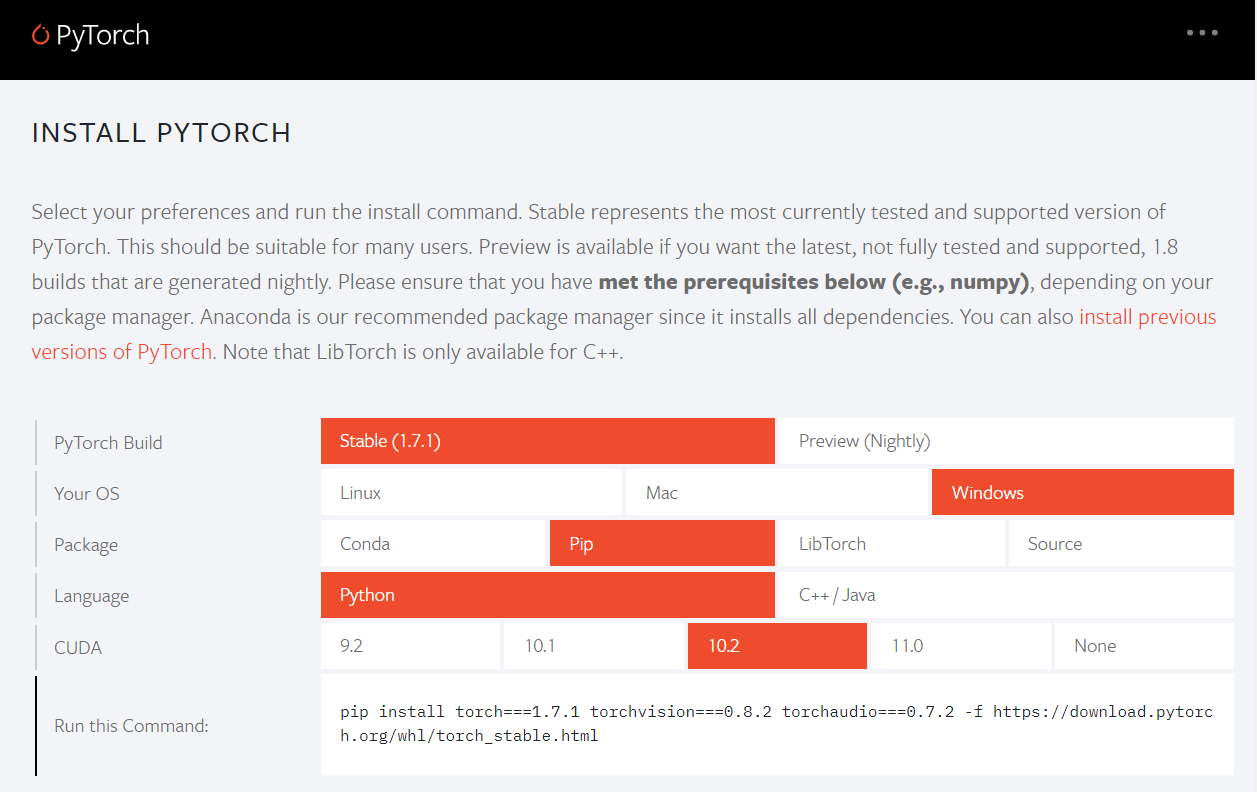
私の場合(2021.1.23現在、Windows)は、以下のような感じです(pipの場合)。
pip install torch===1.7.1 torchvision===0.8.2 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
condaでインストールできない場合に、pipでインストールしてください。
NeuralProphetのインストール
NeuralProphetのインストールをします。
# NeuralProphetのインストール pip install neuralprophet
必要なライブラリーの読み込み(ロード)
データセットの読み込みや処理などに「pandas」を、グラフの描写には「matplotlib」を使います。どちらもPyhtonでよく使うライブラリーですので、インストールされていない方はインストールしておくことをお勧めします。この2つのライブラリーがインストールされているものとして話しを進めます。
では、必要なライブラリーの読み込みます。
以下、コードです。
# ライブラリーの読み込み import pandas as pd #基本ライブラリー from prophet import Prophet #Prophet from neuralprophet import NeuralProphet #NeuralProphet from sklearn.metrics import mean_absolute_error #評価指標MAE from statistics import mean #平均値の計算 import matplotlib.pyplot as plt #グラフ描写
ついでに、グラフのスタイルを次のように「ggplot」に設定します。この処理は必須ではありません。別のスタイルでも問題ございません。好みです。
# グラフのスタイル
plt.style.use('ggplot')
# グラフサイズ設定
plt.rcParams['figure.figsize'] = [12, 9]
データセット
今回は、2種類の時系列データ(データセット)で試します。
- Peyton ManningのWikipediaのPV(ページビュー)数 ※日単位の時系列データ
- Airline Passengers(飛行機乗客数) ※月単位の時系列データ
Peyton ManningのWikipediaのPV(ページビュー)は、Prophetで提供されているサンプルデータ(example_wp_log_peyton_manning.csv)の1つです。facebook/prophetのGitHubからダウンロードして使って頂くか、弊社のHPからダウンロードして使って頂ければと思います。
facebook/prophetのGitHub上のデータ
https://github.com/facebook/prophet/blob/master/examples/example_wp_log_peyton_manning.csv弊社のHP上のURLからダウンロード
https://www.salesanalytics.co.jp/bgr8
Airline Passengers(飛行機乗客数)は、Box and Jenkins (1976) の有名な時系列データです。サンプルデータとして、よく利用されます。
