Excel関数の種類を大まかに知っておきましょう。 なんとなく、こんな関数があったなと知っておくと、時間効率だけでなく、仕事のシーンで、あたふたすることなく、冷静に仕事を進められるからです。 また、社内外で…… 「〇〇な...
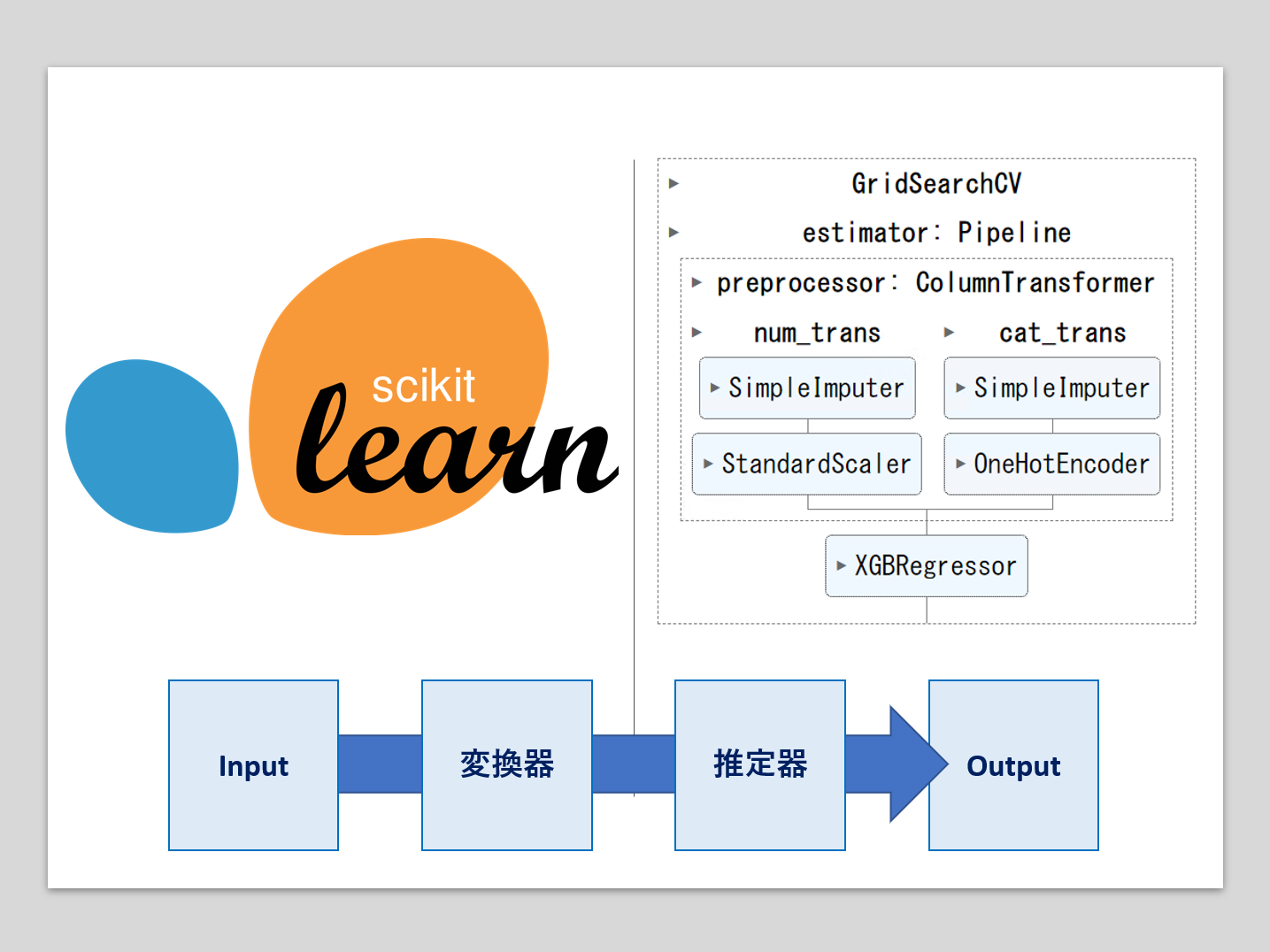
機械学習のパイプラインとは、複数の処理を直列に連結したものです。 最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Trans...
開催概要 日時: 2023年7月26日(水) 13:00~16:00 受講料: 25,000円(消費税込) 会場: JAGAT会員 14,300 円 /一 般 19,800 円 主催:JAGAT(公益社団法人 日本印刷技...
