

機械学習の分野では、データの不均衡がモデルの性能に大きな影響を及ぼす重要な問題となっています。
特に分類問題において、一部のクラスが他のクラスに比べて過剰に存在する場合、モデルは多数派クラスを過剰に予測する傾向に陥り、少数派クラスの重要なパターンを見落とす可能性があります。
今回は、機械学習におけるデータの不均衡問題と、その解決策としてのアンダーサンプリング技術に焦点を当てています。
データ不均衡への理解から始まり、アンダーサンプリングの基本的な概念、さまざまな手法の紹介、そして実世界のケーススタディを通して、この課題に対処するための効果的なアプローチを紹介します。
Contents
- 機械学習におけるデータの不均衡問題
- 課題の理解
- データ不均衡への対応の重要性
- アンダーサンプリングの概要
- アンダーサンプリングとは?
- アンダーサンプリングの役割
- アンダーサンプリング手法の種類
- 固定アンダーサンプリング技術
- ランダムアンダーサンプリング
- ニアミス法
- インスタンスハードネス閾値
- クリーニングアンダーサンプリング技術
- トメックリンク
- ワンサイドセレクション
- 編集された最近傍法
- 繰り返し編集された最近傍法
- AllKNN
- ネイバーフッドクリーニングルール
- 凝縮最近傍法
- 適切なアンダーサンプリング手法の選択
- データセットに対する手法の評価
- 効率と精度のバランス
- アンダーサンプリングの成功事例:ケーススタディ
- 事例1: 金融詐欺検出
- 事例2: 医療画像診断
- 事例3: ソーシャルメディアの感情分析
- 事例4: 顧客の離反対策(チャーン予測)
- 事例5: 機器の故障予知
- 今回のまとめ
機械学習におけるデータの不均衡問題

課題の理解
機械学習におけるデータ不均衡は、モデルのトレーニングにおいて一つのクラスが他のクラスに比べて過剰に存在する状況を指します。
この不均衡は、特に分類問題において重要な問題となります。
例えば、クレジットカードの不正取引を検出するモデルを考えてみましょう。

不正取引は正規の取引に比べて非常に稀であるため、この種のデータセットは高度に不均衡になりがちです。
このような状況では、モデルは多数派クラス(この場合は正規の取引)を過剰に予測する傾向があり、少数派クラス(不正取引)の検出が難しくなります。
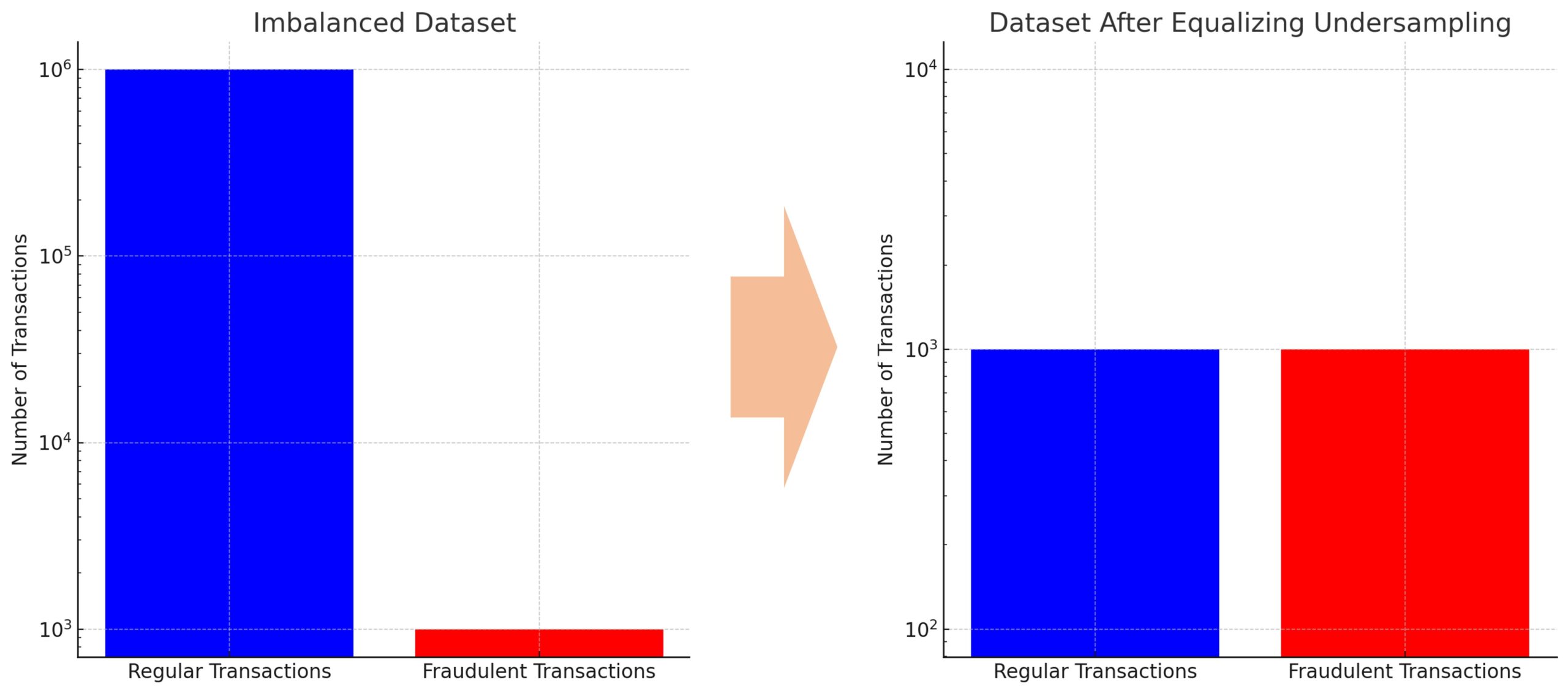
ここで、具体的な数字を用いてこの問題を詳しく説明します。
- 正規取引(多数派クラス):1,000,000件
- 不正取引(少数派クラス):1,000件
このデータセットでは、不正取引は正規取引に比べて非常に稀で、全取引のわずか0.1%を占めるに過ぎません。
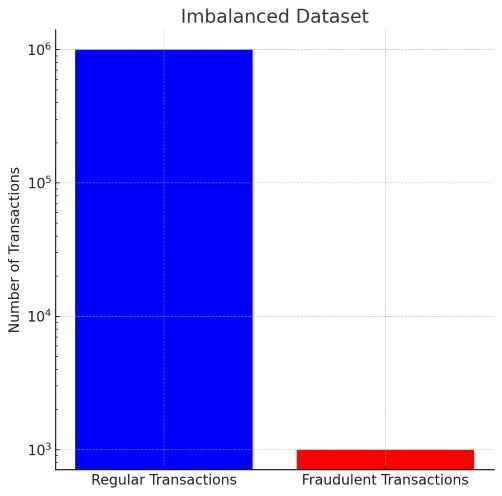
この大きな不均衡が存在すると、機械学習モデルは以下のような問題に直面します。
- 過剰な予測バイアス: モデルは、多数派クラスのパターンを学習する傾向が強くなります。結果として、ほとんどの取引を「正規」と予測し、実際には不正である取引を見逃す可能性が高くなります。