弊社のHPからもダウンロードできます。
弊社のHP上のURLからダウンロード
https://www.salesanalytics.co.jp/591h
弊社のHP上のURLから、直接CSVファイルのデータセットを読み込む場合、以下のようなコードになります。
# Peyton ManningのWikipediaのPVのデータセット読み込み url = 'https://www.salesanalytics.co.jp/bgr8' df1 = pd.read_csv(url) # Airline Passengers(飛行機乗客数)のデータセット読み込み url = 'https://www.salesanalytics.co.jp/591h' df2 = pd.read_csv(url) df2.columns = ['ds', 'y']
グラフで確認
読み込んだデータセットをグラフなどで眺めてみたいと思います。
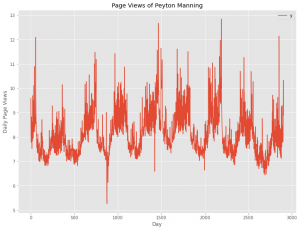
Peyton ManningのWikipediaのPV(ページビュー)数
先ず、どのようなデータなのか確認します。
以下、コードです。
# Peyton ManningのWikipediaのPVのデータセットの内容 df1.info() #データセット情報 df1.head() #上位10個のデータ
以下、実行結果です。
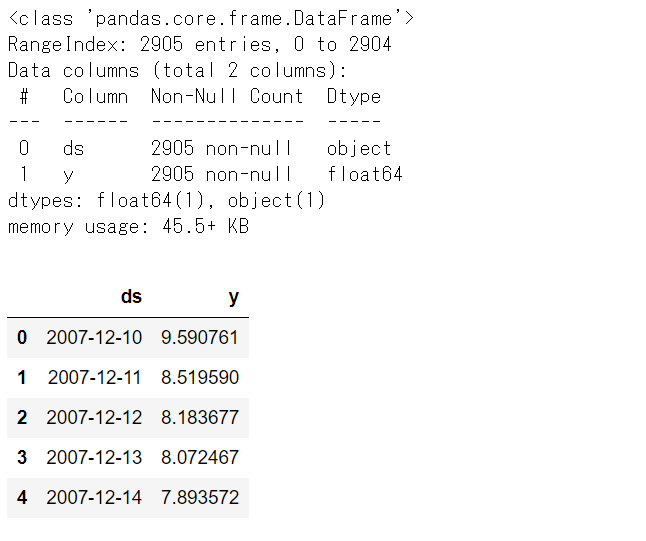
データのレコード数は2905、dsは日付、yはPV数になります。
では、折れ線グラフを描写してみます。
以下、コードです。
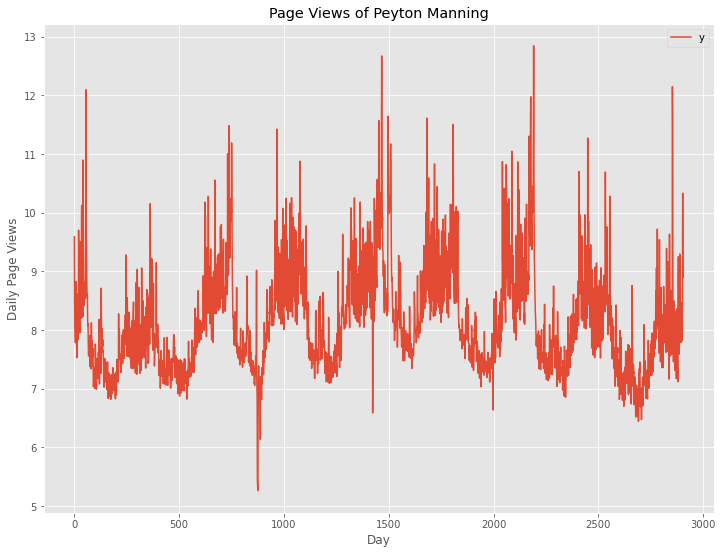
# Peyton ManningのWikipediaのPVのプロット
df1.plot()
plt.title('Page Views of Peyton Manning') #グラフタイトル
plt.ylabel('Daily Page Views') #タテ軸のラベル
plt.xlabel('Day') #ヨコ軸のラベル
plt.show()
以下、実行結果です。
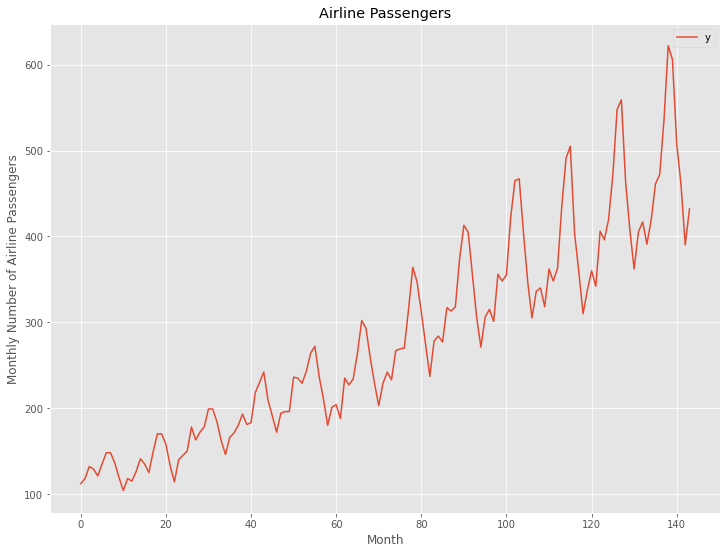
Airline Passengers(飛行機乗客数)
先ず、どのようなデータなのか確認します。
以下、コードです。
# Airline Passengers(飛行機乗客数)のPVのデータセットの内容 df2.info() #データセット情報 df2.head() #上位10個のデータ
以下、実行結果です。
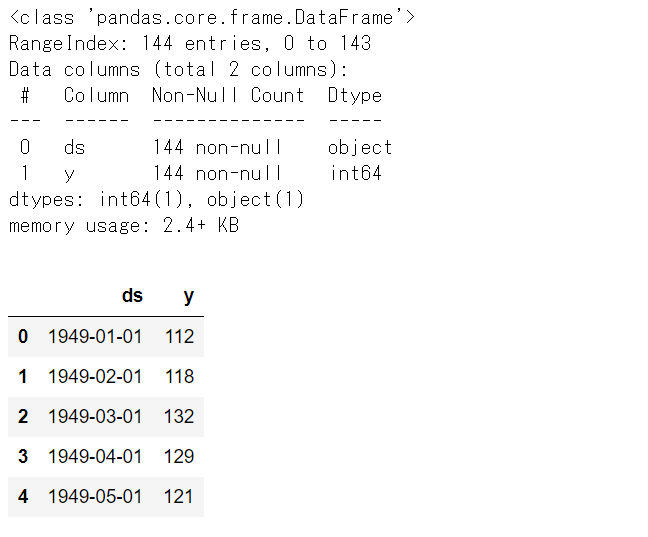
データのレコード数は144、dsは日付(月単位)、yは乗客数になります。
では、折れ線グラフを描写してみます。
以下、コードです。
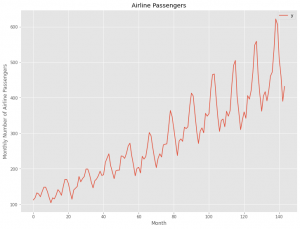
# Airline Passengers(飛行機乗客数)のプロット
df2.plot()
plt.title('Airline Passengers') #グラフタイトル
plt.ylabel('Monthly Number of Airline Passengers') #タテ軸のラベル
plt.xlabel('Month') #ヨコ軸のラベル
plt.show()
以下、実行結果です。
