

前回の記事では、正規分布について紹介しました。
正規分布は「身長」「テストの点数」のように、小数を含む連続的な値のデータに使われる確率分布でした。
しかし、データ分析の現場では、「回数」 を扱う場面も非常に多くあります。
- 1日あたりのWebサイトの不具合報告数
- 1ページあたりの誤字の数
これらはすべて「0回、1回、2回…」と 整数でカウントされるデータ です。
こうしたデータの確率分布を表すのが ポアソン分布 です。
今回は、ポアソン分布の基本概念とSciPyでの扱い方を、できるだけ平易に解説します。
正規分布とポアソン分布の違い(前回の復習)
まず、前回紹介した正規分布との違いを明確にしておきましょう。
| 比較項目 | 正規分布(前回) | ポアソン分布(今回) |
|---|---|---|
| 扱うデータ | 連続データ(小数を含む値) | 離散データ(整数の回数) |
| データの例 | 身長、テスト点数、気温 | 来客数、故障回数、メール受信数 |
| 値の範囲 | -\infty \sim +\infty(どんな値も取りうる) | 0, 1, 2, 3, …(0以上の整数) |
| 確率の求め方 | PDF(確率密度関数) | PMF(確率質量関数) |
| パラメータ | μ(平均)とσ(標準偏差)の2つ |
ポアソン分布とは?
ポアソン分布 は、一定の時間や空間の中で、ある事象が起こる「回数」の確率分布です。
「平均してλ(ラムダ)回起こる事象が、実際には何回起こるか?」を表す分布です。
ポアソン分布は、以下の条件を満たすデータによく当てはまります。
- 一定の期間・空間における平均発生回数がわかっている
SciPyでポアソン分布を使ってみよう
ポアソン分布は λ(ラムダ) というパラメータ1つだけで形が決まります。
| パラメータ | 記号 | SciPyでの名前 | 意味 |
|---|---|---|---|
| 平均発生回数 | λ(ラムダ) | mu |
正規分布はμとσの2つが必要でしたが、ポアソン分布はλだけで決まるのが特徴です。
ポアソン分布では、平均も分散も λ に等しいという面白い性質があります。
- 平均 = \lambda
- 分散 = \lambda
- 標準偏差 = \sqrt{\lambda}
SciPyでは、stats.poisson でポアソン分布を扱います。
from scipy import stats
# 平均発生回数(λ)を設定
lam = 5
print("【各回数の確率】")
# 0回から10回までの発生回数 k に対して確率を計算
for k in range(11):
# ポアソン分布の確率質量関数 PMF を計算
prob = stats.poisson.pmf(k, mu=lam)
# 視覚化用のバー(確率×100 を長さに)
bar = '█' * int(prob * 100)
# 回数、確率、百分率、バーを表示
print(f" {k:>2d}回:{prob:.4f}({prob*100:5.1f}%){bar}")
このコードでは、SciPyの stats.poisson を使って、ポアソン分布の各回数の確率を計算しています。
まず、lam = 5 で平均発生回数 \lambda を 5 に設定しています。ポアソン分布では、この \lambda が「一定の時間や場所の中で、平均して何回起こるか」を表します。
次に、for k in range(11) によって、0回から10回までの発生回数 k について順番に調べています。
ループの中では、stats.poisson.pmf(k, mu=lam) を使って、「k 回起こる確率」を計算しています。ここで pmf は確率質量関数で、離散型の分布において各値そのものの確率を求めるものです。