- 少数派クラスの無視: モデルは、不正取引のような少数派クラスの特徴を無視しがちになります。これは、モデルが主に正規取引のデータポイントから学習するため、不正取引の特徴を捉えるのが難しくなるためです。
- 誤分類のコスト: 不正取引を正規取引と誤って分類するコストは高く、金融損失や顧客の信頼喪失につながる可能性があります。
このような状況では、アンダーサンプリングのようなテクニックを用いてデータセットのバランスを取ることが有効です。
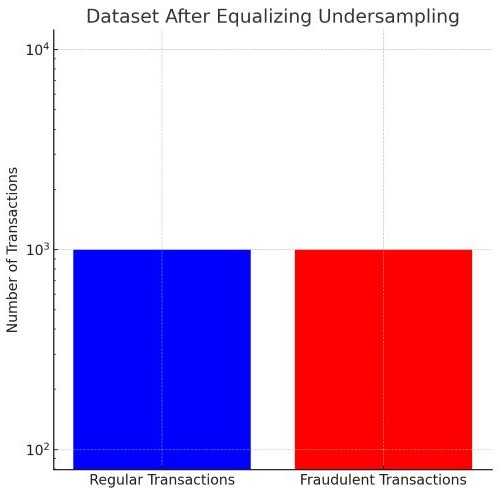
例えば、ランダムアンダーサンプリングを用いて正規取引のデータポイントを減らし、不正取引のデータとバランスを取ることで、モデルは両クラスの特徴をより公平に学習し、不正取引の検出精度を高めることができます。
データ不均衡への対応の重要性
データ不均衡への対応は、効果的な機械学習モデルを構築するために不可欠です。
不均衡データでトレーニングされたモデルは、少数派クラスを適切に識別できない可能性が高く、実際のアプリケーションでは不適切な結果をもたらすことがあります。
たとえモデルが高い精度を示しても、少数派クラスの検出性能が低ければ、そのモデルは実用的な価値が低いと考えられます。
したがって、データ不均衡問題を効果的に扱うことは、モデルの性能を現実世界で最適化する上で重要なステップです。
アンダーサンプリングの概要
アンダーサンプリングとは?
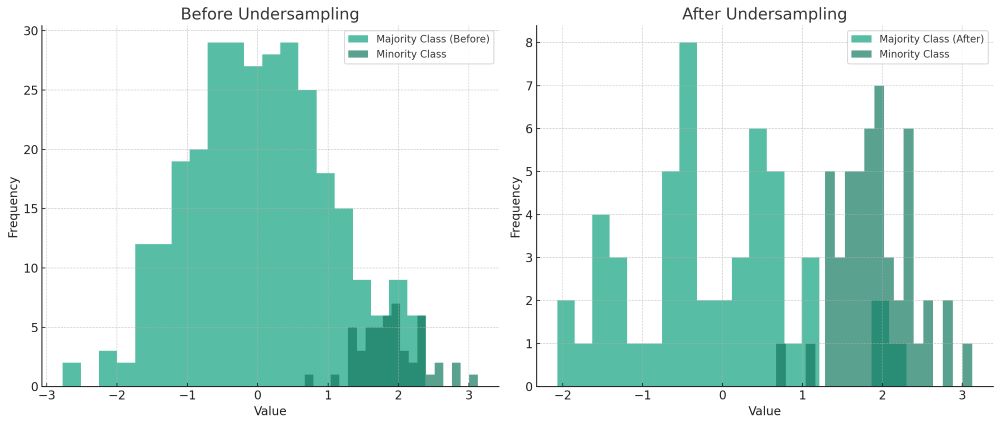
アンダーサンプリングは、データ不均衡問題に対処する方法の一つで、多数派クラスのデータポイントを削減することによって、データセット内のクラス間のバランスを改善する技術です。
具体的には、多数派クラスからデータポイントをランダムに削除するか、特定の基準に基づいて削除することにより、少数派クラスとの比率をより均等にします。
このプロセスは、モデルが少数派クラスのパターンを学習するのを助け、全体的な予測性能を向上させることを目指しています。
アンダーサンプリングの役割
アンダーサンプリングは、特にデータセットが非常に大きい場合や、計算資源が限られている状況で有効です。
この方法は、データセットのサイズを減少させるため、モデルのトレーニング時間を短縮し、計算コストを削減することができます。
また、データの均衡を取ることで、少数派クラスの重要性が強調され、モデルがこれらのクラスにより敏感になることが期待されます。
しかし、多数派クラスの重要な情報が失われる可能性もあるため、アンダーサンプリングを行う際は慎重な検討が必要です。
適切に実施されたアンダーサンプリングは、モデルの一般化能力を向上させ、実際の問題における予測の精度を高めることができます。
アンダーサンプリング手法の種類
アンダーサンプリング手法は大きく分けて「固定手法」と「クリーニング手法」の二つに分類されます。
