
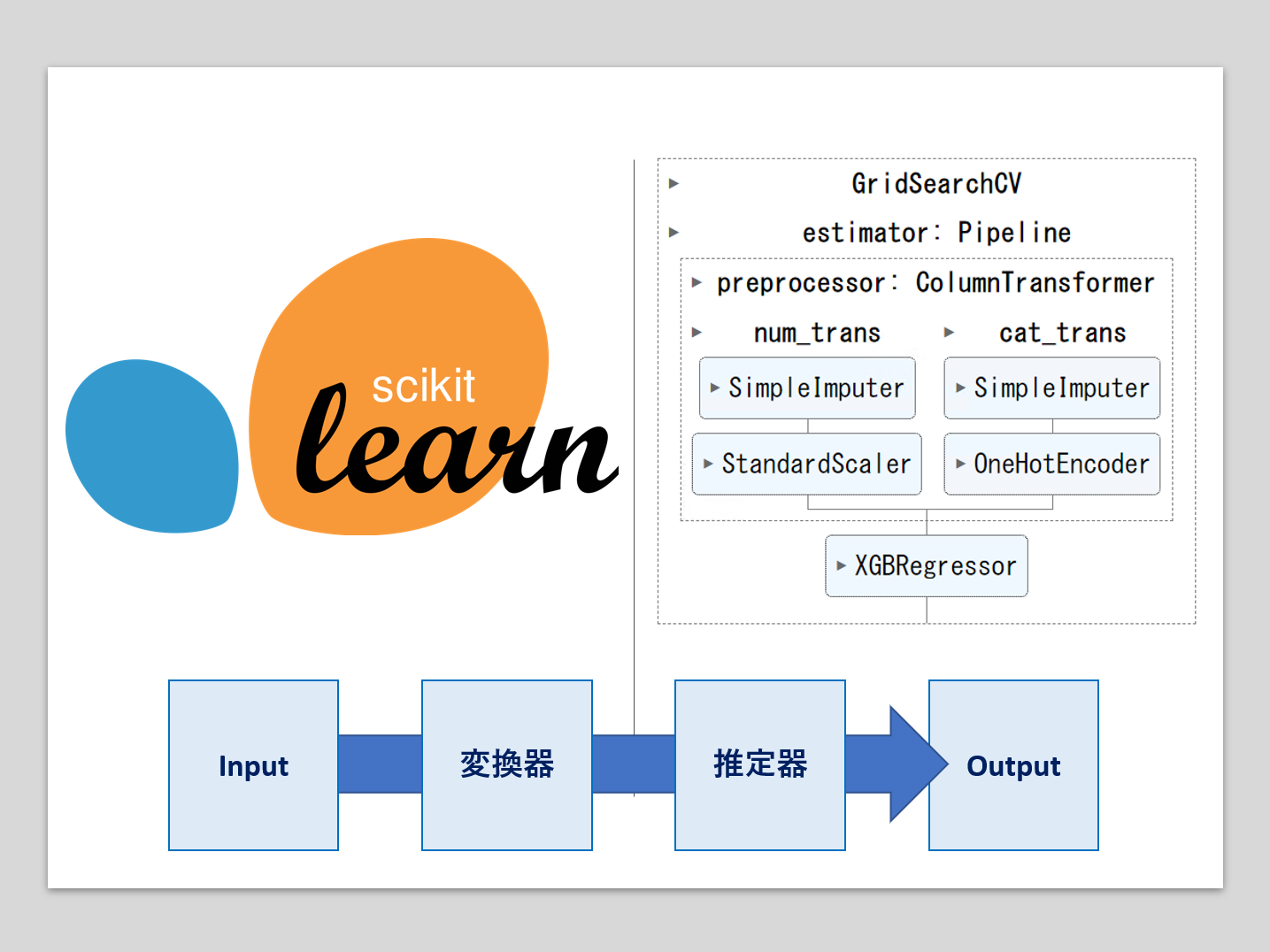
機械学習のパイプラインとは、複数の処理を直列に連結したものです。
最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。

- 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Transformor)
- 推定器:線形回帰モデルやXGBoostなどの数理モデルを使い、目的変数yの予測を実施(Estimator)
多くの場合、Inputは特徴量(説明変数)Xで、Outputは目的変数yの予測値です。
多くはscikit-learnの中にある既存の変換器で十分ですが、作りたい機械学習パイプラインによっては、自作の変換器(カスタマイズ変換器)を使いたいこともあります。
前回は、自作の変換器(カスタマイズ変換器)を、自作関数かららくらく作れるFunctionTransformerについて紹介しました。
scikit-learnの機械学習パイプライン入門(その2:自作関数をFunctionTransformerで変換器にする)
しかし、FunctionTransformerで作れる変換器には限界があります。
ちょっと複雑な処理が求められる変換器を作るとき、一からカスタム変換器(Custom Transformer)を作るのがいいでしょう。
今回は、一からカスタム変換器(Custom Transformer)の作り方を説明します。
Contents
BaseEstimator と TransformerMixin を継承する
カスタム変換器(Custom Transformer)を作るとき、sklearn.base クラスである BaseEstimator と TransformerMixin を継承した Python クラスを定義しています。
ちなみにクラスを継承するとは、既存のクラス(親クラスやベースクラスとも呼ばれます)のプロパティやメソッドを新しいクラス(子クラスや派生クラスとも呼ばれます)に引き継ぐプログラミングの概念です。
要は、BaseEstimator と TransformerMixin を継承したカスタム変換器(Custom Transformer)は、BaseEstimator と TransformerMixin の便利な機能を利用することができます。
ここでこれ以上詳しく説明はしませんが、例えば以下の機能が使えるようになります。
- BaseEstimator:get_params()とset_params()メソッドが利用できるようになる。これらはモデルのパラメータの取得と設定に使用
- TransformerMixin:fit_transform()メソッドが利用できるようになる。これは、データに対してfit()とtransform()を一度に行うメソッド
fit()メソッドとtransform()メソッドについて、例とともに説明します。
以下は、カスタム変換器(Custom Transformer)の作成例です。Custom Transformerの箇所は任意の名称で構いません。
class CustomTransformer(BaseEstimator, TransformerMixin):
def __init__(self, param1=1):
self.param1 = param1
# fitメソッドは、データXに基づいて変換器を設定するために使用されます。
# ここでは何も学習しないので、自分自身を返します。
def fit(self, X, y=None):
return self
# transformメソッドは、fitメソッドで学習した情報を用いてデータXを変換します。
# ここではXにparam1を掛けた結果を返します。
def transform(self, X):
