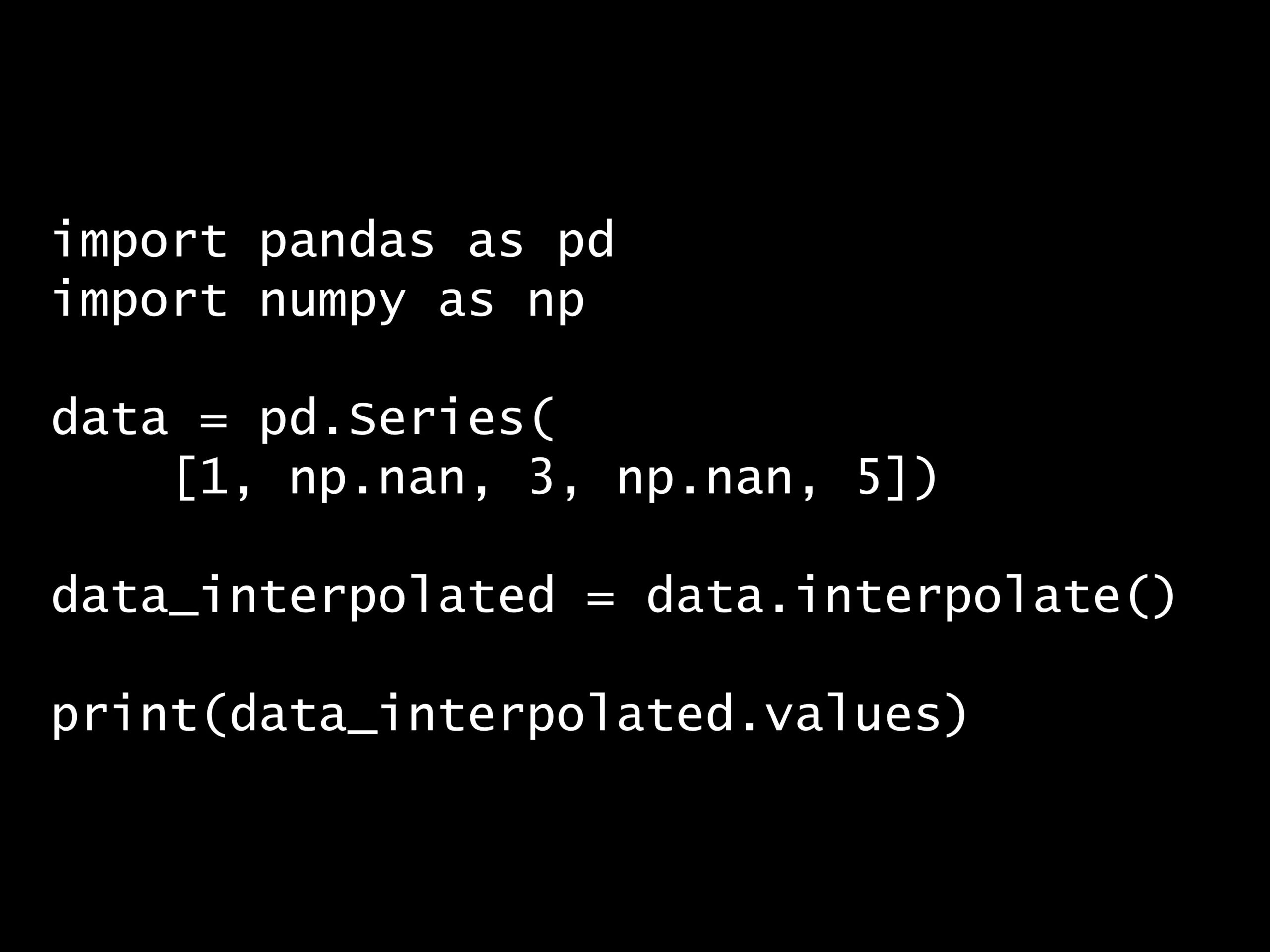
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd import numpy as np data = pd.Series([1...
ビジネスの現場では日々様々な意思決定が求められます。 例えば…… 新商品の開発は売上アップにつながるのか? 新しい広告施策は効果があるのか? 社員の研修プログラムは生産性を高めるのか? こうした問いに答えるためには、単な...
