

後編に入る前に、前回の簡単な復習をします。
前回と同じ手順で、「ライブラリのインポート → データの読み込み → 標準化 → PCAによる次元削減」を一括で実行します。
サンプルデータは、以下からダウンロードできます。
customer_data.csv
以下、コードです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# ---- CSVファイルからデータを読み込む ----
csv_filename = "customer_data.csv"
df = pd.read_csv(csv_filename)
# ---- 標準化 → PCA ----
scaler = StandardScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
pca = PCA(n_components=3)
df_pca = pd.DataFrame(
pca.fit_transform(df_scaled),
columns=['PC1', 'PC2', 'PC3']
)
print(f"準備完了: {len(df)}人 × 3主成分(累積寄与率 {pca.explained_variance_ratio_.sum():.1%})")
以下、実行結果です。
準備完了: 300人 × 3主成分(累積寄与率 89.3%)
これが前回の最終状態です。300人の顧客が3つの主成分スコアで表現されたデータ df_pca が手元に揃います。
ここから後編の本題に入ります。
Contents
クラスター数を決める
k-means法では事前にクラスター数 k を指定する必要があります。
「お客様を何グループに分けるか?」という問いに、データから客観的に答えるための方法を2つ紹介します。
エルボー法とシルエット係数とは
エルボー法
クラスター内のデータ点と重心との距離の二乗和(慣性、inertia)の変化を見る方法です。
クラスター数を増やすと慣性は減少しますが、ある点を境に減少幅が小さくなります。
この「肘」にあたる点が適切なクラスター数の目安です。
シルエット係数
各データ点が「自分のクラスターにどれだけ適切に所属しているか」を -1 から 1 の値で評価する指標です。
値が1に近いほど、そのデータ点は正しいクラスターに所属していると言えます。
全データ点のシルエット係数の平均値が高いクラスター数を選びます。
k=2〜8で両方の指標を計算する
クラスター数を2から8まで変化させ、エルボー法の慣性とシルエット係数の両方を計算します。
最適なkを判断する材料を数値で得るステップです。
以下、コードです。
# 評価するクラスター数の範囲(2〜8)
K_range = range(2, 9)
# 各kでのKMeansの慣性(ひずみ)を格納
inertias = []
# 各kでのシルエット係数を格納
silhouette_scores_list = []
# kを変えながらKMeansを実行
for k in K_range:
kmeans = KMeans(
n_clusters=k, # クラスター数をkに設定
random_state=42, # 乱数シードを固定
n_init=10 # 初期化の試行回数
)
# PCA後のデータにクラスタリングし、ラベル取得
labels = kmeans.fit_predict(df_pca)
# 学習後の慣性を保存(小さいほど良い傾向)
inertias.append(kmeans.inertia_)
silhouette_scores_list.append(
# クラスタの分離の良さを評価(-1〜1)
silhouette_score(df_pca, labels)
)
