
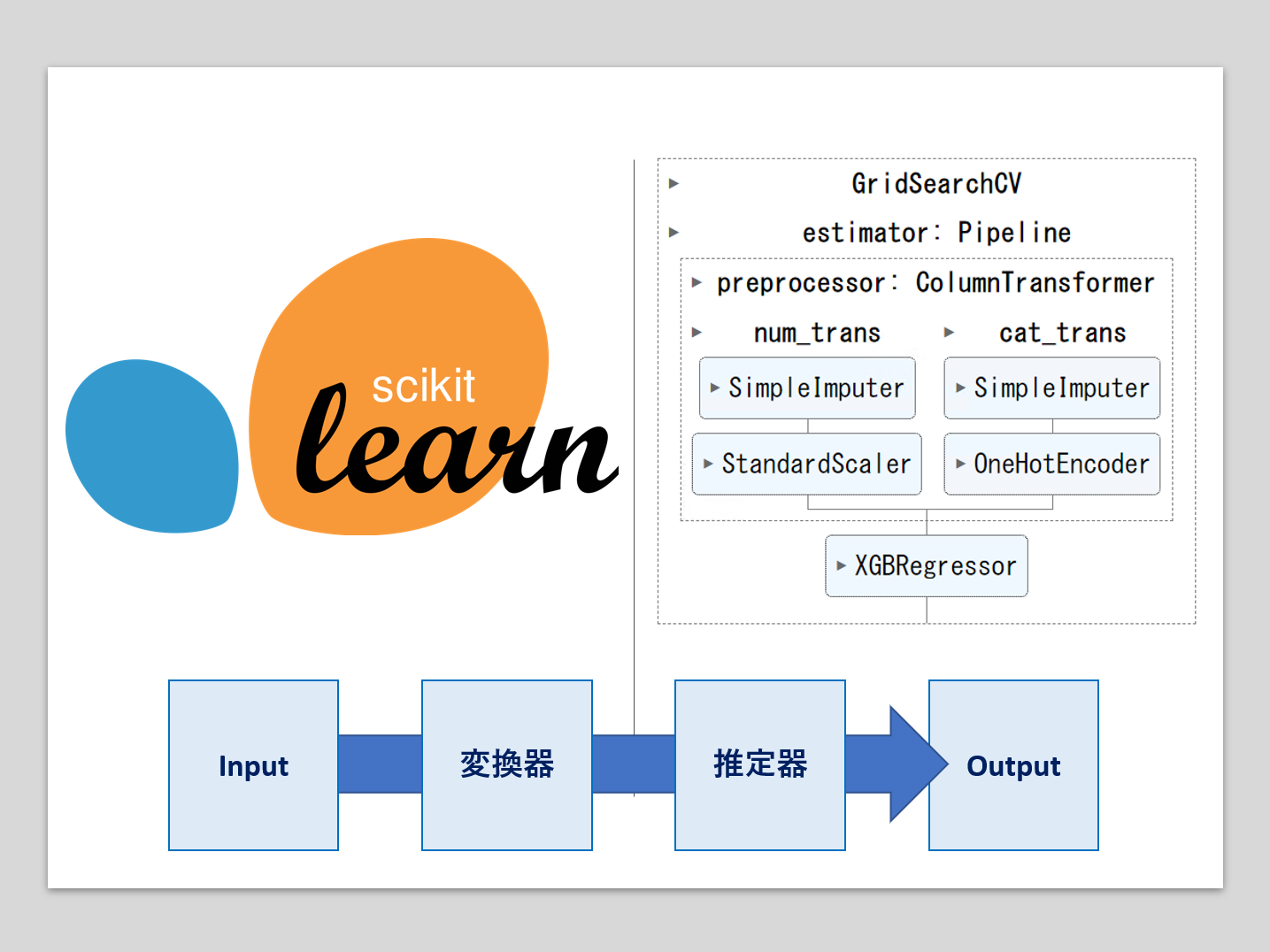
機械学習のパイプラインとは、複数の処理を直列に連結したものです。
最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。

- 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Transformor)
- 推定器:線形回帰モデルやXGBoostなどの数理モデルを使い、目的変数yの予測を実施(Estimator)
多くの場合、Inputは特徴量(説明変数)Xで、Outputは目的変数yの予測値です。
前回は、カスタム変換器(Custom Transformer)の作り方を説明しました。
scikit-learnの機械学習パイプライン入門(その3:カスタム変換器 – Custom Transformer -)
多くの場合、Inputは特徴量(説明変数)Xは、通常は1変数ではなく多変数です。
| 顧客ID | 商品の品質評価 | サービスの評価 | 総合満足度 |
|---|---|---|---|
| 1 | 1 | 2 | 3.0 |
| 2 | 5 | 3 | 1.0 |
| 3 | 2 | 5 | 2.0 |
| 4 | 1 | 4 | 3.0 |
| 5 | 4 | 3 | 1.0 |
| 6 | 4 | 1 | 3.0 |
| 7 | 4 | 1 | 2.0 |
| 8 | 4 | 1 | 2.0 |
| 9 | 2 | 3 | 3.0 |
| 10 | 4 | 4 | 1.0 |
全ての変数に対し同じ変換を施すこともあるでしょう。
しかし、いつも全ての変数に対し同じ変換を施すわけでもありません。
例えば、量的変数と質的変数に対する前処理は異なります。
量的変数と質的変数に対する前処理の例について、「その1:変換器と推定器でパイプラインを作ってみよう」で簡単にお話したとともに、Pythonのコード例も示しました。
今回は、「その1:変換器と推定器でパイプラインを作ってみよう」でお話しした内容を復習しつつ、変数ごとに処理を変える方法についてお話しします。
Contents
復習
「その1:変換器と推定器でパイプラインを作ってみよう」でお話しした内容を、簡単に復習します。
利用するデータセット
利用するデータは、DAT8コース(2015年にワシントンDCで開催されたデータサイエンスコース)のBike Sharing Demand(CSVファイル)です。
簡単に変数について説明します。
以下、データ項目です。
- datetime – 日時
- season
- 1 = 春
- 2 = 夏
- 3 = 秋
- 4 = 冬
- holiday – その日が休日であるかどうか
- workingday – その日が週末でも休日でもない日かどうか
- weather
- 1:晴れ、雲少ない、部分的に曇り、部分的に曇り
- 2: 霧+曇り、霧+切れ落ちた雲、霧+少ない雲、霧
- 3:小雪、小雨+雷雨+雲が散らばる、小雨+雲が散らばる
- 4:大雨+氷柱+雷雨+霧、雪+霧
- temp – 気温(摂氏)。
- atemp – 体感温度
- humidity – 相対湿度
- windspeed – 風の速さ
- casual – 非登録ユーザーによるレンタル開始数
- registered – 登録ユーザーによるレンタル開始数
- count – 総レンタル数
最後の方にある「casual」「registered」「count」が目的変数で、他が特徴量(説明変数)です。
