

あなたは全国にドラッグストアを展開する企業の経営企画部に配属されました。
あなたは上司から……
「来年の新規出店候補が10ヵ所ある。
どこに出店すれば売上が見込めるか、
データに基づいて優先順位をつけてほしい。」
「ついでに、
既存店舗の売上をもっと伸ばすために
何に投資すべきかも分析してくれ。」
……と言われています。
今回は、この課題に回帰分析で挑む第一歩として、データの探索(EDA)から重回帰分析の構築、そして多重共線性の診断までを実施していきます。
Contents
この課題の2つの側面
この事例の上司から与えられた課題には2つの側面があります。
ひとつは予測です。
新しい立地で売上がどの程度になるかを推定すること。
もうひとつは要因分析です。
売上を左右している要因を特定し、その影響度を定量化することです。
回帰分析は、まさにこの2つの目的を同時に達成できる手法です。
ただし実際のビジネスデータでは、候補となる変数が数十個にのぼることも珍しくありません。
立地の特性(人口密度、最寄駅の乗降客数、競合店の数)、店舗の属性(売場面積、駐車場台数、スタッフ数)、商圏の情報(世帯年収、高齢者比率、周辺施設)など、データベースから引っ張ってこられる変数は無数にあります。
これらすべてをモデルに投入すると、多重共線性の問題や過学習の問題が生じます。
今回の前編では、データの準備と探索的分析(EDA)を行い、全変数を投入した重回帰分析を構築し、多重共線性の診断までを扱います。
次回の後編では、Lasso回帰による変数選択やモデル評価、そしてビジネスレポートの作成に進みます。
準備
ライブラリのインポート
今回使用するライブラリをまとめてインポートします。
回帰分析のためにstatsmodels(統計的な詳細を確認するため)とscikit-learn(モデル構築と評価のため)の2つのライブラリを使いま。
variance_inflation_factorは多重共線性を診断するためのVIF計算用です。
以下、コードです。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import japanize_matplotlib import statsmodels.api as sm from sklearn.preprocessing import StandardScaler from statsmodels.stats.outliers_influence import variance_inflation_factor
サンプルデータの読み込み
サンプルデータとして、150店舗 × 11変数(目的変数1+説明変数10)ののドラッグストアデータを利用します。
サンプルデータは、以下からダウンロードできます。
drugstore_data.csv
以下、コードです。
# 読み込むCSVファイル名
csv_path = 'drugstore_data.csv'
# データの読み込み(CSVからDataFrameを作成)
df = pd.read_csv(csv_path)
print(f"店舗データ: {len(df)} 店舗 × {len(df.columns)} 変数")
print("【先頭5店舗のデータ】")
print(df.head())
以下、実行結果です。
