

H2O(エイチツーオー)は、H2O.ai社によって開発された、インメモリ型の機械学習プラットフォームです。
教師あり学習や教師なし学習などの機械学習系の数理モデルを構築することができます。
嬉しいのが、ノンコードで機械学習モデルを構築することのできるH2O FlowというGUI環境が用意されていることです。
さらに嬉しいことに、AutoML(自動機械学習)機能があるため、面倒なパラメータ調整などを全自動で実施してくれる機能がついています。
ノンコードな機械学習モデル構築を可能にする H2O Flow の簡単な使い方について、以下のような順番で説明していきます。
- その1 H2O Flow の起動
- その2 H2O Flow で実施する教師あり学習(回帰問題) ⇒ 今回
- その3 H2O Flow で実施する教師あり学習(分類問題)
- その4 H2O Flow で実施する自動機械学習AutoML(回帰問題)
- その5 H2O Flow で実施する自動機械学習AutoML(分類問題)
- その6 H2O Flow で実施する教師なし学習(次元削減・集約)
- その7 H2O Flow で実施する教師なし学習(異常検知)
- その8 H2O Flow で実施する教師なし学習(クラスタリング)
- その9 H2O Flow の保存と読込
前回は、その1 の「H2O Flow の起動」について説明しました。
今回は、その2 の「H2O Flow で実施する教師あり学習(回帰問題)」について説明します。
H2O Flowの起動
まずは、H2O Flowの起動です。
「h2o.jar」というJARファイルをダブルクリックすることでH2O Flowが起動します。

もしくは、コマンドプロンプト上などで、「h2o.jar」ファイルのあるフォルダまで移動し、以下のコードを実行することでも実行できます。
java -jar h2o.jar
実行したら、ブラウザに以下のURLを入力しアクセスします。
そうすると、以下のようなH2O Flowの実行画面が表示されます。

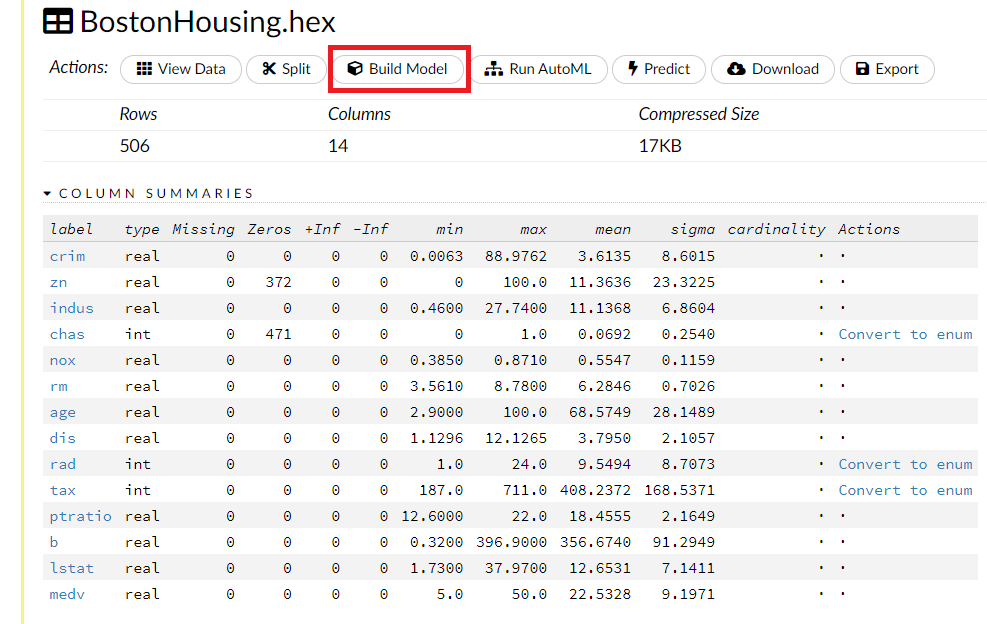
今回利用するデータセット
今回利用するデータセットは、回帰問題でよく登場するみんな大好き「ボストン住宅価格(BostonHousing)」データセットです。
以下、データ項目です。