データセットごとに、FacebookのProphetとNeuralProphetのそれぞれで予測モデルを構築し精度検証していきます。
予測モデルの構築と検証
Peyton ManningのWikipediaのPV(ページビュー)数
予測モデルを構築する学習データと、構築した予測モデルを検証するためのテストデータに分割します。
時系列データですので、ある時期を境に2つのデータに分割します。
今回は、新しい365日(1年間)のデータをテストデータとし、その前のデータを学習データとします。
- 学習データ:1行目から2540行目(行のインデックスでは 0 ~ 2539)
- テストデータ:2541行目から2905行目(行のインデックスでは 2540~ 2904)
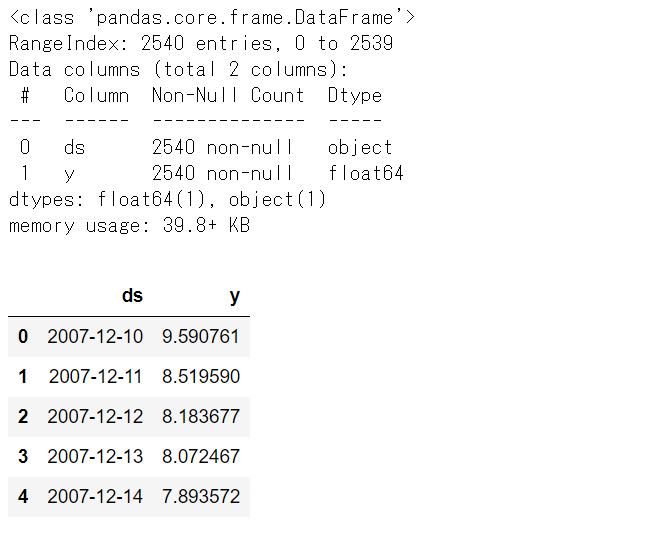
では、データを分割します。以下、コードです。
# Peyton ManningのWikipediaのPV # 学習データとテストデータの分割 test_length = 365 df1_train = df1.iloc[:-test_length] df1_test = df1.iloc[-test_length:]
学習データを確認してみます。
以下、コードです。
# Peyton ManningのWikipediaのPV # 学習データの内容 df1_train.info() #データセット情報 df1_train.head() #上位10個のデータ
以下、実行結果です。
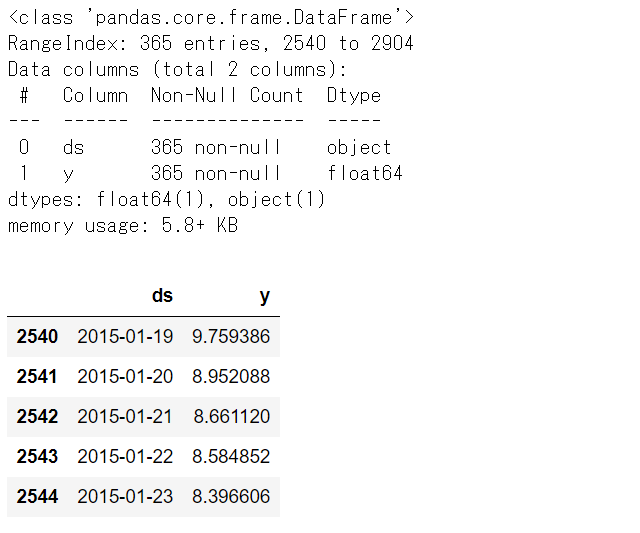
テストデータを確認してみます。
以下、コードです。
# Peyton ManningのWikipediaのPV # テストデータの内容 df1_test.info() #データセット情報 df1_test.head() #上位10個のデータ
以下、実行結果です。
FacebookのProphetとNeuralProphetのそれぞれで、学習データで予測モデルを構築し、テストデータで精度検証していきます。
精度検証で利用する指標は、平均絶対誤差(MAE、Mean Absolute Error)と平均絶対パーセント誤差(MAPE、Mean absolute percentage error)です。
以下の記号を使い精度指標の説明をします。
- y_i^{obs} ・・・i番目の実測値
- y_i^{pred} ・・・i番目の予測値
- \overline{y^{obs}} ・・・実測値の平均
- n ・・・実測値・予測値の数
■ 平均絶対誤差(MAE、Mean Absolute Error)
\frac{1}{n}\sum_{i=1}^n|y_i^{obs}-{y_i^{pred}}|■ 平均絶対パーセント誤差(MAPE、Mean absolute percentage error)
\frac{1}{n}\sum_{i=1}^n|\frac{y_i^{obs}-{y_i^{pred}}}{y_i^{obs}}|FacebookのProphetのケース
先ず学習データを使い、Prophet で予測モデルを構築します。
以下、コードです。
# Peyton ManningのWikipediaのPV # Prophet 予測モデル構築 df1_prophet_model = Prophet(seasonality_mode='multiplicative') df1_prophet_model.fit(df1_train)
これだけです。
