
データサイエンスの世界では、「2つのデータがどれくらい似ているか(近いか)」 を測ることが非常に重要です。
たとえば、おすすめ商品のレコメンド、顧客のグループ分け(クラスタリング)、異常検知など、多くの分析手法の土台に「距離の計算」があります。
この記事では、SciPyの scipy.spatial モジュールを使って、データ間の距離を計算する方法と、機械学習の前処理に役立つ知識を、初心者の方にもわかるように丁寧に解説します。
Contents
なぜ「距離」が重要なのか?
データの「近さ」で判断する分析手法
データサイエンスでは、「値の近いデータは、似ている」という考え方が広く使われています。
- レコメンド → あなたと「近い」購買履歴を持つ人がいたら、その人が買った商品をおすすめする
- クラスタリング → 「近い」データ同士をグループにまとめる
- k近傍法(kNN) → 新しいデータに最も「近い」k個のデータから、分類を予測する
- 異常検知 → 他のデータから「遠い」データを異常として検出する
これらすべての基盤にあるのが 「距離をどう測るか」 です。
データの距離をグラフで理解する
「距離が近い=似ている」というイメージを、グラフで確認してみましょう。
3人の顧客データを2次元の散布図にプロットし、顧客間の距離を緑(近い)と赤(遠い)の線で表示します。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# 顧客データ: 名前 -> (年齢, 年間購買額[万円])
customers = {
'顧客A': (25, 30),
'顧客B': (38, 35),
'顧客C': (55, 80),
}
# 描画領域の作成
plt.figure(figsize=(8, 6))
# 各顧客を点として描画し、ラベルを付与
for name, (age, spend) in customers.items():
plt.scatter(
age,
spend,
s=100 # 点のサイズ
)
plt.annotate(
name,
xy=(age, spend),
xytext=(age-1, spend+2.5),
fontsize=12 # ラベルのフォントサイズ
)
# 顧客Aと顧客Bの距離(近い)を緑の破線で表示
plt.plot(
[25, 38],
[30, 35],
'g--',
linewidth=2,
label='A-B間(近い)'
)
# 顧客Aと顧客Cの距離(遠い)を赤の破線で表示
plt.plot(
[25, 55],
[30, 80],
'r--',
linewidth=2,
label='A-C間(遠い)'
)
# 軸ラベル
plt.xlabel('年齢', fontsize=12)
plt.ylabel('年間購買額(万円)', fontsize=12)
# 軸範囲
plt.xlim(20, 60)
plt.ylim(20, 90)
# タイトルと凡例、グリッド
plt.title('データの「距離」= データの「似ている度合い」')
plt.legend(loc='upper left', fontsize=11)
plt.grid(True, alpha=0.3)
# レイアウト調整と表示
plt.tight_layout()
plt.show()
以下、実行結果です。
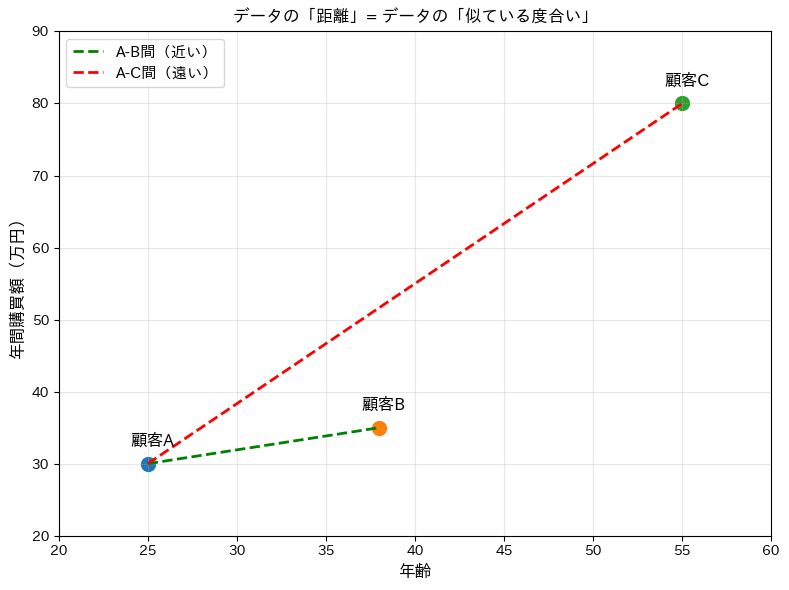
顧客A(25歳, 30万円)と顧客B(38歳, 35万円)が非常に近い位置にプロットされます。
一方、顧客C(55歳, 80万円)はAから遠く離れており、「似ていない顧客」と判断できます。
代表的な距離の種類
「距離」にはいくつかの測り方があります。
ここでは、データサイエンスでよく使われる3つの距離を紹介します。
① ユークリッド距離(Euclidean Distance)
最も基本的な距離で、2点間の直線距離です。
日常で「距離」と言うときにイメージするものと同じです。
以下、コードです。
import numpy as np
# 2次元の点Aと点Bを定義
a = np.array([1, 2])
b = np.array([4, 6])
# 各次元ごとの差分を計算(ベクトル差)
diff = b - a