今回は、「casual」を目的変数に設定しています。
特徴量(説明変数)には、量的変数と質的変数があります。
- 量的変数:temp、atemp、humidity、windspeed
- 質的変数:season、holiday、workingday、weather
量的変数に対し、以下の欠測値補完処理を実施し、その後に変数変換を実施します。
- 平均値で欠測値補完:SimpleImputer(strategy=’mean’)
- 正規化:StandardScaler()
質的変数に対し、以下の欠測値補完処理を実施し、その後に変数変換を実施します。
- 最頻値で欠測値補完:SimpleImputer(strategy=”most_frequent”)
- ダミーコード化:OneHotEncoder
要するに、量的変数と質的変数に対し、別の前処理を施します。
その前処理後のデータを用い、目的変数(casual – 非登録ユーザーによるレンタル開始数)を予測します。推定器にはXGBoostを用います。
Pythonコードと実行結果
モジュール
先ずは、必要なモジュールを読み込みます。
以下、コードです。
# 基本的なモジュール import numpy as np import pandas as pd # データ分割用の関数 from sklearn.model_selection import train_test_split # 評価指標 from sklearn.metrics import r2_score # パイプライン構築のための道具 from sklearn.pipeline import make_pipeline from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.preprocessing import FunctionTransformer # 今回、変換器として利用 from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import OneHotEncoder from sklearn.impute import SimpleImputer # 今回、推定器として利用 import xgboost as xgb # グラフ作成 import matplotlib.pyplot as plt
データセット
次に、データセットを読み込みます。
以下、コードです。
# データセットの読み込み url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/bikeshare.csv' df = pd.read_csv(url, index_col='datetime', parse_dates=True) # 特徴量(説明変数) X = df.drop(['casual','registered','count'],axis=1) # 目的変数 y = df['casual']
読み込んだデータセットを、予測モデルを構築する「学習データ」(train)と、構築した予測モデルを検証する「テストデータ」(test)に分割します。
以下、コードです。
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.3,
random_state=123
)
- X_train:学習データの特徴量(説明変数)
- X_test:テストデータの特徴量(説明変数)
- y_train:学習データの目的変数
- y_test:テストデータの目的変数