print("【クラスター数の評価】")
for k, inertia, sil in zip(
K_range,
inertias,
silhouette_scores_list
):
print(
f" k={k}: "
f"慣性={inertia:.1f}, "
f"シルエット係数={sil:.3f}"
)
以下、実行結果です。
【クラスター数の評価】 k=2: 慣性=1255.1, シルエット係数=0.496 k=3: 慣性=527.1, シルエット係数=0.622 k=4: 慣性=184.1, シルエット係数=0.694 k=5: 慣性=156.2, シルエット係数=0.616 k=6: 慣性=136.8, シルエット係数=0.514 k=7: 慣性=121.2, シルエット係数=0.431 k=8: 慣性=109.0, シルエット係数=0.339
各クラスター数での評価を数値で確認します。
シルエット係数が最大になるkが統計的には最適ですが、ビジネスの観点も重要です。
たとえばシルエット係数がk=3とk=4でほぼ同じなら、施策の打ちやすさから4グループを選ぶこともあります。
次のグラフで視覚的にも確認しましょう。
グラフで「肘」を見つける
エルボー法とシルエット係数のグラフを左右に並べて描画します。
2つの指標を見比べることで、より信頼性の高い判断ができます。
以下、コードです。
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 8))
# エルボー法(ひずみ = クラスター内の誤差の総和)をプロット
ax1.plot(
K_range,
inertias,
'o-',
color='#2E86AB',
linewidth=2,
markersize=8
)
ax1.set_xlabel('クラスター数 k', fontsize=12)
ax1.set_ylabel('慣性(Inertia)', fontsize=12)
ax1.set_title('エルボー法', fontsize=14)
ax1.grid(True, alpha=0.3)
# シルエット係数(クラスタの分離の良さ)をプロット
ax2.plot(
K_range,
silhouette_scores_list,
'o-',
color='#E8553A',
linewidth=2,
markersize=8
)
ax2.set_xlabel('クラスター数 k', fontsize=12)
ax2.set_ylabel('シルエット係数', fontsize=12)
ax2.set_title('シルエット係数', fontsize=14)
ax2.grid(True, alpha=0.3)
plt.suptitle('最適クラスター数の決定', fontsize=14, y=1.02)
plt.tight_layout()
plt.show()
以下、実行結果です。
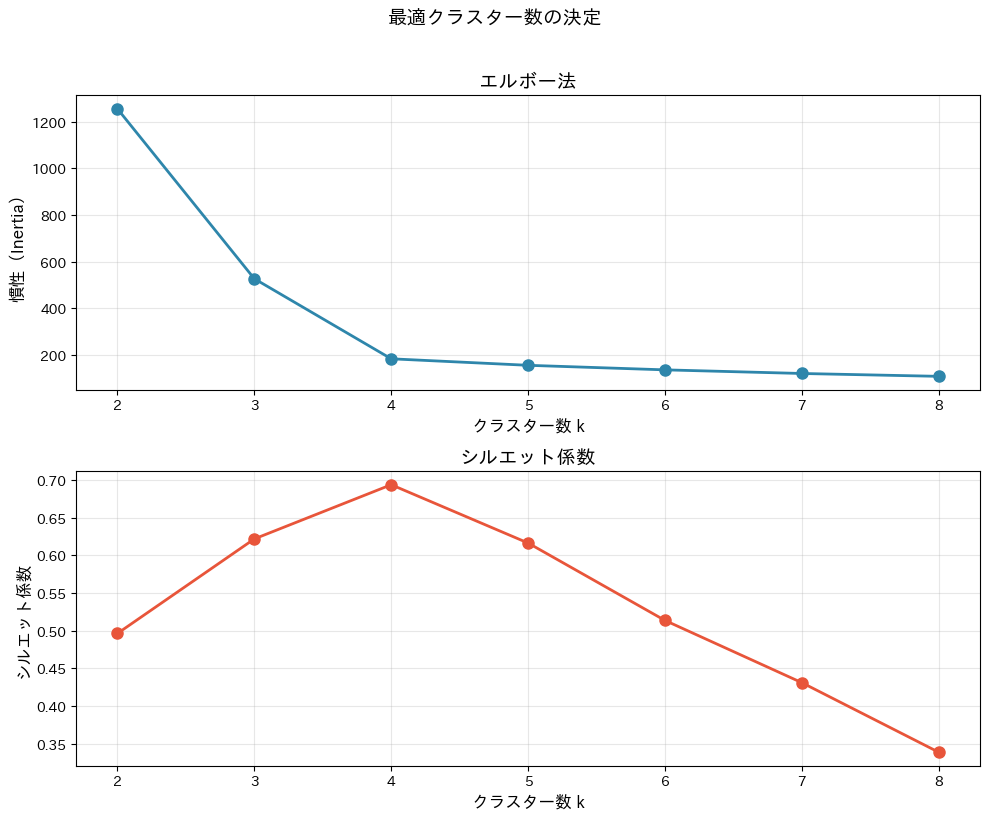
上のエルボー法のグラフで慣性が急激に下がった後になだらかになる「肘」の位置、下のシルエット係数のグラフでスコアが最大になるkを確認しましょう。
今回のデータでは、k=4付近が適切であることが読み取れます。
2つの指標を併用することで、「なぜこのクラスター数にしたのか」を説明できる根拠が得られます。
関係者への報告時にも、グラフと数値の両方を示せると説得力が増します。
k-means法でクラスタリングを実行する
クラスター数が決まったら、いよいよクラスタリングの実行です。
k=4でk-means法を実行し、300人の顧客それぞれにクラスターラベル(0〜3の番号)を割り当てます。
同時にシルエット係数で分割の品質も確認します。
以下、コードです。
