

お客様一人ひとりの行動は実にさまざまです。
- 毎朝コーヒーだけ買って足早に去る人
- 週末に友人とスイーツを楽しむ人
- 月に1回だけ大量のコーヒー豆を買う人
「全員に同じクーポンを配る」のは簡単ですが、効果的とは言えません。
朝のコーヒー派にスイーツの割引券を配っても反応は薄いでしょうし、コーヒー豆のまとめ買い派にドリンク半額券を配っても的外れです。
そこで必要になるのが顧客セグメンテーションという考え方です。
顧客セグメンテーションとは、似た特徴や行動パターンを持つ顧客をグループ(セグメント)に分け、それぞれに最適な施策を打つためのアプローチです。
これはクラスター分析の典型的な応用場面であり、ビジネスの現場で最も頻繁に使われるデータ分析手法の一つです。
ただし、実際の顧客データには変数が非常に多くなりがちです。
来店頻度、平均購入額、購入カテゴリ別の金額、来店時間帯、クーポン利用率、会員歴……。
数十もの変数が存在することも珍しくありません。
変数が多いままクラスター分析を行うと、「次元の呪い」と呼ばれる現象により距離の区別がつきにくくなったり、変数間の相関によって特定の特徴が過大に評価されてしまったりします。
そこで登場するのが主成分分析(PCA)です。
PCAで次元を削減してからクラスター分析を行うことで、ノイズを除去し、データの本質的な構造に基づいた安定したセグメンテーションが可能になります。
この「PCA → クラスター分析」の組み合わせは定番のパターンです。
今回の前編では、データの探索からPCAまでを扱います。
次回の後編では、クラスター分析を実行し、ビジネス施策に落とし込むところまでを紹介します。
Contents
準備
使用するライブラリをまとめてインポートします。
データ操作のpandas、数値計算のnumpy、可視化のmatplotlibとseaborn、そして機械学習のscikit-learnからPCA・標準化のための部品を読み込みます。
以下、コードです。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import japanize_matplotlib from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA
サンプルデータ(カフェチェーンの会員データ)の読み込みます。
サンプルデータは、以下からダウンロードできます。
customer_data.csv
以下、コードです。
# データファイルのパスを指定
csv_filename = "customer_data.csv"
# CSVファイルからデータを読み込む
df = pd.read_csv(csv_filename)
print(f"顧客データ: {len(df)}人 × {len(df.columns)}変数")
print("\n最初の5人分:")
print(df.head())
以下、実行結果です。
顧客データ: 300人 × 8変数 最初の5人分: monthly_visits avg_purchase drink_ratio food_ratio goods_ratio \ 0 2.477843 3182.312689 0.082516 0.033903 0.861779 1 3.182312 616.722267 0.473383 0.383843 0.046014 2 8.865097 1317.834264 0.404428 0.548706 0.053640 3 18.202421 365.891438 1.000000 0.089954 0.000000 4 1.000000 731.462675 0.645636 0.096145 0.055533 avg_stay_min coupon_rate member_months 0 15.305874 0.258180 26.848141 1 28.959687 0.164186 9.305723 2 40.950512 0.614482 14.873875 3 9.152058 0.322289 24.183537 4 29.084219 0.247291 5.557710
