

前回の前編では、ロジスティック回帰で離脱予測モデルを構築し、混同行列と精度指標まで見ました。
今回の後編では決定木とランダムフォレストの2手法を追加し、ROC曲線で3モデルを横断比較します。
さらに「閾値の調整」で適合率と再現率のトレードオフをコントロールする方法や、「ハイリスク顧客リスト」の作成などまで、実施していきます。
Contents
- 前回のおさらいと準備
- 決定木モデル ── 「もし〜なら」の判断ルールを可視化する
- 決定木の考え方
- 決定木モデルを構築する
- 決定木を可視化する ── 最大の魅力
- ランダムフォレスト ── 「200人の専門家の多数決」
- ランダムフォレストの考え方
- ランダムフォレストモデルを構築する
- 変数重要度の比較 ── 2つの視点で離脱要因を確認する
- ROC曲線 ── 3モデルを1枚のグラフで比較する
- ROC曲線とは何か
- 3モデルのROC曲線を重ねて描く
- 閾値の調整 ── ビジネス要件に合わせた最適化
- なぜ閾値を調整するのか
- 閾値と精度指標の関係を可視化する
- 「F1最大」ではなく「損失最小」で決める閾値設定
- ハイリスク顧客リストの作成 ── モデルをアクションにつなげる
- リスクレベル別に集計する
- ハイリスク会員の個別リストを作成する
- 交差検証でモデルの安定性を確認する
- まとめ
前回のおさらいと準備
後編に入る前に、前回(前編)で作成したデータとロジスティック回帰モデルを再現しておきましょう。
サンプルデータは、以下からダウンロードできます。
members_data.csv
ライブラリのインポート → 会員データ読み込み → 前処理 → ロジスティック回帰の構築までを一括で実行します。
以下、コードです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
confusion_matrix, classification_report,
roc_auc_score, accuracy_score,
precision_score, recall_score, f1_score
)
# データの読み込み
df = pd.read_csv('members_data.csv')
# 説明変数と目的変数
X = df.drop('churn', axis=1)
y = df['churn']
# 訓練データ(80%)とテストデータ(20%)に分割
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42,
stratify=y
)
# 標準化スカラーのインスタンスを作成
scaler = StandardScaler()
# 訓練データで学習+変換
X_train_scaled = scaler.fit_transform(X_train)
# テストデータは変換のみ
X_test_scaled = scaler.transform(X_test)
# ---- ロジスティック回帰(前回構築済み) ----
model_lr = LogisticRegression(random_state=42, max_iter=1000)
model_lr.fit(X_train_scaled, y_train)
y_pred_lr = model_lr.predict(X_test_scaled)
y_prob_lr = model_lr.predict_proba(X_test_scaled)[:, 1]
print(f"準備完了: {len(df)}人 × {len(X.columns)}変数")
print(f"離脱率: {df['churn'].mean():.1%}")
print(f"ロジスティック回帰 AUC: {roc_auc_score(y_test, y_prob_lr):.3f}")
以下、実行結果です。
準備完了: 3000人 × 8変数 離脱率: 30.6% ロジスティック回帰 AUC: 0.731
前処理済みの訓練/テストデータ、そしてロジスティック回帰モデルが手元に揃います。
後編で使うライブラリーを追加で読み込みます。
以下、コードです。
from sklearn.model_selection import cross_val_score from sklearn.tree import DecisionTreeClassifier, plot_tree from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import roc_curve
ここから2つ目・3つ目のモデルを追加していきます。
決定木モデル ── 「もし〜なら」の判断ルールを可視化する
決定木の考え方
決定木はロジスティック回帰とはまったく異なるアプローチで分類を行います。
「もし月間視聴時間が5時間未満なら → さらに問い合わせ回数が2回以上なら → 離脱」のように、条件分岐を繰り返してデータを分類します。
この「もし〜なら」のルールは、ビジネスパーソンにとって直感的に理解しやすく、施策立案に直結しやすいという大きな利点があります。
ロジスティック回帰の係数は数学的には正確ですが、決定木の分岐ルールの方が「なぜこの会員は離脱リスクが高いのか」を説明する場面では伝わりやすいことが多いのです。
決定木モデルを構築する
決定木モデルを構築します。
過学習を防ぐために木の深さ(max_depth)と末端ノードの最小サンプル数(min_samples_leaf)を制限しています。
決定木には標準化が不要です。決定木は各変数の値の大小関係だけで分岐するため、スケールの違いに影響されません。
以下、コードです。
# 決定木モデルの構築
model_dt = DecisionTreeClassifier(
max_depth=4, # 木の深さ
min_samples_leaf=10, # リーフノードの最小サンプル数
random_state=42
)