企業内のデータサイエンス組織の1つの役割として、データサイエンス技術を…… より良い商品の開発 より良いCX(カスタマー・エクスペリエンス)の実現 ……のために用い、ビジネスそのものを成長させる、というものがあります。 ...
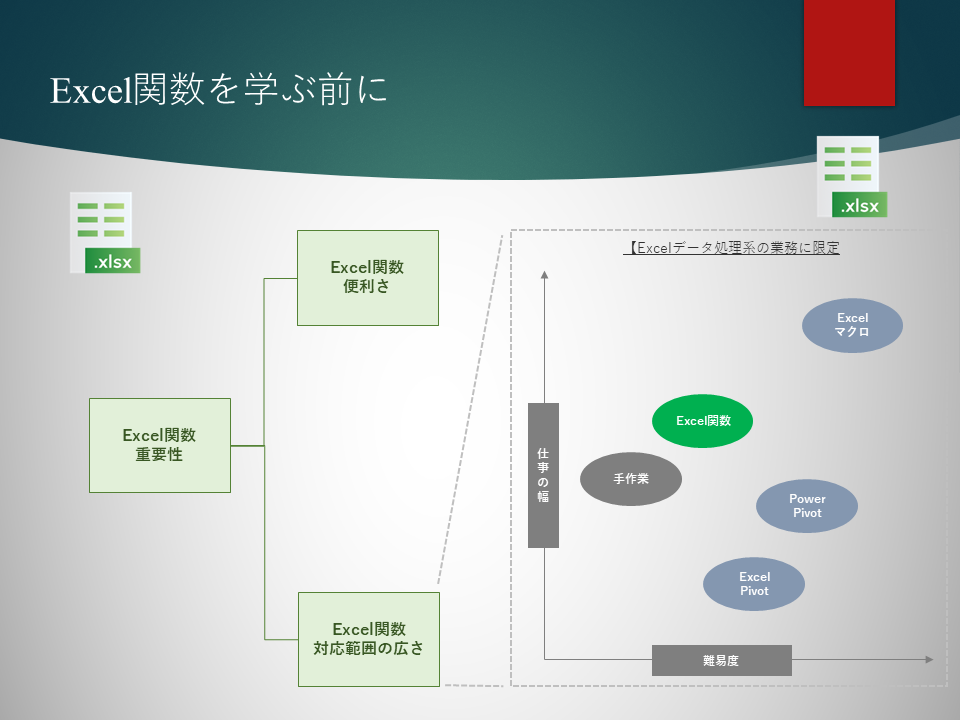
皆さんが最も馴染みがあり、最も仕事で関わりがある、ツールと言えば?? Excelがその一つではないでしょうか。
しかも、“最も馴染みがあり、最も仕事で関わりがある”ということは・・・ うまく使いこなすことで最も仕事の質が向上する可能性のあるツールであり、そのためビジネスパーソンにとって最も習得すべきツールといって...
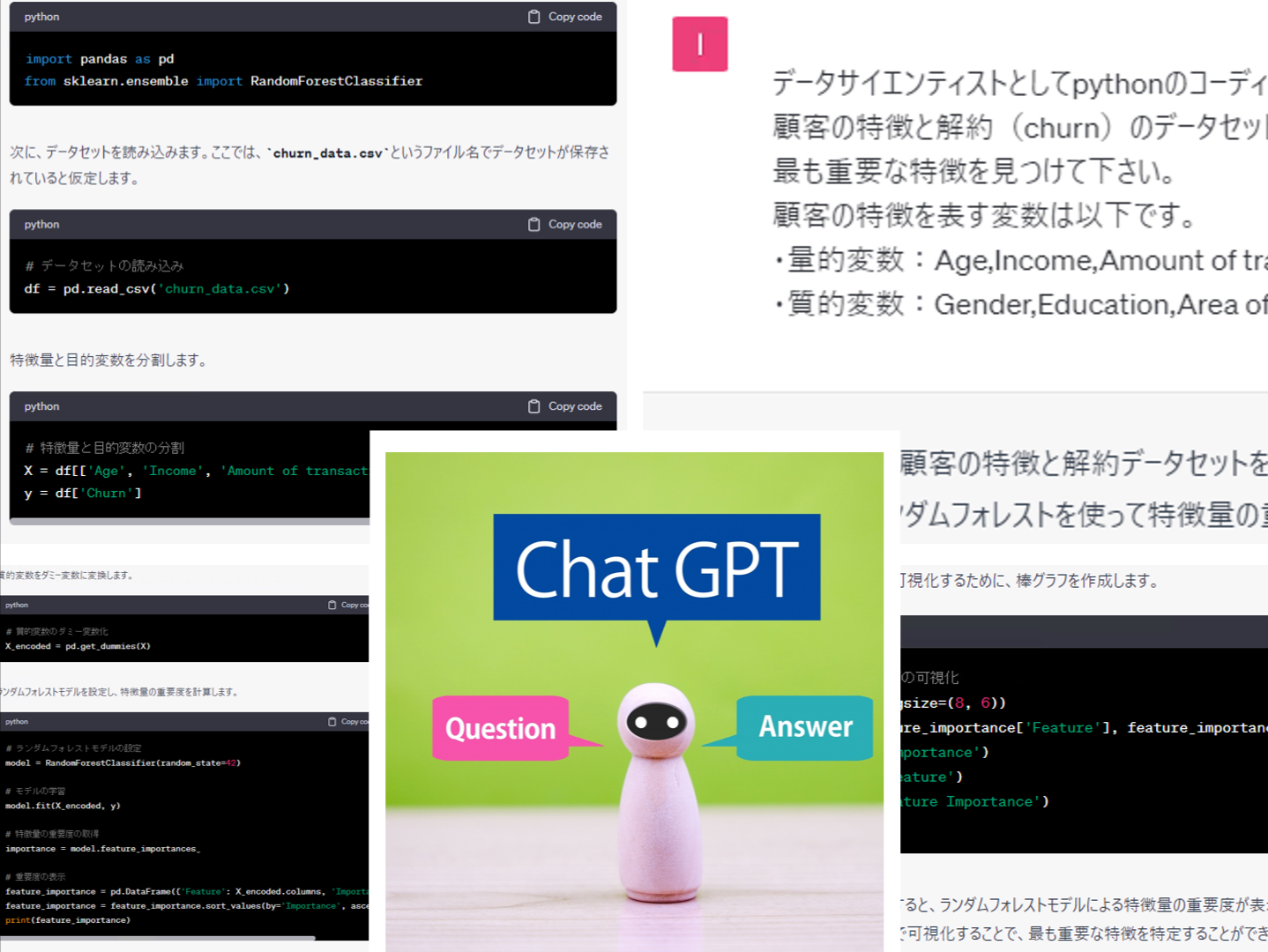
ChatGPTモデルは、 OpenAIによってトレーニングされたLLM(大規模な言語モデル)です。 プロンプトで話しかけると、人のように答えてくれます。テキストでですが…… そして何よりこのChatGPTは、優れたデータ...
企業内のデータサイエンス組織の1つの役割として、データサイエンス技術を…… より良い商品の開発 より良いCX(カスタマー・エクスペリエンス)の実現 ……のために用い、ビジネスそのものを成長させる、というものがあります。 ...
機械学習のパイプラインとは、複数の処理を直列に連結したものです。 最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Trans...
商品やサービスなどを開発し、それを売ることで収益を得るビジネスをしている企業は非常に多いです。 例えば、車を開発しディーラー経由で販売する、クラウドサービスを開発しサブスクリプションで提供する。 このような商品やサービス...
Pythonでデータをこねくり回すとき、よく利用するパッケージがPandasです。 Pandasを操作しながら、データ理解を進めている人も多いことでしょう。 OpenAIのChatGPTと連携することで、実現します。 で...
ChatGPTモデルは、 OpenAIによってトレーニングされたLLM(大規模な言語モデル)です。 プロンプトで話しかけると、人のように答えてくれます。テキストでですが…… そして何よりこのChatGPTは、優れたデータ...
最近大きな注目を集めているイノベーションの 1 つが、生成AI(Generative AI)です。 生成AI は創造的な限界を押し広げることを可能にし、さまざまな業界に広範囲に影響を与えるのではないかと、期待されています...