このデータは、カフェ・コーヒーショップの顧客行動を表す数値データです。
300人の顧客について、以下の8つの変数が含まれています。
- monthly_visits: 月間来店回数。来店頻度の高さを示します。
- avg_purchase: 1回あたりの平均購入額(円)。客単価を表します。
- drink_ratio: 購入内訳に占めるドリンクの比率(0〜1)。
- food_ratio: 購入内訳に占めるフードの比率(0〜1)。
- goods_ratio: 購入内訳に占める物販(豆・グッズ等)の比率(0〜1)。
- avg_stay_min: 1回の平均滞在時間(分)。店内での滞在の長さを示します。
- coupon_rate: 購入時にクーポンを利用する割合(0〜1)。
- member_months: 会員登録からの経過月数。ロイヤルティや関係の長さの指標になります。
各変数の平均・標準偏差・最小値・最大値などの基本統計量を一覧で確認します。
以下、コードです。
print("【基本統計量】")
print(df.describe().round(2))
以下、実行結果です。
【基本統計量】
monthly_visits avg_purchase drink_ratio food_ratio goods_ratio \
count 300.00 300.00 300.00 300.00 300.00
mean 8.04 1204.42 0.56 0.25 0.21
std 7.81 1057.80 0.29 0.17 0.31
min 1.00 200.00 0.00 0.00 0.00
25% 2.36 424.10 0.38 0.11 0.01
50% 4.42 693.33 0.55 0.20 0.07
75% 15.56 1444.24 0.84 0.39 0.14
max 27.59 4461.07 1.00 0.67 1.00
avg_stay_min coupon_rate member_months
count 300.00 300.00 300.00
mean 28.63 0.32 15.21
std 22.31 0.21 9.79
min 5.00 0.00 1.00
25% 11.46 0.17 6.90
50% 18.58 0.28 13.98
75% 44.72 0.45 22.80
max 92.90 0.95 45.19
変数によってスケール(値の範囲)が大きく異なることがわかります。
月間来店回数(monthly_visits)は1〜約30回、平均購入額(avg_purchase)は200〜約4500円、クーポン利用率(coupon_rate)は0〜1と、値の範囲がまったく違います。
このままクラスター分析を行うと、値の大きい変数(購入額など)が距離計算を支配してしまうため、後のステップで標準化が必要になります。この気づきがこの時点の最大の収穫です。
可視化でデータの「手触り」を知る
数値だけでは見えない情報が、グラフにすると一目でわかることがあります。
クラスター分析に入る前に、データの全体像を目で確認しておきましょう。
ヒストグラムで各変数の分布を見る
8つの変数それぞれについてヒストグラムを描き、分布の形を確認します。「山がいくつあるか」に注目してください。
以下、コードです。