「その1:変換器と推定器でパイプラインを作ってみよう」では、変数集合ごとにパイプラインを作る方法を採用していました。
具体的には、量的変数と質的変数の集合(リスト)を作り、その集合(リスト)に対しパイプラインを定義し適用する方法です。
先ず、量的変数と質的変数の集合(リスト)を作ります。
以下、コードです。
# 量的変数 nums = ['temp','atemp','humidity','windspeed'] # 質的変数 cats = ['season','holiday','workingday','weather']
パイプライン
次に、パイプラインを定義します。
以下、コードです。
# 量的変数用の変換器パイプラインの定義
num_pipeline = Pipeline([
("impute", SimpleImputer(strategy='mean')),
("scale", StandardScaler()),
])
# 質的変数用の変換器パイプラインの定義
cat_pipeline = Pipeline([
("impute", SimpleImputer(strategy="most_frequent")),
("encode", OneHotEncoder(handle_unknown='ignore')),
])
そして、量的変数と質的変数の集合(リスト)に対しそれぞれのパイプラインを適用した、変換器全体のパイプラインを定義します。
以下、コードです。
# 変換器パイプラインの定義
trans = ColumnTransformer([
("num_trans", num_pipeline, nums),
("cat_trans", cat_pipeline, cats),
],
remainder = 'drop',
)
最後に、推定器と結合したパイプラインを作り完成です。
以下、コードです。
full_pipeline = Pipeline([
("preprocessor", trans),
("regressor", xgb.XGBRegressor()),
])
学習
このパイプラインを学習データで学習します。
以下、コードです。
# パイプラインの学習 full_pipeline.fit(X_train, y_train)
以下、出力です。
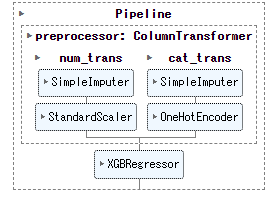
検証
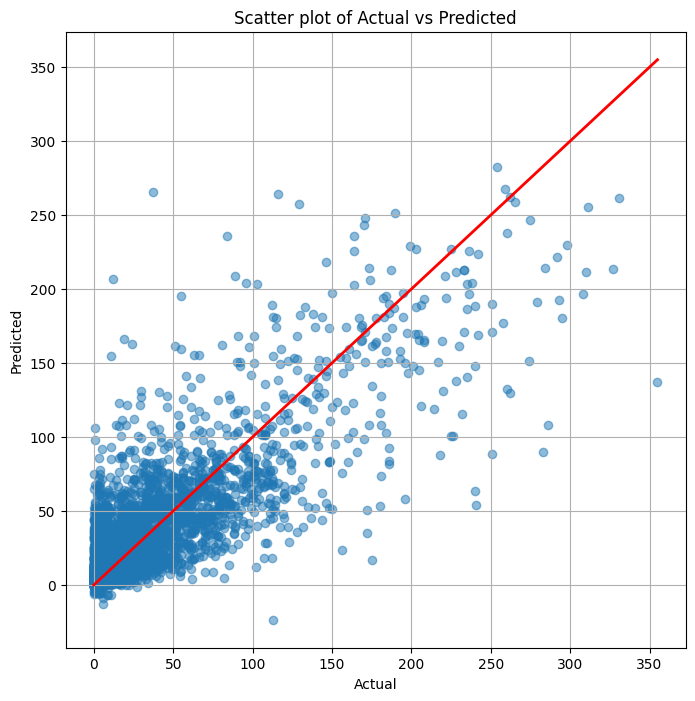
テストデータを予測し、決定係数R^2(最小:0、最大:1、大きいほど良い)を出力します。
以下、コードです。
# 目的変数yの予測 pred_y = full_pipeline.predict(X_test) # R2(決定係数) r2_score(y_test, pred_y)
以下、出力です。
0.6472478306400843
散布図(横軸:実測値、縦軸:予測値)を作ります。
以下、コードです。
# 散布図作成
plt.figure(figsize=(8, 8))
plt.scatter(y_test, pred_y, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', lw=2.0) # diagonal line
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Scatter plot of Actual vs Predicted')
plt.grid(True)
plt.show()
以下、実行結果です。