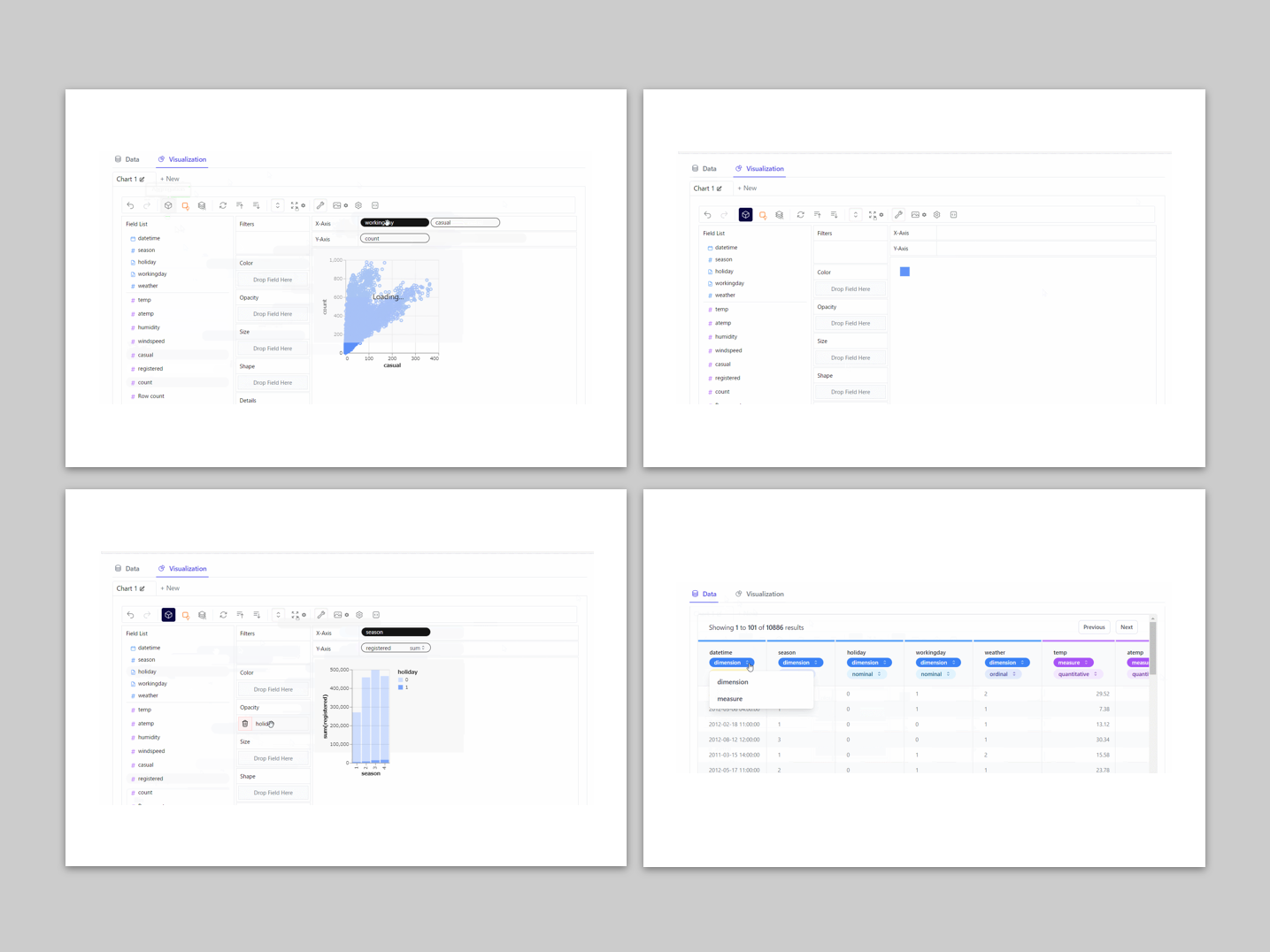
データを手に入れたとき、どのようなデータなのか理解する必要があります。 そのとき求められるのが、データを簡単に探索し分析できるユーザーフレンドリーなTableauのようなツールです。 しかし、それには多大なコストがかかり...
sktimeはPythonでよく使われている機械学習ライブラリsklearn(scikit-learn)と同じインターフェースで提供されているPythonの時系列ライブラリです。 sktimeでは2023.5.1時点で時...
伝わらなければ意味はない。 なぜなら、伝わらなければ、理解されないし、信用もされないし、一緒に何かをやろうともならないからです。 ビジネスにおいてプレゼンテーションスキルは非常な重要な基礎スキルですが、データサイエンスの...
データ分析をするとき、他人と会話しながら実施することがあります。 Pandas AIはそれを実現します。 このPandas AIは生成AI機能を備えており、データフレームの操作を会話相手に変身させることができます。 ただ...