
- 問題
- 答え
- 解説
Python コード:
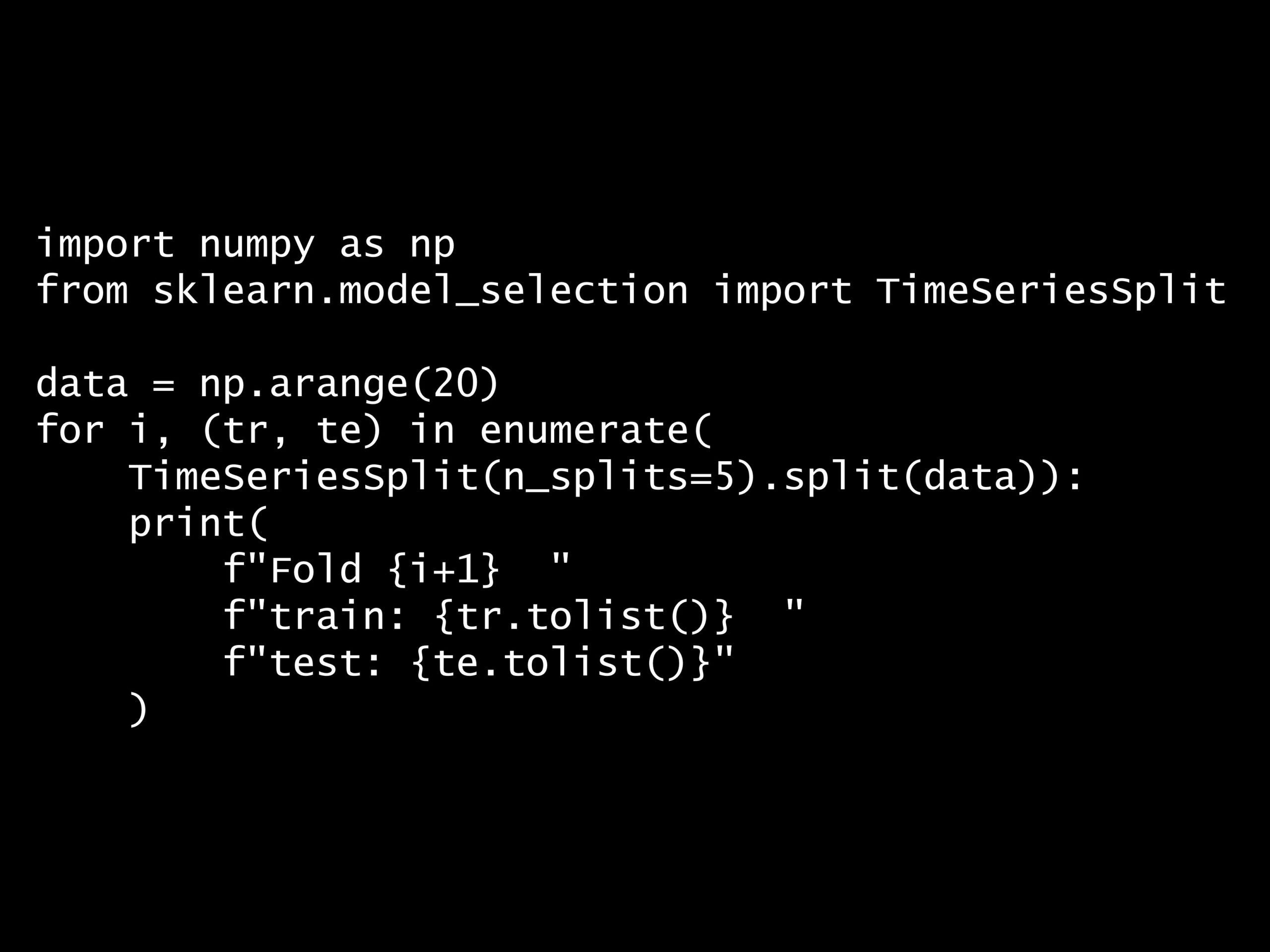
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
data = np.arange(20)
for i, (tr, te) in enumerate(
TimeSeriesSplit(n_splits=5).split(data)):
print(
f"Fold {i+1} "
f"train: {tr.tolist()} "
f"test: {te.tolist()}"
)
回答の選択肢:
(A) ランダムに分割し、各Foldで訓練・テストの比率を一定にしている
(B) 時系列順に分割し、常にテストデータが訓練データより過去になるようにしている
(C) 時系列順に分割し、訓練データを拡張しながらテストデータが常に未来になるようにしている
(D) 等間隔に5分割し、1つずつテストに使うk-fold交差検証を行っている
Fold 1 train: [0, 1, 2, 3, 4] test: [5, 6, 7] Fold 2 train: [0, 1, 2, 3, 4, 5, 6, 7] test: [8, 9, 10] Fold 3 train: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] test: [11, 12, 13] Fold 4 train: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13] test: [14, 15, 16] Fold 5 train: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16] test: [17, 18, 19]
正解: (C)
このコードは、TimeSeriesSplitを使った時系列クロスバリデーション(ウォーク・フォワード検証)を行っています。出力結果から、Foldが進むごとに訓練データが拡張され、テストデータは常に訓練データより未来の区間になっていることがわかります。
回答の選択肢:
(A) ランダムに分割し、各Foldで訓練・テストの比率を一定にしている
(B) 時系列順に分割し、常にテストデータが訓練データより過去になるようにしている
(C) 時系列順に分割し、訓練データを拡張しながらテストデータが常に未来になるようにしている
(D) 等間隔に5分割し、1つずつテストに使うk-fold交差検証を行っている
- コードの解説
-
このコードは、時系列データの評価に適したクロスバリデーション手法を実行しています。
import numpy as np from sklearn.model_selection import TimeSeriesSplit data = np.arange(20) for i, (tr, te) in enumerate( TimeSeriesSplit(n_splits=5).split(data)): print( f"Fold {i+1} " f"train: {tr.tolist()} " f"test: {te.tolist()}" )簡単に説明します。
ライブラリのインポート
numpy:数値計算を行うためのライブラリ。ここでは配列生成に使用しています。sklearn.model_selection.TimeSeriesSplit:時系列データ専用のクロスバリデーション分割器です。
データの生成
np.arange(20):0から19までの整数配列を生成しています。ここでは分割の挙動を確認するためのインデックスとして使用しています。
TimeSeriesSplitの実行
TimeSeriesSplit(n_splits=5):5つのFoldに分割する時系列分割器を作成します。.split(data):データのインデックスを訓練用とテスト用に分割するジェネレータを返します。- 各Foldで
tr(訓練インデックス)とte(テストインデックス)が得られ、その内容を出力しています。
出力結果から、以下のパターンが確認できます。
