

全国50店舗を展開するカジュアルアパレルブランド「STYLENOA」(仮名)のMD(マーチャンダイジング)部門では、半年後の春夏シーズンに向けて、主力商品であるベーシックTシャツの生産数量を決めなければなりません。
これまでの計画手法は「昨対比 + 営業の肌感覚」で、近年いくつかの問題が表面化していました。
- 昨年は猛暑でTシャツが7月に売り切れ、機会損失が発生
- 反動で大量発注したポロシャツは秋にセール処分で粗利が毀損
- 全社売上は緩やかに成長しており、「昨対比」の基準そのものが揺らいでいる
過去3年分の日次POSデータを使い、「3か月先までの需要を、不確実性も込みで予測する」ことになりました。
前編は、まずデータそのものの構造を理解することに集中します。
具体的には次の問いに答えていきます。
- 売上データにはどのような周期性・トレンドが含まれているのか
- それを発見するために、どんな視点(集計粒度)でデータを見ればよいのか
- 「昨対比」や「移動平均」のような素朴な予測はどこまで通用するのか
次回の後編では、これらの土台の上にProphetという確率的予測モデルを導入し、さらに「機会損失と売れ残りコストを踏まえた最適な発注量」まで踏み込みます。
Contents
データセットの準備
前編である本記事では、カジュアルアパレルブランド「STYLENOA」(仮名)全国50店舗の主力商品「ベーシックTシャツ」の日次販売データを使用します。
下記のCSVファイルをダウンロードして、コードを実行する作業ディレクトリに配置してください。
以下、データセットの内容です。
- 期間:2023-01-01 〜 2025-12-31(3年間、1,096日分)
- 単位:全50店舗合算の日次販売点数
- 変数構成:全6変数
| 変数名 | 説明 |
|---|---|
日付(date) |
販売日 |
販売点数(sales) |
50店舗合算の日次販売点数(整数) |
曜日(weekday) |
Mon/Tue/Wed/Thu/Fri/Sat/Sun |
月(month) |
1〜12 |
祝日フラグ(is_holiday) |
祝日期間なら1、それ以外は0 |
祝日名(holiday_name) |
このデータセットは学習用に、実データから変数を減らしたり、値を変えるなど一部改変し作成したものです。
ただし、実際のアパレル販売データに見られる典型的な構造(季節性・トレンド・祝日効果など)を、できるだけ再現しています。
ステップ1:ライブラリの準備
今回使用するライブラリをまとめてインポートします。
pandasとnumpyは定番、matplotlibとjapanize_matplotlibはグラフ描画用、statsmodelsは時系列分解で使います。まだ、インストールしてものが無い場合、pipなどでインストール(例:pip install japanize_matplotlib)しておいてください。
以下、コードです。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import japanize_matplotlib from statsmodels.tsa.seasonal import seasonal_decompose plt.rcParams['figure.figsize'] = [12, 5] plt.rcParams['axes.grid'] = True
エラーなく実行できれば準備完了です。
japanize_matplotlibはインポートするだけで日本語フォントが自動設定されるので、これ以降のグラフで日本語ラベルが文字化けしません。
