
機械学習は現代社会において多くの分野で利用されています。
しかし、モデルの設定やハイパーパラメータの調整など、そのプロセスは非常に煩雑であり、多くの時間と専門知識が要求されます。そこで登場するのが「自動機械学習(AutoML)」です。
この記事では、AutoMLの中でも比較的人気のあるライブラリであるAuto-Sklearnを使って、誰でも簡単に機械学習モデルを構築できる方法を解説します。
基本的な使い方から応用例まで、Pythonの実行例付きでご紹介。機械学習に新しい風を吹き込むAuto-Sklearnで、あなたもデータ解析のプロになりましょう!
はじめに
なぜ自動機械学習(Auto ML)が必要なのか?
機械学習は今や多くの業界で応用されています。医療から金融、製造業まで、データを解析して有用な情報を引き出す力は計り知れません。
しかし、その一方で、機械学習モデルを設計、訓練、テストする過程は非常に時間がかかるばかりか、多くの専門知識が必要です。
- モデル選定: どのアルゴリズムを使用するか?
- 特徴量エンジニアリング: どの特徴量が重要か?
- ハイパーパラメータ調整: アルゴリズムの設定値はどうするか?
- 評価: モデルは正確なのか?
これらの問題に答えるには、一般には大量の時間と労力が必要です。
自動機械学習(AutoML)は、これらの課題に対する解決策を提供します。AutoMLは、データを入力として受け取り、最適な機械学習モデルを自動で設計してくれます。
これにより、非専門家でも短時間で高品質な機械学習モデルを構築できるようになります。
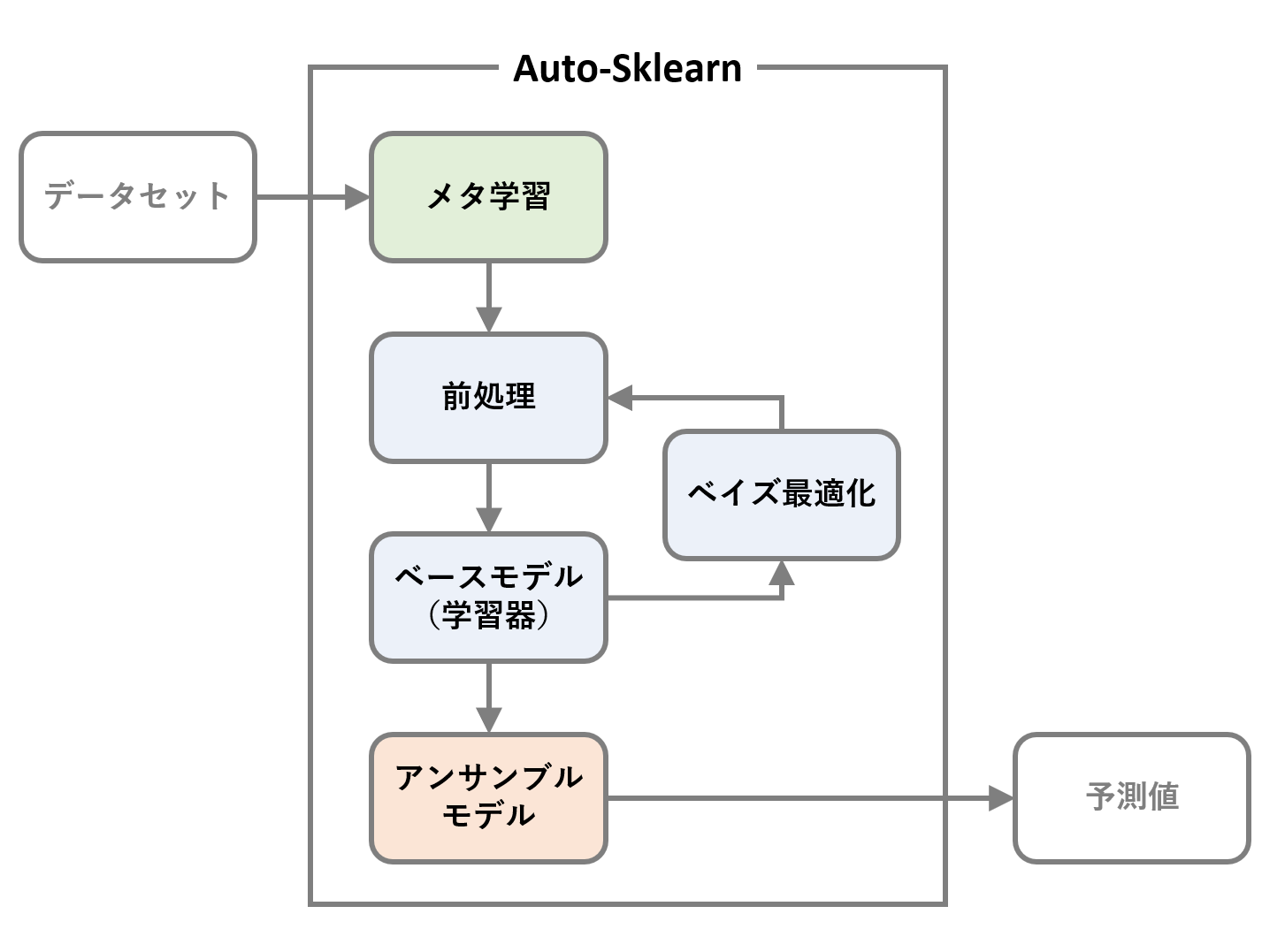
Auto-Sklearnとは何か
Auto-Sklearnは、自動機械学習(AutoML)の一つの実装であり、Pythonの機械学習ライブラリであるScikit-learnを基にしています。
Auto-Sklearn
https://github.com/automl/auto-sklearn
Scikit-learnは非常に高機能でありますが、その全ての機能を使いこなすには高度な知識が求められます。
Auto-Sklearnは、Scikit-learnの豊富な機能を活かしながら、最適なモデルの選定、ハイパーパラメータの調整、評価までを自動化します。
簡単に言えば、Auto-SklearnはScikit-learnの「自動運転版」です。データを与えるだけで、最適な機械学習モデルを短時間で見つけ出してくれます。
では、どういうロジックで自動化しているのでしょうか?
