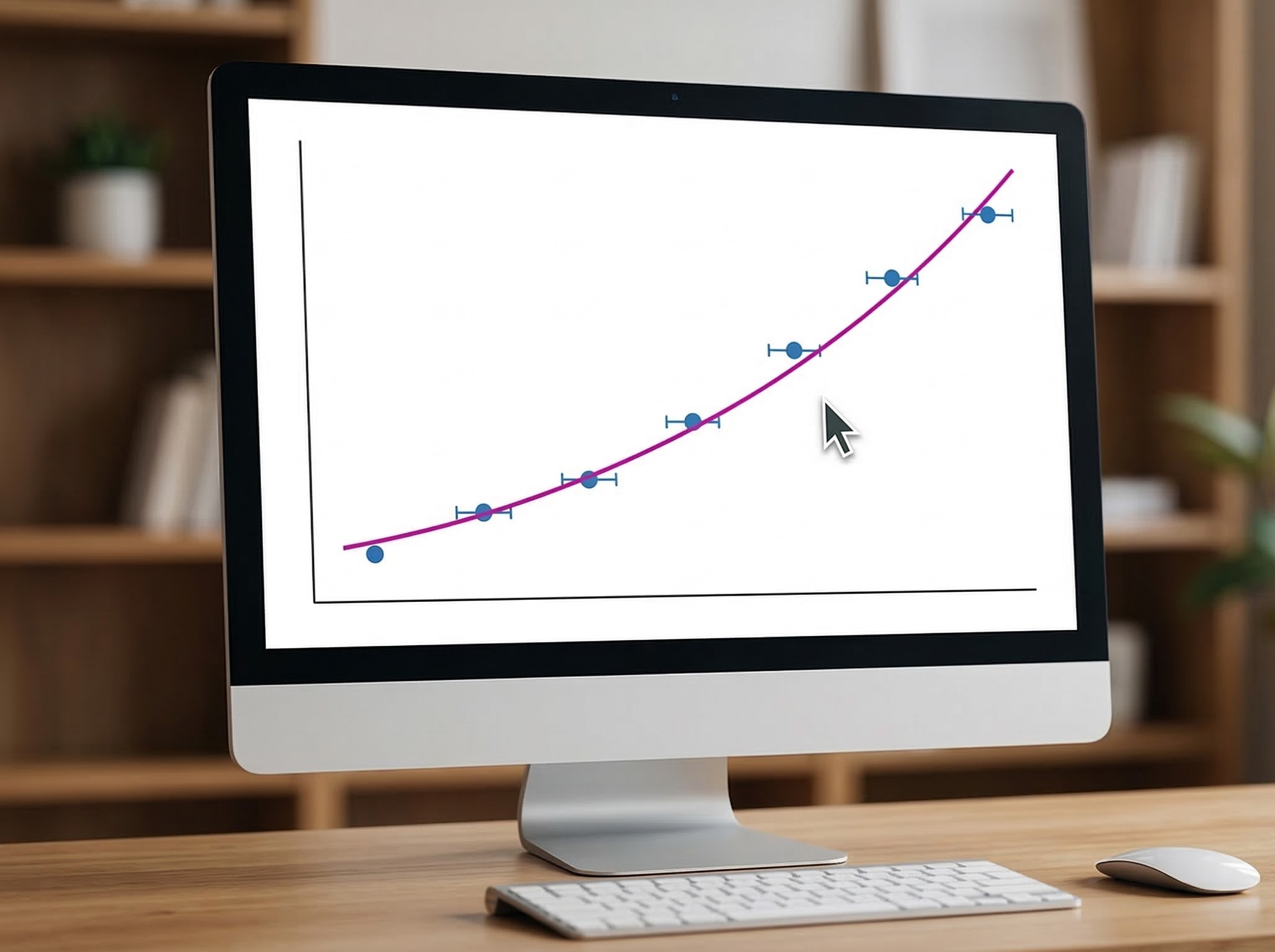
前回の記事では、minimize() を使って最適化問題を解く方法を紹介しました。 scipy.optimizeで最適化問題を解く入門 今回は、その応用とも言える 「カーブフィッティング(曲線あてはめ)」 を紹介します。...
データサイエンスや機械学習の世界では、「最適な値を見つける」 という作業が頻繁に登場します。 たとえば…… 広告費をどう配分すれば利益が最大になるか? 機械学習モデルの誤差を最小にするパラメータは何か? ……といった問題...