ステップ2:データの読み込みと確認
過去3年分(2023-01-01 〜 2025-12-31)のベーシックTシャツ日次販売データ(apparel_sales.csv)を読み込みます。日付(date)列はあらかじめdatetime型となるようにします。
以下、コードです。
df = pd.read_csv(
'apparel_sales.csv',
encoding='utf-8-sig',
parse_dates=['date']
)
print(f'データ形状: {df.shape}')
print(f'期間: {df["date"].min().date()} 〜 {df["date"].max().date()}')
print()
print('最初の5日分:')
print(df.head())
以下、実行結果です。
データ形状: (1096, 6)
期間: 2023-01-01 〜 2025-12-31
最初の5日分:
date sales weekday month is_holiday holiday_name
0 2023-01-01 215 Sun 1 1 NewYear
1 2023-01-02 142 Mon 1 1 NewYear
2 2023-01-03 150 Tue 1 1 NewYear
3 2023-01-04 139 Wed 1 0 NaN
4 2023-01-05 114 Thu 1 0 NaN
3年間(1,096日分)のデータが、6変数で構成されていることが確認できました。
販売点数(sales)の基本統計量も確認しておきましょう。
以下、コードです。
print(df['sales'].describe().round(1))
以下、実行結果です。
count 1096.0 mean 376.8 std 198.4 min 83.0 25% 209.0 50% 349.0 75% 504.2 max 1184.0 Name: sales, dtype: float64
平均(mean)は約377点/日、最小(min)83点、最大(まx)1,184点と、最大値は最小値の14倍以上にもなります。
標準偏差(std)も平均の半分を超えており、日によるばらつきがかなり大きいことが分かります。
このばらつきの正体を明らかにするのが、これから先のステップです。
ステップ3:まずは折れ線グラフで全体を眺める
時系列データのEDA(探索的データ分析)の鉄則は、「まず全期間を1枚の折れ線グラフにしてみる」ことです。
何の変哲もない作業ですが、ここから多くのヒントが得られます。
以下、コードです。
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(
df['date'],
df['sales'],
color='skyblue'
)
ax.set_title(
'ベーシックTシャツ 日次販売点数(2023-2025)',
fontsize=14
)
ax.set_xlabel('日付', fontsize=12)
ax.set_ylabel('販売点数', fontsize=12)
plt.tight_layout()
plt.show()
以下、実行結果です。
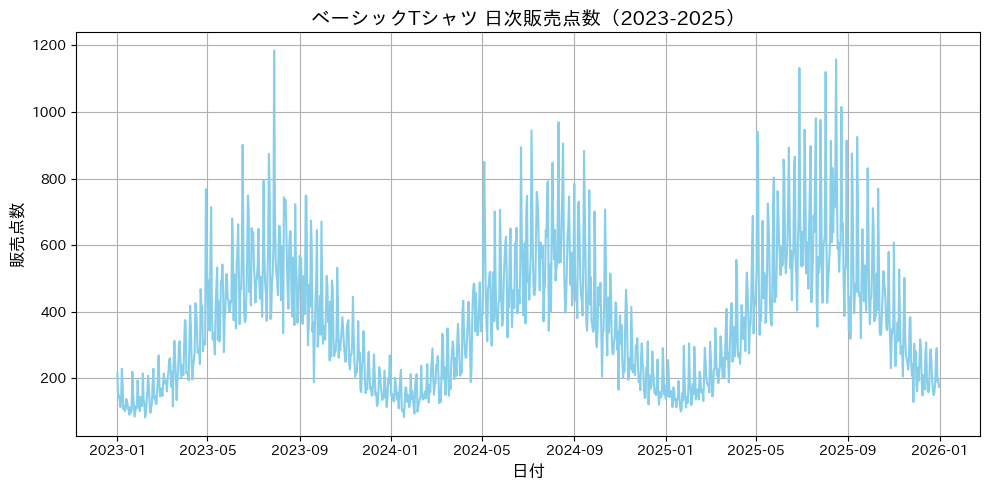
グラフを眺めると、以下のような特徴がすぐに見えてきます。
- 波打つような上下動:1年単位で大きな山と谷が繰り返されている。山は夏、谷は冬で、これは明らかに年間の季節性です。
- 山の高さが年々少しづつ上がっている:2023年の山より2024年の山、さらに2025年の山が少しづつ高くなっています。これは長期トレンド(成長)の存在を示唆します。