変数ごとに利用するパイプラインを選ぶ
次に、同じ処理を別の方法で実施します。
別の方法とは、変数ごとに利用するパイプラインを選ぶ方法です。
具体的には、変数が量的(nums)か質的(cats)か指定したデータをもとに、あらかじめ準備しておいたパイプラインを適用します。
パイプライン
各変数のタイプ(量的 or 質的)の辞書リストの作成します。
以下、コードです。
# 各変数のタイプ(量的 or 質的)の辞書リストの作成
trans_configs = [
{'var_name': 'temp', 'var_type': 'nums'},
{'var_name': 'atemp', 'var_type': 'nums'},
{'var_name': 'humidity', 'var_type': 'nums'},
{'var_name': 'windspeed', 'var_type': 'nums'},
{'var_name': 'season', 'var_type': 'cats'},
{'var_name': 'holiday', 'var_type': 'cats'},
{'var_name': 'workingday', 'var_type': 'cats'},
{'var_name': 'weather', 'var_type': 'cats'},
]
パイプラインを定義し、そのリストを作成します。
以下、コードです。
# 量的変数用の変換器パイプラインの定義
num_pipeline = Pipeline([
("impute", SimpleImputer(strategy='mean')),
("scale", StandardScaler()),
])
# 質的変数用の変換器パイプラインの定義
cat_pipeline = Pipeline([
("impute", SimpleImputer(strategy="most_frequent")),
("encode", OneHotEncoder(handle_unknown='ignore')),
])
# パイプラインのリストの作成
pipelines = {
'nums': num_pipeline,
'cats': cat_pipeline,
}
この2つのリストを使い、変数ごとに利用するパイプラインを割り当てたリストを作ります。
以下、コードです。
column_trans = []
for cfg in trans_configs:
var_name = cfg['var_name']
var_type = cfg['var_type']
column_trans.append((var_name, pipelines[var_type], [var_name]))
このリストを使い、変換器全体のパイプラインを定義します。
以下、コードです。
# 変換器パイプラインの定義
trans = ColumnTransformer(
column_trans,
remainder = 'drop',
)
推定器と結合したパイプラインを作り完成です。
以下、コードです。
full_pipeline = Pipeline([
("preprocessor", trans),
("regressor", xgb.XGBRegressor()),
])
学習
このパイプラインを学習データで学習します。
以下、コードです。
# パイプラインの学習 full_pipeline.fit(X_train, y_train)
以下、実行結果です。
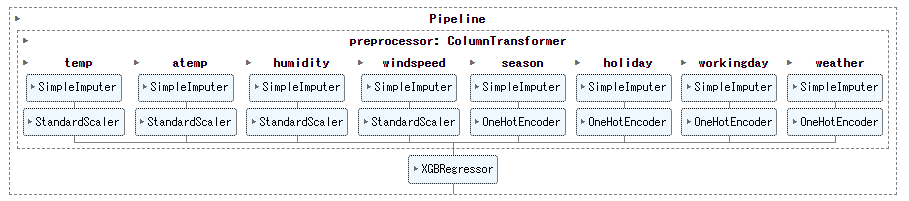
