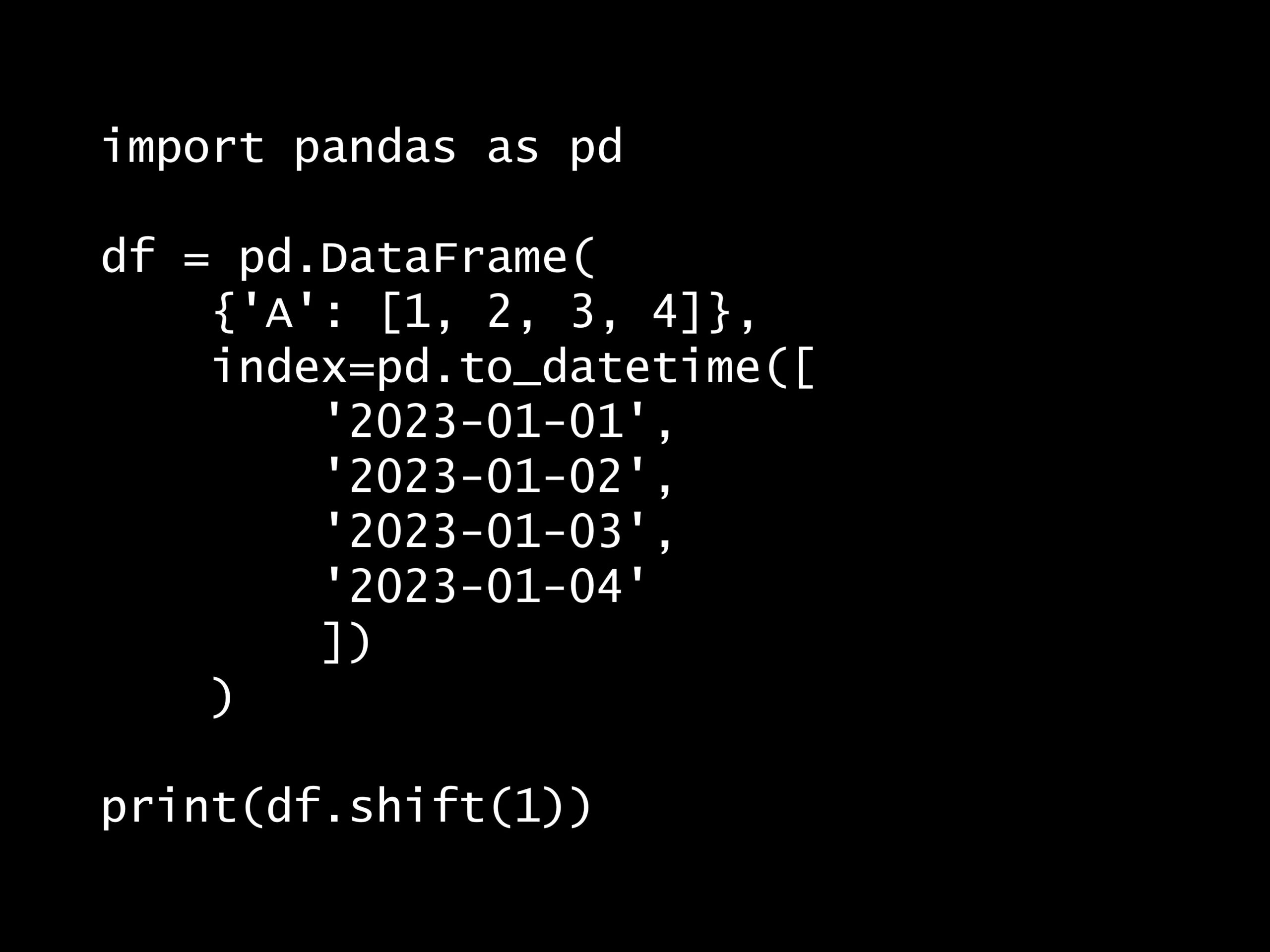
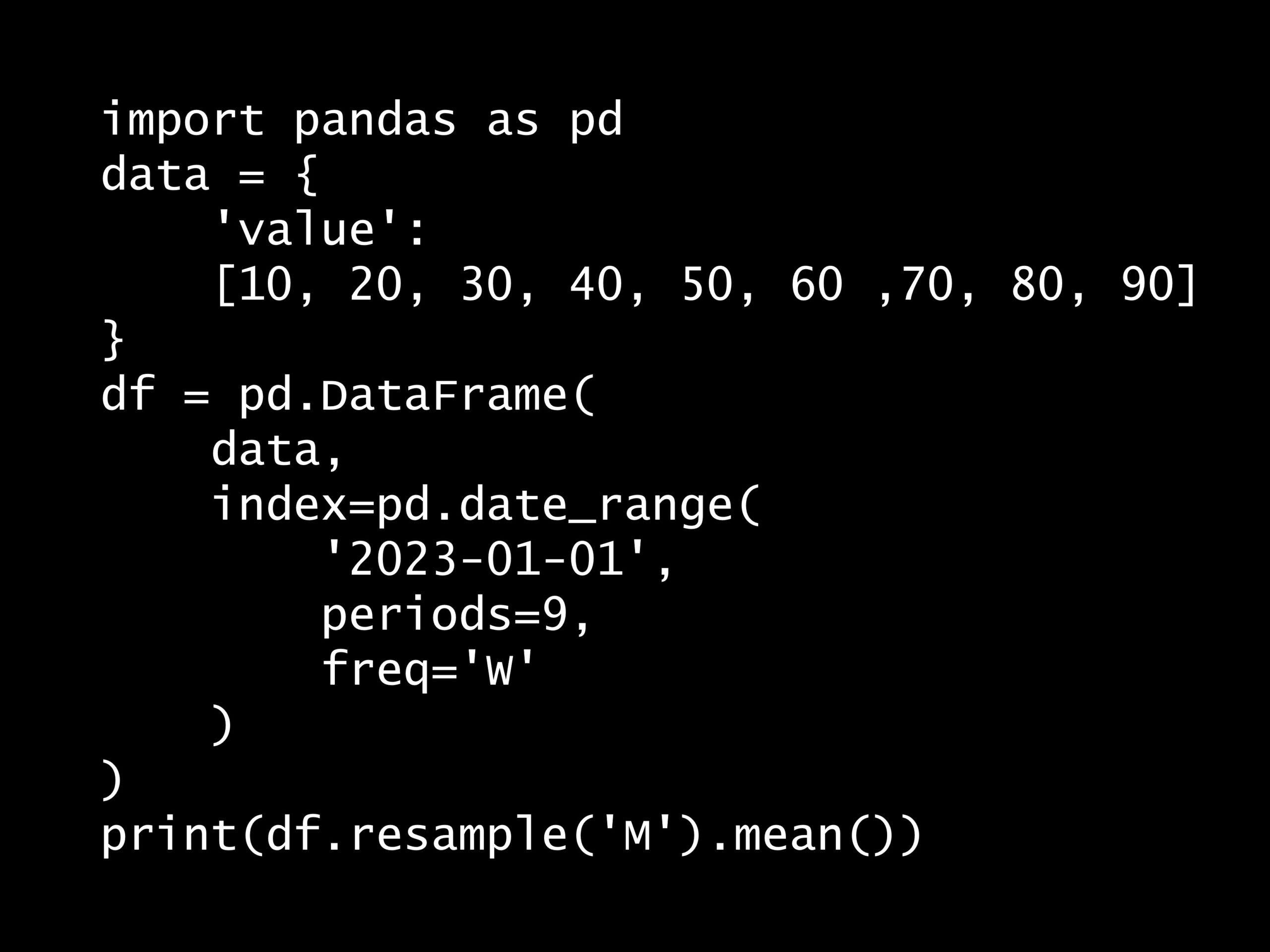
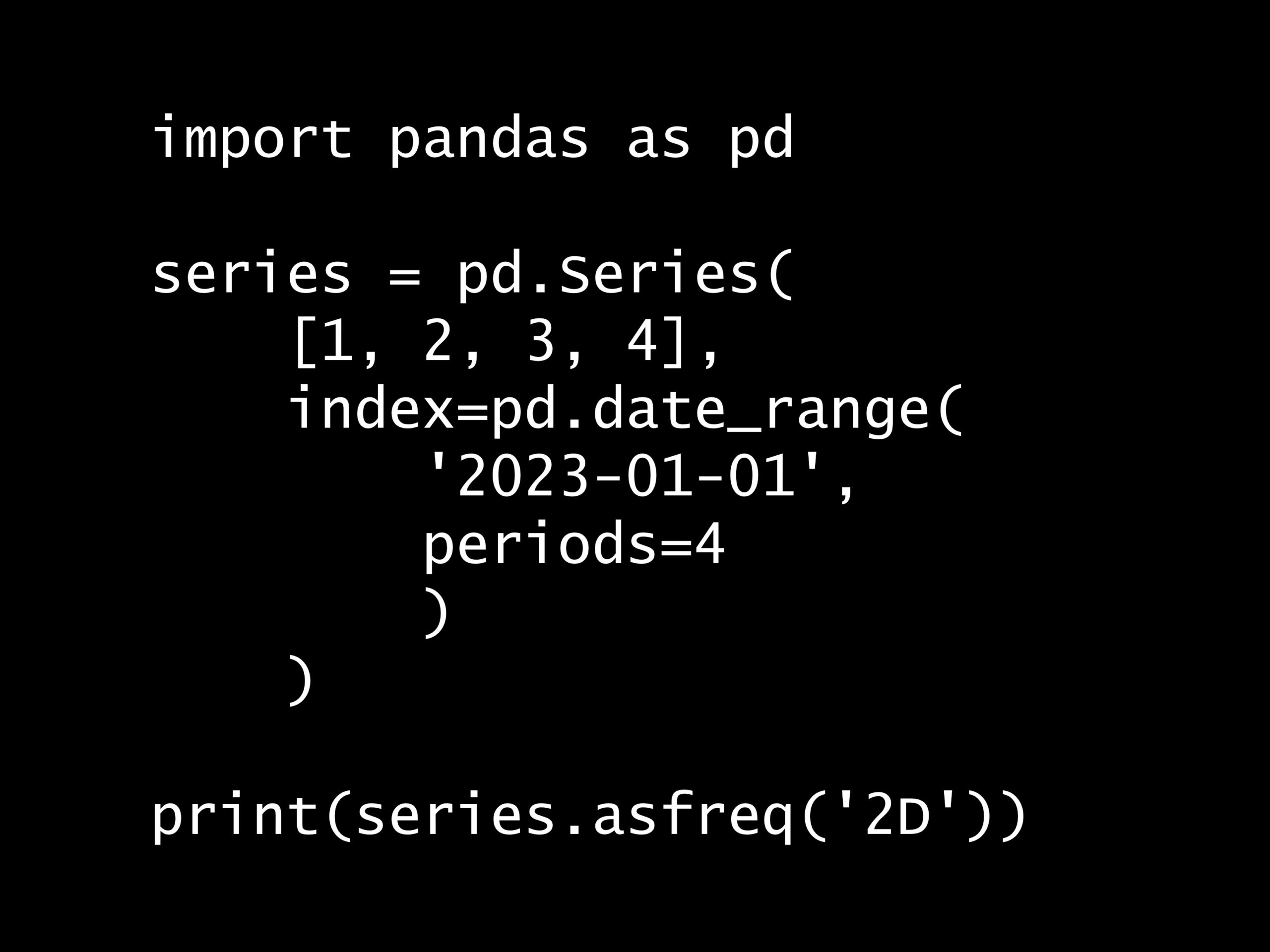
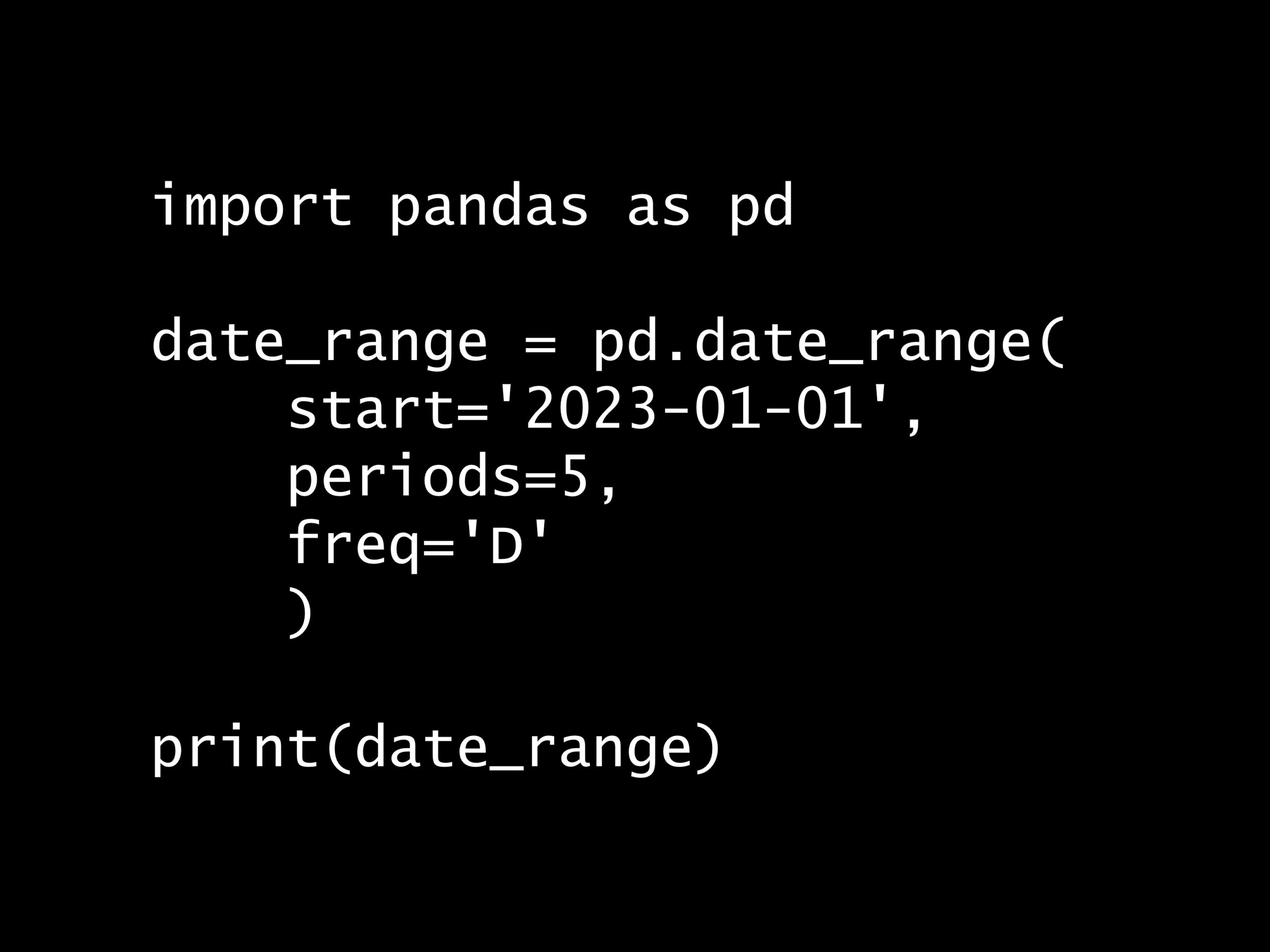
次の Python コードの出力はどれでしょうか? Python コード: import pandas as pd df = pd.DataFrame( {'A': [1, 2, 3, 4&#...
Excelを使用する際、平均値を取得することがよくあります。このような場合に便利なのが、AVERAGE関数です。 2003以降のバージョンに対応しています。 AVERAGE関数を使用することで、手動で数値を比較する必要が...
非線形最適化は、ビジネス、工学、データサイエンスなど、多岐にわたる分野で不可欠なツールとなっています。 この複雑で魅力的な領域に飛び込む準備はできていますか? 今回は、線形最適化から非線形最適化への遷移、非線形最適化の基...