また、bar = '█' * int(prob * 100) では、確率の大きさが目で分かるように、確率に応じた長さの棒を文字で作っています。最後に、各回数について、確率、小数を百分率に直した値、簡単な棒グラフを1行ずつ表示しています。これにより、どの回数が起こりやすいかを数値と見た目の両方で確認できます。
以下、実行結果です。
【各回数の確率】 0回:0.0067( 0.7%) 1回:0.0337( 3.4%)███ 2回:0.0842( 8.4%)████████ 3回:0.1404( 14.0%)██████████████ 4回:0.1755( 17.5%)█████████████████ 5回:0.1755( 17.5%)█████████████████ 6回:0.1462( 14.6%)██████████████ 7回:0.1044( 10.4%)██████████ 8回:0.0653( 6.5%)██████ 9回:0.0363( 3.6%)███ 10回:0.0181( 1.8%)█
実行結果を見ると、\lambda=5 のときは、4回と5回の確率が最も高く、どちらも約17.5%になっています。これは、平均が5回なので、その近くの回数が最も起こりやすいことを示しています。
一方で、0回や1回のようにかなり少ない回数や、10回のように平均から離れた大きな回数の確率は小さくなっています。つまり、ポアソン分布では、平均付近の値が起こりやすく、そこから離れるほど起こりにくくなる傾向があります。
この結果から、ポアソン分布は「平均発生回数を中心に、前後の整数回数に確率が分かれる分布」であることが分かります。特に、連続値ではなく 0回、1回、2回…のような飛び飛びの回数データを扱うときに向いている、という特徴も確認できます。
\lambdaを変えたときのポアソン分布の形の変化を確認してみましょう。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from scipy import stats
# 0〜24までの整数(発生回数の軸)
k = np.arange(0, 25)
# 縦に3つのサブプロットを作成
fig, axes = plt.subplots(3, 1, figsize=(8, 10))
# 3つのλ(平均)と対応する色を用意
lambdas = [2, 5, 10]
colors = ['green', 'blue', 'purple']
# 各λごとにポアソン分布のPMFを計算して棒グラフで表示
for i, (lam, color) in enumerate(zip(lambdas, colors)):
pmf = stats.poisson.pmf(k, mu=lam) # 確率質量関数(PMF)
axes[i].bar(k, pmf, color=color, alpha=0.7, edgecolor='black') # 棒グラフ
axes[i].set_title(f'ポアソン分布(λ={lam})\n平均={lam}, 標準偏差={np.sqrt(lam):.2f}') # タイトル
axes[i].set_xlabel('発生回数') # x軸ラベル
axes[i].set_ylabel('確率') # y軸ラベル
axes[i].set_xlim(-0.5, 24.5) # x軸範囲
axes[i].set_ylim(0, 0.35) # y軸範囲
axes[i].grid(True, alpha=0.3) # グリッド表示
plt.tight_layout()
plt.show()
このコードでは、\lambda を 2、5、10 の3通りに変えながら、それぞれのポアソン分布を描いています。
まず、k = np.arange(0, 25) で、発生回数として 0 回から 24 回までの整数を用意しています。これは横軸にあたります。次に、plt.subplots(3, 1, figsize=(8, 10)) によって、グラフを縦に3つ並べて表示できるようにしています。