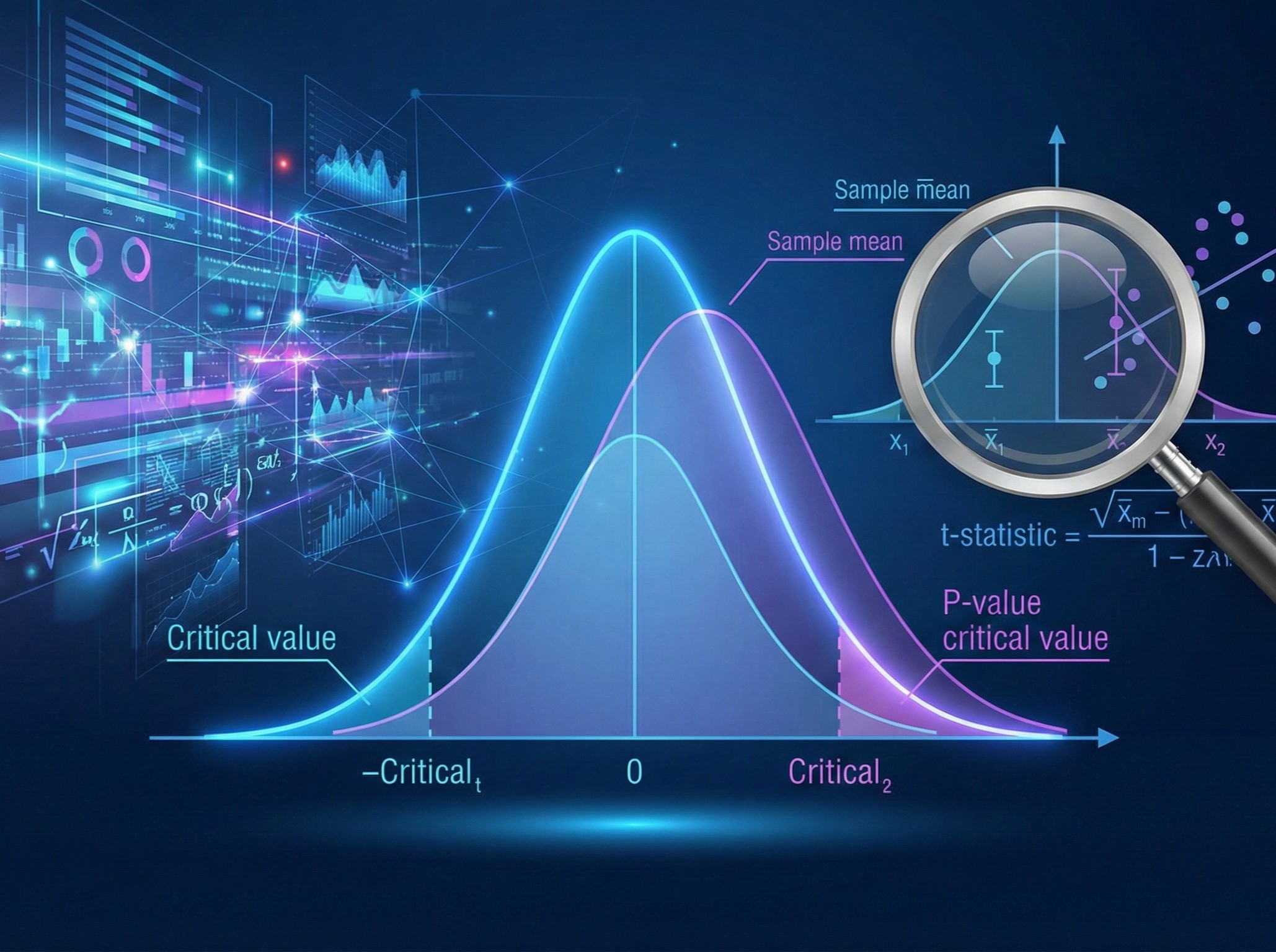
前回の記事では、t検定を使って「2つのグループの平均値に差があるか」を判定する方法を学びました。 t検定をPythonで実行してみよう(scipy.stats.ttest) しかし、データ分析の現場では、数値ではなくカテ...
データ分析をしていると、「AとBに本当に差があるのか?」という疑問に出会うことがよくあります。 たとえば…… 「新しい教材を使ったクラスと従来の教材を使ったクラスで、 テストの平均点に差はあるのか?」 「薬Aと薬Bで、...
データ分析の第一歩は、データの「全体像」をつかむことです。 平均値だけを見ても、データの本当の姿はわかりません。 データがどれくらいばらついているのか、偏りがあるのか、外れ値がありそうかなど、複数の指標をまとめて確認する...