店舗データ: 150 店舗 × 12 変数 【先頭5店舗のデータ】 store_id monthly_sales sales_area pop_density station_passengers \ 0 0 9912.185172 368.281211 13016.146613 35277.142025 1 1 9614.122280 350.012969 14329.963779 58835.854506 2 2 4160.181915 127.071574 3917.759039 30364.878807 3 3 5942.464021 258.735026 3867.264053 22316.068069 4 4 6818.312296 404.383551 1543.796329 32572.337282 competitor_count household_income parking_slots staff_count \ 0 2 601.025317 9 37.0 1 4 534.899105 15 37.0 2 6 418.976512 11 15.0 3 5 437.702779 13 27.0 4 1 428.428072 12 42.0 business_hours building_age signboard_size 0 18 24.089964 18.060646 1 16 12.604745 27.993712 2 24 9.910629 27.624726 3 18 18.884532 23.163064 4 24 7.727617 25.940754
このデータセットは、150店に関する立地特性、店舗属性、その他要因と、月間売上で構成されるデータです。
- 行数: 150(店舗数)
- 列数: 11(目的変数1、説明変数10)
目的変数は、月間売上(monthly_sales)です。
説明変数は以下の10変数です。
- 立地特性
- pop_density: 周辺人口密度(persons/km²)
- station_passengers: 最寄駅の1日当たり乗降客数(persons/day)
- competitor_count: 半径1km以内の競合店数(件)
- household_income: 商圏の世帯年収(10k JPY単位)
- 店舗属性
- sales_area: 売場面積(m²)
- parking_slots: 駐車場台数(台)
- staff_count: スタッフ数(人)
- business_hours: 営業時間(hours:16/18/24のカテゴリ)
- その他
- building_age: 築年数(years)
- signboard_size: 看板サイズ(m²)
基本統計量の確認
各変数の平均・標準偏差・最小値・最大値などの基本統計量を確認し、データの「顔」を数値で把握します。
以下、コードです。
print("【基本統計量】")
print(df.drop(columns=['store_id']).describe().round(1))
以下、実行結果です。
【基本統計量】
monthly_sales sales_area pop_density station_passengers \
count 150.0 150.0 150.0 150.0
mean 7362.5 306.7 7394.7 40549.0
std 1737.0 113.3 4205.1 20807.3
min 3751.0 102.8 519.6 6069.2
25% 5947.3 210.6 3921.3 22510.5
50% 7418.9 314.2 6864.6 41037.2
75% 8599.5 398.6 11420.5 56651.5
max 11784.3 498.5 14774.5 79366.5
competitor_count household_income parking_slots staff_count \
count 150.0 150.0 150.0 150.0
mean 3.1 497.7 14.7 32.6
std 1.7 93.5 3.8 11.4
min 0.0 276.9 7.0 11.0
25% 2.0 431.7 12.0 23.0
50% 3.0 502.1 15.0 33.0
75% 4.0 560.9 17.0 42.0
