
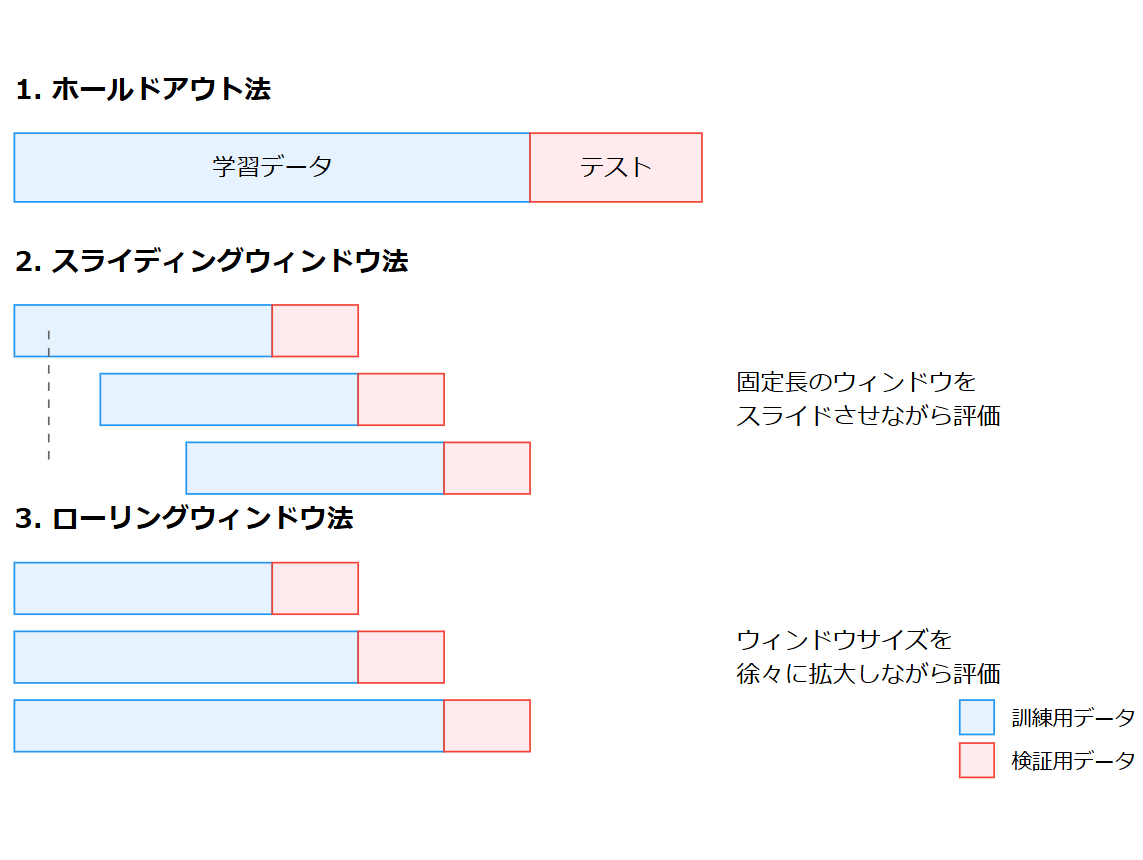
時系列データの予測モデルでは、一般的な回帰や分類タスクとは異なる点が多々あります。
例えば、将来のデータは現在手元にないため、データの分割や評価に注意を払わなければなりません。
例えば、ランダムにデータをシャッフルして分割する通常のCV(クロスバリデーション)は、時系列の順序を無視するため、予測タスクの実運用時に想定されるシナリオと乖離してしまう可能性があります。
このため、時系列に特化した方法でデータを分割・評価することが重要となります。
今回は、時系列データを正しく分割・評価するための「時系列ホールドアウト法」や「時系列クロスバリデーション」について、具体的なサンプルコードとともに紹介します。
データ準備
時系列データを使った予測タスクのデモでは、よく知られたサンプルデータセットを利用するのが理解を深めやすいです。
ここではpmdarimaライブラリに付属のload_airpassengers関数が提供するAirPassengersデータセットを用いて解説します。
まだ、このライブラリをインストールされていない方は、以下のコードでインストールできます。
pip install pmdarima
conda環境でインストールされたい方のコードは、以下です。
conda install -c conda-forge pmdarima
pmdarimaライブラリがすでにインストールされていることを前提に話しを進めます。
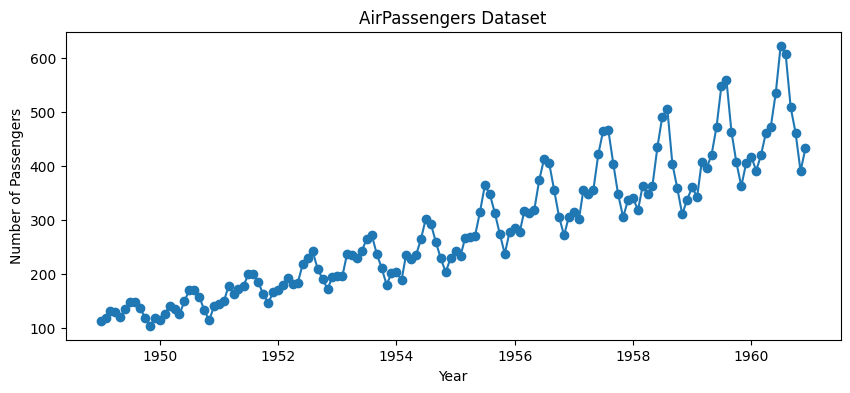
このデータは、時系列予測では定番の例として広く使われています。季節性がはっきりしており、ARIMAモデルやSARIMAモデルなどの季節成分を持つモデルを試すのに適しています。
- 対象期間: 1949年1月から1960年12月までの、月次データ
- 変数: 航空旅客数
- 特徴: 毎年の季節性(夏季に需要が高まる)や右肩上がりのトレンドを含む
実際にデータをロードし、可視化してみましょう。
以下、コードです。
from pmdarima.datasets import load_airpassengers
import pandas as pd
import matplotlib.pyplot as plt
# データ読み込み
y = load_airpassengers()
# 日付インデックス付きのDataFrameに変換(可視化しやすくするため)
start_date = pd.to_datetime("1949-01")
date_index = pd.date_range(start_date, periods=len(y), freq='MS')
