

ここまで、距離の概念から始まり、階層的クラスタリング、K-means法、クラスタ数の決め方と学んできました。
ところで、病院に行って「あなたは風邪です」と診断されただけで帰されたら、どう思いますか?
「で、どうすればいいの?」と思いますよね。診断は大切ですが、その後の治療方針がなければ意味がありません。
クラスター分析も同じです。
「顧客を4つのクラスタに分けました」で終わっては、ビジネスには何の役にも立ちません。
各クラスタがどんな特徴を持つのか理解し、それぞれに適した施策を考えるところまでやって、初めて分析の価値が生まれます。
この「クラスタの特徴を理解し、意味のある名前をつけ、施策につなげる」プロセスをクラスタープロファイリングと呼びます。
今回は、この実務で最も重要なステップを学んでいきましょう。
プロファイリングで実施すること
クラスタープロファイリングで実施することが3つあります。
1つ目はクラスタの特徴を理解することです。
「クラスタ0」と「クラスタ1」は、具体的に何が違うのか? どの変数で差があり、どの変数では似ているのか? を明らかにします。
2つ目は意味のある名前をつけることです。
「クラスタ0」という無機質な名前を、「プレミアム顧客」「ライトユーザー」「休眠顧客」といった、誰もが理解できる名前に変換します。
3つ目は施策につなげることです。
各クラスタに対して、どのようなマーケティング施策や対応が効果的かを検討し、提案します。
準備
今回使うライブラリをインポートしましょう。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import japanize_matplotlib from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler from scipy import stats # 乱数シードを固定 np.random.seed(42)
サンプルデータを準備する
実務を想定した顧客データを作成しましょう。
小売店の顧客200人分のデータで、すでにクラスタリングが完了しているという設定です。
# 顧客データを生成(4つのセグメントを想定)
np.random.seed(42)
n_customers = 200
# セグメント別にデータを生成
segment_data = {
'ユーザ層1': {'n': 50, '購買金額': (30000, 8000), '来店頻度': (2, 0.8), '購入点数': (8, 1.5), '会員歴': (8, 0.5)},
'ユーザ層2': {'n': 60, '購買金額': (80000, 15000), '来店頻度': (6, 1.5), '購入点数': (5, 1), '会員歴': (3, 1)},
'ユーザ層3': {'n': 50, '購買金額': (150000, 25000), '来店頻度': (18, 3), '購入点数': (2, 0.5), '会員歴': (1, 1.5)},
'ユーザ層4': {'n': 40, '購買金額': (280000, 40000), '来店頻度': (12, 2), '購入点数': (12, 2), '会員歴': (10, 2)}
}
data_list = []
for seg_name, params in segment_data.items():
n = params['n']
seg_df = pd.DataFrame({
'年間購買金額': np.random.normal(*params['購買金額'], n),
'来店頻度': np.random.normal(*params['来店頻度'], n),
'平均購入点数': np.random.normal(*params['購入点数'], n),
'会員歴': np.random.normal(*params['会員歴'], n)
})
data_list.append(seg_df)
customers = pd.concat(data_list, ignore_index=True)
# 負の値を補正
for col in customers.columns:
customers[col] = customers[col].clip(lower=0.5)
print("顧客データの概要:")
print(customers.describe().round(1))
以下、実行結果です。
顧客データの概要:
年間購買金額 来店頻度 平均購入点数 会員歴
count 200.0 200.0 200.0 200.0
mean 123942.6 9.0 6.4 5.4
std 91568.1 6.1 3.6 3.7
min 14322.6 0.5 0.8 0.5
25% 48421.7 3.2 3.4 2.1
50% 94898.5 7.3 5.7 4.3
75% 165701.1 13.8 8.7 8.2
max 382934.4 23.7 17.3 15.1
このデータには「年間購買金額」「来店頻度」「平均購入点数」「会員歴」の4つの特徴量があります。
K-meansでクラスタリングを実行
データを標準化してK-means法を適用します。前回学んだ手法でK=4が最適と判断されたという設定で進めます。
# 標準化
features = ['年間購買金額', '来店頻度', '平均購入点数', '会員歴']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(customers[features])
# K-meansでクラスタリング(K=4)
kmeans = KMeans(
n_clusters=4,
random_state=42,
n_init=10
)
customers['クラスタ'] = kmeans.fit_predict(X_scaled)
print("クラスタごとの顧客数:")
print(customers['クラスタ'].value_counts().sort_index())
以下、実行結果です。
クラスタごとの顧客数: クラスタ 0 60 1 40 2 50 3 50 Name: count, dtype: int64
ここからが本番です。「クラスタ0」「クラスタ1」「クラスタ2」「クラスタ3」がそれぞれどんな顧客なのか、プロファイリングしていきましょう。
ステップ1:記述統計で全体像を把握する
クラスタ別の平均値を計算
まずは最も基本的な分析として、各クラスタの平均値を計算します。
# クラスタ別の平均値
cluster_means = customers.groupby('クラスタ')[features].mean()
print("=== クラスタ別平均値 ===")
print(cluster_means.round(1))
以下、実行結果です。
=== クラスタ別平均値 ===
年間購買金額 来店頻度 平均購入点数 会員歴
クラスタ
0 82533.5 6.0 5.1 3.0
1 277550.9 11.9 11.7 10.4
2 28196.2 2.0 7.9 8.0
3 146493.2 17.3 2.0 1.5
この表を見るだけでも、クラスタ間の違いが見えてきます。
購買金額や来店頻度が高いクラスタ、低いクラスタがあることがわかるでしょう。
全体平均との比較
各クラスタの値が「全体と比べてどうか」を把握するため、全体平均からの乖離率を計算します。
# 全体平均
overall_means = customers[features].mean()
# 全体平均からの乖離率(%)
deviation_pct = (
(cluster_means - overall_means) / overall_means * 100
).round(1)
print("=== 全体平均からの乖離率(%) ===")
print(deviation_pct)
以下、実行結果です。
=== 全体平均からの乖離率(%) ===
年間購買金額 来店頻度 平均購入点数 会員歴
クラスタ
0 -33.4 -33.0 -19.8 -43.5
1 123.9 32.1 84.1 93.1
2 -77.3 -77.5 25.0 50.0
3 18.2 91.4 -68.5 -72.2
この乖離率を見ると、各クラスタの特徴がより明確になります。
たとえば「年間購買金額が全体平均より+123.9%」といった形で、相対的な位置づけがわかります。