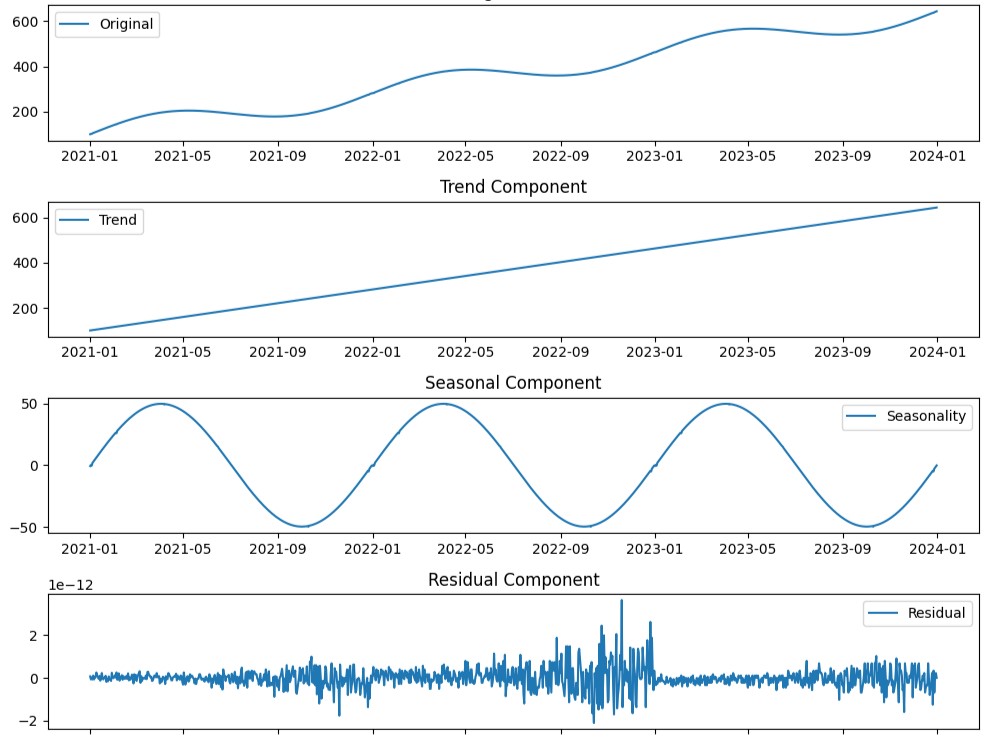
ビジネス環境は常に変化しています。 市場の動向、消費者行動の変化、季節的な要因、経済の波など、多くの要素が企業の成長と収益性に影響を与えています。 これらの変化を理解し、将来のトレンドを予測するためには、時系列分析が不可...
前回は、メタヒューリスティクスを中心に、非線形計画問題の大域的最適化に挑戦しました。 メタヒューリスティクスは、問題依存性が低く、大域的最適解の探索に適した手法ですが、その性能はアルゴリズムの選択とパラメータ設定に大きく...
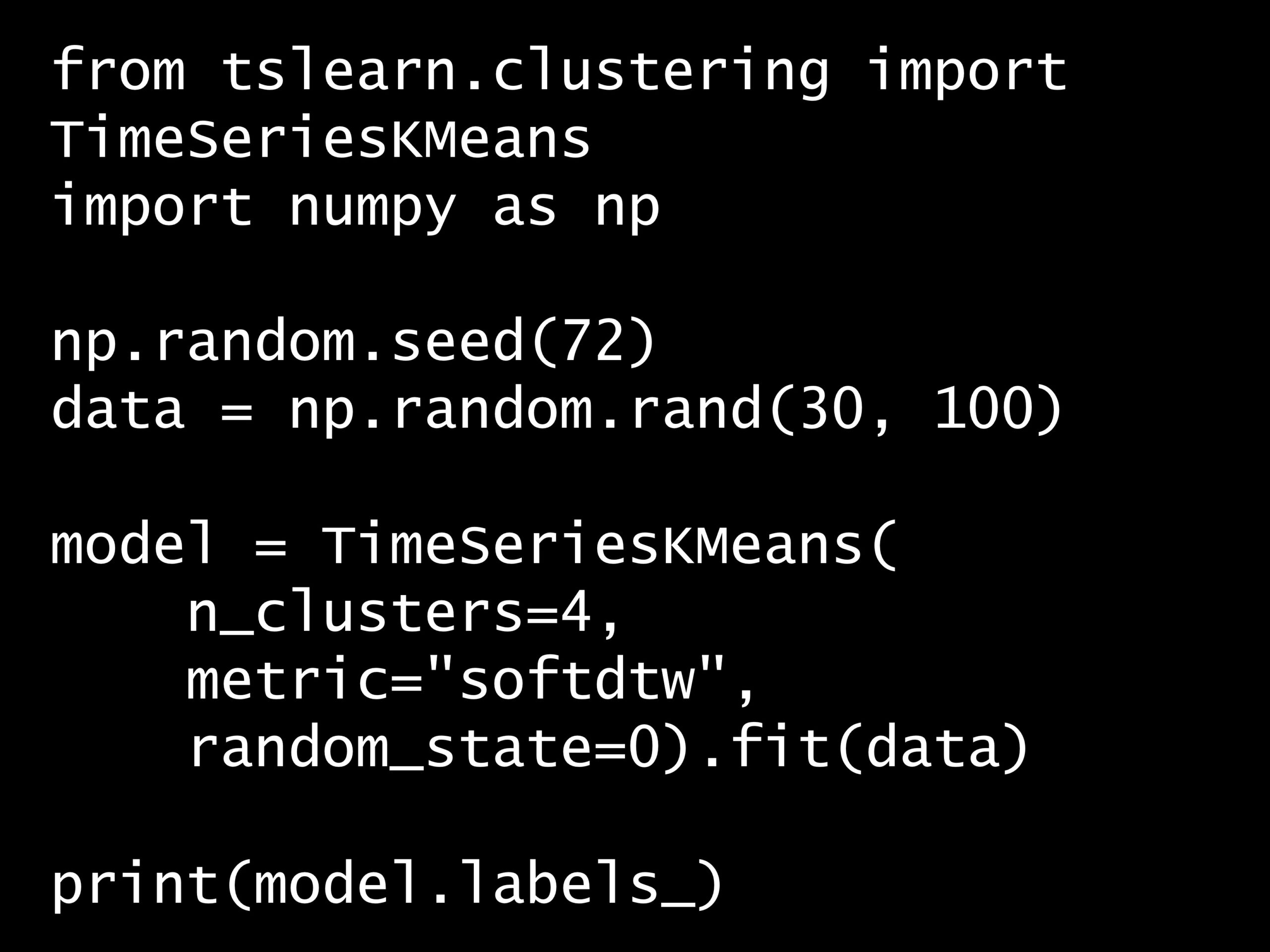
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: from tslearn.clustering import TimeSeriesKMeans import numpy as...
デジタル化が進む現代社会において、企業が抱える膨大なデータは、新たなビジネスチャンスを探る貴重な資源となっています。しかし、そのデータを如何に活用するかは、多くのビジネスリーダーにとって大きな課題です。 ここで重要となる...
Pandasは、Pythonでデータ分析を行う際に広く使用されるオープンソースのライブラリです。 データサイエンスや機械学習の分野で必須のツールとされ、主にデータの前処理や探索的データ分析(EDA)に利用されます。 Pa...
前回は、非線形計画問題の基礎と、Pythonを使った定式化の方法について学びました。 非線形計画問題は、現実世界の様々な問題を数理的にモデル化するのに適していますが、その解法は一般に困難で、大域的最適解を求めることは容易...
ビジネスの意思決定に革命を起こす因果推論の力を、実践的に体験してみませんか? 企業が新たなマーケティング戦略を展開する際、医療専門家が治療法の効果を評価する時、または政策立案者が社会政策の成果を測る際に、単に「何が起こっ...