- CRIM: 犯罪率
- ZN: 広い家の割合(25,000平方フィートを超える区画に分類される住宅地の割合)
- INDUS: 非小売業の割合
- CHAS: 川と隣接(川に隣接している場合は1、そうでない場合は0)
- NOX: NOx濃度(0.1ppm単位)
- RM: 平均部屋数
- AGE: 古い家の割合(1940年より前に建てられた持ち家の割合)
- DIS: 主要施設への距離(5つあるボストン雇用センターまでの加重距離)
- RAD: 主要高速道路アクセス指数
- TAX: 固定資産税率(10,000ドル当たり)
- PTRATIO: 生徒と先生の比率
- B: 1000×(黒人割合- 0.63)の二乗
- LSTAT: 低所得者人口の割合
- MEDV:住宅価格の中央値(1000ドル単位)
項目数は14。
- 目的変数Y:一番下の「MEDV」(住宅価格)
- 説明変数X(特徴量):残り13つのデータすべて
要するに、「MEDV」(住宅価格)を他の変数で当てる問題です。
CSVファイルは、以下からダウンロードできます。
BostonHousing.csv
https://www.salesanalytics.co.jp/0leq
データの読み込み
メニューから、[Data]⇒[Import Files…]を選択します。

以下のようなImport Filesの入力画面が現れます。
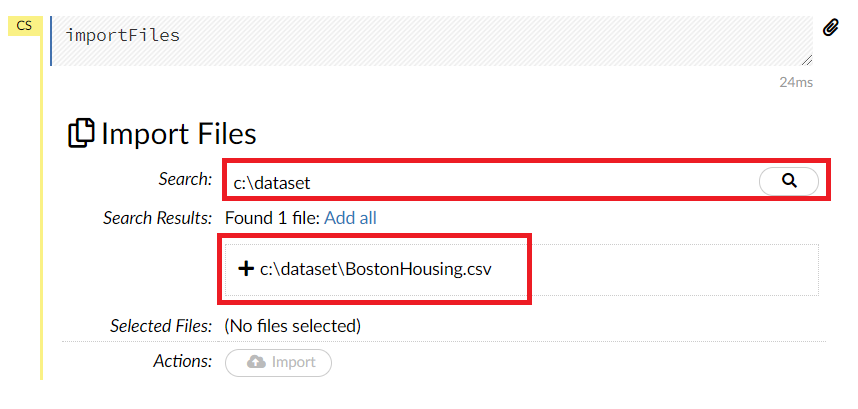
Searchにデータのあるフォルダ名(例 C:\dataset)などを入力し、虫眼鏡をクリックします。そうすると、そのフォルダ内にある候補ファイルが表示されます(例 C:\dataset\BostonHousing.csv)ので、読み込みたいファイルの左側の「+」をクリックします。
一番下のActionのところにあるImportがアクティブになりますので、このImportをクリックします。
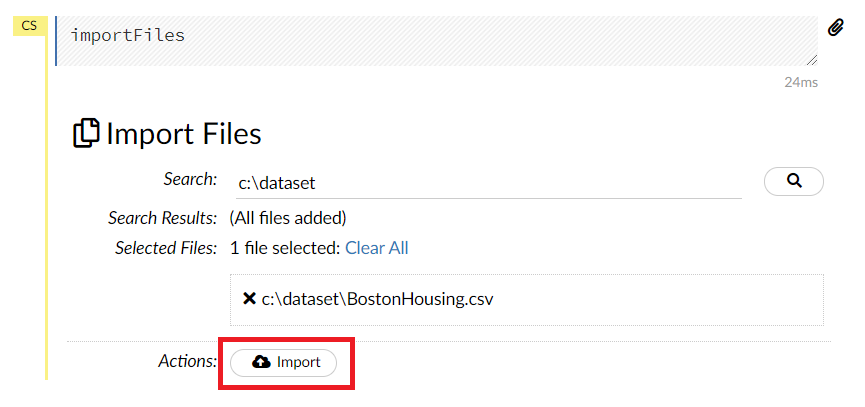
問題なければ、以下のような画面になり、Parse these files…がアクティブになりますので、このParse these files…をクリックします。
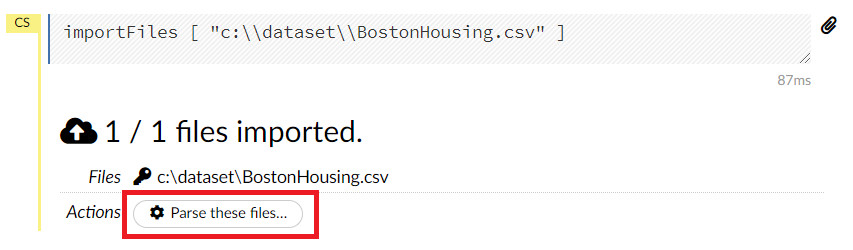
以下のような画面になります。