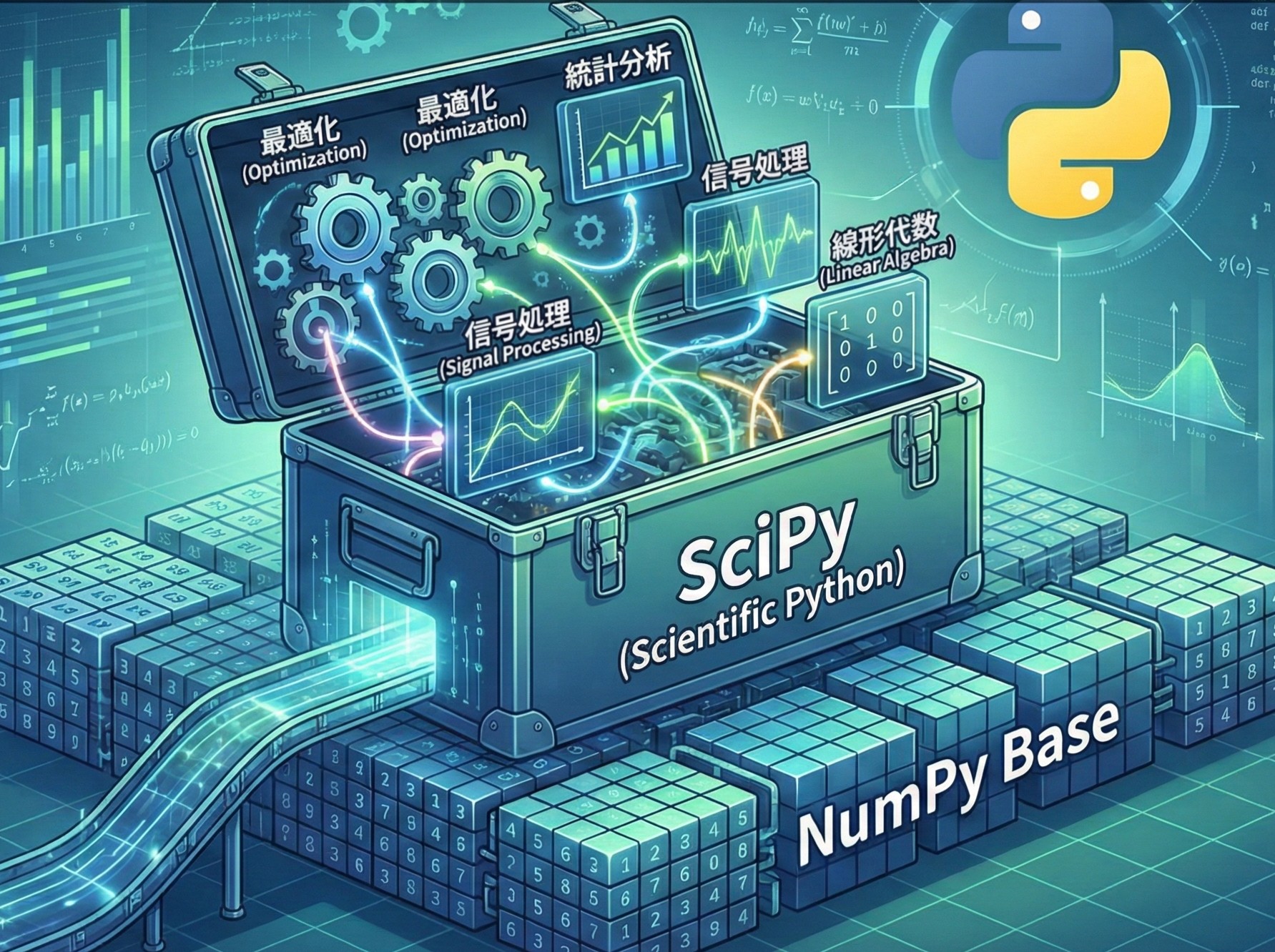
Pythonでデータ分析や科学技術計算を学び始めると、必ず出会うのが SciPy(サイパイ) というライブラリです。 「NumPyは聞いたことあるけど、SciPyって何が違うの?」と感じている方も多いのではないでしょうか...
ここまでの4回で、コレスポンデンス分析(CA)と多重コレスポンデンス分析(MCA)の仕組みと実行方法を学んできました。 しかし、マップを描いただけでは分析は完了していません。 たとえば、あなたが上司やクライアントにCA/...
第1〜3回で学んだコレスポンデンス分析(CA)は、「学部 × メニュー」のように2つのカテゴリ変数の関係を可視化する手法でした。 第1回 —クロス集計表の「その先」へ ― コレスポンデンス分析って何? 第2回 —期待と現...
第1回では prince ライブラリでコレスポンデンス分析のマップを描き、第2回では「期待度数からのズレ(残差)」がその出発点であることを学びました。 第1回 —クロス集計表の「その先」へ ― コレスポンデンス分析って何...
前回(第1回)では、prince ライブラリを使ってコレスポンデンス分析のマップをいきなり描いてみました。 Pythonで学ぶコレスポンデンス分析入門— 第1回 —クロス集計表の「その先」へ ― ...