# ヒストグラム描画(各変数の分布)
fig, axes = plt.subplots(4, 2, figsize=(10, 10)) # 4行×2列のサブプロットを作成
axes = axes.flatten() # 2次元配列を1次元にフラット化
# 各列を順番にプロット
for i, col in enumerate(df.columns):
axes[i].hist(
df[col],
bins=25, # ビン数を指定(細かさ)
color='#2E86AB', # 棒の色
edgecolor='white', # 枠線の色
alpha=0.8 # 透明度
)
axes[i].set_title(col, fontsize=11) # 各サブプロットのタイトル
axes[i].set_ylabel('人数') # Y軸ラベル
plt.suptitle('顧客データの各変数の分布', fontsize=14, y=1.02) # 全体タイトル
plt.tight_layout() # レイアウトの自動調整
plt.show() # 表示
以下、実行結果です。
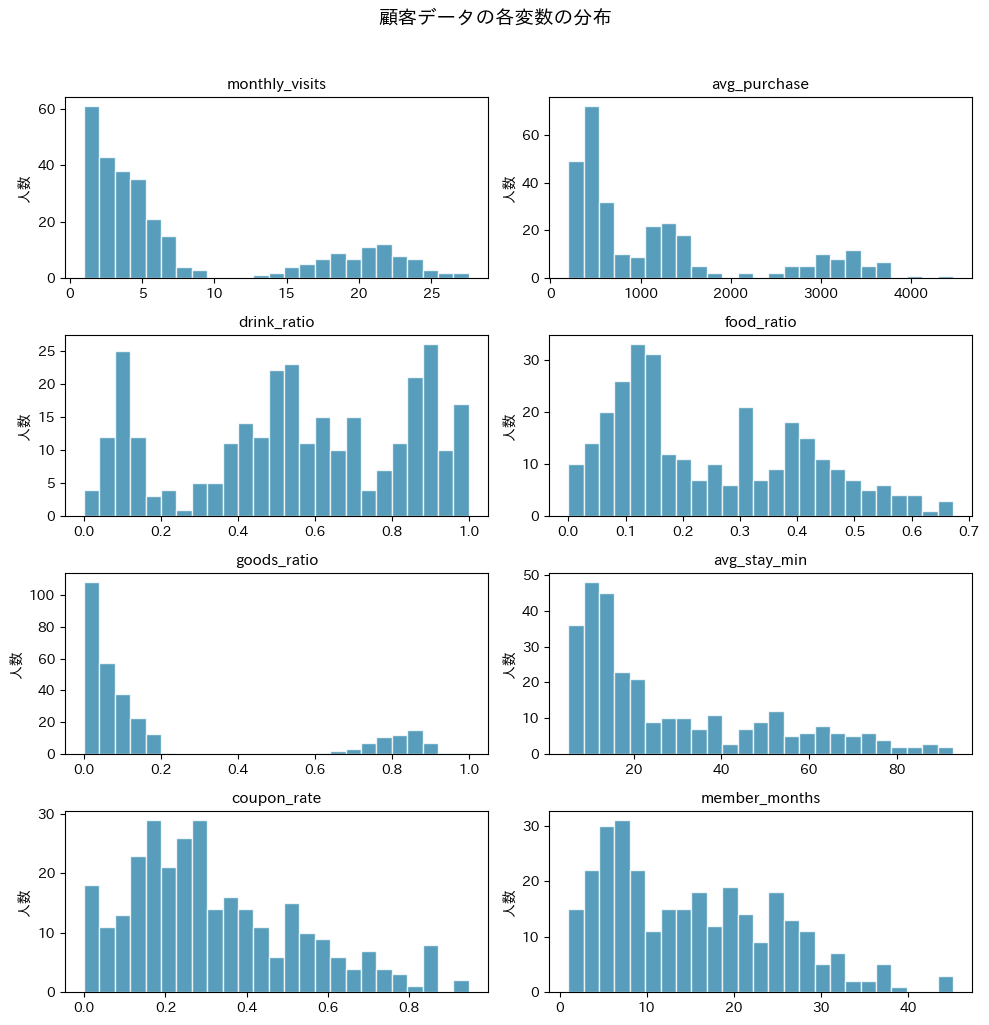
いくつかの変数で分布に「山」が複数あること(多峰性)が確認できるはずです。
たとえば、月間来店回数(monthly_visits)には「2〜5回」付近と「18〜23回」付近に山があり、平均購入額(avg_purchase)にも複数の山が見えます。
これは異なる行動パターンを持つ顧客グループが混在していることを示唆しており、クラスター分析が有効な状況であることがわかります。
もし全変数が綺麗な正規分布ひとつだけであれば、そもそもグループ分けする意味が薄い可能性があります。
相関行列で変数どうしの関係を見る
変数間の相関をヒートマップで可視化します。
相関が強い変数ペアがあるかどうかを確認し、PCAの必要性を判断する材料にします。
以下、コードです。
# 相関ヒートマップを描画
plt.figure(figsize=(10, 8)) # 図のサイズ設定(横10インチ、縦8インチ)
corr = df.corr() # 数値列の相関行列を計算(Pearson相関)
# ヒートマップを作成
sns.heatmap(
corr,
annot=True, # セル内に数値(相関係数)を表示
cmap='RdBu_r', # 赤青のカラーマップ(赤=正、青=負の相関)
center=0, # 0相関を中央色に設定
fmt='.2f', # 相関係数を小数点2桁で表示
square=True, # セルを正方形にする
linewidths=0.5 # セルの区切り線の太さ
)
plt.title('変数間の相関行列', fontsize=14) # タイトル設定
plt.tight_layout() # レイアウトの余白を自動調整
plt.show() # 図の表示
以下、実行結果です。
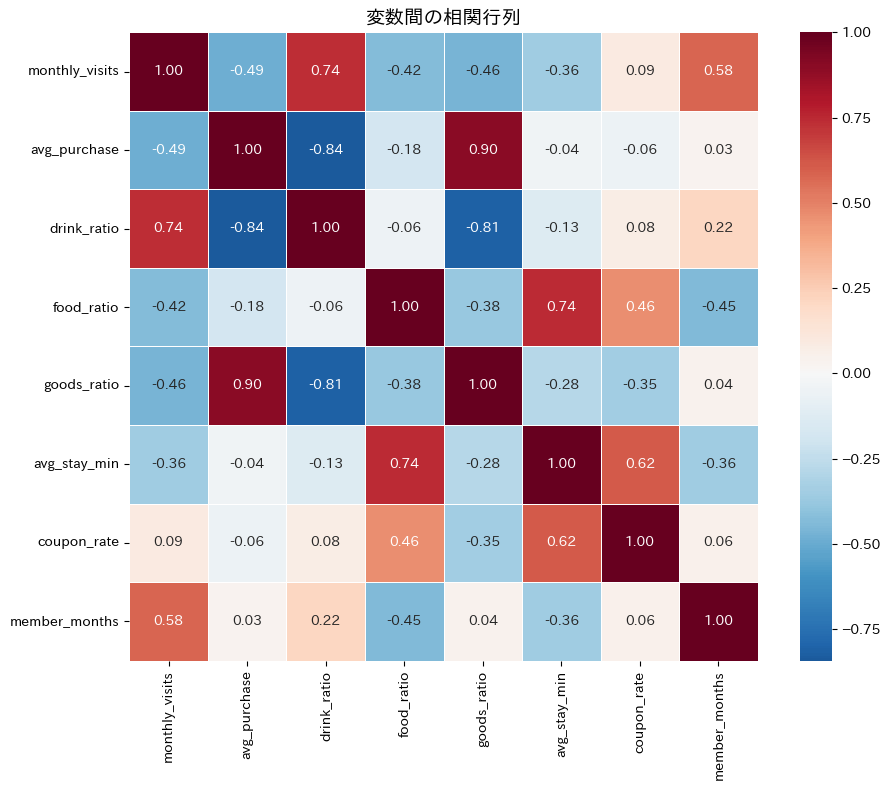
変数間に強い相関があることがわかります。
たとえば、月間来店回数(monthly_visits)とドリンク比率(drink_ratio)、平均購入額(avg_purchase)と物販比率(goods_ratio)などに相関が見られるでしょう。
これは変数間に冗長な情報が含まれていることを意味しており、PCA(主成分分析)で次元削減を行う根拠となります。
もし8つの変数がすべて互いに独立(相関ゼロ)であれば次元削減の意味は薄いのですが、実際のビジネスデータでは変数間に相関があるのが普通です。
標準化 ── 「ものさしの違い」を揃える
なぜ標準化が必要なのか
クラスター分析やPCAを行う前に、データの標準化が不可欠です。