df = pd.DataFrame({'value': y}, index=date_index)
# 簡単な可視化
plt.figure(figsize=(10,4))
plt.plot(df.index, df['value'], marker='o')
plt.title("AirPassengers Dataset")
plt.xlabel("Year")
plt.ylabel("Number of Passengers")
plt.show()
以下、実行結果です。
pmdarima.model_selectionの基本手法概観

pmdarimaライブラリのmodel_selectionモジュールでは、時系列データ向けに以下のようなデータ分割・評価の仕組みが用意されています。
train_test_split
- 過去データと未来データを時系列順に分割するホールドアウト法です。
- 学習やパラメータ調整に使わずに取り分けることをホールドアウトと言い、その取り分けたデータをホールドアウトデータもしくはテストデータと言います。
- 検証方法としては最もシンプルで、テストパターンが1パターンに限られます。
SlidingWindowForecastCV
- 「スライディングウィンドウ」方式で、固定長の学習期間を設定し、そこから直後のデータでテストを行うクロスバリデーション手法です。
- クロスバリデーション(Cross-Validation)とは、手元にあるデータを複数の「訓練用データ」と「検証用データ」に繰り返し分割し、それぞれでモデルを学習・評価することです。
- このCVは、ウィンドウを少しずつスライドすることで、複数の時点でのモデル性能を評価でき、最新の情報を重点的に扱いたいシナリオや短期予測に向いています。
RollingForecastCV
- 「ローリング(拡大)ウィンドウ」方式で、最初に設定した学習期間からテストを行い、次のステップではテスト区間を学習データに組み入れていくクロスバリデーション手法です。
SlidingWindowForecastCVが「一定のウィンドウサイズだけ過去のデータを使う」方法で古いデータはどんどん捨てながら評価するCVであるのに対し、RollingForecastCVは「ウィンドウを拡大」し過去データを捨てずに徐々に蓄積しながら評価する点が異なります。- 長期的な傾向を捉えながら、新しいデータを追加していくため、時系列の変化を徐々に取り込みつつ複数回の評価を行うケースに向いています。
これらの手法はいずれも、単にランダムにデータを分割するのではなく、時系列を考慮した分割が行われるため、将来データ予測をシミュレートしやすいという利点があります。
時系列ホールドアウト法

時系列ホールドアウト法とは?