max 8.0 733.1 28.0 54.0
business_hours building_age signboard_size
count 150.0 150.0 150.0
mean 19.6 12.3 18.0
std 3.2 7.1 7.5
min 16.0 0.2 5.0
25% 18.0 7.0 11.2
50% 18.0 12.5 17.9
75% 24.0 18.2 24.4
max 24.0 24.9 29.9
月間売上の平均や範囲を確認できます。
売上は概ね数千万円程度のオーダーで、変数によってスケールが大きく異なることがわかります。
人口密度は数千〜数万、競合店数は0〜10程度と、桁がまったく違います。
この「スケールの違い」は、後のステップで標準化偏回帰係数を使って「影響度の比較」を行う際に重要になります。
探索的データ分析(EDA)
回帰モデルを構築する前に、データの全体像を可視化して理解しておくことは不可欠です。
データ分析は「まず目で見る」ことから始まります。
売上と各変数の関係を散布図で見る
売上と各説明変数の関係を散布図で確認します。
各散布図の上に相関係数(r)を表示することで、売上との関連の強さを数値でも把握します。
以下、コードです。
# 5行×2列のサブプロットを作成
fig, axes = plt.subplots(5, 2, figsize=(10, 20))
# 2次元配列のaxesを1次元に平坦化
axes = axes.flatten()
# 目的変数とIDを除いた説明変数
explanatory_vars = [
c for c in df.columns
if c not in ['monthly_sales', 'store_id']
]
# 各説明変数についてループ
for i, col in enumerate(explanatory_vars):
# 説明変数 vs 月間売上の散布図
axes[i].scatter(
df[col], df['monthly_sales'],
alpha=0.5, s=30, c='#2E86AB'
)
axes[i].set_xlabel(col, fontsize=10)
axes[i].set_ylabel('monthly_sales' if i % 5 == 0 else '')
# 相関係数を計算してタイトルに表示
r = df[col].corr(df['monthly_sales'])
axes[i].set_title(f'r = {r:.3f}', fontsize=10)
plt.tight_layout()
plt.show()
以下、実行結果です。
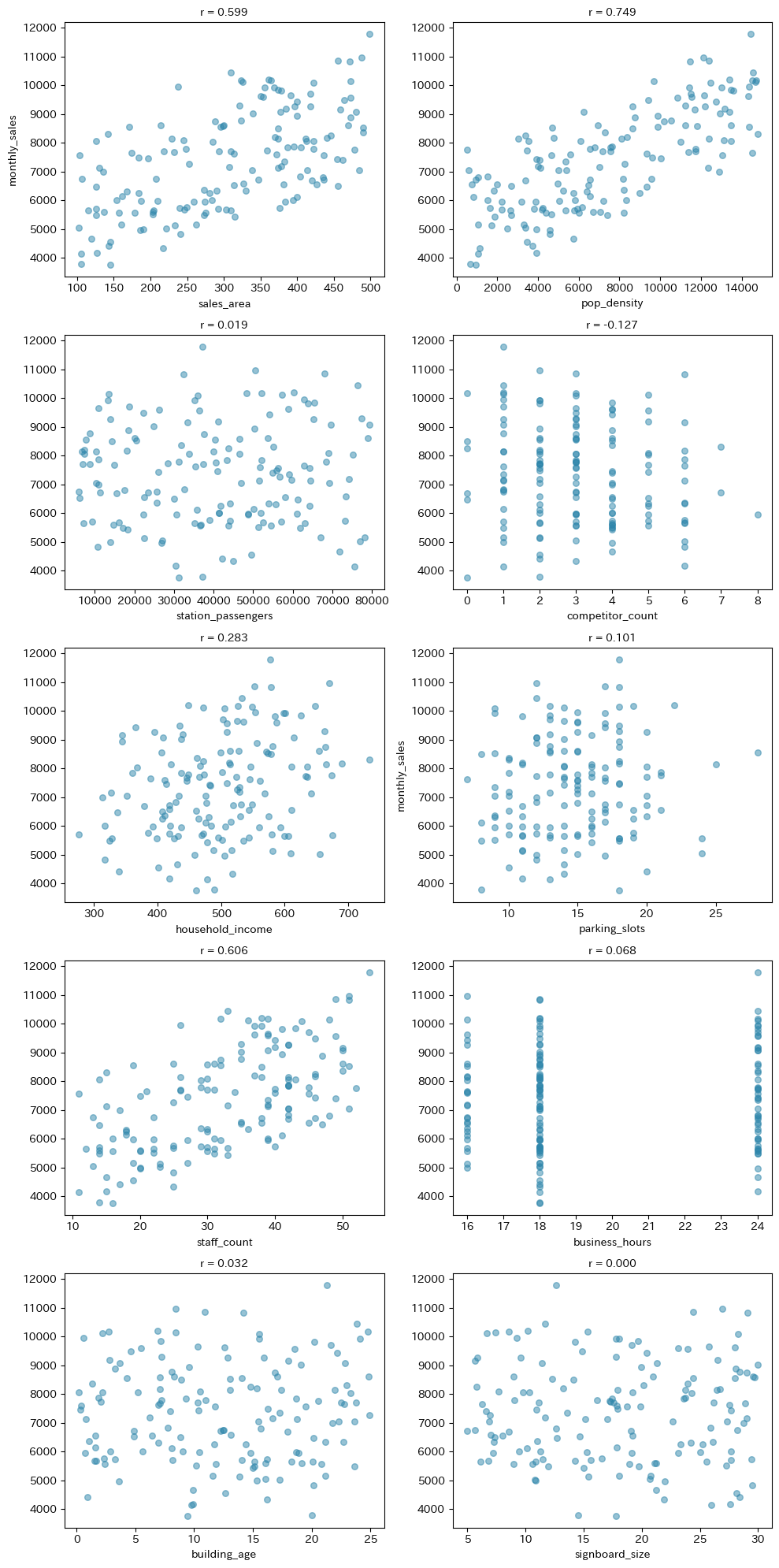
売場面積(sales_area)や人口密度(pop_density)など、売上(monthly_sales)と正の相関を持つ変数が確認できます。
一方で、看板サイズ(signboard_size)や築年数(building_age)のように相関がほとんど見られない変数もあります。
ただし、ここで大事な注意点があります。相関係数はあくまで単純な二変量の関係であり、他の変数の影響を考慮していません。
たとえば「最寄駅の乗降客数」が売上と相関しているように見えても、それは「乗降客数が多い=人口密度が高い」という間接的な関係かもしれません。
重回帰分析を行うことで、他の変数を制御した上での「純粋な効果」がわかります。
相関行列で変数どうしの関係を見る
変数間の相関をヒートマップで可視化します。
ここでは目的変数(売上)との相関だけでなく、説明変数どうしの相関にも注目します。
説明変数間の強い相関は、後で説明する「多重共線性」の予兆となるためです。
以下、コードです。
plt.figure(figsize=(10, 8))
