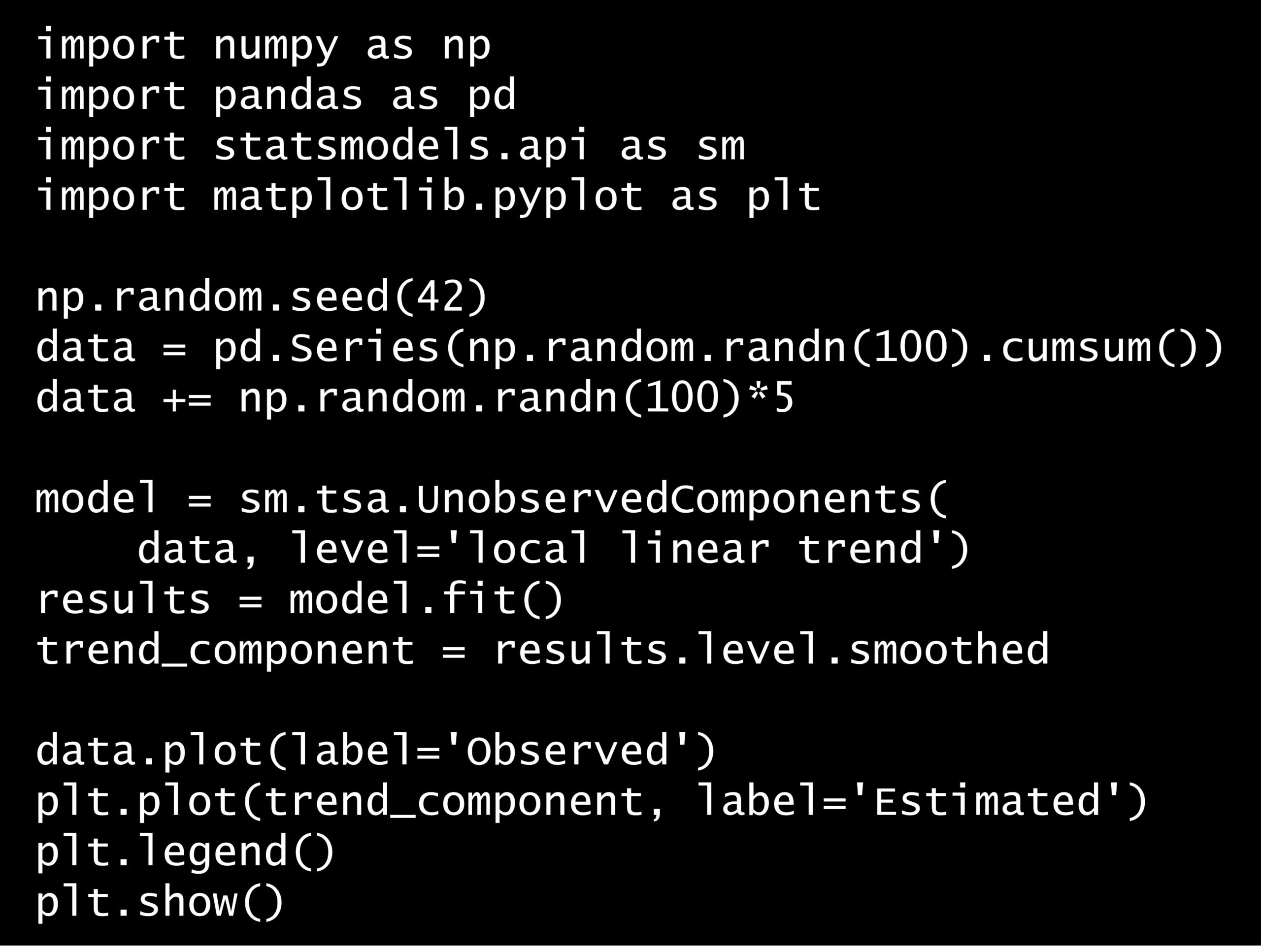
問題 答え 解説 次の Python コードで推定しているのは何ですか? Python コード: import numpy as np import pandas as pd import statsmodels.api...
