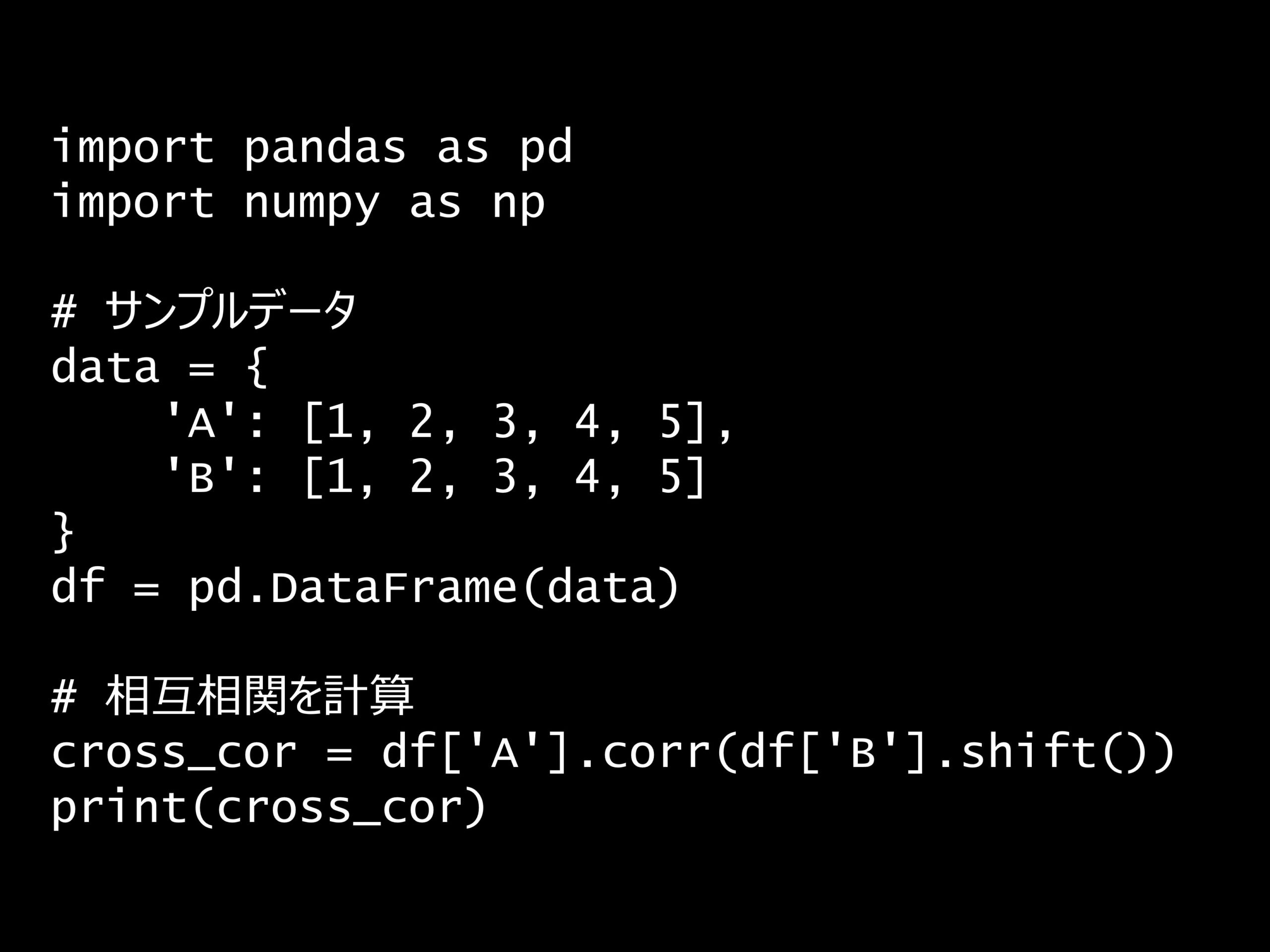
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd import numpy as np # サンプルデータ data = { '...
機械学習の世界では、データの前処理がモデルの精度や性能に大きな影響を与えます。 その中でも、特徴量スケーリング(Feature Scaling)は非常に重要なステップです。 特徴量スケーリングとは、データの範囲や分布を統...
データ分析を始める際に、データフレーム(DataFrame)のメタ情報を確認することは非常に重要です。 メタ情報とは、データそのものではなく、データに関する情報、例えば各列のデータ型、欠損値の数、基本統計量などを指します...
時系列の予測モデリングは、未来のデータを正確に予測するために不可欠な技術です。 しかし、このプロセスには注意が必要です。 なぜなら、データリークという問題が存在するからです。 データリークは、テストデータを不正に使用する...