個々の変数に対し、別々に変換器が適用されている様が分かります。
検証
テストデータを予測し、決定係数R^2(最小:0、最大:1、大きいほど良い)を出力します。
以下、コードです。
# 目的変数yの予測 pred_y = full_pipeline.predict(X_test) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.6472478306400843
散布図(横軸:実測値、縦軸:予測値)を作ります。
以下、コードです。
# 散布図作成
plt.figure(figsize=(8, 8))
plt.scatter(y_test, pred_y, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', lw=2.0) # diagonal line
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Scatter plot of Actual vs Predicted')
plt.grid(True)
plt.show()
以下、実行結果です。
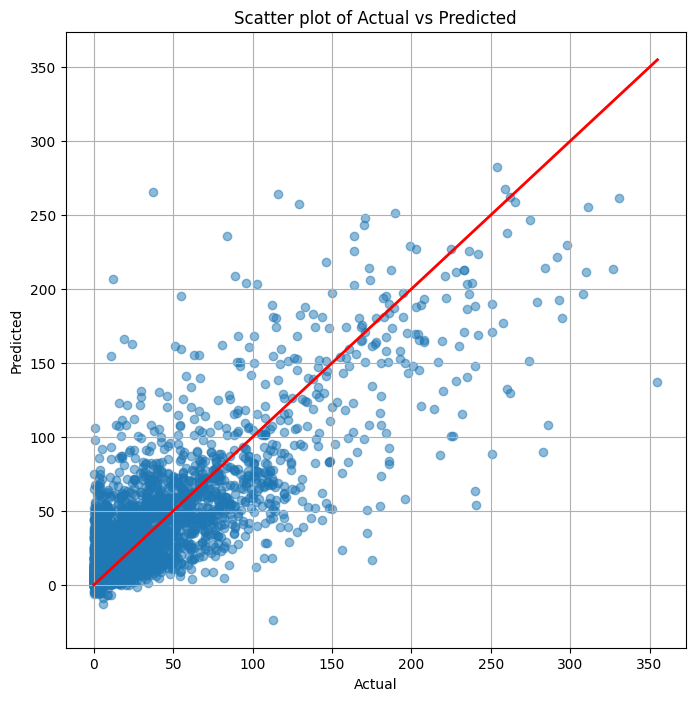
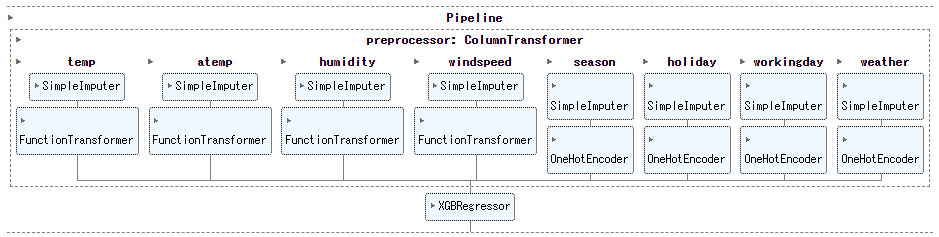
変数ごとにパイプラインを作る
さらに別の方法です。
別の方法とは、変数ごとにパイプラインを作る方法です。
欠測値補完は、量的(nums)か質的(cats)か指定し適用します。今までと同じです。
変数変換は、正規化の代わりに対数変換(log(1+x))と指数変換(x^x)、何もしない(None)を加えます。ダミーコード化(onehot)は残します。
パイプライン
変数ごとのパイプラインで利用する部品リストを作成します。
以下、コードです。
trans_configs = [
{'var_name': 'temp', 'var_type': 'nums', 'var_trans': 'log'},
{'var_name': 'atemp', 'var_type': 'nums', 'var_trans': 'exp'},
{'var_name': 'humidity', 'var_type': 'nums', 'var_trans': 'none'},
{'var_name': 'windspeed', 'var_type': 'nums', 'var_trans': 'exp'},
{'var_name': 'season', 'var_type': 'cats', 'var_trans': 'onehot'},
{'var_name': 'holiday', 'var_type': 'cats', 'var_trans': 'onehot'},
{'var_name': 'workingday', 'var_type': 'cats', 'var_trans': 'onehot'},
{'var_name': 'weather', 'var_type': 'cats', 'var_trans': 'onehot'},
]
部品リストと言っても、量的(nums)か質的(cats)か、変数変換として何を利用するのか、を指定しているだけです。
欠測値補完のリストを作成します。
以下、コードです。
imputers = {
'nums': SimpleImputer(strategy='mean'),
'cats': SimpleImputer(strategy="most_frequent"),
}