直感的に考えてみましょう。平均購入額が3000円と3100円の差(100円)と、クーポン利用率が0.2と0.3の差(0.1)では、数値上は100円のほうが大きいですが、それぞれの変数の中では同程度の差かもしれません。
標準化は、このような「ものさしの違い」を揃えるための処理です。
数式で書くと、各データ x を次のように変換します。
$$
z = \frac{x – \mu}{\sigma}
$$
ここで \mu は変数の平均、\sigma は標準偏差です。変換後の値 z は「平均から標準偏差何個分離れているか」を表します。
scikit-learnのStandardScalerを使って全変数を標準化し、変換前後の統計量を比較します。
以下、コードです。
scaler = StandardScaler()
df_scaled = pd.DataFrame(
scaler.fit_transform(df),
columns=df.columns
)
print("【標準化後のデータ(最初の5人分)】")
print(df_scaled.head().round(3))
print("\n【標準化後の基本統計量】")
print(df_scaled.describe().round(3))
以下、実行結果です。
【標準化後のデータ(最初の5人分)】
monthly_visits avg_purchase drink_ratio food_ratio goods_ratio \
0 -0.712 1.873 -1.637 -1.294 2.123
1 -0.622 -0.557 -0.284 0.817 -0.525
2 0.106 0.107 -0.523 1.812 -0.501
3 1.303 -0.794 1.540 -0.956 -0.675
4 -0.902 -0.448 0.313 -0.918 -0.495
avg_stay_min coupon_rate member_months
0 -0.598 -0.303 1.190
1 0.015 -0.743 -0.604
2 0.553 1.364 -0.035
3 -0.874 -0.003 0.918
4 0.020 -0.354 -0.987
【標準化後の基本統計量】
monthly_visits avg_purchase drink_ratio food_ratio goods_ratio \
count 300.000 300.000 300.000 300.000 300.000
mean -0.000 -0.000 -0.000 0.000 -0.000
std 1.002 1.002 1.002 1.002 1.002
min -0.902 -0.951 -1.923 -1.498 -0.675
25% -0.727 -0.739 -0.618 -0.832 -0.635
50% -0.463 -0.484 -0.013 -0.310 -0.460
75% 0.964 0.227 0.971 0.838 -0.207
max 2.506 3.084 1.540 2.558 2.572
avg_stay_min coupon_rate member_months
count 300.000 300.000 300.000
mean 0.000 0.000 0.000
std 1.002 1.002 1.002
min -1.061 -1.511 -1.453
25% -0.771 -0.738 -0.850
50% -0.451 -0.207 -0.126
75% 0.722 0.617 0.776
max 2.885 2.916 3.066
標準化後のデータでは、すべての変数の平均がほぼ0、標準偏差がほぼ1になっています。
これにより、すべての変数が対等な「重み」でクラスター分析やPCAに寄与するようになります。