次の Python コードの出力はどれでしょうか?
回答の選択肢:
A. 30
B. 30, 75
C. 50, 90
D. 75
次の Python コードの出力はどれでしょうか?
次の Python コードの出力はどれでしょうか?
線形最適化は、複雑な意思決定問題を数学的に定式化し、最適な解を見つけるための強力なツールです。 ビジネスの世界では、資源が限られている中で最大の利益を得る方法を見つける必要があります。また、工学の分野では、与えられた条件...
経営効率性は、今日の競争が激しいビジネス環境において、企業が成功を収めるための鍵となる概念です。 しかし、多くの経営者や起業家は、自社の効率性をどのように測定し、どのように改善すればよいのかについて、具体的な答えを持って...
数理最適化とは、複雑な問題を数学的に解く鍵となる一連の手法です。 この第1回目の記事では、数理最適化の魅力と重要性を探りながら、その基本概念や応用例を紹介します。線形最適化と非線形最適化の違いを明らかにし、数学と現実世界...
先日の記事でIF関数を取り上げました。 IF関数で複数条件を指定する方法を紹介しましたが、条件が増えると複雑になってきます。 そこで、本記事では、IFS関数に関して、取り上げます。いずれの条件に合致しない場合に「その他」...
私たちの身の回りには、様々なデータが溢れています。 スマートフォンの操作履歴、SNSの投稿、オンラインショップの購入記録…… これらは日常的に集積される一部の例です。 現代のビジネスシーンにおいても、データは新しい価値を...
前回の記事『IF関数の使い方と解説 -単一条件の場合 –』では、単一条件でのIF関数の使用法を説明しました。 複数条件でIFを使用したいシーンがあります。 前回記事の未拝読の方向けに、前回記事『IF関数の使い方と解説 -...
データというキーワードが、現代ビジネスの進化と成長をリードしています。 このような現代、データ分析の現場に「エライ人」からある課題を投げられることがあります。 「このデータで、何ができそう?」 「このデータで、何かいい感...
Microsoft社が発表している「よく使われている関数トップ 10」にランクインしているIF関数を取り上げます。 下記はMicrosoft社が発表している「よく使われている関数トップ 10」の一部抜粋したものです。 関...
データ分析がビジネス戦略の核心となる現代。 しかし、分析結果が紙の上の数字に過ぎなくなってしまうこと、あるいはその結果と実際の実行が乖離してしまうケースは少なくありません。 なぜこれが起こるのか、そしてその乖離をどのよう...
先日、SUM関数シリーズを紹介しました。 SUMIF関数とSUMIFS関数を使えば、条件に応じた合計値を算出できました。 今回、その条件部分が曖昧になったときです。 例えば、 下記表から。「亀田製菓 亀田の柿の種 6袋詰...