
前回は、Pywedge を使ったお手軽データビジュアライゼーション(データの可視化)について簡単に説明しました。
Pywedgeには、データビジュアライゼーションの他に前処理機能やベースモデル機能などがあります。現段階(2021年8月2日現在)では不完全な状態な気もしますが、興味のある方はデータビジュアライゼーションのついでに試してみてください。
と言うことで今回は、「Python Pywedge を使ったお手軽『前処理・ベースモデル構築・チューニング』」について簡単に説明します。
サンプルデータ
みんな大好きタイタニック(titanic)のデータを使います。
タイタニック(titanic)データと言っても色々ありますが、今回はSeabornのサンプルデータを使いますので、まだSeabornをインストールされていない方は、インストールしておいてください。

1912年に大西洋で氷山に衝突し沈没したタイタニック号の乗客者の生存状況に関するデータセットです。
目的変数yは、「survived」の「0:死亡、1:生存」の2値変数(カテゴリカル変数)です。
要するに今回は、2値の分類問題を扱います。Pywedgeは回帰問題の予測モデルも構築できます。
必要なライブラリーの読み込み
以下、コードです。
# ライブラリーの読み込み import pywedge as pw import pandas as pd import seaborn as sns from sklearn.metrics import accuracy_score, confusion_matrix from sklearn.model_selection import train_test_split
データセットの読み込み