以下、Auto-Sklearnのロジックの記載されている論文です。
Efficient and Robust Automated Machine Learning
http://papers.nips.cc/paper/5872-efficient-and-robust-automated-machine-learning.pdf
他のAutoMLツールと比べたとき、その大きなポイントは次の2つです。
- メタ学習(Meta Learning)
- ベイズ最適化(Bayesian Optimizer)

環境設定
Auto-Sklearnを使用するための環境設定について説明します。
Auto-Sklearnを動かす上での環境の条件
今現在(2023年9月5日現在)のAuto-Sklearnは多くの依存関係といくつかのシステム要件があります。
以下はその主要な点です。
- Pythonバージョン: Auto-SklearnはPython 3.6以上で動作します。
- オペレーティングシステム: Linux環境での使用が推奨されています。WindowsやmacOSでは、特定の設定や追加のソフトウェア(たとえばDockerやWindows Subsystem for Linux)が必要になる場合があります。
- 依存ライブラリ: Auto-SklearnはScikit-learnに依存しており、その他にもNumPy, SciPyなどのライブラリが必要です。通常は
pip install auto-sklearnを実行すると、これらの依存ライブラリも自動でインストールされます。 - 計算リソース: Auto-Sklearnは様々なモデルとハイパーパラメータを自動で試すため、比較的高い計算リソース(CPU, メモリ)が必要になる場合があります。
Auto-Sklearnは、Linux上で基本使うものです。
Windows上で使いたい方は、以下の記事を参考にWindows上にLinux環境を構築し実施て頂ければと思います。
必要なライブラリのインストール
Auto-Sklearnをインストールするには、以下のコマンドを実行します。
pip install auto-sklearn
また、Auto-SklearnはScikit-learnに依存していますので、Scikit-learnもインストールされている必要があります。
まだインストールしていない場合は、以下のコマンドでインストールできます。
pip install scikit-learn
Auto-Sklearnの基本的な使い方
Auto-Sklearnの基本的な使い方について解説します。
具体的には、データの読み込み、モデルの設定、訓練、そして予測と評価の各ステップを説明します。
サンプルデータセットの準備
Auto-Sklearnの基本的な使い方を説明するために、Scikit-learnに付属のサンプルデータセットを使用します。
今回は、irisデータセットを使い、花の種類を分類する機械学習モデルを作成します。

「セトサ種」「バージニカ種」「バージカラー種」の3品種に関するデータです。
- Sepal Length: がく片の長さ
- Sepal Width: がく片の幅
- Petal Length: 花びらの長さ
- Petal Width: 花びらの幅
- Species: アヤメの種類(セトサ種・バージニカ種・バージカラー種)
Speciesが目的変数Yです。
アヤメの種類(Species)を他の変数で予測する問題(アヤメの種類を分類する問題)になります。
以下のPythonコードでirisデータセットを読み込み、データを表示してみましょう。
以下、コードです。
from sklearn.datasets import load_iris import pandas as pd # irisデータセットの読み込み iris = load_iris() # データフレームに変換 df = pd.DataFrame(iris.data, columns=iris.feature_names) df['target'] = iris.target # データの先頭5行を表示 print(df.head())
以下、実行結果です。
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \ 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 target 0 0 1 0 2 0 3 0 4 0
モデルの設定
Auto-Sklearnを使用するには、分類問題の場合はAutoSklearnClassifier、回帰問題の場合はAutoSklearnRegressorを使用します。
以下は、分類問題に対する基本的な設定の例です。
以下、コードです。
from autosklearn.classification import AutoSklearnClassifier
# モデルのインスタンスを作成
automl = AutoSklearnClassifier(
time_left_for_this_task=120, # 最大実行時間(秒)
per_run_time_limit=30) # 各モデルの最大実行時間(秒)
モデルの訓練
次に、fitメソッドを使用してモデルを訓練します。このメソッドには訓練データ(特徴量とラベル)を引数として渡します。
以下、コードです。
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split # irisデータセットの読み込み iris = load_iris() X = iris.data y = iris.target # 訓練データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) # モデルの訓練 automl.fit(X_train, y_train)
以下、実行結果です。
AutoSklearnClassifier(
ensemble_class=<class 'autosklearn.ensembles.ensemble_selection.EnsembleSelection'>,
per_run_time_limit=30,
time_left_for_this_task=120)
予測と評価
モデルの訓練が完了したら、predictメソッドを使用して新しいデータに対する予測を行います。そして、Scikit-learnの評価関数を用いてモデルの性能を評価します。
以下、コードです。
from sklearn.metrics import accuracy_score
# テストデータに対する予測
y_pred = automl.predict(X_test)
# 精度の計算
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
以下、実行結果です。
Accuracy: 1.00
以上がAuto-Sklearnの基本的な使い方です。これだけで、短時間で優れた性能を持つ機械学習モデルを構築できます。
データ前処理との連携
機械学習モデルの性能は、使用するデータの質に大きく依存します。そのため、データの前処理は非常に重要なステップです。
Auto-Sklearnとデータ前処理をどのように連携させるかを説明します。
SklearnのPipelineとの組み合わせ
Auto-SklearnはScikit-learnと高度に互換性があるため、Scikit-learnのPipelineオブジェクトと簡単に組み合わせることができます。これにより、前処理とモデル訓練を一連の流れとして定義できます。
例として、データの標準化と分類器の設定を一つのパイプラインにまとめます。
以下、コードです。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from autosklearn.classification import AutoSklearnClassifier
# パイプラインの定義
pipeline = Pipeline([
('scaler', StandardScaler()), # 標準化
('classifier', AutoSklearnClassifier(time_left_for_this_task=120)) # 分類器
])
# パイプラインを用いて訓練
pipeline.fit(X_train, y_train)
# 評価
y_pred = pipeline.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
以下、実行結果です。
Accuracy: 1.00
カスタム前処理の適用
Auto-Sklearnに組み込まれていない独自の前処理手法を使用する場合も、Scikit-learnのFunctionTransformerや独自のTransformerクラスを作成することで容易に組み合わせられます。
例として、独自の前処理関数をPipelineに組み込む方法を示します。
以下、コードです。
from sklearn.preprocessing import FunctionTransformer
# カスタム前処理関数(例:すべての値を2倍にする)
def custom_preprocessing(X):
return X * 2
# FunctionTransformerを用いてカスタム前処理をPipelineに組み込む
pipeline = Pipeline([
('custom_transformer', FunctionTransformer(func=custom_preprocessing)),
('classifier', AutoSklearnClassifier(time_left_for_this_task=120))
])
# パイプラインを用いて訓練
pipeline.fit(X_train, y_train)
# 評価
y_pred = pipeline.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
以下、実行結果です。
Accuracy: 1.00
以上がデータ前処理とAuto-Sklearnとの連携方法です。このようにして、データ前処理とモデル訓練を効率的に一つの流れで行うことができます。
ハイパーパラメータの調整
Auto-Sklearnは自動でハイパーパラメータの調整を行いますが、ユーザーが手動でいくつかの設定を行うことも可能です。
タイムリミットの設定
Auto-Sklearnでは、time_left_for_this_taskとper_run_time_limitという二つの時間に関するパラメータがあります。
time_left_for_this_task: Auto-Sklearnが全体として使用できる時間(秒)です。この時間が過ぎると、Auto-Sklearnは現在最良のモデルを出力します。per_run_time_limit: 各モデルの訓練に許される最大時間(秒)です。
以下、設定例です。
# タイムリミットの設定例
automl = AutoSklearnClassifier(
time_left_for_this_task=300, # 5分
per_run_time_limit=50 # 50秒
)
メトリクスの選定
Auto-Sklearnは多くの評価メトリクスをサポートしています。metricパラメータを用いて、どのメトリクスでモデルを評価するかを指定できます。
例えば、分類問題でF1スコアをメトリクスとして使用する場合は以下のように設定します。
from autosklearn.metrics import f1
# メトリクスの設定例
automl = AutoSklearnClassifier(
metric=f1,
time_left_for_this_task=300
)
アンサンブル学習の設定
アンサンブル学習は、複数の学習モデルを組み合わせて一つの強力なモデルを作成する手法です。
アンサンブル学習には以下のようなメリットがあります。
- 精度の向上: 複数のモデルが協力することで、単一のモデルよりも高い精度を達成できる場合があります。
- 過学習の緩和: 複数のモデルを組み合わせることで、過学習(Overfitting)のリスクを減らすことが可能です。
- 堅牢性: 単一のモデルが特定のデータに弱い場合でも、他のモデルがその弱点を補ってくれる可能性があります。
Auto-Sklearnはデフォルトでアンサンブル学習を行います。特に設定を変更しなければ、最終的に生成されるモデルは複数の個別のモデルを組み合わせたアンサンブルモデルになります。
アンサンブル学習を無効にするには、ensemble_sizeパラメータを0に設定します。
# アンサンブル学習を無効にする例
automl = AutoSklearnClassifier(
ensemble_size=0,
time_left_for_this_task=300
)
逆に、アンサンブルのサイズを大きくして多くのモデルを組み合わせることも可能です。
# アンサンブルのサイズを大きくする例
automl = AutoSklearnClassifier(
ensemble_size=50,
time_left_for_this_task=300
)
ちなみに、アンサンブルサイズ (ensemble_size)のデフォルトは50です。
アンサンブル学習を利用することで、より精度の高い、堅牢なモデルを短時間で作成することが可能となります。
Auto-Sklearnではこの強力な手法がデフォルトで容易に利用できるため、高度な機械学習モデルの構築がより手軽になります。
Auto-Sklearnのアンサンブル学習のベースモデルは、設定されたタイムリミットとリソース制限内で、Auto-Sklearnによって自動的に選択と訓練が行われます。
具体的には、Auto-Sklearnが内部で以下のようなプロセスを経てモデルを作成します。
- アルゴリズム選択: サポートベクターマシン、ランダムフォレスト、勾配ブースティングなど、さまざまな機械学習アルゴリズムから選択されます。
- ハイパーパラメータ調整: 各アルゴリズムには多くのハイパーパラメータがあり、これを調整することでモデルの性能が変わります。Auto-Sklearnは、選択されたアルゴリズムに対して自動的にハイパーパラメータ調整を行います。
- モデル評価: 作成された各モデルは、交差検証などの手法で評価されます。
このプロセスを繰り返し、生成された多数のベースモデルから、性能が良いものが選択されてアンサンブルが形成されます。そして、このアンサンブルモデルが最終的に出力されるモデルとなります。
アンサンブルに含まれるベースモデルの予測結果は通常、次のように統合されて最終的な予測結果が生成されます。
- 分類問題:確率の加重平均:(ベースモデルが出力するクラス所属確率に対して重みを付けて平均し、最も確率が高いクラスを最終的な予測とする)