- 細かいギザギザ:日々のスケールでデータが激しく上下しています。週次の周期性なのか、ただのノイズなのか、この粒度では判別できません。
つまり、生データを見ただけでも「何かしらの周期があり、しかも長期トレンドも乗っている」という大きな構造が見えてきます。
次のステップでは、これらを集計粒度を変えながらよりはっきりと取り出していきます。
ステップ4:集計粒度を変えると、見える情報が変わる
データを分析する上での最も重要なアプローチの一つに、「同じデータを別の軸で集計することで、別の真実をあぶりだす」というものがあります。
ここでは月次/曜日別の2つの粒度で集計し、それぞれ違う情報を取り出してみます。
月次集計:年間の季節性を捉える
月(month)ごとに販売点数(sales)の平均を計算します。
以下、コードです。
monthly_mean = (
df.groupby('month')
['sales']
.mean()
.round(1)
)
print(monthly_mean)
以下、実行結果です。
month 1 144.3 2 169.7 3 239.5 4 354.9 5 480.0 6 561.9 7 587.6 8 603.2 9 498.9 10 391.1 11 284.1 12 194.7 Name: sales, dtype: float64
8月の平均(603.2点)が最大、1月の平均(144.3点)が最小で、その差は4倍以上。
Tシャツらしい、明らかな夏ピーク・冬ボトムのパターンが浮かび上がりました。
これは折れ線グラフでも見えていた「年次の波」を、数値として確定させた形です。
可視化するとさらに直感的に理解できます。
以下、コードです。
fig, ax = plt.subplots(figsize=(10, 5))
ax.bar(
monthly_mean.index,
monthly_mean.values,
color='blue'
)
ax.set_title('月別 平均販売点数', fontsize=13)
ax.set_xlabel('月')
ax.set_ylabel('平均販売点数')
ax.set_xticks(range(1, 13))
plt.tight_layout()
plt.show()
以下、実行結果です。
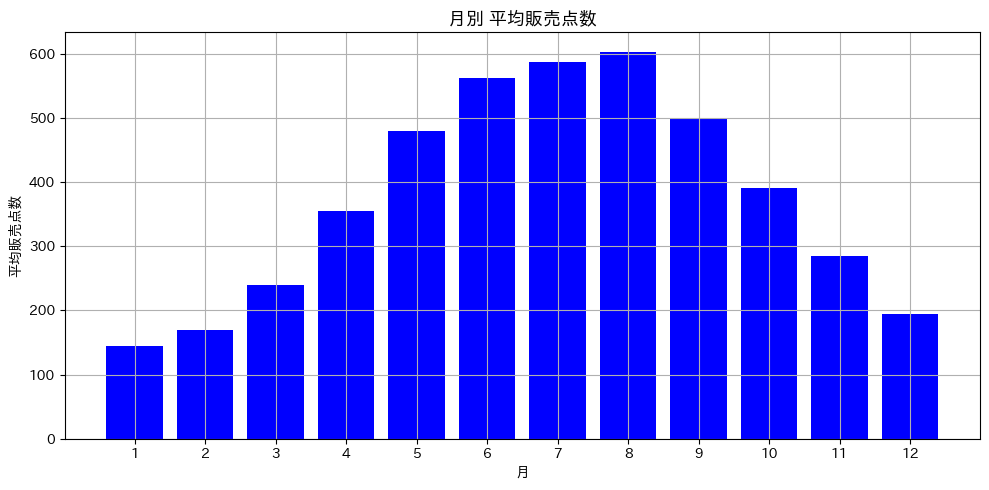
棒グラフが、夏に向かって伸び、冬に向かって縮む山なりの形になります。
Tシャツという商品特性から見ても、これは納得感のある結果です。
曜日別集計:月次集計では見えなかった週次パターン
ここからが「集計粒度」の面白いところです。
同じデータを今度は曜日別に集計してみます。
以下、コードです。
weekday_order = [
'Mon',
'Tue',
'Wed',
'Thu',
'Fri',
'Sat',
'Sun'
]
weekday_mean = (
df.groupby('weekday')['sales']
.mean()
.reindex(weekday_order)
.round(1)
)
print(weekday_mean)
以下、実行結果です。
weekday Mon 329.5 Tue 304.1 Wed 314.1 Thu 325.3 Fri 382.9 Sat 527.5 Sun 454.8 Name: sales, dtype: float64
土曜日(Sat)の平均(527.5点)は火曜日(Tue)の平均(304.1点)の1.7倍以上。
これは月次集計では完全に埋もれて見えなかったパターンです。
