
データ分析で「可視化」は欠かせないステップです。
数値の羅列を見ても傾向はわかりにくいですが、グラフにすれば一目瞭然。
しかし、Pythonの定番ライブラリ matplotlib でキレイなグラフを作ろうとすると、設定項目が多くて大変ですよね。
そこで登場するのが seaborn(シーボーン)です。
seabornを使えば、たった数行のコードで「見せても恥ずかしくない」美しいグラフが作れます。
今回は、探索的データ分析(EDA)でよく使う6種類のグラフを紹介します。
seabornとは?
seaborn は、matplotlibをベースにした統計データ可視化ライブラリです。
「matplotlib のラッパー(包み込むもの)」とも呼ばれ、複雑な設定を隠蔽して、シンプルなコードで美しいグラフを描けるようにしてくれます。
matplotlibとseabornの違いを簡単に整理すると、以下のようになります。
| matplotlib | seaborn | |
|---|---|---|
| コード量 | 多い(細かい設定が必要) | 少ない(デフォルトで美しい) |
| デザイン | シンプル(自分で調整) | 洗練されている(最初から美しい) |
| 統計処理 | 自分で計算が必要 | 自動で計算してくれる |
| 学習コスト | 高い | 低い |
| 柔軟性 | 非常に高い |
「まずデータの傾向をサッと確認したい」という探索的データ分析(EDA)の場面では、seabornが圧倒的に便利です。
ライブラリのインストールとインポート
seabornを使うには、まずインストールが必要です。
以下のコマンドでインストールできます。
pip install seaborn
インストールが完了したら、ライブラリをインポートします。
以下のコードは、この記事全体で使用する準備コードです。
seabornは慣例として sns という名前でインポートします。
この名前は、seabornの由来である海外ドラマ「The West Wing」の登場人物「Samuel Norman Seaborn」のイニシャルから来ています。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import japanize_matplotlib # 日本語化 # seabornをインポート import seaborn as sns # seabornのスタイルを設定(グラフ全体の見た目が良くなる) sns.set_theme(style="whitegrid")
sns.set_theme() を実行するだけで、以降のグラフすべてが設定したスタイルの洗練されたデザインになります。
これがseabornの「デフォルトで美しい」という特徴です。
サンプルデータの準備
この記事では、2種類のサンプルデータを使います。
1つ目は、seabornに組み込まれている有名なデータセット「tips(チップ)」です。
レストランでの食事代とチップの関係を記録したデータで、可視化の練習に最適です。
以下、コードです。
# seaborn組み込みのサンプルデータを読み込む
tips = sns.load_dataset("tips")
print(f"データ件数: {len(tips)}件")
print(tips.head())
以下、実行結果です。
データ件数: 244件 total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
このデータセットは、244件のレストランデータです。各列(変数)の意味は以下の通りです。
| 列名 | 意味 | 型 |
|---|---|---|
| total_bill | 食事代(ドル) | 数値 |
| tip | チップ(ドル) | 数値 |
| sex | 支払者の性別 | カテゴリ |
| smoker | 喫煙者かどうか | カテゴリ |
| day | 曜日 | カテゴリ |
| time | 時間帯(Lunch/Dinner) | カテゴリ |
| size | 人数 |
このデータを使って、様々なグラフを描いていきましょう。
散布図:2つの数値の関係を見る
matplotlibとの比較
まず、散布図を描いてみましょう。
散布図は「2つの数値変数の関係」を視覚化するグラフです。
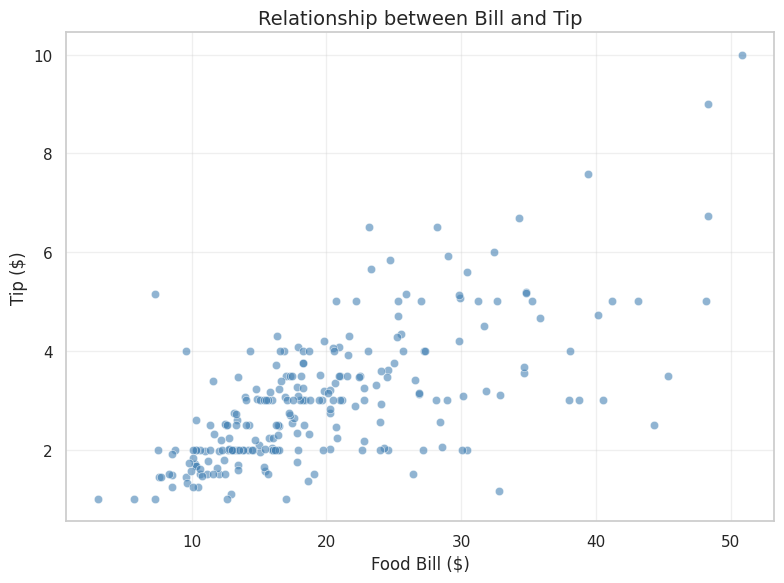
matplotlibで「見栄えの良い」散布図を作ろうとすると、以下のように多くのコードが必要です。
# matplotlib版:設定項目が多い
fig, ax = plt.subplots(figsize=(8, 6))
ax.scatter(
tips['total_bill'],
tips['tip'],
alpha=0.6,
c='steelblue',
edgecolors='white',
linewidth=0.5
)
ax.set_xlabel(
'Food Bill ($)',
fontsize=12
)
ax.set_ylabel(
'Tip ($)',
fontsize=12
)