- 訓練データは毎回拡張される:Fold 1では5個、Fold 2では8個、…と訓練データが増えていきます。
- テストデータは常に訓練データの直後:各Foldで、テストの開始インデックスは訓練の終了インデックスの次になっています。
- 時系列の順序が保持される:未来のデータが訓練に混入することがありません。
- 選択肢の解説
-
(A) ランダムに分割し、各Foldで訓練・テストの比率を一定にしている → ×
ランダム分割は通常の
KFoldの動作です。TimeSeriesSplitではデータの時系列順序を保持するため、シャッフルやランダム分割は行いません。(B) 時系列順に分割し、常にテストデータが訓練データより過去になるようにしている → ×
テストデータが訓練データより過去になるのは誤りです。
TimeSeriesSplitでは逆に、テストデータは常に訓練データより未来になります。過去のデータで学習し、未来のデータで評価するのが時系列検証の基本です。(C) 時系列順に分割し、訓練データを拡張しながらテストデータが常に未来になるようにしている → ○
正解です。出力結果の通り、Foldが進むごとに訓練データが拡大し(expanding window)、テストデータは常に訓練データの直後の区間になっています。
(D) 等間隔に5分割し、1つずつテストに使うk-fold交差検証を行っている → ×
通常のk-fold交差検証では、データを等間隔に分割し各Foldを順番にテストに使います。しかし、この方法では未来のデータが訓練に混入する可能性があり、時系列データには不適切です。
TimeSeriesSplitはこの問題を防ぐ設計になっています。 - なぜ時系列では通常のクロスバリデーションが使えないのか
-
通常のk-fold交差検証では、データをランダムまたは等間隔に分割します。例えば5-foldの場合、以下のような分割が行われます。
通常のk-fold(5-fold): Fold 1 test: [0,1,2,3] train: [4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19] Fold 2 test: [4,5,6,7] train: [0,1,2,3,8,9,10,11,12,13,14,15,16,17,18,19] Fold 3 test: [8,9,10,11] train: [0,1,2,3,4,5,6,7,12,13,14,15,16,17,18,19] ...
Fold 1のように、未来のデータ(4〜19)で訓練して過去のデータ(0〜3)をテストするケースが生じます。これはデータリーケージ(data leakage) と呼ばれ、モデルの評価が過度に楽観的になる原因となります。
TimeSeriesSplitはこの問題を防ぎ、「過去で学習→未来で評価」という実運用に近い条件でモデルを検証できます。 - Expanding Window と Sliding Window
-
TimeSeriesSplitのデフォルト動作はExpanding Window(拡張窓) です。Foldが進むごとに訓練データが蓄積されていきます。Expanding Window(デフォルト): Fold 1 train: [-------] test: [---] Fold 2 train: [----------] test: [---] Fold 3 train: [-------------] test: [---]
一方、
max_train_sizeを指定するとSliding Window(スライディング窓) になり、訓練データのサイズが一定に保たれます。Sliding Window(max_train_size指定時): Fold 1 train: [-------] test: [---] Fold 2 train: [-------] test: [---] Fold 3 train: [-------] test: [---]
データの性質が時間とともに変化する場合(非定常性が強い場合)は、Sliding Windowの方が直近のパターンに集中できるため有効なことがあります。