model_dt.fit(X_train, y_train)
# テストデータで予測
# ラベル(0 or 1)
y_pred_dt = model_dt.predict(X_test)
# 離脱確率
y_prob_dt = model_dt.predict_proba(X_test)[:, 1]
print("【決定木の精度指標】")
print(f"正解率: {accuracy_score(y_test, y_pred_dt):.3f}")
print(f"適合率: {precision_score(y_test, y_pred_dt):.3f}")
print(f"再現率: {recall_score(y_test, y_pred_dt):.3f}")
print(f"F1スコア: {f1_score(y_test, y_pred_dt):.3f}")
print(f"AUC: {roc_auc_score(y_test, y_prob_dt):.3f}")
以下、実行結果です。
【決定木の精度指標】 正解率: 0.780 適合率: 0.691 再現率: 0.511 F1スコア: 0.588 AUC: 0.781
決定木の精度指標が表示されます。
ロジスティック回帰(Accuracy 0.727、Precision 0.614、Recall 0.293、F1 0.397、AUC 0.731)と比べると、決定木は全指標で上回っています。
特に再現率が0.293→0.511へ大きく改善しており、離脱者の取りこぼしが大幅に減っています。
一方で適合率も0.614→0.691と上昇しております。
F1スコアも0.397→0.588とバランス面での改善が顕著です。
AUCは0.731→0.781へ上がっており、順位付け能力も決定木が優勢です。
決定木を可視化する ── 最大の魅力
決定木を図として描画します。これが決定木の最大の魅力です。
上から下に分岐ルールを辿ることで、離脱を判定するロジックがそのまま読み取れます。
以下、コードです。
plt.figure(figsize=(10, 5))
plot_tree(
model_dt,
feature_names=X.columns,
class_names=['継続', '離脱'],
filled=True, rounded=True, fontsize=9, proportion=True,
max_depth=2 # 表示する深さを制限
)
plt.title('決定木による離脱予測ルール', fontsize=14)
plt.tight_layout()
plt.show()
以下、実行結果です。
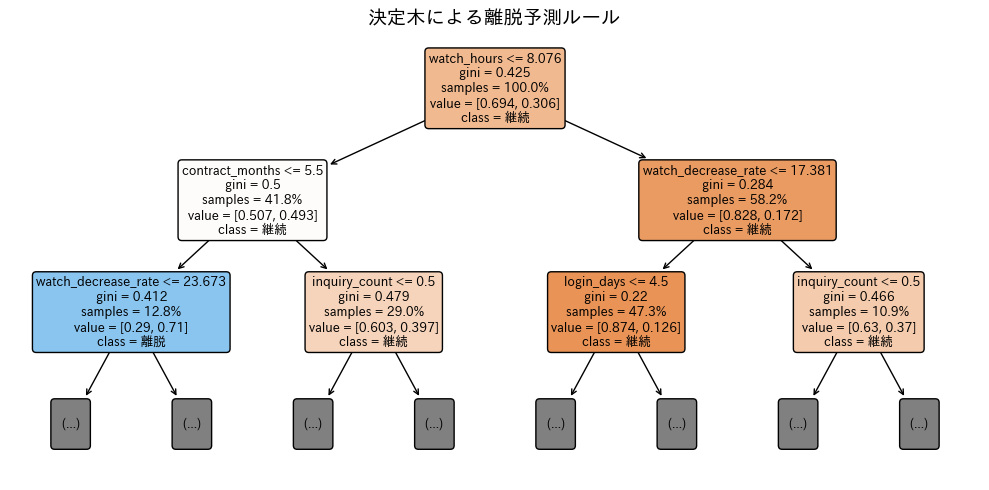
この図は、決定木モデルがどのようにデータを分岐させて離脱・継続を判定しているかを可視化したものです。
上から下へ向かって分岐が進みます。最上部(ルートノード)が最初の判定基準で、以降は条件に応じて枝分かれし、最後に到達する葉ノードで予測クラス(継続/離脱)が決まります。
各ノードには分岐条件(例:watch_hours ≤ ある値)が表示され、ノード内のクラス分布(継続と離脱の割合)やサンプル比率が示されます。色の濃さは「どちらのクラスに偏っているか(純度)」を表し、濃いほど特定クラスの割合が高いことを意味します。
ノードに書かれた条件を満たす場合は左側の枝へ、満たさない場合は右側の枝へ進みます。これにより、視聴時間や視聴減少率、ログイン日数などの数値条件を段階的に適用し、より同質なグループに分けていきます。
上位の分岐に現れる特徴量ほど重要度が高い傾向にあります。最初の数段に出ている「watch_hours(視聴時間)」や「watch_decrease_rate(視聴減少率)」は、これらが離脱判定に強く効いていると解釈できます。
葉ノードでは、そのノードに属するサンプルのクラス割合が表示され、より大きい割合のクラスが予測結果になります。色がより濃い葉ノードほど確信度が高い(偏りが大きい)と捉えられます。
離脱側に強く偏った葉ノードが示すルール(例:視聴時間が低く、かつ視聴が直近で大きく減っている)をターゲット条件として抽出することで、優先的な介入対象を定義できます。反対に継続側に偏った葉ノードは、過剰介入を避けるための基準として活用できます。
図は表示用に深さを2に制限しています。全体の分岐をテキストで表示します。
以下、コードです。
from sklearn.tree import export_text
rules_text = export_text(
model_dt,
feature_names=list(X.columns),
decimals=3
)
print(rules_text)
以下、実行結果です。
|--- watch_hours <= 8.076 | |--- contract_months <= 5.500 | | |--- watch_decrease_rate <= 23.673 | | | |--- login_days <= 11.500 | | | | |--- class: 1 | | | |--- login_days > 11.500 | | | | |--- class: 1 | | |--- watch_decrease_rate > 23.673 | | | |--- contract_months <= 2.500 | | | | |--- class: 1 | | | |--- contract_months > 2.500 | | | | |--- class: 1 | |--- contract_months > 5.500 | | |--- inquiry_count <= 0.500 | | | |--- age <= 55.500 | | | | |--- class: 0 | | | |--- age > 55.500 | | | | |--- class: 1 | | |--- inquiry_count > 0.500 | | | |--- watch_decrease_rate <= 14.446 | | | | |--- class: 0 | | | |--- watch_decrease_rate > 14.446 | | | | |--- class: 1 |--- watch_hours > 8.076 | |--- watch_decrease_rate <= 17.381 | | |--- login_days <= 4.500 | | | |--- class: 1 | | |--- login_days > 4.500 | | | |--- watch_hours <= 12.030 | | | | |--- class: 0 | | | |--- watch_hours > 12.030 | | | | |--- class: 0 | |--- watch_decrease_rate > 17.381 | | |--- inquiry_count <= 0.500 | | | |--- contract_months <= 3.500 | | | | |--- class: 0 | | | |--- contract_months > 3.500 | | | | |--- class: 0 | | |--- inquiry_count > 0.500 | | | |--- favorite_count <= 10.500 | | | | |--- class: 1 | | | |--- favorite_count > 10.500 | | | | |--- class: 1
ランダムフォレスト ── 「200人の専門家の多数決」
ランダムフォレストの考え方
単一の決定木は解釈しやすい反面、予測精度が十分でないことがあります。
ランダムフォレストは、多数の決定木を「寄せ集めて」多数決を取ることで、個々の木の弱点を補い合い、より高い精度を実現する手法です。
「200本の木がそれぞれ予測して、多数派の結論を採用する」というイメージです。
各木はデータの一部をランダムに選んで構築されるため、過学習にも強いという利点があります。
ランダムフォレストモデルを構築する
200本の決定木を組み合わせたランダムフォレストモデルを構築します。
以下、コードです。
# ランダムフォレストモデルの構築
model_rf = RandomForestClassifier(
n_estimators=1000, # 決定木の本数
max_depth=10, # 木の最大深さ
min_samples_leaf=10, # リーフノードの最小サンプル数
min_samples_split=10, # 分割に必要な最小サンプル数
class_weight='balanced',# クラス不均衡を考慮して重み付け
random_state=42, # 再現性のための乱数シード
)
model_rf.fit(X_train, y_train)
# テストデータで予測
# ラベル(0 or 1)
y_pred_rf = model_rf.predict(X_test)
# 離脱確率
y_prob_rf = model_rf.predict_proba(X_test)[:, 1]
print("【ランダムフォレストの精度指標】")
print(f"正解率: {accuracy_score(y_test, y_pred_rf):.3f}")
print(f"適合率: {precision_score(y_test, y_pred_rf):.3f}")
print(f"再現率: {recall_score(y_test, y_pred_rf):.3f}")
print(f"F1スコア: {f1_score(y_test, y_pred_rf):.3f}")
print(f"AUC: {roc_auc_score(y_test, y_prob_rf):.3f}")
以下、実行結果です。
【ランダムフォレストの精度指標】 正解率: 0.748 適合率: 0.579 再現率: 0.658 F1スコア: 0.616 AUC: 0.798
ロジスティック回帰や単体の決定木と比べて、全体的なバランスと順位付け能力がさらに向上しています。
特にAUCが0.798と高く、スコアによる優先度付けに適しています。
再現率が0.658まで上がっており、離脱者の取りこぼしを大きく減らせています。
一方で適合率は0.579と中程度で、再現率向上とのトレードオフとして決定木より低くなっています。
F1スコア0.616は適合率・再現率の両立度合いが改善していることを示します。
実務上は、上位スコア帯に段階的な介入を行う運用(例:上位10%へ強介入、10–30%へ軽接触)が有効で、さらにコスト・利得を踏まえたしきい値最適化で成果最大化が期待できます。
変数重要度の比較 ── 2つの視点で離脱要因を確認する
3つのモデルがそれぞれ「どの変数を重視しているか」を比較してみましょう。
複数のモデルが同じ変数を重要視していれば、結果の信頼性が高いと言えます。
ロジスティック回帰の係数(標準化データでの値)とランダムフォレストの変数重要度を並べて比較します。
以下、コードです。
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 10))
# ロジスティック回帰の係数(標準化データでの値)
lr_importance = pd.Series(
model_lr.coef_[0], index=X.columns
).sort_values()
colors_lr = [
'#2E86AB' if v < 0 else '#E94F37'
for v in lr_importance
]
ax1.barh(
range(len(lr_importance)),
lr_importance.values,
color=colors_lr
)
ax1.set_yticks(range(len(lr_importance)))
