

「クーポンやキャンペーンを打っているのに、売上がいまひとつ伸びた気がしない…」
「販促費ばかりかさんで、本当に利益が出ているのか分からない…」
そんな経験はありませんか?
実は、多くの企業が陥る落とし穴があります。
それは「見かけの成功」に騙されることです。
販促を行った結果、売上が上がったように見えても、実はもともと買う予定だった顧客が割引価格で購入しただけかもしれません。
この問題を解決する強力な手法が アップリフト分析 です。
今回は、身近な例を使いながら アップリフト という考え方を解説します。
A/Bテストの結果を 本当に増えた売上(金額も顧客も) という視点で捉え直すだけで、マーケティングのROIは見違えるほど変わります。
Contents
- 「売上がどれだけ『純増』したか」を見逃していませんか?
- よくある判断ミスの例
- 隠れた真実:顧客の行動パターン
- なぜこの視点が重要なのか
- アップリフト分析とは?
- アップリフト分析の本質
- 顧客を4つのタイプに分類する
- なぜ「逆効果の人」が存在するのか?
- ROIを最大化する鍵
- まずはグラフで効果を眺める
- シンプルに始める「Two-Model法」
- Two-Model法の基本的な考え方
- 準備するデータ
- シンプル手順
- 分析品質を保つためのチェックリスト
- ケーススタディ:A社 で ROI 改善を体験する
- A社 の課題
- アップリフト分析の実施
- 改善施策と結果
- 成功ポイント
- 実務でつまずきやすい落とし穴と、その回避策
- よくある失敗パターン
- 落とし穴1:サンプル不足による不安定な結果
- 落とし穴2:セレクションバイアス
- 落とし穴3:タイミングの無視
- 組織導入時の課題と解決策
- 課題1:現場の抵抗
- 課題2:システム・インフラの制約
- 今日から始めるアップリフト実践
- ステップ1 過去のA/Bテストを見直してみよう(所要時間:2時間)
- ステップ2 Two-Model法でざっくり差分を予測(所要時間:4時間)
- ステップ3 累積純増グラフで可視化(所要時間:2時間)
- 今回のまとめ
「売上がどれだけ『純増』したか」を見逃していませんか?

よくある判断ミスの例
まずは、多くの企業が陥りがちな判断ミスの例から見ていきましょう。
あるオンラインショップで、5%OFFクーポンを配布した結果を見てください。
| グループ | 購入率 | 購入者数(1万人中) |
|---|---|---|
| 配布しなかった人 | 3% | 300人 |
| 配布した人 | 5% | 500人 |
この表だけを見ると……
「2ポイント上がったから成功! 200人も購入者が増えた!」
……と考えがちです。
しかし、本当にそうでしょうか?
隠れた真実:顧客の行動パターン
実は、この「増えた200人」の内訳を詳しく見ると、異なる真実が見えてきます。
例えば、クーポンを配布した5,000人の内訳が以下のようになっていたとします。
| 顧客層 | 人数 | 購買行動 | 純増効果 |
|---|---|---|---|
| 常連客 | 1,500人 | クーポンがあってもなくても買う | 純増効果ゼロ |
| 無関心層 | 3,000人 | クーポンを配っても買わない | 純増効果ゼロ |
| クーポンで心が動く層 | 400人 | クーポンがあれば買う | 純増効果あり! |
| 天邪鬼な層 | 100人 | クーポンがあると逆に買わない | マイナス効果 |
つまり、本当の純増は400人 – 100人 = 300人だけなのです。
そして、1,500人の常連客に配った分のクーポン費用は「利益を削っただけ」という結果になります。
なぜこの視点が重要なのか
従来のマーケティング分析では、「施策を実施したグループの成果」だけを見ていました。
しかし、これでは以下の重要な質問に答えられません。
- その顧客は本当に施策のおかげで購入したのか?
- 施策なしでも購入していたのではないか?
- むしろ施策が逆効果になった顧客はいないか?
これらの質問に答えるのが、まさに アップリフト分析 なのです。
アップリフト分析とは?