return X * self.param1
# inverse_transformメソッドは、変換されたデータを元の形に戻すためのメソッドです。
# ここではXをparam1で割った結果を返します。
def inverse_transform(self, X):
return X / self.param1
ここで作成したCustomTransformerは、パラメータ(param1)で掛ける(変換する)という簡単な例です。
- __init__:通常はクラスが初期化される際に必要な設定を行います。今回の例では、パラメータ(param1)の値を設定します。
- fit()メソッド:データに基づいて必要なパラメータを学習するために使用されます。今回の例では、学習が発生しないので「return self」と自分自身を返します。
- transform()メソッド:fit()メソッドで学習したパラメータを用いてデータの変換を行います。今回の例では、学習が発生しないので、fit()による学習の結果は利用していません。
- inverse_transform()メソッド:変換したデータを元に戻すためのメソッドです。この例では変換されたデータをパラメータで割ることで元のデータに戻しています。このメソッドは必須ではありませんが、変換後のデータから元のデータを復元したい場合に便利です。
fit_transform()メソッドというものもあります。これはfit()とtransform()を一度に行うメソッドで、TransformerMixinを継承することで自動的に利用できます。
以上のように、自分で定義したカスタム変換器を作成することで、scikit-learnの機能を拡張し、自分だけのデータ変換処理を追加することができます。
準備(モジュールとデータの読み込み)
必要なモジュールを読み込みます。
以下、コードです。
# 基本的なモジュール import numpy as np import pandas as pd # 例で利用するデータセット取得 from sklearn.datasets import fetch_openml # カスタム変換器のための道具 from sklearn.base import BaseEstimator, TransformerMixin # BoxCox変換器 from sklearn.preprocessing import PowerTransformer # パイプライン構築のための道具 from sklearn.pipeline import Pipeline # データ分割用の関数 from sklearn.model_selection import train_test_split # 評価指標(正答率) from sklearn.metrics import accuracy_score # 今回、推定器として利用 import xgboost as xgb
今回利用するタイタニック(titanic)のデータセットを読み込みます。
以下、コードです。
# タイタニック(titanic)のデータセット dataset = fetch_openml(data_id=40945, parser='auto') df = dataset['frame'] print(df) #確認
以下、実行結果です。
pclass survived name \
0 1 1 Allen, Miss. Elisabeth Walton
1 1 1 Allison, Master. Hudson Trevor
2 1 0 Allison, Miss. Helen Loraine
3 1 0 Allison, Mr. Hudson Joshua Creighton
4 1 0 Allison, Mrs. Hudson J C (Bessie Waldo Daniels)
... ... ... ...