ax1.set_yticklabels(lr_importance.index, fontsize=10)
ax1.set_xlabel('係数(標準化)', fontsize=11)
ax1.set_title('ロジスティック回帰の係数', fontsize=13)
ax1.axvline(x=0, color='black', linewidth=0.5)
# ランダムフォレストの変数重要度
rf_importance = pd.Series(
model_rf.feature_importances_, index=X.columns
).sort_values()
ax2.barh(
range(len(rf_importance)),
rf_importance.values,
color='#44AF69'
)
ax2.set_yticks(range(len(rf_importance)))
ax2.set_yticklabels(rf_importance.index, fontsize=10)
ax2.set_xlabel('重要度', fontsize=11)
ax2.set_title('ランダムフォレストの変数重要度', fontsize=13)
plt.suptitle('モデル間の変数重要度比較', fontsize=14, y=1.02)
plt.tight_layout()
plt.show()
以下、実行結果です。
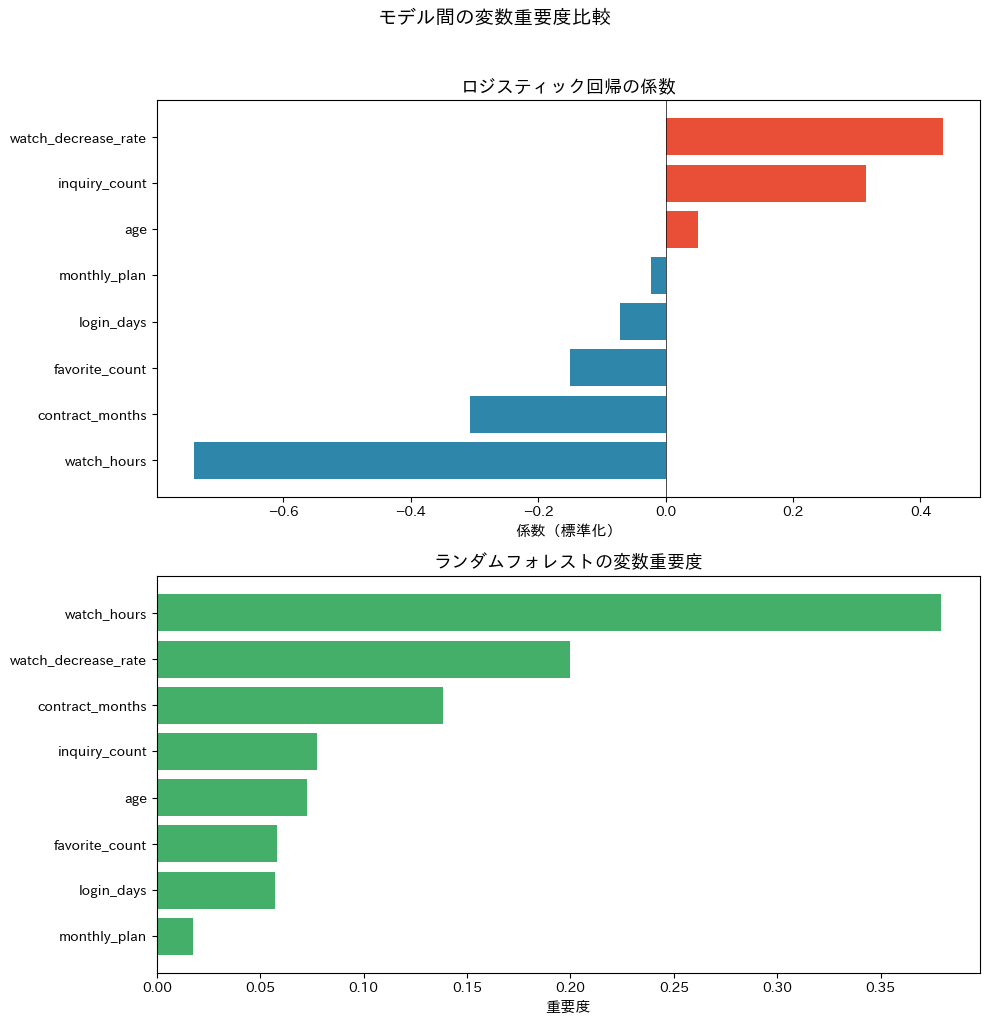
2つのグラフを見比べてください。ロジスティック回帰の係数は「正 → 離脱を促進」「負 → 継続を促進」と方向性がわかる一方、ランダムフォレストの重要度は「その変数が予測にどれだけ貢献しているか」を示しますが方向性はわかりません。
両方を併用することで、変数の重要度と影響の方向の両方を把握できます。
たとえば両モデルとも「問い合わせ回数」と「月間視聴時間」を重要視していれば、これらが離脱の核心的な要因であるという結論に自信が持てます。
ROC曲線 ── 3モデルを1枚のグラフで比較する
ROC曲線とは何か
ROC曲線(Receiver Operating Characteristic Curve)は、分類モデルの識別力を総合的に評価するためのグラフです。
横軸に偽陽性率(FPR = 1 – 特異度)、縦軸に真陽性率(TPR = 再現率)をプロットします。
曲線が左上に膨らんでいるほど「少ない偽陽性で多くの真陽性を捕捉できる」優れたモデルであり、その下の面積がAUC(Area Under the Curve)です。
AUCの目安として、0.7以上で「まずまず」、0.8以上で「良好」、0.9以上で「優秀」と判断されます。0.5は「コインを投げて決めるのと同じ」ランダム予測を意味します。
3モデルのROC曲線を重ねて描く
ロジスティック回帰・決定木・ランダムフォレストの3モデルのROC曲線を1枚のグラフに重ねて描き、AUCの値とともに性能を視覚的に比較します。
以下、コードです。
# ROC曲線をプロット
plt.figure(figsize=(8, 8))
# 各モデルの予測確率を辞書にまとめる
models_dict = {
'ロジスティック回帰': y_prob_lr,
'決定木': y_prob_dt,
'ランダムフォレスト': y_prob_rf
}
colors = ['#2E86AB', '#F4A261', '#E94F37']
# 各モデルについてROC曲線を計算・描画
for (name, probs), color in zip(models_dict.items(), colors):
fpr, tpr, _ = roc_curve(y_test, probs) # FPRとTPRを計算
auc_val = roc_auc_score(y_test, probs) # AUCを計算
plt.plot(
fpr, tpr,
color=color, linewidth=2,
# 凡例にモデル名とAUCを表示
label=f'{name} (AUC={auc_val:.3f})'
)
# ランダム分類器の基準線(対角線)
plt.plot(
[0, 1], [0, 1],
'k--', linewidth=1,
label='ランダム (AUC=0.500)'
)
plt.xlabel('偽陽性率 (FPR)', fontsize=12)
plt.ylabel('真陽性率 (TPR)', fontsize=12)
plt.title('ROC曲線の比較', fontsize=14)
plt.legend(fontsize=11, loc='lower right')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
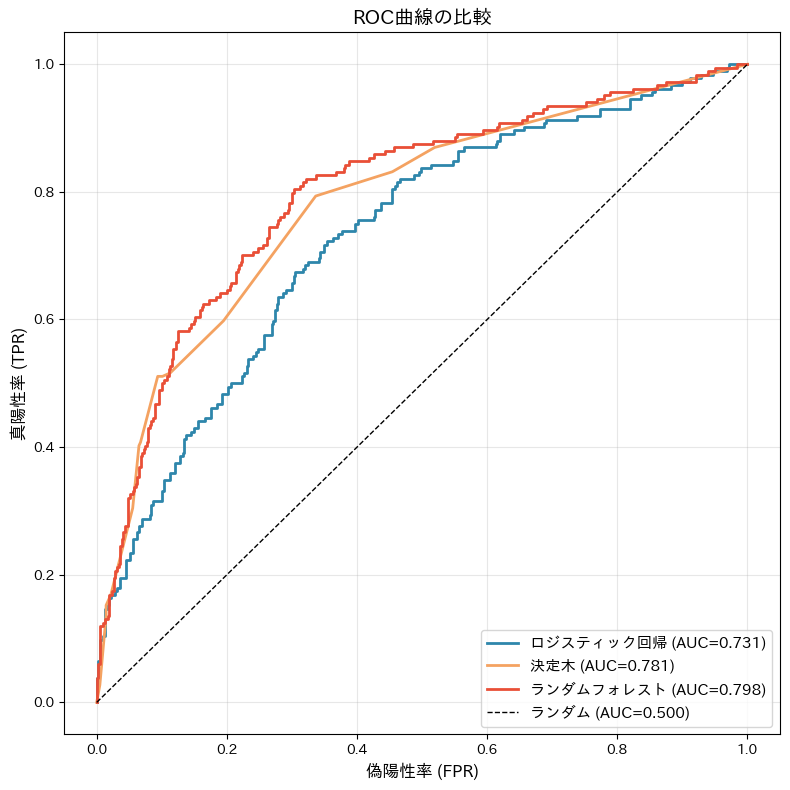
この図は、横軸は偽陽性率(False Positive Rate: FPR)、縦軸は真陽性率(True Positive Rate: TPR)を表し、各モデルのしきい値を連続的に変化させたときの検知性能のトレードオフを曲線で描いています。
FPRは実際には陰性(継続)であるものを誤って陽性(離脱)と判定してしまう比率で、TPRは実際の陽性(離脱)を正しく陽性と判定できた比率です。
図中の対角線はランダム分類器の基準であり、ROC曲線がこの対角線から左上方向へ離れるほど、モデルの識別能力が高いことを示します。
見方としては、曲線全体が左上に張り出しているほど優秀であり、同時に凡例に表示されているAUC(Area Under the Curve)がその優劣を一数値で要約します。
AUCはROC曲線の下の面積で、1に近いほど「離脱者に高いスコア、継続者に低いスコアを与える」順位付け能力が高いことを意味します。
この図では、ランダムフォレストの曲線が最も左上に位置しAUCも最大で、次いで決定木、最後にロジスティック回帰という順に性能差が表れています。
