

機械学習モデルの精度がなかなか上がらない、と悩んだ経験はありませんか?
データを集め、特徴量を整え、ハイパーパラメータも調整したのに結果が伸びない原因が、実は 欠損値(missing values) の扱い方にあった、というのはよくある話です。
このシリーズでは、欠損値の 検出・分析・処理 を数回にわたって解説していきます。
第1回となる今回は、すべての処理の出発点となる「欠損値の3つのメカニズム」、つまり MCAR・MAR・MNAR という分類について、用語の意味から紹介します。
そもそも「欠損値」とは?
欠損値 とは、本来あるべきデータが何らかの理由で記録されていない値のことです。
pandas のデータフレームでは NaN(Not a Number の略)として表現されます。
たとえば……
- アンケートの「年収」欄で答えたくない人が空欄にしたり
- センサーが一時的に故障してデータが取れなかったり
- 調査票のデータをエクセルに入力する際に入力漏れが起きたり
……と、欠損が発生する原因はさまざまです。
この「なぜ」を見極めるための分類が、これから紹介する MCAR・MAR・MNAR の3つです。
欠損のメカニズム:MCAR・MAR・MNAR
統計学では、欠損値の発生原因を 欠損メカニズム(missing mechanism) と呼び、主に次の3つに分類します。
| 略称 | 正式名称 | 日本語 | |
|---|---|---|---|
| MCAR | Missing Completely At Random | 完全にランダムな欠損 | 欠損が完全に偶然 |
| MAR | Missing At Random | ランダムな欠損 | 欠損が他の変数で説明できる |
| MNAR | Missing Not At Random | ランダムでない欠損 | 欠損が値そのものに依存 |
それぞれを、ひとつずつ見ていきましょう。
MCAR(Missing Completely At Random)
MCAR は、欠損が 完全にランダム に発生するケースです。
「どの値が欠損するか」が、観測されている他の変数とも、欠損している値そのものとも、まったく関係がない状態を指します。
たとえば、「アンケート用紙を100枚配ったうち、いくつかが郵送中に紛失してしまった」というような状況です。
紛失するかどうかは、回答者の属性や回答内容とは無関係なので、これは MCAR にあたります。
MAR(Missing At Random)
MAR は、欠損が 他の観測されている変数によって説明できる ケースです。
名前に「ランダム」と入っているので紛らわしいのですが、「完全にランダム」ではなく「他の変数で条件づければランダム」というのがポイントです。
たとえば、健康に関するアンケートで、女性の方が「体重」を答え渋る傾向があったとします。ただし、体重が軽いから答える、重いから答えない、という傾向はないとします。
このとき「体重」の欠損は、性別(観測されている変数)と関連しています。
ただし、体重の値そのもの(体重が軽いから答える、重いから答えない)には依存しません。これは、男性という条件の中ではランダムに欠損が発生する、女性という条件の中ではランダムに欠損が発生する、ということです。
これが MAR の典型例です。
MNAR(Missing Not At Random)
MNAR は、欠損が 欠損している値そのものに依存する ケースです。
3つの中で最も扱いが難しいタイプです。
たとえば、収入アンケートで「高所得者ほど年収を答えたがらない」という傾向があるとします。
このとき、「年収」が欠損するかどうかは、その年収の値そのもの(高いか低いか)に依存しています。