ax.set_title(
'Relationship between Bill and Tip',
fontsize=14
)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
実行すると散布図が表示されますが、色や透明度、ラベルのフォントサイズなど、多くの設定を自分で書く必要がありました。
seabornなら3行で美しい散布図
同じグラフをseabornで描くと、驚くほどシンプルになります。
# seaborn版:たった3行!
sns.scatterplot(data=tips, x="total_bill", y="tip")
plt.title("Relationship between Bill and Tip")
plt.show()
実行すると、美しい散布図が表示されます。
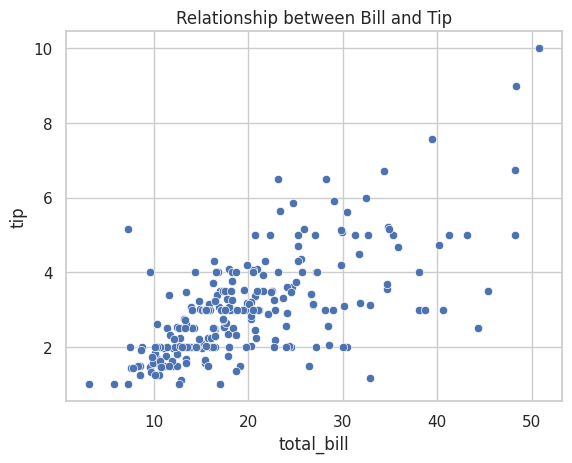
コードは3行だけなのに、適切な色、ラベル、グリッドが自動的に設定されています。
これがseabornの魅力です。
カテゴリで色分けする
seabornの真価は、カテゴリ変数による色分けが簡単にできることです。
「性別ごとに色を変えたい」という要望も、引数を1つ追加するだけで実現できます。
# 性別で色分け(hue引数を追加するだけ)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="sex")
plt.title("Bill vs Tip by Gender")
plt.show()
実行すると、男性と女性で異なる色で点がプロットされ、凡例も自動的に追加されます。
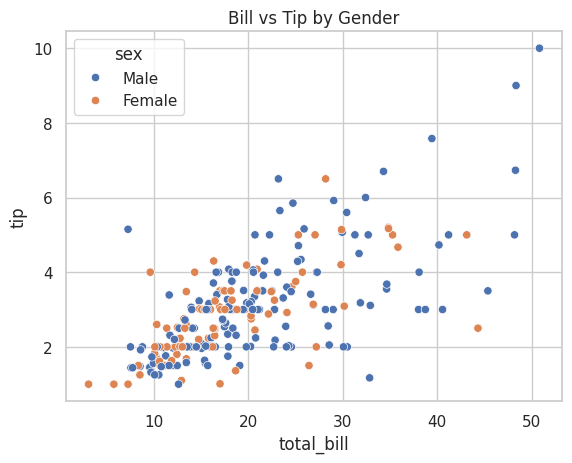
hue(ヒュー)は「色相」という意味で、カテゴリごとに色を変える引数です。
この1つの引数を追加するだけで、matplotlibなら10行以上かかる処理が完了します。
さらに情報を追加する
点の大きさや形でも情報を表現できます。
sns.scatterplot(
data=tips, x="total_bill", y="tip",
hue="sex", # 色=性別
size="size", # 大きさ=人数
