

PythonのNumPyやPandas、Scikit-Learn(sklearn)で扱えないぐらいビッグなデータならDaskです。
Pythonでデータ分析をするとき、NumPyやPandas、Scikit-Learn(sklearn)などのライブラリーを使う人は多いと思います。
しかし、ある程度データ量が大きくなると、うんともすんともPCが反応しなくなったり、データ量が大きくそもそも扱えないケース(エラーがでる)も多々あります。
そのようなときに、とっても便利なライブラリーの1つがDaskです。
NumPyやPandas、Scikit-Learn(sklearn)ライクに操作を行えるのが特徴です。
データ量が多いなと感じた場合、試してみてください。
今回は、「NumPyやPandas、Scikit-Learn(sklearn)で扱えないぐらいビッグなデータならDask(Python)」というお話しをします。
Daskとは?
簡単に言うと、並列処理や分散処理を行ったり、機械学習ライブラリー(Scikit-Learnなど)を高速化することが出来ます。
みんな大好きNumPyやPandasは、基本的にシングルコアでの処理を行うため速度が遅くなったり、そもそもデータがメモリに乗らず扱えなかったりします。
データ量の大きなデータセットに対し、例えばDaskは並列処理などを駆使し全てのデータに対し処理を行うことができます。
ちなみに、並列(Parallel)処理とは、AとBという処理がある場合、同時に処理を行うことです。一方、分散(Distributed)処理は、処理AとBを異なる場所で行うことです。
今回は、最低限知っておいた方が良さそうな「ビッグデータ」の扱いの部分を、出来るだけ平易に説明します。

インストール
Anacondaの方は、以下のコードでインストールできます。もちろん、pipでもインストールできます。
conda install dask conda install python-graphviz -y conda install -c conda-forge dask-ml conda install -c conda-forge dask-glm conda install -c conda-forge dask-xgboost
今回は、分散処理などの小難しい話しではなく、PC1台でできることを簡単に紹介します。
- Dask Arrays(Numpyの配列のようなもの)
- Dask DataFrame(Pandasのデータフレームのようなもの)
- 機械学習モデル(分類モデル)を作ろう!
ライブラリーの読み込み
先ずは、今回利用するライブラリーを読み込みます。
以下、コードです。
# 基本ライブラリー読み込み
import numpy as np
import pandas as pd
# dask関連のライブラリー読み込み
import dask
import dask.array as da
import dask.dataframe as dd
import dask_xgboost #xgboost分類器
import xgboost #xgboost分類器
import joblib #並列処理(daskと連携)
from dask.distributed import Client, progress #クライアント(並列・分散処理)
