
データ分析・活用(データサイエンス実践)するとき、いつまでも手作業ベースで分析結果や予測結果を、データ分析者やデータサイエンティストなどが提供し続けるのは困難です。
そのため、データ活用の現場でも使えるように、何かしらツール化(Webアプリなど)したほうがいいでしょう。
Pythonですと、DjangoやFlaskなどを活用することが多いとは思いますが、もっと手軽にさくっと行きたいものです。
そこまで美しいものが必要でなければ(そこそこで十分であれば)、Pythonのstreamlitがとっても手軽でお勧めです。
極端なことを言うと、数行のコードで数理モデルを組み込んだWebアプリを素早く構築することができます。
ということで、今回は「さくっと機械学習のWebアプリを作りたくなったらPythonのstreamlitがとっても手軽だよ」というお話しをします。
今回は、Jupyter Notebookではなく、ターミナル(Anaconda Prompt や PowerShell など)の使いコマンドラインベースで進めいてきます。
私のPCの場合は以下のような感じです。
ライブラリーのインストール
先ずは、Pythonのstreamlitをインストールする必要があります。
以下、コードです。
pip install streamlit
インプットとアウトプットのところを作り込む
Webアプリは、単に機械学習のモデルがあればいいというわけではなく、インプットとアウトプットのところの作り込みが発生します。
例えば、何かを予測するためのアプリを作るのであれば、予測するときに入力するインプット部分、その結果を返すアウトプット部分を、Python上で作る必要があります。
インプット
↓
予測器(学習済み予測モデル)
↓
アウトプット
streamlitは、そのインプット部分とアウトプット部分が簡単に作れます。逆に言うと、あまり自由度がないとも言えます(たぶん)。
アプリの実行
アプリを実行するときは非常に簡単です。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行するだけです。
streamlit run xyz.py
「xyz.py」はPyhtonコードの書かれたファイルで、ファイル名は何でも構いません。この「xyz.py」にインプット部分や予測器部分、アウトプット部分などをPythonコードで記述していきます。
よく使うインプット・アウトプットの部品
先ほども言いましたが、Webアプリですので、単に機械学習のモデルがあればいいというわけではなく、インプットとアウトプットのところの作り込みが発生します。
ここで、比較的よく使うであろうインプット・アウトプットの部品を紹介します。
詳細はStreamlitのサイトを参照して頂ければと思います
https://docs.streamlit.io/en/stable/index.html
基本、「st.write()」を使うことが多いです。
タイトルの表示(st.title)
Webアプリのタイトルを記述するときに利用します。
タイトルだけ表示するstreamlitアプリ例です。以下、コードです。
import streamlit as st
st.title('My Web Application')
このコードは、sample001.pyという名前で保存しているものとします。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行します。
streamlit run sample001.py
実行すると以下のように、ターミナル(Anaconda Prompt や PowerShell など)に表示されます。
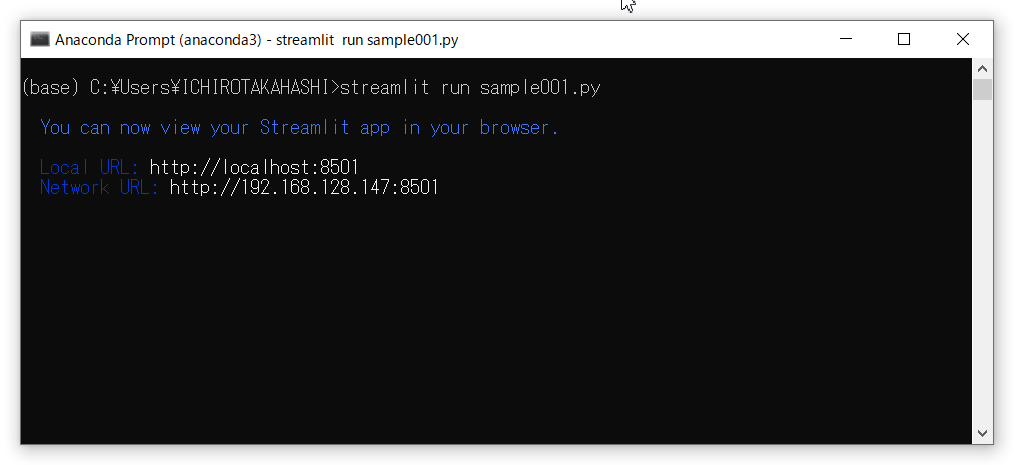
通常は、ブラウザ上にWebアプリのインターフェースが登場しますが、登場しないときには、「Local URL」をブラウザに入力してください(例では、「http://localhost:8501」となっています)。
以下、ブラウザ上に表示されたWebアプリのインターフェースです。

以後、実行結果はブラウザ上に表示されたもののみ提示します。
文書の表示(st.write)
st.writeは、色々なことに使えます。その1つが、文書の表示です。
「#」を付けることで、文字のサイズなどが変わります。「#」が1つのときは、st.titleと同じサイズです。
文書だけを表示するstreamlitアプリ例です。以下、コードです。
import streamlit as st
st.write("""