変数変換のリストを作成します。
以下、コードです。
transformers = {
'none': FunctionTransformer(lambda x: x),
'log': FunctionTransformer(func=np.log1p),
'exp': FunctionTransformer(func=np.exp),
'onehot': OneHotEncoder(handle_unknown='ignore'),
}
今作った3つのリストを使い、変数ごとのパイプラインのリストを作ります。
以下、コードです。
column_trans = []
for cfg in trans_configs:
var_name = cfg['var_name']
var_type = cfg['var_type']
var_trans = cfg['var_trans']
column_trans.append((
var_name,
make_pipeline(
imputers[var_type],
transformers[var_trans]
),
[var_name]
)
)
このリストを使い、変換器全体のパイプラインを定義します。
以下、コードです。
# 変換器パイプラインの定義
trans = ColumnTransformer(
column_trans,
remainder = 'drop',
)
推定器と結合したパイプラインを作り完成です。
以下、コードです。
full_pipeline = Pipeline([
("preprocessor", trans),
("regressor", xgb.XGBRegressor()),
])
学習
このパイプラインを学習データで学習します。
以下、コードです。
# パイプラインの学習 full_pipeline.fit(X_train, y_train)
以下、実行結果です。
検証
テストデータを予測し、決定係数R^2(最小:0、最大:1、大きいほど良い)を出力します。
以下、コードです。
# 目的変数yの予測 pred_y = full_pipeline.predict(X_test) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.6472478306400843
散布図(横軸:実測値、縦軸:予測値)を作ります。
以下、コードです。
# 散布図作成
plt.figure(figsize=(8, 8))
plt.scatter(y_test, pred_y, alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', lw=2.0) # diagonal line
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Scatter plot of Actual vs Predicted')
plt.grid(True)
plt.show()
以下、実行結果です。
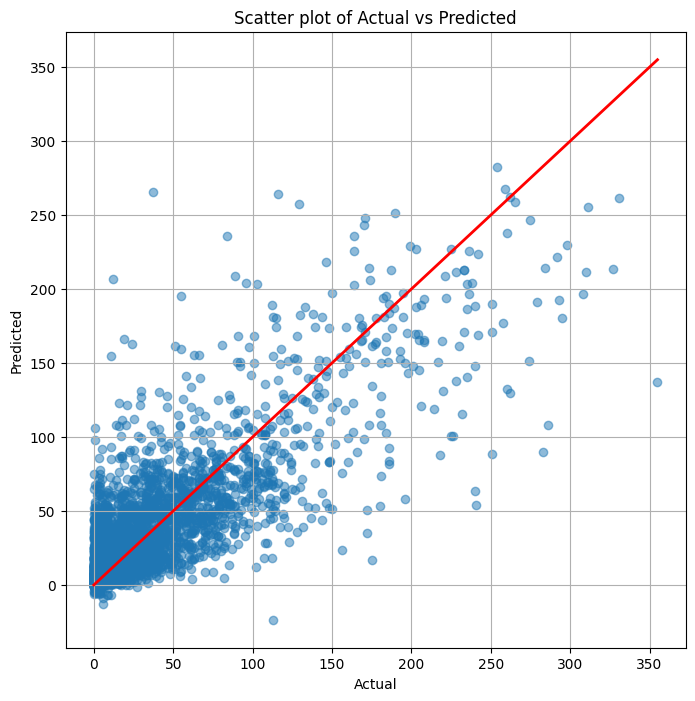
まとめ
今回は、変数ごとにパイプラインの変換器の処理を変える方法について説明しました。
多くの場合、Inputは特徴量(説明変数)Xは、通常は1変数ではなく多変数です。
全ての変数に対し同じ変換を施すこともあるでしょうが、いつも全ての変数に対し同じ変換を施すわけでもありません。
例えば、量的変数と質的変数に対する前処理は異なります。
個々の変数に別の前処理などを実施するときなど、参考にして頂ければと思います。