lambdas = [2, 5, 10] では、比較したい \lambda の値を指定しています。for 文の中では、それぞれの \lambda について stats.poisson.pmf(k, mu=lam) を使い、各回数が起こる確率を計算しています。ここで pmf は「確率質量関数」で、離散的な値ごとの確率を求めるものです。
その後、bar() を使って棒グラフを描いています。タイトルには \lambda の値だけでなく、平均と標準偏差も表示しています。ポアソン分布では、平均は \lambda、標準偏差は \sqrt{\lambda} になるため、それも合わせて確認できるようにしています。
最後に、軸ラベルや表示範囲、グリッドを整えたうえで、グラフを表示しています。
以下、実行結果です。
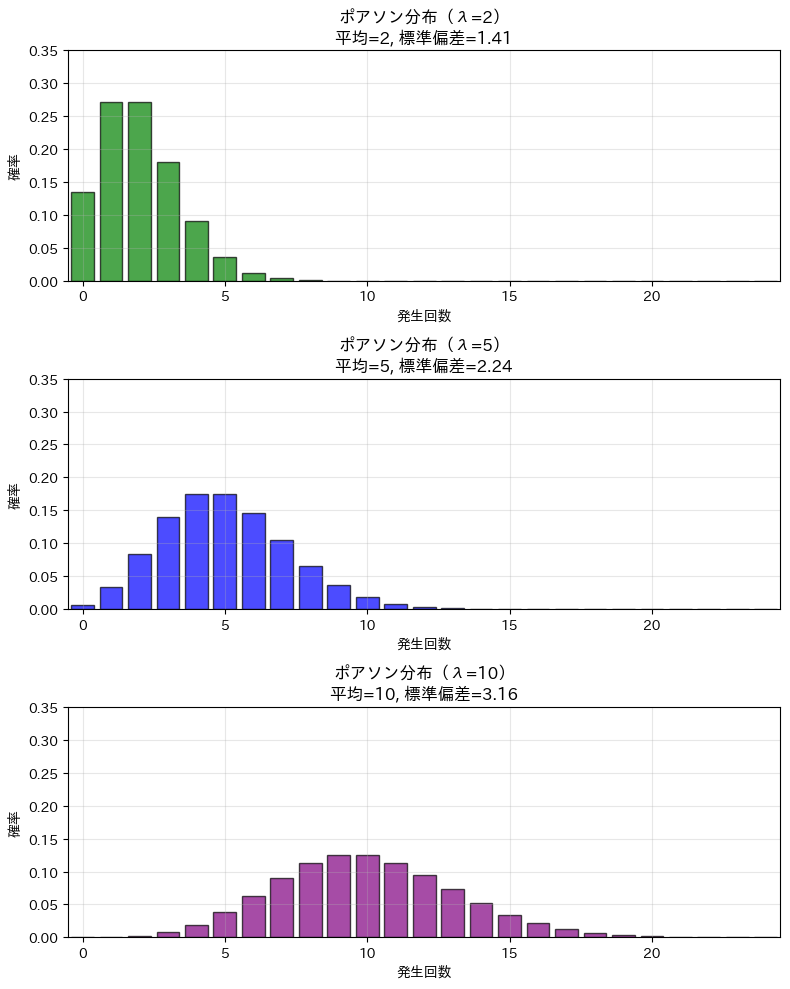
図を見ると、\lambda=2 のときは 0回、1回、2回あたりの確率が高く、右に長く裾を引く形になっています。
\lambda=5 になると、分布の山は右に移動し、3回~6回あたりが起こりやすくなります。さらに \lambda=10 では、山はもっと右に移り、形も左右にやや広がって、以前よりなだらかに見えるようになります。
このように、ポアソン分布は \lambda の値によって、どこを中心に分布するか と どのくらい広がるか が変わります。
\lambda が小さいと少ない回数に集中し、\lambda が大きいとより大きな回数を中心とした分布になる、というのが基本的な見方です。
PMF(確率質量関数)とは?
前回の正規分布ではPDF(確率密度関数)を使いましたが、ポアソン分布では PMF(確率質量関数) を使います。
PMF(Probability Mass Function) は、離散データにおいて、ある値が出る確率そのものを表します。
PDFとの違いを確認しておきましょう。
| 対象データ | 返す値 | 使う分布の例 | |
|---|---|---|---|
| PDF(確率密度関数) | 連続データ | 確率の「密度」(面積が確率) | 正規分布 |
| PMF(確率質量関数) | 離散データ | その値が出る「確率そのもの」 |
PDFでは「ちょうどx=3.0」の確率はゼロでしたが、PMFでは「ちょうど3回」の確率をズバリ求められます。
PDFとPMFの違いをグラフで確認してみましょう。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 2行1列のサブプロットを作成
fig, axes = plt.subplots(2, 1, figsize=(8, 6))
# 上:正規分布のPDF(連続 → 曲線)
# x軸の連続値を生成
x_cont = np.linspace(-4, 4, 300)
# 正規分布のPDFを曲線で描画
axes[0].plot(x_cont, stats.norm.pdf(x_cont), color='blue', linewidth=2)
# 曲線の下の面積を薄い色で塗る(面積=確率のイメージ)
axes[0].fill_between(x_cont, stats.norm.pdf(x_cont), alpha=0.2, color='blue')
# タイトルと軸ラベル、グリッド
axes[0].set_title('PDF(正規分布)\n曲線 → 面積が確率')
axes[0].set_xlabel('値')
axes[0].set_ylabel('確率密度')
axes[0].grid(True, alpha=0.3)
# 下:ポアソン分布のPMF(離散 → 棒グラフ)
# 0〜14の離散値(発生回数)
k = np.arange(0, 15)