これも棒グラフにしてみます。
以下、コードです。
fig, ax = plt.subplots(figsize=(8, 5))
colors = ['skyblue']*5 + ['red']*2 # 土日を強調色に
ax.bar(
weekday_mean.index,
weekday_mean.values,
color=colors
)
ax.set_title('曜日別 平均販売点数', fontsize=13)
ax.set_xlabel('曜日')
ax.set_ylabel('平均販売点数')
plt.tight_layout()
plt.show()
以下、実行結果です。
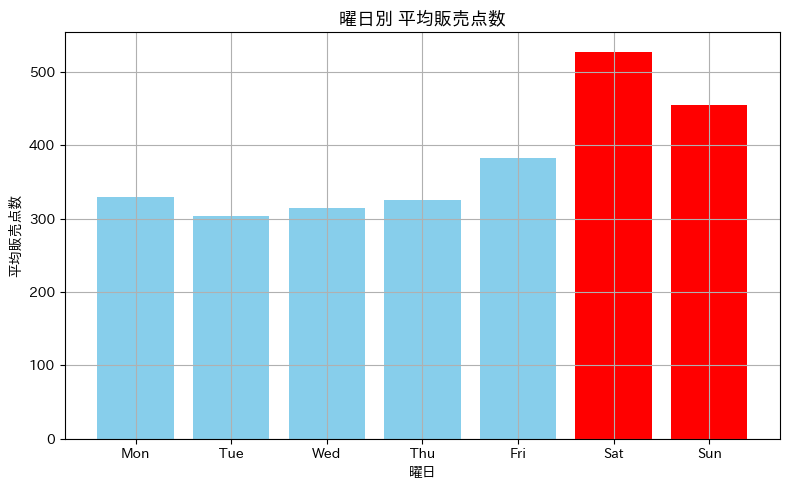
平日(月〜木)はほぼ同じ水準にあり、金曜日からじわっと上がり、土曜日でピーク、日曜日もまだ高水準、という典型的な「週末型」のパターンが見えます。
考えてみれば、衣料品は休日の家族連れの買い物で動くことが多いので、これも納得感のある結果です。
粒度を変えるという発想
ここで一つ立ち止まりましょう。同じsalesカラムを、
- 月で集計すれば年次の季節性が浮かび上がり、
- 曜日で集計すれば週次の周期性が浮かび上がる
これは時系列分析だけでなく、データ分析全般に通じる重要な発想です。
ステップ5:時系列を3つの成分に分解する
ここまでで「年次の季節性」「週次の周期性」「長期のトレンド」という3つの構造が見えてきました。
これらを機械的に分離してくれる便利な関数がstatsmodelsのseasonal_decomposeです。
時系列分解では、まずデータを「日付をインデックスに持つ時系列」の形に整える必要があります。
次に、model='multiplicative'(乗法モデル)とperiod=365(年次の周期)を指定して分解します。
乗法モデルとは、観測値を「トレンド × 季節性 × 残差」と捉えるモデルです。
今回のように「夏は冬の何倍売れる」という比率で季節性を表現するのが自然なケースに向いています。
以下、コードです。
ts = df.set_index('date')['sales']
result = seasonal_decompose(
ts,
model='multiplicative',
period=365
)
fig, axes = plt.subplots(4, 1, figsize=(10, 10))
axes[0].plot(
ts,
color='black',
linewidth=0.8
)
axes[0].set_title('元データ')
axes[1].plot(
result.trend,
color='blue',
linewidth=1.5
)
axes[1].set_title('トレンド成分')
axes[2].plot(
result.seasonal,
color='red',
linewidth=0.8
)
axes[2].set_title('季節成分')
axes[3].plot(
result.resid,
color='gray',
linewidth=0.5
)
axes[3].set_title('残差成分')
plt.tight_layout()
plt.show()
以下、実行結果です。
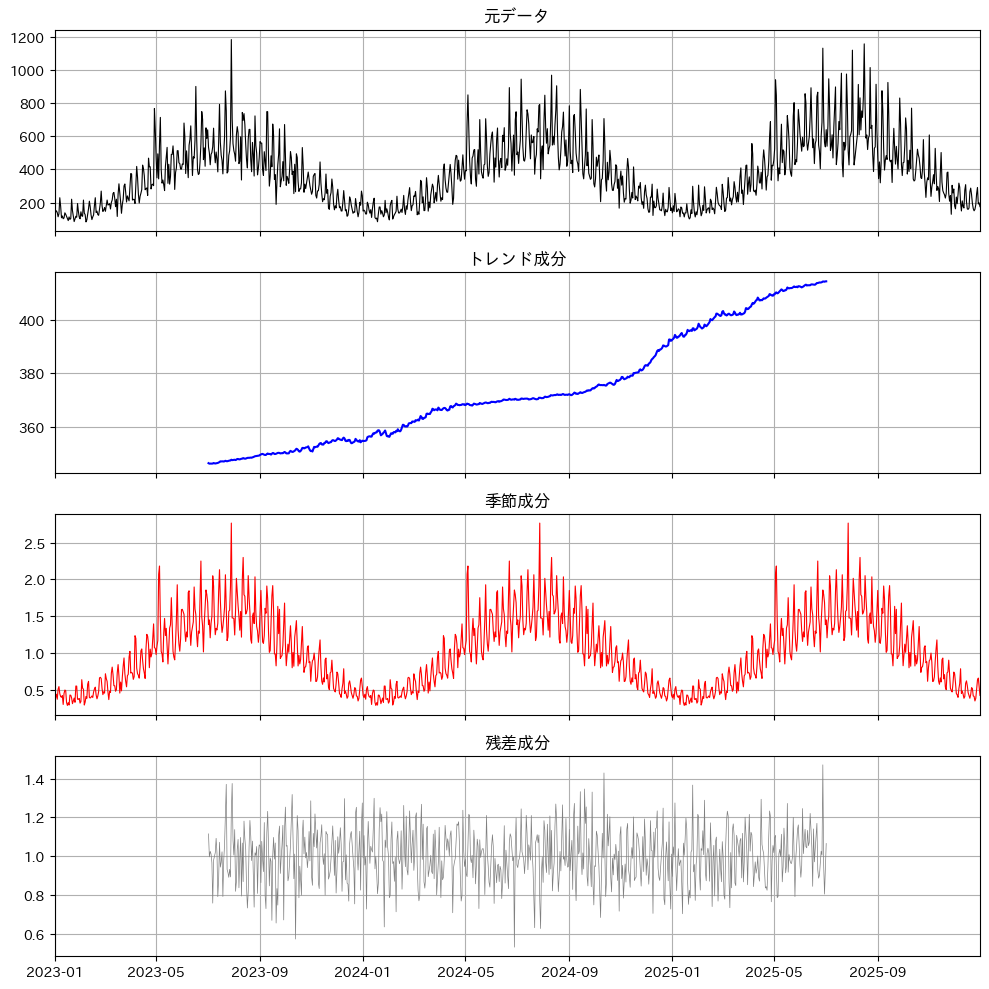
4段の図が描かれています。
それぞれが意味するものを順番に見ていきましょう。
- 元データ:日々の生の販売点数。山と谷の繰り返し、徐々に水準が上がる傾向、細かいばらつきが混在しています。