固定手法 (Fixed Methods)は、多数派クラスからランダムにデータポイントを削除することにより、データセットのバランスを取ることに焦点を当てています。固定手法は実装が簡単であり、データ量を効果的に減少させることができますが、重要な情報が失われるリスクがあります。
クリーニング手法 (Cleaning Methods)は、データの品質やクラス間の境界に基づいて多数派クラスからサンプルを選択的に削除します。これらは、データセット内のノイズを減らすと同時に、クラス間の境界をより明確にすることにより、分類器の性能を向上させることができます。
固定アンダーサンプリング技術
以下は、主な固定アンダーサンプリング手法です。
| 手法 | 説明 |
|---|---|
| ランダムアンダーサンプリング | 多数派クラスのデータポイントをランダムに削除し、データセット内のクラス間のバランスを改善する方法。 |
| ニアミス法 | 多数派クラスのデータポイントの中で、少数派クラスのデータポイントに最も近いものを選択的に削除する方法。 |
| インスタンスハードネス閾値 | 分類器にとって「困難」とされる多数派クラスのデータポイントを特定し、それらをデータセットから除去する方法。 |
ランダムアンダーサンプリング
ランダムアンダーサンプリングは、データ不均衡を解決するためのシンプルな方法の一つです。この手法は、多数派クラスのデータポイントをランダムに削除し、データセット内のクラス間のバランスを改善することを目的としています。
ランダムアンダーサンプリングでは、多数派クラスからランダムにデータポイントを選択し、これらをデータセットから除外します。このプロセスにより、多数派クラスと少数派クラスのサンプル数が近似することで、データセットがより均衡化されます。この方法は、多数派クラスのデータポイントが多すぎても少なすぎてもない、適切な割合でサンプルを減らすことが重要です。
ランダムアンダーサンプリングは、計算資源が限られている場合や、データセットが非常に大きく処理が困難な場合に特に有効です。例えば、顧客の離反予測、クレジットカード詐欺検出、医療診断など、さまざまな分類問題に適用されます。しかし、ランダムにデータを削除するため、多数派クラスの重要な情報が失われる可能性があることに注意が必要です。
ニアミス法
ニアミス法は、アンダーサンプリングの一種で、特にテキストデータのような高次元データセットに適用されることが多い手法です。この方法は、多数派クラスのデータポイントの中で少数派クラスのデータポイントに最も近いものを選択的に削除します。
ニアミス法では、距離測定(例えばユークリッド距離やコサイン類似度)を用いて、多数派クラスの各データポイントと少数派クラスのデータポイントとの間の距離を計算します。そして、最も近い多数派クラスのデータポイントを特定し、これをデータセットから除去します。これにより、クラス間の境界がより明確になり、少数派クラスが分類器によって認識されやすくなります。