元のデータでは購入額の数千円が距離を支配していましたが、標準化後は来店回数もクーポン利用率も同じスケールで比較できます。
主成分分析(PCA) ── 8変数を少数の軸に圧縮する
8つの変数を持つ標準化データに対してPCAを適用し、情報をできるだけ保持しながら次元を削減します。
PCAの考え方
PCAは、データの分散(ばらつき)が最大になる方向を見つけ、その方向を新しい軸(主成分)とする手法です。
第1主成分はデータの分散を最も多く説明する方向、第2主成分は第1主成分と直交する方向の中で分散を最も多く説明する方向……というように順に決まります。
数学的には、標準化されたデータの共分散行列(≒相関行列)を固有値分解することで主成分が求まります。
$$
C = V \Lambda V^T
$$
ここで C は共分散行列、V は固有ベクトルを並べた行列(各列が主成分の方向)、\Lambda は固有値を対角に並べた行列です。
固有値の大きさが、その主成分がどれだけの分散を説明するかを表しています。
寄与率を確認する
まず全ての主成分を計算し、各主成分の寄与率(説明できる分散の割合)と累積寄与率を数値で確認します。
「何個の主成分を採用すべきか」を判断するための最初のステップです。
以下、コードです。
# 全主成分を計算(PCAインスタンスを作成し学習)
pca_full = PCA()
pca_full.fit(df_scaled)
# 寄与率(各主成分が説明する分散の割合)と累積寄与率を計算
explained = pca_full.explained_variance_ratio_
cumulative = np.cumsum(explained)
# 結果をわかりやすく表示
print("【主成分分析の結果】")
for i, (exp, cum) in enumerate(zip(explained, cumulative)):
# 各主成分について、寄与率と累積寄与率を小数3桁とパーセントで表示
print(f" 第{i+1}主成分: 寄与率 {exp:.3f} ({exp*100:.1f}%) "
f"累積 {cum:.3f} ({cum*100:.1f}%)")
以下、実行結果です。
【主成分分析の結果】 第1主成分: 寄与率 0.404 (40.4%) 累積 0.404 (40.4%) 第2主成分: 寄与率 0.342 (34.2%) 累積 0.746 (74.6%) 第3主成分: 寄与率 0.146 (14.6%) 累積 0.893 (89.3%) 第4主成分: 寄与率 0.045 (4.5%) 累積 0.937 (93.7%) 第5主成分: 寄与率 0.027 (2.7%) 累積 0.964 (96.4%) 第6主成分: 寄与率 0.018 (1.8%) 累積 0.982 (98.2%) 第7主成分: 寄与率 0.012 (1.2%) 累積 0.994 (99.4%) 第8主成分: 寄与率 0.006 (0.6%) 累積 1.000 (100.0%)
各主成分がデータの分散をどれだけ説明しているかがわかります。
一般的に、累積寄与率が70〜80%を超えるところまでの主成分を採用するのが目安です。
今回の場合、第3主成分までの累積寄与率が約90%であり、8変数の情報の約90%を3つの主成分で表現できていることになります。
「8次元を3次元に圧縮しても情報の8割は残っている」と考えると、大幅な情報ロスなく次元削減ができていることが実感できます。
スクリープロットで視覚的に判断する
寄与率をスクリープロット(棒グラフ+折れ線グラフ)で可視化します。
これはPCAの結果を解釈する際の定番の可視化手法です。
以下、コードです。
fig, ax1 = plt.subplots(figsize=(10, 6))