ホールドアウト法とは、過去のデータを学習(トレーニング)用に、未来のデータをテスト(検証)用に分割(ホールドアウト)する、時系列評価において最もシンプルな手法です。
たとえば「最初の数年分を学習データとして使い、最後の数ヶ月分をテストデータとする」というように、歴史的に古いデータから新しいデータの順序を崩さずに分ける点が特徴です。
メリット
- 実装が非常に簡単で、直感的に理解しやすい。
- 時系列の順番を保ったまま分割し、将来のデータを“未知データ”として扱える。
デメリット
- 学習データとテストデータが1パターンだけのため、評価指標が偏る可能性がある。
- 分割位置(どの時点までを学習にして、どの時点からをテストにするか)によって結果が変わる。
実装例:train_test_split
pmdarimaのtrain_test_splitを使うと、簡単に時系列データをホールドアウト分割できます。
以下、コードです。直近12カ月をテスト用にする例です。
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error
from pmdarima.model_selection import train_test_split
from pmdarima import AutoARIMA
# データを学習データとテストデータに分割
train, test = train_test_split(
df['value'].values, # 分割対象の時系列データ
test_size=12, # 12ヶ月分をテスト
)
# AutoARIMAなどのモデルを学習
model = AutoARIMA(seasonal=True, m=12)
model.fit(train)
# テスト部分に対して予測
forecast = model.predict(n_periods=12)
# 評価指標(MAEとMAPE)を計算
mae = mean_absolute_error(test, forecast)
mape = mean_absolute_percentage_error(test, forecast)
print("MAE:", mae)
print("MAPE:", mape)
以下、実行結果です。
MAE: 14.89820842162878 MAPE: 0.030975615456563868
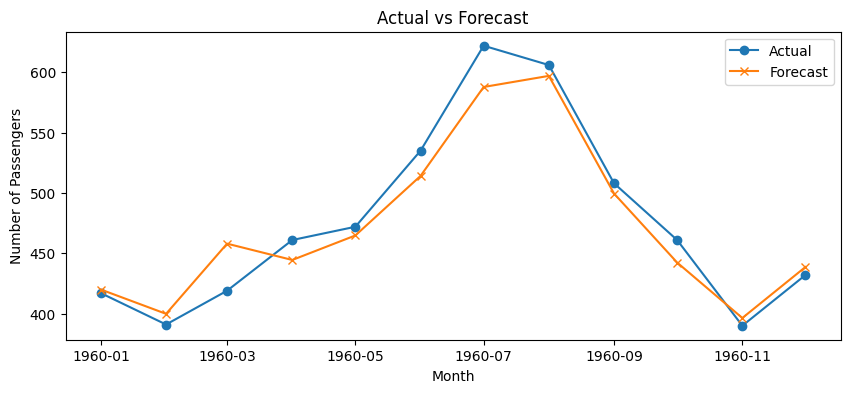
テストデータに対する予測値(Forecast)と実測値(Actual)の乖離を、視覚的に確認します。
以下、コードです。
plt.figure(figsize=(10, 4))
plt.plot(date_index[-12:], test, label='Actual', marker='o')
plt.plot(date_index[-12:], forecast, label='Forecast', marker='x')
plt.title("Actual vs Forecast")
plt.xlabel("Month")
plt.ylabel("Number of Passengers")
plt.legend()
plt.show()
以下、実行結果です。
ホールドアウト法は最もシンプルな時系列評価手法で、実際の運用に近い形で“将来を予測”するシナリオを簡単に実現できます。
ただし、評価パターンが1回分しか得られないため、モデルの調整や複数モデル比較にはやや不十分な面があります。必要に応じて、複数時点で繰り返し学習・評価するクロスバリデーション手法と組み合わせると効果的です。
通常のテーブルデータとの違い
一般的な回帰・分類タスクでのホールドアウト法は、「学習データ」と「テストデータ」へランダムに分割することが多いです。
この場合、データの順序はあまり問題にならず、単純にシャッフルしてデータを混ぜたうえで一定割合を分けることがあります。
一方、時系列データのホールドアウト法では、ランダムに分割することは通常行いません。
なぜなら、未来のデータを過去の学習に混ぜ込んでしまうと、本来の予測シナリオと乖離してしまうからです。
時系列データでは「時間の順序」を厳密に守り、学習データは全てテストデータよりも過去のタイムスタンプを持つものに限定する必要があります。
通常のテーブルデータ
- シャッフル分割可能(時系列的な依存関係が薄い)
- X-yの組を無作為に分割し、モデル構築後にテスト
- 時間的連続性を考慮しない
時系列データ
- 時系列の順序を保った分割が必須
- 学習データは過去、テストデータは未来
- トレンドや季節性など、時間依存の要素を考慮
そのため、時系列ホールドアウト法は「直近数ヶ月(または四半期・年など)をテスト区間にする」という形を取ります。最新のデータをテストに使うことで、モデルが将来的にどの程度の性能を発揮するかを模擬できる点が魅力です。
スライディングウィンドウ法
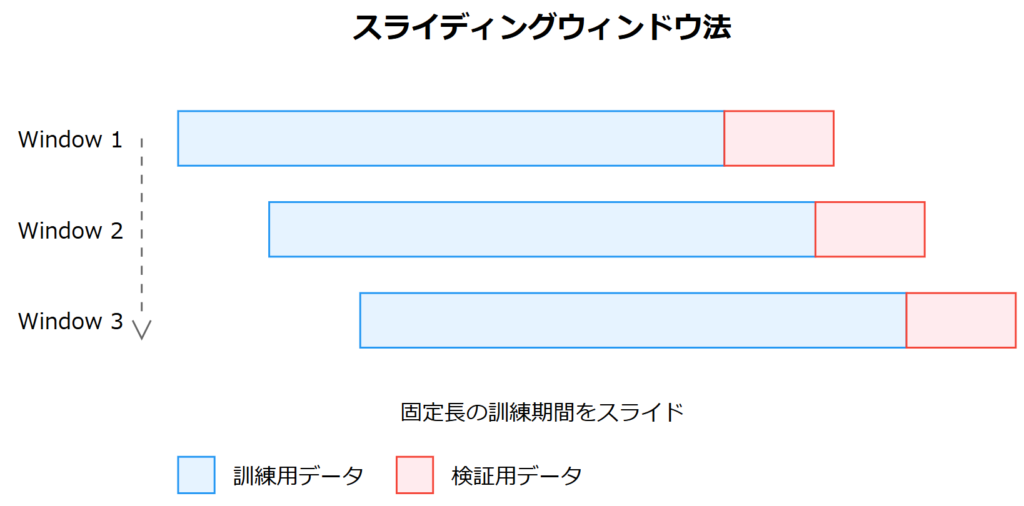
スライディングウィンドウ法とは?