正の値は平均より高く、負の値は平均より低いことを示しています。
ステップ2:可視化で特徴を直感的に理解する
数値だけでは直感的に理解しにくいので、さまざまなグラフで可視化していきましょう。
棒グラフで比較する
まずは最もシンプルな棒グラフで、クラスタ間の違いを確認します。
fig, axes = plt.subplots(4, 1, figsize=(10, 12))
colors = ['#3498db', '#e74c3c', '#2ecc71', '#9b59b6']
for idx, col in enumerate(features):
ax = axes[idx]
means = cluster_means[col]
bars = ax.bar(range(4), means, color=colors)
ax.axhline(
y=overall_means[col],
color='gray', linestyle='--', linewidth=2,
label='Overall Average'
)
ax.set_xlabel('Cluster')
ax.set_ylabel(col)
ax.set_title(f'{col} by Cluster')
ax.set_xticks(range(4))
ax.legend()
ax.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.show()
以下、実行結果です。
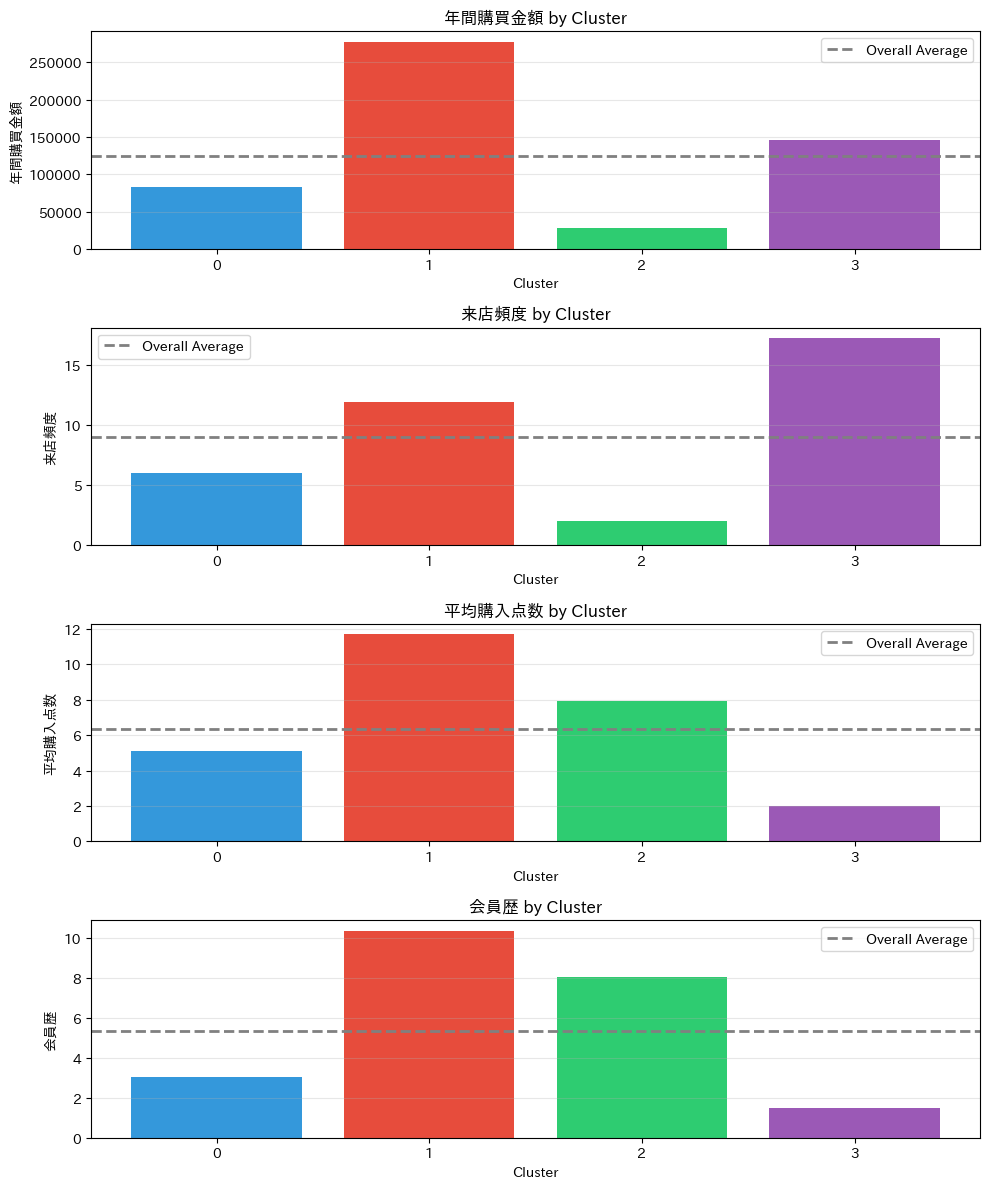
4つのグラフが表示され、各変数についてクラスタ間の違いが一目でわかります。
灰色の点線が全体平均なので、それより上か下かで「高い顧客層」「低い顧客層」を判断できます。
レーダーチャートで多次元を一度に見る
複数の変数を同時に比較するには、レーダーチャート(スパイダーチャート)が効果的です。
各クラスタの「形」を見ることで、特徴を直感的に把握できます。
"""レーダーチャートを描画する関数"""
def plot_radar_chart(data, categories, title):
# 角度を計算
angles = np.linspace(
0, 2 * np.pi,
len(categories), endpoint=False
).tolist()
angles += angles[:1]
fig, ax = plt.subplots(
figsize=(10, 10),
subplot_kw=dict(polar=True)
)
colors = ['#3498db', '#e74c3c', '#2ecc71', '#9b59b6']
for idx, (cluster_id, values) in enumerate(data.iterrows()):
values_list = values.tolist()
values_list += values_list[:1]
ax.plot(
angles, values_list,
'o-', linewidth=2,
label=f'Cluster {cluster_id}', color=colors[idx]
)
ax.fill(
angles, values_list,
alpha=0.1, color=colors[idx]
)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories)
ax.set_title(title, size=16, y=1.1)
ax.legend(
loc='upper right',
bbox_to_anchor=(1.3, 1.0)
)
plt.tight_layout()
plt.show()
レーダーチャートを描くには、まずデータを正規化する必要があります。各変数のスケールが異なるためです。
# 0-1に正規化(各変数の最大値を1とする)
normalized_means = cluster_means.copy()
for col in features:
max_val = cluster_means[col].max()