- トレンド成分:季節性とノイズを取り除いた、なめらかな上昇カーブ。これがまさに「事業全体の成長」を示しています。
- 季節成分:1年周期で繰り返される、夏に高く冬に低いきれいな波形。各時点の倍率(1なら平均、1.7なら平均の1.7倍)として表現されます。
- 残差成分:トレンドと季節性で説明しきれなかった部分。週次の凸凹や祝日効果、純粋なノイズが含まれています。
トレンド成分の伸び率を確認してみましょう。
以下、コードです。
trend_clean = result.trend.dropna()
start_v = trend_clean.iloc[0]
end_v = trend_clean.iloc[-1]
n_days = (
trend_clean.index[-1] - trend_clean.index[0]
).days
annual_growth = (end_v / start_v) ** (365 / n_days) - 1
print(
f'トレンドの開始 ({trend_clean.index[0].date()}): '
f'{start_v:.1f}'
)
print(
f'トレンドの終了 ({trend_clean.index[-1].date()}): '
f'{end_v:.1f}'
)
print(
f'推定年間成長率: {annual_growth*100:.1f}%'
)
以下、実行結果です。
トレンドの開始 (2023-07-02): 346.4 トレンドの終了 (2025-07-02): 414.4 推定年間成長率: 9.4%
データから「年率約9.4%で成長している」ことが定量的に取り出せました。
これは「昨対比で1.0倍(昨年と同じ水準)を目標にすると、本来期待すべき水準を約9%程度下回ってしまう(本来であれば昨年よりも9%高い目標にすべき)」ことを意味します。
事業の成長を無視した昨対比は、それだけで構造的な過小予測の罠を抱えていることになります。
ステップ6:訓練データと評価データを分ける
ここからは予測モデルの話に移ります。
モデルの良し悪しを公平に評価するには、データを「訓練用」と「評価用」に分け、未来側を評価用として確保しておく必要があります。
これは時系列でも分類でも変わらない基本ルールです。
ただし時系列の場合、ランダムに分けてはいけません。
「未来のデータでモデルを訓練して、過去のデータで評価する」という時間的な逆転が起こると、現実にはあり得ない情報を使ってしまうからです。
あくまで「ある時点までの過去」で訓練し、「それ以降の未来」で評価します。
では、訓練期間を2025年9月末まで、評価期間を直近3か月(2025年10月〜12月)に設定します。
以下、コードです。
train_end = '2025-09-30'
test_start = '2025-10-01'
train = df[df['date'] <= train_end].copy()
test = df[df['date'] >= test_start].copy()
print(
f'訓練期間: {train["date"].min().date()}'
f' 〜 {train["date"].max().date()}'
f' ({len(train)}日)'
)
print(
f'評価期間: {test["date"].min().date()}'
f' 〜 {test["date"].max().date()}'
f' ({len(test)}日)'
)
以下、実行結果です。
訓練期間: 2023-01-01 〜 2025-09-30 (1004日) 評価期間: 2025-10-01 〜 2025-12-31 (92日)