スライディングウィンドウ法は、時系列データを一定の長さ(ウィンドウサイズ)に区切り、そのウィンドウをスライドさせながら複数回の学習・評価を行う時系列のクロスバリデーション手法です。
例えば、ウィンドウサイズを36ヶ月に設定すると……
- 最初の36ヶ月を学習データとし、直後の月をテスト
- 1ヶ月先にスライドして、次の36ヶ月を再度学習データとして使い、その直後の月をテスト
- 以下、時系列の終端付近まで繰り返す
このようにして、各“ウィンドウ”でモデルを学習し、直後のデータを予測することを繰り返すため、複数の評価結果が得られます。これらを平均するなどして、より安定した汎化性能の推定が可能になります。
実装例:SlidingWindowForecastCV
pmdarimaのSlidingWindowForecastCVを利用すると、簡単にスライディングウィンドウ法による時系列クロスバリデーションを実施できます。
SlidingWindowForecastCVでは、以下の3つの引数を設定する必要があります。
- ウィンドウサイズ (window_size): 学習に使用する期間の長さ(例:36や60など、月次データなら数ヶ月単位で設定)
- 先読み期間 (h): 何ステップ先を予測するか(例:1ヶ月先ならh=1、3ヶ月先ならh=3)
- ステップ幅 (step): スライドする間隔(例:1ヶ月ずつスライド)
では、次のように設定してSlidingWindowForecastCVを用い時系列クロスバリデーションを実施します。
window_size = 36: 過去36ヶ月分を学習h = 12: 12ヶ月先を予測step = 3: 3ヶ月ずつスライド
以下、コードです。直近12カ月をテスト用にする例です。
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error
from pmdarima.model_selection import SlidingWindowForecastCV
from pmdarima import AutoARIMA
# SlidingWindowForecastCVクラスのインスタンスを作成
cv = SlidingWindowForecastCV(
window_size=36, # 過去36か月分のデータを使用してモデルを学習
h=12, # 先の12か月のデータを予測対象とする
step=3 # スライディングウィンドウを3か月ずつ移動
)
# データセットを取得(データ配列)
y_values = df['value'].values
# 平均絶対誤差(MAE)と平均絶対百分率誤差(MAPE)を保存するリスト
mae_list = []
mape_list = []
# クロスバリデーションを実行
for train_idx, test_idx in cv.split(y_values):
# トレーニングデータとテストデータに分割
train_data = y_values[train_idx] # 訓練用データ
test_data = y_values[test_idx] # 検証用データ
# AutoARIMAモデルをインスタンス化して学習
model = AutoARIMA(seasonal=True, m=12) # 季節性の周期を12として設定
model.fit(train_data) # モデルを訓練用データで学習
# 検証用データの期間を予測
forecast = model.predict(n_periods=len(test_data))
# 検証用データと予測値の間でMAEとMAPEを計算
mae = mean_absolute_error(test_data, forecast)
mape = mean_absolute_percentage_error(test_data, forecast)
mae_list.append(mae) # 計算したMAEをリストに追加
mape_list.append(mape) # 計算したMAPEをリストに追加
# 全クロスバリデーションの平均MAEとMAPEを計算して表示
print("平均MAE:", np.mean(mae_list))
print("平均MAPE:", np.mean(mape_list))
以下、実行結果です。
平均MAE: 16.60160880984222 平均MAPE: 0.05204884049326798
splitメソッドの挙動
cv.split(y_values)は、SlidingWindowForecastCVクラスのメソッドであり、スライディングウィンドウ方式に基づいて時系列データを訓練用データと検証用データに分割するために使用されます。
このメソッドは、指定されたウィンドウサイズ、予測期間(h)、およびステップサイズに従って、複数の訓練用データと検証用データのインデックスを生成します。
具体的には、以下のような動作をします。
1. ウィンドウの設定:
window_sizeで指定された期間(例: 過去36か月)をトレーニングデータとして使用します。hで指定された期間(例: 12か月)をテストデータとして使用します。stepで指定された間隔(例: 3か月)でウィンドウをスライドさせます。
2. インデックスの生成:
cv.split(y_values)を呼び出すと、トレーニングデータとテストデータのインデックス(train_idxとtest_idx)が生成されます。- 例えば、最初のスライディングウィンドウでは、
train_idxはデータの最初の36か月分のインデックスを含み、test_idxはその直後の12か月分のインデックスを含みます。 - 次に、ウィンドウが
step(例: 3か月)だけスライドし、新しいtrain_idxとtest_idxが生成されます。このプロセスがデータの終端に到達するまで繰り返されます。
3. 複数回の分割:
cv.split(y_values)は、スライディングウィンドウの各ステップごとにtrain_idxとtest_idxのペアを返します。- これにより、時系列データを複数のトレーニングセットとテストセットに分割することができ、モデルの性能を異なる期間で評価することが可能になります。