1304 3 0 Zabour, Miss. Hileni
1305 3 0 Zabour, Miss. Thamine
1306 3 0 Zakarian, Mr. Mapriededer
1307 3 0 Zakarian, Mr. Ortin
1308 3 0 Zimmerman, Mr. Leo
sex age sibsp parch ticket fare cabin embarked boat \
0 female 29.0000 0 0 24160 211.3375 B5 S 2
1 male 0.9167 1 2 113781 151.5500 C22 C26 S 11
2 female 2.0000 1 2 113781 151.5500 C22 C26 S NaN
3 male 30.0000 1 2 113781 151.5500 C22 C26 S NaN
4 female 25.0000 1 2 113781 151.5500 C22 C26 S NaN
... ... ... ... ... ... ... ... ... ...
1304 female 14.5000 1 0 2665 14.4542 NaN C NaN
1305 female NaN 1 0 2665 14.4542 NaN C NaN
1306 male 26.5000 0 0 2656 7.2250 NaN C NaN
1307 male 27.0000 0 0 2670 7.2250 NaN C NaN
1308 male 29.0000 0 0 315082 7.8750 NaN S NaN
body home.dest
0 NaN St Louis, MO
1 NaN Montreal, PQ / Chesterville, ON
2 NaN Montreal, PQ / Chesterville, ON
3 135.0 Montreal, PQ / Chesterville, ON
4 NaN Montreal, PQ / Chesterville, ON
... ... ...
1304 328.0 NaN
1305 NaN NaN
1306 304.0 NaN
1307 NaN NaN
1308 NaN NaN
[1309 rows x 14 columns]
このデータセットは、1912年に大西洋で氷山に衝突し沈没したタイタニック号の乗客者の生存状況に関するデータセットです。

- pclass: 旅客クラス(1=1等、2=2等、3=3等)
- name: 乗客の名前
- sex: 性別(male=男性、female=女性)
- age: 年齢
- sibsp: タイタニック号に同乗している兄弟(Siblings)や配偶者(Spouses)の数
- parch: タイタニック号に同乗している親(Parents)や子供(Children)の数
- ticket: チケット番号
- fare: 旅客運賃
- cabin: 客室番号
- embarked: 出港地(C=Cherbourg:シェルブール、Q=Queenstown:クイーンズタウン、S=Southampton:サウサンプトン)
- boat: 救命ボート番号
- body: 遺体収容時の識別番号
- home.dest: 自宅または目的地
- survived:生存状況(0=死亡、1=生存)
目的変数はsurvived(生存状況)で、残りの変数が説明変数Xです。
カスタム変換器の作成例
タイタニック(titanic)のデータセットに対する、以下の3つのカスタム変換器を作っていきます。
- 作成例1:変数選択
- 作成例2:欠測値処理
- 作成例3:Box-Cox変換
少しずつ難しくなってきます。
作成例1:変数選択
データフレームの変数(カラム)をフィルタリングするためのカスタム変換器ColumnFilterTransformerを作成します。
以下、コードです。
class ColumnFilterTransformer(BaseEstimator, TransformerMixin):
def __init__(self, columns=[]):
self.columns = columns
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.columns]
この変換器はcolumnsというパラメータを受け取ります。fitメソッドでは特に何も行いませんが、transformメソッドでは指定されたカラムのみを抽出して新しいデータフレームを返します。
以下は、この変換器を使用する例です。
以下、コードです。
# 選択した変数 columns_to_keep = ['age','fare','sibsp','parch'] # インスタンスの生成 transformer = ColumnFilterTransformer(columns=columns_to_keep) # 変換器の適用 filtered_df = transformer.transform(df) print(filtered_df) #確認
以下、実行結果です。
age fare sibsp parch 0 29.0000 211.3375 0 0 1 0.9167 151.5500 1 2 2 2.0000 151.5500 1 2 3 30.0000 151.5500 1 2 4 25.0000 151.5500 1 2 ... ... ... ... ... 1304 14.5000 14.4542 1 0 1305 NaN 14.4542 1 0 1306 26.5000 7.2250 0 0 1307 27.0000 7.2250 0 0 1308 29.0000 7.8750 0 0 [1309 rows x 4 columns]
上記の例では、columns_to_keepというリストに’age’と’fare’が指定され、この変数のみを抽出して新しいデータフレームが作成されます。
欠測値の数を数えてみます。
以下、コードです。
# 欠測値の数 filtered_df.isnull().sum()
以下、実行結果です。
age 263 fare 1 sibsp 0 parch 0 dtype: int64
欠測値があるため、何らかの処理をする必要があります。
例えば、各変数の欠測値をその変数の中央値で補完する、といった処理です。