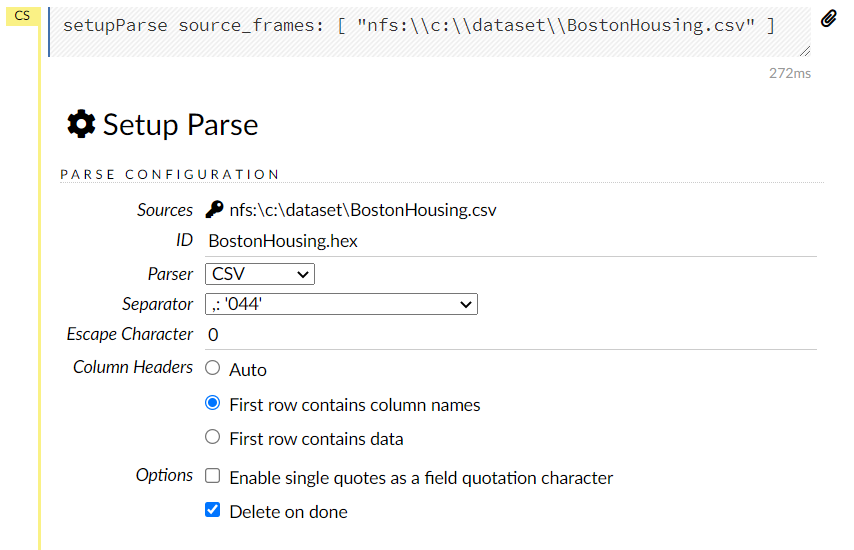
この画面を下にスクロールすると、変数設定を変更できる画面が登場しますので、必要があれば変更します。最後に、一番下のParseをクリックします。
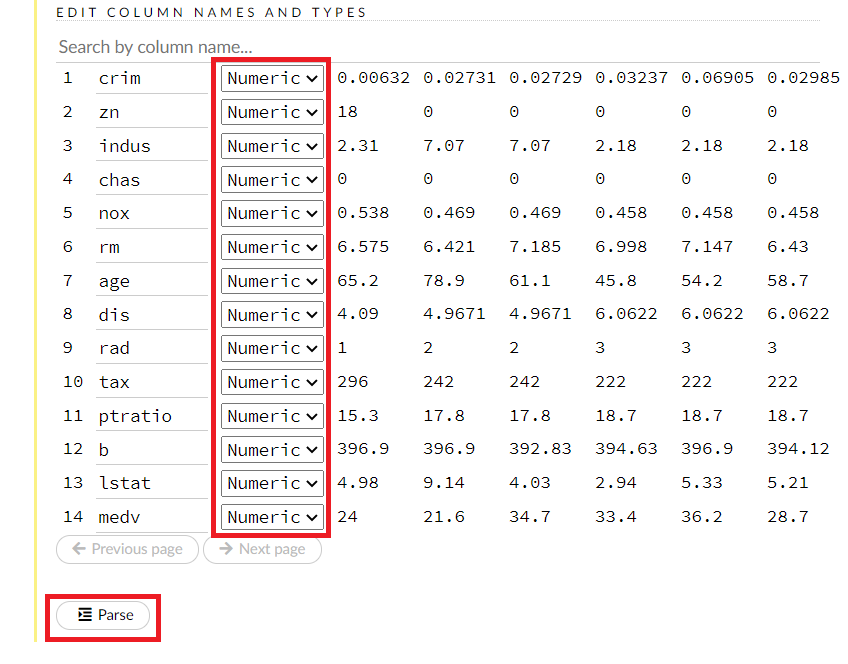
データの読み込みが開始されます。
上手くデータが読み込めると、以下のような画面になり、Viewがアクティブになりますので、このViewをクリックします。
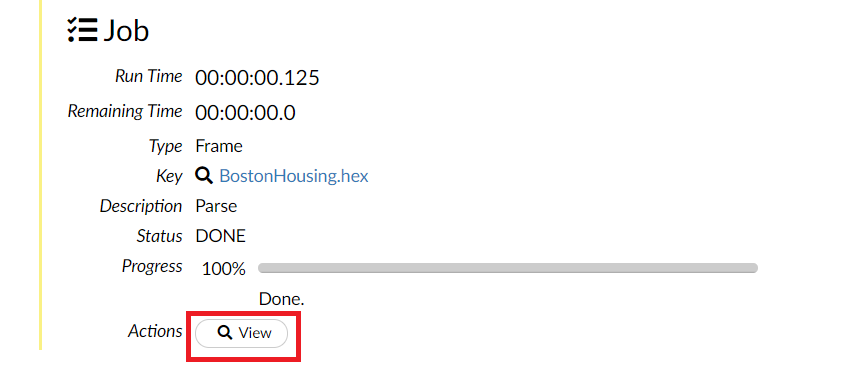
以下のような画面が表示されます。この画面上で、データの分割やモデル構築などを実施していきます。

データセットの分割(学習データとテストデータ)
読み込んだデータを、モデルを構築する学習データと、構築したモデルを評価するテストデータに分割します。
上にあるSplitをクリックします。
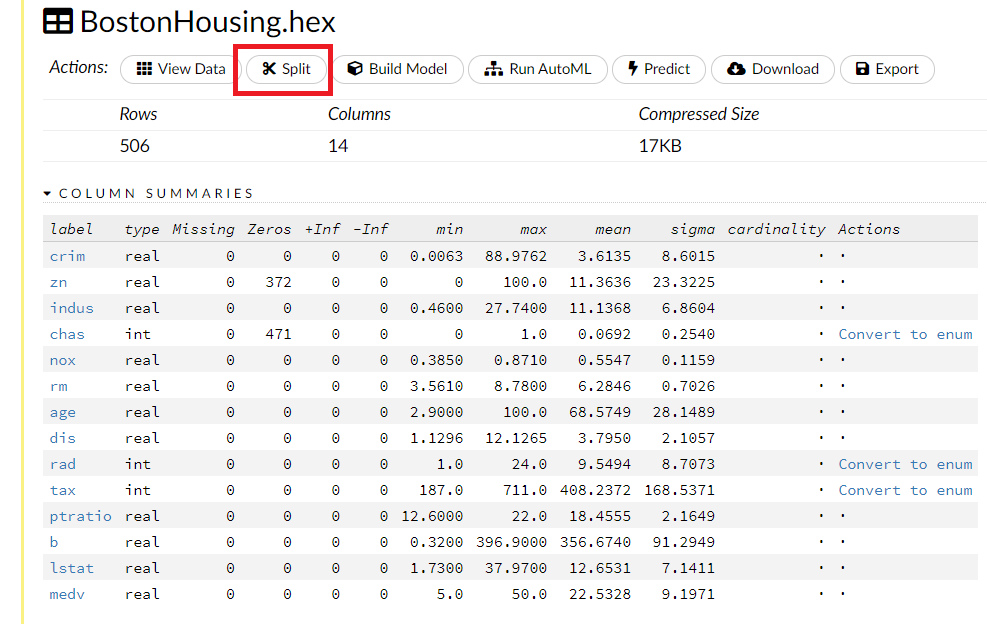
以下のようなデータ分割のための画面が表示されます。
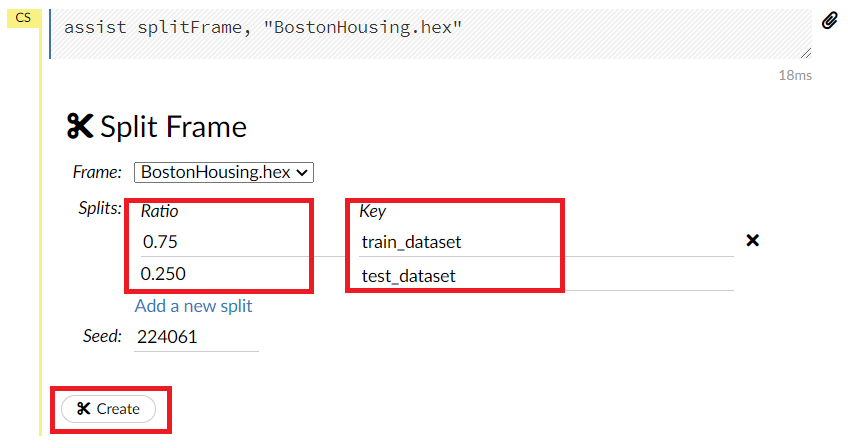