このようにして、スライディングウィンドウ方式は、時系列データの特性を考慮しながら、モデルの汎化性能を評価するためのクロスバリデーションを実現します。
では、cv.split(y_values)の中を見てみましょう。
以下、コードです。
cv_generator = cv.split(y_values)
# 全ての訓練用データと検証用データのインデックスを取得して表示
for i, (train_idx, test_idx) in enumerate(cv_generator):
print(f"{i+1}つ目の訓練用データと検証用データのインデックスを取得")
print("Train indices:", train_idx)
print("Test indices:", test_idx)
以下、実行結果です。
1つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35] Test indices: [36 37 38 39 40 41 42 43 44 45 46 47] 2つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38] Test indices: [39 40 41 42 43 44 45 46 47 48 49 50] 3つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41] Test indices: [42 43 44 45 46 47 48 49 50 51 52 53] ・・・略・・・ 32つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128] Test indices: [129 130 131 132 133 134 135 136 137 138 139 140] 33つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131] Test indices: [132 133 134 135 136 137 138 139 140 141 142 143]
このように、訓練用データのインデックスtrain_idxと検証用データのインデックスtest_idxのペアが生成されることが分かります。
通常のテーブルデータのCVとの違い
一般のテーブルデータ(回帰や分類タスクなど)では、ランダム分割によるクロスバリデーションが主流です。
これらの方法では、データをシャッフルして分割し、学習・評価を繰り返すことが多いです。時系列の依存関係がない、あるいは極めて薄い場合には、順序を気にせずに性能評価ができます。
しかし、時系列データの場合は明確な時間的順序が存在し、未来のデータを過去の学習に混ぜ込んでしまうと本来の予測場面を模擬できなくなります。
したがって、時間軸を保ったまま複数回の学習・評価を行う必要があり、スライディングウィンドウやローリングウィンドウといった方法が採用されます。
時系列でのクロスバリデーションは、将来の予測性能をより現実的に捉えるための工夫と考えてください。
スライディングウィンドウ法は、ホールドアウト法より多面的な評価が可能でありながら、最新の情報を重視した学習ができるため、短期的な予測精度を意識するシナリオに適しています。
一方で、長期的なトレンドや季節性の考慮が難しくなる場合があるため、必要に応じてローリングウィンドウ法や別のクロスバリデーション手法との比較・検討が必要です。
ローリングウィンドウ法

ローリングウィンドウ法とは?
ローリングウィンドウ法は、時系列データの学習区間を「少しずつ拡大」させながら、複数回の学習・予測・評価を行うクロスバリデーション手法です。
初期の一定期間を訓練用データとし、その直後の期間を検証用データに用いる → 次のステップでは検証用データの区間を訓練用データに加え、さらに直後を検証する…… という流れを繰り返します。
例えば、初期訓練用データ期間 initial=36、検証用データ期間 h=1、ローリング期間 step=1の場合には……
- 最初の36ヶ月(初期ウィンドウ)でモデルを学習 → 直後1ヶ月をテスト
- 次のステップでは最初の37ヶ月を学習(前のテスト1ヶ月を含む)→ その直後1ヶ月をテスト
- これを時系列終端まで繰り返す
これにより、過去から積み上げたデータを使いながら、最新の情報も少しずつ学習に取り入れることができます。
このようなローリング(徐々に訓練用データ期間を拡大)をしていくことで、古いデータを捨てずに参照し続けられる点が、スライディングウィンドウ法との大きな違いです。
実装例:RollingForecastCV
pmdarimaのRollingForecastCVを利用すると、簡単にローリングウィンドウ法による時系列クロスバリデーションを実施できます。
RollingForecastCVでは、以下の3つの引数を設定する必要があります。
- initial: 最初に訓練に使う期間の長さ(例:36ヶ月)
- h: 何ステップ先を予測するか(例:1ヶ月先ならh=1、3ヶ月先ならh=3)
- step: 検証後にどの程度ローリング(拡大)するか
initialで定めた学習区間をベースに、テスト終了後はテスト部分を含めて学習データに加え、さらに次のテストに進みます。
では、次のように設定してRollingForecastCVを用い時系列クロスバリデーションを実施します。
initial = 36: 最初36ヶ月を訓練h = 12: 12ヶ月先を予測step = 3: 3ヶ月ずつスライド
以下、コードです。直近12カ月をテスト用にする例です。
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error
from pmdarima.model_selection import RollingForecastCV
from pmdarima import AutoARIMA
# RollingForecastCVクラスのインスタンスを作成
cv = RollingForecastCV(