予測モデルが構築できたら、次に予測モデルの精度検証用データを生成します。端的に言うと、モデルを使って予測をするということです。
以下、コードです。
# Peyton ManningのWikipediaのPV # Prophet 予測モデルの精度検証用データの生成 df1_future = df1_prophet_model.make_future_dataframe(periods=test_length, freq='D') df1_pred = df1_prophet_model.predict(df1_future)
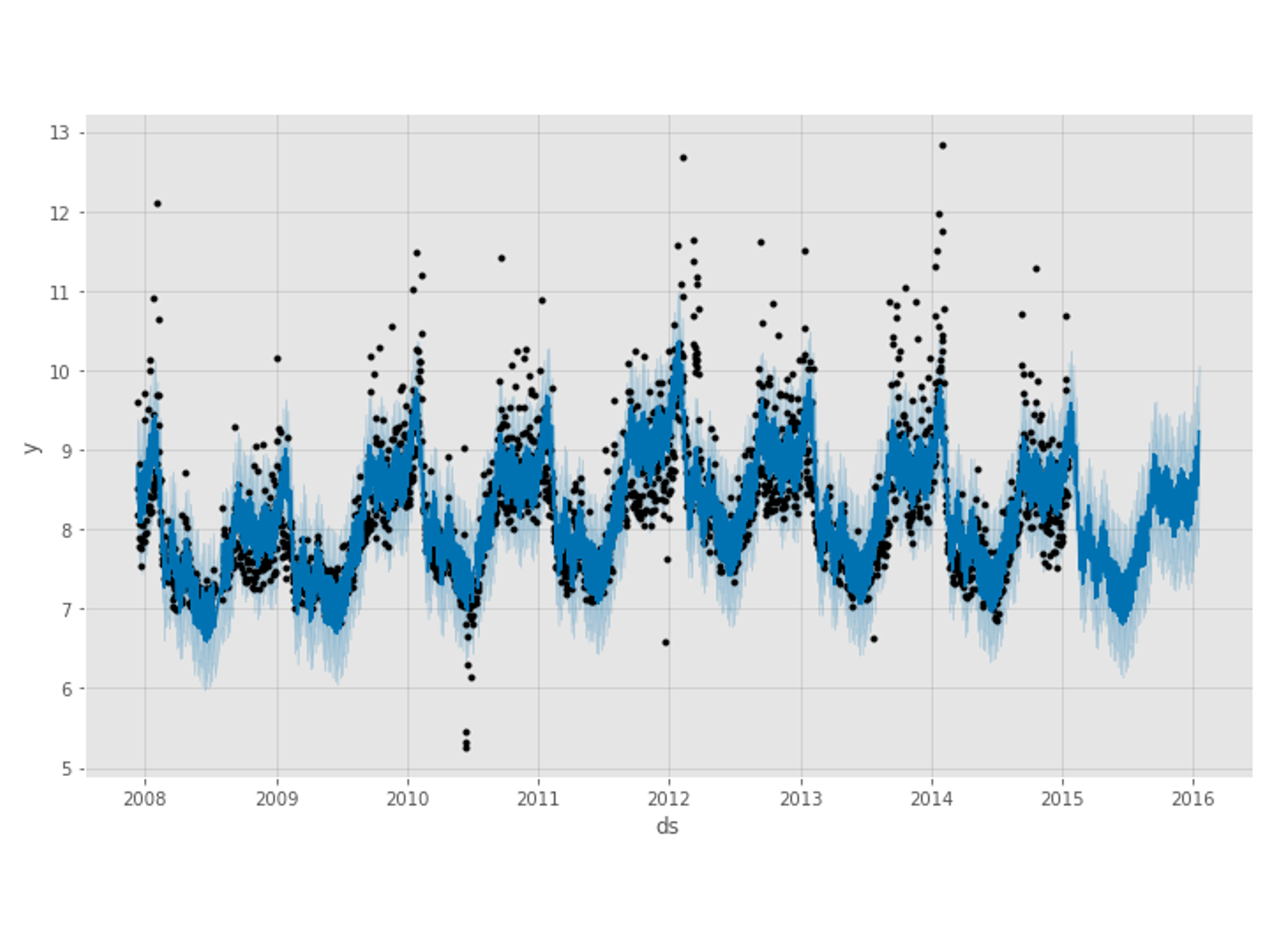
予測結果(学習データ期間+テストデータ期間)をグラフ化し見てみます。
以下、コードです。
# Peyton ManningのWikipediaのPV # Prophet 予測モデルの予測結果(学習データ期間+テストデータ期間) df1_pred_plot = df1_prophet_model.plot(df1_pred) #予想値(点は学習データの実測値) df1_pmpc = df1_prophet_model.plot_components(df1_pred) #モデルの要素分解
以下、実行結果です。
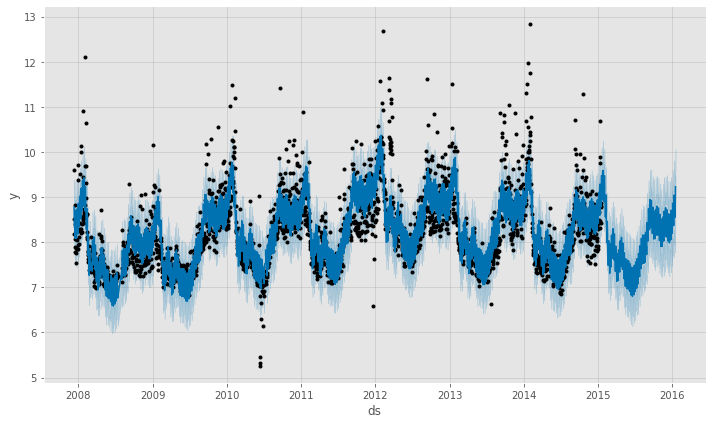
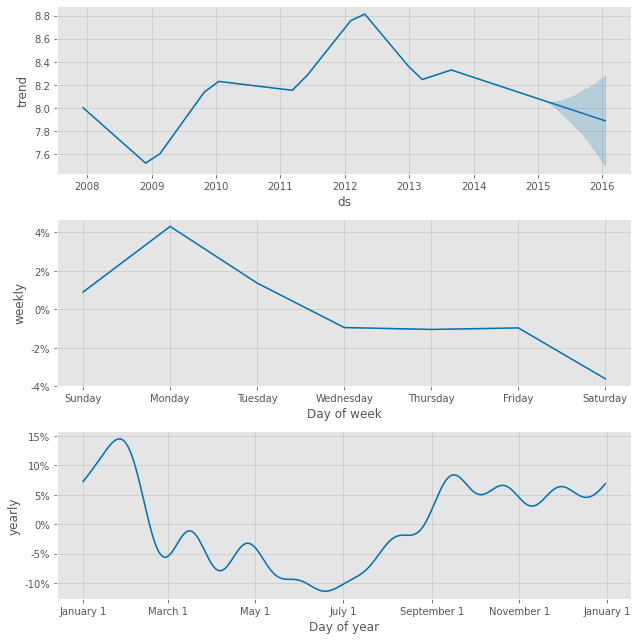
テストデータに予測結果を結合し、精度評価したいと思います。
以下、コードです。
# Peyton ManningのWikipediaのPV # テストデータに予測値を結合 df1_test['Prophet Predict'] = df1_pred.iloc[-test_length:].loc[:, 'yhat']
結合したデータを見てみます。
以下、コードです。
df1_test.head()
以下、実行結果です。

MAEおよびMAPE(%)を出力し、そして実測値と予測値をグラフ化し視覚的に確認します。
# Peyton ManningのWikipediaのPV
# Prophet 予測モデルの精度検証(テストデータ期間)
print('MAE:')
print(mean_absolute_error(df1_test['y'], df1_test['Prophet Predict']))
print('MAPE:')
print(mean(abs(df1_test['y'] - df1_test['Prophet Predict'])/df1_test['y']) *100)
df1_test.plot(title='Forecast evaluation',ylim=[0,15])
以下、実行結果です。

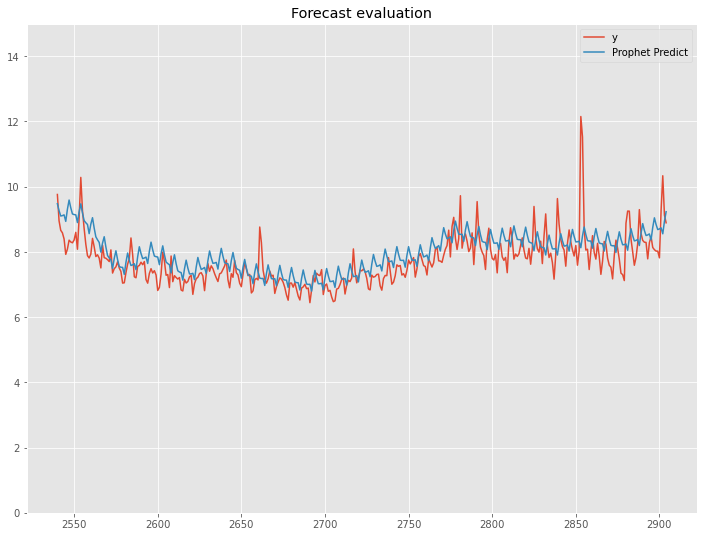
NeuralProphetのケース
先ず学習データを使い、NeuralProphetで予測モデルを構築します。
以下、コードです。
# Peyton ManningのWikipediaのPV # NeuralProphet 予測モデル構築 df1_nprophet_model = NeuralProphet(seasonality_mode='multiplicative') df1_nprophet_model_result = df1_nprophet_model.fit(df1_train, freq="D")
これだけです。