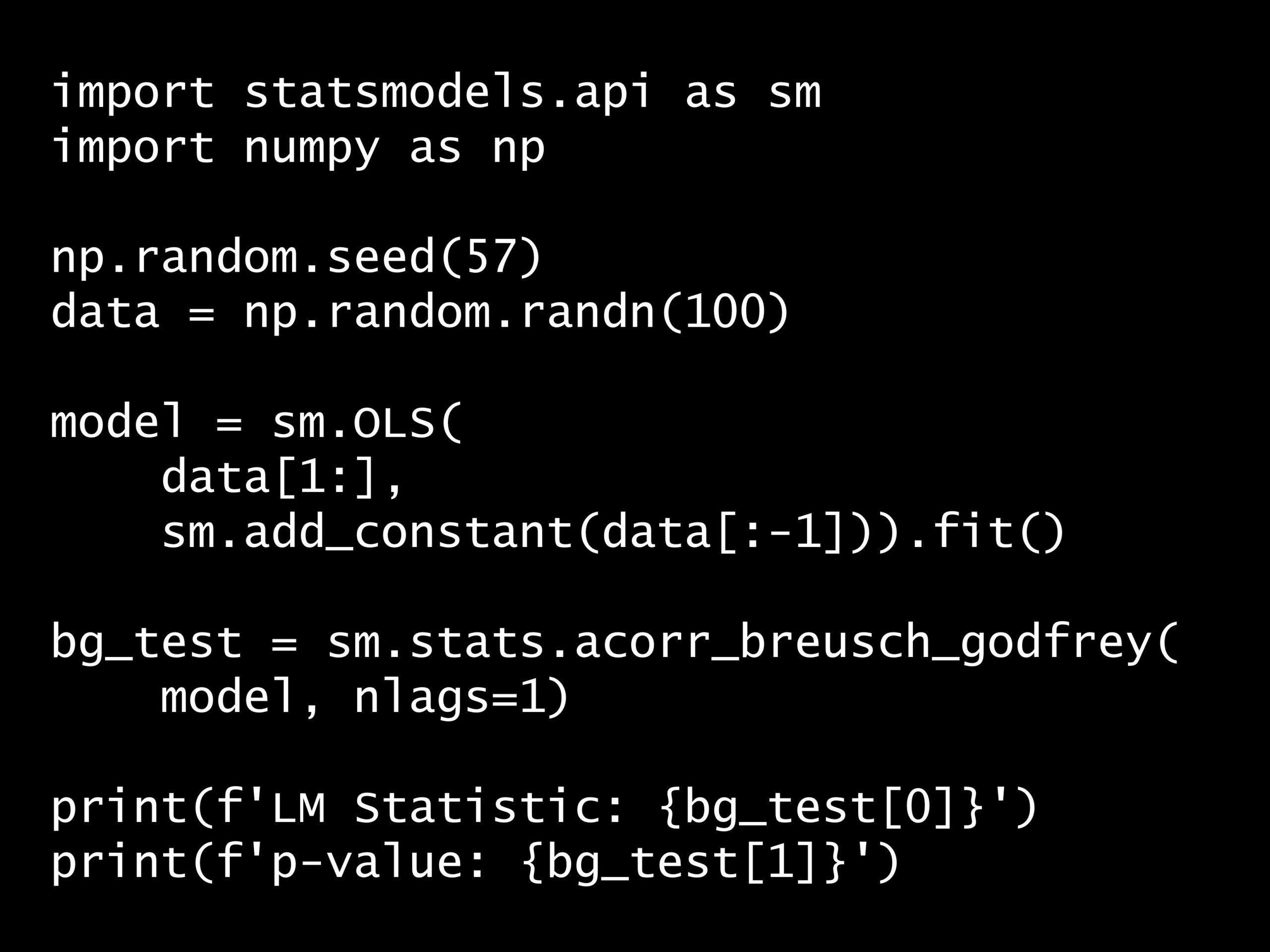
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import statsmodels.api as sm import numpy as np np.random.seed(...
機械学習モデルの性能に不満を感じたことはありませんか? どんなに時間をかけてモデルを調整しても、予測精度が思うように上がらないことがあります。そんな時、アンサンブル学習という手法が効果的です。 アンサンブル学習とは、複数...
アンサンブル学習は、複数の機械学習モデルを組み合わせることで、単一のモデルよりも高い予測精度を達成する手法です。 アンサンブル学習は、現実世界の様々な問題に適用され、機械学習コンペティションでも常に上位を占める手法として...
最適化問題は、工学、経済学、物理学など様々な分野で登場します。機械学習のハイパーパラメータチューニング、構造設計の最適化、リソース配分の最適化など、最適な解を求めることは、多くの問題解決に不可欠です。 最適化問題の中でも...
データが語る物語の奥深くには、単なる相関関係を超えた「因果関係」が隠されています。 企業が新たなマーケティング戦略を展開する際、医療専門家が治療法の効果を評価する時、または政策立案者が社会政策の成果を測る際に、単に「何が...