# λ=5のポアソン分布のPMFを棒グラフで描画
axes[1].bar(k, stats.poisson.pmf(k, mu=5), color='green', alpha=0.7, edgecolor='black')
# タイトルと軸ラベル、グリッド
axes[1].set_title('PMF(ポアソン分布 λ=5)\n棒の高さ = そのまま確率')
axes[1].set_xlabel('発生回数')
axes[1].set_ylabel('確率')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
このコードでは、PDF(確率密度関数) と PMF(確率質量関数) の違いを、2つのグラフで見比べられるようにしています。
まず、plt.subplots(2, 1, figsize=(8, 6)) で、グラフを縦に2つ並べる準備をしています。上のグラフでは正規分布を使い、下のグラフではポアソン分布を使います。
上のグラフでは、np.linspace(-4, 4, 300) によって -4 から 4 までの連続的な値をたくさん用意し、それに対して stats.norm.pdf(x_cont) で正規分布のPDFを計算しています。これを plot() で滑らかな曲線として描き、さらに fill_between() で曲線の下を塗ることで、「連続型の分布では、ある範囲の面積が確率を表す」というイメージが分かるようにしています。
下のグラフでは、np.arange(0, 15) によって 0回から14回までの離散的な値を用意し、stats.poisson.pmf(k, mu=5) でポアソン分布のPMFを計算しています。こちらは bar() を使って棒グラフで描いており、「離散型の分布では、それぞれの値に対応する棒の高さそのものが確率を表す」ということが見て分かるようになっています。
このように、同じ「確率分布」を表すグラフでも、連続型では曲線と面積、離散型では棒グラフと高さで表現する、という違いがあります。
以下、実行結果です。
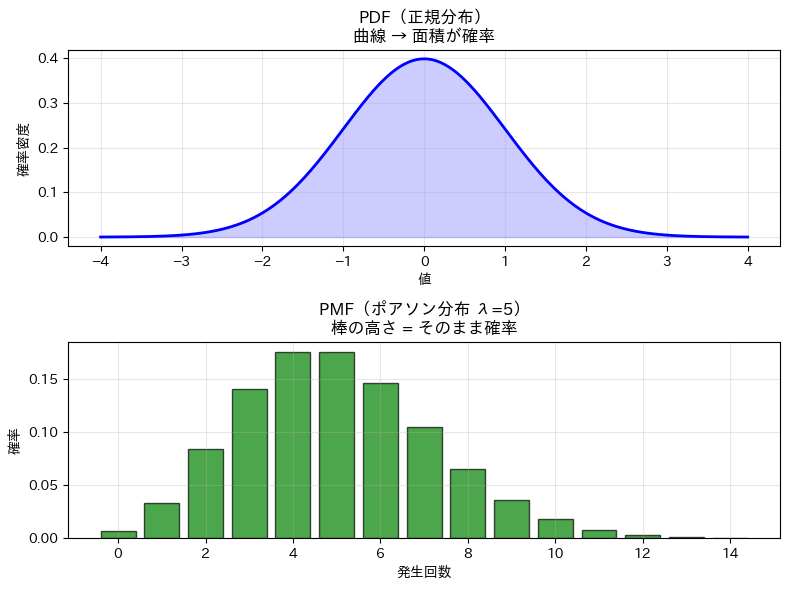
実行結果を見ると、上の正規分布のグラフは滑らかな曲線になっています。これは、正規分布が連続型の確率分布だからです。
連続型では、ある1点だけを取り出した確率は考えず、「この範囲に入る確率」を曲線の下の面積で考えます。そのため、縦軸は「確率」そのものではなく、「確率密度」となっています。
一方、下のポアソン分布のグラフは棒グラフになっています。
これは、ポアソン分布が離散型の確率分布だからです。離散型では、0回、1回、2回…のように値が飛び飛びになっており、それぞれの値に対して直接確率を割り当てることができます。そのため、棒の高さがそのまま「その回数が起こる確率」を表しています。
この図から分かるのは、PDFは曲線の下の面積で確率を考えるのに対し、PMFは各値に対応する棒の高さで確率を表すということです。
見た目は似た「分布のグラフ」でも、確率の読み方が異なる点が重要です。
乱数生成とシミュレーション
ポアソン分布から乱数を生成して、シミュレーションを行ってみましょう。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 乱数の再現性を保つためのシード設定
np.random.seed(42)
# ポアソン分布の平均(λ)を設定:平均5件/時間、500時間分をシミュレーション
lam = 5
calls = stats.poisson.rvs(mu=lam, size=500) # ポアソン分布に従う乱数を生成
# 結果の統計量を表示
print("【シミュレーション結果(500時間分の問い合わせ件数)】")
print(f" 平均件数 :{calls.mean():.2f} 件/時間(理論値: {lam})") # 経験平均と理論値
print(f" 標準偏差 :{calls.std():.2f}(理論値: {np.sqrt(lam):.2f})") # 経験標準偏差と理論値