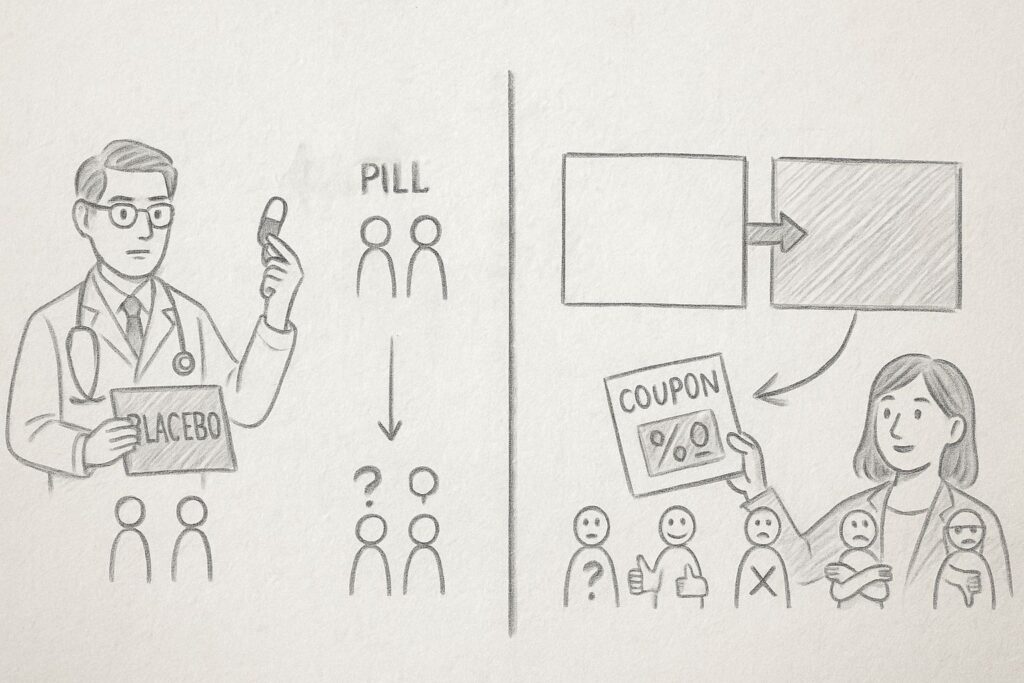
アップリフト分析の本質
アップリフト分析は「施策を行ったとき『だけ』起こる顧客行動の変化」を測る手法です。
言い換えると、「もし施策を行わなかったら」という架空の世界と現実を比較する ことで、施策の真の効果を見極めます。
この考え方は、医学の世界では当たり前に使われています。
新薬の効果を測るとき、「薬を飲んだグループ」と「偽薬(プラセボ)を飲んだグループ」を比較しますよね。
マーケティングでも同じ考え方を適用するのです。
顧客を4つのタイプに分類する
アップリフト分析の第一歩は、顧客を以下の4つのタイプに分類することです。
| 顧客タイプ | 英語名 | クーポンなし | クーポンあり | 純増効果 | 特徴 |
|---|---|---|---|---|---|
| 効く人 | Persuadable | 買わない | 買う | +1 | 施策が購買の決め手になる層 |
| もともと買う人 | Sure Thing | 買う | 買う | 0 | ロイヤル顧客、常連客 |
| まったく買わない人 | Lost Cause | 買わない | 買わない | 0 | 商品やブランドに無関心 |
| 逆効果の人 | Do-Not-Disturb | 買う | 買わない | −1 | 過度な販促を嫌う層 |
なぜ「逆効果の人」が存在するのか?