作成例2:欠測値処理
各変数の欠測値をその変数の中央値で補完する変換器を作ります。
すでに、Scikit-learnには欠測値補完をするSimpleImputer()クラスがあるため自作する必要はありませんが、ここでは自作します。
以下、コードです。
class CustomMedianImputer(BaseEstimator, TransformerMixin):
def __init__(self):
self.medians_ = None
def fit(self, X, y=None):
# X is expected to be a DataFrame
self.medians_ = X.median()
return self
def transform(self, X, y=None):
# X is expected to be a DataFrame
X_copy = X.copy()
for column in X_copy.columns:
X_copy[column].fillna(self.medians_[column], inplace=True)
return X_copy
このCustomMedianImputer変換器は、fitメソッドで入力データXの各列の中央値を計算し、これらの値をインスタンス変数に保存します。その後、transformメソッドで、各列の欠測値(NaN)をその列の中央値で置き換えます。
以下は、この変換器を使用する例です。
以下、コードです。
# インスタンスの生成 imputer = CustomMedianImputer() # 変換器の学習 imputer.fit(filtered_df) # 変換器の適用 imputed_data = imputer.transform(filtered_df) print(imputed_data) #確認
以下、実行結果です。
age fare sibsp parch 0 29.0000 211.3375 0 0 1 0.9167 151.5500 1 2 2 2.0000 151.5500 1 2 3 30.0000 151.5500 1 2 4 25.0000 151.5500 1 2 ... ... ... ... ... 1304 14.5000 14.4542 1 0 1305 28.0000 14.4542 1 0 1306 26.5000 7.2250 0 0 1307 27.0000 7.2250 0 0 1308 29.0000 7.8750 0 0 [1309 rows x 4 columns]
欠測値の数を数えてみます。
以下、コードです。
# 欠測値の数 imputed_data.isnull().sum()
以下、実行結果です。
age 0 fare 0 sibsp 0 parch 0 dtype: int64
欠測値がなくなりました。
作成例3:Box-Cox変換
データの変換を行う際にべき乗変換(power transform)をすることがあります。
有名なところでは、対数変換(log)を一般化したBox-Cox変換です。
ちなみに、Box-Cox変換は、正規分布から逸脱した分布を持つデータを、より正規分布に近づけるために使用されます。
scikit-learnには、PowerTransformerというクラスがあらかじめ準備されています。
対数変換(log)やBox-Cox変換は、0に対し変換をすることができません。
そのため、これらの変換の前処理として、例えば0以上のデータに対し1を足し対処することがあります。
そのような処理を含んだカスタム変換器を作っていきます。要は、既に存在する変換器をもとに新しい変換器を作る、ということです。
以下、コードです。
class CustomBoxCoxTransformer(BaseEstimator, TransformerMixin):
def __init__(self):
self._estimators = {}
def fit(self, X, y=None):
X_copy = X.copy()
for column in X_copy.columns:
X_copy[column] += 1
estimator = PowerTransformer()
self._estimators[column] = estimator.fit(np.array(X_copy[column]).reshape(-1, 1))
return self
def transform(self, X):
X_copy = X.copy()
for column in X_copy.columns:
X_copy[column] += 1
X_copy[column] = self._estimators[column].transform(np.array(X_copy[column]).reshape(-1, 1))
return X_copy
def inverse_transform(self, X):
X_copy = X.copy()
for column in X_copy.columns:
X_copy[column] = self._estimators[column].inverse_transform(np.array(X_copy[column]).reshape(-1, 1))
X_copy[column] -= 1
return X_copy
ちょっと複雑になったので、中身について以下で簡単に説明します。
- __init__:変換器を初期化します。ここでは、各列に対応するPowerTransformerのインスタンスを保持する辞書を作成します。
- fit:データフレームの各列に対してBox-Cox変換を適用するために必要なパラメータを学習します。各列に対して個別にPowerTransformerをfitさせ、それぞれのインスタンスを辞書に保存します。Box-Cox変換は非負の値に対してのみ適用可能であるため、列の値に1を加えてすべての値が正になるようにします。
- transform:fitメソッドで学習したパラメータを使用して、データフレームの各列に対してBox-Cox変換を適用します。またここでも、変換前に各列の値に1を加えます。