initial=36, # 初期の訓練用データ期間を36ヶ月に設定
h=12, # 先の12か月のデータを予測対象とする
step=3 # ローリングするステップ数を3ヶ月ずつとする
)
# データセットを取得(データ配列)
y_values = df['value'].values
# 平均絶対誤差(MAE)と平均絶対百分率誤差(MAPE)を保存するリスト
mae_list = []
mape_list = []
# クロスバリデーションでスプリットしたデータでループ処理
for train_idx, test_idx in cv.split(y_values):
# トレーニングデータとテストデータに分割
train_data = y_values[train_idx] # 訓練用データ
test_data = y_values[test_idx] # 検証用データ
# AutoARIMAモデルをインスタンス化して学習
model = AutoARIMA(seasonal=True, m=12) # 季節性の周期を12として設定
model.fit(train_data) # モデルを訓練用データで学習
# 検証用データの期間を予測
forecast = model.predict(n_periods=len(test_data))
# 検証用データと予測値の間でMAEとMAPEを計算
mae = mean_absolute_error(test_data, forecast)
mape = mean_absolute_percentage_error(test_data, forecast)
mae_list.append(mae) # 計算したMAEをリストに追加
mape_list.append(mape) # 計算したMAPEをリストに追加
# 全クロスバリデーションの平均MAEとMAPEを計算して表示
print("平均MAE:", np.mean(mae_list))
print("平均MAPE:", np.mean(mape_list))
以下、実行結果です。
平均MAE: 16.978673379788454 平均MAPE: 0.0540262202701875
cv.split(y_values)は、RollingForecastCVクラスのメソッドであり、ローリングウィンドウ方式に基づいて時系列データを訓練用データと検証用データに分割するために使用されます。
このメソッドは、初期の訓練用データ期間、予測期間(h)、およびステップサイズに従って、複数の訓練用データと検証用データのインデックスを生成します。
cv.split(y_values)の中を見てみましょう。
以下、コードです。
cv_generator = cv.split(y_values)
# 全ての訓練用データと検証用データのインデックスを取得して表示
for i, (train_idx, test_idx) in enumerate(cv_generator):
print(f"{i+1}つ目の訓練用データと検証用データのインデックスを取得")
print("Train indices:", train_idx)
print("Test indices:", test_idx)
以下、実行結果です。
1つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35] Test indices: [36 37 38 39 40 41 42 43 44 45 46 47] 2つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38] Test indices: [39 40 41 42 43 44 45 46 47 48 49 50] 3つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41] Test indices: [42 43 44 45 46 47 48 49 50 51 52 53] ・・・略・・・ 32つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128] Test indices: [129 130 131 132 133 134 135 136 137 138 139 140] 33つ目の訓練用データと検証用データのインデックスを取得 Train indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131] Test indices: [132 133 134 135 136 137 138 139 140 141 142 143]
スライディングウィンドウ法(SlidingWindowForecastCV)との違い
| 項目 | スライディングウィンドウ | ローリングウィンドウ |
|---|---|---|
| 学習範囲の更新方法 | 過去の一定期間のみを使い、ウィンドウをスライドさせながら古いデータを切り捨てる。 | 過去のデータを捨てず、テストで使った区間も学習データに取り込みながら拡張していく。 |
| 向いているシナリオ | 最新動向を重視する短期予測向き。古いデータが過度に古くなっている場合、切り捨てることで現行トレンドに集中できる。 | 長期トレンドや豊富な履歴情報を活かしたい場合に有効。より多くのデータを使い続けるため、安定した学習が期待できる。 |
| トレードオフ | 長期的傾向を捉えにくい場合があるが、急激な変化には比較的素早く対応できる。 | 長期的傾向を活かしやすい一方、急激な変化には追随が遅れがち。 |
ローリングウィンドウ法は、時系列に合わせて学習範囲を拡大しながら繰り返しモデル評価を行うアプローチです。
評価結果を安定化できるうえ、長期的な傾向も考慮しやすい利点があります。
ただし、急激なトレンドシフトへの対応力はスライディングウィンドウに劣る場合があるため、時系列の特性や目的に応じて使い分けることが重要です。
ホールドアウト法×クロスバリデーション法
なぜ組み合わせが必要?