style="smoker", # 形=喫煙者かどうか
)
plt.title("Bill vs Tip (with multiple dimensions)")
plt.show()
実行すると、1つのグラフに4つの情報(食事代、チップ、性別、人数、喫煙有無)が表現されます。
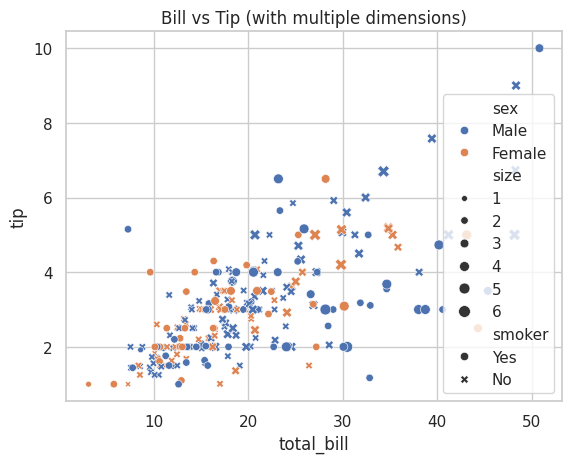
複数の変数の関係を一度に把握できるのは、データ分析において非常に価値があります。
棒グラフ:カテゴリごとの比較
基本的な棒グラフ
棒グラフは「カテゴリごとの値を比較する」ためのグラフです。
seabornでは barplot() を使います。以下のコードでは、曜日ごとの平均チップ額を比較します。
# 曜日ごとの平均チップ額
sns.barplot(data=tips, x="day", y="tip")
plt.title("Average Tip by Day")
plt.show()
実行すると、曜日ごとの棒グラフが表示されます。
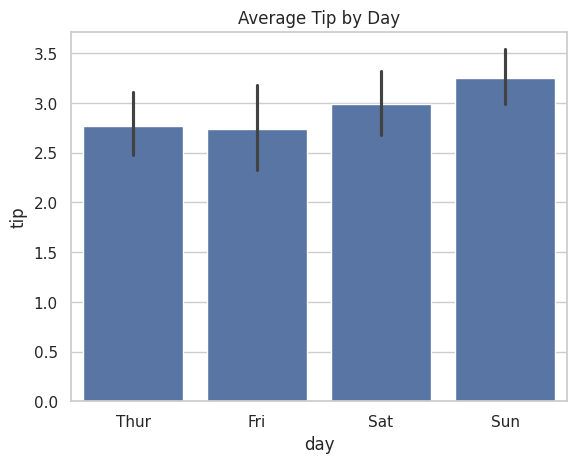
注目すべき点は、各棒の上に黒い線(エラーバー)があることです。
これは「95%信頼区間」を表しており、データのばらつきを視覚的に示しています。
matplotlibでこれを実装するには、統計計算を自分で行う必要がありますが、seabornは自動で計算してくれます。
カテゴリで色分けする
棒グラフでも hue 引数を使って、さらに細かい比較ができます。
# 曜日ごと、さらに性別で分けて比較
sns.barplot(data=tips, x="day", y="tip", hue="sex")
plt.title("Average Tip by Day and Gender")
plt.show()
実行すると、各曜日の棒が性別で2本ずつ並んだグラフが表示されます。
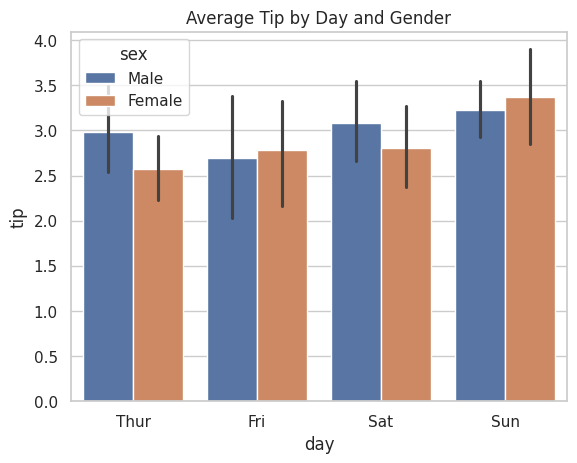
「金曜日は男女差が小さい」といった傾向が一目でわかります。
比較分析やレポート作成で非常に役立つグラフです。
水平棒グラフ
カテゴリ名が長い場合は、水平棒グラフの方が見やすくなります。