用語の補足として、真陽性率(TPR)は「感度」とも呼ばれ、陽性(離脱)をどれだけ見逃さずに当てられるかを示します。
一方、特異度(Specificity)は「実際に陰性(継続)であるものを陰性と正しく判定する比率」で、1−FPRに相当します。
ROCの横軸がFPRであることから、曲線を左に寄せる(FPRを低く保つ)ことは、特異度を高く保つことと同義です。
したがって、左上に張り出した曲線は「感度(TPR)も高く、特異度(1−FPR)も高い」理想的な判別に近いことを示します。
閾値の調整 ── ビジネス要件に合わせた最適化
なぜ閾値を調整するのか
ここまでの予測はすべて、デフォルトの閾値 0.5 を使って「離脱確率が50%以上なら離脱と判定」していました。
しかし、この閾値は必ずしもビジネスに最適とは限りません。
たとえば「クーポンのコストが安いから、空振り(FP)してもいい。見逃し(FN)の方が怖い」という状況なら閾値を下げて再現率を重視すべきですし、「引き留め施策のコストが高いので無駄打ちを避けたい」なら閾値を上げて適合率を重視すべきです。
閾値と精度指標の関係を可視化する
最も性能の良いモデル(ランダムフォレスト)を使い、閾値を変化させたときの適合率・再現率・F1スコアの推移を可視化します。
以下、コードです。
# 閾値の候補を作成(0.1 から 0.85 まで 0.05刻み)
thresholds = np.arange(0.1, 0.9, 0.05)
# 各指標の値を格納するリストを初期化
precisions, recalls, f1s = [], [], []
# 閾値ごとに予測→指標を計算
for thresh in thresholds:
# 閾値以上を1(離脱)と予測
y_pred_thresh = (y_prob_rf >= thresh).astype(int)
# 適合率(Precision)を計算(ゼロ除算は0に)
precisions.append(precision_score(y_test, y_pred_thresh, zero_division=0))
# 再現率(Recall)を計算
recalls.append(recall_score(y_test, y_pred_thresh))
# F1スコアを計算(ゼロ除算は0に)
f1s.append(f1_score(y_test, y_pred_thresh, zero_division=0))
# プロットの設定
plt.figure(figsize=(10, 6))
# 各指標の曲線を描画
# 適合率(Precision)の曲線
plt.plot(
thresholds,
precisions,
'o-', color='#2E86AB', linewidth=2,
label='適合率 (Precision)'
)
# 再現率(Recall)の曲線
plt.plot(
thresholds,
recalls,
's-', color='#E94F37', linewidth=2,
label='再現率 (Recall)'
)
# F1スコアの曲線
plt.plot(
thresholds,
f1s,
'^-', color='#44AF69', linewidth=2,
label='F1スコア'
)
plt.xlabel('閾値', fontsize=12)
plt.ylabel('スコア', fontsize=12)
plt.title('閾値と精度指標の関係', fontsize=14)
plt.legend(fontsize=11)
plt.grid(True, alpha=0.3)
# デフォルトの閾値0.5を縦線で表示
plt.axvline(
x=0.5,
color='gray',
linestyle='--',
alpha=0.5,
label='デフォルト閾値 (0.5)'
)
plt.tight_layout()
plt.show()
以下、実行結果です。
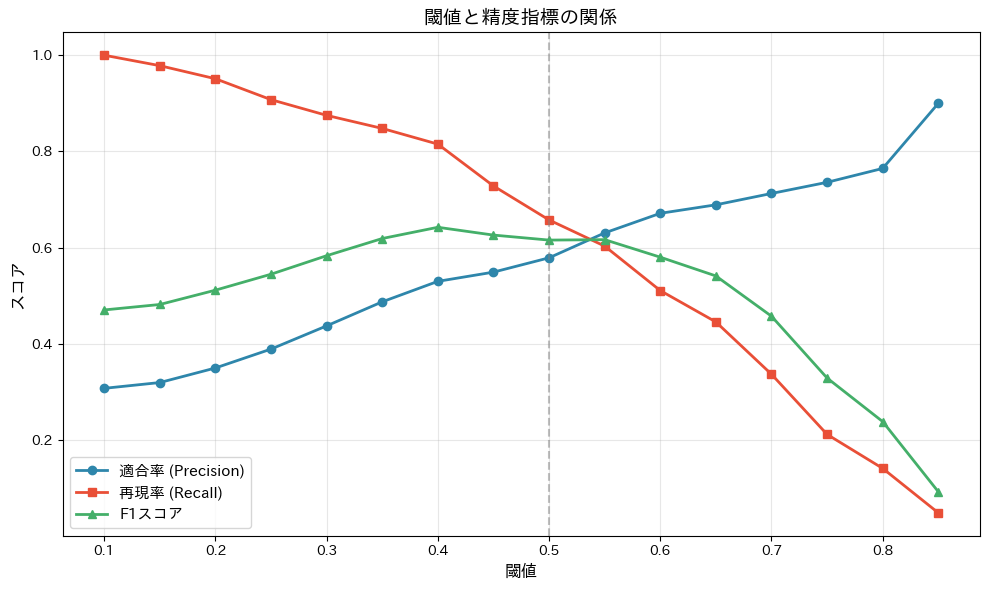
グラフには3本の曲線が描かれ、閾値を動かすと適合率と再現率がトレードオフの関係にあることが見て取れます。
閾値を下げると再現率(離脱者の捕捉率)は上がりますが、適合率(予測の的中率)は下がります。
F1スコアが最大になる閾値は、両者のバランスが最も良い点です。
ビジネスの状況に応じた閾値設定の考え方を整理すると、「クーポンのコストが安い → 空振りしてもいい → 閾値を下げて再現率を重視」「引き留め施策のコストが高い → 無駄打ちを避けたい → 閾値を上げて適合率を重視」という判断になります。
この閾値調整は、データサイエンスの技術とビジネス判断が交わる重要なポイントです。
「F1最大」ではなく「損失最小」で決める閾値設定
ただし実務では、「適合率・再現率・F1」だけで閾値を決めるのではなく、誤分類が生む金額の損失を直接評価して閾値を決めるのが合理的です。
ここで、離脱(1)を検知してクーポンを配る施策を考えると、誤分類のコストは次のように整理できます。
| 何が起きるか(分類のズレ) | ビジネス上の意味 | 発生するコスト(例) | |
|---|---|---|---|
| FP(偽陽性) | 実際は継続する会員(0)に「離脱(1)」と予測してクーポンを配る | 不要なクーポン配布(空振り) | 無駄なクーポンコスト:1人あたり200円 |
| FN(偽陰性) | 実際は離脱する会員(1)を「継続(0)」と予測して見逃す | 離脱防止の機会損失 |
この2つを比較すると、多くのケースで FNの損失のほうが大きいため、F1最大の閾値よりも「やや低めの閾値(再現率寄り)」が最適になることが多いです。
そこで、閾値ごとに混同行列を計算し、以下を最小化する閾値 \tau を求めます。
$$
\text{期待コスト}(\tau)= C_{FP}\cdot FP(\tau) + C_{FN}\cdot FN(\tau)