観測されている他の変数だけでは欠損のパターンを説明できないため、MNAR は単純な補完手法ではバイアスが残ってしまいます。
3つのメカニズムを Python で再現してみよう
ここからは実際に手を動かして、MCAR・MAR・MNAR の3パターンを人工的に作り出してみましょう。
同じ元データから3種類の欠損を発生させて、その違いを目で確認します。
サンプルデータの作成
まずは、年齢(Age)と年収(Income)を含むデータを生成します。
年齢が高いほど年収も高くなる、という現実に近い設定にしておきます。
以下、コードです。
import numpy as np
import pandas as pd
# 再現性のため乱数の種を固定
np.random.seed(42)
# 1000人分の年齢を生成(20歳〜60歳)
n = 1000
age = np.random.randint(20, 61, size=n)
# 年齢に応じて年収を生成(年齢×10万円 + ノイズ)
income = age * 10 + np.random.normal(0, 50, size=n)
# データフレームにまとめる
df_original = pd.DataFrame({
'Age': age,
'Income': income
})
print(df_original.head())
print(f"\nデータ件数: {len(df_original)}件")
print(f"年収の平均: {df_original['Income'].mean():.2f}万円")
np.random.seed(42):乱数のシードを42に固定することで、何度実行しても同じデータが生成されます。再現性のために重要な指定ですnp.random.randint(20, 61, size=n):20以上61未満の整数を1000個生成します(つまり20〜60歳)np.random.normal(0, 50, size=n):平均0、標準偏差50の正規分布から1000個のノイズを生成します
以下、実行結果です。
Age Income 0 58 612.718283 1 48 477.220766 2 34 353.998431 3 27 213.725548 4 40 522.287599 データ件数: 1000件 年収の平均: 406.87万円
MCAR を再現する
MCAR は完全にランダムな欠損なので、行を 無作為に 選んで Income を欠損させます。
以下、コードです。
# MCARパターンの再現
df_mcar = df_original.copy()
# 1000件のうち200件をランダムに選んで欠損させる
np.random.seed(0)
mcar_indices = np.random.choice(
df_mcar.index, # df_mcarのインデックスを使う
size=200, # 200件を選択
replace=False # 重複なし
)
df_mcar.loc[mcar_indices, 'Income'] = np.nan
print(f"MCAR:欠損数 = {df_mcar['Income'].isnull().sum()}件")
print(f"欠損した人の平均年齢: {df_mcar.loc[mcar_indices, 'Age'].mean():.2f}歳")
print(f"全体の平均年齢: {df_original['Age'].mean():.2f}歳")
df_original.copy():元データを変更しないよう、コピーを作って操作しますnp.random.choice(..., replace=False):重複なしで200個のインデックスをランダムに選びますdf_mcar.loc[mcar_indices, 'Income'] = np.nan:選ばれた行のIncome列をNaN(欠損)に置き換えます