from dask_ml.datasets import make_classification as dm_mc #分類問題用のサンプルデータ生成
from dask_ml.model_selection import train_test_split #学習データとテストデータの分割
from dask_ml.linear_model import LogisticRegression #ロジスティック回帰
from dask_ml.metrics import accuracy_score #分離問題の正答率スコア
# sklearnのライブラリー読み込み
from sklearn.svm import SVC #SVM分類器
from sklearn.model_selection import GridSearchCV #グリッドサーチ
from sklearn.datasets import make_classification as sk_mc #分類問題用のサンプルデータ生成
# グラフ描写の設定
import matplotlib.pyplot as plt #ライブラリー読み込み
plt.style.use('ggplot') #グラフのスタイル
plt.rcParams['figure.figsize'] = [12, 9] #グラフサイズ設定
今回の例では、NumPyやPandas、Scikit-Learn(sklearn)、joblibなど一般的によく使われるライブラリーも使いますので、まだインストールされていない方は、必要なものを適時インストールして頂ければと思います。
Dask Arrays(NumPyの配列のようなもの)
乱数を使い、サンプルデータを作ります。NumPyのArray型(行列)です。
作るサンプルデータは以下の2つです。
- 1,000行×1,000列
- 100,000行×100,000列
以下、1,000行×1,000列の行列(サンプルデータ)を作るコードです。
X = np.random.uniform(size=(1000, 1000)) X
以下、実行結果です。

問題なくXにデータが格納されたようです。
以下、100,000行×100,000列の行列(サンプルデータ)を作るコードです。
X = np.random.uniform(size=(100000, 100000)) X
以下、実行結果です。

私のPCではエラー(MemoryError)がでて、Xにデータを格納できません。PCのスペックによっては、エラーメッセージが出ていないかもしれません。その場合には、サンプルデータの行列のサイズを増やして試してみてください。
次に、DarrayでArray型(行列)の100,000行×100,000列の行列(サンプルデータ)を、NumPyと同じように乱数を使い作ってみます。
以下、コードです。
X = da.random.random((100000, 100000)) X
以下、実行結果です。

出力されるアウトプットが、NumPyのときと異なり概要だけになります。
Arrayの右にあるChunkが鍵を握っています。DaskのArray(行列)は、Chunkに記載されているチャンクサイズ単位に分割され、分割された行列はNumPyのArray(行列)です。