print(f" 最小件数 :{calls.min()} 件") # 観測最小値
print(f" 最大件数 :{calls.max()} 件") # 観測最大値
print(f" 0件の割合 :{(calls == 0).sum() / len(calls) * 100:.1f}%"
f"(理論値: {stats.poisson.pmf(0, lam)*100:.1f}%)") # 0件の確率(経験と理論)
このコードでは、ポアソン分布に従う乱数を実際に発生させて、シミュレーションを行っています。
まず、np.random.seed(42) で乱数の種を固定しています。これにより、毎回ほぼ同じ結果を再現できるようになります。
次に、lam = 5 で平均問い合わせ件数を 5 件/時間に設定し、stats.poisson.rvs(mu=lam, size=500) によって、500時間分の問い合わせ件数をランダムに生成しています。ここで rvs は「乱数を発生させるメソッド」です。
そのあと、生成したデータについて、平均、標準偏差、最小値、最大値、さらに「0件だった時間の割合」を計算して表示しています。平均と標準偏差については、シミュレーションで得られた値だけでなく、ポアソン分布の理論値もあわせて表示しているため、乱数で作ったデータが理論的な性質にどのくらい近いかを確認できるようになっています。
以下、実行結果です。
【シミュレーション結果(500時間分の問い合わせ件数)】 平均件数 :4.97 件/時間(理論値: 5) 標準偏差 :2.29(理論値: 2.24) 最小件数 :0 件 最大件数 :12 件 0件の割合 :0.6%(理論値: 0.7%)
実行結果を見ると、シミュレーションで得られた平均件数は 4.97 件/時間で、理論値の 5 にかなり近くなっています。
標準偏差も 2.29 で、理論値の 2.24 に近い値です。また、0件の割合も 0.6% で、理論値の 0.7% とほぼ一致しています。
もちろん、乱数を使っているので毎回ぴったり理論値と同じになるわけではありません。
しかし、500時間分のようにある程度まとまったデータを生成すると、全体としては理論上のポアソン分布の性質にかなり近い結果になることが分かります。
このように、シミュレーションを行うと、ポアソン分布が「平均付近の値を中心にばらつく分布」であることや、理論値が実際のランダムなデータの中にも表れてくることを具体的に確認できます。
次に、生成した 500 時間分の問い合わせ件数をヒストグラムで可視化し、理論上のポアソン分布と重ねて比べてみましょう。
以下、コードです。
# ヒストグラムと理論PMFを同じ図に描画
k = np.arange(0, calls.max() + 2) # x軸として使用する離散値の範囲
plt.figure(figsize=(8, 4)) # 図のサイズ
# ヒストグラム(密度表示にして確率に正規化)
plt.hist(calls, bins=np.arange(-0.5, calls.max()+1.5, 1),
color='green', alpha=0.7, edgecolor='black',
density=True, label='シミュレーション(500時間)')
# 理論のポアソンPMFを点線と点で重ねる
plt.plot(k, stats.poisson.pmf(k, mu=lam), 'ro-', markersize=8,
linewidth=2, label=f'理論曲線(λ={lam})')
# 軸ラベルやタイトルなどの装飾
plt.xlabel('問い合わせ件数')
plt.ylabel('確率')
plt.title('ポアソン分布からの乱数生成:500時間の問い合わせシミュレーション')
plt.xticks(k) # x軸の目盛を整数に設定
plt.legend()