以下、実行結果です。
MCAR:欠損数 = 200件 欠損した人の平均年齢: 41.03歳 全体の平均年齢: 40.34歳
欠損した人の平均年齢と全体の平均年齢がほぼ同じになります。これが MCAR の特徴です。
欠損は年齢に依存していない ため、欠損グループと非欠損グループの属性に偏りが出ません。
MAR を再現する
MAR は他の変数(観測されている値)に依存する欠損です。
ここでは「若い人ほど年収を答えたがらない」という設定で、Age が低い人ほど Income が欠損しやすくなるようにします。
以下、コードです。
# MARパターンの再現
df_mar = df_original.copy()
# 年齢が低いほど欠損確率が高くなるように設定
# 20歳で確率0.5、60歳で確率0.05程度に
np.random.seed(1)
prob_missing = (60 - df_mar['Age']) / 80 # 年齢から欠損確率を計算
random_values = np.random.uniform(0, 1, size=len(df_mar))
mar_mask = random_values < prob_missing
df_mar.loc[mar_mask, 'Income'] = np.nan
print(f"MAR:欠損数 = {df_mar['Income'].isnull().sum()}件")
print(f"欠損した人の平均年齢: {df_mar.loc[mar_mask, 'Age'].mean():.2f}歳")
print(f"全体の平均年齢: {df_original['Age'].mean():.2f}歳")
prob_missing:年齢が低いほど大きな値(=欠損しやすい)になるように計算しています。20歳なら(60-20)/80 = 0.5、60歳なら(60-60)/80 = 0ですnp.random.uniform(0, 1, size=len(df_mar)):0〜1の一様乱数を1000個生成しますrandom_values < prob_missing:乱数が欠損確率より小さい行をTrueとすることで、年齢に応じた確率で欠損が発生します
以下、実行結果です。
MAR:欠損数 = 240件 欠損した人の平均年齢: 33.15歳 全体の平均年齢: 40.34歳
欠損した人の平均年齢が全体平均より明らかに低くなっています。
欠損が年齢という観測変数で説明できる のが MAR の特徴です。
MNAR を再現する
MNAR は 欠損している値そのもの に依存します。
ここでは「年収が高い人ほど年収を答えたがらない」という設定にします。
以下、コードです。
# MNARパターンの再現
df_mnar = df_original.copy()
# 年収が高いほど欠損確率が高くなるように設定
np.random.seed(2)
income_normalized = (df_mnar['Income'] - df_mnar['Income'].min()) / \
(df_mnar['Income'].max() - df_mnar['Income'].min())
prob_missing = income_normalized * 0.5 # 最高で確率0.5
random_values = np.random.uniform(0, 1, size=len(df_mnar))
mnar_mask = random_values < prob_missing
df_mnar.loc[mnar_mask, 'Income'] = np.nan