近年、機械学習がビジネスの様々な分野で活用されており、データを使った意思決定の重要性はますます高まっています。 しかし、機械学習を成功させるためには、データをどのように準備するかが極めて重要です。その中でも「データ処理」...
計算結果をわかりやすく表示することは、ビジネスや教育、技術計算の場面で非常に重要です。特に複雑な数式や計算過程を伝えるとき、視覚的に見やすい形式で表示することが理解を助け、コミュニケーションを円滑にします。ここで役立つの...
近年、「データサイエンス」という言葉が当たり前のように使われるようになりつつあり、ビジネスの世界にも浸透しつつあります。 実際、多くの企業がデータ活用に取り組んでいますが、実は思わぬ落とし穴が待ち受けています。 驚くべき...
問題 答え 解説 次の Python コードの検定の目的は何ですか? Python コード: import pandas as pd import numpy as np import statsmodels.tsa.s...
データ分析って難しそう…… そう思っていませんでしょうか? 実は、あなたも知らないうちにデータ探偵の素質を持っているかもしれません。 日々の業務で直感的に行っている「状況把握」や「問題解決」、それ...
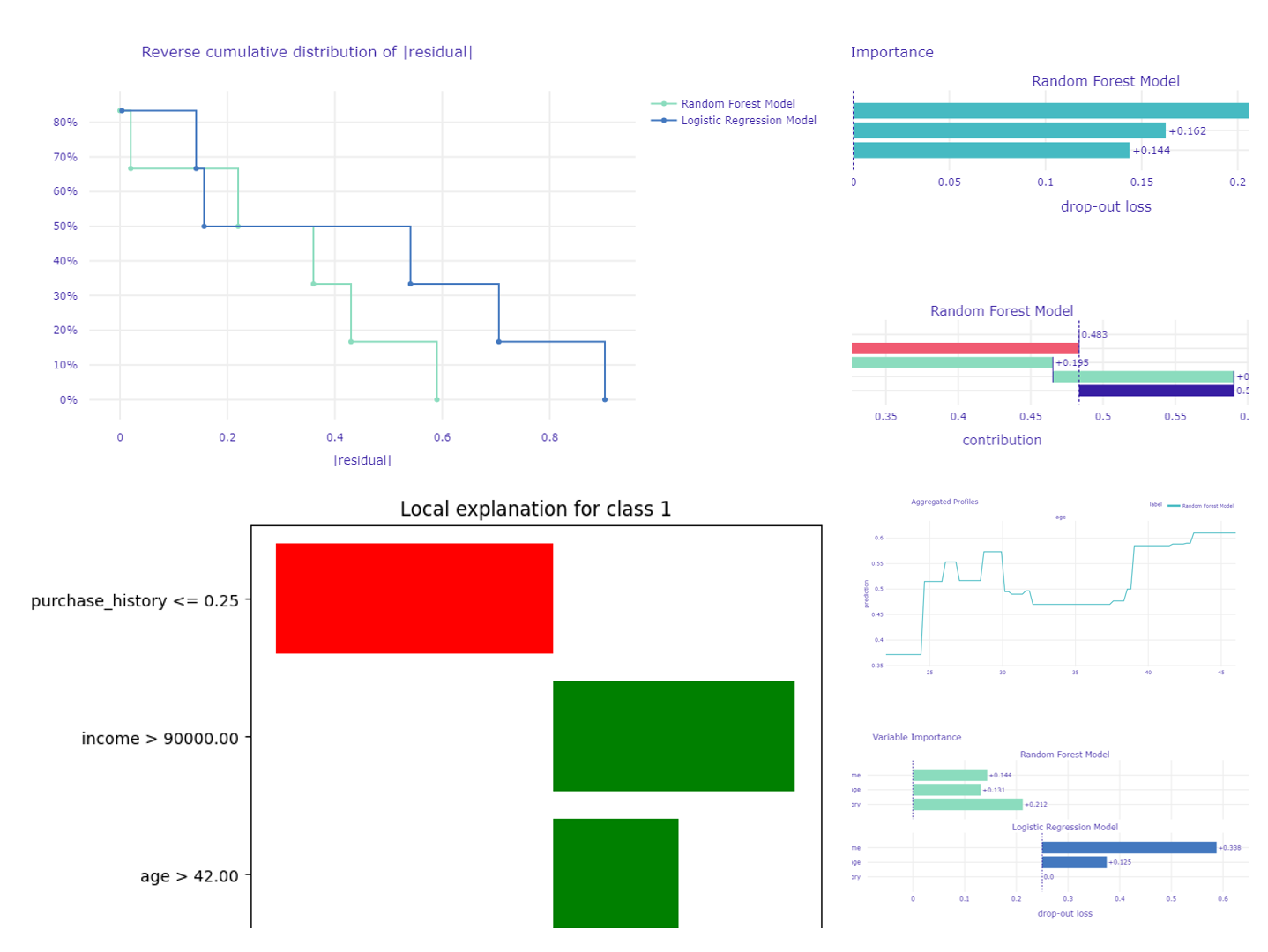
機械学習やAIが私たちの生活やビジネスにますます浸透している一方で、それらの技術がどのように判断や予測を行っているのかを理解することが求められています。 この理解が不十分だと、AIの予測や判断がブラックボックスのように感...