# クラスタ数を設定
n_clusters = 4
# KMeansモデルを作成
kmeans = KMeans(
n_clusters=n_clusters,
random_state=42,
n_init=10
)
# PCA後のデータでクラスタリングしてラベルを付与
df['クラスター'] = kmeans.fit_predict(df_pca)
# 結果を表示
print("【クラスタリング結果】")
print(f"クラスター数: {n_clusters}")
print(
"シルエット係数: "
f"{silhouette_score(df_pca, df['クラスター']):.3f}"
)
print(f"\n各クラスターの人数:")
print(df['クラスター'].value_counts().sort_index())
以下、実行結果です。
【クラスタリング結果】 クラスター数: 4 シルエット係数: 0.694 各クラスターの人数: クラスター 0 79 1 80 2 81 3 60 Name: count, dtype: int64
各クラスターの人数が表示されます。
ここで確認してほしいのは、極端にサイズが偏ったクラスター(全体の5%未満など)がないかどうかです。
もしあれば、クラスター数の設定やデータの前処理を見直す必要があるかもしれません。
概ね均等な分割(もしくは、極端にサイズが小さいクラスターがない状態)であれば、次のステップでクラスターの中身を詳しく見ていきます。
クラスターを散布図で「見る」
数値だけでは実感しにくいクラスタリングの結果を、主成分空間上の散布図で可視化してみましょう。
PCA(主成分分析)の第1・第2主成分を軸とした散布図に、クラスターを色分けしてプロットします。
×印はクラスターの重心(各グループの「典型的な顧客」の位置)を示します。
以下、コードです。
# 色の指定(各クラスターの色)
colors = ['#2E86AB', '#E8553A', '#44AF69', '#F4A261']
# 図の作成(サイズ指定)
plt.figure(figsize=(10, 8))
# 各クラスターごとにPC1-PC2平面へ散布図を描く
for i in range(n_clusters):
# クラスターiに属する行だけを抽出するマスク
mask = df['クラスター'] == i
plt.scatter(
df_pca.loc[mask, 'PC1'], # 第1主成分のスコア
df_pca.loc[mask, 'PC2'], # 第2主成分のスコア
c=colors[i], # クラスターごとの色
label=f'クラスター{i}', # 凡例ラベル
alpha=0.7, # 透明度
s=60, # 点のサイズ
edgecolors='white' # 白い縁取り
)
# クラスター重心をPCA空間に投影して表示する
centers_df = (
df.drop('クラスター', axis=1)
.groupby(df['クラスター']).mean()
)
# 標準化の入力として列名付きDataFrameを渡す
centers_scaled = pd.DataFrame(
scaler.transform(centers_df),
columns=centers_df.columns,
index=centers_df.index
)
centers_pca = pca.transform(centers_scaled)
# 重心をXマーカーで強調表示
for i in range(n_clusters):
plt.scatter(
centers_pca[i, 0], centers_pca[i, 1], # 重心のPC1, PC2座標