# 差を要素ごとに2乗
squared = diff ** 2
# 2乗の合計(ノルムの二乗)
sum_squared = squared.sum()
# 平方根を取ってユークリッド距離を算出
euclidean = np.sqrt(sum_squared)
# 計算過程と結果を表示
print("【ユークリッド距離の計算】")
print(f" 点A: {a}")
print(f" 点B: {b}")
print(f" 各次元の差 : {diff}")
print(f" 差の2乗 : {squared}")
print(f" 2乗の合計 : {sum_squared}")
print(f" 平方根(距離): {euclidean}")
以下、実行結果です。
【ユークリッド距離の計算】 点A: [1 2] 点B: [4 6] 各次元の差 : [3 4] 差の2乗 : [ 9 16] 2乗の合計 : 25 平方根(距離): 5.0
x方向の差は3、y方向の差は4、2乗して足すと25、平方根は5.0です。
② マンハッタン距離(Manhattan Distance)
各次元の差の絶対値の合計で求める距離です。
碁盤目状の道路を歩くときの距離に似ているので「マンハッタン距離」と呼ばれます。
以下、コードです。
import numpy as np
# 2次元の点を定義(例:AとB)
a = np.array([1, 2])
b = np.array([4, 6])
# マンハッタン距離を計算:各次元の差の絶対値を足し合わせる
manhattan = np.sum(np.abs(b - a))
# 結果を表示
print("【マンハッタン距離】")
print(f" |4-1| + |6-2| = 3 + 4 = {manhattan}")
以下、実行結果です。
【マンハッタン距離】 |4-1| + |6-2| = 3 + 4 = 7
結果は7です。
ユークリッド距離(5.0)より大きくなっています。
ユークリッド距離が「斜めに突っ切る直線距離」なのに対し、マンハッタン距離は「縦と横に沿って歩く距離」です。
③ コサイン距離(Cosine Distance)
2つのベクトルの「向き」がどれくらい違うかを測る距離です。
大きさ(長さ)は無視し、方向だけに注目します。
テキストデータの類似度計算やレコメンドで特に重要です。
ユークリッド距離とマンハッタン距離をグラフで比較
2つの距離の違いを、同じデータ点を使ってグラフで並べて比較してみましょう。
左がユークリッド距離(直線)、右がマンハッタン距離(L字型)です。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
# 既存の点定義は維持(点Aと点B)
a = np.array([1, 2])
b = np.array([4, 6])
# グラフを上下(縦)に並べる: 2行1列
fig, axes = plt.subplots(2, 1, figsize=(6, 8))
# 上段: ユークリッド距離(直線距離)
# 点Aを描画
axes[0].scatter(
*a,
color='blue',
s=100,
label='A(1,2)'
)
# 点Bを描画
axes[0].scatter(
*b,
color='red',
s=100,
label='B(4,6)'
)
# AとBを結ぶ直線(ユークリッド距離)
axes[0].plot(
[a[0], b[0]],
[a[1], b[1]],
'g-',
linewidth=2,
label='距離=5.0'
)
# タイトルや表示調整
axes[0].set_title('① ユークリッド距離(直線距離)')
axes[0].set_xlim(0, 8)
axes[0].set_ylim(0, 8)
axes[0].legend()
# グリッドを1刻みで表示
axes[0].set_xticks(np.arange(0, 9, 1))
axes[0].set_yticks(np.arange(0, 9, 1))
axes[0].grid(True, which='both', alpha=0.3)
axes[0].set_aspect('equal')