時系列モデルの開発において、単にホールドアウト法で最終的な性能を見るだけでは、モデル選択やハイパーパラメータ調整の際に過剰適合のリスクを把握しきれないことがあります。
一方で、クロスバリデーション(CV)だけを頼りにすると、最終的な評価を行う純粋な未知データがなくなってしまう可能性があるため、どこまで本当に汎化能力が高いかを判断しづらくなります。
これは、時系列データであっても通常のテーブルデータと同様です。
通常の機械学習でも学習データとテストデータを分けるのに加え、その学習データの中でCVを行い、モデルの選択やパラメータチューニングを進める方法が一般的です。
ただし、時系列の場合は分割を時系列の順序に従って行う必要がある点に注意します。
こうした背景から、最終的な評価に使うホールドアウトデータ(将来を模擬したデータ)をあらかじめ取り分けテストデータとし、それ以外のデータでCVを回してモデルを選定やチューニングなどをする方法が有効です。
全体の流れ
STEP 1 : ホールドアウトデータ(最終テスト)を事前に確保
- 時系列の最後の数ヶ月や数四半期など、将来を模擬した区間をテストデータとして取り分けておく。
- 残りの区間を“学習+検証”用とする。
ここで取り分けたホールドアウトデータは、後に最終的な評価だけに使うデータなので、途中のチューニング等には一切利用しません。
これにより、モデル選定で得られたベストなモデルの“真の性能”を厳密に測ることができます。
STEP 2 : 学習データ(ホールドアウトデータ以外のデータ)でCVを実行
- このデータを使って、SlidingWindowやRollingForecastなどでモデルの種類やハイパーパラメータのチューニングを行い、ベストなモデル(もしくは最適なパラメータ設定)を見つけます。
- 例えば、季節性の周期mを色々変えて試したり、ARIMAのp, d, qパラメータを探索したりといった作業を行います。
STEP 3 : CVで決まったモデルを、学習データ全体で再学習
- STEP 2 で使った区間すべて(ホールドアウトデータを除く)を学習に使い、見つかったベストなパラメータで最終モデルを構築します。
STEP 4 : 最後にホールドアウトデータで最終評価
- ここまで一切触れていないホールドアウトデータを“将来を模擬した未知データ”として用い、予測性能を算出します。
- これにより、実際の運用で遭遇する予測精度に近い指標が得られます。
実装例
以下、コードです。
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error
from pmdarima.model_selection import train_test_split, SlidingWindowForecastCV
from pmdarima import AutoARIMA
#
# 0. データ準備
#
# データセットを取得(データ配列)
y_values = df['value'].values
#
# 1. ホールドアウト確保(最後の12ヶ月分をテストに)
#
# 時系列データをホールドアウト方式で分割する(最後の12ヶ月分をテストデータに)
train_all, test_final = train_test_split(
y_values,
test_size=12
)
#
# 2. 学習データ(ホールドアウトデータ以外)でCVを実行
#
# SlidingWindowForecastCVを用いてクロスバリデーションを設定
cv = SlidingWindowForecastCV(
window_size=36, # 訓練データのウィンドウサイズを36ヶ月に設定
h=12, # 予測期間を12ヶ月に設定
step=3 # スライディングステップを3に設定
)
# ベストスコア(最小平均絶対誤差)を無限大で初期化
best_score = float('inf')
# ベストの季節性周波数を保持する変数
best_m = None
# 複数の季節性周波数(12, 6, 3)を試行
for seasonal_m in [12, 6, 3]:
# 平均絶対誤差を格納するリスト
mae_list = []
# クロスバリデーションで学習データをスプリット
for train_idx, test_idx in cv.split(train_all):
train_data = train_all[train_idx] # 訓練データ
test_data = train_all[test_idx] # 検証データ
# AutoARIMAモデルを適用(指定した季節性周波数)
model = AutoARIMA(seasonal=True, m=seasonal_m)
model.fit(train_data) # モデルを訓練用データで学習
# 検証データサイズ分の予測を生成
forecast = model.predict(n_periods=len(test_data))
# 検証データと予測値の間で平均絶対誤差を計算
mae = mean_absolute_error(test_data, forecast)
mae_list.append(mae) # リストに追加
# すべてのスプリットでの平均絶対誤差を計算
avg_mae = np.mean(mae_list)
print(f"m={seasonal_m}, CV MAE={avg_mae}")
# ベストスコアを更新
if avg_mae < best_score:
best_score = avg_mae
best_m = seasonal_m
#
# 3. CVで決まったモデルを、学習データ全体(train_all)で再学習
#
# CVで得られた最良の季節性モデルを使用して学習
final_model = AutoARIMA(
seasonal=True,
m=best_m,
)
final_model.fit(train_all)
#
# 4. ホールドアウトデータで最終評価
#
# ホールドアウトデータ(test_final)を用いて予測
final_forecast = final_model.predict(n_periods=len(test_final))