現代のビジネス環境では、データに基づく意思決定が求められています。 AI(人工知能)や機械学習を活用することで、企業は以前では考えられなかったような高度な予測や分析を行うことができるようになりました。 しかし、その一方で...
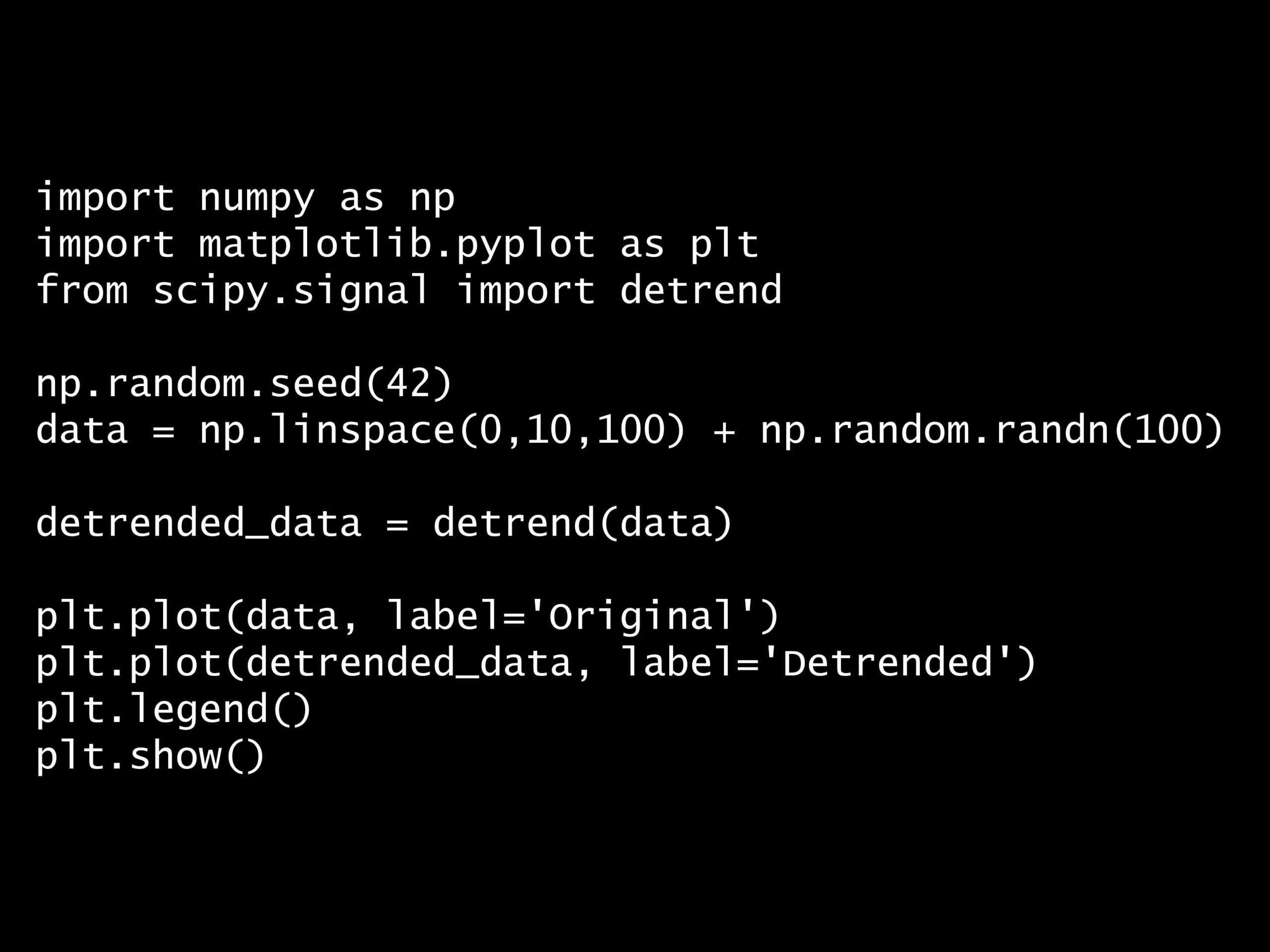
問題 答え 解説 次の Python コードは、どのトレンド除去手法を使用していますか? Python コード: import numpy as np import matplotlib.pyplot as plt fr...
ビジネスの成功は、未来を見通す力にかかっています。 需要予測は、その力の中核を担う重要なスキルです。 適切な需要予測により、企業は効率的な在庫管理、的確な生産計画、戦略的な経営判断を行うことができます。 しかし、多くの企...