以下、コードです。
# データセットの読み込み
df = sns.load_dataset('titanic')
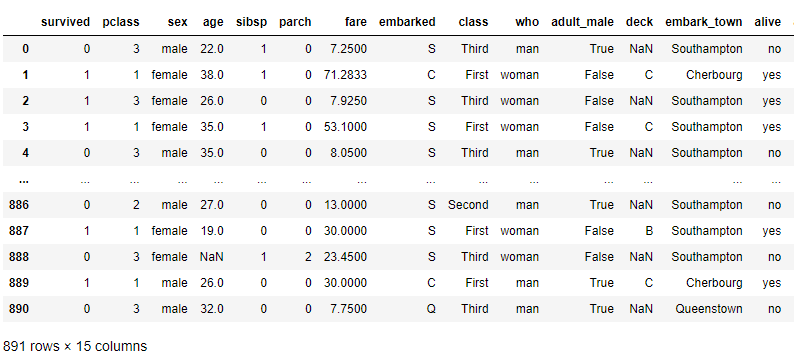
df #確認用
以下、実行結果です。
データを目的変数yと説明変数Xに分けます。
以下、コードです。
# 目的変数yと説明変数X y = df.iloc[:,0:1] #目的変数y X = df.iloc[:,1:9] #説明変数X
今回は、変数「who」以降(classより右側)の変数は使いません。
先ほども言いましたが、目的変数yは変数「survived」です。残りが説明変数Xです。
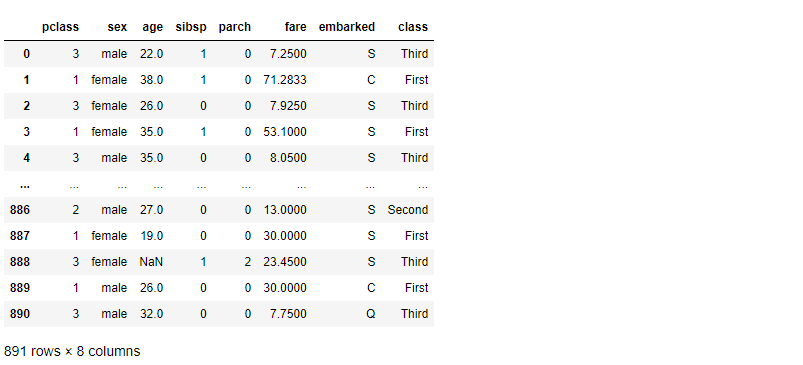
説明変数Xだけ確認してみます。
以下、コードです。
X
以下、実行結果です。
次に、学習データとテストデータに分割します。
以下、コードです。
# データセットの分割(学習データとテストデータ)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.8,
test_size=0.2,
random_state=42)
- X_train:学習データの説明変数
- X_test:テストデータの説明変数
- y_train:学習データの目的変数
- y_test:テストデータの目的変数