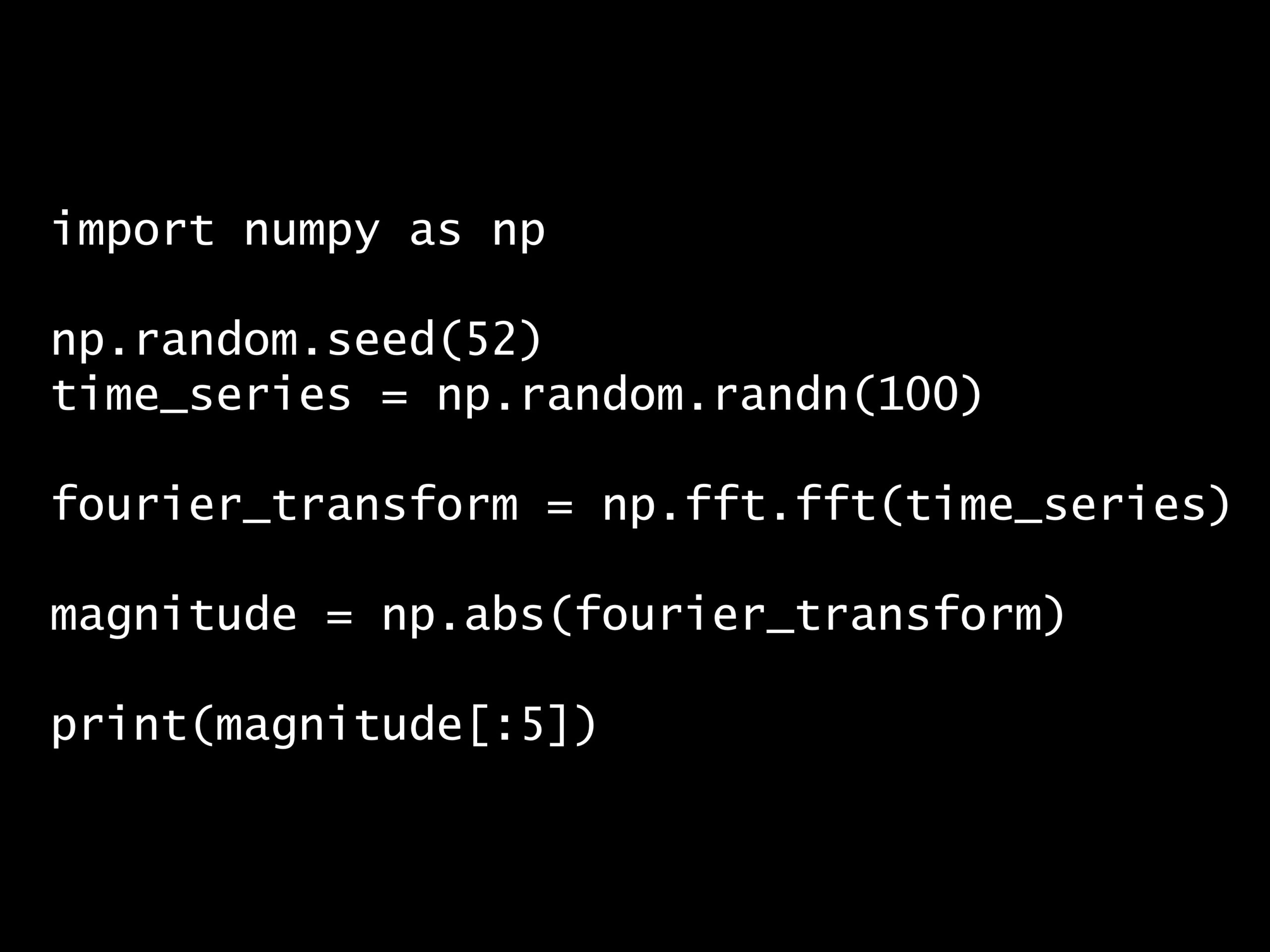
問題 答え 解説 次の Python コードの出力はどれでしょうか? Python コード: import numpy as np np.random.seed(52) time_series = np.random.r...
ビジネスにおけるリスク管理と効率化は、常に経営者の最優先事項の一つです。 異常検知技術の進化により、これらの課題への対処方法が根本から変わりつつあります。 今回は、異常検知がビジネスに与える影響に焦点を当てます。 統計的...