ニアミス法は、特にテキストデータのような高次元データセットで効果的です。これは、テキストデータの特徴空間が非常に大きいため、多数派クラスと少数派クラスの境界を明確にすることが重要であるからです。ニュースのカテゴリ分類や感情分析など、テキストデータを扱うアプリケーションで有効に機能します。
インスタンスハードネス閾値
インスタンスハードネス閾値は、アンダーサンプリングの一種であり、特にデータの品質を重視する場合に用いられます。この手法は、分類器にとって「困難」とみなされる多数派クラスのデータポイントを特定し、それらをデータセットから除去することによって、全体のデータ品質を向上させます。
このアプローチでは、まず分類器(例えば決定木やSVM)を用いて、各インスタンスの「ハードネス」、つまり分類が難しい度合いを評価します。次に、あらかじめ設定されたハードネスの閾値を基準にして、その閾値以上のハードネスを持つ多数派クラスのインスタンスをデータセットから削除します。これにより、より「簡単」かつ「識別可能」なインスタンスを保持し、分類器の性能を向上させることができます。
インスタンスハードネス閾値は、特にデータの品質が重要とされる分野で有効です。例えば、医療診断や金融詐欺検出など、誤分類のコストが非常に高いアプリケーションで役立ちます。この手法は、データセットからノイズや外れ値を除去し、より信頼性の高い予測モデルの構築を支援します。
クリーニングアンダーサンプリング技術
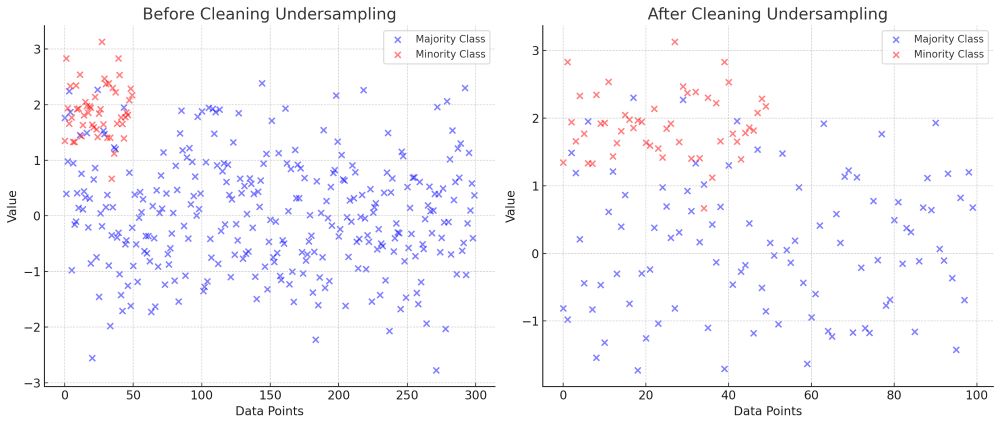
クリーニングアンダーサンプリング方法は、データセット内の重要な特徴を保持しつつ、クラス間のバランスを改善するためにより洗練されたアプローチを採用します。
以下は、主なクリーニングアンダーサンプリング手法です。
| 手法 | 説明 |
|---|---|
| トメックリンク | 異なるクラスに属するが近接しているデータポイントペアを削除して境界を明確化 |
| ワンサイドセレクション | トメックリンクとランダムアンダーサンプリングの組み合わせ |
| 編集された最近傍法 | 多数派クラスのデータポイントで最近傍が異なるクラスに属する場合に削除 |
| 繰り返し編集された最近傍法 | 編集された最近傍法を繰り返し適用してノイズや外れ値を除去 |
| AllKNN | 異なるk値に対して最近傍法を繰り返し適用 |
| ネイバーフッドクリーニングルール | 多数派クラスのデータポイントが少数派を圧迫する場合に削除 |
| 凝縮最近傍法 | 最も代表的なサブセットを選択してデータセットのサイズを減らす |
トメックリンク
トメックリンクは、クラス間の境界線をより明確にすることに焦点を当てたアンダーサンプリング手法です。この方法は、異なるクラスに属するが非常に近接しているデータポイントペア(トメックリンク)を特定し、これらをデータセットから除去することにより、クラス間の境界を精密化します。
トメックリンクの概念は、最近傍法に基づいています。具体的には、異なるクラスに属するデータポイントのペアが互いに最近傍である場合、これらをトメックリンクとみなします。これらのペアは、クラス間の境界領域に存在すると考えられ、それらを除去することで、クラス間の区別がより明確になり、分類器の性能が向上します。