c=colors[i], # クラスターと同じ色
marker='X', # X印のマーカー
s=200, # マーカーサイズ大きめ
edgecolors='black', linewidths=2 # 黒縁で視認性を高める
)
# 軸ラベル(寄与率を併記)
plt.xlabel(f'第1主成分 (寄与率 {pca.explained_variance_ratio_[0]:.1%})', fontsize=12)
plt.ylabel(f'第2主成分 (寄与率 {pca.explained_variance_ratio_[1]:.1%})', fontsize=12)
plt.title('PCA空間上のクラスター分布', fontsize=14)
plt.legend(fontsize=11)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
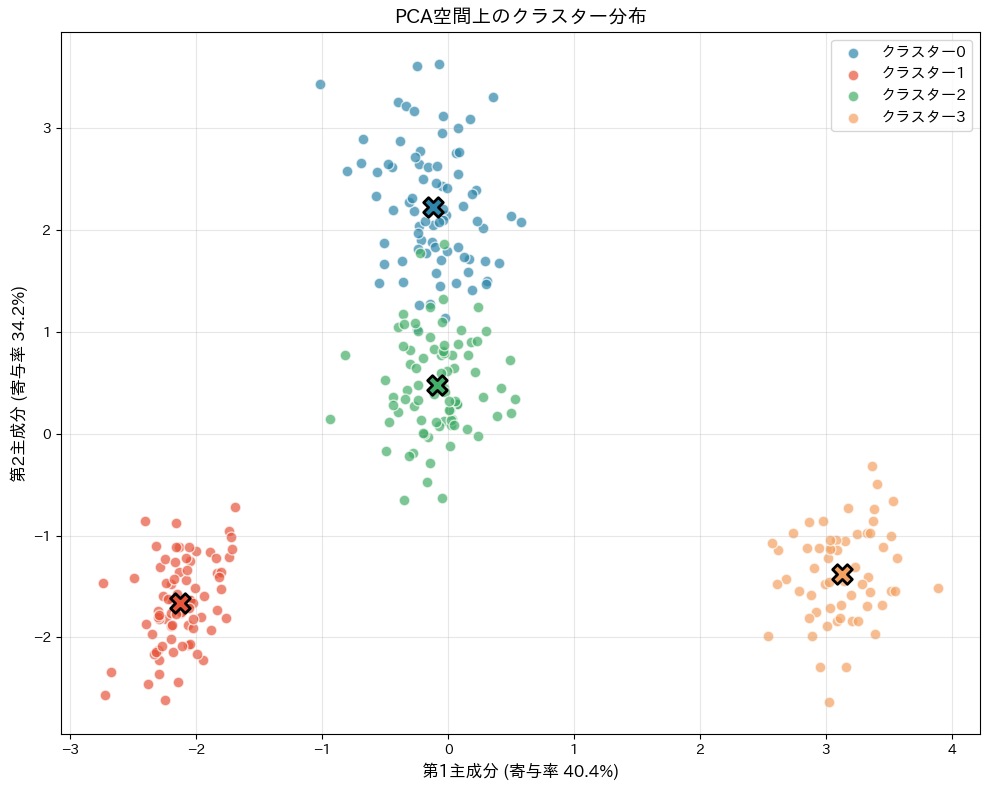
散布図で、4つのクラスターが主成分空間上でどのように分布しているかを確認できます。
クラスターが明確に分離していれば、セグメンテーションがうまくいっている証拠です。
一部のクラスターが重なって見える場合でも、第3主成分(PC3)の方向では分離している可能性があるため、3次元的な視点も重要です。
この散布図は、分析結果を関係者に見せる際に「ちゃんとグループが分かれていますよ」と直感的に伝えるための強力な武器になります。
クラスタープロファイリング
分析の中で最も重要なステップがクラスタープロファイリングです。
各クラスターの特徴を元の変数で確認し、ビジネス的に意味のある「名前」をつけることで、具体的な施策につなげることができます。
クラスター別の平均値を見る
各クラスターの平均値を計算し、クラスター間の違いを明確にします。
「来店回数が多いのはどのグループか」「購入額が高いのはどのグループか」を数値で把握するステップです。
以下、コードです。
profile = df.groupby('クラスター').mean().round(2)
print("【クラスタープロファイル(各クラスターの平均値)】")
print(profile.to_string())
print(f"\n各クラスターの人数:")
print(df['クラスター'].value_counts().sort_index())
以下、実行結果です。
【クラスタープロファイル(各クラスターの平均値)】
monthly_visits avg_purchase drink_ratio food_ratio goods_ratio avg_stay_min coupon_rate member_months
クラスター
0 4.97 1271.36 0.49 0.45 0.06 60.34 0.60 12.49
1 20.40 397.14 0.90 0.11 0.01 10.47 0.32 25.28
2 3.13 507.53 0.60 0.30 0.11 26.41 0.15 6.17
3 2.21 3133.47 0.11 0.10 0.81 14.11 0.19 17.57
各クラスターの人数:
クラスター
0 79
1 80
2 81
3 60
Name: count, dtype: int64
各クラスターの平均値を比較することで、グループの特徴が浮かび上がります。
たとえば、来店回数が月20回で平均購入額が400円のクラスターは「朝型常連客」、来店回数が月2回で購入額が3000円のクラスターは「まとめ買い客」と解釈できるかもしれません。
ただし数値の羅列だけでは読み取りにくいので、次のレーダーチャートでグラフ化して「形」で理解しましょう。
レーダーチャートで形を比較する