予測モデルが構築できたら、次に予測モデルの精度検証用データを生成します。端的に言うと、モデルを使って予測をするということです。
以下、コードです。
# Peyton ManningのWikipediaのPV
# NeuralProphet 予測モデルの精度検証用データの生成
df1_future = df1_nprophet_model.make_future_dataframe(df1_train,
periods = test_length,
n_historic_predictions=len(df1_train))
df1_pred = df1_nprophet_model.predict(df1_future)
予測結果(学習データ期間+テストデータ期間)をグラフ化し見てみます。
以下、コードです。
# Peyton ManningのWikipediaのPV # NeuralProphet 予測モデルの予測結果(学習データ期間+テストデータ期間) df1_pred_plot = df1_nprophet_model.plot(df1_pred) #予想値(点は学習データの実測値) df1_pmpc = df1_nprophet_model.plot_components(df1_pred) #モデルの要素分解
以下、実行結果です。
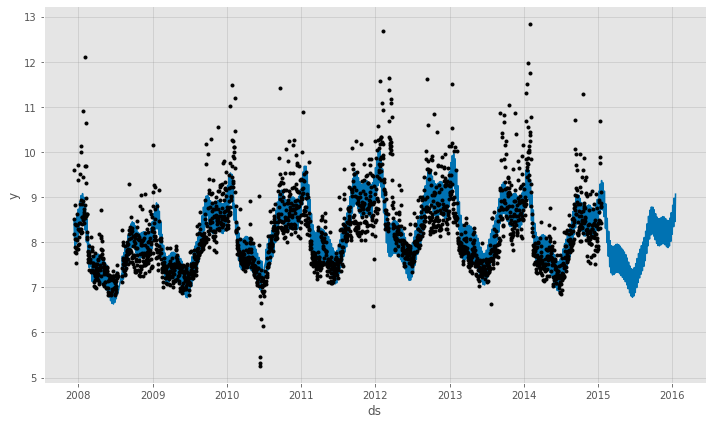
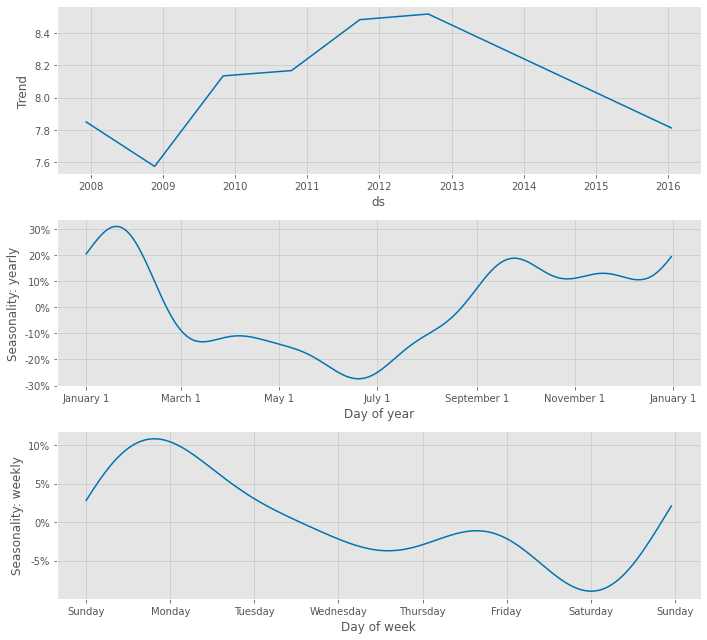
テストデータに予測結果を結合し、精度評価したいと思います。
以下、コードです。
# Peyton ManningのWikipediaのPV # テストデータに予測値を結合 df1_test['NeuralProphet Predict'] = df1_pred.iloc[-test_length:].loc[:, 'yhat1']
結合したデータを見てみます。
以下、コードです。
df1_test.head()
以下、実行結果です。
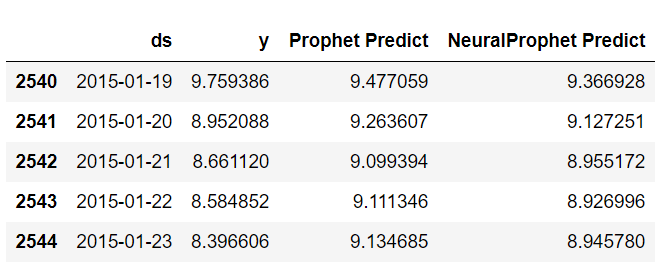
MAEおよびMAPE(%)を出力し、そして実測値と予測値をグラフ化し視覚的に確認します。
# Peyton ManningのWikipediaのPV
# NeuralProphet 予測モデルの精度検証(テストデータ期間)
print('MAE(Prophet):')
print(mean_absolute_error(df1_test['y'], df1_test['Prophet Predict']))
print('MAE(NeuralProphet):')
print(mean_absolute_error(df1_test['y'], df1_test['NeuralProphet Predict']))
print('----------------------------')
print('MAPE(Prophet):')
print(mean(abs(df1_test['y'] - df1_test['Prophet Predict'])/df1_test['y']) *100)
print('MAPE(NeuralProphet):')
print(mean(abs(df1_test['y'] - df1_test['NeuralProphet Predict'])/df1_test['y']) *100)