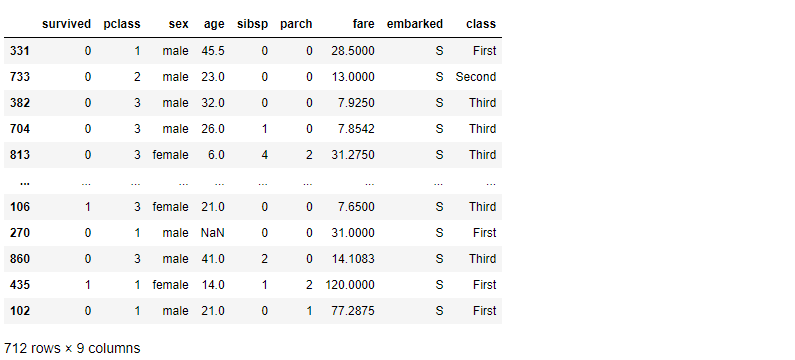
学習データの目的変数(y_train)と説明変数(x_train)を横に結合します。
以下、コードです。
# 学習データの目的変数と説明変数の結合(y,X) train = pd.concat([y_train, X_train], axis=1) train #確認用
以下、実行結果です。
Pywedgeを使った前処理とベースモデル構築
baseline_modelで前処理とベースモデルの構築をします。
ちなみに、ベースモデルとは、ハイパーパラメータのチューニングが実施されていないモデルです。要は、デフォルトの設定のまま構築したモデルです。
次の5つの設定をする必要があります。
- 学習データ(目的変数込み)
- テストデータ(目的変数なし)
- 目的変数(y)の指定
- 除外する変数(c)の指定
- 問題のタイプ(Classification:分類問題、Regression:回帰問題)
以下、コードです。
# 前処理とベースモデル構築
blm = pw.baseline_model(train,
X_test,
y='survived',
c=None,
type = 'Classification')
blm.classification_summary()
コードの最後の行は、今回は分類問題でしたので「classification_summary()」にしていますが、回帰問題の場合には「Regression_summary()」になります。
以下、実行結果です。
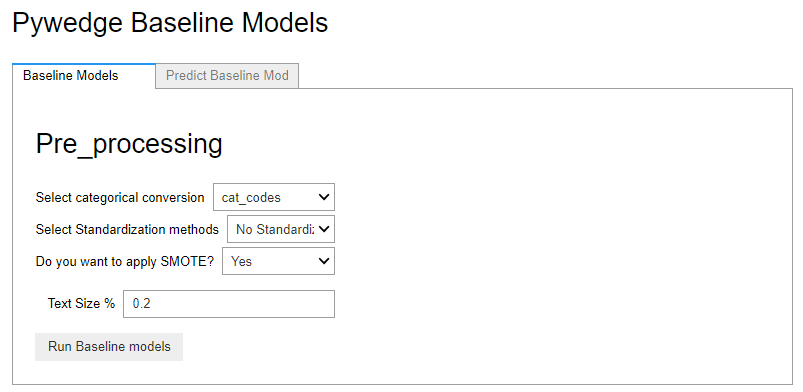