要は、DaskのArray(行列)は、複数のNumPyのArray(行列)で構成されています。
チャンクサイズ単位は、指定することができます。
以下、コードです。
X = da.random.random((100000, 100000),chunks=(1000, 1000)) X
以下、実行結果です。

Arrayの右にあるChunkが変わっています。
DaskのArrayの演算は、NumPyのArrayの演算とほぼ同じように実施できます。
3つのサンプルデータを生成し、行例の和を計算してみます。
以下、サンプルデータを生成するコードです。
X1 = da.random.uniform(size=(1000, 1000)) X2 = da.random.uniform(size=(1000, 1000)) X3 = da.random.uniform(size=(1000, 1000))
以下、行列の和を計算するコードです。
Y = X1 + X2 + X3
NumPyと異なり、これだけでは計算はされません。同じArrayでも、ここがNumpyとDaskの大きな違いです。
DaskのArrayの演算を実施するときは、「compute」メソッドを実施する必要になります。
以下、コードです。
Y.compute()
以下、実行結果です。
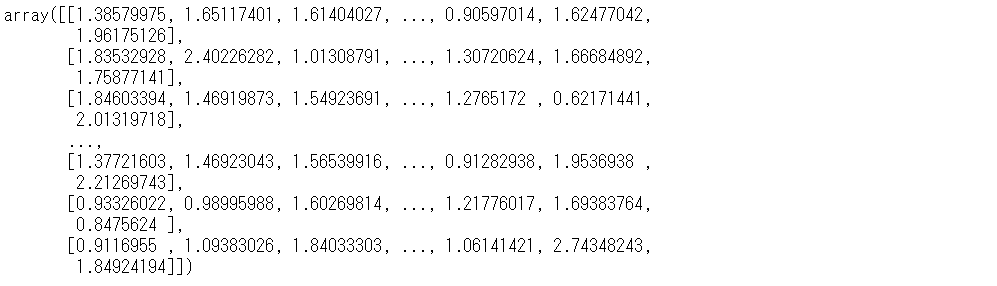
実行時間を表示させたいときには、「%%time」を付けて計算を実施します。
以下、コードです。
%%time Y.compute()
以下、実行結果です。

47.9ミリ秒(ms)です。ミリ秒(ms)とは1/1000秒(s)です。
Dask Graphを使い、各処理を見える化することができます。見える化するには、「visualize」メソッドを利用します。
以下、コードです。
Y.visualize()
以下、実行結果です。
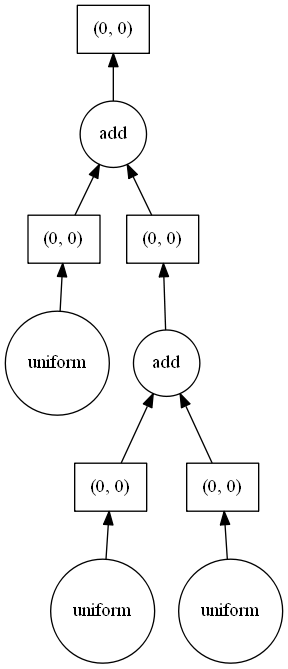
このGraph 上で、縦につながっていない処理同士は、並列で実行できます。
もう少し、複雑な処理をしてみます。
以下、コードです。
X4 = X1 + X2 #行列の和 Y = np.dot(X4, X3) #行列の積 invY = np.linalg.inv(Y) #行列の逆行列
以下、invYを計算するコードです。
invY.compute()
以下、実行結果です。

以下、invYを計算する処理を見える化するコードです。
invY.visualize()
以下、実行結果です。
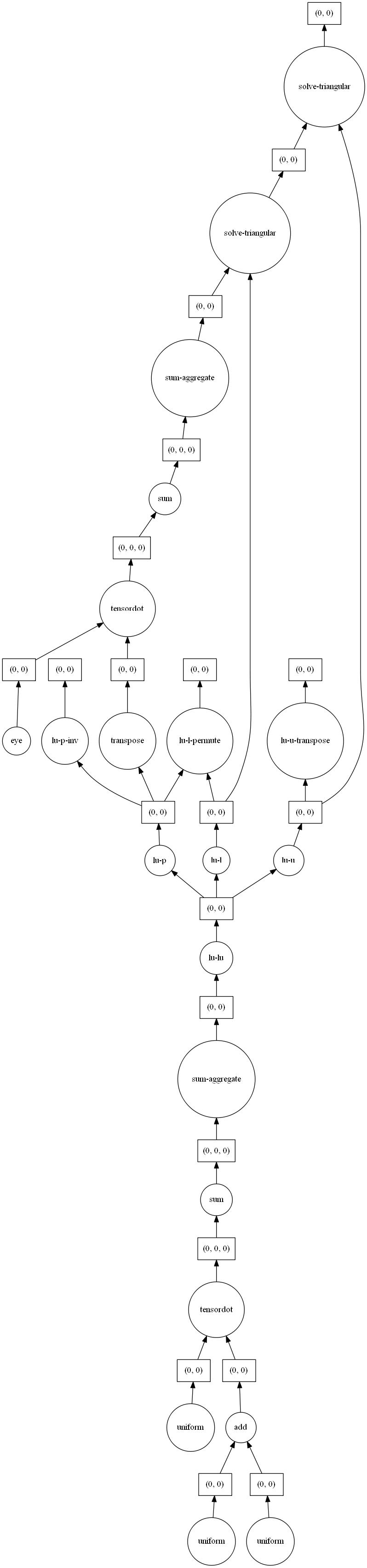
Dask DataFrame(Pandasのデータフレームのようなもの)
DaskのDataFrame(データフレーム)は、DaskのArray(行列)が多くのNumPy Array(行列)で構成されるのと同様、多くのPandasのDataFrame(データフレーム)で構成されます。
DaskのDataFrame(データフレーム)の演算などは、PandasのDataFrame(データフレーム)の演算とほぼ同じです。
ここでは、簡単にデータセットの読み込み(ロード)のみ説明します。