トメックリンクは、特にクラス間の境界が不明瞭なデータセットに有効です。これには、顧客セグメンテーション、画像認識、テキスト分類など、様々な分野が含まれます。トメックリンクを適用することで、クラス間の重複を減らし、モデルがより精度高くクラスを区別するのに役立ちます。
ワンサイドセレクション
ワンサイドセレクションは、少数派クラス(マイノリティクラス)の表現を強化することを目的としたアンダーサンプリング手法です。この手法は、トメックリンクの概念とランダムアンダーサンプリングを組み合わせたもので、特に多数派クラスのデータポイントが少数派クラスに圧迫されている場合に有効です。
ワンサイドセレクションはまず、トメックリンクを用いて多数派クラスと少数派クラスの間の境界領域にある多数派クラスのデータポイントを削除します。その後、ランダムアンダーサンプリングを適用して、残りの多数派クラスのデータポイントをさらに減らします。このプロセスにより、少数派クラスのデータポイントがモデルによってより効果的に認識されるようになります。
ワンサイドセレクションは、クラスの境界が不明瞭なデータセットや、少数派クラスが重要な意味を持つアプリケーションで特に役立ちます。例えば、病気の診断、貴重なイベントの予測、異常検知などが該当します。この手法は、少数派クラスの特徴を損なうことなく、データセットの全体的なバランスを改善するのに有効です。
編集された最近傍法
編集された最近傍法は、データセットからノイズや外れ値を除去し、クラスの純度を高めることを目的としたアンダーサンプリング手法です。この方法は、多数派クラスのデータポイントを精選し、分類器の性能を向上させるために使用されます。
この手法では、各データポイントに対して最近傍のデータポイントを探し、その最近傍が異なるクラスに属している場合にそのデータポイントを削除します。このプロセスにより、クラス間の境界領域にある曖昧なデータポイントが除去され、より明確なクラス分離が可能になります。
編集された最近傍法は、特にノイズが多いデータセットや、クラスの分離が難しいデータセットに適しています。これには、顧客セグメンテーション、画像分類、テキスト分類などが含まれます。この手法により、分類器がより正確な予測を行い、一般化能力を向上させることが期待されます。
繰り返し編集された最近傍法
繰り返し編集された最近傍法は、データセットからノイズや外れ値を反復的に除去し、よりクリーンで識別可能なデータセットを作成することを目的としたアンダーサンプリング手法です。この方法は、特にデータの品質向上とモデルの一般化能力の強化に有効です。
この手法は、編集された最近傍法の概念を複数回適用します。最初のステップで、異なるクラスに属する最近傍を持つ多数派クラスのデータポイントを除去します。次に、更新されたデータセットに対して再び同じプロセスを適用し、これを数回繰り返します。各反復により、データセットはより洗練され、クラス間の区分が明確になります。