この実行画面で前処理(Pre_processing)の設定をし、ボタン「Run Baseline models」をクリックするとベースモデルが構築されます。
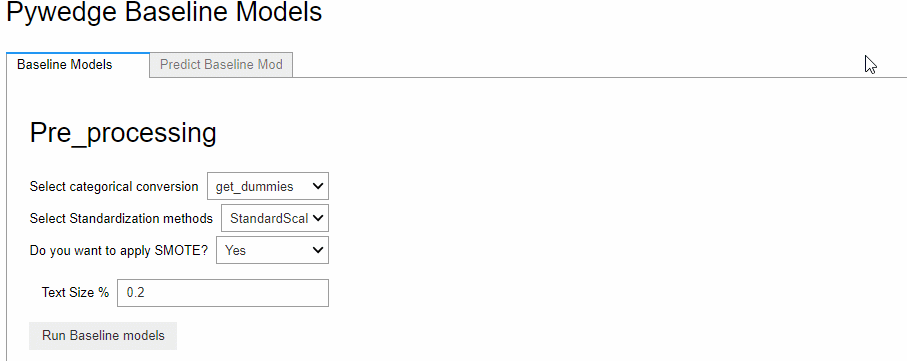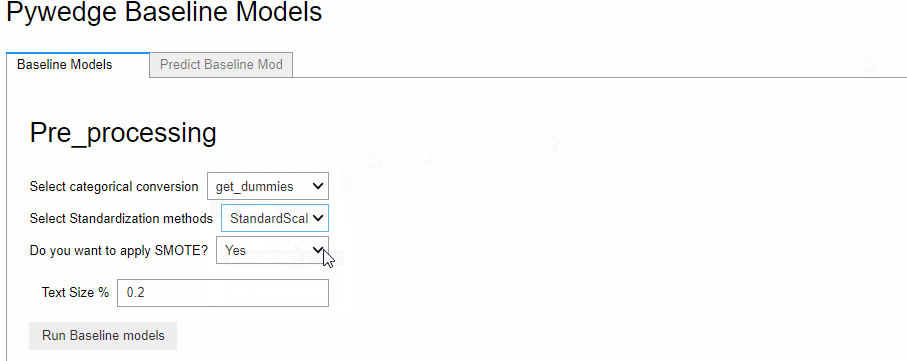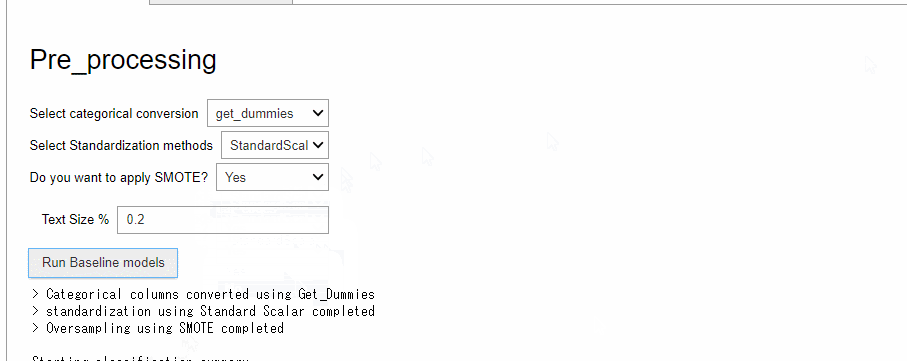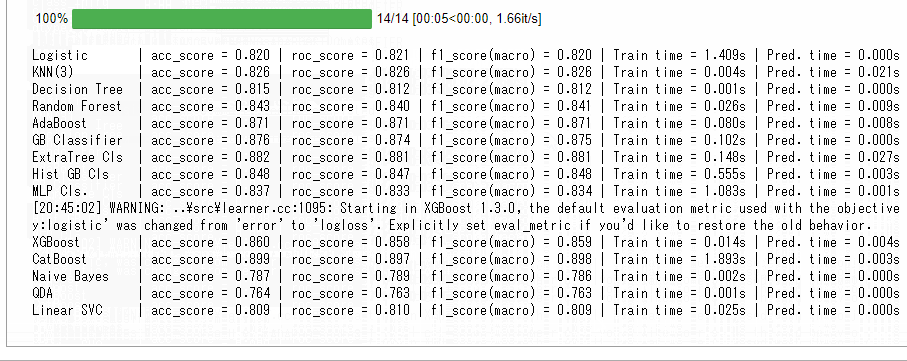
今回は、カテゴリカルデータをダミー化(One-hot encoding)を実施、量的データを一般的な標準化(平均が0で分散が1のデータに変換)しています。SMOTE(Synthetic Minority Oversampling Technique)で、目的変数yの0-1の不均等(「0:死亡」の数と「1:生存」の数が異なる状態)を是正しています。
構築後、テストデータを予測することができます。
タブ「Predict Baseline Mod」をクリックし、モデルを選択し実行するとテストデータの予測値が計算され、predictions_baselineに予測結果が格納されます。
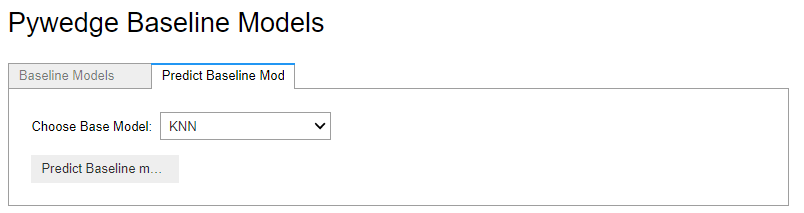
今回はもっともシンプルなアルゴリズムであるKNN(k-近傍法)で予測してみました。
テストデータの予測結果の精度を、正答率で評価してみます。
以下、コードです。