クラスターごとの特徴をレーダーチャートで可視化します。
レーダーチャートは多変量のプロファイルを比較するのに最適な可視化手法で、各クラスターの「形」の違いが一目でわかります。
比較しやすいように標準化後の平均値を使います。
以下、コードです。
# 元の標準化データをコピー
profile_scaled = df_scaled.copy()
# クラスター列を付与
profile_scaled['クラスター'] = df['クラスター']
# クラスターごとの平均を計算
profile_means = profile_scaled.groupby('クラスター').mean()
# レーダーチャートの作成準備
categories = list(df.columns[df.columns != 'クラスター'])
# 変数の数
n_vars = len(categories)
# 各軸の角度を計算
angles = np.linspace(
0,
2 * np.pi,
n_vars,
endpoint=False
).tolist()
# グラフを閉じるために最初の角度を追加
angles += angles[:1]
# 図と極座標の軸を用意
fig, ax = plt.subplots(
# 図のサイズ
figsize=(10, 10),
# 極座標で描画
subplot_kw=dict(polar=True)
)
# 各クラスターの線と塗りを描画
for i in range(n_clusters):
# クラスターiの平均値を取得
values = profile_means.iloc[i].tolist()
# 始点に戻るために最初の値を追加
values += values[:1]
# 折れ線を描画
ax.plot(
angles,
values,
'o-',
linewidth=2,
color=colors[i],
label=f'クラスター{i}'
)
# 面を薄く塗る
ax.fill(angles, values, alpha=0.1, color=colors[i])
# 角度の位置に目盛りを設定
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, fontsize=10)
ax.set_title(
'クラスター別プロファイル(レーダーチャート)',
fontsize=14,
pad=20
) # タイトル
ax.legend(
loc='upper right',
bbox_to_anchor=(1.3, 1.1),
fontsize=11
) # 凡例を配置
plt.tight_layout() # レイアウトを自動調整
plt.show() # 図を表示
以下、実行結果です。
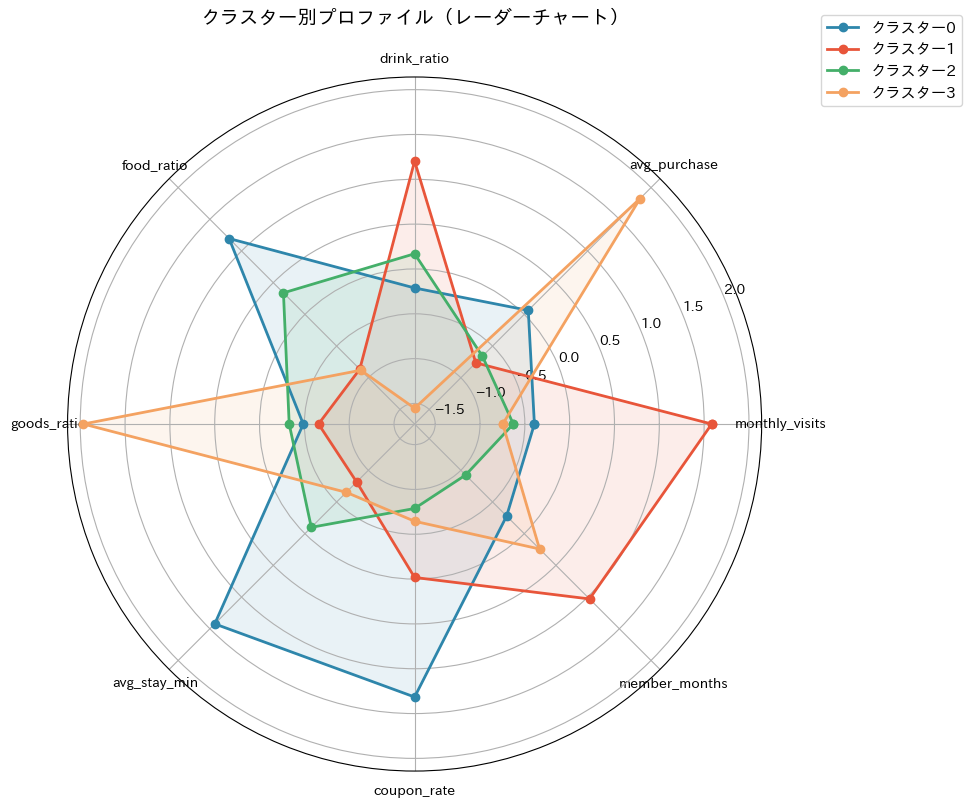
レーダーチャートによって、各クラスターの「形」が一目でわかります。尖りのある方向がそのクラスターの特徴を示しています。
| 人数 | 行動パターンの要約 | 解釈 | |
|---|---|---|---|
| クラスター0 | 約79人 | 長時間滞在・フード中心・クーポン高反応 | 週末やレジャー的な「長滞在フード志向」層 |
| クラスター1 | 約80人 | 高頻度・短時間・ドリンク特化 | 「朝型・ドリンク常連」層(長期会員中心) |
| クラスター2 | 約81人 | バランス型・新規寄り・低反応 | 「ライトユーザー・定着途上」層 |
| クラスター3 | 約60人 | 低頻度・高単価・物販中心 |
この「形の違い」こそが、次のステップで施策を考えるための出発点になります。
ビジネス的な解釈と施策提案
分析結果を眺めるだけでは、ビジネスの価値は生まれません。