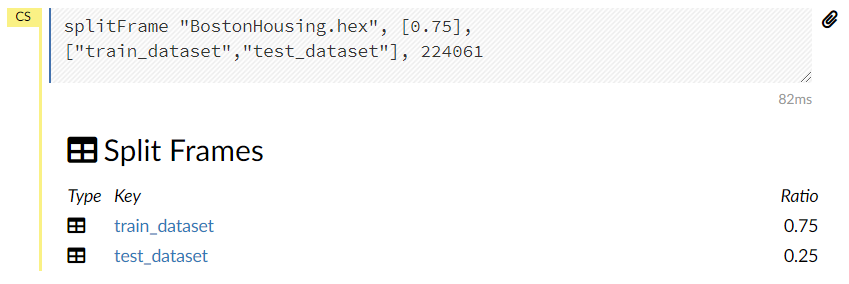
Ratioに分割比率を設定し、Keyに分割後のデータセット名を入力します。例では、75%が学習データで名称をtrain_datasetとし、残りの25%がテストデータで名称をtest_datasetとしています。
設定したら、一番下のCreateをクリックします。
問題なければ、以下のような画面が表示されます。
構築するモデルの設定と実行
構築するモデルの設定、構築、評価を実施していきます。
先ほどの画面に戻り(上にスクロール)、Build Modelをクリックします。
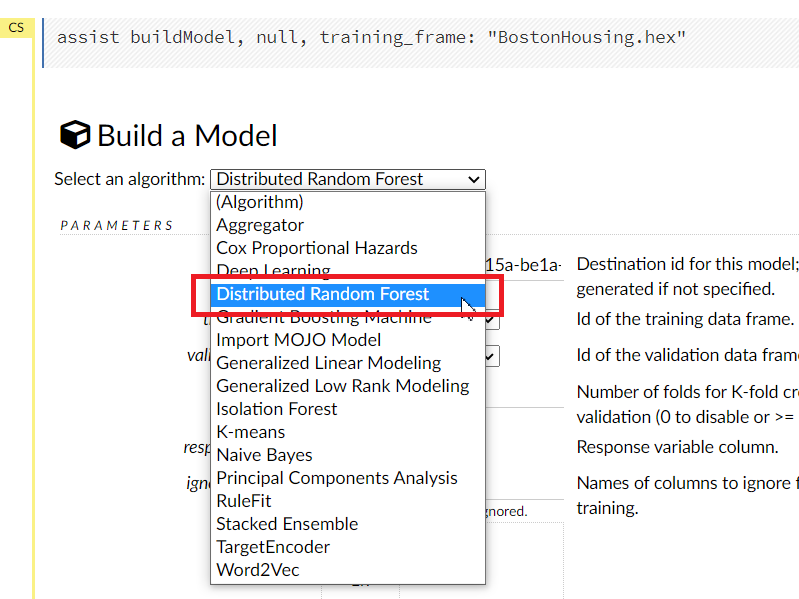
H2Oに実装されているモデル(アルゴリズム)が表示されますので、1つ選択します。
例では、Distributed Random Forestを選択しています。
そうすると、選択したモデル(アルゴリズム)で学習し評価するための設定をするための画面が表示されます。
今回は、学習データ(例 train_dataset)とテストデータ(例 test_dataset)の指定と、目的変数(例 medv)の設定のみ実施しています(他はデフォルトの設定のまま)。