- 回帰問題:加重平均:(ベースモデルの予測値に対して重みを付けて平均をとり最終的な予測とする)
各ベースモデルに割り当てられる重みは、交差検証による性能評価に基づいて自動的に決定されます。性能が高いモデルには大きな重みが割り当てられ、性能が低いモデルには小さな重みが割り当てられることが一般的です。
このような加重平均または加重多数決の方法により、Auto-Sklearnはアンサンブル内の各モデルが持つ強みと弱みを補完し合い、全体としてより堅牢で高性能な予測モデルを生成します。
メタ学習の設定
initial_configurations_via_metalearningとは、Auto-Sklearnのメタ学習(Meta-Learning)機能を制御するためのパラメータです。
メタ学習とは、過去に解いた類似の問題(またはデータセット)から学び、新しい問題に対する初期モデルの設定(ハイパーパラメータ等)を効率的に選択する手法を指します。
具体的には、Auto-Sklearnは、公開されている多数のデータセットとそれらに対する最適なモデル設定の履歴を持っています。
新しいデータセットが与えられたとき、この履歴を用いてそのデータセットがどの既存のデータセットに似ているかを評価します。そして、最も類似したデータセットに対して良い性能を示したモデル設定を、新しいデータセットに対する初期設定として使用します。
このinitial_configurations_via_metalearningパラメータは、どれくらいの数のメタ学習による初期設定を用いるかを制御します。デフォルトは25で、最初の25個のモデル設定がメタ学習によって選ばれます。
その後、通常のハイパーパラメータ最適化が続きます。
この機能は特に、データセットが大きいまたは複雑で、ハイパーパラメータの最適化に時間がかかるような場合に有用です。メタ学習によって良い初期値が選ばれることで、全体の最適化プロセスが高速化される可能性があります。
例えば、最初の10個のモデル設定だけをメタ学習で選ぶように設定する場合は以下のようにします。
automl = AutoSklearnClassifier(initial_configurations_via_metalearning=10)
このように、initial_configurations_via_metalearningパラメータを調整することで、メタ学習の影響度を制御できます。
最終的なアンサンブルモデルの調べ方
Auto-Sklearnで生成された最終的なアンサンブルモデルの詳細を調べるためには、get_models_with_weightsメソッドを使用します。このメソッドは、アンサンブルに含まれる各モデル(ベースモデル)とそれらのモデルに割り当てられた重みのリストを返します。
先ほど構築したモデルで見てみましょう。
以下、コードです。
# Auto-Sklearnのインポートと設定
from autosklearn.classification import AutoSklearnClassifier
# モデルのインスタンス生成と訓練
automl = AutoSklearnClassifier(time_left_for_this_task=120)
automl.fit(X_train, y_train)
# アンサンブルに含まれるモデルとその重みを取得
ensemble_models_with_weights = automl.get_models_with_weights()
# モデルと重みの詳細を出力
for weight, model in ensemble_models_with_weights:
print(f"Weight: {weight}")
print(f"Model: {model}")
以下、実行結果です。
Weight: 0.08
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'extra_trees_preproc_for_classification', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'entropy', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.5, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 1, 'classifier:random_forest:min_samples_split': 2, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none', 'feature_preprocessor:extra_trees_preproc_for_classification:bootstrap': 'False', 'feature_preprocessor:extra_trees_preproc_for_classification:criterion': 'gini', 'feature_preprocessor:extra_trees_preproc_for_classification:max_depth': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:max_features': 0.5, 'feature_preprocessor:extra_trees_preproc_for_classification:max_leaf_nodes': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:min_impurity_decrease': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_leaf': 1, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_split': 2, 'feature_preprocessor:extra_trees_preproc_for_classification:min_weight_fraction_leaf': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:n_estimators': 100},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.06
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'polynomial', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'entropy', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.9361600425014094, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 3, 'classifier:random_forest:min_samples_split': 12, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'quantile_transformer', 'feature_preprocessor:polynomial:degree': 2, 'feature_preprocessor:polynomial:include_bias': 'True', 'feature_preprocessor:polynomial:interaction_only': 'True', 'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:n_quantiles': 1573, 'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:output_distribution': 'normal'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.06
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'extra_trees', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'liblinear_svc_preprocessor', 'classifier:extra_trees:bootstrap': 'False', 'classifier:extra_trees:criterion': 'entropy', 'classifier:extra_trees:max_depth': 'None', 'classifier:extra_trees:max_features': 0.8453098888839191, 'classifier:extra_trees:max_leaf_nodes': 'None', 'classifier:extra_trees:min_impurity_decrease': 0.0, 'classifier:extra_trees:min_samples_leaf': 20, 'classifier:extra_trees:min_samples_split': 6, 'classifier:extra_trees:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:liblinear_svc_preprocessor:C': 1874.3310336717195, 'feature_preprocessor:liblinear_svc_preprocessor:dual': 'False', 'feature_preprocessor:liblinear_svc_preprocessor:fit_intercept': 'True', 'feature_preprocessor:liblinear_svc_preprocessor:intercept_scaling': 1, 'feature_preprocessor:liblinear_svc_preprocessor:loss': 'squared_hinge', 'feature_preprocessor:liblinear_svc_preprocessor:multi_class': 'ovr', 'feature_preprocessor:liblinear_svc_preprocessor:penalty': 'l1', 'feature_preprocessor:liblinear_svc_preprocessor:tol': 0.00042204158027066014},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.06
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'passive_aggressive', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'select_rates_classification', 'classifier:passive_aggressive:C': 4.162410073979079, 'classifier:passive_aggressive:average': 'True', 'classifier:passive_aggressive:fit_intercept': 'True', 'classifier:passive_aggressive:loss': 'hinge', 'classifier:passive_aggressive:tol': 3.683719041236911e-05, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'quantile_transformer', 'feature_preprocessor:select_rates_classification:alpha': 0.21192404605501053, 'feature_preprocessor:select_rates_classification:score_func': 'mutual_info_classif', 'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:n_quantiles': 990, 'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:output_distribution': 'normal'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.04
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'liblinear_svc_preprocessor', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'gini', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.7258011125423461, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 1, 'classifier:random_forest:min_samples_split': 6, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize', 'feature_preprocessor:liblinear_svc_preprocessor:C': 2.0628492459123464, 'feature_preprocessor:liblinear_svc_preprocessor:dual': 'False', 'feature_preprocessor:liblinear_svc_preprocessor:fit_intercept': 'True', 'feature_preprocessor:liblinear_svc_preprocessor:intercept_scaling': 1, 'feature_preprocessor:liblinear_svc_preprocessor:loss': 'squared_hinge', 'feature_preprocessor:liblinear_svc_preprocessor:multi_class': 'ovr', 'feature_preprocessor:liblinear_svc_preprocessor:penalty': 'l1', 'feature_preprocessor:liblinear_svc_preprocessor:tol': 0.00025450378106637233},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.04