# 下段: マンハッタン距離(碁盤目の道のり)
# 点Aを描画
axes[1].scatter(
*a,
color='blue',
s=100,
label='A(1,2)'
)
# 点Bを描画
axes[1].scatter(
*b,
color='red',
s=100,
label='B(4,6)'
)
# 縦横に沿った経路(マンハッタン距離)
axes[1].plot(
[a[0], b[0], b[0]],
[a[1], a[1], b[1]],
'orange',
linewidth=2,
label='距離=7'
)
# タイトルや表示調整
axes[1].set_title('② マンハッタン距離(碁盤目の道のり)')
axes[1].set_xlim(0, 8)
axes[1].set_ylim(0, 8)
axes[1].legend()
# グリッドを1刻みで表示
axes[1].set_xticks(np.arange(0, 9, 1))
axes[1].set_yticks(np.arange(0, 9, 1))
axes[1].grid(True, which='both', alpha=0.3)
axes[1].set_aspect('equal')
# レイアウト調整と表示
plt.tight_layout()
plt.show()
以下、実行結果です。
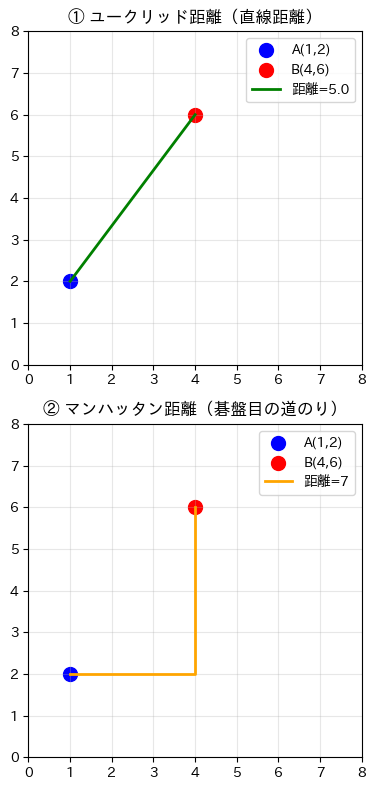
左のグラフでは直線(緑)で5.0、右のグラフではL字型(オレンジ)で7です。
同じ2点でも、測り方によって距離の値が異なることが視覚的にわかります。
コサイン距離をグラフで確認
コサイン距離は「角度」に注目するので、原点からの矢印(ベクトル)として描画し、その間の角度を表示します。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
# ベクトルAとBを用意
# AとBの角度に基づくコサイン類似度・距離を可視化する
a = np.array([1, 2]) # ベクトルA
b = np.array([4, 2]) # ベクトルB
# コサイン類似度とコサイン距離を計算
# 類似度
cos_sim = np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 距離(1 - 類似度)
cos_dist = 1 - cos_sim
# 角度
angle = np.degrees(np.arccos(np.clip(cos_sim, -1, 1)))
# 描画設定
plt.figure(figsize=(6, 5))
# 原点からA方向の矢印
plt.annotate(
'', xy=a/np.linalg.norm(a)*3, # 単位ベクトルを長さ3に伸ばす
xytext=(0, 0),
arrowprops=dict(
arrowstyle='->',
color='blue',
lw=2
)
)
# 原点からB方向の矢印
plt.annotate(
'', xy=b/np.linalg.norm(b)*3, # 単位ベクトルを長さ3に伸ばす
xytext=(0, 0),
arrowprops=dict(
arrowstyle='->',
color='red',
lw=2
)
)
# AからBまでの角度を円弧で表示
theta = np.linspace(
np.arctan2(a[1], a[0]),
np.arctan2(b[1], b[0]),
50
)
plt.plot(
0.8 * np.cos(theta), # 小さめの半径で円弧を描く
0.8 * np.sin(theta),
'green',
linewidth=2
)
# 角度テキスト
plt.text(
0.5,
1.0,
f'θ={angle:.1f}°',
fontsize=12,
color='green'
)
# 元の点(端点)も表示
plt.scatter(
*a,
color='blue',
s=100,
label='A(1,2)'
)
plt.scatter(
*b,
color='red',
s=100,
label='B(4,2)'