# 相関行列の計算
corr = df.corr()
# 上三角をマスク
mask = np.triu(np.ones_like(corr, dtype=bool))
# ヒートマップの描画
sns.heatmap(
corr, mask=mask, annot=True, cmap='RdBu_r',
center=0, fmt='.2f', square=True, linewidths=0.5
)
plt.title('変数間の相関行列', fontsize=14)
plt.tight_layout()
plt.show()
以下、実行結果です。
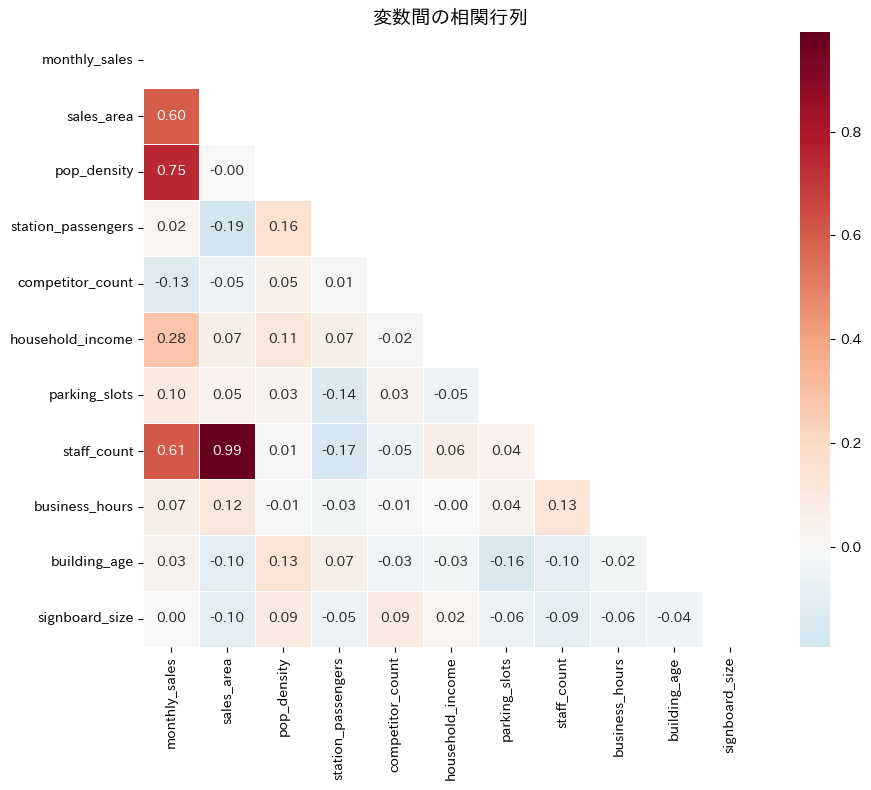
売上との相関が強い変数と弱い変数が一目でわかります。
同時に、説明変数同士の相関もチェックしてみましょう。
もし説明変数間の相関が0.8を超えるようなペアがあれば、多重共線性に注意が必要です。
今回の場合ですと、売場面積(sales_area)とスタッフ数(staff_count)の相関係数が約0.99と非常に高いことが分かります。
全変数を投入した重回帰分析
重回帰分析
まずは手元にあるすべての説明変数を投入した重回帰モデルを構築します。
これが「ベースラインモデル」となり、後のステップで変数を絞り込んだモデルと比較する基準になります。
重回帰分析のモデルは、p 個の説明変数 x_1, x_2, \ldots, x_p を使って目的変数 y を予測する式で表されます。
$$
y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p + \varepsilon
$$
ここで \beta_0 は切片、\beta_j は各説明変数の偏回帰係数、\varepsilon は誤差項です。
偏回帰係数 \beta_j は「他の変数を一定に保ったとき、x_j が1単位増えると y がどれだけ変化するか」を表しています。
散布図で見た単純相関とは異なり、他の変数の影響を取り除いた「純粋な効果」を示すのが偏回帰係数の強みです。
モデルの全体的な性能を確認する
statsmodelsを使って全変数モデルを構築し、R^2(決定係数)と自由度調整済みR^2を確認します。
この2つの指標の差が、モデルに不要な変数が含まれているかどうかの最初のヒントになります。
以下、コードです。
# 説明変数Xと目的変数yを設定
X = df.drop(['monthly_sales','store_id'], axis=1)
y = df['monthly_sales']
# statsmodelsで回帰分析(定数項を追加して実行)
X_const = sm.add_constant(X)
model_full = sm.OLS(y, X_const).fit()
print("【全変数モデルの結果(抜粋)】")
print(f"R²: {model_full.rsquared:.4f}")
print(f"自由度調整済みR²: {model_full.rsquared_adj:.4f}")
print(
f"F統計量: {model_full.fvalue:.2f} "
f"(p値: {model_full.f_pvalue:.2e})"
)
以下、実行結果です。
【全変数モデルの結果(抜粋)】 R²: 0.9724 自由度調整済みR²: 0.9704 F統計量: 490.19 (p値: 4.14e-103)
R^2 と自由度調整済み R^2 の差に注目してください。
変数を増やせば R^2 は必ず上昇しますが、自由度調整済み R^2 は不要な変数が入ると下がります。
両者の差が大きい場合は、モデルに不要な変数が含まれている可能性を示唆しています。
今回は、F統計量のp値が十分小さいため(通常0.05未満)、「少なくともいずれかの説明変数は売上と関連がある」ことが統計的に確認できます。