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'libsvm_svc', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'feature_agglomeration', 'classifier:libsvm_svc:C': 1198.7850746967626, 'classifier:libsvm_svc:gamma': 0.015219182148092949, 'classifier:libsvm_svc:kernel': 'rbf', 'classifier:libsvm_svc:max_iter': -1, 'classifier:libsvm_svc:shrinking': 'True', 'classifier:libsvm_svc:tol': 0.040610448809956276, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize', 'feature_preprocessor:feature_agglomeration:affinity': 'cosine', 'feature_preprocessor:feature_agglomeration:linkage': 'average', 'feature_preprocessor:feature_agglomeration:n_clusters': 242, 'feature_preprocessor:feature_agglomeration:pooling_func': 'median'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.04
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'mlp', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'feature_agglomeration', 'classifier:mlp:activation': 'tanh', 'classifier:mlp:alpha': 0.00021148999718383549, 'classifier:mlp:batch_size': 'auto', 'classifier:mlp:beta_1': 0.9, 'classifier:mlp:beta_2': 0.999, 'classifier:mlp:early_stopping': 'train', 'classifier:mlp:epsilon': 1e-08, 'classifier:mlp:hidden_layer_depth': 3, 'classifier:mlp:learning_rate_init': 0.0007452270241186694, 'classifier:mlp:n_iter_no_change': 32, 'classifier:mlp:num_nodes_per_layer': 113, 'classifier:mlp:shuffle': 'True', 'classifier:mlp:solver': 'adam', 'classifier:mlp:tol': 0.0001, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize', 'feature_preprocessor:feature_agglomeration:affinity': 'euclidean', 'feature_preprocessor:feature_agglomeration:linkage': 'complete', 'feature_preprocessor:feature_agglomeration:n_clusters': 247, 'feature_preprocessor:feature_agglomeration:pooling_func': 'max'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.04
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'extra_trees', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'polynomial', 'classifier:extra_trees:bootstrap': 'False', 'classifier:extra_trees:criterion': 'gini', 'classifier:extra_trees:max_depth': 'None', 'classifier:extra_trees:max_features': 0.5707983257382487, 'classifier:extra_trees:max_leaf_nodes': 'None', 'classifier:extra_trees:min_impurity_decrease': 0.0, 'classifier:extra_trees:min_samples_leaf': 3, 'classifier:extra_trees:min_samples_split': 11, 'classifier:extra_trees:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none', 'feature_preprocessor:polynomial:degree': 2, 'feature_preprocessor:polynomial:include_bias': 'False', 'feature_preprocessor:polynomial:interaction_only': 'False'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.04
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'pca', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'gini', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.5254151103835996, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 3, 'classifier:random_forest:min_samples_split': 14, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:pca:keep_variance': 0.540254991707572, 'feature_preprocessor:pca:whiten': 'False'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.04
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'polynomial', 'classifier:random_forest:bootstrap': 'False', 'classifier:random_forest:criterion': 'gini', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.6373517500329606, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 12, 'classifier:random_forest:min_samples_split': 5, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler', 'feature_preprocessor:polynomial:degree': 3, 'feature_preprocessor:polynomial:include_bias': 'True', 'feature_preprocessor:polynomial:interaction_only': 'False', 'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7454410611762495, 'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.06210514652608169},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.04
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'libsvm_svc', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'select_percentile_classification', 'classifier:libsvm_svc:C': 5421.257977429908, 'classifier:libsvm_svc:gamma': 0.2750770199055177, 'classifier:libsvm_svc:kernel': 'rbf', 'classifier:libsvm_svc:max_iter': -1, 'classifier:libsvm_svc:shrinking': 'True', 'classifier:libsvm_svc:tol': 0.0003395078154890969, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'normalize', 'feature_preprocessor:select_percentile_classification:percentile': 58.93045992720484, 'feature_preprocessor:select_percentile_classification:score_func': 'f_classif'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.04
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'extra_trees_preproc_for_classification', 'classifier:random_forest:bootstrap': 'False', 'classifier:random_forest:criterion': 'entropy', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.23485585688158775, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 1, 'classifier:random_forest:min_samples_split': 12, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize', 'feature_preprocessor:extra_trees_preproc_for_classification:bootstrap': 'True', 'feature_preprocessor:extra_trees_preproc_for_classification:criterion': 'gini', 'feature_preprocessor:extra_trees_preproc_for_classification:max_depth': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:max_features': 0.8158572542469601, 'feature_preprocessor:extra_trees_preproc_for_classification:max_leaf_nodes': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:min_impurity_decrease': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_leaf': 1, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_split': 7, 'feature_preprocessor:extra_trees_preproc_for_classification:min_weight_fraction_leaf': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:n_estimators': 100},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'no_preprocessing', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'gini', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.5, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 1, 'classifier:random_forest:min_samples_split': 2, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'random_trees_embedding', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'entropy', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.5, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 1, 