# My Web Application
## This app was created by me!
This app is a sample of the user interface.
""")
このコードは、sample002.pyという名前で保存しているものとします。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行します。
streamlit run sample002.py
以下、実行結果(ブラウザ上)です。
サブヘッダーの表示(st.subheader)
アプリのメインパネルなどは、幾つかのパートに分かれます。
例えば、あるパートにはデータセットを表示させ、あるパートにはラジオボタンを表示させ、あるパートにはグラフを表示させる、などです。
各パートのタイトル(サブヘッダー)を表示させるとき、st.subheaderを使います。
ですので、st.subheaderは単体で使うと言うよりも、他の部品(グラフ表示など)と一緒に使うことが多いです。
その部品をいくつか紹介していきます。
データフレームの表示(st.table)
入力データや出力データなどを表示させるときに、st.tableを利用します。データフレーム型のデータを表示させます。
タイタニックのデータを表示するstreamlitアプリ例です。以下、コードです。
# データの読み込み
import pandas as pd
url = 'https://www.salesanalytics.co.jp/h3lk'
train = pd.read_csv(url)
# アプリ
import streamlit as st
## タイトルなど
st.write("""
# My Web Application
## This app was created by me!
This app is a sample of the user interface.
""")
## データセット表示
st.subheader('Titanic dataset')
st.table(train.head(10))
このコードは、sample003.pyという名前で保存しているものとします。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行します。
streamlit run sample003.py
以下、実行結果(ブラウザ上)です。
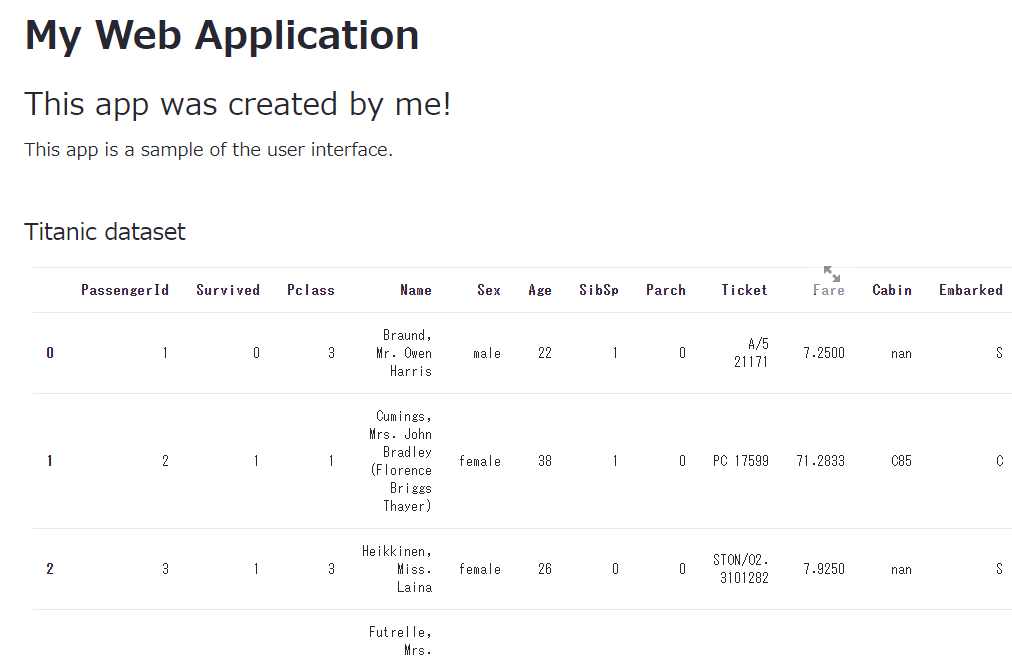
グラフ描写(st.write or st.plotly_chart)
グラフを表示させたい、と考える方も多いはずです。基本、PlotlyかAltairを使うことになります。
実は、グラフ作成ライブラリーであるAltairを使うのが簡単です。なぜならば、st.writeでグラフを描けるからです。
Altairをまだインストールされていない方は、インストールしておきましょう。
以下、コードです。
pip install altair
詳細はAltairのサイトを参照して頂ければと思います。
![]() https://altair-viz.github.io/index.html
https://altair-viz.github.io/index.html
では、棒グラフを描くstreamlitアプリ例です。以下、コードです。
# データの読み込み
import pandas as pd
url = 'https://www.salesanalytics.co.jp/h3lk'
train = pd.read_csv(url)