normalized_means[col] = cluster_means[col] / max_val
# レーダーチャートを描画
plot_radar_chart(
normalized_means,
features,
'Cluster Profiles (Radar Chart)'
)
以下、実行結果です。
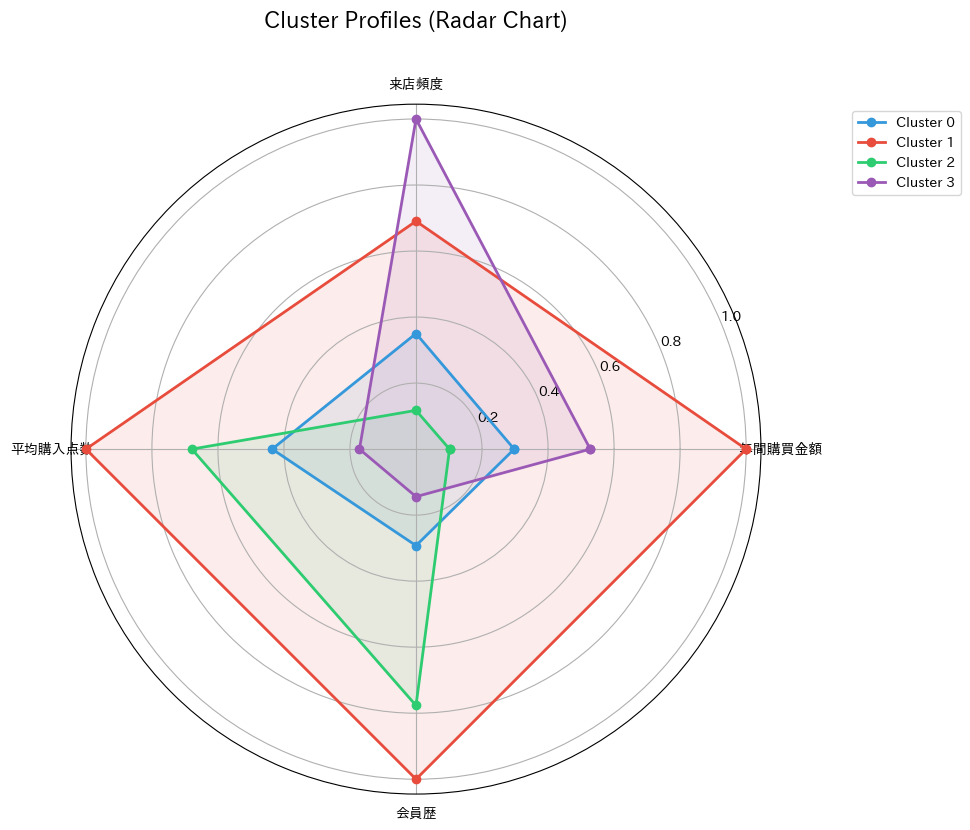
このレーダーチャートを見ると、各クラスタの「形」が異なることがわかります。
すべての軸で大きい(外側に広がった)クラスタは「優良顧客」、すべてで小さい(中心に近い)クラスタは「ライトユーザー」と解釈できます。
ヒートマップで一覧表示する
全体像を俯瞰するには、ヒートマップが便利です。色の濃淡で値の大小を表現します。
from sklearn.preprocessing import MinMaxScaler
scaler_mm = MinMaxScaler()
heatmap_data = pd.DataFrame(
scaler_mm.fit_transform(cluster_means),
index=cluster_means.index,
columns=cluster_means.columns
)
fig, ax = plt.subplots(figsize=(10, 8))
im = ax.imshow(
heatmap_data.values,
cmap='RdPu',
aspect='auto',
alpha=0.6
)
# 軸の設定
ax.set_xticks(range(len(features)))
ax.set_xticklabels(features, rotation=45, ha='right')
ax.set_yticks(range(4))
ax.set_yticklabels([f'Cluster {i}' for i in range(4)])
# 値を表示
for i in range(4):
for j in range(len(features)):
text = ax.text(
j, i, f'{cluster_means.iloc[i, j]:.0f}',
ha='center', va='center',
color='black', fontsize=12
)
plt.colorbar(im, label='Normalized Value')
plt.title('Cluster Heatmap', fontsize=14)
plt.tight_layout()
plt.show()
以下、実行結果です。
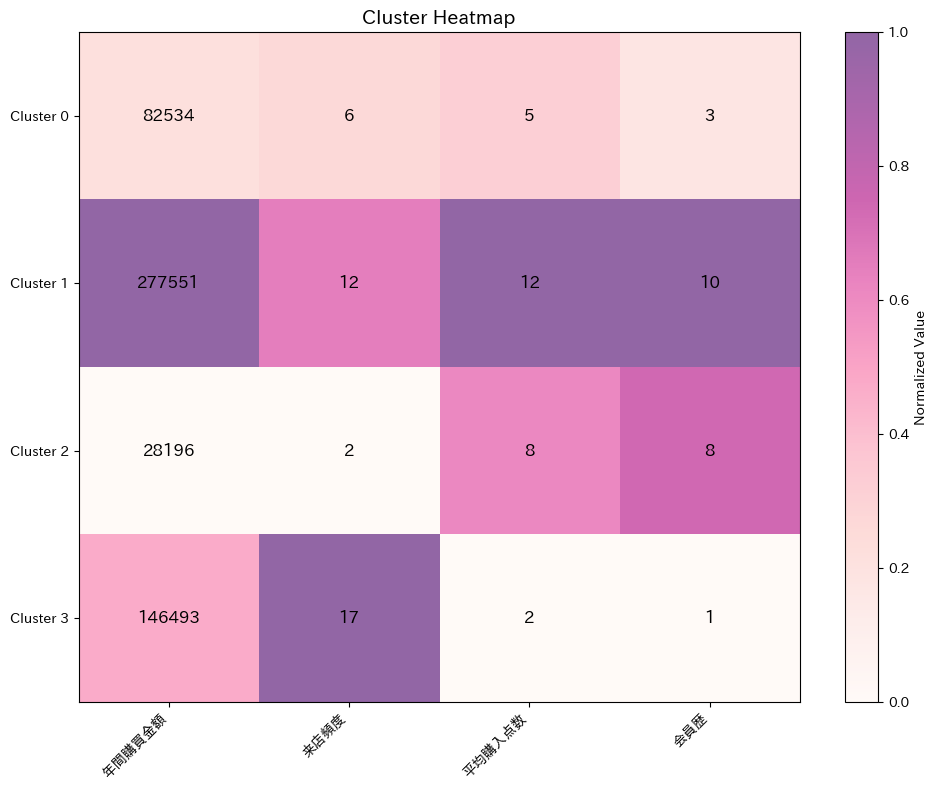
行(クラスタ)ごとに見ると、そのクラスタの強み・弱みがわかります。
列(変数)ごとに見ると、どのクラスタがその変数で優れているかがわかります。
箱ひげ図で分布を確認する
平均値だけでなく、各クラスタ内のばらつきも確認しておきましょう。箱ひげ図を使います。
fig, axes = plt.subplots(4, 1, figsize=(10, 16))
colors = ['#3498db', '#e74c3c', '#2ecc71', '#9b59b6']
for idx, col in enumerate(features):
ax = axes[idx]
data_by_cluster = [
customers[customers['クラスタ'] == c][col]
for c in range(4)
]
bp = ax.boxplot(data_by_cluster, patch_artist=True)
for patch, color in zip(bp['boxes'], colors):
patch.set_facecolor(color)
patch.set_alpha(0.7)
ax.set_xlabel('Cluster')
ax.set_ylabel(col)
ax.set_title(f'{col} Distribution by Cluster')
ax.set_xticklabels(['0', '1', '2', '3'])