訓練に約2年9か月分(1,004日)、評価に3か月分(92日)を確保しました。
この92日に対して、これから紹介するベースライン手法がどれくらい当てられるかを比べていきます。
ステップ7:ベースライン①「昨対比」
最もシンプルで、ビジネスの現場で一番よく使われる予測手法が「昨対比」です。
「来年の同じ日は、今年の同じ日と同じくらいの売上が出るはずだ」という発想です。
評価期間の各日について、ちょうど365日前の値をそのまま予測値として使います。
以下、コードです。
test_dates = test['date'].values
yoy_pred = []
for d in test_dates:
prev_year = d - np.timedelta64(365, 'D')
matched = df[df['date'] == prev_year]
if len(matched) > 0:
yoy_pred.append(matched['sales'].iloc[0])
else:
yoy_pred.append(np.nan)
test['yoy_pred'] = yoy_pred
print((
test[['date', 'sales', 'yoy_pred']]
.head(10)
.to_string(index=False)
))
以下、実行結果です。
date sales yoy_pred 2025-10-01 441 294 2025-10-02 443 344 2025-10-03 545 474 2025-10-04 711 419 2025-10-05 646 456 2025-10-06 372 487 2025-10-07 455 351 2025-10-08 387 205 2025-10-09 516 338 2025-10-10 405 344
実績値(sales)と予測値(yoy_pred)を見比べると、実績値の方が一貫して高く出ていることが分かります。
これは先ほど時系列分解で確認した「年率約9%の成長」が反映されていないからです。
「昨対比は、成長している事業では構造的に予測を下振れさせる」という現象を、ここで目の当たりにしているわけです。
可視化してみましょう。
以下、コードです。
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(
test['date'],
test['sales'],
label='実績',
linewidth=1.5,
color='skyblue'
)
ax.plot(
test['date'],
test['yoy_pred'],
label='昨対比予測',
linewidth=1.5,
linestyle='--',
color='red'
)
ax.set_title('昨対比による予測 vs 実績', fontsize=13)
ax.set_xlabel('日付')
ax.set_ylabel('販売点数')
ax.legend()
plt.tight_layout()
plt.show()
以下、実行結果です。
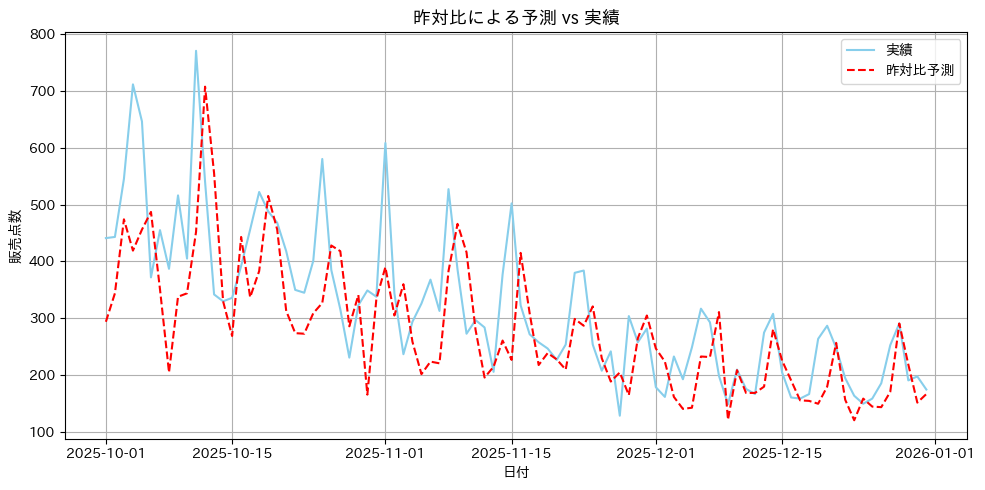
赤の破線(昨対比予測)が、青の実線(実績)よりも一貫して下に位置していることが視覚的に確認できます。
波形そのものはある程度追従できているものの、全体水準のずれが解消できていないのです。
ステップ8:ベースライン②「移動平均」
もう一つよく使われる手法が「移動平均」です。
「直近のN日間の平均を計算し、それを未来の予測値とする」というシンプルな発想です。