# 棒グラフ:各主成分の寄与率
x_pos = range(1, len(explained) + 1) # 主成分番号(1〜n)
ax1.bar(
x_pos,
explained * 100, # 寄与率を%に変換
color='#2E86AB', # 棒の色(青系)
alpha=0.7, # 透明度
label='各主成分の寄与率' # 凡例ラベル
)
ax1.set_xlabel('主成分', fontsize=12) # X軸ラベル
ax1.set_ylabel('寄与率 (%)', fontsize=12, color='#2E86AB') # 左Y軸ラベル
# 折れ線グラフ:累積寄与率
ax2 = ax1.twinx() # 右Y軸を作成(同じX軸を共有)
ax2.plot(
x_pos,
cumulative * 100, # 累積寄与率を%に変換
'o-', # 点マーカー+線
color='#E8553A', # 線の色(赤系)
linewidth=2, # 線の太さ
markersize=8, # マーカーサイズ
label='累積寄与率' # 凡例ラベル
)
ax2.set_ylabel('累積寄与率 (%)', fontsize=12, color='#E8553A') # 右Y軸ラベル
ax2.axhline(y=80, color='gray', linestyle='--', alpha=0.5) # 80%の基準線
ax2.text(
7.5,
82,
'80%ライン',
fontsize=10,
color='gray'
) # 80%ラインの注記
plt.title('スクリープロット:主成分の寄与率', fontsize=14) # タイトル
plt.xticks(x_pos) # X軸目盛りを主成分番号に合わせる
plt.tight_layout() # レイアウト調整
plt.show() # 図を表示
以下、実行結果です。
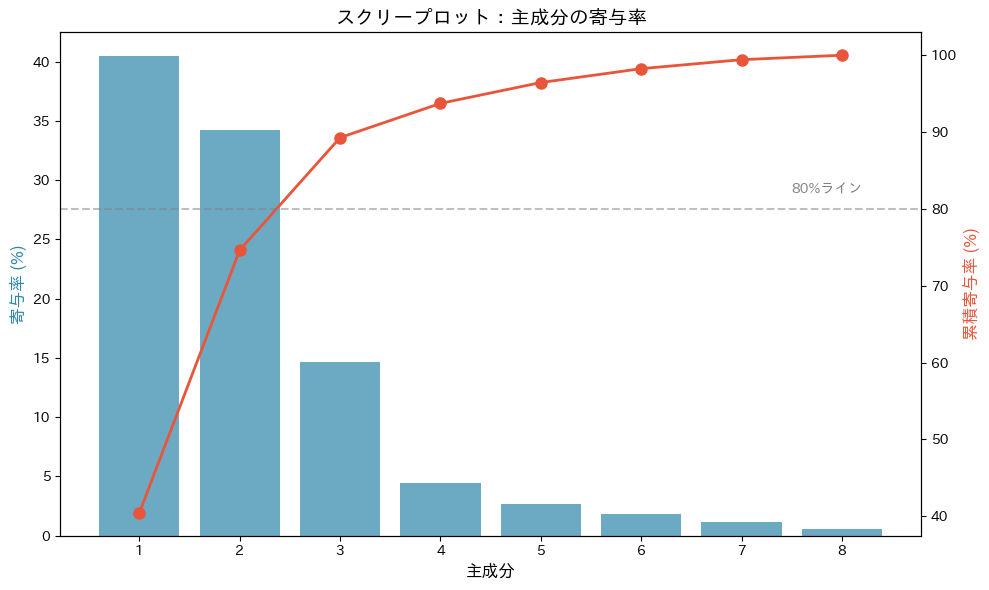
スクリープロットから、何個の主成分を採用すべきかを視覚的に判断できます。
判断のポイントは2つあります。ひとつは、棒グラフの高さが急激に低下する「肘」のポイントです。
肘より左の主成分は情報量が大きく、右の主成分は「あってもなくてもほぼ変わらない」ことを意味します。
もうひとつは、累積寄与率の折れ線が80%ラインを超えるポイントです。この2つの基準を総合的に判断して、採用する主成分の数を決定します。
今回の場合は、主成分の数は3が妥当である、と判断しました。
主成分の解釈 ── 「新しい軸」は何を意味しているのか
PCAで次元削減をしたら、「新しい軸(主成分)は何を意味しているのか」を解釈することが重要です。
これを理解するために、負荷量(各主成分と元の変数との関係の強さ)を確認します。
負荷量をヒートマップで見る
負荷量をヒートマップで可視化します。色の濃さが「その主成分にその変数がどれだけ関わっているか」を表します。
以下、コードです。
# 因子負荷量の計算(各変数が主成分にどれだけ寄与しているか)
loadings = pd.DataFrame(
# 主成分の成分行列を転置して、行=変数・列=主成分にする
pca_full.components_.T,
# 列名をPC1, PC2, ...に設定
columns=[f'PC{i+1}' for i in range(len(df.columns))],
index=df.columns # 行名に元の変数名を設定
)
# 上位3主成分の因子負荷量をヒートマップで表示
plt.figure(figsize=(8, 6)) # 図のサイズを設定
sns.heatmap(
loadings.iloc[:, :3], # PC1〜PC3のみを表示