各クラスターにビジネス的な「名前」をつけ、それぞれに対する具体的な施策を考えることで、はじめてデータ分析がマーケティングの武器になります。
プロファイリングの結果に基づいて、各クラスターの命名と施策案をまとめ、マーケティング部門に提出できるレポート形式で出力します。
分析結果を踏まえ、各クラスターのビジネス的な位置づけと施策案を以下の表のように整理しました。
| クラスター | セグメント名 | 売上構造 | 課題仮説 | 主要施策 | 追うべきKPI |
|---|---|---|---|---|---|
| 0 | 長滞在フード志向層 | 中頻度 × 中単価 | 滞在時間は長いが客単価伸び代あり | セットメニュー強化、季節限定スイーツ | 客単価、フード比率 |
| 1 | 朝型ドリンク常連層 | 高頻度 × 低単価 | 単価が低い | サイズアップ提案、定期券型サブスク | 客単価、来店回数 |
| 2 | ライトユーザー層 | 低頻度 × 低単価 | 定着していない | 来店動機づくり、初回特典 | 来店頻度、会員継続率 |
| 3 | 物販まとめ買い層 | 低頻度 × 高単価 | 来店頻度が低い | ギフト提案、限定商品 |
セグメント名は、プロファイルの中身を見て人が適切に命名しましょう。
数字(機械的なクラスター分析結果)を機械が出し、意味を人間が読み取り魂を込める、このバランスがデータ分析の肝です。
Pipelineで一括実行 ── 実務で使える形にまとめる
ここまで一つひとつの手順を丁寧に追ってきましたが、実務ではこの一連のプロセスを効率的に実行したい場面も多いでしょう。
scikit-learnのPipelineを使えば、標準化→PCA→クラスタリングの流れをひとまとめに記述できます。
Pipelineを使って、前処理からクラスタリングまでを一括実行する方法を紹介します。
新規顧客が来たときに即座にグループ分けできる「再利用可能な仕組み」を作るイメージです。
以下、コードです。
from sklearn.pipeline import Pipeline
# パイプラインの構築
pipeline = Pipeline([
# ステップ1: 標準化
('scaler', StandardScaler()),
# ステップ2: PCA
('pca', PCA(n_components=3)),
# ステップ3: クラスタリング
('kmeans', KMeans(n_clusters=4, random_state=42, n_init=10))
])
# データを渡して一括実行
df_features = df.drop('クラスター', axis=1)
labels_pipe = pipeline.fit_predict(df_features)
print("【Pipeline による一括実行】")
print(f"クラスター割り当て(最初の10人): {labels_pipe[:10]}")
print(f"\n各クラスターの人数:")
print(pd.Series(labels_pipe).value_counts().sort_index())
以下、実行結果です。
【Pipeline による一括実行】 クラスター割り当て(最初の10人): [3 2 0 1 2 2 3 0 1 3] 各クラスターの人数: 0 79 1 80 2 81 3 60 Name: count, dtype: int64
わずか数行のコードで、標準化・PCA・k-meansの3ステップが一括実行できました。
Pipelineの利点は、コードが簡潔になるだけでなく、新しいデータに対しても同じ前処理を一貫して適用できることです。