各変数の偏回帰係数とp値を読む
各変数の偏回帰係数・標準誤差・p値を一覧で確認し、どの変数が統計的に有意かを判断します。
p値の横に★印を表示して読みやすくしています。
以下、コードです。
# 結果のデータフレームを作成
results = pd.DataFrame({
'偏回帰係数': model_full.params,
'標準誤差': model_full.bse,
'p値': model_full.pvalues,
}).drop('const') # 切片(const)は除外
# 有意性のマークを付与(p値に応じて***, **, *)
results['有意性'] = results['p値'].apply(
lambda p: '***' if p < 0.001 else
('**' if p < 0.01 else
('*' if p < 0.05 else ''))
)
# 結果の表示
print("【偏回帰係数と有意性】")
print(results.round(4).to_string())
print("\n有意水準: *** p<0.001, ** p<0.01, * p<0.05")
以下、実行結果です。
【偏回帰係数と有意性】
偏回帰係数 標準誤差 p値 有意性
sales_area 3.7699 1.6518 0.0240 *
pop_density 0.3028 0.0061 0.0000 ***
station_passengers 0.0006 0.0012 0.6224
competitor_count -138.5469 14.3432 0.0000 ***
household_income 2.9941 0.2658 0.0000 ***
parking_slots 31.0289 6.5698 0.0000 ***
staff_count 51.5733 16.3244 0.0019 **
business_hours -0.1502 7.8533 0.9848
building_age 1.0473 3.5468 0.7682
signboard_size 0.8034 3.3482 0.8107
p値が0.05未満の変数は統計的に有意、つまり「売上への影響が偶然では説明できない」と判断できます。
一方、p値が大きい変数(看板サイズ、営業時間など)は、このモデルでは売上との有意な関係が認められません。
ここで重要な注意点が2つあります。ひとつは、「p値が大きい=影響がない」と即断するのは危険だということです。
サンプルサイズが小さい場合や多重共線性がある場合は、本来重要な変数のp値が大きくなることもあります。
もうひとつは、偏回帰係数の「大きさ」を変数間でそのまま比較してはいけないということです。
売場面積の係数が8で競合店数の係数が-150だからといって、競合店数の方が影響が大きいとは限りません。
変数のスケールが違うためです。影響度の公平な比較は、後編で標準化偏回帰係数を使って行います。
多重共線性の診断
多重共線性とは何か
複数の説明変数を使う重回帰分析では、多重共線性(multicollinearity)のチェックが不可欠です。
多重共線性とは、説明変数の間に強い相関がある状態のことで、これが起きると偏回帰係数が不安定になり、推定結果が信頼できなくなります。
たとえば「売場面積」と「スタッフ数」が非常に強い相関を持つ場合を考えてみましょう。
売上増加の原因が「面積が広いから」なのか「スタッフが多いから」なのか、モデルが区別できなくなります。
結果として、係数がデータのわずかな変化で大きくブレてしまい、「面積を増やすと売上が上がる」という結論と「面積を増やすと売上が下がる」という結論が、データセットの微妙な違いで入れ替わるようなことが起きます。
VIF(分散拡大係数)で診断する