# グラフ
import altair as alt
fig = alt.Chart(train).mark_bar(size=60).encode(
x='Survived:O',
y='count()',
column=alt.Column('Pclass')
).properties(
width=150,
height=150
).interactive()
# アプリ
import streamlit as st
## タイトルなど
st.write("""
# My Web Application
## This app was created by me!
This app is a sample of the user interface.
""")
## グラフ表示
st.subheader('Titanic Graph')
st.write(fig)
## データセット表示
st.subheader('Titanic dataset')
st.table(train.head(10))
このコードは、sample004.pyという名前で保存しているものとします。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行します。
streamlit run sample004.py
以下、実行結果(ブラウザ上)です。
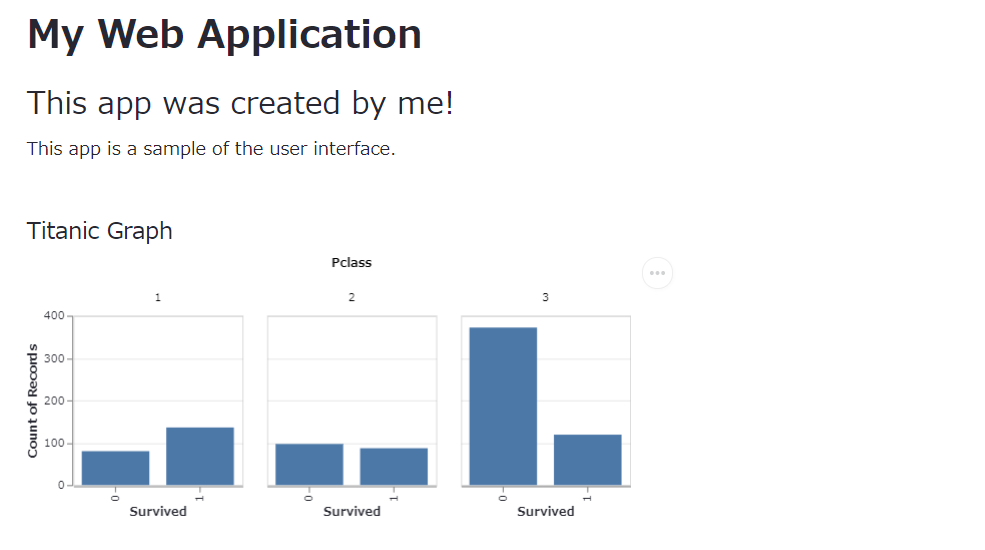
Plotlyを使ってグラフを描写するときは、st.plotly_chartを使います。
ボタンを表示させ、そのボタンをクリックしたとき何かを実行させるアプリを作ることもできます。st.buttonを使います。
ボタンをクリックしたときに、3つのグラフを表示させるstreamlitアプリ例です。以下、コードです。
# データの読み込み
import pandas as pd
url = 'https://www.salesanalytics.co.jp/h3lk'
train = pd.read_csv(url)
# グラフ
import altair as alt
## グラフ1
fig = alt.Chart(train).mark_bar(size=60).encode(
x='Survived:O',
y='count()',
column=alt.Column('Pclass')
).properties(
width=150,
height=150
).interactive()
## グラフ2
fig2 = alt.Chart(train).mark_bar(size=60).encode(
x='Survived:O',
y='mean(Age)',
column=alt.Column('Pclass')
).properties(
width=150,
height=150
).interactive()
## グラフ3
fig3 = alt.Chart(train).mark_bar(size=60).encode(
x='Survived:O',
y='mean(Fare)',
column=alt.Column('Pclass')
).properties(
width=150,
height=150
).interactive()
# アプリ
import streamlit as st
## タイトルなど
st.write("""
# My Web Application
## This app was created by me!
This app is a sample of the user interface.