# 水平棒グラフ(x と y を入れ替えるだけ)
sns.barplot(data=tips, x="tip", y="day", hue="sex")
plt.title("Average Tip by Day and Gender")
plt.show()
実行すると、横向きの棒グラフが表示されます。
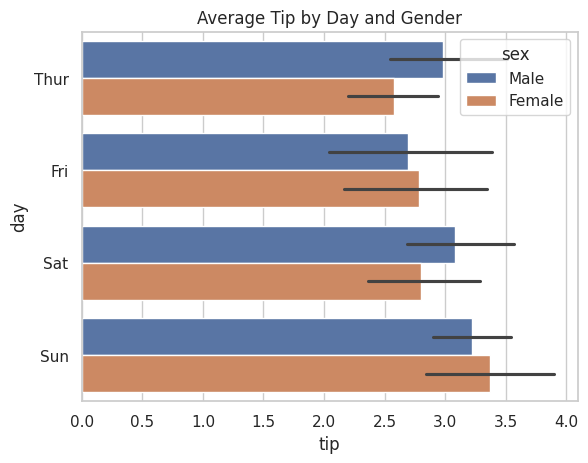
x と y を入れ替えるだけで水平になるのは、直感的でわかりやすいですね。
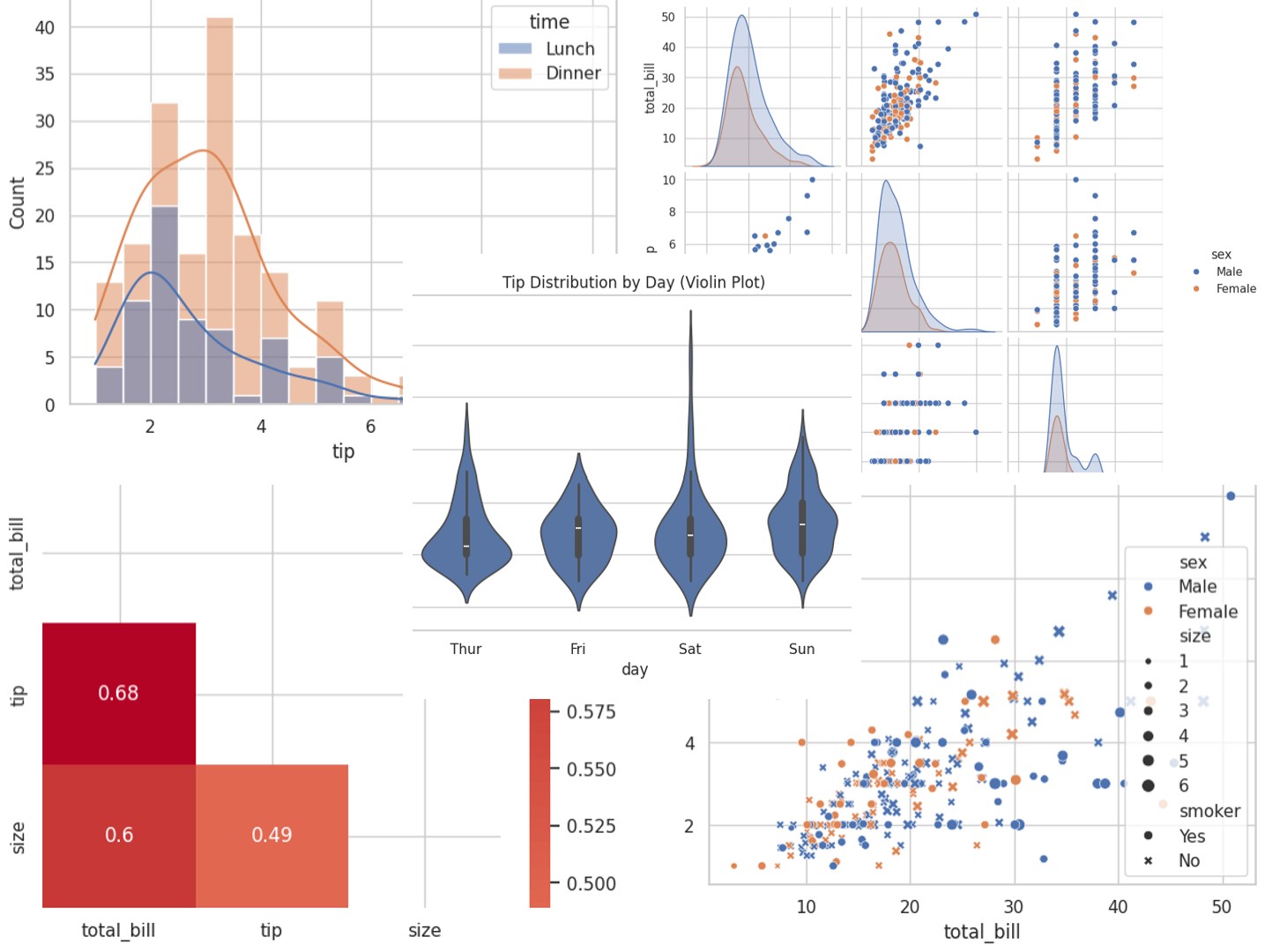
ヒストグラム:データの分布を見る
基本的なヒストグラム
ヒストグラムは「データがどのように分布しているか」を視覚化するグラフです。
「チップは何ドルくらいが多いのか」「極端に高いチップはあるのか」といった疑問に答えてくれます。
# チップの分布を表示
sns.histplot(data=tips, x="tip")
plt.title("Distribution of Tips")
plt.show()
実行すると、チップ額の分布が棒グラフ形式で表示されます。
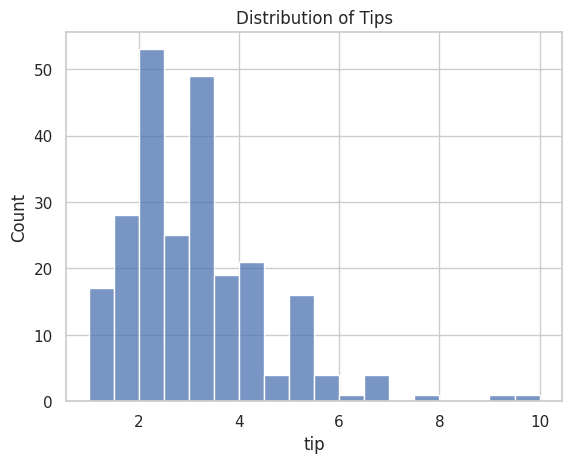
2〜3ドルのチップが最も多く、5ドルを超えるチップは少ないことがわかります。
データの「形」を理解することは、分析の第一歩です。
KDE(カーネル密度推定)を重ねる
ヒストグラムに滑らかな曲線(KDE)を重ねると、分布の形がより明確になります。
KDE(Kernel Density Estimation)は、データの確率密度関数を推定する手法です。
難しく聞こえますが、要は「滑らかにした分布の形」と思ってください。
以下、コードです。
# KDE曲線を追加
sns.histplot(data=tips, x="tip", kde=True)
plt.title("Distribution of Tips with KDE")
plt.show()
実行すると、棒グラフの上に滑らかな曲線が重なります。
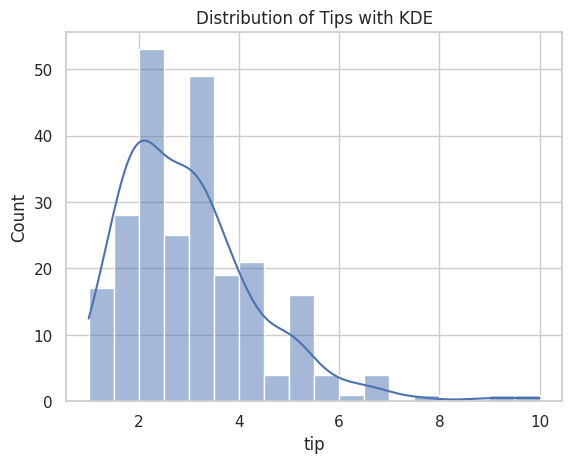
kde=True を追加するだけで、この曲線が描かれます。
レポートで「データは右に裾が長い分布(右に偏った分布)」と説明する際の根拠になります。