annot=True, # セル内に数値(負荷量)を表示
cmap='RdBu_r', # 赤青のカラーマップ(赤=正、青=負)
center=0, # 0を中央色に設定(正負を視覚的に区別)
fmt='.2f', # 表示を小数点2桁に整形
linewidths=0.5 # セルの区切り線の太さ
)
plt.title('因子負荷量(上位3主成分)', fontsize=14) # タイトル
plt.xlabel('主成分') # X軸ラベル
plt.ylabel('元の変数') # Y軸ラベル
plt.tight_layout() # レイアウト調整
plt.show() # 図を表示
以下、実行結果です。
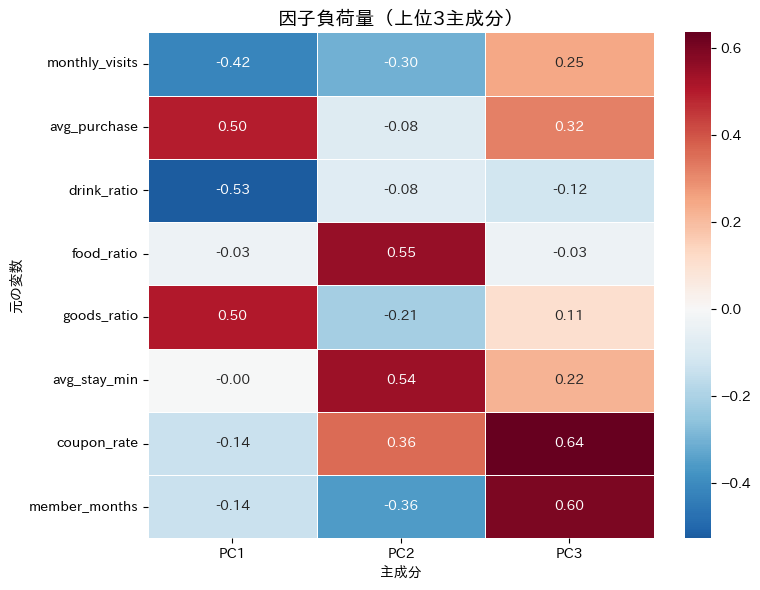
ヒートマップから、各主成分がどの変数と強く関係しているかが読み取れます。
たとえば、第1主成分は月間来店回数(monthly_visits)とドリンク比率(drink_ratio)に負の負荷量を持ち、平均購入額(avg_purchase)と物販比率(goods_ratio)に正の負荷量を持っているため、この軸は「少額頻回型 vs 高額低頻度型」の違いを捉えていると解釈できます。
主成分に名前をつける
負荷量を数値でも確認し、各主成分で特に影響の大きい変数を抽出します。
これを手がかりに主成分の「命名」を行います。
以下、コードです。
print("【負荷量(上位3主成分)】")
print(loadings.iloc[:, :3].round(3))
print("\n【主成分の解釈例】")
for i in range(3):
# 各主成分の負荷量ベクトルを取得
pc = loadings.iloc[:, i]
# 正方向に大きい変数を上位2つ抽出
top_pos = pc.nlargest(2)
# 負方向に大きい(絶対値が大きい)変数を上位2つ抽出
top_neg = pc.nsmallest(2)
print(f"\n第{i+1}主成分:")
# 正の影響が強い変数名を表示
print(f" 正の方向に強い変数: {', '.join(top_pos.index)}")
# 負の影響が強い変数名を表示
print(f" 負の方向に強い変数: {', '.join(top_neg.index)}")
以下、実行結果です。
【負荷量(上位3主成分)】
PC1 PC2 PC3
monthly_visits -0.423 -0.301 0.248
avg_purchase 0.498 -0.080 0.319
drink_ratio -0.527 -0.076 -0.122
food_ratio -0.035 0.551 -0.032
goods_ratio 0.505 -0.214 0.106
avg_stay_min -0.001 0.542 0.219
coupon_rate -0.139 0.356 0.637
member_months -0.140 -0.358 0.597
【主成分の解釈例】
第1主成分:
正の方向に強い変数: goods_ratio, avg_purchase
負の方向に強い変数: drink_ratio, monthly_visits
第2主成分:
正の方向に強い変数: food_ratio, avg_stay_min
負の方向に強い変数: member_months, monthly_visits
第3主成分:
正の方向に強い変数: coupon_rate, member_months
負の方向に強い変数: drink_ratio, food_ratio
各主成分がどのような顧客特性の「軸」を表しているかの手がかりが得られます。
- 第1主成分(PC1):物販・高額購買 vs ドリンク常連