# 評価(テストデータの正答率) accuracy_score(y_test,blm.predictions_baseline)
以下、実行結果です。
![]()
正答率は、75.42%です。
ベースモデルの結果から、どのアルゴリズムが良さそうなのかの検討が付くと思います。次にすべきは、ハイパーパラメータのチューニングでしょう。
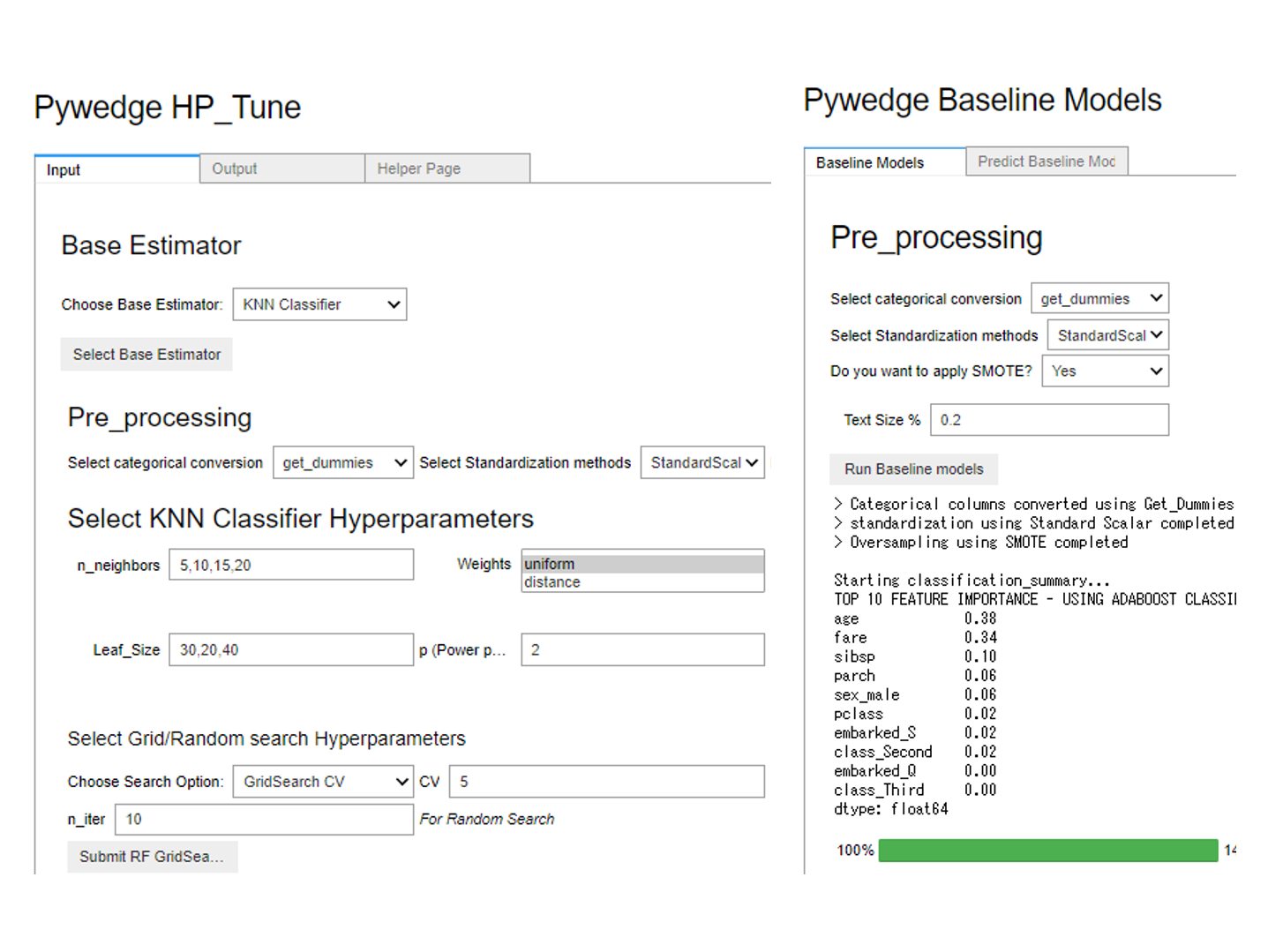
Pywedgeを使ったハイパーパラメータのチューニング
Pywedge_HPでハイパーパラメータのチューニングをします。
次の6つの設定をする必要があります。
- 学習データ(目的変数込み)
- テストデータ(目的変数なし)
- 目的変数(y)の指定
- 除外する変数(c)の指定
- ハイパーパラメータのトラッキング(tracking)の指定(True or False)
- 問題のタイプ(Classification:分類問題、Regression:回帰問題)
以下、コードです。
# ハイパーパラメータチューニング
pph = pw.Pywedge_HP(train,
X_test,
c=None,
y='survived',
tracking=False)
pph.HP_Tune_Classification()
コードの最後の行は、今回は分類問題でしたので「HP_Tune_Classification()」にしていますが、回帰問題の場合には「HP_Tune_Regression()」になります。
以下、実行結果です。
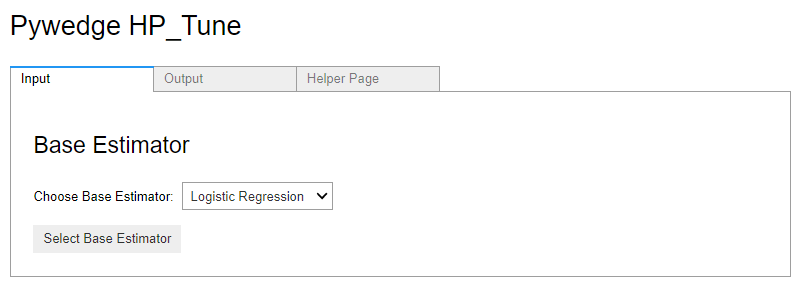