ax.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.show()
以下、実行結果です。
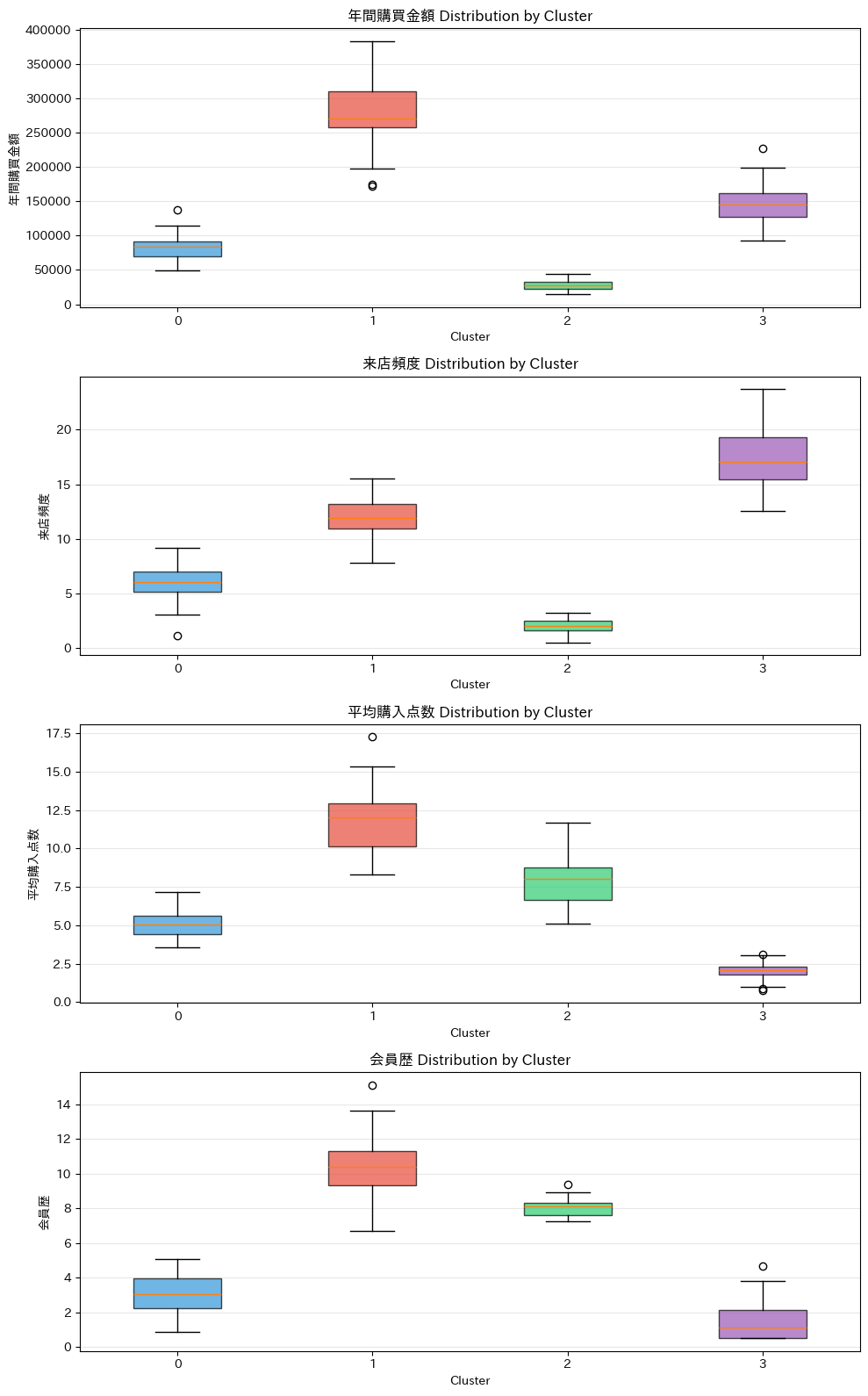
箱ひげ図を見ると、各クラスタ内のばらつき(箱の大きさ)や外れ値(点)の存在がわかります。
平均値だけでは見えない情報が得られるので、重要なチェックポイントです。
ステップ3:統計的に差があるか検証する
「クラスタ間で平均値が違う」ように見えても、それが統計的に意味のある差かどうかは別問題です。
ANOVA(分散分析)を使って検定しましょう。
print("=== ANOVA検定結果 ===")
print("帰無仮説:すべてのクラスタで平均値は等しい")
print("p値 < 0.05 なら、クラスタ間に統計的に有意な差がある\n")
anova_results = []
for col in features:
groups = [
customers[customers['クラスタ'] == c][col]
for c in range(4)
]
f_stat, p_value = stats.f_oneway(*groups)
significance = (
"***" if p_value < 0.001 else
"**" if p_value < 0.01 else
"*" if p_value < 0.05 else
""
)
anova_results.append({
'変数': col,
'F値': round(f_stat, 2),
'p値': f'{p_value:.2e}',
'有意性': significance
})
print(
f"{col}: \tF={f_stat:.2f},"
f"\tp={p_value:.2e}\t{significance}"
)
print("\n(*:p<0.05, **:p<0.01, ***:p<0.001)")
以下、実行結果です。
=== ANOVA検定結果 === 帰無仮説:すべてのクラスタで平均値は等しい p値 < 0.05 なら、クラスタ間に統計的に有意な差がある 年間購買金額: F=724.27, p=9.29e-106 *** 来店頻度: F=722.35, p=1.18e-105 *** 平均購入点数: F=463.06, p=1.13e-88 *** 会員歴: F=581.89, p=2.67e-97 *** (*:p<0.05, **:p<0.01, ***:p<0.001)
すべての変数でp値が非常に小さい(< 0.001)場合、クラスタ間の差は統計的に有意であり、偶然ではないと判断できます。
これにより、「クラスタ分けには意味がある」ことが裏付けられます。
ステップ4:クラスタに名前をつける
ここまでの分析結果を踏まえて、各クラスタの特徴を整理しましょう。
# クラスタ別の特徴をまとめる
print("=== クラスタ特徴まとめ ===")
for cluster_id in range(4):
print(f"\n【クラスタ {cluster_id}】")
print(f" 顧客数: {(customers['クラスタ'] == cluster_id).sum()}人")
cluster_data = customers[customers['クラスタ'] == cluster_id]
for col in features:
mean_val = cluster_data[col].mean()
overall_val = customers[col].mean()
diff_pct = (mean_val - overall_val) / overall_val * 100
direction = (
"↑" if diff_pct > 10 else
"↓" if diff_pct < -10 else
"→"
)
print(
f" {col}: {mean_val:.1f} "
f"({direction} {diff_pct:+.1f}%)"
)
以下、実行結果です。
