
- 問題
- 答え
- 解説
次の Python コードの検定における帰無仮説は何ですか?
Python コード:
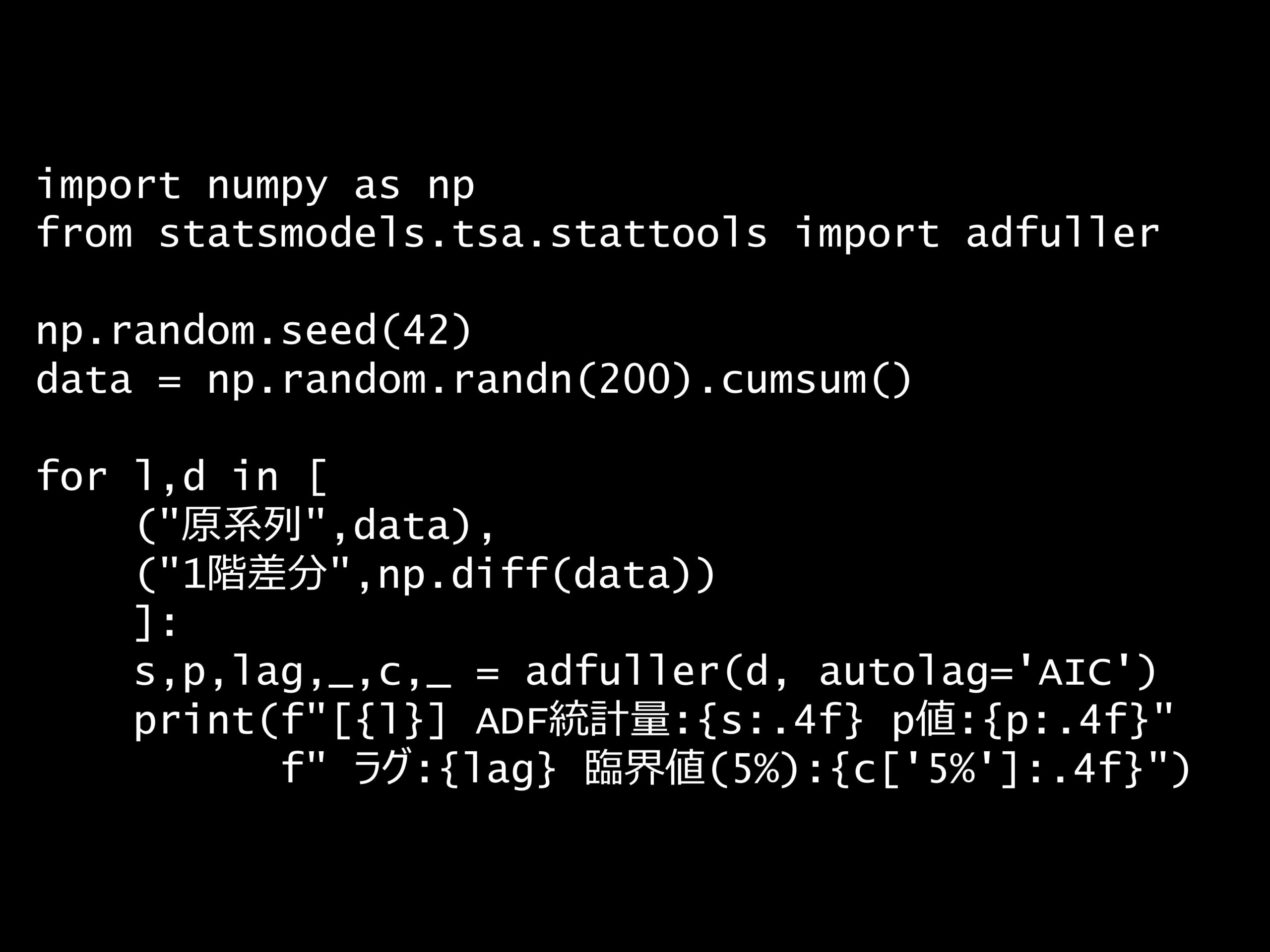
import numpy as np
from statsmodels.tsa.stattools import adfuller
np.random.seed(42)
data = np.random.randn(200).cumsum()
for l,d in [
("原系列",data),
("1階差分",np.diff(data))
]:
s,p,lag,_,c,_ = adfuller(d, autolag='AIC')
print(f"[{l}] ADF統計量:{s:.4f} p値:{p:.4f}"
f" ラグ:{lag} 臨界値(5%):{c['5%']:.4f}")
回答の選択肢:
(A) データは定常である
(B) データは非定常である(単位根を持つ)
(C) データのトレンドは線形である
(D) データの自己相関はゼロである