- inverse_transform:Box-Cox変換の逆変換を行います。これにより、変換されたデータを元のスケールに戻すことができます。逆変換後、各列の値から1を引きます。
この変換器はデータフレーム全体に対してBox-Cox変換とその逆変換を適用することができます。
なお、Box-Cox変換はデータが正の値を持つことを前提としています。そのため、この変換器では変換前に1を加え、逆変換後に1を引く操作を行っています。
以下は、この変換器を使用する例です。
以下、コードです。
# インスタンスの生成 boxcox_trans = CustomBoxCoxTransformer() # 変換器の学習 boxcox_trans.fit(imputed_data) # 変換器の適用 transformed_data = boxcox_trans.transform(imputed_data) print(transformed_data) #確認
以下、実行結果です。
age fare sibsp parch 0 0.012524 2.106427 -0.681878 -0.553158 1 -2.583499 1.893590 1.361687 1.884514 2 -2.444805 1.893590 1.361687 1.884514 3 0.089024 1.893590 1.361687 1.884514 4 -0.299485 1.893590 1.361687 1.884514 ... ... ... ... ... 1304 -1.177474 -0.175955 1.361687 -0.553158 1305 -0.064552 -0.175955 1.361687 -0.553158 1306 -0.181299 -0.947454 -0.681878 -0.553158 1307 -0.142228 -0.947454 -0.681878 -0.553158 1308 0.012524 -0.850326 -0.681878 -0.553158 [1309 rows x 4 columns]
推定器と連携しパイプラインを学習しよう
データ準備
目的変数yと説明変数Xに分けます。
以下、コードです。
# 目的変数yと説明変数X
y = df['survived'].astype(int) #目的変数y(整数型)
X = df.drop('survived', axis=1) #説明変数X
次に、学習データとテストデータに分割します。
以下、コードです。
# データセットの分割(学習データとテストデータ)
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.3,
random_state=123)
目的変数yは「survived」(生存状況)で、生存を予測する分類問題です。数理モデルは、XGBoostを利用します。
パイプラインの定義
変数「age」「fare」「sibsp」「parch」に対し、パイプラインを構築します。
以下、コードです。
# 選択した変数
columns_to_keep = ['age','fare','sibsp','parch']
# パイプラインの定義
titanic_pipeline = Pipeline(
steps=[
("filter", ColumnFilterTransformer(columns_to_keep)),
("imputer", CustomMedianImputer()),
("boxcoxtrans", CustomBoxCoxTransformer()),
("estimator", xgb.XGBClassifier()),
]
)
学習とテスト
このパイプラインを学習します。
以下、コードです。
# 選択した変数
columns_to_keep = ['age','fare','sibsp','parch']
# パイプラインの定義
titanic_pipeline = Pipeline(
steps=[
("filter", ColumnFilterTransformer(columns_to_keep)),
("imputer", CustomMedianImputer()),
("boxcoxtrans", CustomBoxCoxTransformer()),
("estimator", xgb.XGBClassifier()),
]
)
以下、実行結果です。

テストデータで評価します。
以下、コードです。
# 目的変数yの予測 pred_y = titanic_pipeline.predict(X_test) # 正答率 accuracy_score(y_test, pred_y)
以下、実行結果です。
0.6997455470737913
パイプラインのパラメータを変更
パイプラインのパラメータを変更し、パイプラインを学習します。
ちなみに、このパイプラインのパラメータは、filterのcolumnsのみです。
このパラメータをいじることで、変数「age」「fare」に対するパイプラインに変更します。
以下、コードです。
# 選択した変数
columns_to_keep = ['age','fare']
# パイプラインにパラメータを設定
params = {'filter__columns':columns_to_keep}
titanic_pipeline.set_params(**params)
# パイプラインの学習
titanic_pipeline.fit(X_train, y_train)
以下、実行結果です。
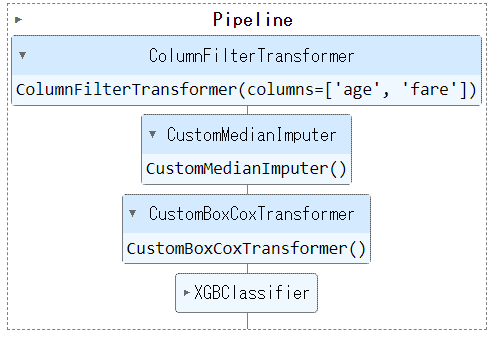
テストデータで評価します。
以下、コードです。
# 目的変数yの予測 pred_y = titanic_pipeline.predict(X_test) # 正答率 accuracy_score(y_test, pred_y)
以下、実行結果です。
0.6895674300254453
まとめ
今回は、一からカスタム変換器(Custom Transformer)の作り方を説明しました。
多くはscikit-learnの中にある既存の変換器で十分ですが、作りたい機械学習パイプラインによっては、自作の変換器(カスタマイズ変換器)を使いたいこともあります。
このような場合、自作の変換器(カスタマイズ変換器)づくりにチャレンジしてみてください。