print(f"MNAR:欠損数 = {df_mnar['Income'].isnull().sum()}件")
print(f"欠損していない人の平均年収: {df_mnar['Income'].mean():.2f}万円")
print(f"元データの平均年収: {df_original['Income'].mean():.2f}万円")
income_normalized:年収を0〜1の範囲に正規化しています。mnar_mask:年収が高い人ほどTrueになりやすいマスクです
以下、実行結果です。
MNAR:欠損数 = 536件 欠損していない人の平均年収: 345.13万円 元データの平均年収: 406.87万円
欠損していない人の平均年収が元データより明らかに低く なります。
高年収者が選択的に欠損したため、残ったデータだけを見ると「年収が低めの集団」になってしまうのです。
これが MNAR の怖いところで、欠損行を単純に無視すると 分析結果に大きなバイアス が生じます。
3つのメカニズムを可視化して比較する
数値だけでは違いがわかりにくいので、年収の分布をヒストグラムで並べて比較してみましょう。
以下、コードです。
import matplotlib.pyplot as plt
# 縦に4つのヒストグラムを並べる
fig, axes = plt.subplots(4, 1, figsize=(8, 12))
# 元データの分布
axes[0].hist(
df_original['Income'],
bins=30,
color='gray',
edgecolor='white'
)
axes[0].set_title('Original (No Missing)')
axes[0].set_ylabel('Frequency')
# MCAR後の分布(欠損していない値だけ)
axes[1].hist(
df_mcar['Income'].dropna(),
bins=30,
color='steelblue',
edgecolor='white'
)
axes[1].set_title('MCAR (Random Missing)')
axes[1].set_ylabel('Frequency')
# MAR後の分布
axes[2].hist(
df_mar['Income'].dropna(),
bins=30,
color='seagreen',
edgecolor='white'
)
axes[2].set_title('MAR (Depends on Age)')
axes[2].set_ylabel('Frequency')
# MNAR後の分布
axes[3].hist(
df_mnar['Income'].dropna(),
bins=30,
color='indianred',
edgecolor='white'
)
axes[3].set_title('MNAR (Depends on Income)')
axes[3].set_xlabel('Income')
axes[3].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
plt.subplots(1, 4, ...):1行4列のグラフを並べて作成しますsharey=True:4つのグラフでy軸の目盛を共通化し、比較しやすくしますdf_mcar['Income'].dropna():欠損行を除いてヒストグラムを描画します
以下、実行結果です。
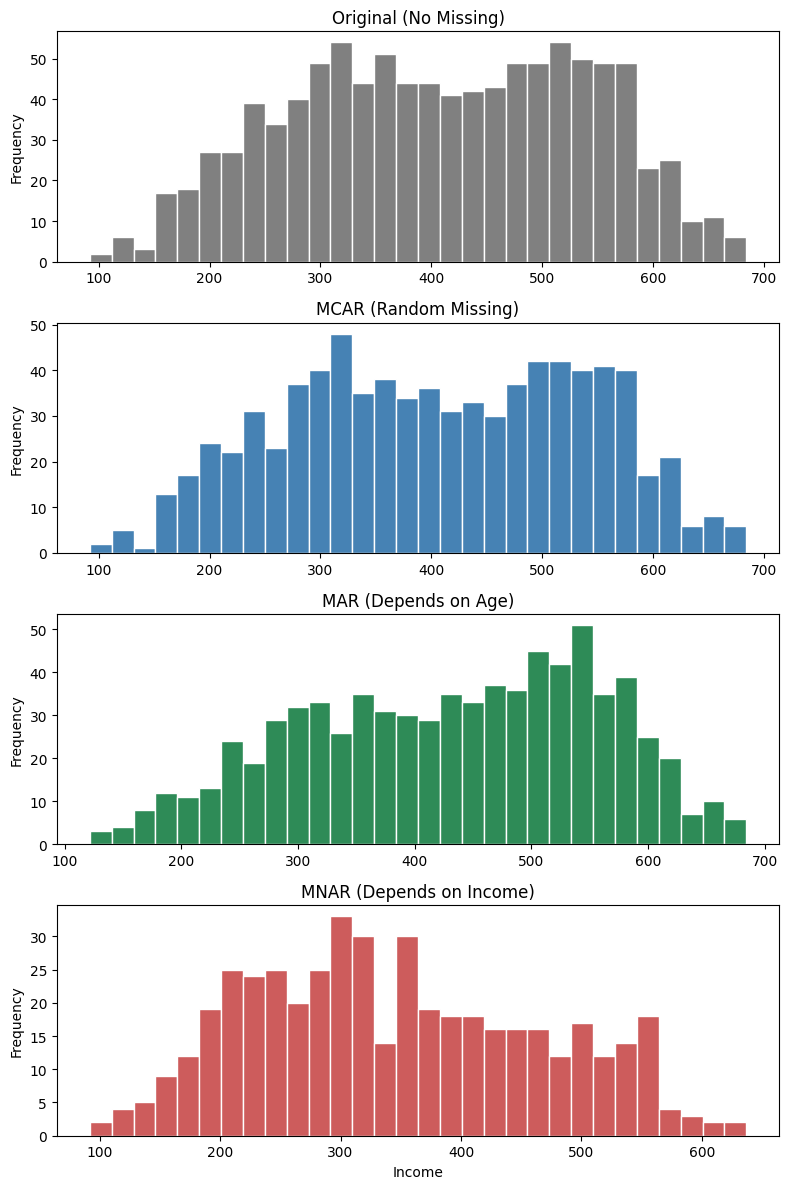
MCAR と MAR では、残ったデータの分布形状が元データと大きく変わらない のに対し、MNAR では右側(高年収側)が削れて分布が左に偏っている ことが視覚的にわかります。