「クーポンを配ると逆に買わなくなる人がいる」というのは、一見不思議に思えるかもしれません。
しかし、実際には例えば以下のような心理が働きます。
- ブランドイメージの毀損:「高級ブランドなのに安売りしている」と感じて興ざめする
- 品質への疑念:「値引きするということは、売れ残りか品質が悪いのでは?」と疑う
- 購買タイミングのズレ:「今回は安いけど、次はもっと安くなるかも」と買い控える
- プライドの問題:「クーポンを使うのは恥ずかしい」と感じる層
実際、ある高級アパレルブランドでは、セール告知メールを送った結果、一部の優良顧客の購買頻度が下がったという事例もあります。
ROIを最大化する鍵
この4分類から分かる重要な事実があります。
- ROIを押し上げるのはPersuadable(効く人)だけ
- Sure Thing(もともと買う人)やLost Cause(まったく買わない人)に配るクーポンは「ムダ打ち」
- Do-Not-Disturb(逆効果の人)に至っては「逆効果」になりかねません
つまり 「誰に配るか」 がROIを決める最大のカギになるのです。
全員に配布するのではなく、Persuadable(効く人)を見つけ出し、彼ら・彼女らにピンポイントで施策を打つことが、マーケティング効率を劇的に改善します。
まずはグラフで効果を眺める
「アップリフトって難しそう…」と思った方もご安心ください。
最初の一歩は 累積純増グラフ を描くだけです。
これは、簡単ですが地味に施策の効果を理解する強力なツールです。
| 手順 | やること | 説明 |
|---|---|---|
| 1 | 顧客を「効きそうな順」に並べる | アップリフトスコアが高い順にソート または過去の反応率などを参考に並べ替え |
| 2 | 上位からクーポンを配ったと仮定し、配布率と売上の純増を累積計算 | 10%配布したら純増100万円 20%配布したら純増180万円 30%配布したら純増240万円… |
| 3 | その結果を線グラフにする | 横軸:配布率(0%〜100%) 縦軸:累積純増額(または純増人数) |
実際のグラフは以下のような形になることが多いです。
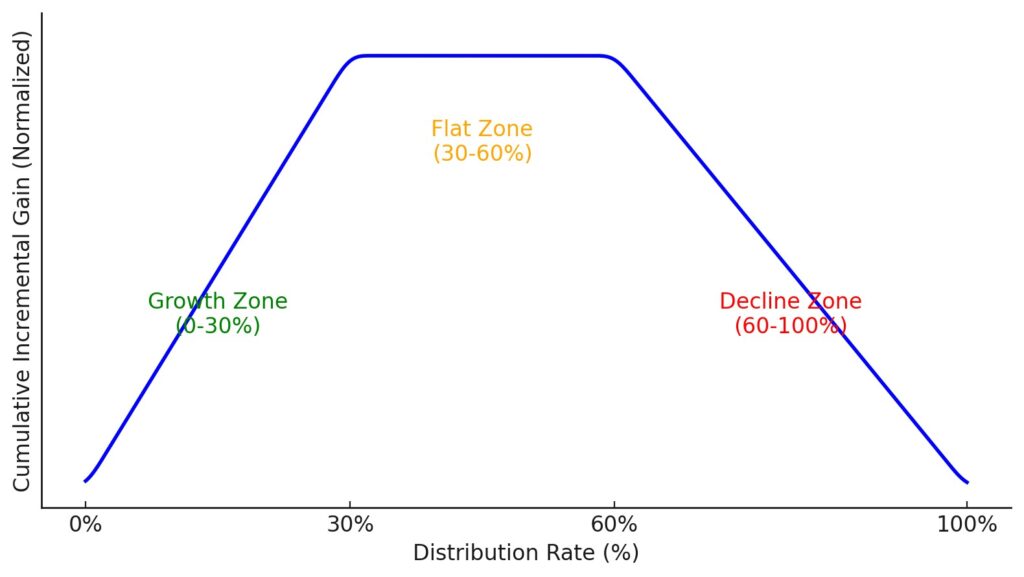
| ゾーン | 区間例 | 説明 | 施策例 |
|---|---|---|---|
| Growth Zone (右肩上がりが続く区間) | 0–30% | 配れば配るほど得をするゾーン | 積極的に配布すべき優良ターゲット |
| Flat Zone (横ばい区間) | 30–60% | 追加で配っても得は増えないゾーン | 配布してもしなくても変わらない層 |
| Decline Zone (下がり始める区間) | 60–100% | もはや配らないほうが良いゾーン | Do-Not-Disturb層が含まれ始める危険域 |
このグラフの素晴らしい点は、専門知識がなくても直感的に理解できることです。
ExcelでもGoogleスプレッドシートでも簡単に作れるので、会議資料に1枚追加してみるだけで議論が深まります。
シンプルに始める「Two-Model法」
Two-Model法の基本的な考え方
ここからは少し実践的な統計モデルなどを使った方法の説明に入ります。
ただし 統計モデル といっても、それほど難しいことをするわけではありません。
やることは「配った人」と「配っていない人」で それぞれ購入確率を予測し、その差を取るだけ です。
医学の臨床試験を思い出してください。
同じ患者さんに「薬を飲んだ場合」と「飲まなかった場合」の両方を試すことはできません。
マーケティングでも同じで、同じ顧客に「クーポンありなし両方」を試すことはできません。
そこで、似た特徴を持つ顧客グループから 「もしこの人にクーポンを配ったら/配らなかったら」を推定 するのです。
準備するデータ
必要なデータは意外とシンプルです。
| 必要な列 | 例 | 説明 |
|---|---|---|
| 顧客ID | 12345 | ユニークな識別子 |
| クーポン配布フラグ | 1:配布 / 0:未配布 | A/Bテストの結果 |