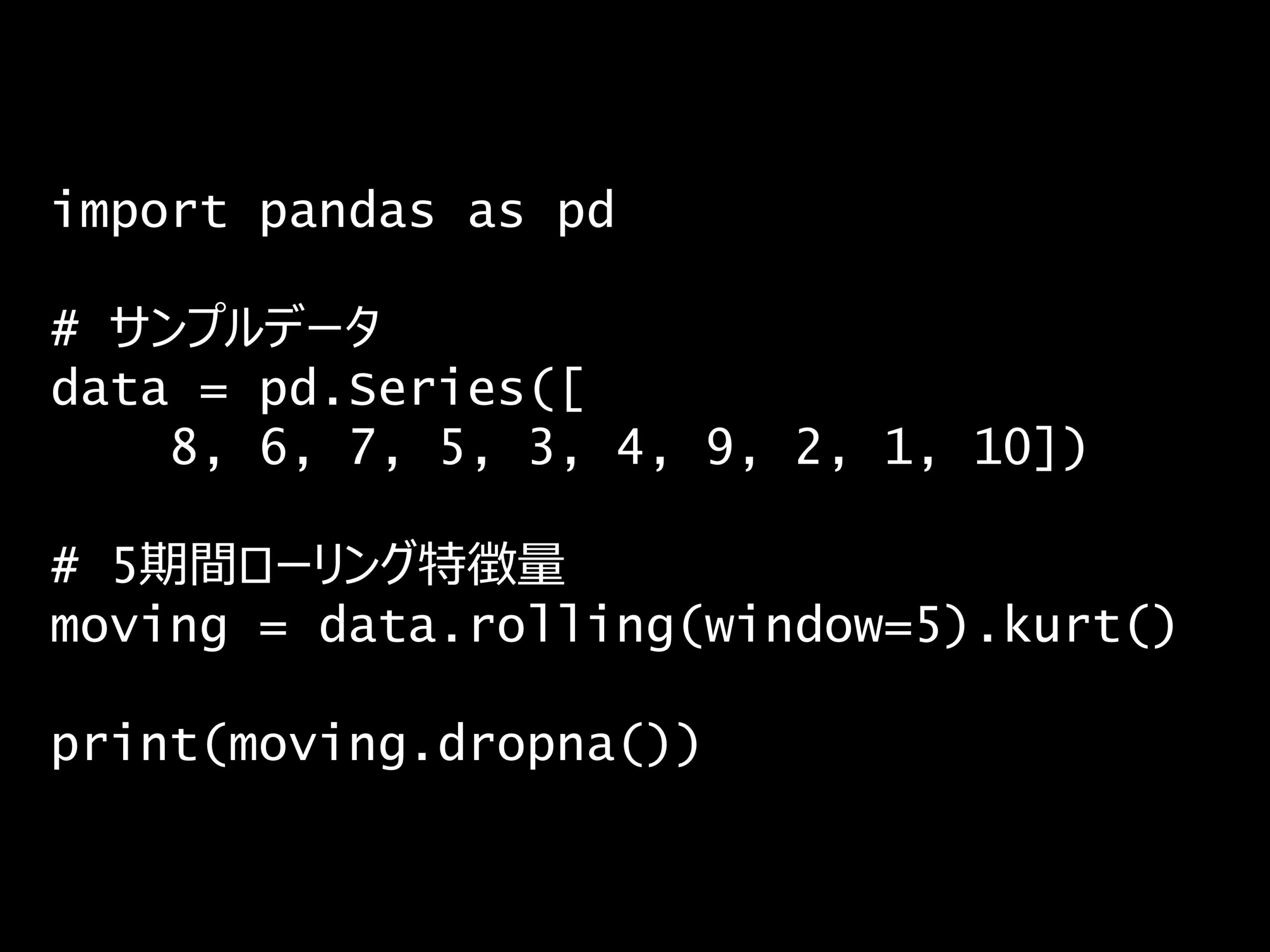
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd # サンプルデータ data = pd.Series([ 8, 6, 7, ...
データ分析の世界に足を踏み入れると、さまざまなグラフや図表に出会います。 その中でも、特に便利でよく使われるものの一つが「ボックスプロット(Boxplot)」です。 ボックスプロットは、データの分布を視覚的に簡単に理解で...
データ分析の第一歩は、必要なデータを効率的に抽出することから始まります。 PythonのPandasライブラリは、データのフィルタリングや特定の列の選択を簡単に行うための強力なツールです。 今回は、Pandasを使用して...
前回の記事では、因果グラフであるDAGを、Pythonのsemopyライブラリを使い構造方程式モデリング(SEM)する方法についてお話ししました。 Pythonで実践するグラフ因果推論入門第2回:構造方程式モデリングの基...