カテゴリで色分けした分布
複数のカテゴリの分布を重ねて比較することもできます。
# 昼食と夕食でチップの分布を比較
sns.histplot(data=tips, x="tip", hue="time", kde=True)
plt.title("Tip Distribution: Lunch vs Dinner")
plt.show()
実行すると、昼食(Lunch)と夕食(Dinner)の分布が色分けされて重なって表示されます。
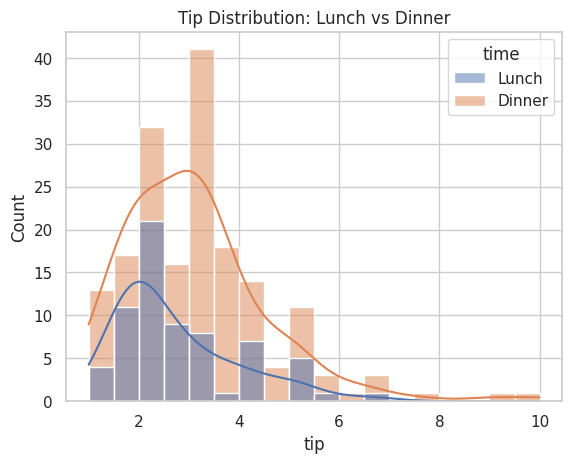
箱ひげ図:分布と外れ値を一目で把握
箱ひげ図とは?
箱ひげ図(ボックスプロット) は、データの分布を5つの要約統計量で表現するグラフです。
ヒストグラムよりコンパクトで、複数のカテゴリを並べて比較するのに適しています。
箱ひげ図の読み方を簡単に説明すると、箱の中央の線が「中央値(メディアン)」、箱の上下の端が「第1四分位数」と「第3四分位数」、ひげの端が「最小値・最大値(外れ値を除く)」、点が「外れ値」を表します。
基本的な箱ひげ図
曜日ごとのチップの分布を箱ひげ図で比較してみましょう。
# 曜日ごとのチップの分布を箱ひげ図で表示
sns.boxplot(data=tips, x="day", y="tip")
plt.title("Tip Distribution by Day")
plt.show()
実行すると、4つの曜日それぞれの箱ひげ図が並んで表示されます。
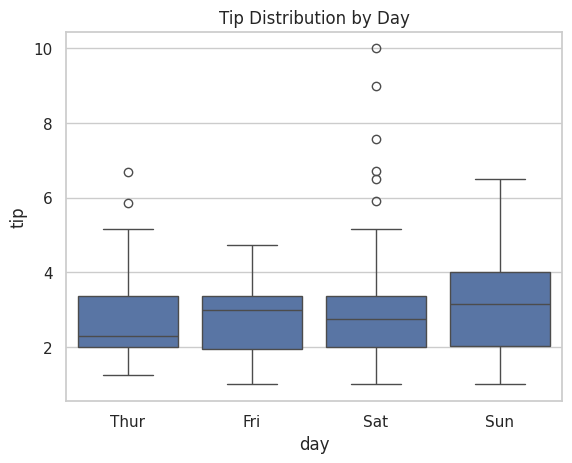
土曜日と日曜日は箱が大きく(ばらつきが大きい)、外れ値(点)も多いことがわかります。
週末は高額なチップを払う人がいる一方、低いチップの人もいるということです。
カテゴリで色分けする
箱ひげ図でも hue を使って、さらに細かい比較ができます。
# 曜日ごと、さらに時間帯で分けて比較
sns.boxplot(data=tips, x="day", y="tip", hue="time")
plt.title("Tip Distribution by Day and Time")
plt.show()
実行すると、各曜日に2つの箱(昼食と夕食)が並びます。