| 購入フラグ | 1:購入 / 0:未購入 | 施策後の行動結果 |
| 顧客属性 | 年齢、性別、購買履歴など | 予測に使う特徴量 |
以下は、実践でよく使われる顧客属性の例です。
| カテゴリ | 項目例 |
|---|---|
| 基本属性 | 年齢、性別、居住地域 会員ランク、会員期間 |
| 行動履歴 | 過去3ヶ月の購入回数、購入金額 最終購入からの経過日数 カテゴリ別購入履歴 |
| エンゲージメント | メール開封率、クリック率 サイト訪問頻度、滞在時間 アプリ利用頻度 |
シンプル手順
ステップ1:データを2つに分ける
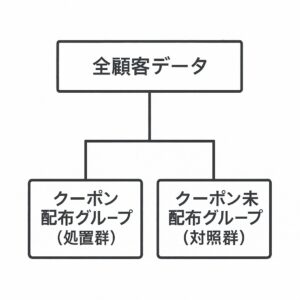
ステップ2:2つのモデルを作る
| モデル | 説明 |
|---|---|
| 配布ありモデル | クーポンを配布した顧客のデータ(処置群)だけを使い、どんな特徴の人が購入しやすいかを学習 |
| 配布なしモデル | クーポンを配布しなかった顧客のデータ(対照群)だけを使い、どんな特徴の人が購入しやすいかを学習 |
ステップ3:全顧客に両モデルを適用
全ての顧客に対して、2つの予測確率をそれぞれ求めます。
| モデル | 計算内容 |
|---|---|
| 配布ありモデル | もし配布したら購入する確率を計算(配布あり予測確率) |
| 配布なしモデル | もし配布しなかったら購入する確率を計算(配布なし予測確率) |
ステップ4:差分を計算
$$アップリフトスコア = 配布あり予測確率 – 配布なし予測確率$$
この差分が大きい顧客ほど「クーポンが効く人」ということになります。
分析品質を保つためのチェックリスト
アップリフト分析を行う際は、以下のチェックリストで品質を確認しましょう。
| チェックカテゴリ | チェック項目 |
|---|---|
| データ品質チェック | ☐ 配布群と非配布群の顧客特性に大きな偏りはないか? ☐ 分析期間中に大きな外部要因(競合のセール等)はなかったか? ☐ データの欠損や異常値は適切に処理されているか? |
| モデル評価チェック | ☐ アップリフトの大きさは現実的か?(100%改善などは要注意) ☐ 複数の手法で同様の結果が得られるか? ☐ 時期を変えても安定した結果か? |
| ビジネス妥当性チェック | ☐ 結果は業務知識と整合的か? ☐ 実行可能な示唆が得られているか? ☐ ROIは十分にポジティブか? |
ケーススタディ:A社 で ROI 改善を体験する
A社 の課題
理屈より「やってみた結果」を見たほうがイメージしやすいでしょう。
ということで、A社の事例を見ていきます。
概要
- ECサイトを運営する中堅アパレル企業
- 顧客数:10万人
- 平均客単価:5,000円
- 課題:クーポン配布の費用対効果が悪化
クーポン配布施策
- 月1回、全顧客の30%(3万人)にランダムで500円クーポンを配布
- クーポン利用率:約20%
- 費用ばかりかさんで利益が出ない
アップリフト分析の実施
まず、1万人を対象にクーポン配布のA/Bテストを実施しました。
- A群:5,000人にクーポン配布
- B群:5,000人にクーポン未配布
Two-Model法で分析した結果、以下の傾向が明らかになりました。
| アップリフト | セグメント | 特徴 | 全体の割合 |
|---|---|---|---|
| +15%~ | 高反応層 | 20-30代、月1-2回サイト訪問 | 15% |
| +8%~+15% | 中反応層 | 全年代、新規会員 | 25% |
| -3%~+8% | 無反応層 | 常連客、高額購入者 | 40% |
| ~-3% | 逆効果層 | 40代以上、ブランド志向 | 20% |
改善施策と結果
この分析結果を基に、配布戦略を次のように変更しました。
- 高反応層(上位15%)に優先的に配布
- 逆効果層には配布しない
- 配布総数を3万枚から1.5万枚に削減
以下、この新施策の結果です。
| 比較項目 | 従来 | 改善後 | 改善率 |
|---|---|---|---|
| 配布枚数 | 3万枚 | 1.5万枚 | -50% |