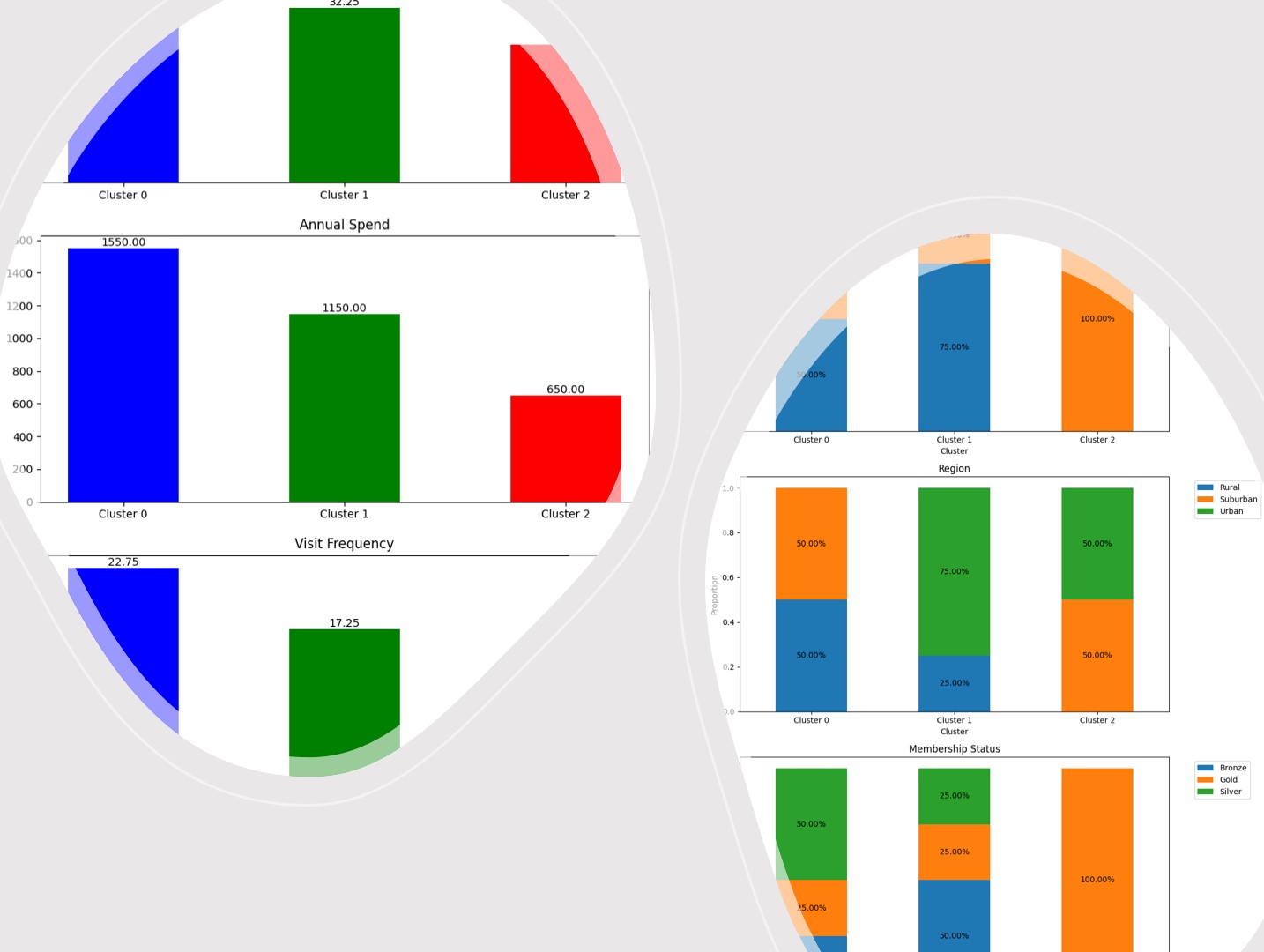
データ分析や機械学習の現場では、量的(数値)データと質的(カテゴリ)データが混在することが多々あります。 このようなデータを効果的にクラスタリングする方法として、k-プロトタイプ法が注目されています。 k-プロトタイプ法...
ビジネスにおけるデータ分析の重要性が増す中で、記述的分析(Descriptive Analytics)は、過去のデータから「何が起こったか」を理解するための基礎的なアプローチとして広く認識されています。 しかし、「なぜそ...
2024年8月27日の夜に、こっそりSchooでデータを武器にする営業のお話し(オンライン授業)をします。 タイトル: 第1回 打率の高い「営業リスト」を作るには? 開催日: 生放送 8 月 27 日(火) 20:00...