df1_test.plot(title='Forecast evaluation',ylim=[0,15])
以下、実行結果です。

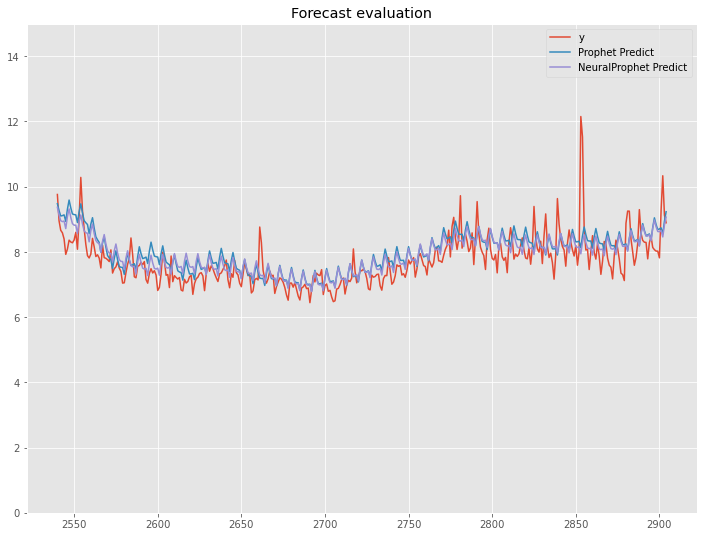
Airline Passengers(飛行機乗客数)
予測モデルを構築する学習データと、構築した予測モデルを検証するためのテストデータに分割します。
時系列データですので、ある時期を境に2つのデータに分割します。
今回は、新しい12カ月(1年間)のデータをテストデータとし、その前のデータを学習データとします。
- 学習データ:1行目から132行目(行のインデックスでは 0 ~ 131)
- テストデータ:133行目から144行目(行のインデックスでは 132~ 143)
では、データを分割します。以下、コードです。
# Airline Passengers(飛行機乗客数) # 学習データとテストデータの分割 test_length = 12 df2_train = df2.iloc[:-test_length] df2_test = df2.iloc[-test_length:]
学習データを確認してみます。
以下、コードです。
# Airline Passengers(飛行機乗客数) # 学習データの内容 df2_train.info() #データセット情報 df2_train.head() #上位10個のデータ
以下、実行結果です。
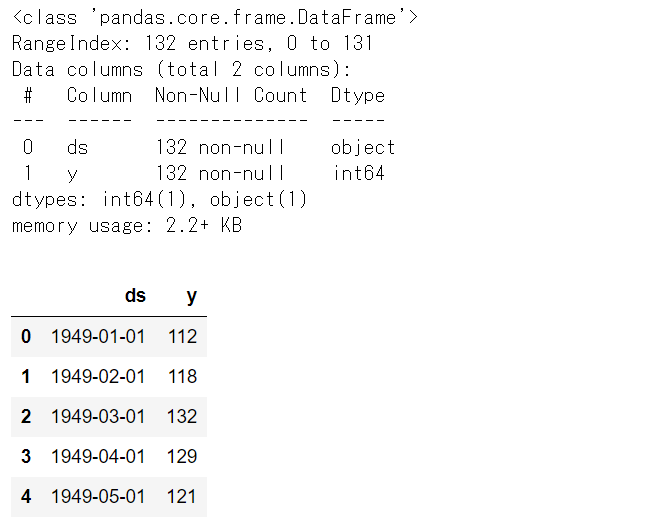
テストデータを確認してみます。
以下、コードです。
# Airline Passengers(飛行機乗客数) # テストデータの内容 df2_test.info() #データセット情報 df2_test.head() #上位10個のデータ
以下、実行結果です。
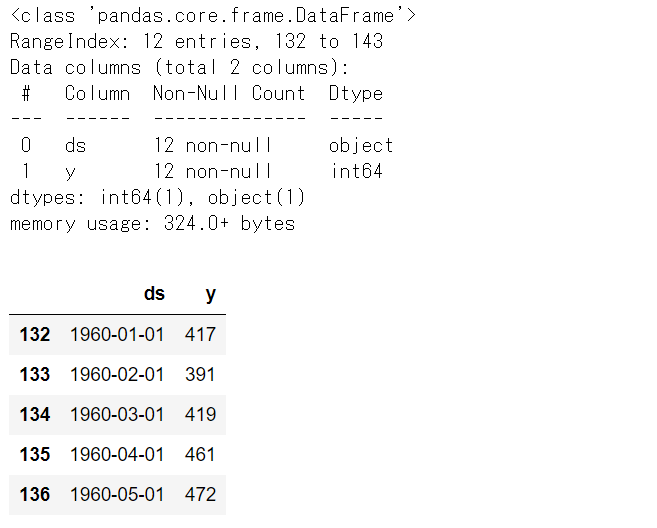
FacebookのProphetとNeuralProphetのそれぞれで、学習データで予測モデルを構築し、テストデータで精度検証していきます。
FacebookのProphetのケース
先ず学習データを使い、Prophet で予測モデルを構築します。
以下、コードです。
# Airline Passengers(飛行機乗客数) # Prophet 予測モデル構築 df2_prophet_model = Prophet(seasonality_mode='multiplicative') df2_prophet_model.fit(df2_train)
予測モデルが構築できたら、次に予測モデルの精度検証用データを生成します。端的に言うと、モデルを使って予測をするということです。
以下、コードです。
# Airline Passengers(飛行機乗客数) # Prophet 予測モデルの精度検証用データの生成 df2_future = df2_prophet_model.make_future_dataframe(periods=test_length, freq='M') df2_pred = df2_prophet_model.predict(df2_future)
予測結果(学習データ期間+テストデータ期間)をグラフ化し見てみます。
以下、コードです。