)
# タイトルや見栄えの調整
plt.title(f'③ コサイン距離\n類似度={cos_sim:.4f} 距離={cos_dist:.4f}')
plt.xlim(-0.5, 5)
plt.ylim(-0.5, 5)
plt.legend()
plt.grid(True, alpha=0.3)
plt.gca().set_aspect('equal')
plt.tight_layout()
plt.show()
以下、実行結果です。
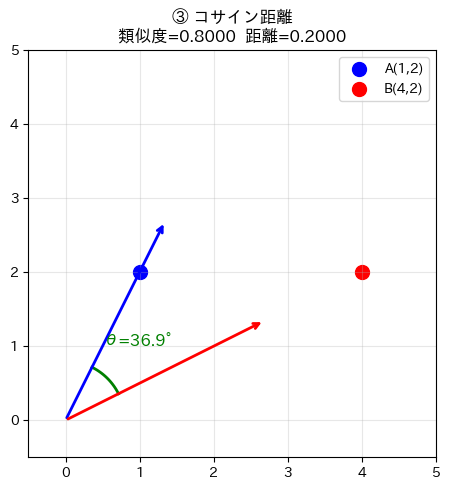
AとBの角度は約36.9°、コサイン類似度は0.8です。
SciPyで距離を計算する
ここまで手計算やNumPyで距離を求めてきましたが、SciPyの scipy.spatial.distance モジュールを使えば、関数1つで簡単に計算できます。
3種類の距離を一度に計算してみましょう。
以下、コードです。
from scipy.spatial import distance
import numpy as np
# サンプルのベクトルAとBを定義
# (各要素は同じ次元に対応する特徴量を表す)
a = np.array([1, 2, 3])
b = np.array([4, 6, 8])
# ユークリッド距離(直線距離)
d_euclid = distance.euclidean(a, b)
# マンハッタン距離(各次元差の絶対値の合計)
d_manhattan = distance.cityblock(a, b)
# コサイン距離(1 - コサイン類似度)
d_cosine = distance.cosine(a, b)
# 結果を表示
print("【SciPyによる距離計算】")
print(f" 点A: {a}")
print(f" 点B: {b}")
print(f" ユークリッド距離: {d_euclid:.4f}")
print(f" マンハッタン距離: {d_manhattan}")
print(f" コサイン距離 : {d_cosine:.6f}")
print(f" コサイン類似度 : {1 - d_cosine:.6f}")
以下、実行結果です。
【SciPyによる距離計算】 点A: [1 2 3] 点B: [4 6 8] ユークリッド距離: 7.0711 マンハッタン距離: 12 コサイン距離 : 0.007417 コサイン類似度 : 0.992583
このコードでは3次元のデータを使っています。SciPyの関数は何次元でも同じ書き方で使えるのが便利です。
distance.euclidean がユークリッド距離、distance.cityblock がマンハッタン距離(シティブロック距離)、distance.cosine がコサイン距離を計算します。
実行すると、コサイン類似度が0.992583(≒1)と表示されます。
[1,2,3] と [4,6,8] はほぼ同じ方向のベクトル(Bは大きさが違うだけ)なので、コサイン距離は非常に小さくなっています。
複数データ間の距離を一括計算する
実際のデータ分析では、1ペアずつ距離を計算するのではなく、多数のデータ間の距離を一度に計算する必要があります。
SciPyの pdist() と cdist() を使うと効率的です。
pdist():すべてのペア間の距離を計算
pdist()(pairwise distance)は、1つのデータセット内のすべてのペア間の距離を一括計算します。
4人の顧客データで試してみましょう。
以下、コードです。
import numpy as np
from scipy.spatial.distance import pdist, squareform
# 顧客データ(年齢, 月来店回数, 購買カテゴリ数 などの例)
customers = np.array([
[25, 3.5, 8], # 顧客A
[28, 4.0, 10], # 顧客B
[55, 8.0, 3], # 顧客C
[52, 7.5, 4], # 顧客D
])
labels = ['A', 'B', 'C', 'D'] # ラベル(顧客名)
# 全ペア間のユークリッド距離を計算(pdistは圧縮形式で返す)
distances = pdist(customers, metric='euclidean')