たとえば新規顧客が来たときに pipeline.predict(new_customer_data) と書くだけで、標準化→PCA→クラスター割り当てが自動的に行われます。
# 新規顧客のデータをデータフレームで作成(2名分)
new_customers = pd.DataFrame([
{
'monthly_visits': 4,
'avg_purchase': 800,
'drink_ratio': 0.6,
'food_ratio': 0.3,
'goods_ratio': 0.1,
'avg_stay_min': 30,
'coupon_rate': 0.2,
'member_months': 5
},
{
'monthly_visits': 18,
'avg_purchase': 380,
'drink_ratio': 0.9,
'food_ratio': 0.08,
'goods_ratio': 0.02,
'avg_stay_min': 12,
'coupon_rate': 0.35,
'member_months': 24
}
])
# クラスタ予測
pred_clusters = pipeline.predict(new_customers)
# 予測結果をデータフレームに追加
new_customers['予測クラスター'] = pred_clusters
# 結果表示
print(new_customers)
以下、実行結果です。
monthly_visits avg_purchase drink_ratio food_ratio goods_ratio \ 0 4 800 0.6 0.30 0.10 1 18 380 0.9 0.08 0.02 avg_stay_min coupon_rate member_months 予測クラスター 0 30 0.20 5 2 1 12 0.35 24 1
まとめ
前編・後編を通して、カフェチェーンの顧客データを題材に、PCAとクラスター分析を組み合わせた顧客セグメンテーションまでのプロセスの一例を紹介しました。
分析の流れを改めて振り返ってみましょう。
| やったこと | 得られたもの | |
|---|---|---|
| データの理解 | 基本統計量・ヒストグラム・相関行列 | 「スケールが違う」「山が複数ある」「変数間に相関がある」という気づき |
| 標準化 | StandardScalerで平均0・標準偏差1に変換 | 全変数が対等に比較できる状態 |
| PCA | 8変数 → 3主成分に圧縮 | ノイズが減り、本質的な構造が浮き出たデータ |
| クラスター数の決定 | エルボー法 + シルエット係数 | 「k=4が適切」という客観的根拠 |
| k-means実行 | PCA後のデータでクラスタリング | 各顧客へのクラスターラベル |
| 可視化 | 散布図でクラスター分布を確認 | 「ちゃんと分かれている」という視覚的な確信 |
| プロファイリング | 平均値の比較 + レーダーチャート | 各グループの「顔」と「形」 |
| 施策提案 | ビジネス的な命名と施策立案 |
この「前処理 → 次元削減 → クラスタリング → 解釈」という一連の流れは、顧客セグメンテーションに限らず、多くのビジネス分析に共通するパターンです。
たとえば商品のグループ化、市場のセグメント分析、従業員のタイプ分類など、「似たものをグループ化して特徴を理解する」場面であれば、ほぼ同じアプローチが適用できます。
一つ注意しておきたいのは、クラスター分析の結果は「唯一の正解」ではないということです。
クラスター数の選択、PCAで何個の主成分を使うか、外れ値をどう処理するかなど、分析者の判断によって結果は変わります。
重要なのは、統計的な指標(シルエット係数など)とビジネスの知見の両方を活用して、実務で使える妥当な結果を導くことです。