ここでは「訓練期間の最後30日の平均」を予測値として、評価期間全体(92日間)に適用します。
つまり、評価期間中はずっと同じ予測値を出し続ける、ということです。
以下、コードです。
ma30_pred = train['sales'].tail(30).mean()
test['ma30_pred'] = ma30_pred
print(
f'30日移動平均(直近30日の平均):'
f' {ma30_pred:.1f}'
)
以下、実行結果です。
30日移動平均(直近30日の平均): 523.0
訓練データの最後の30日間(2025年9月)の平均が約523点と算出されました。
これを10月から12月までずっと予測値として使う、というのが今回の設定です。
実際のグラフを見てみましょう。
以下、コードです。
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(
test['date'],
test['sales'],
label='実績',
linewidth=1.5,
color='skyblue'
)
ax.axhline(
ma30_pred,
label=f'30日移動平均予測 ({ma30_pred:.0f})',
linestyle='--',
color='red',
linewidth=1.5
)
ax.set_title('30日移動平均による予測 vs 実績', fontsize=13)
ax.set_xlabel('日付')
ax.set_ylabel('販売点数')
ax.legend()
plt.tight_layout()
plt.show()
以下、実行結果です。
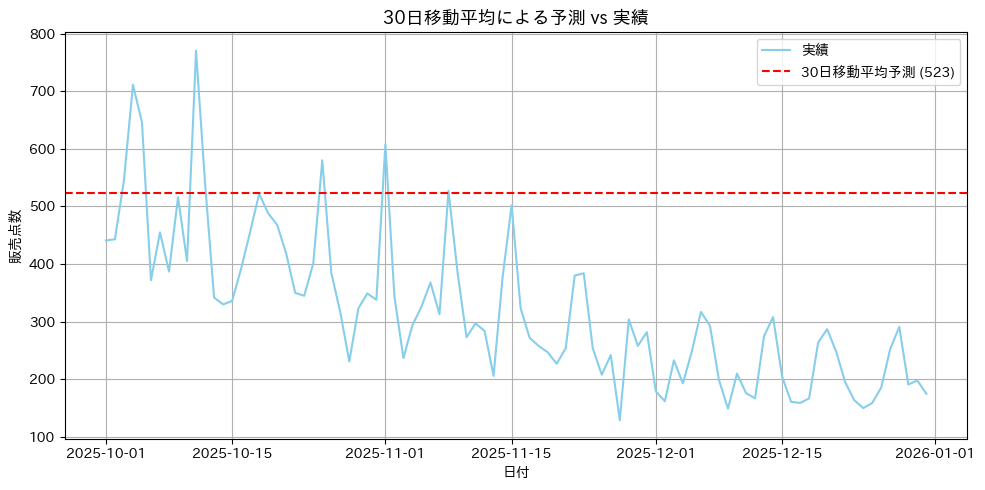
水平の赤い破線が「予測値」、青い実線が「実績値」です。
10月の前半は予測値(523)と実績値が比較的近いものの、11月以降は実績がどんどん下がっていくのに対し、予測値はずっと523のままです。
冬に向かって需要が下がるという季節性をまったく捉えていないので、当然の結果といえます。
ここから重要な教訓が得られます。
過去のトレンドや週次のノイズを取り除く前処理としては優秀ですが、それ自体を予測値として使うと、評価期間が訓練期間と異なる季節にまたがる場合に致命的に失敗します。
ステップ9:MAEとMAPEで精度を比較する
直感的にどちらが良さそうかは分かりましたが、定量的に比較するための評価指標を導入します。
時系列予測でよく使われるのがMAEとMAPEの2つです。
- MAE(Mean Absolute Error、平均絶対誤差):予測値\hat{y_t}と実績値y_tの差の絶対値の平均。単位は元のデータと同じ(点)。
- MAPE(Mean Absolute Percentage Error、平均絶対パーセント誤差):誤差を実績値y_tで割ったものの絶対値の平均(%)。スケールに依存しないので比較しやすい。
数式で書くと次の通りです。
$$
\text{MAE} = \frac{1}{n} \sum_{t=1}^{n} |y_t – \hat{y}_t|
$$
$$
\text{MAPE} = \frac{100}{n} \sum_{t=1}^{n} \left| \frac{y_t – \hat{y}_t}{y_t} \right|
$$
両指標を計算する関数を定義し、2つのベースラインに適用します。
以下、コードです。
def mae(y_true, y_pred):
return np.mean(np.abs(y_true - y_pred))