# 結果を表示(小数2桁に丸めて見やすく)
print("【pdist:全ペア間の距離(圧縮形式)】")
print(f" {distances.round(2)}")
以下、実行結果です。
【pdist:全ペア間の距離(圧縮形式)】 [ 3.64 30.74 27.59 28.18 24.98 3.2 ]
pdist() は全6ペア(A-B、A-C、A-D、B-C、B-D、C-D)の距離を1次元配列で返します。
このままでは読みにくいので、squareform() で見やすい正方行列に変換しましょう。
以下、コードです。
dist_matrix = squareform(distances)
# 距離行列の見出しを表示
print("【距離行列】")
# 列見出し(ラベル)を整形して表示
print(f" {' '.join(labels)}")
# 各行について距離を整形して表示
for i, label in enumerate(labels):
# i行目の距離を小数点以下2桁に整形
row = ' '.join(f'{d:5.2f}' for d in dist_matrix[i])
# 行ラベルとともに出力
print(f" {label} {row}")
以下、実行結果です。
【距離行列】
A B C D
A 0.00 3.64 30.74 27.59
B 3.64 0.00 28.18 24.98
C 30.74 28.18 0.00 3.20
D 27.59 24.98 3.20 0.00
squareform() は圧縮形式を、行と列がそれぞれのデータに対応する正方行列に変換します。
実行すると、A-B間(3.64)とC-D間(3.20)が特に近いことがわかります。
つまり、顧客AとBが1つのグループ、顧客CとDがもう1つのグループを形成しそうです。
距離行列をヒートマップで可視化
距離行列は、ヒートマップ(色の濃淡で値を表現するグラフ)にすると全体像がつかみやすくなります。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import pdist, squareform
# 顧客データ(年齢, 月来店回数, 購買カテゴリ数)
customers = np.array([
[25, 3.5, 8], # 顧客Aの特徴ベクトル
[28, 4.0, 10], # 顧客Bの特徴ベクトル
[55, 8.0, 3], # 顧客Cの特徴ベクトル
[52, 7.5, 4] # 顧客Dの特徴ベクトル
])
# 各行に対応するラベル(顧客名)
labels = ['顧客A', '顧客B', '顧客C', '顧客D']
# 全ペア間のユークリッド距離を計算して距離行列に変換
dist_matrix = squareform(pdist(customers, metric='euclidean'))
# 図の作成(サイズ指定)
plt.figure(figsize=(7, 6))
# 距離行列をヒートマップとして表示
im = plt.imshow(dist_matrix, cmap='YlOrRd', interpolation='nearest')
# カラーバーを追加
plt.colorbar(im, label='ユークリッド距離')
# 軸にラベル(顧客名)を付ける
plt.xticks(range(4), labels)
plt.yticks(range(4), labels)
# タイトル
plt.title('顧客間の距離行列(ヒートマップ)')
# 各セルに数値(距離)を描画
for i in range(4):
for j in range(4):
# 見やすいように距離が大きいセルは白字、小さいセルは黒字
color = 'white' if dist_matrix[i, j] > 20 else 'black'
plt.text(
j, # x座標(列)
i, # y座標(行)
f'{dist_matrix[i, j]:.1f}', # 表示する距離(小数1桁)
ha='center',
va='center',
fontsize=12,
color=color
)