読み込むデータセットは、Peyton ManningのWikipediaのPVです。よく利用されるサンプルデータの1つです。
URLから直接読み込みます。URLから直接CSVファイルなどを読み込むためにrequestsとaiohttpの2つのライブラリーが必要になりますので、まだインストールされていない方は、インストールしてください。
以下、コードです。
# Peyton ManningのWikipediaのPV # データセット(CSV形式)読み込み url = 'https://www.salesanalytics.co.jp/bgr8' df = dd.read_csv(url)
読み込んだデータセットは、「df」に格納されています。中を見てみます。
以下、コードです。
df
以下、実行結果です。

データセットの概要がアウトプットされます。
どうしてもデータセットの中を見てみたい人は、「head」メソッドでデータセットの一部分を見ることができます。
以下、コードです。
df.head(10)
以下、実行結果です。
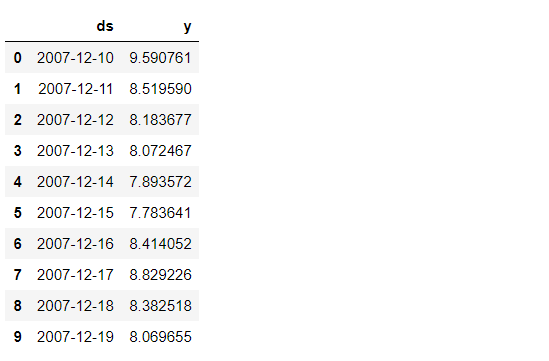
上位10のデータが表示されていると思います。
読み込んだデータセットをグラフ化します。
以下、コードです。
# Peyton ManningのWikipediaのPVのプロット
df.compute().plot()
plt.title('Page Views of Peyton Manning') #グラフタイトル
plt.ylabel('Daily Page Views') #タテ軸のラベル
plt.xlabel('Day') #ヨコ軸のラベル
plt.show()
以下、実行結果です。
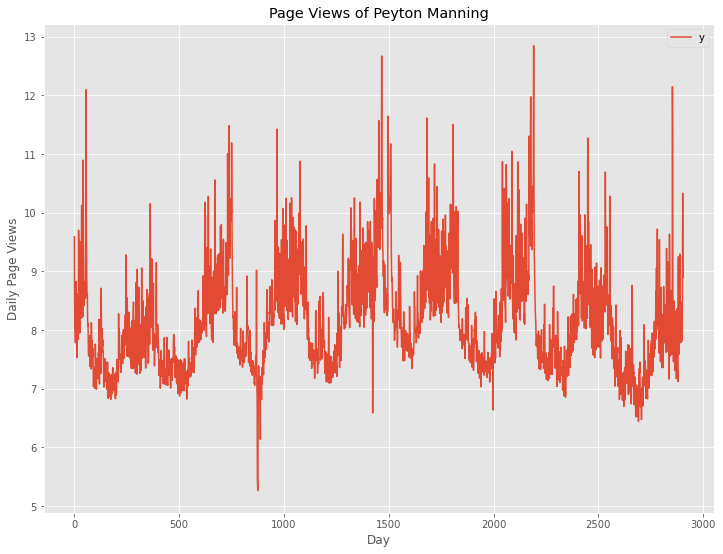
Pandasと違い「compute」メソッドを実施してからプロットしています。
機械学習モデル(分類モデル)を作ろう!
スケーリングの種類
現在(2021年2月10日現在)のDaskが想定している、数理モデル構築上のスケーリングの問題の種類は、次の2つです。
- CPU:学習時間がかかりすぎる
- RAM:データがRAMより大きい
使い分け方です。
- データがRAMより大きい場合は、dask実装された機械学習モデル(dask_ml)を使いましょう
- データはRAMに収まるが、モデルの学習時間がかかりすぎるなら、 joblib×daskとScikit-Learn(sklearn)などを組み合わせて使いましょう
- データがRAMに収まり、モデルの学習時間もかからないなら、普通にScikit-Learn(sklearn)などを使いましょう。
データ量もそれほど多くなく、モデルもそれほど複雑でないときに、Daskを利用すると時間がかかる可能性がありますので、最初はScikit-Learn(sklearn)などを使い、どうしようもないときにDaskを試しましょう。
dask実装された機械学習モデル(dask_ml)は、日々増えています。Scikit-Learn(sklearn)やXGBoost &LightGBM、PyTorch、Keras&Tensorflowなどと連携されています。
ちなみに、モデル構築の流れは、基本的にScikit-Learn(sklearn)と同じです。
分類モデル構築