""")
## グラフ表示
st.subheader('Titanic Graph')
submit = st.button('Graph Display')
if submit == True:
st.write(fig)
st.write(fig2)
st.write(fig3)
## データセット表示
st.subheader('Titanic dataset')
st.table(train.head(10))
このコードは、sample005.pyという名前で保存しているものとします。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行します。
streamlit run sample005.py
以下、実行結果(ブラウザ上)です。
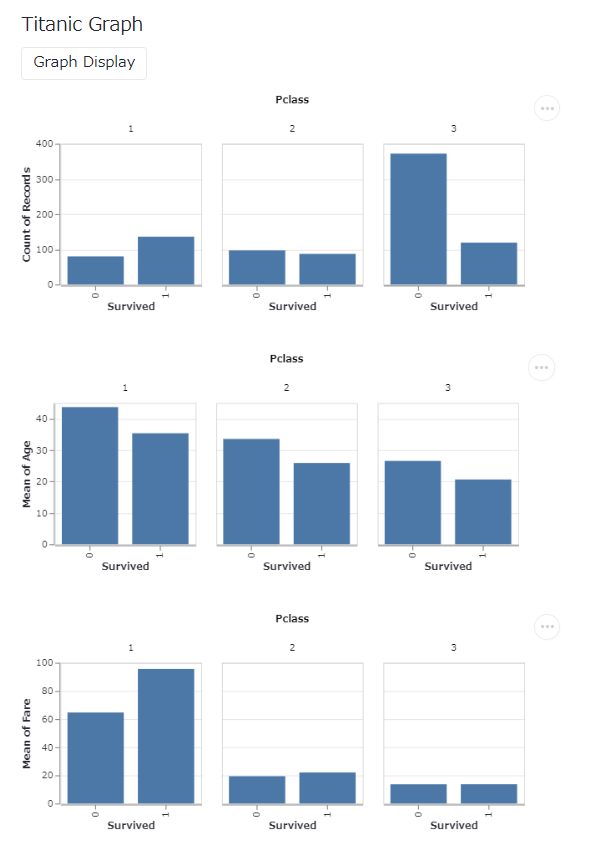
スライダーの表示(st.slider)
当然ながら、値を入力するインターフェースを作ることもできます。
連続した数値を選ぶときに便利なのが、スライダーです。st.sliderを使います。表示させたスライダーを動かして数字を動かし、特定の値を選択することができます。
ちなみに今回の例では、Scikit-Learn(sklearn)を使いますので、まだインストールされていない方はインストールして頂ければと思います。インストールされているものとして、話しを進めます。
今回は、タイタニックの生存確率を予測モデルを特徴量「Fare」のみで構築(今回は、ロジスティック回帰モデル)し、スライダーで「Fare」を入力したときの生存確率を、構築した予測モデルを使い計算し、表示させます。
- インプット部分:スライダーで「Fare」の値を入力
- 予測器部分:ロジスティック回帰モデル(Fareの値をもとに生存確率を予測する)
- アウトプット部分:テキストで「生存確率」を表示
以下、コードです。
# 基本ライブラリー
import numpy as np
import pandas as pd
# データの読み込み
url = 'https://www.salesanalytics.co.jp/h3lk'
train = pd.read_csv(url)
# 予測モデル構築
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
train_X = train[['Fare']]
train_y = train[['Survived']]
logreg.fit(train_X, train_y)
# アプリ
import streamlit as st
## タイトルなど
st.write("""
# My Web Application
## This app was created by me!
This app is a sample of the user interface.