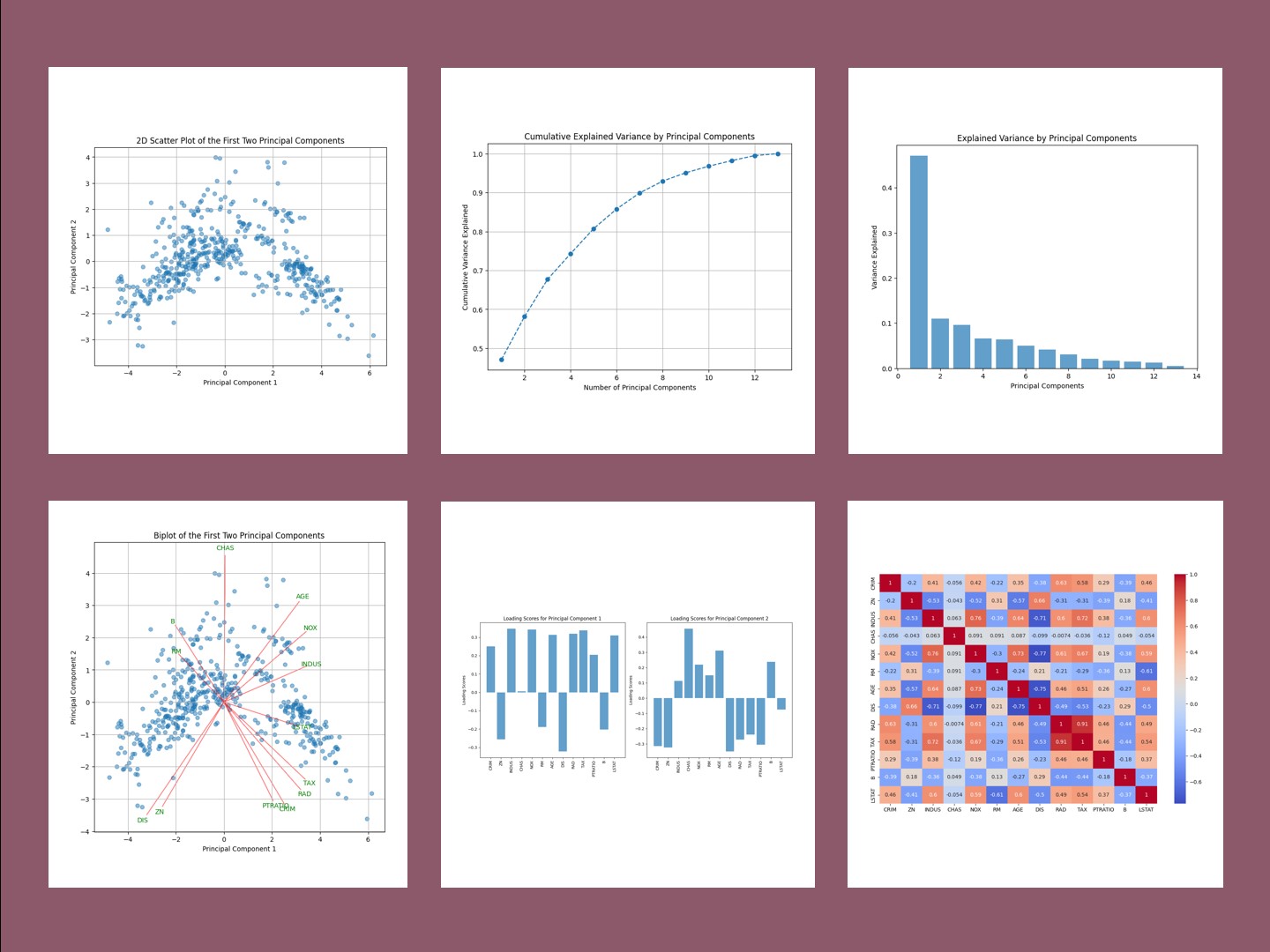
データサイエンスにおいて、高次元のデータセットを効果的に解析し理解することは、常に一つの大きな課題です。 主成分分析(PCA)は、この課題を解決するための強力なツールであり、多次元データの本質を捉え、より低次元の空間で表...