前回のブログでは、以下の確率分布の基礎から離散分布のビジネス応用について解説しました。 離散一様分布 二項分布 ポアソン分布 幾何分布 負の二項分布 超幾何分布 それぞれの分布について、定義、確率関数、期待値と分散、そし...
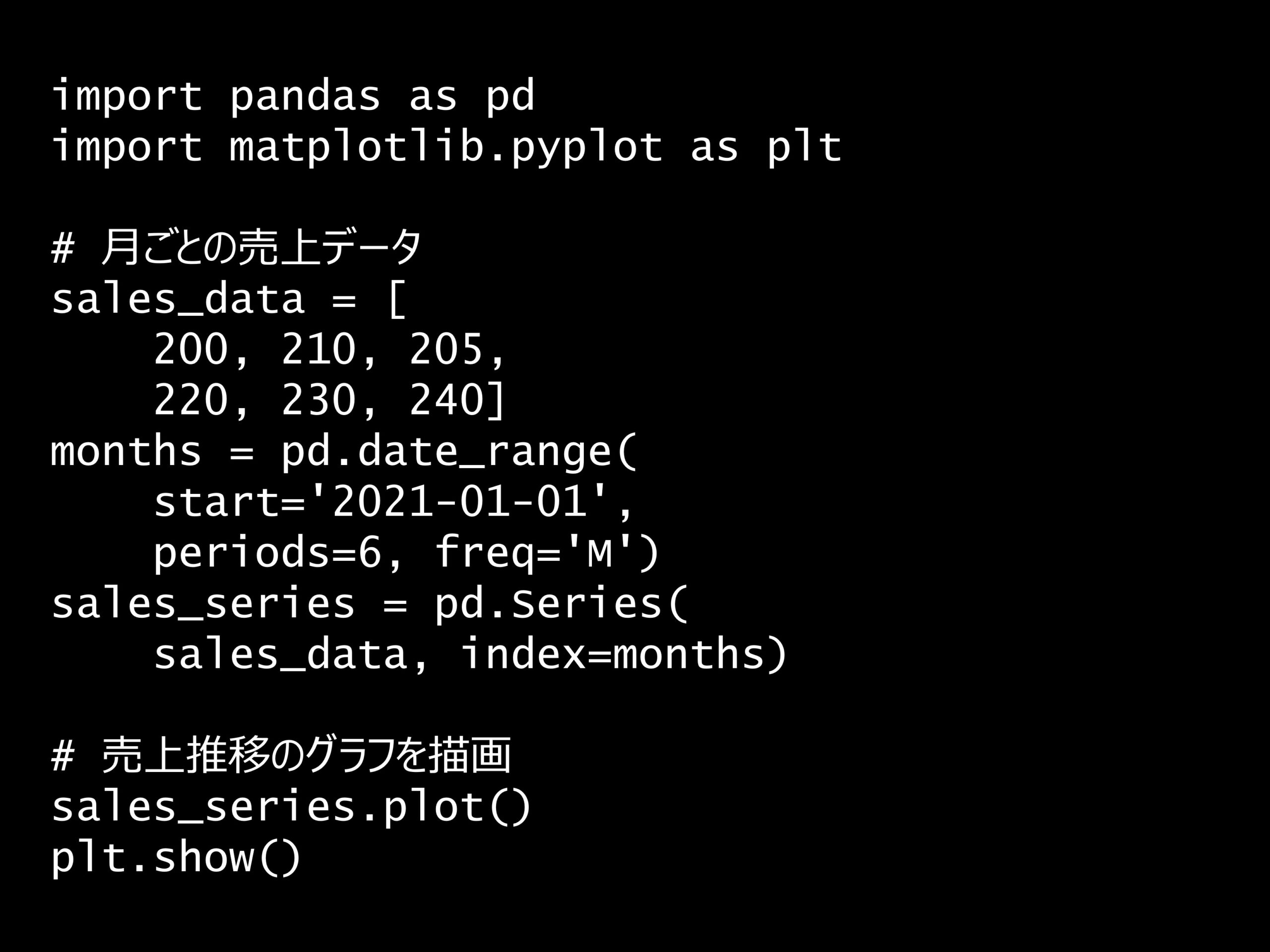
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd import matplotlib.pyplot as plt # 月ごとの売上データ...
機械学習やデータ分析において、カテゴリカルデータの取り扱いは非常に重要です。 カテゴリカルデータは数値データとは異なり、そのままでは多くの機械学習アルゴリズムに適用できません。 そのため、カテゴリカルデータを数値に変換す...
確率分布は、データ分析や統計学の基礎を成す重要な概念です。 ビジネスの世界においても、確率分布を理解し適用することで、さまざまな意思決定や予測が可能になります。 今回は、確率分布の基礎からビジネス応用に至るまでを簡単に解...