今回は、分類問題を扱います。そのため、構築するモデルは分類モデルです。
- Y:0-1データ(0 or 1)、目的変数
- X:特徴量(説明変数)
分類問題のサンプルデータは、乱数を使い生成します。
小規模データと大規模データそれぞれで、Daskを絡ませながら分類モデル構築を実施していきます。
- 小規模データ(SVM分類器をグリットサーチで構築)
- SVM分類器(並列処理設定なし)
- SVM分類器(sklearnのn_jobs設定で並列処理)
- SVM分類器(joblib×daskで並列処理)
- 大規模データ(XGBoost分類器とロジスティック回帰)
- XGBoost分類器
- ロジスティック回帰
小規模データ(SVM分類器をグリットサーチで構築)
小規模データセット生成
先ず、分類問題用のサンプルデータセットを生成します。
以下、コードです。
# 分類問題用のサンプルデータ生成 X, y = sk_mc(n_samples=1000, n_features=10,n_informative=4,random_state=0) X
以下、実行結果です。

学習データとテストデータに分割します。
以下、コードです。
# 学習データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
- X_train:学習データの特徴量
- X_test:テストデータの特徴量
- y_train:学習データの目的変数
- y_test:テストデータの目的変数
学習データでモデル構築し、テストデータで構築したモデルの正答率の精度を検証します。
SVM分類器(並列処理設定なし)
Scikit-Learn(sklearn)を使いSVM分類器を、並列処理などの特別な設定することなく、グリッドサーチでパラメータ調整しながら構築します。
以下、グリッドサーチの設定です。
# グリッドサーチの設定
param_grid = [
{'C': [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0], 'kernel': ['linear']},
{'C': [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0], 'kernel': ['rbf'], 'gamma': [0.001, 0.0001]},
{'C': [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0], 'kernel': ['poly'], 'degree': [2, 3, 4], 'gamma': [0.001, 0.0001]},
{'C': [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0], 'kernel': ['sigmoid'], 'gamma': [0.001, 0.0001]}]
grid_search = GridSearchCV(SVC(),
param_grid=param_grid,
cv=10)
では、実行してみたいと思います。
以下、コードです。
%%time # モデル学習(グリッドサーチの実施) grid_search.fit(X_train, y_train)