$$
この方法なら「ビジネス上、どちらのミスが痛いか」を数値で反映した意思決定ができます。
以下、コードです。
#----------------------------------------------------------
# コスト設定
# ------------------------------------------------------------
cost_fp = 500 # FP1件あたりのコスト(不要なクーポン)
cost_fn = 3000 # FN1件あたりのコスト(離脱見逃し=会員喪失)
# ------------------------------------------------------------
# 閾値ごとに「指標」と「期待コスト」を計算(0.10〜0.89を0.01刻み)
# ------------------------------------------------------------
# 閾値の候補を作成(0.10から0.89まで0.01刻み)
thresholds = np.arange(0.1, 0.9, 0.01)
# 計算結果の行を格納するリスト
rows = []
for thresh in thresholds:
# 予測確率が閾値以上なら離脱(1)と判定
y_pred = (y_prob_rf >= thresh).astype(int)
# 混同行列の各要素を取得
tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()
# 精度指標を計算
# 適合率
precision = precision_score(y_test, y_pred, zero_division=0)
# 再現率
recall = recall_score(y_test, y_pred, zero_division=0)
# F1スコア
f1 = f1_score(y_test, y_pred, zero_division=0)
# 期待コスト(合計):FPとFNの件数にコストを掛け合わせる
total_cost = cost_fp * fp + cost_fn * fn
# 1人あたりコスト(比較しやすいよう正規化)
cost_per_user = total_cost / len(y_test)
# 結果を行として保存
rows.append({
"threshold": thresh,
"tn": tn, "fp": fp, "fn": fn, "tp": tp,
"precision": precision,
"recall": recall,
"f1": f1,
"total_cost": total_cost,
"cost_per_user": cost_per_user
})
# すべての閾値の結果をDataFrame化
result_df = pd.DataFrame(rows)
# ------------------------------------------------------------
# コスト最小の閾値を取得(最もコストが低い行を抽出)
# ------------------------------------------------------------
best_row = result_df.loc[result_df["total_cost"].idxmin()]
best_thresh = best_row["threshold"]
# 結果の概要表示
print("=== コスト最小の閾値 ===")
print(f"最適閾値: {best_thresh:.2f}")
print(
" "
f"FP={int(best_row['fp'])}, "
f"FN={int(best_row['fn'])}, "
f"TP={int(best_row['tp'])}, "
f"TN={int(best_row['tn'])}"
)
print(
" "
f"Precision={best_row['precision']:.3f}, "
f"Recall={best_row['recall']:.3f}, "
f"F1={best_row['f1']:.3f}"
)
print(
" "
f"総コスト={best_row['total_cost']:.0f}, "
f"1人あたりコスト={best_row['cost_per_user']:.2f}"
)
以下、実行結果です。
=== コスト最小の閾値 === 最適閾値: 0.35 FP=164, FN=28, TP=156, TN=252 Precision=0.487, Recall=0.848, F1=0.619 総コスト=166000, 1人あたりコスト=276.67
グラフ化し視覚的に確認します。
以下、コードです。
plt.figure(figsize=(10, 6))
# 1人あたりコストのプロット
plt.plot(
result_df["threshold"],
result_df["cost_per_user"],
marker="o", linewidth=2
)
# 最適閾値に縦線、最適点をプロット
plt.axvline(best_thresh, linestyle="--", alpha=0.7)
plt.scatter([best_thresh], [best_row["cost_per_user"]], s=120)
plt.xlabel("閾値", fontsize=12)
plt.ylabel("1人あたり期待コスト", fontsize=12)
plt.title("閾値と期待コスト(FP/FNコスト反映)", fontsize=14)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
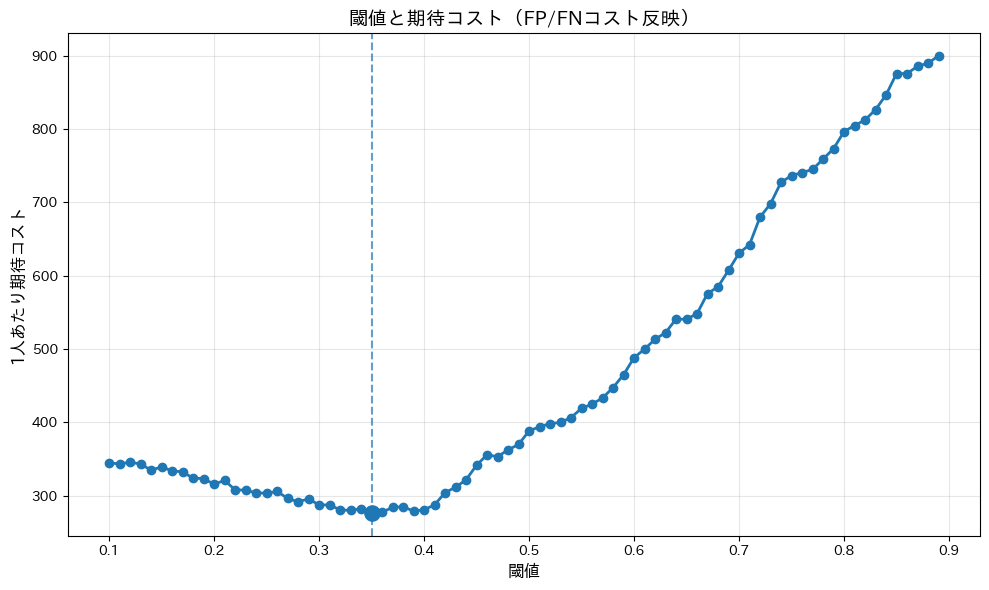