# ホールドアウトデータ(test_final)の評価指標を計算
final_mae = mean_absolute_error(test_final, final_forecast) # MAEを計算
final_mape = mean_absolute_percentage_error(test_final, final_forecast) # MAPEを計算
# 結果を出力
print(f"Best m: {best_m}")
print(f"Final MAE: {final_mae}")
print(f"Final MAPE: {final_mape}")
以下、実行結果です。
m=12, CV MAE=16.00943650325559 m=6, CV MAE=41.71146873441522 m=3, CV MAE=40.69962099422005 Best m: 12 Final MAE: 14.89820842162878 Final MAPE: 0.030975615456563868
テストデータに対する予測値(Forecast)と実測値(Actual)の乖離を、視覚的に確認します。
以下、コードです。
plt.figure(figsize=(10, 4))
plt.plot(date_index[-12:], test_final, label='Actual', marker='o')
plt.plot(date_index[-12:], final_forecast, label='Forecast', marker='x')
plt.title("Actual vs Forecast")
plt.xlabel("Month")
plt.ylabel("Number of Passengers")
plt.legend()
plt.show()
以下、実行結果です。
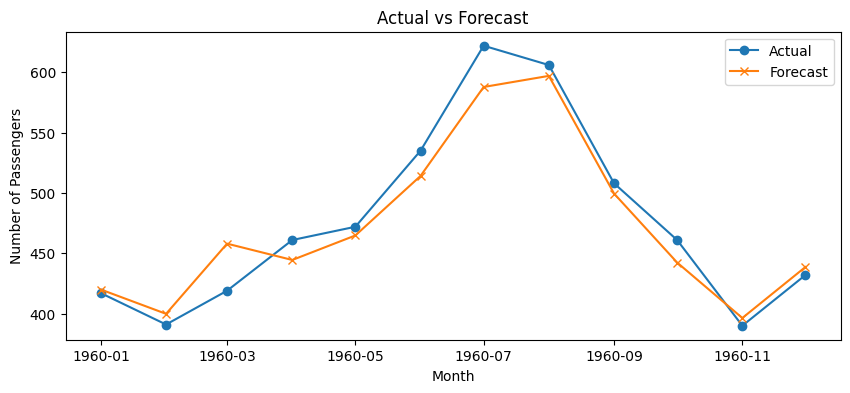
ホールドアウト法とクロスバリデーションを組み合わせることで、モデルの開発・チューニング・最終評価の各ステップを切り分けてより信頼性の高い時系列予測モデルを構築できます。
特に、最終評価用のデータを別途確保しながらCVを回す手法は、汎化性能をしっかりと測るうえで非常に有用です。
実務環境での運用を意識する場合にも、最新のテストデータを適切に確保しておくことが、正しいモデル評価の鍵となります。
各手法・組み合わせのまとめ
これまで、時系列データを扱う際の評価・検証手法として……
- ホールドアウト法
- スライディングウィンドウ法(SlidingWindowForecastCV)
- ローリングウィンドウ法(RollingForecastCV)
- ホールドアウトとクロスバリデーションの組み合わせ
……を順に解説してきました。
ここでは、それぞれの特徴と適用シーンを再度整理し、実務での活かし方を総括します。
時系列データ評価手法の比較と適用シーン
以下の表は、時系列データの評価手法について、それぞれの特徴、利点、欠点、主な用途を整理したものです。
| 手法 | 概要 | メリット | デメリット | 主な用途 |
|---|---|---|---|---|
| ホールドアウト法 | 時系列の最後の部分をテストデータとし、それ以前を学習に使用。ランダムなシャッフルは行わない。 | – 実装が簡単で直感的に理解しやすい。 – 時系列の分割を厳密に守れる。 |
– 評価が1パターンのみでモデル選択や調整には不向き。 – データ量が限られる場合、十分な学習・テストデータを確保しづらい。 |
最終評価や簡易的な精度チェック。CVと組み合わせる場合が多い。 |
| スライディングウィンドウ法 | 一定期間の過去データで学習→直後のデータで評価を繰り返す手法。 | – 最新データを重視できる。 – 複数回の評価でモデルの安定度を測れる。 |
– 長期的傾向を捉えにくい。 – ウィンドウサイズなどの設定次第で結果が大きく変わる。 |
短期予測を重視するケース。需要予測や急変するトレンドがある場合に有効。 |
| ローリングウィンドウ法 | 初期ウィンドウで学習→評価→評価区間を学習データに取り込みながら拡大→評価を繰り返す手法。 | – 過去データを活用し、長期的傾向を反映しやすい。 – 複数評価で安定した指標が得られる。 |
– データ量が増えると学習コストが上昇。 – 急激な変化への対応が遅れがち。 |
長期トレンドを重視するケース。過去の豊富なデータを活かしたい場合に適している。 |
| ホールドアウト+CV | 学習+検証でCVを行い、未使用のホールドアウトデータで最終評価を行う手法。 | – CVでモデル選択・調整ができ、最終評価は未使用データで行えるため客観性が高い。 – 過剰適合リスクを軽減できる。 |
– データ量が少ない場合、ホールドアウトを確保しづらい。 – 手順が増え計算コストも高くなる。 |
高い信頼性が求められる実務や研究。最終評価を厳密に行いたい場合に有効。 |
実務視点での選択基準
データ量
- 十分なデータがある場合、ホールドアウト+CVを組み合わせるのが最適。
- データが少ない場合は、シンプルなホールドアウト法や短いウィンドウでのCVを検討する。
目的
- 短期予測の精度を重視するならスライディングウィンドウ法を選択。
- 長期トレンドを重視するならローリングウィンドウ法が適している。
季節性やトレンドの強さ
- 季節性が強いデータの場合、ウィンドウサイズを調整(例:1年周期なら12の倍数)する必要がある。
計算リソースと時間
- 複数のモデルやパラメータを試す際、CVの計算コストが大きくなる。リソースや目的に応じて手法を選ぶ。
評価手法は目的やデータ特性によって使い分けるのが重要です。短期予測を重視するか、長期トレンドを重視するか、データ量やリソースを考慮しながら選択しましょう。
実務では以下の組み合わせが一般的です。
- モデル開発段階: クロスバリデーション(スライディング/ローリング)で多角的に検証
- 最終評価: ホールドアウトデータで性能を確認
これにより、過学習を防ぎながら、実際の運用に近い信頼性の高いモデルを構築できます。