以下、実行結果です。
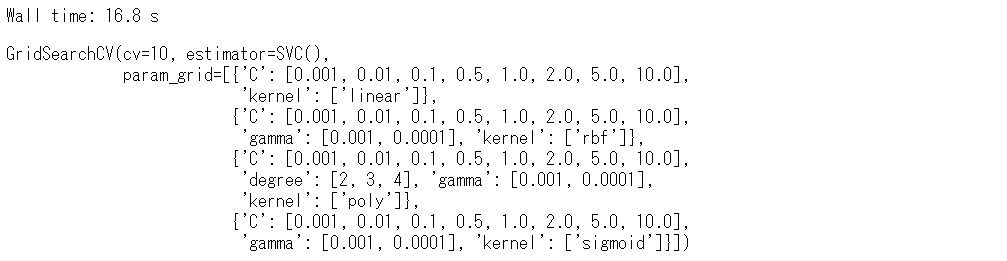
実行時間は、16.8秒です。
学習データで構築されたモデルと、構築されたモデルの正答率の精度をテストデータで検証します。
以下、コードです。
# モデル学習結果 print(grid_search.best_params_) #モデルのパラメータ print(grid_search.score(X_test, y_test)) #正答率(テストデータ)
以下、実行結果です。

正答率は、71.5%です。
SVM分類器(sklearnのn_jobs設定で並列処理)
Scikit-Learn(sklearn)を使いSVM分類器を、sklearnのn_jobs設定で並列処理し、グリッドサーチでパラメータ調整しながら構築します。
以下、グリッドサーチの設定です。
# グリッドサーチの設定
param_grid = [
{'C': [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0], 'kernel': ['linear']},
{'C': [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0], 'kernel': ['rbf'], 'gamma': [0.001, 0.0001]},
{'C': [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0], 'kernel': ['poly'], 'degree': [2, 3, 4], 'gamma': [0.001, 0.0001]},
{'C': [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0], 'kernel': ['sigmoid'], 'gamma': [0.001, 0.0001]}]
grid_search = GridSearchCV(SVC(),
param_grid=param_grid,
cv=10,
n_jobs=-1)
では、実行してみたいと思います。
以下、コードです。
%%time # モデル学習(グリッドサーチの実施) grid_search.fit(X, y)
以下、実行結果です。
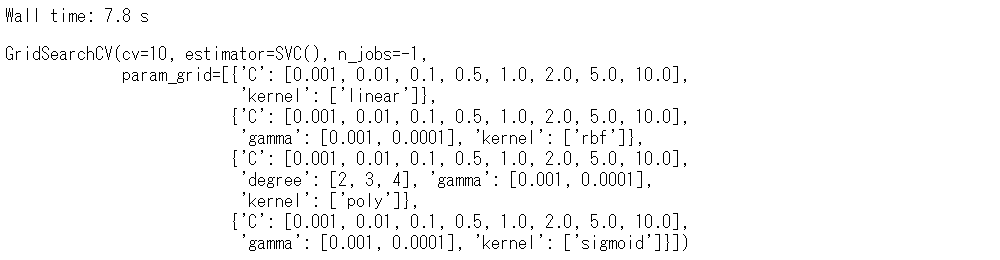
実行時間は、7.8秒です。
学習データで構築されたモデルと、構築されたモデルの正答率の精度をテストデータで検証します。
以下、コードです。
# モデル学習結果 print(grid_search.best_params_) #モデルのパラメータ print(grid_search.score(X_test, y_test)) #正答率(テストデータ)
以下、実行結果です。

正答率は、71.5%です。
SVM分類器(joblib×daskで並列処理)
先ほどのグリッドサーチの設定そのままで、Scikit-Learn(sklearn)を使いSVM分類器を、 joblib×daskで並列処理し、グリッドサーチでパラメータ調整しながら構築します。
先ずは、Daskの並列処理・分散処理のためのクライアントを作ります。
以下、コードです。