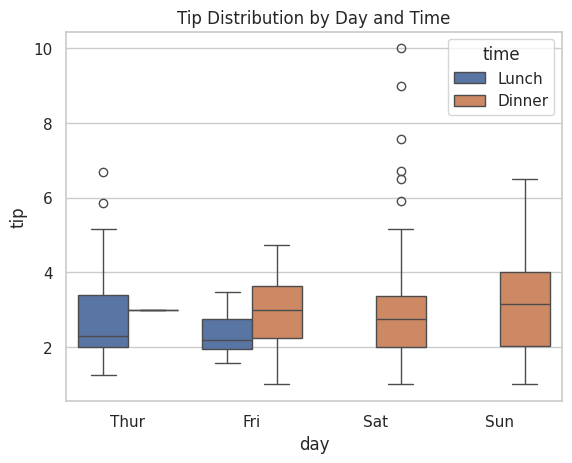
昼食より夕食の方がチップの中央値が高い傾向が見て取れます。
複数の条件でデータを比較する際に、箱ひげ図は非常に有効です。
バイオリンプロット:箱ひげ図の進化版
箱ひげ図の発展形として「バイオリンプロット」があります。
箱ひげ図の情報に加えて、分布の形状も表現できます。
# バイオリンプロット
sns.violinplot(data=tips, x="day", y="tip")
plt.title("Tip Distribution by Day (Violin Plot)")
plt.show()
実行すると、バイオリンのような形のグラフが表示されます。
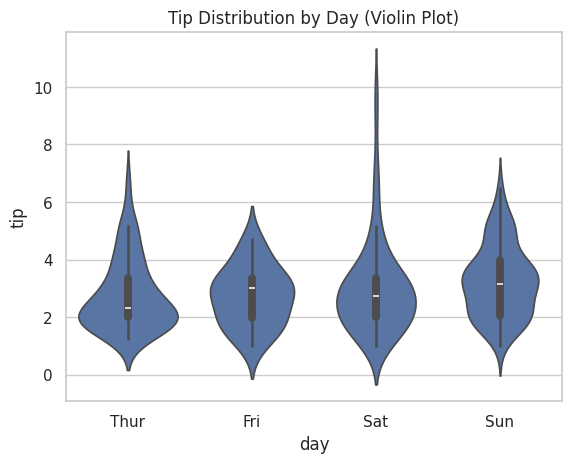
幅が広い部分はデータが集中していることを示します。
箱ひげ図では見えなかった「分布の形」がわかるため、より詳細な分析に使えます。
ヒートマップ:相関関係を可視化
相関係数とは?
相関係数 は、2つの変数がどの程度「一緒に動くか」を表す指標です。
値は -1 から 1 の範囲で、1に近いほど「一方が増えると他方も増える」関係が強く、-1に近いほど「一方が増えると他方は減る」関係が強いことを意味します。
0に近いと、関係がほとんどないことを示します。
相関行列の計算
まず、数値データの相関係数を計算します。
# 数値列だけを選択して相関行列を計算 numeric_cols = tips.select_dtypes(include=[np.number]) correlation = numeric_cols.corr() print(correlation)
実行すると、各数値列の間の相関係数が行列形式で表示されます。
total_bill tip size total_bill 1.000000 0.675734 0.598315 tip 0.675734 1.000000 0.489299 size 0.598315 0.489299 1.000000
しかし、数値の羅列では直感的に理解しにくいですよね。
ヒートマップで可視化
相関行列をヒートマップで可視化すると、関係性が一目瞭然になります。