=== クラスタ特徴まとめ === 【クラスタ 0】 顧客数: 60人 年間購買金額: 82533.5 (↓ -33.4%) 来店頻度: 6.0 (↓ -33.0%) 平均購入点数: 5.1 (↓ -19.8%) 会員歴: 3.0 (↓ -43.5%) 【クラスタ 1】 顧客数: 40人 年間購買金額: 277550.9 (↑ +123.9%) 来店頻度: 11.9 (↑ +32.1%) 平均購入点数: 11.7 (↑ +84.1%) 会員歴: 10.4 (↑ +93.1%) 【クラスタ 2】 顧客数: 50人 年間購買金額: 28196.2 (↓ -77.3%) 来店頻度: 2.0 (↓ -77.5%) 平均購入点数: 7.9 (↑ +25.0%) 会員歴: 8.0 (↑ +50.0%) 【クラスタ 3】 顧客数: 50人 年間購買金額: 146493.2 (↑ +18.2%) 来店頻度: 17.3 (↑ +91.4%) 平均購入点数: 2.0 (↓ -68.5%) 会員歴: 1.5 (↓ -72.2%)
この出力を見ながら、各クラスタの特徴を言語化していきます。
↑は平均より大幅に高い、↓は大幅に低い、→はほぼ平均並みを示しています。
良い名前をつけるためのポイントを押さえておきましょう。
まず、特徴を端的に表すことが重要です。「クラスタ2」ではなく「プレミアム顧客」「ヘビーユーザー」など、特徴が一目でわかる名前をつけます。
次に、ポジティブな表現を心がけることです。「低価値顧客」より「ライトユーザー」「お試し顧客」など、ネガティブすぎない表現が望ましいです。社内で共有する際に、特定の顧客を貶めるような印象を与えないよう配慮しましょう。
さらに、施策につながる名前にすることも効果的です。「育成対象顧客」「ロイヤル顧客候補」など、次のアクションを想起させる名前にすることで、分析後の施策検討がスムーズになります。
# クラスタ名を定義(分析結果に基づいて命名)
cluster_names = {
0: 'ライトユーザー', # 全指標が低い
1: 'プレミアム顧客', # 全指標が高い
2: '離反リスク層', # 会員歴が長いが来店頻度が低く購買金額も低い
3: 'アクティブ成長層' # 会員歴が短いが来店頻度が高い
}
# 名前を適用
customers['セグメント名'] = customers['クラスタ'].map(cluster_names)
サマリーを作成しましょう。
# セグメント別サマリー
summary = customers.groupby('セグメント名').agg({
'年間購買金額': ['mean', 'sum'],
'来店頻度': 'mean',
'平均購入点数': 'mean',
'会員歴': 'mean',
'クラスタ': 'count'
}).round(1)
summary.columns = [
'平均購買金額',
'合計購買金額',
'平均来店頻度',
'平均購入点数',
'平均会員歴',
'顧客数'
]
# 構成比を追加
summary['顧客構成比'] = (
summary['顧客数'] / summary['顧客数'].sum() * 100
).round(1)
summary['売上構成比'] = (
summary['合計購買金額'] / summary['合計購買金額'].sum() * 100
).round(1)
# 売上構成比の高い順にソート
summary = summary.sort_values(by='売上構成比', ascending=False)
print("=== セグメント分析サマリー ===")
print(summary)
以下、実行結果です。
=== セグメント分析サマリー ===
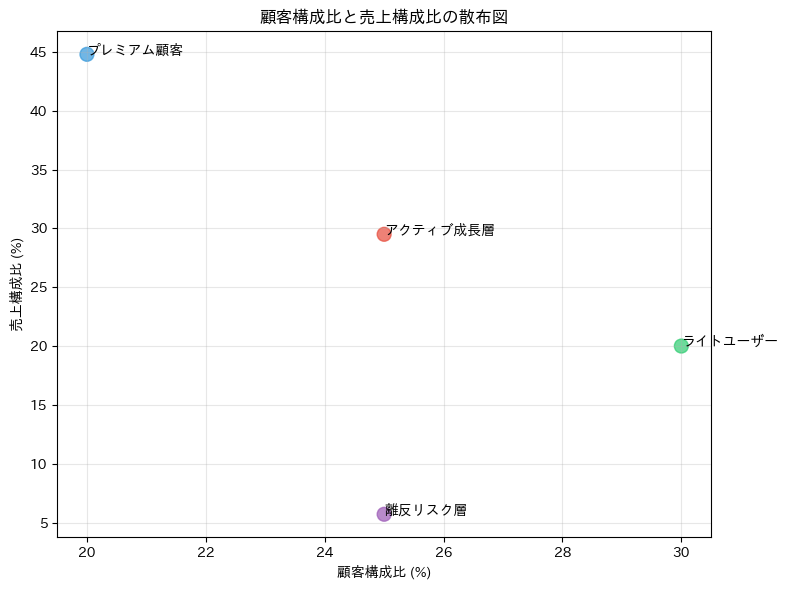
平均購買金額 合計購買金額 平均来店頻度 平均購入点数 平均会員歴 顧客数 顧客構成比 売上構成比
セグメント名
プレミアム顧客 277550.9 11102037.8 11.9 11.7 10.4 40 20.0 44.8
アクティブ成長層 146493.2 7324658.1 17.3 2.0 1.5 50 25.0 29.5
ライトユーザー 82533.5 4952012.4 6.0 5.1 3.0 60 30.0 20.0