| クーポン費用 | 300万円 | 150万円 | -50% |
| クーポン経由売上 | 900万円 | 750万円 | -17% |
| クーポンなし売上への影響 | -50万円 | +20万円 | +140% |
| 売上増加合計 | +280万円 | +270万円 | -4% |
| 純利益 (売上−費用) | -20万円 | +120万円 | +140万円改善 |
成功ポイント
この事例のポイントは以下です。
売上はわずかに減っても、利益は大幅に改善
- 無駄なクーポン配布を削減
- 逆効果層を避けることで、通常購入への悪影響を回避
顧客体験の向上
- 興味のない人への過度な販促メールが減少
- ブランドイメージの毀損を防止
次の施策への示唆
- 高反応層の特徴を詳しく分析し、類似顧客の獲得に注力
- 逆効果層には別のアプローチ(品質訴求など)を検討
実務でつまずきやすい落とし穴と、その回避策

よくある失敗パターン
アップリフト分析は強力な手法ですが、実践では様々な落とし穴があります。
ここでは、実際の企業でよく見られる失敗とその対策を解説します。
落とし穴1:サンプル不足による不安定な結果
症状
- 「先月は効果があったのに、今月は逆効果だった」
- 「A店舗では成功したが、B店舗では失敗した」
原因
統計的に有意な差を検出(効果があると判断)するには、一定以上のサンプルサイズが必要です。
特に効果が小さい場合、本当に効果があるのかを見極めるのに必要なサンプルの数は、増えます。
対策
有意水準 α = 5 %(両側)・検出力 1 – β = 80 %・2 群(均等割付)を想定
| 基準 CVR(p₀) |
最小検出効果 MDE(絶対差) |
p₀ → p₁ | 各グループに 必要な人数 |
2群 合計 |
|---|---|---|---|---|
| 5 % | +5 pt | 5 % → 10 % | 434 | 868 |
| 5 % | +3 pt | 5 % → 8 % | 1 058 | 2 116 |
| 5 % | +1 pt | 5 % → 6 % | 8 149 | 16 298 |
| 10 % | +5 pt | 10 % → 15 % | 685 | 1 370 |
| 10 % | +3 pt | 10 % → 13 % | 1 772 | 3 544 |
| 10 % | +1 pt | 10 % → 11 % | 14 735 | 29 470 |
| 20 % | +5 pt | 20 % → 25 % | 1 093 | 2 186 |
| 20 % | +3 pt | 20 % → 23 % | 2 940 | 5 880 |
| 20 % | +1 pt | 20 % → 21 % | 25 554 | 51 108 |
- 自社の基準 CVR (p₀) と 検出したい効果 (MDE) を選び、対応する行を参照します。
- 表の「各グループに必要な人数」が、テスト群(例:クーポン配布)・コントロール群(例:クーポン未配布)それぞれに最低限必要なサンプル数です。
- 表にない数値が必要な場合は、同じ前提(α = 0.05, 1 – β = 0.80)で再計算してください(Python例:
statsmodels.stats.powerのNormalIndPowerなど)。
実務的なアプローチ
- 最初は効果の大きそうなセグメントに絞って実験
- 複数月のデータを統合して分析
- ベイズ統計を活用して、少ないサンプルでも安定した推定
落とし穴2:セレクションバイアス
症状
- 「メルマガ開封者にクーポンを配ったら効果絶大だった」
- 「アプリユーザー限定キャンペーンが大成功」
原因
もともと興味の高い層だけを対象にすると、効果を過大評価してしまいます。
対策
- ランダム化:可能な限りランダムにグループ分け
- 傾向スコアマッチング:似た特徴の顧客同士を比較
- 操作変数法:外的要因を使って因果関係を推定
落とし穴3:タイミングの無視
症状
- 「年末セールの分析結果を、通常月に適用したら失敗」
- 「新商品発売時の施策が、在庫処分時には効かない」
原因
顧客の購買意欲は時期によって大きく変動します。
対策