# 相関係数をヒートマップで表示
sns.heatmap(
correlation,
annot=True, cmap="coolwarm", center=0
)
plt.title("Correlation Heatmap")
plt.show()
実行すると、相関係数が色で表現されたヒートマップが表示されます。
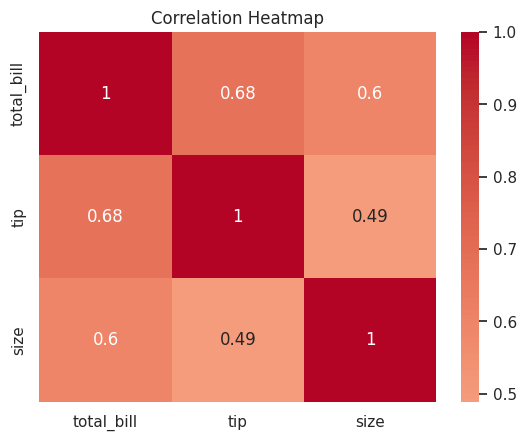
annot=True で各セルに数値を表示し、cmap="coolwarm" で青(負の相関)から赤(正の相関)のカラーマップを指定しています。
total_bill と tip の交点が赤く、相関係数0.68と高いことがわかります。これは「食事代が高いほどチップも高い傾向がある」ことを示しています。
より見やすいヒートマップ
対角線より下だけを表示するなど、さらに見やすくすることもできます。
# 下三角だけを表示(上三角は冗長なので隠す)
mask = np.triu(np.ones_like(correlation, dtype=bool))
sns.heatmap(
correlation,
mask=mask,
annot=True, cmap="coolwarm", center=0
)
plt.title("Correlation Heatmap (Lower Triangle)")
plt.show()
実行すると、対角線より上が隠れたヒートマップが表示されます。
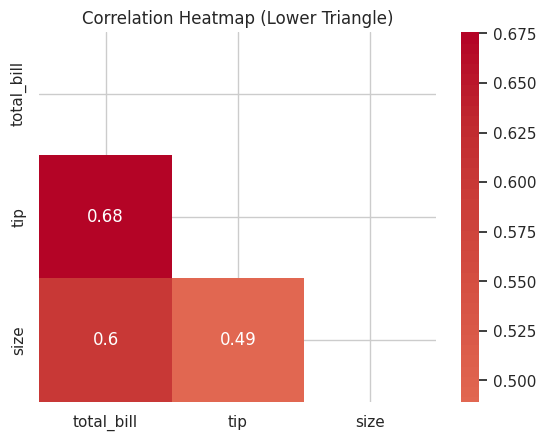
相関行列は対称なので、片側だけ表示すれば十分です。
レポートに載せる際は、このようにすっきりさせると見やすくなります。
ペアプロット:全体像を一気に把握
ペアプロットとは?
ペアプロット(pairplot) は、データセット内の全ての数値変数の組み合わせを一度に可視化する強力なグラフです。
探索的データ分析(EDA)の最初に実行すると、データの全体像を一気に把握できます。
基本的なペアプロット
たった1行で、全変数の関係性を可視化できます。
# 全数値変数の組み合わせを一度に可視化 sns.pairplot(tips) plt.show()
実行すると、複数のグラフが格子状に配置された大きな図が表示されます。