多重共線性の程度を数値で評価するのがVIF(Variance Inflation Factor、分散拡大係数)です。
ある説明変数 x_j のVIFは、x_j を他のすべての説明変数で回帰したときの R^2_j を使って次のように計算されます。
$$
\text{VIF}_j = \frac{1}{1 – R^2_j}
$$
VIFが高いほど、その変数は他の変数で「説明できてしまう」ことを意味します。
つまり、その変数が持つ情報の多くが他の変数と重複しているということです。
- VIF < 5 → 問題なし
- 5 ≦ VIF < 10 → 注意
- 10 ≦ VIF → 要対処
各変数のVIFを計算し、多重共線性の程度を確認します。
以下、コードです。
# 空のデータフレームを作成
vif_data = pd.DataFrame()
# 変数名をセット
vif_data['variable'] = X.columns
# 各変数のVIFを計算
vif_data['VIF'] = [
variance_inflation_factor(X.values, i)
for i in range(X.shape[1])
]
print("【VIF(分散拡大係数)】")
print(
vif_data.sort_values('VIF', ascending=False)
.round(2).to_string(index=False)
)
以下、実行結果です。
【VIF(分散拡大係数)】
variable VIF
staff_count 533.23
sales_area 490.09
business_hours 28.26
household_income 23.17
parking_slots 13.52
signboard_size 6.48
station_passengers 5.05
pop_density 4.45
competitor_count 4.18
building_age 3.93
VIFがすべて5未満であれば、深刻な多重共線性はないと判断できます。
もしVIFが10を超える変数があった場合は、その変数を除外するか、PCA(第1回・第2回で学んだ手法)で次元削減を行ってから回帰分析を行う方法(主成分回帰)が有効です。
今回のデータでは、スタッフ数(staff_count)および売場面積(sales_area)、営業時間(business_hours)および商圏の世帯年収(household_income)、駐車場台数(parking_slots)のVIFが高い値になっています。
ここまでの振り返り
ここで一度立ち止まって、全変数モデルの結果を振り返りましょう。
全変数モデルのサマリーから、統計的に有意な変数と有意でない変数を整理して、現状の問題点を明確にします。
以下、コードです。
# 有意な変数と有意でない変数を分類
sig_vars = results[results['p値'] < 0.05].index.tolist() nonsig_vars = results[results['p値'] >= 0.05].index.tolist()
print("【全変数モデルの診断まとめ】")
print(f"\nモデル全体の説明力:")
print(f" R² = {model_full.rsquared:.4f}")
print(f" 自由度調整済みR² = {model_full.rsquared_adj:.4f}")
print(f" 差分 = {model_full.rsquared - model_full.rsquared_adj:.4f}")
print(f"\n統計的に有意な変数(p < 0.05): {len(sig_vars)}個")
for v in sig_vars:
coef = results.loc[v, '偏回帰係数']