def mape(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
y_true = test['sales'].values
print('【精度比較】')
print(
f' 昨対比 : '
f'MAE = {mae(y_true, test["yoy_pred"]):5.1f}点 '
f'MAPE = {mape(y_true, test["yoy_pred"]):4.1f}%')
print(
f' 30日移動平均 : '
f'MAE = {mae(y_true, test["ma30_pred"]):5.1f}点 '
f'MAPE = {mape(y_true, test["ma30_pred"]):4.1f}%')
以下、実行結果です。
【精度比較】 昨対比 : MAE = 80.1点 MAPE = 23.4% 30日移動平均 : MAE = 218.2点 MAPE = 93.0%
昨対比が圧勝です。
MAPEで23.4%、つまり「平均すると実績の約23%ずれている」程度に当てられています。
一方の30日移動平均はMAPEが93%、ほぼ予測の体をなしていません。
ただし「昨対比のMAPE 23%が良いか悪いか」は、ビジネス的にどれくらいの誤差が許容できるかによります。
仮に1日500点売れる商品で23%ずれるとすれば、約115点の誤差。50店舗で割ると1店舗あたり約2.3点の誤差です。
これを「許容範囲」と見るか、「もっと縮めたい」と見るかは、次回の後編で扱う機会損失と売れ残りのコスト構造次第です。
前編のまとめ
ここまでを振り返ると、以下のようなプロセスを経てきました。
- 折れ線グラフでデータの全体像を眺め、年次の周期と長期トレンドを直感的に把握
- 集計粒度を月別/曜日別と切り替えることで、月次の季節性と週次の周期性を分離して観察
seasonal_decomposeで構造(トレンド・季節性・残差)を機械的に分離し、年率約9.4%の成長を定量化- 訓練/評価データを時間軸で分割し、「昨対比」と「30日移動平均」という素朴な手法を実装
- MAEとMAPEで精度を比較し、昨対比が圧勝(MAPE 23.4%)であることを確認
今回の大きなポイントの1つは、予測モデルに飛びつく前に、データの構造を理解することが何より重要だということです。
データに含まれる周期性やトレンドを把握していれば、なぜ「昨対比」がそこそこ機能するのか、なぜ「移動平均」が季節をまたぐと失敗するのかを、予測結果を見る前に予想できます。
逆にそれを理解せずにいきなりモデルを当てはめても、結果の良し悪しを判断できません。
しかし、ここまでの分析だけでは、まだ実務的な意思決定には届きません。
たとえば、次の3つの問いが残されています。
- 昨対比は成長を無視している:トレンドを取り込めば、もっと精度を上げられるのではないか?
- どの予測手法も「点予測」しか出していない:「明日は400点売れる」と言われても、それが「380〜420の間」なのか「200〜600の間」なのか、まったく分からない。不確実性の幅はどう扱えばよいのか?
- MAPEが小さい予測が、本当に「ビジネスにとって最良の予測」なのか?:機会損失と売れ残りのコストが非対称な状況で、平均誤差を最小化することは正解なのか?
これらの問いに答えていくのが、次回の後編です。
後編ではProphetという確率的予測モデルを導入し、トレンド・季節性・祝日効果を一気に学習させた上で、予測区間(不確実性の幅)を含む予測を取り出します。
さらに、機会損失と売れ残りのコスト構造を踏まえた真にビジネス的な評価指標を導入し、「予測区間の中のどの分位点で発注すべきか」という意思決定の問題まで踏み込みます。