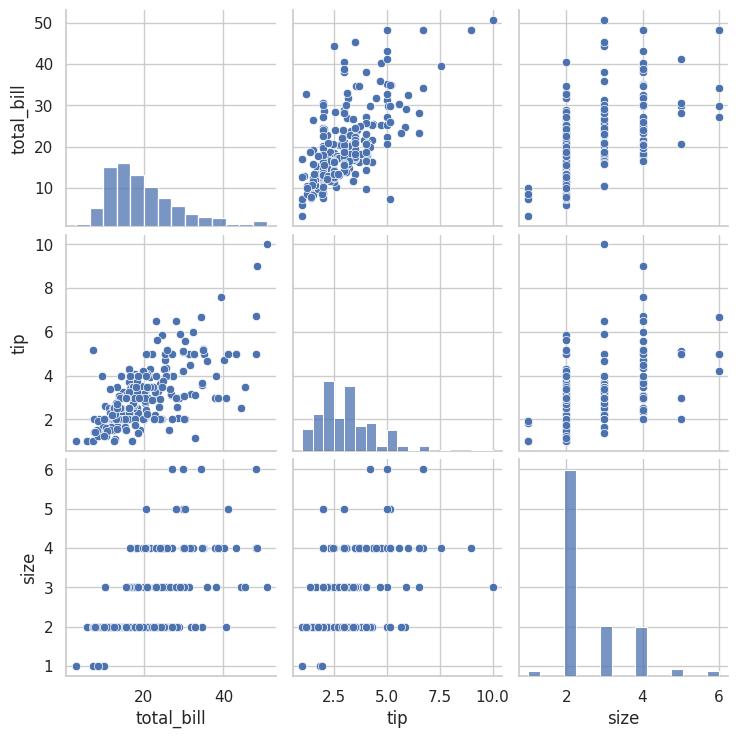
対角線上には各変数のヒストグラム、それ以外には2変数の散布図が配置されます。
このグラフを見るだけで、「total_billとtipには正の相関がある」「sizeは離散的な値を取る」といった多くの情報が得られます。
カテゴリで色分けする
ペアプロットでも hue を使って、カテゴリごとの傾向を確認できます。
# 性別で色分け sns.pairplot(tips, hue="sex") plt.show()
実行すると、男性と女性で色分けされたペアプロットが表示されます。
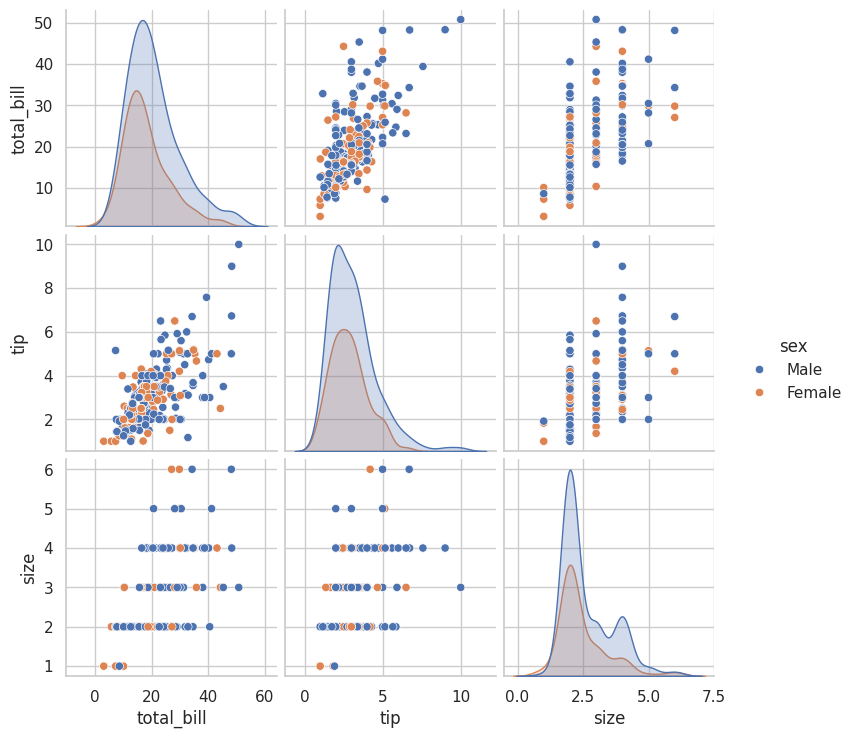
「男性の方が高額な食事代が多い」「チップの分布に性差がある」といった傾向が視覚的にわかります。
特定の変数だけを選択
全変数だと情報過多になる場合は、特定の変数だけを選択できます。
# 特定の変数だけを選択
sns.pairplot(
tips,
vars=["total_bill", "tip", "size"],
hue="time"
)
plt.show()
実行すると、選択した3変数だけのペアプロットが表示されます。
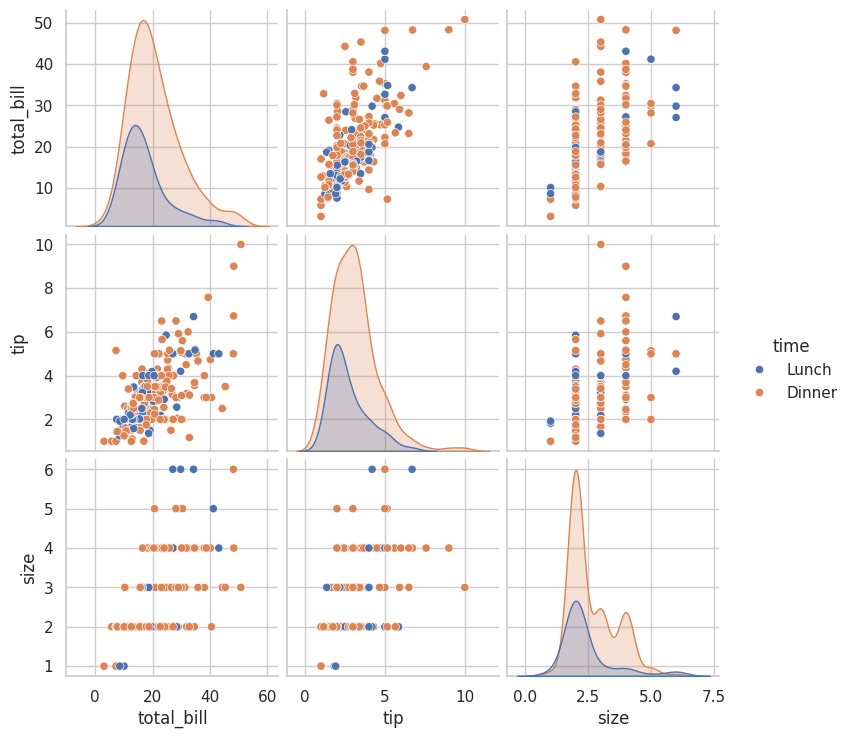
vars 引数で分析したい変数を指定することで、注目したい関係性に焦点を当てられます。
まとめ
以下は、この記事で紹介した6種類のグラフと、その使いどころを整理したものです。
| グラフの種類 | 用途 |
|---|---|
散布図 scatterplot() |
2つの数値変数の関係(相関など)を確認する |
棒グラフ barplot() |
カテゴリごとの平均値や合計値を比較する |
ヒストグラム histplot() |
1つの数値変数の分布・頻度を確認する |
箱ひげ図 boxplot() |
カテゴリごとの分布のばらつきや外れ値を比較する |
ヒートマップ heatmap() |
相関行列やクロス集計表を色の濃淡で可視化する |
ペアプロット pairplot() |
これらのグラフを使いこなせれば、探索的データ分析(EDA)の大半はカバーできます(たぶん)。