- 季節性の考慮:同じ時期のデータで学習・適用
- イベントカレンダー:セール、新商品発売などの影響を明示的にモデルに組み込む
- 時系列分析:トレンドや周期性を考慮した予測
組織導入時の課題と解決策
課題1:現場の抵抗
よくある反応
- 「今までのやり方で問題ない」
- 「データ分析は机上の空論」
- 「顧客のことは現場が一番知っている」
解決策
- 小さな成功体験から始める
- 限定的な商品カテゴリで実験
- 成果を数字で明確に示す
- 現場の知見を取り入れる
- 「データ vs 経験」ではなく「データ × 経験」
- 現場の仮説をデータで検証
- 段階的な導入
段階 内容 第1段階 分析結果の共有のみ 第2段階 一部の施策で試験運用 第3段階 全面展開
課題2:システム・インフラの制約
典型的な問題
- 「顧客データが分散していて統合できない」
- 「リアルタイムでスコアリングできない」
- 「A/Bテストの仕組みがない」
段階的な解決アプローチ
| フェーズ | タスク |
|---|---|
| Phase 1:既存データで分析(1-3ヶ月) |
|
| Phase 2:システム連携(3-6ヶ月) |
|
| Phase 3:自動最適化(6ヶ月以降) |
|
今日から始めるアップリフト実践

ステップ1
過去のA/Bテストを見直してみよう(所要時間:2時間)
過去1年間のキャンペーン結果を集める
必要なデータ - 施策名 - 対象者数 - 実施群/対照群の売上 - かかったコスト
真の増分効果を計算
増分効果 = (実施群の売上 - 対照群の売上 × 実施群の人数/対照群の人数) [latex]ROI = (増分効果 - コスト) / コスト[/latex]
簡易セグメント分析
- 年代別、性別、会員ランク別に上記を計算
- 効果の高い/低いセグメントを特定
ステップ2
Two-Model法でざっくり差分を予測(所要時間:4時間)
Excelだけでも簡易的に実施できます。ただ、RやPythonなどの分析ツールを使うと、もっといい感じに実施できます。
データ準備
Excelシート例 - A列:顧客ID - B列:年齢グループ(20代、30代...) - C列:性別 - D列:過去購入回数グループ(0回、1-2回、3回以上) - E列:クーポン配布(1/0) - F列:購入(1/0)
Excelピボットテーブルなどで集計
- 行:年齢×性別×購入回数
- 列:クーポン配布有無
- 値:購入率
アップリフトを計算
- 各セグメント(性別や年齢、購入回数別など)で(配布あり購入率 – 配布なし購入率)
- アップリフトの高い順にソート
ステップ3
累積純増グラフで可視化(所要時間:2時間)
顧客リストを作成
Excelシート例 - A列:顧客ID - B列:アップリフトスコア(ステップ2の結果) - C列:予想売上増加額(スコア × 平均購入額) - D列:クーポンコスト
累積計算
- アップリフトスコアの高い順にソート
- 上から順に、累積売上増加 – 累積コストを計算
グラフ化
- X軸:配布率(上位何%まで配布)
- Y軸:累積純利益
- 最高点を「最適配布率」として提案
今回のまとめ
デジタルマーケティングが成熟期を迎える中、「とりあえず全員に配信」という時代は終わりました。
これからは……
- 顧客体験の最適化:必要な人に、必要なタイミングで
- マーケティングROIの最大化:限られた予算で最大の効果
- ブランド価値の保護:過度な販促によるブランド毀損を防ぐ
これら全てを実現する鍵が、アップリフト分析なのです。
アップリフト分析は、決して難しい手法ではありません。本質は「誰に効くのか」を見極めることです。
小さな一歩から始めて、徐々に精度を上げていけば、必ず成果は表れます。
- 次のキャンペーンでA/Bテストを実施
- 結果を「差分」の視点で分析
- 効果の高い顧客の特徴を把握
販促の効果に悩むすべての人に、アップリフト分析という武器が広まることを願っています。
Excelなどだけで非常に簡単にできます。もちろん、機械学習因果推論などの手法で精緻にもできます。
結構、面白い結果が分かると思いますので、機会があればぜひ挑戦してみてください。