繰り返し編集された最近傍法は、複雑なデータセットや、多様な特徴を持つデータセットに特に適しています。医療診断、顧客行動予測、異常検出など、正確で信頼性の高い予測が必要なアプリケーションで有効です。この手法は、データセットの純度を高め、分類器の誤分類を減少させることが期待されます。
AllKNN
AllKNNは、異なるk値(最近傍の数)に基づいてデータセットを複数回編集することで、アンダーサンプリングを行う手法です。この手法は、データセット内のクラス間の重複を減らし、より明確なクラス分離を実現することを目的としています。
AllKNNでは、まず最小のk値(例えば1)から始め、最近傍法を用いて多数派クラスのデータポイントを削除します。その後、k値を徐々に増やしながら、同じプロセスを繰り返します。各ステップで、異なるk値に基づいてデータセットが再評価され、クラス間の境界が徐々に洗練されます。
AllKNNは、データセット内の関係が複雑で、単一のk値では十分な情報を捉えきれない場合に有効です。特に、多様な特徴を持つデータセットや、微妙なクラスの違いが重要な場合に適しています。医療データの分析や、複雑な顧客行動の理解など、精緻なデータの洞察が求められるアプリケーションで役立ちます。
ネイバーフッドクリーニングルール
ネイバーフッドクリーニングルールは、クラス間の分類のバランスを保つことを目的としたアンダーサンプリング手法です。この手法は、データセット内のクラス間の関係を改善し、特に多数派クラスのデータポイントが少数派クラスに圧迫されている場合に効果的です。
ネイバーフッドクリーニングルールでは、最近傍法を用いて多数派クラスのデータポイントが少数派クラスのデータポイントに近接しすぎている場合にこれを削除します。具体的には、多数派クラスの各データポイントについて、その最近傍のデータポイントが異なるクラスに属しているかどうかを評価し、異なるクラスのデータポイントに囲まれている場合に削除します。これにより、クラス間の境界がより明確になり、分類の精度が向上します。
ネイバーフッドクリーニングルールは、クラス間の境界が曖昧で、多数派クラスのデータが少数派クラスの特徴を隠蔽している可能性があるデータセットに特に有効です。この手法は、医療データの分析、顧客行動の予測、画像認識など、正確なクラス分類が重要な様々な分野で利用されます。
凝縮最近傍法
凝縮最近傍法は、データセットから最も代表的なサブセットを選択し、データセットのサイズを効果的に減らしながら重要な情報を保持することを目的としたアンダーサンプリング手法です。この手法は、データの凝縮を通じて、分類器のトレーニング効率と性能を向上させます。
凝縮最近傍法では、まずランダムに選ばれたサブセットから始め、残りのデータセットに含まれる各データポイントに対して、既に選択されたサブセットに基づいて分類を行います。もしデータポイントが誤って分類された場合、それはサブセットに追加されます。このプロセスは、全てのデータポイントが正しく分類されるか、あるいは改善が見られなくなるまで続けられます。