'classifier:random_forest:min_samples_split': 2, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'quantile_transformer', 'feature_preprocessor:random_trees_embedding:bootstrap': 'True', 'feature_preprocessor:random_trees_embedding:max_depth': 5, 'feature_preprocessor:random_trees_embedding:max_leaf_nodes': 'None', 'feature_preprocessor:random_trees_embedding:min_samples_leaf': 1, 'feature_preprocessor:random_trees_embedding:min_samples_split': 2, 'feature_preprocessor:random_trees_embedding:min_weight_fraction_leaf': 1.0, 'feature_preprocessor:random_trees_embedding:n_estimators': 10, 'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:n_quantiles': 937, 'data_preprocessor:feature_type:numerical_transformer:rescaling:quantile_transformer:output_distribution': 'uniform'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'mlp', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'fast_ica', 'classifier:mlp:activation': 'relu', 'classifier:mlp:alpha': 0.02847755502162456, 'classifier:mlp:batch_size': 'auto', 'classifier:mlp:beta_1': 0.9, 'classifier:mlp:beta_2': 0.999, 'classifier:mlp:early_stopping': 'train', 'classifier:mlp:epsilon': 1e-08, 'classifier:mlp:hidden_layer_depth': 2, 'classifier:mlp:learning_rate_init': 0.000421568792103947, 'classifier:mlp:n_iter_no_change': 32, 'classifier:mlp:num_nodes_per_layer': 123, 'classifier:mlp:shuffle': 'True', 'classifier:mlp:solver': 'adam', 'classifier:mlp:tol': 0.0001, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:fast_ica:algorithm': 'parallel', 'feature_preprocessor:fast_ica:fun': 'exp', 'feature_preprocessor:fast_ica:whiten': 'False'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'adaboost', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'extra_trees_preproc_for_classification', 'classifier:adaboost:algorithm': 'SAMME.R', 'classifier:adaboost:learning_rate': 0.046269426995092074, 'classifier:adaboost:max_depth': 3, 'classifier:adaboost:n_estimators': 406, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler', 'feature_preprocessor:extra_trees_preproc_for_classification:bootstrap': 'False', 'feature_preprocessor:extra_trees_preproc_for_classification:criterion': 'entropy', 'feature_preprocessor:extra_trees_preproc_for_classification:max_depth': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:max_features': 0.40839846168190147, 'feature_preprocessor:extra_trees_preproc_for_classification:max_leaf_nodes': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:min_impurity_decrease': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_leaf': 4, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_split': 7, 'feature_preprocessor:extra_trees_preproc_for_classification:min_weight_fraction_leaf': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:n_estimators': 100, 'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7697572103377026, 'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.280953821785477},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'gradient_boosting', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'liblinear_svc_preprocessor', 'classifier:gradient_boosting:early_stop': 'train', 'classifier:gradient_boosting:l2_regularization': 0.005326508887463406, 'classifier:gradient_boosting:learning_rate': 0.060800813211425456, 'classifier:gradient_boosting:loss': 'auto', 'classifier:gradient_boosting:max_bins': 255, 'classifier:gradient_boosting:max_depth': 'None', 'classifier:gradient_boosting:max_leaf_nodes': 6, 'classifier:gradient_boosting:min_samples_leaf': 5, 'classifier:gradient_boosting:scoring': 'loss', 'classifier:gradient_boosting:tol': 1e-07, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:liblinear_svc_preprocessor:C': 13.550960330919455, 'feature_preprocessor:liblinear_svc_preprocessor:dual': 'False', 'feature_preprocessor:liblinear_svc_preprocessor:fit_intercept': 'True', 'feature_preprocessor:liblinear_svc_preprocessor:intercept_scaling': 1, 'feature_preprocessor:liblinear_svc_preprocessor:loss': 'squared_hinge', 'feature_preprocessor:liblinear_svc_preprocessor:multi_class': 'ovr', 'feature_preprocessor:liblinear_svc_preprocessor:penalty': 'l1', 'feature_preprocessor:liblinear_svc_preprocessor:tol': 1.2958033930435781e-05, 'classifier:gradient_boosting:n_iter_no_change': 5},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'extra_trees', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'polynomial', 'classifier:extra_trees:bootstrap': 'False', 'classifier:extra_trees:criterion': 'entropy', 'classifier:extra_trees:max_depth': 'None', 'classifier:extra_trees:max_features': 0.993803313878608, 'classifier:extra_trees:max_leaf_nodes': 'None', 'classifier:extra_trees:min_impurity_decrease': 0.0, 'classifier:extra_trees:min_samples_leaf': 2, 'classifier:extra_trees:min_samples_split': 20, 'classifier:extra_trees:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler', 'feature_preprocessor:polynomial:degree': 2, 'feature_preprocessor:polynomial:include_bias': 'True', 'feature_preprocessor:polynomial:interaction_only': 'True', 'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7305615609807856, 'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.25595970768123566},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'mlp', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'feature_agglomeration', 'classifier:mlp:activation': 'relu', 'classifier:mlp:alpha': 4.2841884333778574e-06, 'classifier:mlp:batch_size': 'auto', 'classifier:mlp:beta_1': 0.9, 'classifier:mlp:beta_2': 0.999, 'classifier:mlp:early_stopping': 'train', 'classifier:mlp:epsilon': 1e-08, 'classifier:mlp:hidden_layer_depth': 3, 'classifier:mlp:learning_rate_init': 0.0011804284312897009, 'classifier:mlp:n_iter_no_change': 32, 'classifier:mlp:num_nodes_per_layer': 263, 'classifier:mlp:shuffle': 'True', 'classifier:mlp:solver': 'adam', 'classifier:mlp:tol': 0.0001, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:feature_agglomeration:affinity': 'manhattan', 'feature_preprocessor:feature_agglomeration:linkage': 'average', 'feature_preprocessor:feature_agglomeration:n_clusters': 338, 'feature_preprocessor:feature_agglomeration:pooling_func': 'mean'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'feature_agglomeration', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'gini', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.6951498365440666, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 8, 'classifier:random_forest:min_samples_split': 20, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:feature_agglomeration:affinity': 'cosine', 