離反リスク層 28196.2 1409810.4 2.0 7.9 8.0 50 25.0 5.7
2つの構成比(顧客数と売上)の散布図を作成してます。
fig, ax = plt.subplots(figsize=(8, 6))
# 散布図を描画
ax.scatter(
summary['顧客構成比'],
summary['売上構成比'],
color=colors,
s=100,
alpha=0.7
)
# 各セグメント名を表示
for i, seg_name in enumerate(summary.index):
ax.text(
summary['顧客構成比'].iloc[i], # ilocを使用して位置でアクセス
summary['売上構成比'].iloc[i], # ilocを使用して位置でアクセス
seg_name,
fontsize=10,
ha='left'
)
ax.set_xlabel('顧客構成比 (%)')
ax.set_ylabel('売上構成比 (%)')
ax.set_title('顧客構成比と売上構成比の散布図')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
以下、実行結果です。
ステップ5:施策につなげる
各セグメントの特徴に基づいて、具体的な施策を検討します。
① ライトユーザー
(年間購買金額:低〜中/来店頻度:低/会員歴:短め)
ライトユーザーは、来店頻度が低く、年間購買金額も比較的少ない層です。会員歴は短めで、まだ店舗・サービスへの理解や定着が進んでいないと考えられます。
このセグメントでは、「まず来てもらう・思い出してもらう」ことが最優先です。
- 初回・再来店クーポン
- 期間限定キャンペーンの案内
- メール・アプリ通知によるリマインド施策
このような施策を実施し接点を増やすことで、利用習慣の形成を目指します。
KPI例
- 再来店率
- 来店頻度の増加
- 初回→2回目購入転換率
② アクティブ成長層
(年間購買金額:中/来店頻度:高/平均購入点数:少なめ/会員歴:短い)
アクティブ成長層は、来店頻度が高く、店舗利用がすでに習慣化している層です。一方で、平均購入点数は少なく、1回あたりの購買規模には伸びしろがあります。
このため、施策の方向性は「来店回数」ではなく、1回の購買価値を高めることです。
- まとめ買い割引
- 関連商品のレコメンド(クロスセル)
- セット販売・高単価商品の提案
このような施策を実施することにより、客単価や購入点数の引き上げを狙います。
KPI例
- 平均購入点数
- 客単価
- 高単価商品購入率
③ プレミアム顧客
(年間購買金額:非常に高い/購入点数:多い/会員歴:長い)
プレミアム顧客は、年間購買金額・平均購入点数・会員歴がすべて高い最優良顧客です。来店頻度は突出して高いわけではありませんが、1回あたりの購買価値が非常に大きい点が特徴です。
このセグメントでは、新規施策よりも 「維持・関係強化」 が最重要になります。
- 会員限定特典・先行販売
- 特別割引・バースデー特典
- 専用サポートやVIP施策
このような施策を実施することでロイヤルティを高め、離反を防ぎます。
KPI例
- 継続率
- LTV(顧客生涯価値)
- 購買金額の維持率
④ 離反リスク層
(年間購買金額:低/来店頻度:極めて低い/会員歴:長い)
離反リスク層は、会員歴が長いにもかかわらず、来店頻度・購買金額が著しく低下している層です。過去には利用していたものの、現在は関係性が弱まっていると考えられます。
このセグメントでは、「掘り起こし施策を行うか、撤退判断をするか」の見極めが重要です。
- 休眠復活キャンペーン
- 「お久しぶりです」系の再接触メール
- 利用理由・不満点の簡易アンケート
このような施策を実施し、反応がある顧客のみを重点的にフォローします。
KPI例
- 復活率(再来店率)
- 反応率(メール開封・クリック率)
- 施策ROI
プロファイリングの心得10か条
実務でクラスタープロファイリングを行う際の心得をまとめておきます。
第1条:ビジネス目的を明確に
何のためにセグメンテーションするのか、最初に定義しましょう。