凝縮最近傍法は、大規模データセットや、計算資源が限られている環境で特に有用です。この手法により、データセットのサイズを効果的に減少させることができ、計算コストを抑えながらモデルの一般化能力を保つことができます。特に、時系列データ分析、テキスト分類、画像認識など、大量のデータを扱うアプリケーションで効果的です。
適切なアンダーサンプリング手法の選択
アンダーサンプリング手法を選択する際には、データセットの特性と要件を考慮することが重要です。
以下は、適切なアンダーサンプリング手法を選択するための具体的な手順です。
| 手順 | 詳細 |
|---|---|
| [1] データセットの評価 | データセットのサイズ、特徴、クラス間の不均衡の程度を分析。データの種類を確認。 |
| [2] 目的と制約の確認 | モデルの目的(精度、リコール、F1スコアなど)と計算資源や時間の制約を確認。 |
| [3] 手法の選択 | データセットの特性に基づいてアンダーサンプリング手法を選択。効率と精度のバランスを考慮。 |
| [4] 実装と評価 | 選択した手法を実装し、クロスバリデーションなどで評価。 |
| [5] 性能の比較と最終決定 | 異なる手法の結果を比較し、最も適した手法を最終的なモデルに適用。 |
| [6] 結果の検証 | 選択した手法がモデルの性能に与える影響を検証。必要に応じて微調整。 |
データセットに対する手法の評価
まず、データセットのサイズ、特徴の種類(数値、カテゴリカル、テキストなど)、クラス間の不均衡の程度を考慮します。
大規模なデータセットでは、計算効率を重視するため単純なランダムアンダーサンプリングが適している場合があります。
一方、データセットが小さい場合や、多数派クラスのデータポイントが重要な情報を含んでいる場合は、より洗練されたクリーニング手法を選択することが望ましいです。
効率と精度のバランス
アンダーサンプリング手法を選択する際は、計算効率とモデル精度のバランスを取る必要があります。
ランダムアンダーサンプリングは効率的ですが、多数派クラスの重要な情報が失われる可能性があります。
一方、クリーニング手法はより精度が高いですが、計算コストが高くなることがあります。
したがって、特定のアプリケーションのニーズに応じて、これらのトレードオフを慎重に検討することが重要です。
最終的には、異なる手法を試し、クロスバリデーションや他の評価方法を使用して、最も効果的なアンダーサンプリング戦略を決定します。
このプロセスは、モデルの性能を最適化し、データ不均衡の問題を効果的に解決するために不可欠です。
アンダーサンプリングの成功事例:ケーススタディ
アンダーサンプリング手法は、多くの業界で効果的にデータ不均衡の問題を解決し、モデルの性能を向上させるのに役立っています。
以下に、実際の例をもとにした5つのケーススタディを紹介します。
事例1: 金融詐欺検出
背景
金融取引データセットで、詐欺取引(少数派クラス)は正規取引(多数派クラス)に比べて非常に少ない。
アプローチ