p = results.loc[v, 'p値']
print(f" {v}: 係数={coef:.4f}, p値={p:.4f}")
print(f"\n有意でない変数(p ≥ 0.05): {len(nonsig_vars)}個")
for v in nonsig_vars:
p = results.loc[v, 'p値']
print(f" {v}: p値={p:.4f}")
print(f"\n→ {len(nonsig_vars)}個の変数はモデルから除外できる可能性があります")
以下、実行結果です。
【全変数モデルの診断まとめ】 モデル全体の説明力: R² = 0.9724 自由度調整済みR² = 0.9704 差分 = 0.0020 統計的に有意な変数(p < 0.05): 6個 sales_area: 係数=3.7699, p値=0.0240 pop_density: 係数=0.3028, p値=0.0000 competitor_count: 係数=-138.5469, p値=0.0000 household_income: 係数=2.9941, p値=0.0000 parking_slots: 係数=31.0289, p値=0.0000 staff_count: 係数=51.5733, p値=0.0019 有意でない変数(p ≥ 0.05): 4個 station_passengers: p値=0.6224 business_hours: p値=0.9848 building_age: p値=0.7682 signboard_size: p値=0.8107 → 4個の変数はモデルから除外できる可能性があります
全変数モデルの現状が整理されます。
R^2 と自由度調整済み R^2 の差、有意な変数と有意でない変数の一覧が出力されるので、「どの変数がモデルに貢献していて、どの変数がノイズになっている可能性があるか」が明確になります。全変数モデルの問題点を整理すると、次の3つに集約されます。
- 不要な変数が含まれている:p値が大きい変数はモデルの精度向上に貢献しておらず、むしろ過学習のリスクを高めています。
- 偏回帰係数の比較が難しい:変数のスケールが異なるため、係数の大きさをそのまま比較して「どの要因が最も影響が大きいか」を判断できません。
- 本当に新しいデータで予測できるかわからない:手元のデータへの当てはまり(R^2)が良くても、見たことのないデータに対する予測力は別問題です。
これらの問題を解決するのが、次回(後編)で扱うLasso回帰による変数選択、標準化偏回帰係数による影響度比較、交差検証によるモデル評価です。
まとめ
今回は、ドラッグストアチェーンの店舗データを題材に、以下の分析を実施しました。
| ステップ | やったこと | 得られた知見 |
|---|---|---|
| データの理解 | 基本統計量の確認 | 変数間のスケールの大きな違い |
| EDA(散布図) | 売上と各変数の散布図 + 相関係数 | 売上との関連が強い変数・弱い変数の把握 |
| EDA(相関行列) | 変数間の相関ヒートマップ | 説明変数間の冗長性の確認 |
| 重回帰分析 | 全変数モデルの構築 | R²、各変数のp値、有意な変数の特定 |
| 多重共線性診断 | VIFの計算 |
重要なのは、「全部入りモデル」をそのまま信じてはいけないという気づきです。
全変数を投入すると R^2 は高くなりますが、不要な変数が含まれている可能性があり、新しいデータに対する予測力は保証されません。
p値も、多重共線性やサンプルサイズの影響を受けます。
次回(後編)では、Lasso回帰で本当に効く変数だけを自動選択し、標準化偏回帰係数で影響度を公平に比較し、交差検証でモデルの安定性を確認します。
そして最後に、新規出店候補地の売上予測と経営層向けのビジネスレポート作成まで一気に進めます。