plt.grid(True, alpha=0.3, axis='y') # y方向のグリッド
plt.tight_layout()
plt.show()
このコードでは、シミュレーションで得られた問い合わせ件数の分布をヒストグラムで表し、それに理論上のポアソン分布の PMF を重ねて描いています。
plt.hist() では、500時間分のデータがそれぞれ何件だったかを集計し、確率として比較しやすいように density=True を指定して正規化しています。棒の高さは、「その件数がどのくらいの割合で現れたか」を表しています。
一方、plt.plot() では、同じ \lambda=5 のポアソン分布について理論的な確率を計算し、赤い点と線で重ねています。
このように、シミュレーション結果と理論値を1つの図に重ねることで、実際に発生させた乱数の分布が、理論上のポアソン分布にどのくらい近いかを視覚的に確認できます。
以下、実行結果です。
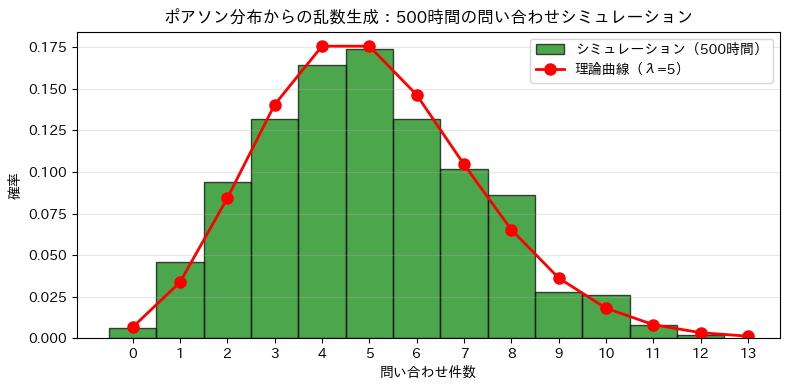
ヒストグラムの山がおおむね 4 件や 5 件付近に集まり、赤い理論曲線ともよく対応しているはずです。多少のずれはありますが、これは乱数による自然なばらつきです。
全体として形がよく似ているため、シミュレーション結果がポアソン分布の性質をうまく再現していると考えられます。
λが大きいとき、正規分布に近づく
ポアソン分布の面白い性質として、λが大きくなると正規分布に近づくというものがあります。
以下、コードです。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# 4つのサブプロットを縦に作成)
fig, axes = plt.subplots(4, 1, figsize=(8, 10))
axes = axes.flatten() # 取り回しやすいように1次元配列に変換
# 検証するλ(平均値)のリスト
lambdas = [2, 5, 15, 50]
# 各λに対してポアソン分布と近似する正規分布を重ね描き
for i, lam in enumerate(lambdas):
# 可視化範囲:平均±4σ程度まで(離散値の上限を整数で設定)
k_max = int(lam + 4 * np.sqrt(lam)) + 1
k = np.arange(0, k_max) # 離散のx軸(件数)
pmf = stats.poisson.pmf(k, mu=lam) # ポアソン分布のPMF
# ポアソン分布(棒グラフで表示)
axes[i].bar(k, pmf, color='green', alpha=0.6, edgecolor='black', label='ポアソン分布')
# 対応する正規分布(連続なので曲線で表示)
x_cont = np.linspace(0, k_max, 300) # 連続のx軸
axes[i].plot(
x_cont,
stats.norm.pdf(x_cont, loc=lam, scale=np.sqrt(lam)), # 平均=λ, 分散=λ → 標準偏差=√λ
color='red', linewidth=2, label=f'正規分布(μ={lam}, σ={np.sqrt(lam):.1f})'
)
# タイトル・ラベル・凡例・グリッドの設定
axes[i].set_title(f'λ={lam}')
axes[i].set_xlabel('値')
axes[i].set_ylabel('確率')
axes[i].legend(fontsize=9)
axes[i].grid(True, alpha=0.3)
plt.suptitle('λが大きくなると、ポアソン分布は正規分布に近づく', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