'feature_preprocessor:feature_agglomeration:linkage': 'complete', 'feature_preprocessor:feature_agglomeration:n_clusters': 223, 'feature_preprocessor:feature_agglomeration:pooling_func': 'mean'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'decision_tree', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'liblinear_svc_preprocessor', 'classifier:decision_tree:criterion': 'entropy', 'classifier:decision_tree:max_depth_factor': 1.2604168067173658, 'classifier:decision_tree:max_features': 1.0, 'classifier:decision_tree:max_leaf_nodes': 'None', 'classifier:decision_tree:min_impurity_decrease': 0.0, 'classifier:decision_tree:min_samples_leaf': 19, 'classifier:decision_tree:min_samples_split': 20, 'classifier:decision_tree:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize', 'feature_preprocessor:liblinear_svc_preprocessor:C': 205.55338441856475, 'feature_preprocessor:liblinear_svc_preprocessor:dual': 'False', 'feature_preprocessor:liblinear_svc_preprocessor:fit_intercept': 'True', 'feature_preprocessor:liblinear_svc_preprocessor:intercept_scaling': 1, 'feature_preprocessor:liblinear_svc_preprocessor:loss': 'squared_hinge', 'feature_preprocessor:liblinear_svc_preprocessor:multi_class': 'ovr', 'feature_preprocessor:liblinear_svc_preprocessor:penalty': 'l1', 'feature_preprocessor:liblinear_svc_preprocessor:tol': 3.922262206507567e-05},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'lda', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'pca', 'classifier:lda:shrinkage': 'auto', 'classifier:lda:tol': 2.284032008368911e-05, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:pca:keep_variance': 0.8557040295112393, 'feature_preprocessor:pca:whiten': 'False'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'lda', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'kitchen_sinks', 'classifier:lda:shrinkage': 'None', 'classifier:lda:tol': 0.012743464101411408, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'standardize', 'feature_preprocessor:kitchen_sinks:gamma': 0.351879815457925, 'feature_preprocessor:kitchen_sinks:n_components': 396},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'mlp', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'extra_trees_preproc_for_classification', 'classifier:mlp:activation': 'tanh', 'classifier:mlp:alpha': 3.155139708992184e-07, 'classifier:mlp:batch_size': 'auto', 'classifier:mlp:beta_1': 0.9, 'classifier:mlp:beta_2': 0.999, 'classifier:mlp:early_stopping': 'valid', 'classifier:mlp:epsilon': 1e-08, 'classifier:mlp:hidden_layer_depth': 1, 'classifier:mlp:learning_rate_init': 0.004986255131165076, 'classifier:mlp:n_iter_no_change': 32, 'classifier:mlp:num_nodes_per_layer': 21, 'classifier:mlp:shuffle': 'True', 'classifier:mlp:solver': 'adam', 'classifier:mlp:tol': 0.0001, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none', 'feature_preprocessor:extra_trees_preproc_for_classification:bootstrap': 'True', 'feature_preprocessor:extra_trees_preproc_for_classification:criterion': 'entropy', 'feature_preprocessor:extra_trees_preproc_for_classification:max_depth': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:max_features': 0.7443499693706075, 'feature_preprocessor:extra_trees_preproc_for_classification:max_leaf_nodes': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:min_impurity_decrease': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_leaf': 2, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_split': 20, 'feature_preprocessor:extra_trees_preproc_for_classification:min_weight_fraction_leaf': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:n_estimators': 100, 'classifier:mlp:validation_fraction': 0.1},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'lda', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'select_percentile_classification', 'classifier:lda:shrinkage': 'auto', 'classifier:lda:tol': 0.05632567598079515, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:select_percentile_classification:percentile': 66.37635966401439, 'feature_preprocessor:select_percentile_classification:score_func': 'mutual_info'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'pca', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'gini', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.9642599579858266, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 15, 'classifier:random_forest:min_samples_split': 11, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none', 'feature_preprocessor:pca:keep_variance': 0.5547236123132241, 'feature_preprocessor:pca:whiten': 'True'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'liblinear_svc', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'liblinear_svc_preprocessor', 'classifier:liblinear_svc:C': 22675.42949430509, 'classifier:liblinear_svc:dual': 'False', 'classifier:liblinear_svc:fit_intercept': 'True', 'classifier:liblinear_svc:intercept_scaling': 1, 'classifier:liblinear_svc:loss': 'squared_hinge', 'classifier:liblinear_svc:multi_class': 'ovr', 'classifier:liblinear_svc:penalty': 'l2', 'classifier:liblinear_svc:tol': 0.008423775799125446, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:liblinear_svc_preprocessor:C': 28.320523576712255, 'feature_preprocessor:liblinear_svc_preprocessor:dual': 'False', 'feature_preprocessor:liblinear_svc_preprocessor:fit_intercept': 'True', 'feature_preprocessor:liblinear_svc_preprocessor:intercept_scaling': 1, 'feature_preprocessor:liblinear_svc_preprocessor:loss': 'squared_hinge', 'feature_preprocessor:liblinear_svc_preprocessor:multi_class': 'ovr', 'feature_preprocessor:liblinear_svc_preprocessor:penalty': 'l1', 'feature_preprocessor:liblinear_svc_preprocessor:tol': 0.0936482630686436},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'mlp', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'polynomial', 'classifier:mlp:activation': 'tanh', 'classifier:mlp:alpha': 0.0022455048743537844, 'classifier:mlp:batch_size': 'auto', 'classifier:mlp:beta_1': 0.9, 'classifier:mlp:beta_2': 0.999, 'classifier:mlp:early_stopping': 'train', 'classifier:mlp:epsilon': 1e-08, 'classifier:mlp:hidden_layer_depth': 2, 'classifier:mlp:learning_rate_init': 0.0017580248856052239, 'classifier:mlp:n_iter_no_change': 32, 'classifier:mlp:num_nodes_per_layer': 30, 'classifier:mlp:shuffle': 'True', 'classifier:mlp:solver': 'adam', 'classifier:mlp:tol': 0.0001, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'robust_scaler', 'feature_preprocessor:polynomial:degree': 3, 'feature_preprocessor:polynomial:include_bias': 'True', 'feature_preprocessor:polynomial:interaction_only': 