# クライアント構築 client = Client(processes=False) client
以下、実行結果です。
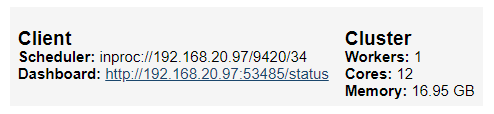
DashboardのURLをクリックすると、次のようなダッシュボードを見ることができます。
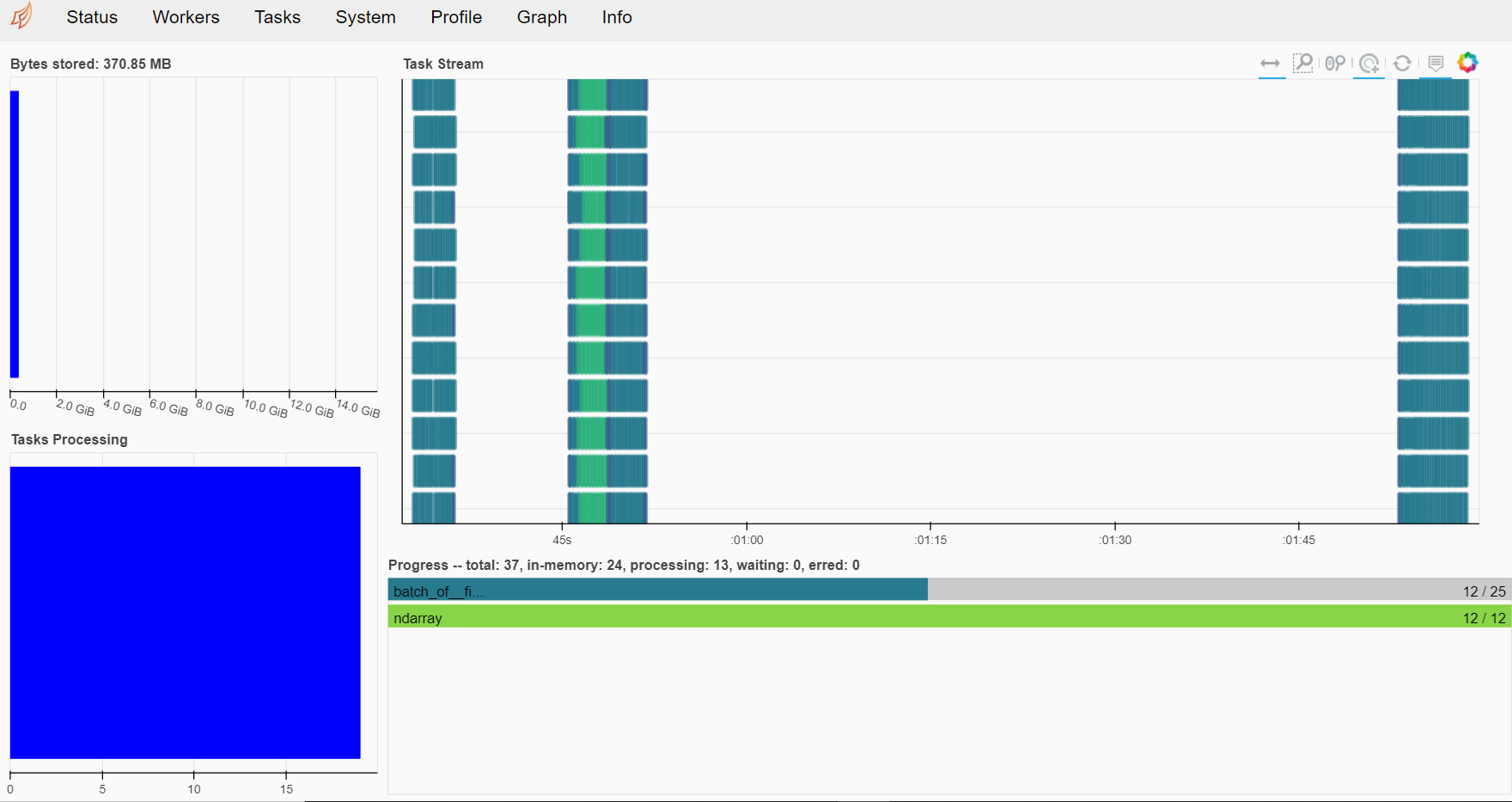
では、モデル構築を実行してみたいと思います。
以下、コードです。
%%time
# モデル学習(グリッドサーチの実施)
with joblib.parallel_backend('dask'):
grid_search.fit(X, y)
以下、実行結果です。
![]()
実行時間は、5.36秒です。
学習データで構築されたモデルと、構築されたモデルの正答率の精度をテストデータで検証します。
以下、コードです。
# モデル学習結果 print(grid_search.best_params_) #モデルのパラメータ print(grid_search.score(X_test, y_test)) #正答率(テストデータ)
以下、実行結果です。

正答率は、73.5%です。
大規模データ(XGBoost分類器とロジスティック回帰)
大規模データセット生成
先ず、分類問題用のサンプルデータセットを生成します。
以下、コードです。
# 分類問題用のサンプルデータ生成
X, y = dm_mc(n_samples=100000, n_features=100,
chunks=4000, n_informative=10,
random_state=0)
X
以下、実行結果です。

学習データとテストデータに分割します。
以下、コードです。
# 学習データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
- X_train:学習データの特徴量
- X_test:テストデータの特徴量
- y_train:学習データの目的変数
- y_test:テストデータの目的変数
学習データでモデル構築し、テストデータで構築したモデルの正答率の精度を検証します。
XGBoost分類器
daskのXGBoost分類器を構築します。
以下、XGBoost分類器モデルの設定です。
# モデルの設定
params = {'objective': 'binary:logistic',
'max_depth': 5,
'eta': 0.01,
'subsample': 0.5,
'min_child_weight': 0.5}
では、モデル構築を実行してみたいと思います。
以下、コードです。
%%time
# モデルの学習
bst = dask_xgboost.train(client,
params,
X_train,
y_train,
num_boost_round=1000)
以下、実行結果です。
![]()
実行時間は、4分19秒です。
学習データで構築されたモデルの特徴量重要度のグラフ化と、構築されたモデルの正答率の精度をテストデータで検証します。
以下、コードです。
# モデル学習結果
## グラフ化(特徴量重要度)
ax = xgboost.plot_importance(bst, height=0.8, max_num_features=9)