このコードでは、\lambda の値を少しずつ大きくしたときに、ポアソン分布の形が正規分布にどのように近づいていくかを確かめています。
まず、lambdas = [2, 5, 15, 50] で、比較する \lambda の値を 4 通り用意しています。for 文の中では、それぞれの \lambda に対して、ポアソン分布と、それに対応する正規分布を同じグラフに重ねて描いています。
ポアソン分布は離散型の分布なので、stats.poisson.pmf() を使って各整数値の確率を求め、棒グラフで表しています。
一方、正規分布は連続型の分布なので、stats.norm.pdf() を使って確率密度を計算し、赤い滑らかな曲線として描いています。
ここで重ねている正規分布は、平均を \lambda、標準偏差を \sqrt{\lambda} に設定しています。
これは、ポアソン分布が 平均 \lambda、分散 \lambda をもつため、それに合わせた正規分布を比較対象にしているからです。
このようにして、\lambda が小さいときと大きいときで、ポアソン分布の形がどのように変わり、正規分布にどのくらい近づくのかを見やすくしています。
以下、実行結果です。
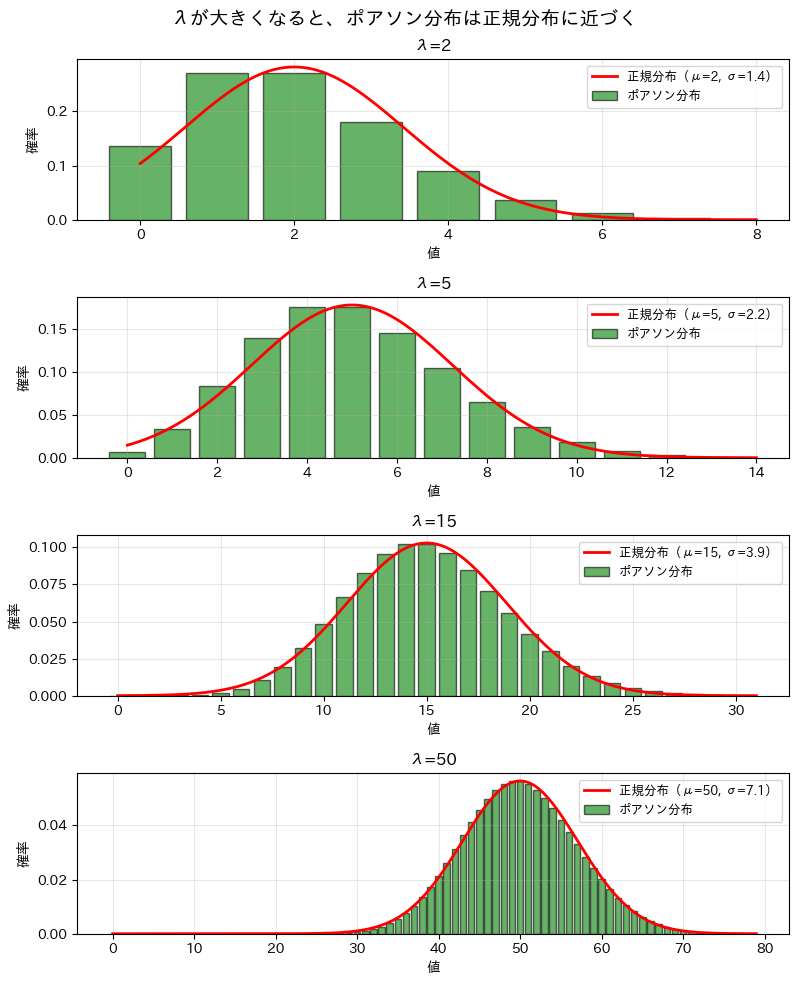
実行結果を見ると、\lambda=2 のときは、ポアソン分布は右に裾を引いた非対称な形をしており、正規分布の曲線とはあまり一致していません。
\lambda=5 になると少し形がなめらかになり、正規分布にやや近づいてきますが、まだ違いは残っています。さらに \lambda=15 になると、ポアソン分布の山の形がかなり左右対称に近づき、正規分布の曲線ともだいぶ重なるようになります。
そして \lambda=50 では、棒グラフの形が赤い正規分布の曲線とかなりよく一致しており、ポアソン分布が正規分布で近似できることが視覚的に分かります。
このように、ポアソン分布は \lambda が小さいうちは右に歪んだ形をしていますが、\lambda が大きくなるにつれて左右対称に近づき、正規分布に似た形になっていきます。
これが「\lambda が大きいとき、ポアソン分布は正規分布に近づく」という性質です。
SciPyで使えるポアソン分布メソッドのまとめ
stats.poisson で使えるメソッドを整理します。前回の正規分布と対比して覚えましょう。
| メソッド | 意味 | |
|---|---|---|
pmf(k) |
確率質量関数(ちょうどk回の確率) | pdf(x) に対応 |
cdf(k) |
累積分布関数(k回以下の確率) | 共通 |
ppf(q) |
パーセント点関数(確率→回数) | 共通 |
rvs(size=n) |
乱数生成 | 共通 |
mean() |
理論的な平均(= \lambda) | 共通 |
std() |
理論的な標準偏差(= \sqrt{\lambda}) | 共通 |
各メソッドを実行してみましょう
以下、コードです。
from scipy import stats
# 分布オブジェクトを作成(λ=5)
dist = stats.poisson(mu=5)
print("【ポアソン分布メソッド一覧(λ=5)】")
print(f" 平均 : {dist.mean():.1f}")
print(f" 標準偏差 : {dist.std():.4f}")
print(f" PMF(k=5) : {dist.pmf(5):.4f}(ちょうど5回の確率)")
print(f" PMF(k=0) : {dist.pmf(0):.4f}(ゼロ回の確率)")
print(f" CDF(k=7) : {dist.cdf(7):.4f}(7回以下の確率)")
print(f" 1-CDF(k=7) : {1-dist.cdf(7):.4f}(8回以上の確率)")
print(f" PPF(q=0.95) : {dist.ppf(0.95):.0f}(95%カバーの回数)")