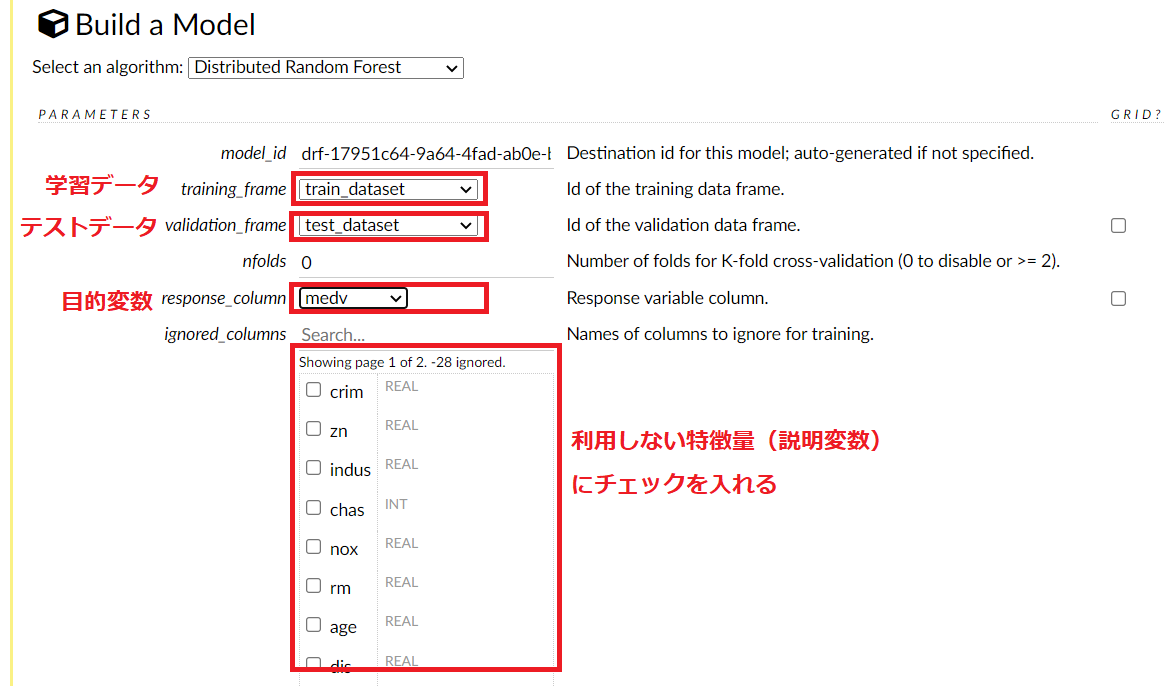
この画面を下にスクロールしていくと、一番下にBuild Modelというボタンがあるので、このBuild Modelをクリックします。

これで、学習データによるモデル構築と、構築したモデルに対するテストデータによる評価が実施されます。
学習結果と検証結果
学習と評価が終了すると、以下のような画面になり、Viewがアクティブになりますので、このViewをクリックします。
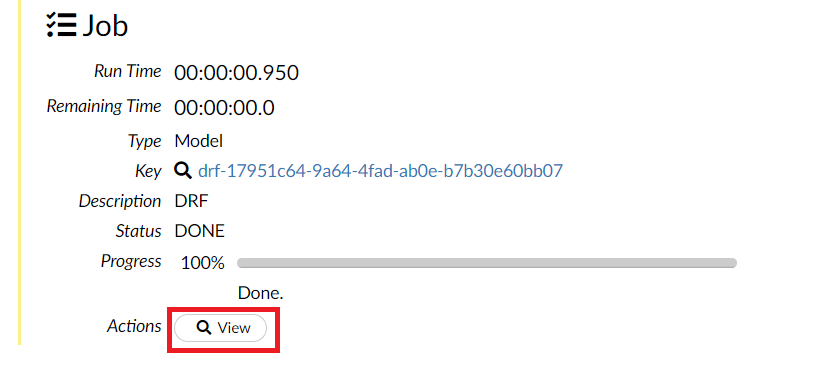
そうすると、学習結果や評価結果を見るとこができます。
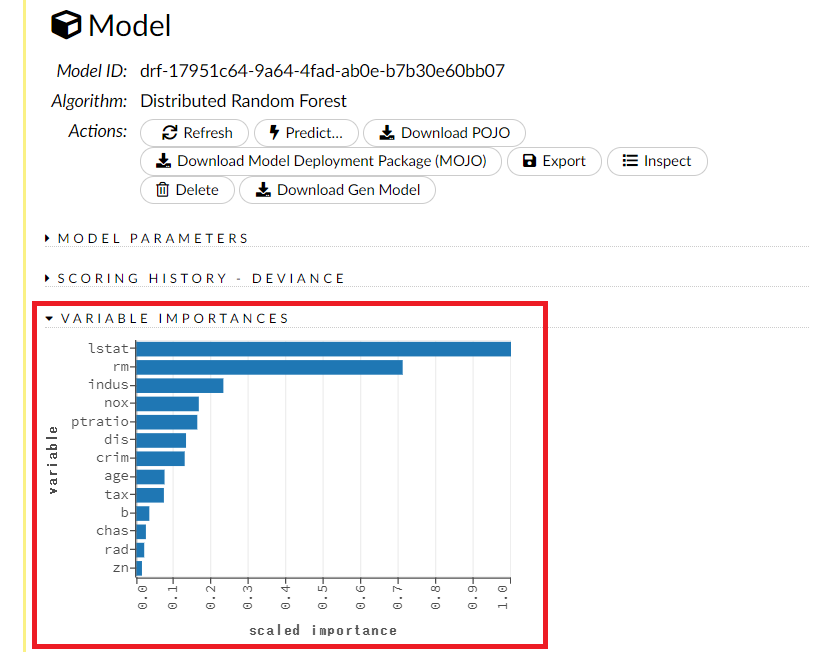
以下は、各特徴量(説明変数)の重要度であるインポータンス(Importance)が表示されている状態です。
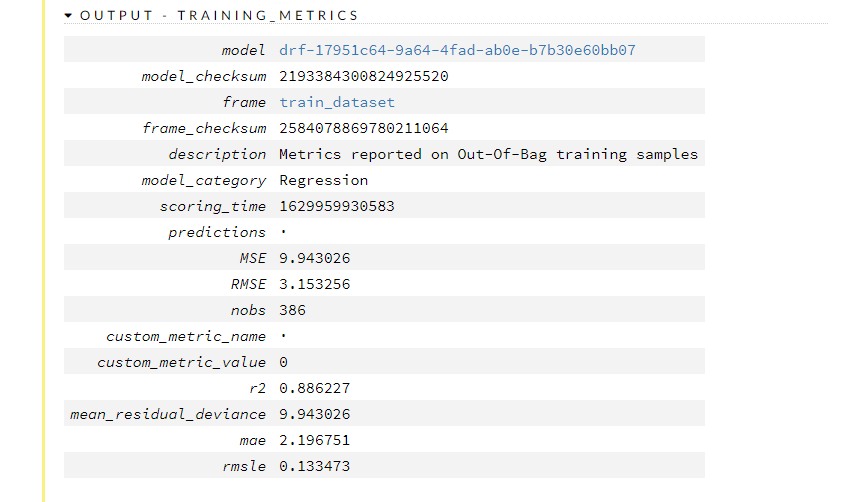
学習結果(学習データ)を見てみます。OUTPUT – TRAINING_METRICSのタブを開くと見れます。決定係数R2(r2)は0.886227です。