ax.grid(False, axis="y")
ax.set_title('xgboost feature importance')
plt.show()
## 正答率
predictions = dask_xgboost.predict(client, bst, X_test)
y_pred_max = da.around(predictions)
accuracy_score(y_true=y_test, y_pred=y_pred_max)
以下、実行結果です。
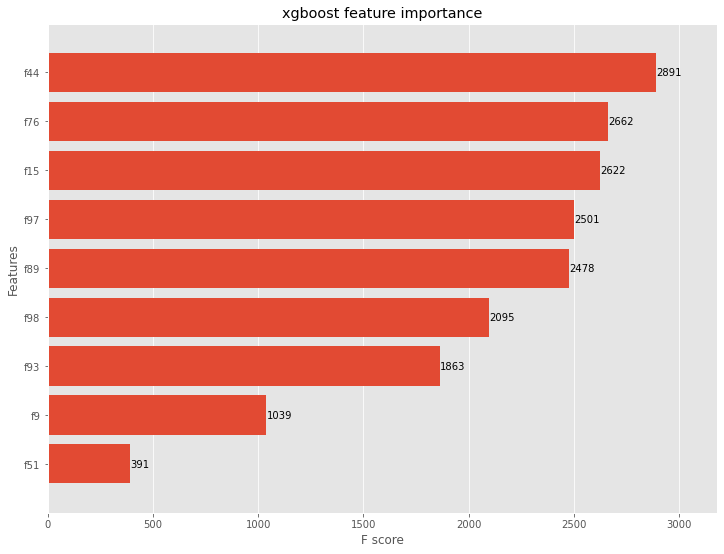
![]()
正答率は、77.305%です。
予測結果は「predictions」に格納されています。
どうなっているのか見てみましょう。以下、コードです。
predictions
以下、実行結果です。
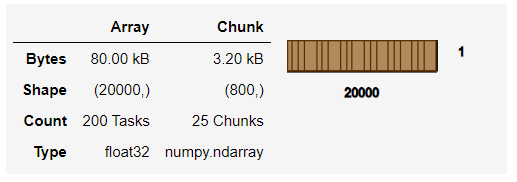
Dask Array(行列)型なので概要しか表示されません。NumPy Array(行列)型にし、中を見たい場合には「compute」メソッドを使います。
以下、コードです。
predictions.compute()
以下、実行結果です。
ロジスティック回帰
daskのロジスティック回帰モデルを構築します。
以下、コードです。
%%time # モデルの学習 lr = LogisticRegression() lr.fit(X_train, y_train)
以下、実行結果です。
![]()
実行時間は、3分です。
学習データで構築されたモデルの特徴量重要度のグラフ化と、構築されたモデルの正答率の精度をテストデータで検証します。
以下、コードです。
# モデル学習結果
## 係数
f_coef = pd.DataFrame(lr.coef_) #係数取得
f_coef.columns = ['coef']
f_coef['No'] = pd.RangeIndex(start=0, stop=100, step=1) #連番
des_f_coef = f_coef.loc[f_coef.coef.abs().argsort()[::-1]] #係数の絶対値で降順
## グラフ化
x = np.arange(10, 0, -1)
label_x = des_f_coef.head(10).No
y = des_f_coef.head(10).coef
plt.barh(x, y, align="center")
plt.yticks(x, label_x)
plt.title('LogisticRegression Coefficients')
plt.show()
## 正答率
lr.score(X_test, y_test).compute()
以下、実行結果です。
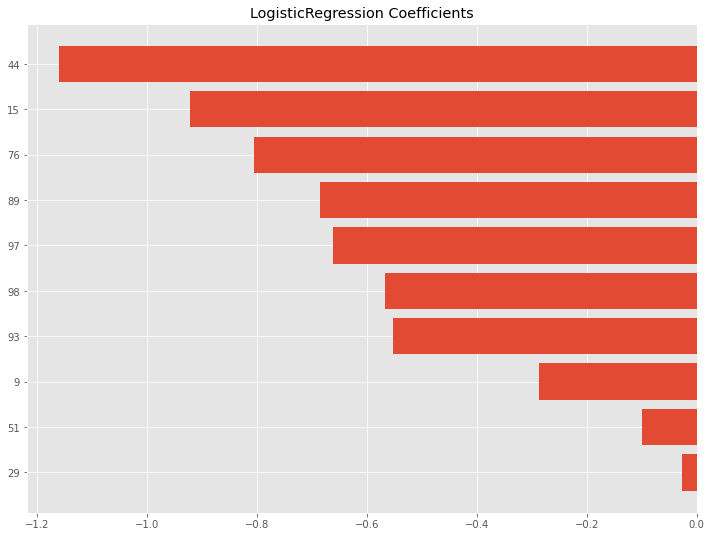
![]()
正答率は、78.175%です。
今回のまとめ
PythonのNumPyやPandas、Scikit-Learn(sklearn)で扱えないぐらいビッグなデータなら、取り急ぎDaskで試してみてはいかがでしょうか。
NumPyやPandas、Scikit-Learn(sklearn)ライクに操作を行えるのが特徴です。