""")
## 生存確率予測 入力→予測器→出力
st.subheader('Survival Probability')
### 入力(スライダー)
minValue = int(np.floor(train['Fare'].min()))
maxValue = int(np.ceil(train['Fare'].max()))
startValue =int((maxValue+minValue)/2)
fareVlue = st.slider('Please select fare', min_value=minValue, max_value=maxValue, step=1, value=startValue)
fareVlue_df = pd.DataFrame([fareVlue], columns=['Fare'])
### 予測器(ロジスティック回帰)
pred_probs = logreg.predict_proba(fareVlue_df)
### 出力(テキスト)
st.write('Survival Probability:',pred_probs[0,1])
このコードは、sample006.pyという名前で保存しているものとします。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行します。
streamlit run sample006.py
以下、実行結果(ブラウザ上)です。

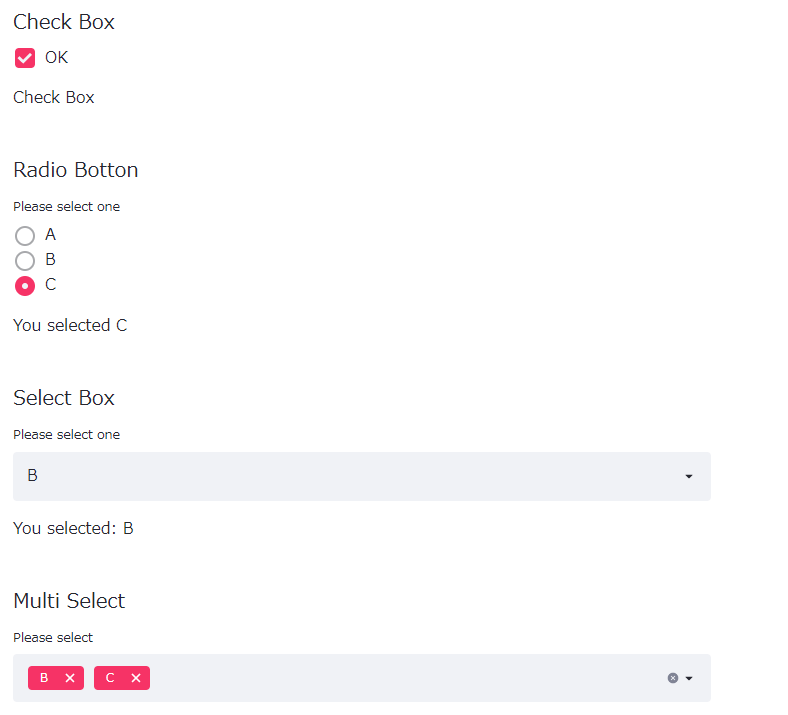
選択系(チェックボックス・ラジオボタン・ドロップダウンなど)の表示(st.write, st.radio, st.selectbox, st.multiselect)
インプット部品は、他にも色々あります。
例えば……
- チェックボックス
- ラジオボタン
- ドロップダウン(セレクトボックス)
- マルチセレクト(複数選択)
……などです。
色々なインプット部品を表示するだけのstreamlitアプリ例です。以下、コードです。
# アプリ
import streamlit as st
## チェックボックス
st.subheader('Check Box')
agree = st.checkbox('OK')
if agree == True :
st.write('Check Box')
## ラジオボタン
st.subheader('Radio Botton')
ABC = st.radio(
'Please select one',
('A', 'B', 'C'))
st.write('You selected ',ABC)
## ドロップダウン(セレクトボックス)
st.subheader('Select Box')
ABC2 = st.selectbox(
'Please select one',
('A', 'B', 'C'))
st.write('You selected:', ABC2)