# レイアウト調整と表示
plt.tight_layout()
plt.show()
以下、実行結果です。
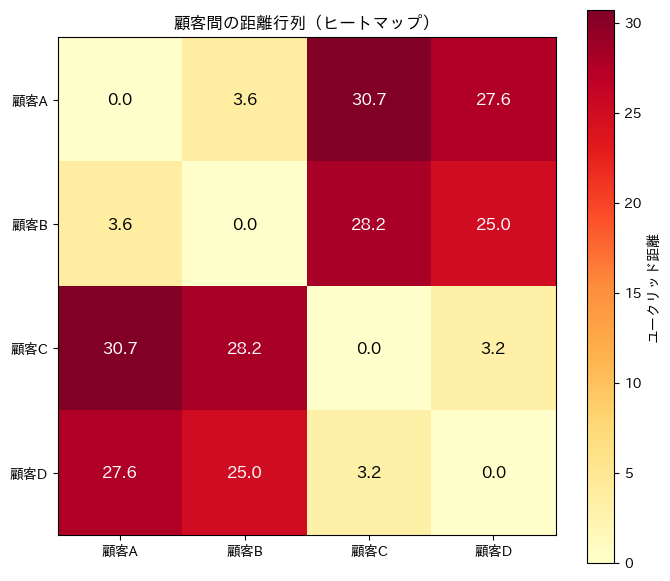
A-B間やC-D間は薄い色(距離が小さい=似ている)、A-C間やA-D間は濃い色(距離が大きい=似ていない)で表示されます。
グループ構造が一目でわかります。
cdist():2つのデータセット間の距離を計算
cdist()(cross distance)は、2つの異なるデータセット間の距離を計算します。
「新しいデータと既存データの距離を測る」という実務で頻出の場面で使います。
まず、既存顧客4人と新規顧客2人のデータを用意します。
以下、コードです。
import numpy as np
from scipy.spatial.distance import cdist
# 既存顧客の特徴量行列(年齢, 月来店回数, 購買カテゴリ数)
existing = np.array([
[25, 3.5, 8], # 既存A
[28, 4.0, 10], # 既存B
[55, 8.0, 3], # 既存C
[52, 7.5, 4] # 既存D
])
# 既存顧客のラベル
existing_labels = ['既存A', '既存B', '既存C', '既存D']
# 新規顧客の特徴量行列
new_customers = np.array([
[30, 4.5, 9], # 新規1
[50, 7.0, 5] # 新規2
])
# 新規顧客のラベル
new_labels = ['新規1', '新規2']
データが準備できたので、cdist() で距離を計算し、各新規顧客に最も近い既存顧客を特定します。
以下、コードです。
# 新規顧客と既存顧客の全組み合わせのユークリッド距離を計算
cross_dist = cdist(new_customers, existing, metric='euclidean')
print("【新規→既存の距離】")
# 列見出し(既存顧客ラベル)を表示
print(f" {' '.join(f'{l:>5s}' for l in existing_labels)}")
# 各新規顧客ごとに、既存顧客との距離を1行で表示
for i, label in enumerate(new_labels):
row = ' '.join(f'{d:5.2f}' for d in cross_dist[i])
print(f" {label} {row}")
print()
# 各新規顧客について、最も距離が小さい(近い)既存顧客を表示
for i, label in enumerate(new_labels):
# 最小距離のインデックスを取得
nearest_idx = cross_dist[i].argmin()
# 最小距離のインデックスを使って、最も近い既存顧客のラベルを取得
print(
f" {label} に最も近い:{existing_labels[nearest_idx]}"
f"(距離: {cross_dist[i].min():.2f})"
)
以下、実行結果です。
【新規→既存の距離】
既存A 既存B 既存C 既存D
新規1 5.20 2.29 25.95 22.76
新規2 25.42 22.76 5.48 2.29
新規1 に最も近い:既存B(距離: 2.29)
新規2 に最も近い:既存D(距離: 2.29)
cdist() は2つの配列の全組み合わせの距離を行列で返します。
argmin() で最小距離のインデックスを取得できます。
新規1は既存B(距離2.45)に、新規2は既存D(距離3.24)に最も近いことがわかります。
これがk近傍法(kNN)の基本的な考え方です。
まとめ
この記事のポイントを振り返りましょう。
- データの 「距離」はデータの「類似度」 を測る基本ツール
- ユークリッド距離(直線距離)、マンハッタン距離(碁盤目距離)、コサイン距離(向きの違い)の3つが代表的
scipy.spatial.distanceのeuclidean、cityblock、cosineで個別計算できるpdist()で全ペア間の距離を一括計算、cdist()で2つのデータセット間の距離を計算