他の閾値も含め、上位候補を10件ほど表示します。
以下、コードです。
# 表示する列を定義
display_cols = [
"threshold",
"precision", "recall", "f1", "fp", "fn",
"cost_per_user"
]
# total_costで昇順ソートし、指定列の上位10件を整形して表示
print("=== コストが小さい閾値上位10件 ===")
print(
result_df.sort_values("total_cost")[
display_cols].head(10).to_string(index=False)
)
以下、実行結果です。
=== コストが小さい閾値上位10件 ===
threshold precision recall f1 fp fn cost_per_user
0.35 0.487500 0.847826 0.619048 164 28 276.666667
0.36 0.493631 0.842391 0.622490 159 29 277.500000
0.39 0.515254 0.826087 0.634656 143 32 279.166667
0.33 0.467456 0.858696 0.605364 180 26 280.000000
0.40 0.530035 0.815217 0.642398 133 34 280.833333
0.32 0.459538 0.864130 0.600000 187 25 280.833333
0.34 0.477064 0.847826 0.610568 171 28 282.500000
0.37 0.496753 0.831522 0.621951 155 31 284.166667
0.38 0.503311 0.826087 0.625514 150 32 285.000000
0.41 0.534296 0.804348 0.642082 129 36 287.500000
このように、閾値を「精度指標の最大化」ではなく「期待損失の最小化」で決めると、モデルの出力(確率)をそのままビジネスの意思決定ルールに変換できます。
特に、FN(離脱見逃し)の損失が大きい局面では、F1最大の閾値よりも低い閾値が選ばれやすくなり、逆にクーポン原資が厳しい局面では高い閾値が選ばれやすくなります。
ハイリスク顧客リストの作成 ── モデルをアクションにつなげる
リスクレベル別に集計する
ランダムフォレストの予測確率を使って、テストデータの全会員を「低リスク」「中リスク」「高リスク」の3レベルに分類し、各レベルの実際の離脱率を確認します。
以下、コードです。
# テストデータの説明変数のコピーを作成
risk_df = X_test.copy()
# 予測した離脱確率を追加
risk_df['churn_prob'] = y_prob_rf
# 実際の離脱ラベル(0:継続, 1:離脱)を追加
risk_df['actual'] = y_test.values
# 離脱確率に基づいてリスク区分(低・中・高)を付与
risk_df['risk_level'] = pd.cut(
risk_df['churn_prob'],
bins=[0, 0.3, 0.6, 1.0], # 区切りの閾値
labels=['低リスク', '中リスク', '高リスク'] # 各区間のラベル
)
# リスクレベル別に、人数・平均離脱確率・実際の離脱率を集計
print("【リスクレベル別の集計】")
risk_summary = risk_df.groupby('risk_level', observed=True).agg(
人数=('churn_prob', 'count'), # 該当者数
平均離脱確率=('churn_prob', 'mean'), # 離脱確率の平均
実際の離脱率=('actual', 'mean') # 実際に離脱した割合
).round(3)
# 集計結果を表示
print(risk_summary)
以下、実行結果です。
【リスクレベル別の集計】
人数 平均離脱確率 実際の離脱率
risk_level
低リスク 232 0.210 0.099
中リスク 228 0.442 0.294
高リスク 140 0.734 0.671
高リスクグループの実際の離脱率が高く、低リスクグループの離脱率が低ければ、モデルの識別力が実用的であることが確認できます。
たとえば高リスクグループの実際の離脱率が50%を超えていれば、このグループに集中的に施策を打つことでコスト効率の良い顧客引き留めが可能です。
「全員に同じ施策を打つ」のではなく「リスクに応じて施策を変える」ことを可能にする。これこそが予測モデルのビジネス価値です。
ハイリスク会員の個別リストを作成する
離脱確率の上位20名をリストアップし、各会員の特徴を確認します。
個別の施策立案のヒントとして活用します。
以下、コードです。
# 離脱確率の高い上位20名を抽出し、主要指標を表示する
high_risk = risk_df.nlargest(20, 'churn_prob')[[
'watch_hours', # 視聴時間(週あたりなどの想定)
'login_days', # ログイン日数(一定期間内)
'watch_decrease_rate', # 視聴減少率(行動変化の指標)
'inquiry_count', # 問い合わせ件数(不満・問題の兆候)
'contract_months', # 契約月数(加入期間)
'churn_prob', # 予測された離脱確率
'actual' # 実際の離脱ラベル(0:継続, 1:離脱)
]].round(2)
# 結果の表を出力
print("【離脱リスク上位20名】")
print(high_risk.to_string())
# 上位20名のうち実際に離脱した人数を集計して表示
print(
f"\n上位20名中の実際の離脱者数: "
f"{high_risk['actual'].sum():.0f}人 / 20人"