# Airline Passengers(飛行機乗客数) # Prophet 予測モデルの予測結果(学習データ期間+テストデータ期間) df2_pred_plot = df2_prophet_model.plot(df2_pred) #予想値(点は学習データの実測値) df2_pmpc = df2_prophet_model.plot_components(df2_pred) #モデルの要素分解
以下、実行結果です。
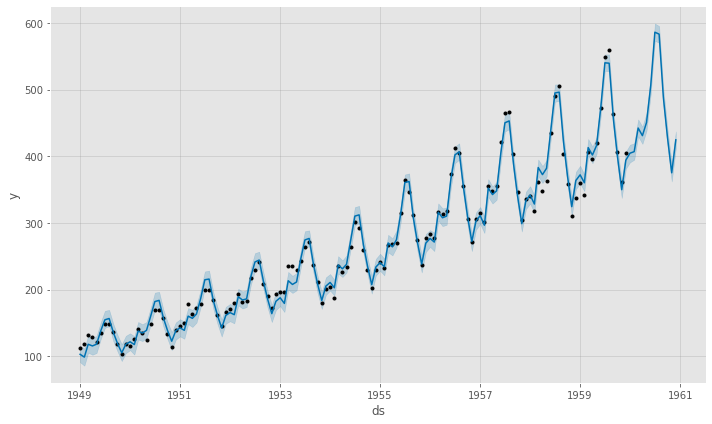
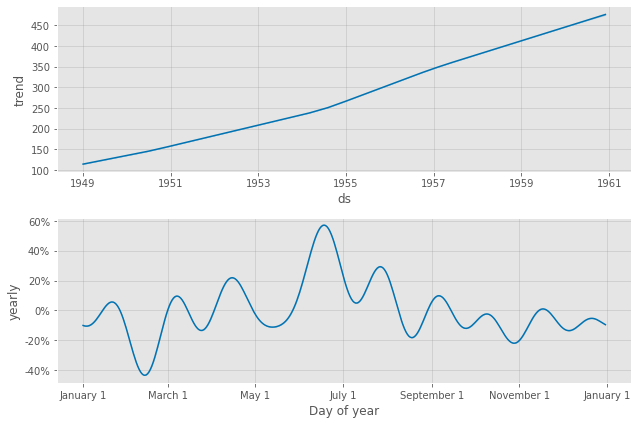
テストデータに予測結果を結合し、精度評価したいと思います。
以下、コードです。
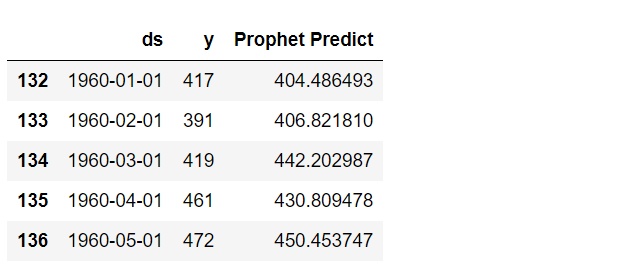
# Airline Passengers(飛行機乗客数) # テストデータに予測値を結合 df2_test['Prophet Predict'] = df2_pred.iloc[-test_length:].loc[:, 'yhat']
結合したデータを見てみます。
以下、コードです。
df2_test.head()
以下、実行結果です。
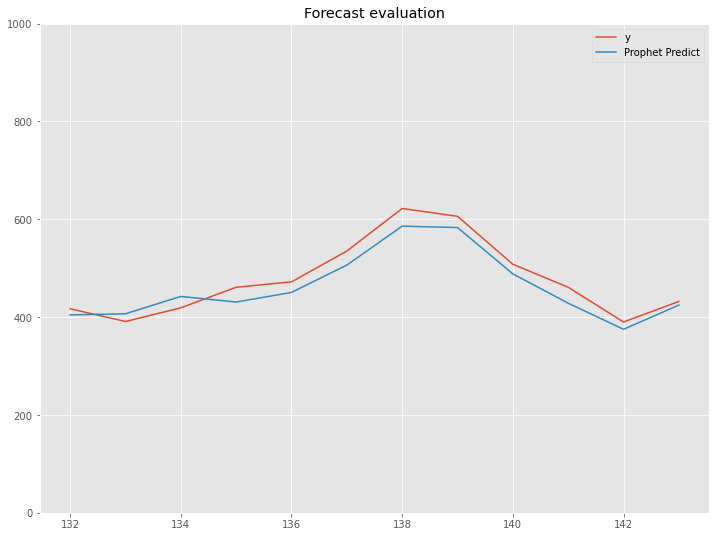
MAEおよびMAPE(%)を出力し、そして実測値と予測値をグラフ化し視覚的に確認します。
# Airline Passengers(飛行機乗客数)
# Prophet 予測モデルの精度検証(テストデータ期間)
print('MAE:')
print(mean_absolute_error(df2_test['y'], df2_test['Prophet Predict']))
print('MAPE:')
print(mean(abs(df2_test['y'] - df2_test['Prophet Predict'])/df2_test['y']) *100)
df2_test.plot(title='Forecast evaluation',ylim=[0,1000])
以下、実行結果です。

NeuralProphetのケース
先ず学習データを使い、NeuralProphetで予測モデルを構築します。
以下、コードです。
# Airline Passengers(飛行機乗客数) # NeuralProphet 予測モデル構築 df2_nprophet_model = NeuralProphet(seasonality_mode='multiplicative') df2_nprophet_model_result = df2_nprophet_model.fit(df2_train, freq="M")
予測モデルが構築できたら、次に予測モデルの精度検証用データを生成します。端的に言うと、モデルを使って予測をするということです。
以下、コードです。
# Airline Passengers(飛行機乗客数)
# NeuralProphet 予測モデルの精度検証用データの生成
df2_future = df2_nprophet_model.make_future_dataframe(df2_train,
periods = test_length,
n_historic_predictions=len(df2_train))
df2_pred = df2_nprophet_model.predict(df2_future)
予測結果(学習データ期間+テストデータ期間)をグラフ化し見てみます。