今回のブログシリーズ『Pythonで実践するグラフ因果推論入門』の第2回では、「構造方程式モデリングの基礎(semopyを使ったSEM)」に焦点を当てています。 このシリーズの第1回では、因果グラフモデルの概念を紹介し、...
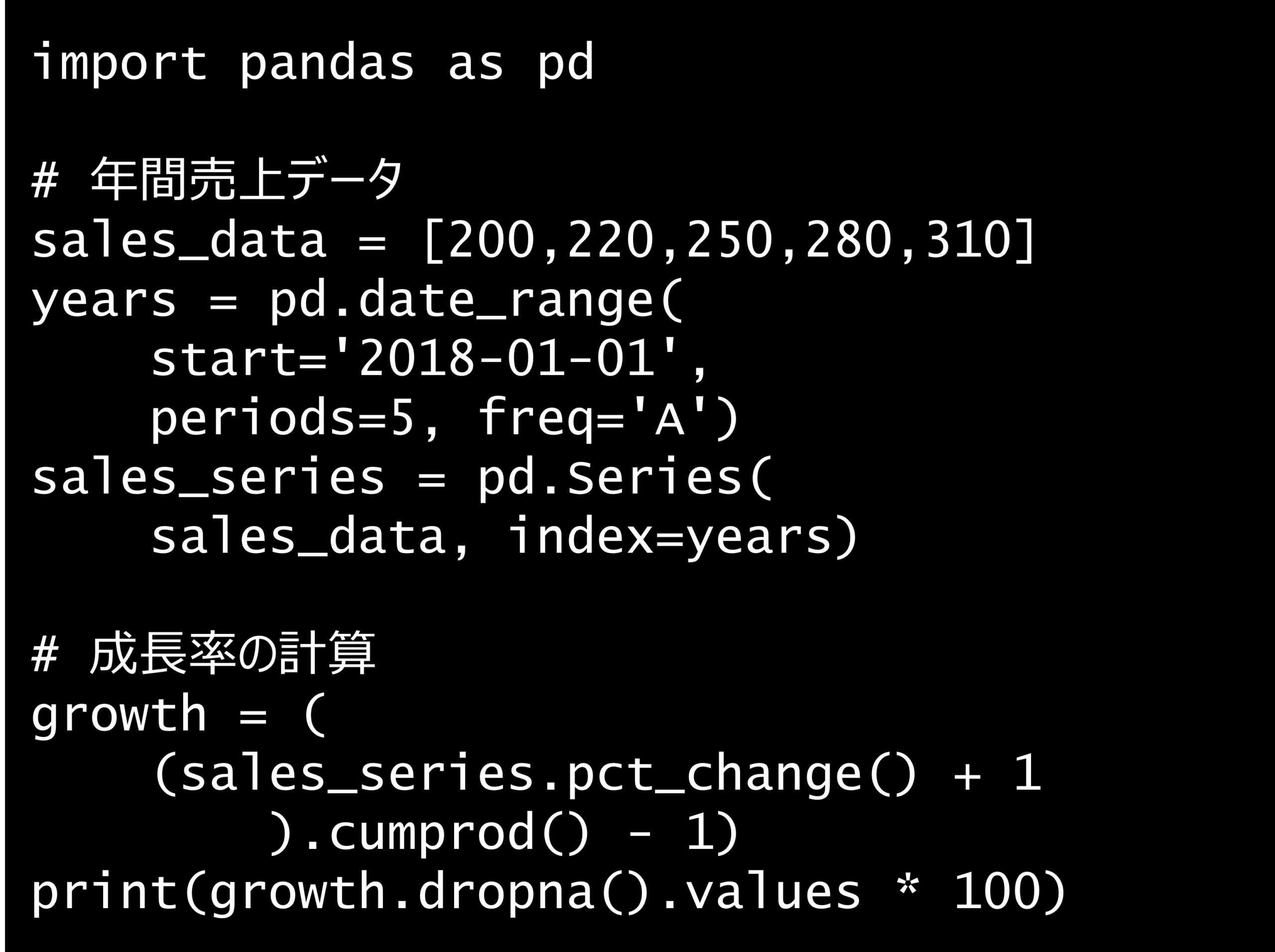
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd # 年間売上データ sales_data = [200,220,250,28...
機械学習モデルの開発において、モデルの性能を適切に評価することは非常に重要です。 評価指標は、モデルの予測性能を定量的に測定し、モデルの選択、比較、改善に役立ちます。 しかし、多様な評価指標の中から、どの指標を使うべきか...
因果推論は、因果関係を理解し、その影響を予測するための重要な分析手法です。 特にDAG(有向非巡回グラフ)は、複雑な因果関係を視覚化し、交絡因子やバックドア基準を特定するために重要です。 今回は、PythonのCausa...