このコードでは、stats.poisson(mu=5) を使って、\lambda=5 のポアソン分布オブジェクトを作り、その分布で使える代表的なメソッドを順番に実行しています。
dist.mean() は平均、dist.std() は標準偏差を返します。ポアソン分布では平均は \lambda、標準偏差は \sqrt{\lambda} なので、ここでは平均 5、標準偏差 約 2.236 になることを確認しています。
dist.pmf(5) は「ちょうど 5 回起こる確率」、dist.pmf(0) は「1回も起こらない確率」を求めています。pmf は離散型分布で、各値そのものの確率を返すメソッドです。
また、dist.cdf(7) は「7回以下になる確率」を表しています。cdf は累積分布関数で、「その値以下になる確率」を求めるものです。
1 - dist.cdf(7) とすると、「7回以下」の反対なので、「8回以上になる確率」が分かります。
最後の dist.ppf(0.95) は、累積確率が 95% に達する境目の回数を求めています。これは「95%点」と呼ばれるもので、「全体の 95% がこの値以下に入るような回数」を調べるときに使います。
以下、実行結果です。
【ポアソン分布メソッド一覧(λ=5)】 平均 : 5.0 標準偏差 : 2.2361 PMF(k=5) : 0.1755(ちょうど5回の確率) PMF(k=0) : 0.0067(ゼロ回の確率) CDF(k=7) : 0.8666(7回以下の確率) 1-CDF(k=7) : 0.1334(8回以上の確率) PPF(q=0.95) : 9(95%カバーの回数)
実行結果を見ると、平均は 5.0、標準偏差は 2.2361 となっており、ポアソン分布の性質である「平均 = \lambda」「標準偏差 = \sqrt{\lambda}」がそのまま確認できます。
PMF(k=5) は 0.1755 なので、\lambda=5 のとき「ちょうど 5 回起こる確率」は約 17.6% です。PMF(k=0) は 0.0067 なので、「まったく起こらない確率」は約 0.7% とかなり小さいことが分かります。
CDF(k=7) は 0.8666 なので、「7回以下になる確率」は約 86.7% です。したがって、その反対である「8回以上になる確率」は 1-CDF(k=7) の 0.1334、つまり約 13.3% になります。
また、PPF(q=0.95) が 9 という結果は、「95%の確率で 9 回以下に収まる」と読めます。言い換えると、10回以上になるのは比較的まれであり、\lambda=5 のポアソン分布では、たいてい 9 回以下の範囲に入ることを示しています。
> 補足:過分散(かぶんさん)
> 実際のデータでは、ポアソン分布の仮定(平均 = 分散)が成り立たないことも多くあります。分散が平均より大きい状態を過分散(overdispersion)と呼びます。このような場合は、負の二項分布など、より柔軟な分布を使うことが推奨されます。
まとめ
この記事のポイントを振り返りましょう。
- ポアソン分布 は、一定の期間・空間内で事象が起こる「回数」の確率分布
- パラメータは λ(平均発生回数)の1つだけ で、平均も分散もλに等しい
- 離散データなので、PDFではなく PMF(確率質量関数) を使う
- SciPyでは
stats.poissonで扱い、pmf、cdf、ppf、rvsなどが使える
- λが大きくなると正規分布に近づく 性質がある
- 人員配置、障害予測、需要予測 など、ビジネスの実務に直結する分析ができる
- 平均と分散がほぼ等しいかを確認して、ポアソン分布の適用可否を判断する
次回は、「scipy.spatial:距離計算とクラスタリングの前処理」 をテーマに、データ間の「近さ」を測る方法と、機械学習の前処理で役立つ知識を紹介します。