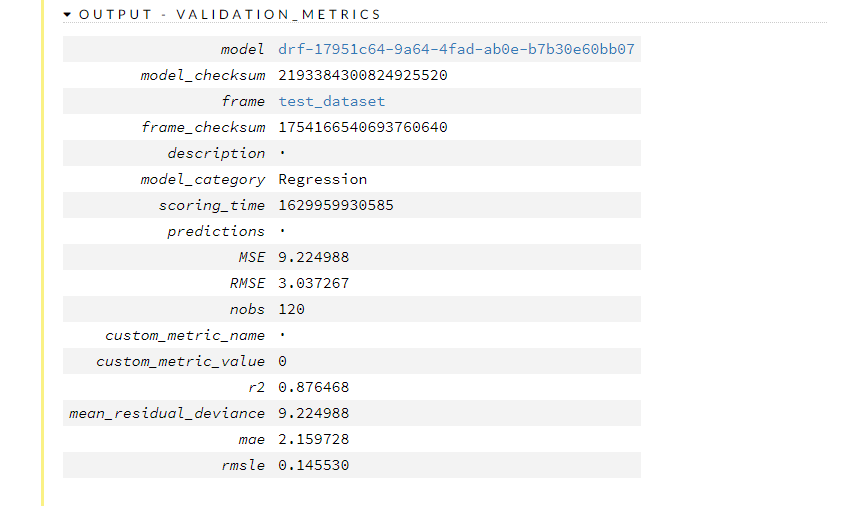
評価結果(テストデータ)を見てみます。OUTPUT – VALIDATION_METRICSのタブを開くと見れます。
次回
今回は、その2の「 H2O Flow で実施する教師あり学習(回帰問題)」について説明しました。
- その1 H2O Flow の起動
- その2 H2O Flow で実施する教師あり学習(回帰問題)
- その3 H2O Flow で実施する教師あり学習(分類問題) ⇒ 次回
- その4 H2O Flow で実施する自動機械学習AutoML(回帰問題)
- その5 H2O Flow で実施する自動機械学習AutoML(分類問題)
- その6 H2O Flow で実施する教師なし学習(次元削減・集約)
- その7 H2O Flow で実施する教師なし学習(異常検知)
- その8 H2O Flow で実施する教師なし学習(クラスタリング)
- その9 H2O Flow の保存と読込
次回は、その3の「H2O Flow で実施する教師あり学習(分類問題)」について説明します。