'True', 'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_max': 0.7151351307083559, 'data_preprocessor:feature_type:numerical_transformer:rescaling:robust_scaler:q_min': 0.2734275202746094},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'libsvm_svc', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'liblinear_svc_preprocessor', 'classifier:libsvm_svc:C': 1414.3165171577596, 'classifier:libsvm_svc:gamma': 0.08399927231906988, 'classifier:libsvm_svc:kernel': 'rbf', 'classifier:libsvm_svc:max_iter': -1, 'classifier:libsvm_svc:shrinking': 'False', 'classifier:libsvm_svc:tol': 0.0354993989593887, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'most_frequent', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:liblinear_svc_preprocessor:C': 4285.583208980176, 'feature_preprocessor:liblinear_svc_preprocessor:dual': 'False', 'feature_preprocessor:liblinear_svc_preprocessor:fit_intercept': 'True', 'feature_preprocessor:liblinear_svc_preprocessor:intercept_scaling': 1, 'feature_preprocessor:liblinear_svc_preprocessor:loss': 'squared_hinge', 'feature_preprocessor:liblinear_svc_preprocessor:multi_class': 'ovr', 'feature_preprocessor:liblinear_svc_preprocessor:penalty': 'l1', 'feature_preprocessor:liblinear_svc_preprocessor:tol': 0.0009484351472025005},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'random_forest', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'extra_trees_preproc_for_classification', 'classifier:random_forest:bootstrap': 'True', 'classifier:random_forest:criterion': 'gini', 'classifier:random_forest:max_depth': 'None', 'classifier:random_forest:max_features': 0.5064601235242102, 'classifier:random_forest:max_leaf_nodes': 'None', 'classifier:random_forest:min_impurity_decrease': 0.0, 'classifier:random_forest:min_samples_leaf': 1, 'classifier:random_forest:min_samples_split': 2, 'classifier:random_forest:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'minmax', 'feature_preprocessor:extra_trees_preproc_for_classification:bootstrap': 'True', 'feature_preprocessor:extra_trees_preproc_for_classification:criterion': 'gini', 'feature_preprocessor:extra_trees_preproc_for_classification:max_depth': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:max_features': 0.5, 'feature_preprocessor:extra_trees_preproc_for_classification:max_leaf_nodes': 'None', 'feature_preprocessor:extra_trees_preproc_for_classification:min_impurity_decrease': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_leaf': 10, 'feature_preprocessor:extra_trees_preproc_for_classification:min_samples_split': 4, 'feature_preprocessor:extra_trees_preproc_for_classification:min_weight_fraction_leaf': 0.0, 'feature_preprocessor:extra_trees_preproc_for_classification:n_estimators': 100},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'weighting', 'classifier:__choice__': 'libsvm_svc', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'random_trees_embedding', 'classifier:libsvm_svc:C': 10.333377374155885, 'classifier:libsvm_svc:gamma': 0.004626339195129745, 'classifier:libsvm_svc:kernel': 'poly', 'classifier:libsvm_svc:max_iter': -1, 'classifier:libsvm_svc:shrinking': 'False', 'classifier:libsvm_svc:tol': 0.05834375290751928, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none', 'feature_preprocessor:random_trees_embedding:bootstrap': 'False', 'feature_preprocessor:random_trees_embedding:max_depth': 10, 'feature_preprocessor:random_trees_embedding:max_leaf_nodes': 'None', 'feature_preprocessor:random_trees_embedding:min_samples_leaf': 17, 'feature_preprocessor:random_trees_embedding:min_samples_split': 6, 'feature_preprocessor:random_trees_embedding:min_weight_fraction_leaf': 1.0, 'feature_preprocessor:random_trees_embedding:n_estimators': 58, 'classifier:libsvm_svc:coef0': -0.8477085379652083, 'classifier:libsvm_svc:degree': 5},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'decision_tree', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'polynomial', 'classifier:decision_tree:criterion': 'entropy', 'classifier:decision_tree:max_depth_factor': 1.782562709576749, 'classifier:decision_tree:max_features': 1.0, 'classifier:decision_tree:max_leaf_nodes': 'None', 'classifier:decision_tree:min_impurity_decrease': 0.0, 'classifier:decision_tree:min_samples_leaf': 3, 'classifier:decision_tree:min_samples_split': 5, 'classifier:decision_tree:min_weight_fraction_leaf': 0.0, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'mean', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'power_transformer', 'feature_preprocessor:polynomial:degree': 2, 'feature_preprocessor:polynomial:include_bias': 'False', 'feature_preprocessor:polynomial:interaction_only': 'True'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Weight: 0.02
Model: SimpleClassificationPipeline({'balancing:strategy': 'none', 'classifier:__choice__': 'qda', 'data_preprocessor:__choice__': 'feature_type', 'feature_preprocessor:__choice__': 'no_preprocessing', 'classifier:qda:reg_param': 0.6966532719017251, 'data_preprocessor:feature_type:numerical_transformer:imputation:strategy': 'median', 'data_preprocessor:feature_type:numerical_transformer:rescaling:__choice__': 'none'},
dataset_properties={
'task': 2,
'sparse': False,
'multilabel': False,
'multiclass': True,
'target_type': 'classification',
'signed': False})
Auto-Sklearnのメタ学習
メタ学習とは?
メタ学習は、以前に解かれた問題(またはデータセット)から学び、新しい未知の問題に対する初期モデルの設定を効率的に選択する手法です。
具体的には、Auto-Sklearn は多数の公開データセットに対する最適なモデル設定の履歴を持っています。
新しい問題が与えられたとき、この履歴を用いてその問題がどの既存の問題に似ているかを評価し、似ている問題でよい性能を発揮したモデル設定を新しい問題に対する初期設定として用います。
Auto-Sklearnのメタ学習の流れ
Auto-SklearnはOpenMLという公開データセットプラットフォームと連携しています。
ちなみに、以下でOpenMLに関する簡単な紹介をしています。
OpenMLには多数の機械学習データセットが公開されており、Auto-Sklearnはこれらのデータセットに対して過去に行われた多数のモデル訓練の結果を履歴として保持しています。
これがメタ学習の基礎となる「公開データセットに対する最適なモデル設定の履歴」です。
この履歴には、各データセットに対してどのような前処理が行われ、どのアルゴリズムが用いられ、どのハイパーパラメータが最適だったのかといった情報が含まれます。
新しいデータセットに対するモデル訓練を開始する際、Auto-Sklearnはこの履歴を参照して、新しいデータセットが過去のどのデータセットに似ているかを判断します。
そして、最も似ているデータセットで高性能だったモデル設定を、新しいデータセットの初期設定として採用します。
以下手順の概要です。
- データセットの特性の抽出: まず、新しいデータセットに対して一連のメタフィーチャーが計算されます。
- 類似性の計算: 次に、これらのメタフィーチャーを用いて、新しいデータセットが過去に解かれたデータセットとどれだけ似ているかの類似性スコアを計算します。類似性の計算方法は、ユークリッド距離やコサイン類似性など、様々な手法が用いられることがあります。
- 初期設定の選択: 最後に、最も類似性の高い過去のデータセットで良い性能を示したモデル設定を、新しいデータセットの初期設定として採用します。
この過程を通じて、Auto-Sklearnは新しい問題に対して適切な初期設定を高速に選択することができます。
これにより、全体のモデル訓練プロセスが加速され、限られた時間内でより高性能なモデルを見つける可能性が高くなります。
initial_configurations_via_metalearningパラメータは、このメタ学習プロセスにおいて、どれだけ多くの初期設定を採用するかを制御します。
この数値が大きいほど、多くの初期設定が試されますが、それだけ探索にかかる時間も増える可能性があります。逆にこの数値が小さいと、探索は高速になりますが、良い初期設定を見逃す可能性があります。
メタフィーチャーとは?