以下、コードです。
# Airline Passengers(飛行機乗客数) # NeuralProphet 予測モデルの予測結果(学習データ期間+テストデータ期間) df2_pred_plot = df2_nprophet_model.plot(df2_pred) #予想値(点は学習データの実測値) df2_pmpc = df2_nprophet_model.plot_components(df2_pred) #モデルの要素分解
以下、実行結果です。
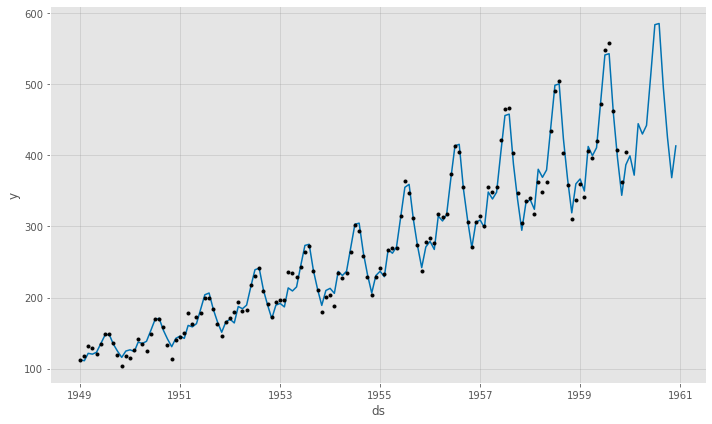
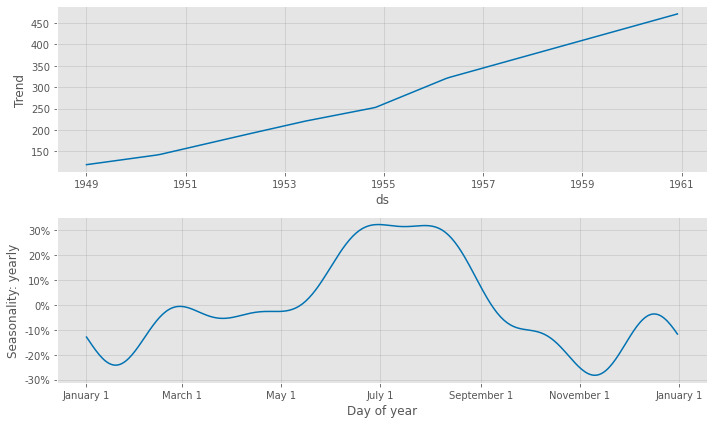
テストデータに予測結果を結合し、精度評価したいと思います。
以下、コードです。
# Airline Passengers(飛行機乗客数) # テストデータに予測値を結合 df2_test['NeuralProphet Predict'] = df2_pred.iloc[-test_length:].loc[:, 'yhat1']
結合したデータを見てみます。
以下、コードです。
df2_test.head()
以下、実行結果です。
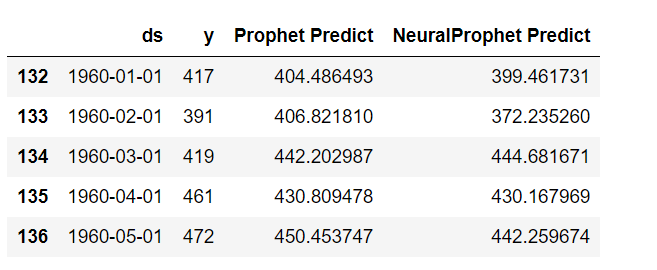
MAEおよびMAPE(%)を出力し、そして実測値と予測値をグラフ化し視覚的に確認します。
# Airline Passengers(飛行機乗客数)
# NeuralProphet 予測モデルの精度検証(テストデータ期間)
print('MAE(Prophet):')
print(mean_absolute_error(df2_test['y'], df2_test['Prophet Predict']))
print('MAE(NeuralProphet):')
print(mean_absolute_error(df2_test['y'], df2_test['NeuralProphet Predict']))
print('----------------------------')
print('MAPE(Prophet):')
print(mean(abs(df2_test['y'] - df2_test['Prophet Predict'])/df2_test['y']) *100)
print('MAPE(NeuralProphet):')
print(mean(abs(df2_test['y'] - df2_test['NeuralProphet Predict'])/df2_test['y']) *100)
df2_test.plot(title='Forecast evaluation',ylim=[0,1000])
以下、実行結果です。

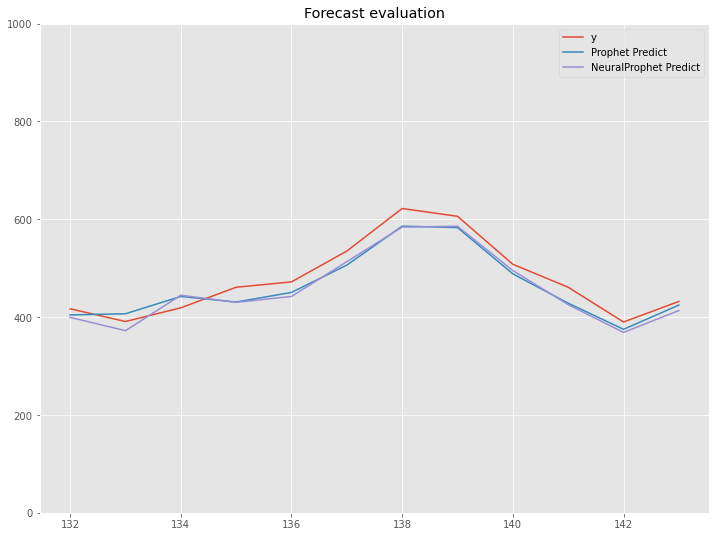
今回のまとめ
今回は、FacebookのProphetとNeuralProphetを使い簡単な予測モデルの作り方を説明しました。
正直、計算時間の割に精度の劇的改善が望めるようなモデルではないようにも見えますが…… 、こういうのもあるよというお話しでした。
ディープラーニングというか、ニューラルネット系の時系列モデルは他にもあります。また、そもそもARIMAなどのオーソドックスな時系列モデルはどうなんだ??? というお話しもあります。モデル構築のアルゴリズムの違いを言及しつつ、別の機会に触れたいと思います。