)
以下、実行結果です。
【離脱リスク上位20名】
watch_hours login_days watch_decrease_rate inquiry_count contract_months churn_prob actual
1008 2.86 11 26.44 2 5 0.93 1
1199 3.61 10 26.48 2 2 0.93 1
2113 1.95 12 28.20 1 40 0.90 1
2021 0.80 11 23.13 1 14 0.89 1
1654 5.27 13 23.30 1 1 0.89 1
2075 0.22 7 28.82 1 36 0.88 1
1598 4.98 11 22.89 1 1 0.87 1
1963 1.82 13 29.96 1 8 0.87 0
933 4.16 9 20.30 1 13 0.86 1
1967 3.64 11 33.72 3 8 0.86 1
1942 2.04 10 45.51 1 27 0.85 1
3 0.30 14 23.06 1 16 0.85 1
1523 1.06 13 8.32 1 1 0.85 0
1662 0.27 12 16.43 1 45 0.84 1
278 2.40 16 26.40 1 21 0.84 1
2309 3.10 18 24.68 1 7 0.84 1
1779 4.59 15 24.13 1 33 0.84 1
1543 0.42 13 11.30 1 5 0.84 1
1157 5.79 13 21.53 2 38 0.83 1
1953 5.19 11 17.07 4 23 0.83 1
上位20名中の実際の離脱者数: 18人 / 20人
リスク上位20名の中に実際の離脱者が18人と多く含まれていることより、モデルが実務で役立つことを意味しています。
各会員の特徴(視聴時間が少ない、視聴減少率が高いなど)を見ることで、個別の引き留め施策のヒントも得られます。
たとえば視聴減少率が高い会員にはおすすめコンテンツの提案を、問い合わせ回数が多い会員にはカスタマーサポートの強化を、といった個別対応が考えられます。
交差検証でモデルの安定性を確認する
Pipeline を使って前処理からモデル構築までを一括実行し、5分割交差検証でモデルの安定性を評価します。
ロジスティック回帰とランダムフォレストの2モデルを比較します。
以下、コードです。
from sklearn.pipeline import Pipeline
# パイプライン: 標準化 → ロジスティック回帰
pipe_lr = Pipeline([
('scaler', StandardScaler()),
('clf', LogisticRegression(
random_state=42,
max_iter=1000
)
)
])
# パイプライン: ランダムフォレスト(標準化不要)
pipe_rf = Pipeline([
('clf', RandomForestClassifier(
n_estimators=200, # 決定木の本数
max_depth=10, # 木の最大深さ
random_state=42 # 乱数シード(再現性)
)
)
])
# 交差検証で比較(5分割、指標はAUC)
print("【5分割交差検証の結果(AUC)】")
for name, pipe in [
('ロジスティック回帰', pipe_lr), # 線形モデル
('ランダムフォレスト', pipe_rf) # アンサンブルモデル
]:
scores = cross_val_score(
pipe,
X, y, # データ一式
cv=5, # 5-fold CV
scoring='roc_auc' # AUCで評価
)
# 平均と標準偏差を表示
print(
f" {name}: "
f"AUC = {scores.mean():.3f} ± {scores.std():.3f}"
)
以下、実行結果です。
【5分割交差検証の結果(AUC)】 ロジスティック回帰: AUC = 0.732 ± 0.014 ランダムフォレスト: AUC = 0.789 ± 0.015
交差検証により、データの分割方法に依存しない安定的な評価が得られます。
AUCの平均値が高く、標準偏差が小さいモデルほど信頼性が高いと判断できます。
Pipeline を使うことで、新しいデータに対しても前処理→予測を一貫して実行でき、実運用に適した形になっています。
まとめ
今回の後編では、ロジスティック回帰に加えて 決定木・ランダムフォレストを構築し、ROC曲線とAUCで3モデルを横断比較しました。
結果として、ランダムフォレストが最も高いAUCを示し、「離脱者に高いスコア、継続者に低いスコア」を付ける順位付け能力が最も優れていることが確認できました。
また、分類モデルは「予測確率」を出すだけでは不十分で、どの閾値で離脱と判定するかが実務成果を左右します。
閾値を下げれば再現率は上がる一方で適合率が下がり、閾値を上げればその逆になります。
さらに実務では、F1最大ではなく FP(不要なクーポン配布)とFN(離脱見逃し)の損失を金額で置き、期待コストが最小になる閾値を選ぶのが合理的です。
最後に、予測確率を使って「低・中・高リスク」に区分し、ハイリスク会員のリスト化まで行いました。
これにより「全員に同じ施策」ではなく、リスクに応じて介入強度を変える運用が可能になります。
加えて、交差検証によりモデルの安定性も確認し、運用に耐える形(Pipelineで前処理→予測を一貫)まで整えました。
実務で次に行うべきは……
- (1)クーポン単価・会員損失額などの前提を明確にして閾値を確定
- (2)上位◯%への段階的施策(強介入/軽介入)を設計
- (3)施策後の離脱率・LTV・利益で効果検証して閾値と施策を更新
……というサイクルです。
モデルは「当てる」ためではなく、意思決定を最適化して成果を出すために使う、この視点が最も重要です。