メタフィーチャー(Meta-features)とは、データセット自体の特性や性質を表す特徴量のことです。
これらは通常、データセットが機械学習アルゴリズムにとってどのような挑戦や特性を持つかを理解するために用いられます。
メタフィーチャーは、特にメタ学習の文脈で、新しいデータセットが既存のどのデータセットに似ているかを評価するための基準として使用されます。
以下、主な種類のメタフィーチャーです。
- サイズ関連: 例えば、データセットのサンプル数や特徴量の数。
- クラス関連: クラス分布の偏り、クラスごとのサンプル数など。
- 特徴量関連: 特徴量のタイプ(数値、カテゴリカル)、欠損値の有無、特徴量間の相関など。
- 統計的特性: 各特徴量やクラスラベルの平均、分散、歪度、尖度などの統計量。
メタフィーチャーは、メタ学習のアルゴリズムが新しいデータセットに対してどのようなモデルやハイパーパラメータが有望かを高速に判断するために用いられます。
具体的には、新しいデータセットのメタフィーチャーを計算し、既存のデータセットのメタフィーチャーと比較することで、最も似ていると判断されたデータセットに対して以前に成功したモデルやハイパーパラメータの設定を借用します。
このようにして、メタフィーチャーは新しいデータセットに対する初期のモデル選択やハイパーパラメータ設定の選択を効率化し、全体のモデル訓練プロセスを加速する役割を果たします。
メタ学習後
ベイズ最適化でベースモデルを構築
Auto-Sklearnは、初期のメタ学習フェーズの後も、時間制限に達するまでさまざまなモデル設定を試し続けます。
Auto-Sklearnはベイズ最適化を主要な探索戦略として使用します。
ベイズ最適化は、既存のモデル設定とその性能から、次に試すべきモデル設定を効率的に選択します。この方法は計算負荷を抑えつつ、高い性能のモデルを探索する能力があります。
Auto-SklearnはSmAC(Sequential Model-based Algorithm Configuration)というRandom Forest を用いたベイズ最適化の一形態を用いて、ハイパーパラメータの最適な設定を探索します。
初期のメタ学習フェーズでは、既存のデータセットとの類似性に基づいて、一連の初期モデル設定(デフォルトでは25個)が試されます。これはinitial_configurations_via_metalearningパラメータで設定できます。
これらの探索戦略は、時間制限(time_left_for_this_taskパラメータで設定可能)や他の制約条件内で、効率的に高性能なモデルを見つけ出すように設計されています。
このようにして、Auto-Sklearnは自動化された探索と最適化を行い、最終的なアンサンブルモデルを構築します。
最終的なアンサンブルモデル
Auto-Sklearnでは、時間制限内で訓練された全てのベースモデルがアンサンブルの候補となりますが、実際にアンサンブルに選ばれるモデルはその性能に基づいて厳選されます。すべてのモデルが必ずしもアンサンブルに含まれるわけではありません。
具体的には、以下のようなプロセスが行われます。
- 性能評価: 各モデルは交差検証やホールドアウトセットによって評価されます。
- モデル選択: 高性能なモデルがアンサンブルに選ばれます。この選択は、各モデルがテストデータに対してどれだけよく予測できるか、またはクラス分類問題の場合はどれだけのクラスを正確に識別できるか、に基づいています。
- 重み付け: 選ばれたモデルには重みが付けられ、これが最終的なアンサンブルの予測に用いられます。重みは、各モデルの訓練データに対する性能に基づいて最適化されます。
このようにして、Auto-Sklearnは最終的なアンサンブルモデルを構築します。
このアンサンブルモデルは、個々のモデルが持っている長所を組み合わせ、短所を相互に補完することで、より堅牢で高性能な予測を行います。
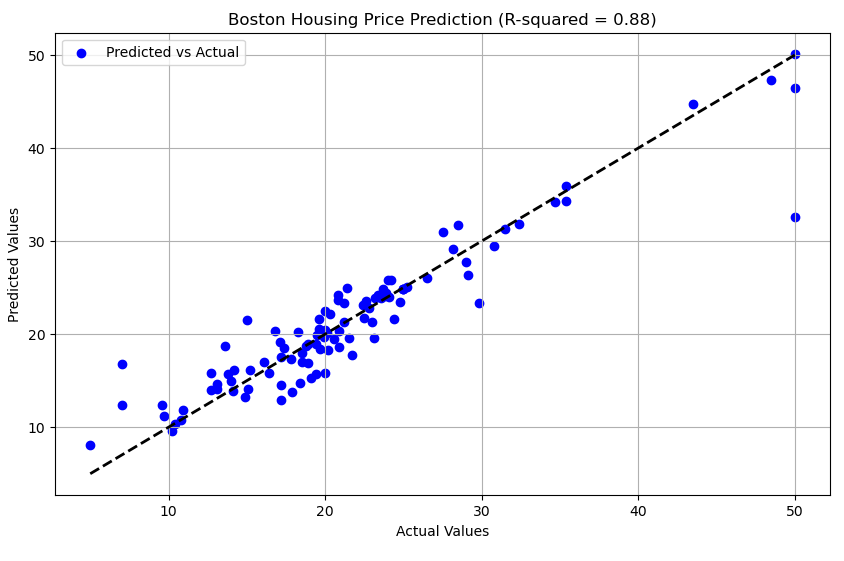
回帰問題の例
回帰問題では、連続値を予測するモデルを訓練します。基本、分類問題と大きく異なりません。
Auto-SklearnにはAutoSklearnRegressorが用意されており、これを用いて回帰モデルの自動訓練が可能です。
以下、コードの簡単な流れです。
- Boston Housingデータセットをロードして、訓練データとテストデータに分割します。
AutoSklearnRegressorクラスを用いて回帰モデルを訓練します。- 訓練されたモデルでテストデータに対する予測を行い、R-squaredスコアを計算します。
- 実際の価格と予測された価格をプロットして、モデルの性能を視覚的に評価します。
以下、コードです。
# 必要なライブラリとモジュールをインポート
from sklearn.datasets import load_boston
from autosklearn.regression import AutoSklearnRegressor
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# ボストンの住宅価格データセットをロード
boston = load_boston()
X = boston.data
y = boston.target
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# AutoSklearnで回帰モデルを初期化と訓練
automl = AutoSklearnRegressor(time_left_for_this_task=120)
automl.fit(X_train, y_train)
# 予測を行う
y_pred = automl.predict(X_test)
# R二乗値を計算
r2_score = automl.score(X_test, y_test)
# 予測値と実測値の散布図をプロット
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, color='blue', label='Predicted vs Actual')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title(f'Boston Housing Price Prediction (R-squared = {r2_score:.2f})')
plt.legend()
plt.grid(True)
plt.show()
以下、実行結果です。
まとめ
今回は、Auto-Sklearnによる自動機械学習(AutoML)の使い方を簡単に説明しました。
機械学習モデルを設計、訓練、テストする過程は非常に時間がかかるばかりか、多くの専門知識が必要です。
自動機械学習(AutoML)は、これらの課題に対する解決策を提供します。AutoMLは、データを入力として受け取り、最適な機械学習モデルを自動で設計してくれます。
これにより、非専門家でも短時間で高品質な機械学習モデルを構築できるようになります。
AutoMLの中でも特に人気のあるライブラリの一つにAuto-Sklearnがあります。
Auto-Sklearnには長所もありますが、短所もあります。
以下、Auto-Sklearnの長所です。
- 効率的なハイパーパラメータ探索: Auto-Sklearnはベイズ最適化とスモータリング(SmAC)を使用して効率的なハイパーパラメータ探索を行います。
- メタ学習による高速スタート: 初期モデル設定はメタ学習を通じて効率的に選ばれるため、新しい問題に対しても迅速に適応できます。
- アンサンブル学習: 複数のモデルを組み合わせることで、予測性能が向上します。
- Scikit-learnとの高い互換性: Scikit-learnと同じインターフェースを有するため、既存のコードやプロジェクトに容易に組み込むことができます。
以下、Auto-Sklearnの短所です。
- 計算負荷: 効率的な探索手法を用いているものの、多くのモデルを試すためには依然として高い計算負荷が必要です。
- 時間制限の必要性: 最適なモデルを見つけるためには、適切な時間制限の設定が必要です。
- メモリ使用量: 大規模なデータセットや複雑なモデルを扱う場合、メモリ使用量が問題となる可能性があります。
最後に他のAutoMLツールとの比較です。
- Google AutoML: クラウドベースであり、より多くのリソースと高度なアルゴリズムを使用できますが、費用がかかります。
- H2O AutoML: 多様なアルゴリズムと高度な最適化手法をサポートしていますが、JavaベースであるためPython環境とは少々異なります。
- TPOT: 遺伝的アルゴリズムを使用してパイプラインを最適化します。非常に多様なモデル設定が可能ですが、計算負荷が高い場合があります。
- Hyperopt: ベイズ最適化に特化していますが、Auto-Sklearnよりも手動設定が多く必要です。
- MLflow: モデルのライフサイクル管理に優れていますが、ハイパーパラメータ最適化の機能は限定的です。
以上のように、Auto-Sklearnはその効率性と使いやすさで多くの場合において優れた選択肢となるでしょう。
しかし、具体的な用途や制約に応じて、他のAutoMLツールが適している場合もあります。