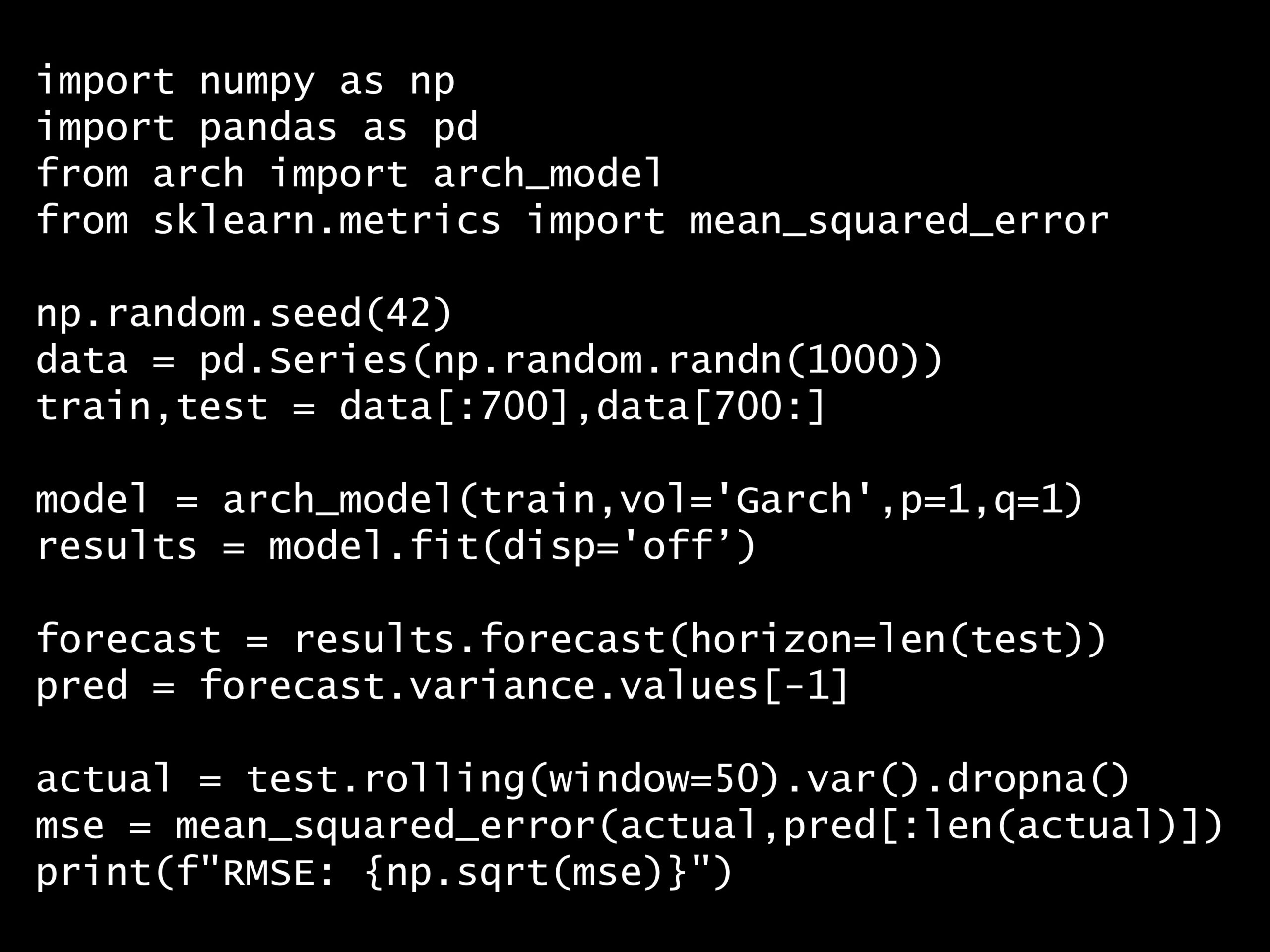
問題 答え 解説 次の Python コードは、どの評価方法を実施していますか? Python コード: import numpy as np import pandas as pd from arch import a...
データは21世紀の新しい資源と呼ばれています。しかし、生のデータだけでは、ビジネスの成功をもたらすことはできません。 そこで登場するのが記述的分析です。 この強力なツールは、膨大なデータの海から意味のあるパターンや傾向を...