ランダムアンダーサンプリングを用いて多数派クラスのサンプルを削減し、バランスの取れたデータセットを作成。
結果
詐欺取引の検出精度が向上し、偽陽性率が低減された。
事例2: 医療画像診断
背景
特定の疾患の医療画像は全体のデータセットにおいて少数派である。
アプローチ
クリーニングアンダーサンプリング手法(例:トメックリンク)を使用し、多数派クラスの不要なデータを除去。
結果
モデルが疾患の特徴をより効果的に学習し、診断の正確性が向上。
事例3: ソーシャルメディアの感情分析

背景
ソーシャルメディアの投稿データにおいて、特定の感情(例:喜び、悲しみ)が他の感情に比べて不均衡。
アプローチ
クリーニング手法(例:エディテッドニアレストネイバー)を使用し、感情のバランスを取る。
結果
精度が向上し、多様な感情をより正確に識別できるようになった。
事例4: 顧客の離反対策(チャーン予測)
背景
多くのビジネスにおいて、一部の顧客のみがサービスや製品の利用をやめる(離反する)ため、データセットが不均衡。
アプローチ
クリーニングアンダーサンプリング手法(例:ワンサイドセレクション)を採用して、離反しない顧客(多数派クラス)のデータを削減。
結果
モデルが離反する顧客の特徴をより正確に捉え、早期の離反防止戦略の策定に貢献。
事例5: 機器の故障予知

背景
製造業や保守管理において、機器の故障は稀であり、正常な動作データが圧倒的多数を占める。
アプローチ
インスタンスハードネス閾値を用いたアンダーサンプリングで、多数派クラス(正常動作データ)のうち、分類において「困難」なデータを選択的に削除。
結果
故障予知の精度が向上し、未然に機器のメンテナンスを行うことが可能になり、運用コストの削減に貢献。
今回のまとめ
今回は、「機械学習の課題: 不均衡データへのアンダーサンプリング解決策」というお話しをしました。
アンダーサンプリングは、機械学習においてデータ不均衡問題に対処するための効果的なアプローチです。
この手法は、多数派クラスのデータポイントを適切に削減することで、少数派クラスの特徴がモデルによってより効果的に学習されるようにします。
アンダーサンプリングには、ランダムアンダーサンプリングからより洗練されたクリーニング手法まで、さまざまな形態があり、各手法は特定のデータセットやビジネスニーズに応じて選択されるべきです。
アンダーサンプリングを適切に実施することで、モデルの予測精度の向上、過学習のリスクの低減、そして実際の問題におけるより実用的な結果の達成が可能になります。
ただし、データの削減には慎重に取り組む必要があり、重要な情報の喪失を避けるための適切な手法の選択が不可欠です。
また、異なるアンダーサンプリング手法を試し、モデルの性能を継続的に監視し、改善することが重要です。
最終的には、アンダーサンプリングは、機械学習モデルがデータ不均衡の問題を効果的に克服し、より正確で信頼性の高い予測を行うための重要なツールです。
その適用は、多様な業界やアプリケーションにわたり、ビジネスの効率と効果を大きく改善することができます。