## マルチセレクト
st.subheader('Multi Select')
ABC3 = st.multiselect(
'Please select',
['A', 'B', 'C'],
[])
このコードは、sample007.pyという名前で保存しているものとします。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行します。
streamlit run sample007.py
以下、実行結果(ブラウザ上)です。
先ほど、タイタニックの生存確率を予測モデルを特徴量「Fare」のみで構築(今回は、ロジスティック回帰モデル)し、スライダーで「Fare」を選択したときの生存確率を予測するアプリを作りました。
1つのパネル(メインパネル)に、インプット部分とアウトプット部分が混在している状態です。
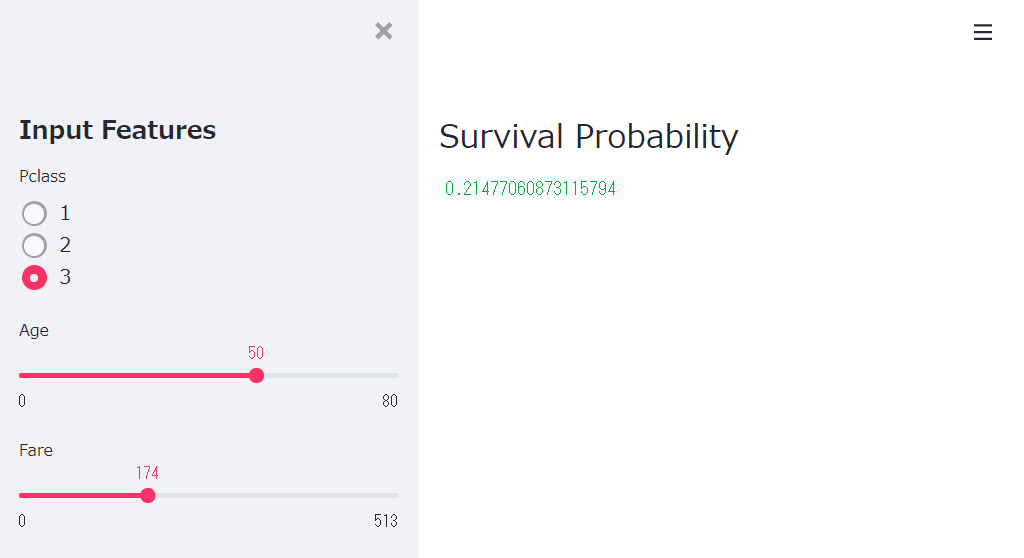
そこで、インプットする特徴量の幾つかを選択する部分をサイドパネルに表示し、予測結果をメインパネルに表示させるstreamlitアプリを作ってみたいと思います。
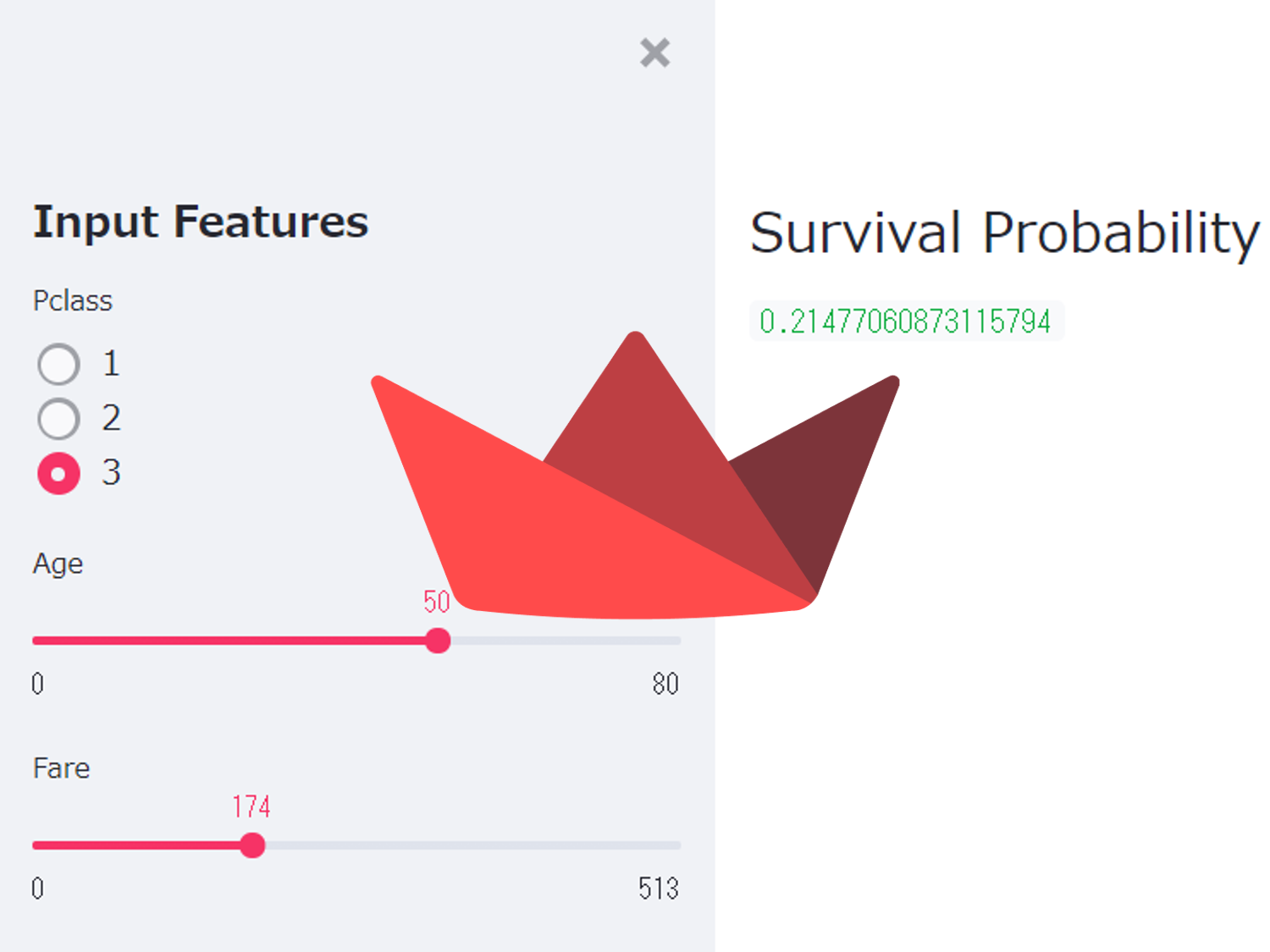
- サイドパネル(インプット部分):「Pclass」「Age」「Fare」の値を入力
- 予測器部分:ロジスティック回帰モデル(Fareの値をもとに生存確率を予測する)
- メインパネル(アウトプット部分):テキストで「生存確率」を表示
以下、コードです。
# 基本ライブラリー
import numpy as np
import pandas as pd
# データセット
## データの読み込み
url = 'https://www.salesanalytics.co.jp/h3lk'
train = pd.read_csv(url)
## 欠測値補完
from sklearn.impute import SimpleImputer
mean_imputer = SimpleImputer(strategy='mean')
train[['Age']] = mean_imputer.fit_transform(train[['Age']])
# 予測モデル構築
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
train_X = train[['Pclass','Age','Fare']]
train_y = train[['Survived']]
logreg.fit(train_X, train_y)
# アプリ
import streamlit as st
## サイドパネル(インプット部)
st.sidebar.header('Input Features')
### Pclass入力(ラジオボタン)
pclassValue = st.sidebar.radio('Pclass',(1, 2, 3))