「顧客理解のため」という漠然とした目的ではなく、「休眠顧客の掘り起こし施策を打つため」「優良顧客の離反を防ぐため」など、具体的なゴールを設定することが重要です。
第2条:解釈可能な変数を使う
ブラックボックスな変数より、誰もが意味を理解できる変数を選びましょう。
「購買金額」「来店頻度」など、マーケティング担当者や経営層が直感的に理解できる変数を使うことで、分析結果の共有と活用がスムーズになります。
第3条:統計と直感の両立
p値が小さいからといって、それだけで重要な差とは限りません。統計的に有意であっても、ビジネス的に意味のある差でなければ施策には使えません。
逆に、統計的な有意差がなくても、実務上重要な示唆が得られることもあります。両方の視点を持ちましょう。
第4条:複数の可視化を組み合わせる
1つのグラフだけでは伝わらない情報も、複数のグラフを組み合わせることで明確になります。
棒グラフで全体比較、レーダーチャートで多次元の俯瞰、ヒートマップで詳細確認、箱ひげ図で分布把握と、目的に応じて使い分けましょう。
第5条:具体的な数字で語る
「高い」「低い」という曖昧な表現ではなく、「平均の1.5倍」「月8万円」「全体の40%を占める」など、具体的な数字で語りましょう。
数字があることで、施策の優先順位や目標設定がしやすくなります。
第6条:ペルソナとして描く
「30代女性、週3回来店、日用品中心、会員歴3年」のように、各セグメントを具体的な人物像として描きましょう。
統計的なプロファイルだけでなく、その人がどんな生活をしているか想像することで、より効果的な施策が思いつきます。
第7条:施策につなげる
分析で終わらず、各セグメントへの具体的なアクションを提案しましょう。
「このセグメントにはこのDMを」「このセグメントには専用クーポンを」など、次のステップを明確にすることで、分析の価値が何倍にも高まります。
第8条:定期的に更新する
顧客は時間とともに変化します。1年前のセグメンテーションは、今日の顧客を正しく反映していない可能性があります。
半年〜1年に1回は再分析を行い、セグメントの定義や顧客の所属を更新しましょう。
第9条:移動を追跡する
同一顧客が時間の経過とともにどのセグメントに移動したかを追跡することで、施策の効果を測定できます。
「ライトユーザーがミドルユーザーに成長した割合」「プレミアム顧客が離反した割合」などを把握し、PDCAを回しましょう。
第10条:ステークホルダーと対話する
分析者だけで完結せず、現場のスタッフやマーケティング担当者と議論してブラッシュアップしましょう。
現場の肌感覚と数字が一致しているか確認することで、より実践的で説得力のある分析結果になります。
まとめ
全5回のシリーズ、お疲れさまでした!ここで学んだことを振り返りましょう。
第1回では距離の考え方を学びました。「似ている」を距離で数値化する方法として、ユークリッド距離、マンハッタン距離、Gower距離の使い分けと、標準化の重要性を理解しました。
第2回では階層的クラスタリングに取り組みました。「最も近いものからまとめる」という直感的なアルゴリズムを学び、デンドログラムで階層構造を可視化する方法を習得しました。
第3回ではK-means法を学びました。大規模データに対応できるこの手法のアルゴリズムと、初期値問題への対処(k-means++)を理解し、顧客セグメンテーションを実践しました。
第4回ではクラスタ数の決め方を学びました。エルボー法とシルエット分析を使って、データに適したクラスタ数を見極める方法を習得しました。
第5回ではクラスタープロファイリングを学びました。分析結果をビジネス価値に変換する方法として、可視化、命名、施策立案までの一連の流れを理解しました。
クラスター分析は、データの中に隠れた構造を発見する強力な手法です。しかし、その真価は「分析後」に発揮されます。
分析結果を理解し、意味のある名前をつけ、具体的な施策に落とし込む。このプロファイリングのプロセスこそが、データサイエンティストの腕の見せどころです。
このシリーズで学んだ知識を活かして、ぜひ実際のデータで手を動かしてみてください。理論と実践を往復することで、スキルは確実に身についていきます。
皆さんのデータ分析の旅に、このシリーズが少しでもお役に立てれば幸いです。