年齢別でグラフを描いてみます。
以下、コードです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 既存データと依存関係は維持しつつ、年齢でグループ分けして可視化を分ける
# 年齢帯の作成(例:20代、30代、40代、50代、60代)
if 'AgeGroup' not in df_original.columns:
bins = [19, 29, 39, 49, 59, 70]
labels = ['20s', '30s', '40s', '50s', '60s']
# 各データフレームにAgeGroup列を追加
df_original = df_original.assign(
AgeGroup=pd.cut(
df_original['Age'],
bins=bins,
labels=labels,
right=True
)
)
df_mcar = df_mcar.assign(
AgeGroup=pd.cut(
df_mcar['Age'],
bins=bins,
labels=labels,
right=True
)
)
df_mar = df_mar.assign(
AgeGroup=pd.cut(
df_mar['Age'],
bins=bins,
labels=labels,
right=True
)
)
df_mnar = df_mnar.assign(
AgeGroup=pd.cut(
df_mnar['Age'],
bins=bins,
labels=labels,
right=True
)
)
# 年齢帯ごとのヒストグラム(重ね描き)
fig, axes = plt.subplots(4, 1, figsize=(8, 12))
# 可視化の共通設定
plot_settings = {
'bins': 30,
'edgecolor': 'white',
'alpha': 0.6
}
colors = {
'20s': 'tab:blue',
'30s': 'tab:orange',
'40s': 'tab:green',
'50s': 'tab:red',
'60s': 'tab:purple'
}
age_groups = ['20s', '30s', '40s', '50s', '60s']
# 1. 元データ
for ag in age_groups:
subset = df_original.loc[df_original['AgeGroup'] == ag, 'Income']
if len(subset) > 0:
axes[0].hist(subset, color=colors[ag], label=ag, **plot_settings)
axes[0].set_title('Original (No Missing) by Age Group')
axes[0].set_ylabel('Frequency')
axes[0].legend()
# 2. MCAR 後
for ag in age_groups:
subset = df_mcar.loc[(df_mcar['AgeGroup'] == ag) & (~df_mcar['Income'].isna()), 'Income']
if len(subset) > 0:
axes[1].hist(subset, color=colors[ag], label=ag, **plot_settings)
axes[1].set_title('MCAR (Random Missing) by Age Group')
axes[1].set_ylabel('Frequency')
axes[1].legend()
# 3. MAR 後
for ag in age_groups:
subset = df_mar.loc[(df_mar['AgeGroup'] == ag) & (~df_mar['Income'].isna()), 'Income']
if len(subset) > 0:
axes[2].hist(subset, color=colors[ag], label=ag, **plot_settings)
axes[2].set_title('MAR (Depends on Age) by Age Group')
axes[2].set_ylabel('Frequency')
axes[2].legend()
# 4. MNAR 後
for ag in age_groups:
subset = df_mnar.loc[(df_mnar['AgeGroup'] == ag) & (~df_mnar['Income'].isna()), 'Income']
if len(subset) > 0:
axes[3].hist(subset, color=colors[ag], label=ag, **plot_settings)
axes[3].set_title('MNAR (Depends on Income) by Age Group')
axes[3].set_xlabel('Income')
axes[3].set_ylabel('Frequency')
axes[3].legend()
plt.tight_layout()
plt.show()
以下、実行結果です。
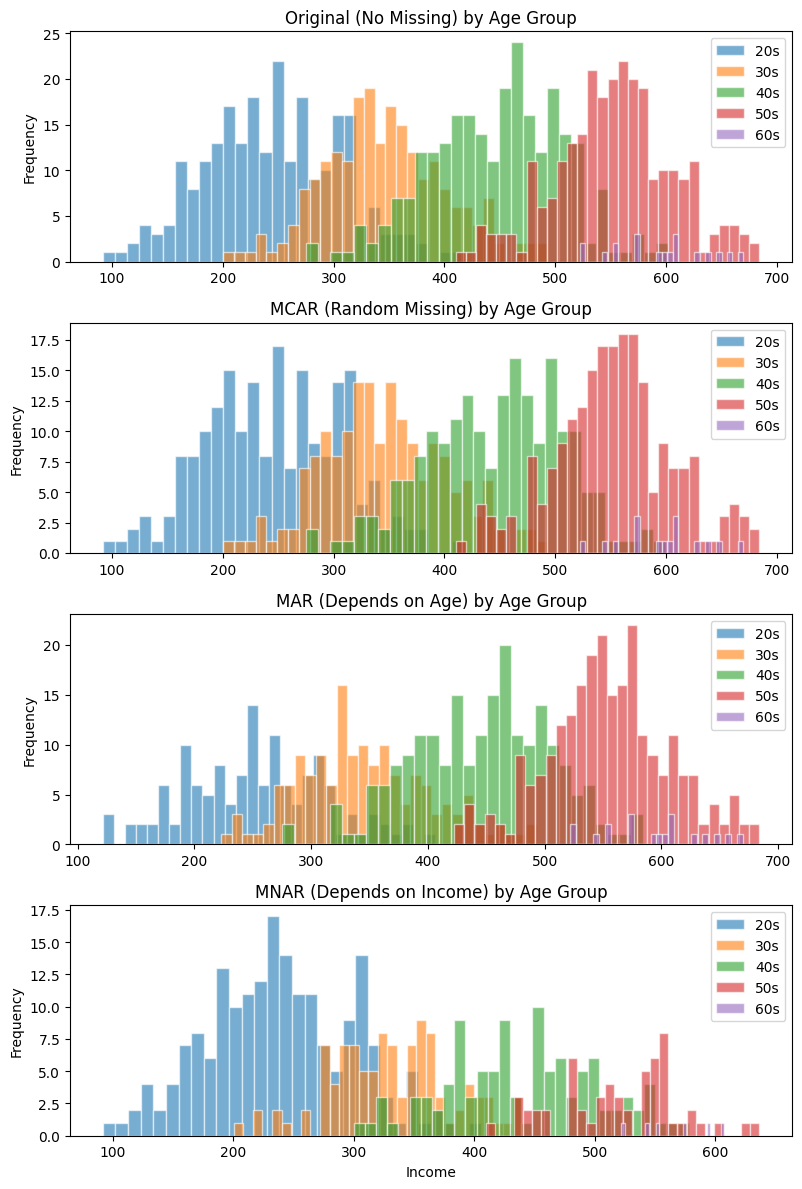
メカニズムによって処理方法が変わる
欠損のメカニズムによって、適切な処理方法が異なります。
おおまかな対応関係を表にまとめると次のようになります。あくまでも一例です。
| メカニズム | 推奨される処理 | |
|---|---|---|
| MCAR | 削除、平均値・中央値補完など | バイアスが生じにくいため、シンプルな手法でOK |
| MAR | KNN、MICE、MissForest などの多変量補完 | 他の変数の情報を使って補完できる |
| MNAR | 専用モデル(パターン代入、最尤推定) | 通常の補完ではバイアスが残る |
つまり、「とりあえず平均値で埋める」「とりあえず欠損行を削除する」という機械的な処理は危険 なのです。
まずデータの欠損メカニズムを推定してから、適切な手法を選ぶことになります。
データ漏洩への注意
シリーズ全体を通して何度も登場する重要な概念を簡単に説明します。
それが データ漏洩(data leakage) です。
たとえば、機械学習モデルを構築するときに、訓練データとテストデータに分けてモデルを検証しているとします。
テストデータの欠損値を補完するとき、「テストデータの統計量を使って補完してはいけない」という鉄則があります。
たとえば、テストデータの平均値で訓練データの欠損を埋めてしまうと、本来モデルが知るべきでない情報(テストデータの情報)が訓練に紛れ込んでしまいます。
これを防ぐには、訓練データだけから計算した統計量を、テストデータにも適用する という流れを徹底する必要があります。
まとめ
今回のポイントを振り返りましょう。
- 欠損値 は機械学習モデルの精度を下げる大きな要因のひとつ
- 欠損には3つのメカニズムがある
- MCAR:完全にランダムな欠損(バイアスが生じにくい)
- MAR:他の観測変数に依存する欠損(多変量補完で対処可能)
- MNAR:欠損値そのものに依存する欠損(最も扱いが難しい)
- メカニズムによって適切な処理方法が変わる ため、まず欠損の性質を見極めることが重要
- データ漏洩 を防ぐため、訓練データの統計量だけを使って補完する