- 第2主成分(PC2):滞在型フード利用 vs 短時間会員歴長
- 第3主成分(PC3):プロモ反応・新規度
もう少し短くするなら、たとえば「PC1:物販高額志向」「PC2:滞在フード志向」「PC3:プロモ反応・会員ステージ」といったラベルが読みやすいです。
この命名作業は機械的にはできず、分析者のビジネス知識が問われるところです。
「数字の裏にあるストーリーを読み取る」──これがデータサイエンティストの腕の見せどころです。
次元削減を実行する
3つの主成分に圧縮する
300人 × 8変数のデータを300人 × 3主成分に圧縮します。
# 主成分の数を3に指定
n_components = 3
# PCAモデルを作成(n_componentsで主成分数を指定)
pca = PCA(n_components=n_components)
# 標準化済みデータにPCAを適用して主成分スコアを得る
df_pca = pca.fit_transform(df_scaled)
# 主成分スコアをDataFrameに変換(列名をPC1, PC2, PC3にする)
df_pca = pd.DataFrame(
df_pca,
columns=[f'PC{i+1}' for i in range(n_components)]
)
# 結果の概要を表示
print(f"次元削減: {df.shape[1]}変数 → {n_components}主成分")
print(f"累積寄与率: {pca.explained_variance_ratio_.sum():.1%}")
print(f"\n主成分スコア(最初の5人分):")
print(df_pca.head().round(3))
以下、実行結果です。
次元削減: 8変数 → 3主成分
累積寄与率: 89.3%
主成分スコア(最初の5人分):
PC1 PC2 PC3
0 3.090 -1.837 1.273
1 0.030 0.776 -1.209
2 -0.217 1.902 0.982
3 -2.193 -1.630 0.197
4 -0.037 0.122 -1.238
8変数が3つの主成分に圧縮されました。
累積寄与率が約90%であるため、元データの情報の大部分を保持できています。
各顧客が3次元の主成分スコアで表現されるようになったので、このデータに対してクラスター分析を行うことで、ノイズに強い安定したクラスタリングが期待できます。
次の表で、この圧縮の意味を整理しておきましょう。
| 圧縮前 | 圧縮後 | |
|---|---|---|
| 変数の数 | 8個(来店回数、購入額、…) | 3個(PC1, PC2, PC3) |
| 各変数の意味 | 具体的(「月間来店回数」など) | 抽象的(複数変数の組み合わせ) |
| 情報量 | 100% | 約90%(累積寄与率) |
| ノイズの影響 | 大きい |
まとめ
今回は、カフェチェーンの顧客データを題材に、以下を実施しました。
- データの理解 : 基本統計量でスケールの違いを把握し、ヒストグラムで分布の多峰性を確認しました。相関行列で変数間の冗長性も見つけました。
- 標準化 : 変数間の「ものさしの違い」を揃え、すべての変数が対等に分析に寄与するようにしました。
- PCA(主成分分析) : 8変数を3つの主成分に圧縮しました。スクリープロットで主成分数を決め、因子負荷量で各主成分の意味を解釈しました。
ここまでで、データは「分析しやすい姿」に整いました。300人の顧客は、もはや8つのバラバラな数値ではなく、3つの意味のある軸上の点として表現されています。
次回(後編)では、この3次元のデータに対してk-means法によるクラスター分析を実行し、最適なクラスター数の決定、クラスターの可視化などを実施します。