### Age入力(スライドバー)
minValue_age = int(np.floor(train['Age'].min()))
maxValue_age = int(np.ceil(train['Age'].max()))
startValue_age =int((maxValue_age+minValue_age)/2)
ageValue = st.sidebar.slider('Age', min_value=minValue_age, max_value=maxValue_age, step=1, value=startValue_age)
### Fare入力(スライドバー)
minValue = int(np.floor(train['Fare'].min()))
maxValue = int(np.ceil(train['Fare'].max()))
startValue =int((maxValue+minValue)/2)
fareValue = st.sidebar.slider('Fare', min_value=minValue, max_value=maxValue, step=1, value=startValue)
## メインパネル(アウトプット部)
st.write("""
## Survival Probability
""")
### インプットデータ(1行のデータフレーム生成)
value_df = pd.DataFrame([],columns=['Pclass', 'Age','Fare'])
record = pd.Series([pclassValue, ageValue, fareValue], index=value_df.columns)
value_df = value_df.append(record, ignore_index=True)
### 予測
pred_probs = logreg.predict_proba(value_df)
### 結果出力
st.write(pred_probs[0,1])
このコードは、sample008.pyという名前で保存しているものとします。
ターミナル(Anaconda Prompt や PowerShell など)に以下を入力し実行します。
streamlit run sample008.py
以下、実行結果(ブラウザ上)です。
サンプルデータとサンプルコード
今回利用するサンプルデータとサンプルコードは、以下からダウンロードできます。
サンプルデータは、タイタニックのデータです。サンプルコードから直接上記のURL経由で読み込むようにコードを記載しています。
まとめ
今回は「さくっと機械学習のWebアプリを作りたくなったらPythonのstreamlitがとっても手軽だよ」というお話しをしました。
興味ある方は、Pythonのstreamlitでお手軽Webアプリを作ってみてください。