この実行画面でモデルを選択し、チューニングするハイパーパラメータを設定し、i一番下にあるボタン「submit …」をクリックするとハイパーパラメータチューニングが実行されます。最適なモデルのテストデータの予測結果はpredict_Hに格納されます。
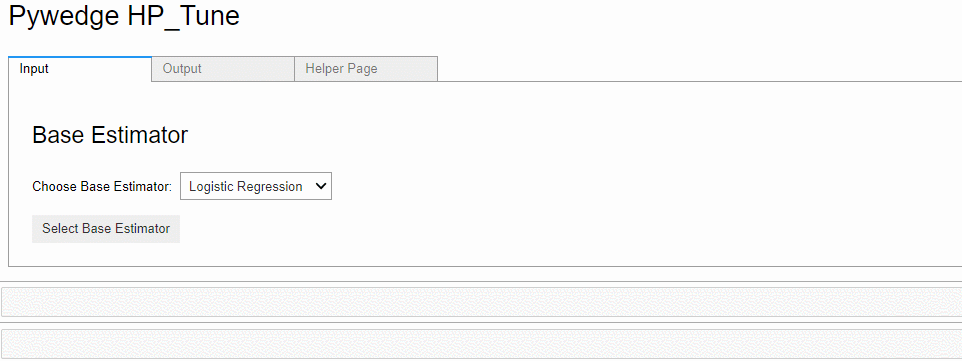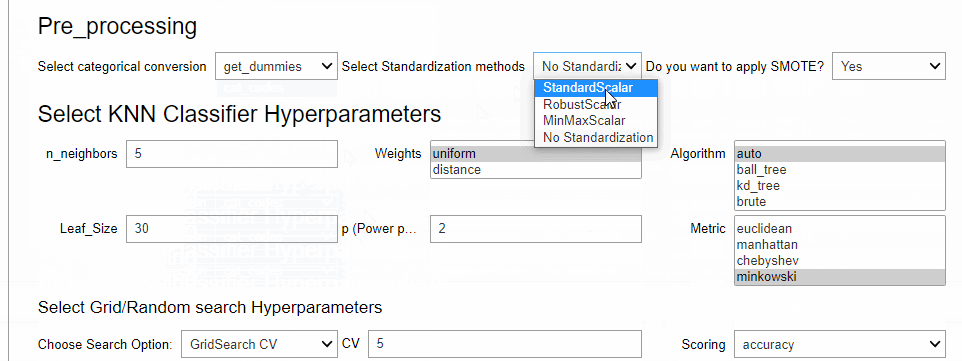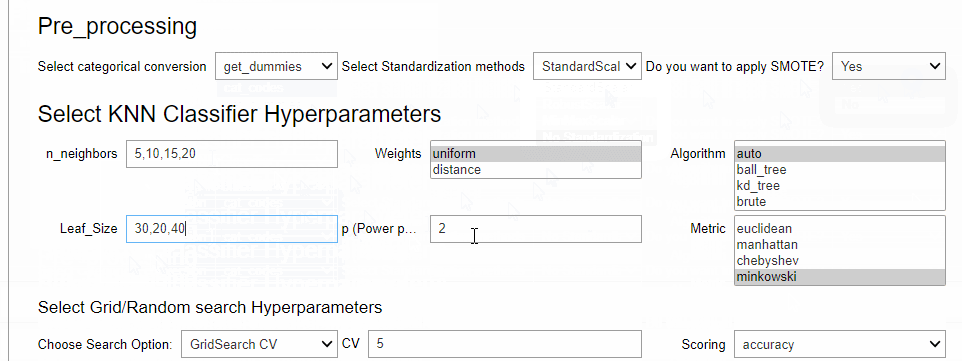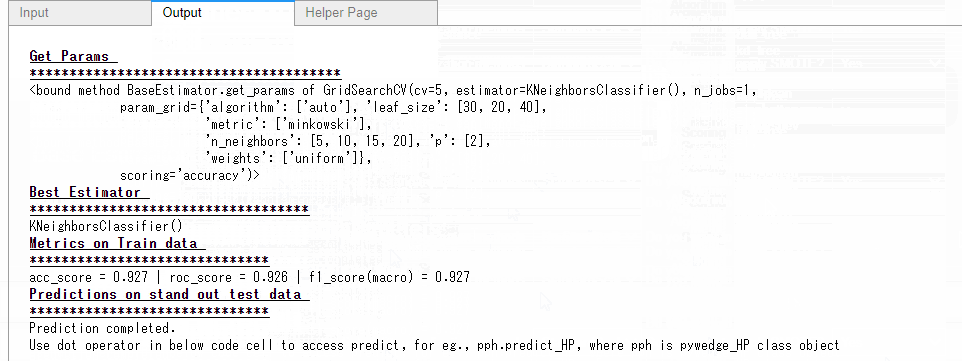
今回はもっともシンプルなアルゴリズムであるKNN(k-近傍法)のハイパーパラメータチューニングをしてみました。タブ「Output」をクリックすると、ハイパーパラメータチューニングの結果を見ることができます。
テストデータの予測結果の精度を、正答率で評価してみます。
以下、コードです。
# 評価(テストデータの正答率) accuracy_score(y_test,pph.predict_HP)
以下、実行結果です。
![]()
正答率は、80.45%です。
まとめ
今回は、「Python Pywedge を使ったお手軽『前処理・ベースモデル構築・チューニング』」について簡単に使い方を解説しました。
Pywedgeはどちらかと言うと、データビジュアライゼーションのツールとして使った方がいいでしょう。興味のある方はデータビジュアライゼーションのついでに、モデル構築にも使ってみてください。