
時系列データをビジネス活用するとき、最も期待される活用方法の1つが「データで近未来を予測しこれからのビジネス活動に活かす」というものです。
これは、需要予測や受注予測、LTV予測、離反予測、故障予測などの「〇〇予測」と呼ばれることが多いです。
では、近未来を予測しビジネス活動に活かすためには、何が必要でしょうか。
当然ながら、予測モデルが必要です。
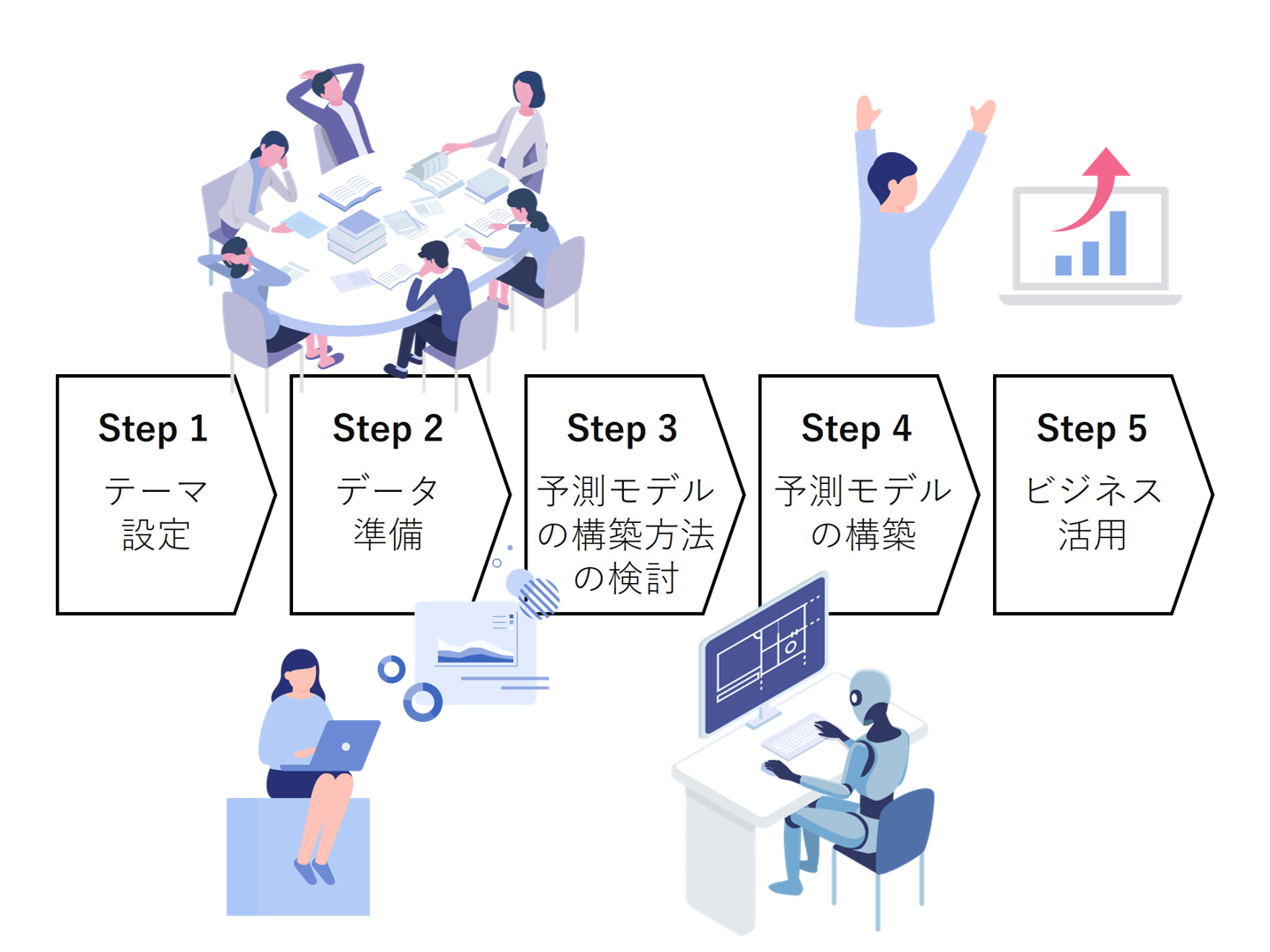
今回は、1変量の時系列データで予測モデルを構築する流れを、簡単に説明します。
- Step1:テーマ設定
- Step2:データ準備
- Step3:予測モデルの構築方法の検討
- Step4:予測モデルの構築
- Step5:ビジネス活用
時系列だからといって特別なわけではなく、よくある機械学習のモデル構築の流れと大差はありません。
Contents
Step 1でデータ活用ストーリーを描きStep 5で実現する
Step 1とStep 5に登場する「データ活用ストーリー」とは何でしょうか。
それは、データがビジネス価値を生み出すまでの流れや関係性を描写したものです。
非常に重要なものです。
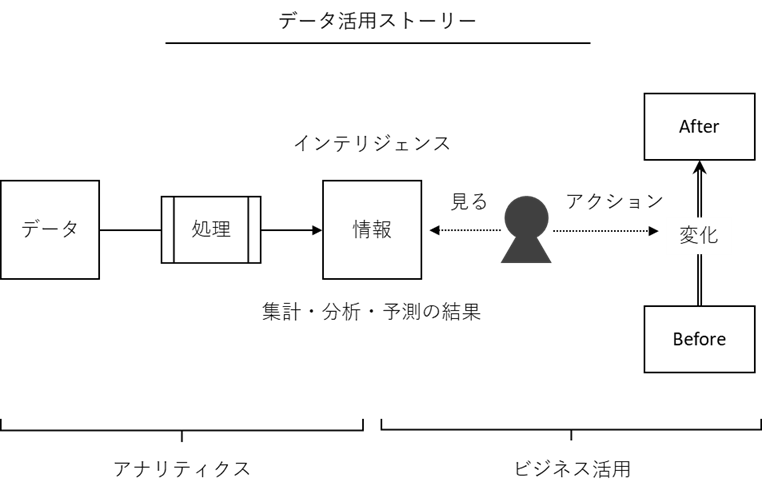
Step 1で、「データからどうビジネス価値を出すのか」というグランドデザインを「データ活用ストーリー」としてざっくり描きます。
その描いた「データ活用ストーリー」は、Step 5で実現します。
Step 1では、単に「データ活用ストーリー」を描くだけでなく、「どのよう予測モデルを構築すればいいのか」も併せて検討します。
ちなみに、Step 1のテーマ設定(データ活用ストーリーの描写)で失敗すると、その後のステップはすべて無駄になるケースが多いです。
無駄になるとは、ビジネスの現場で価値を生み出さない、ということです。
Step 2の「データの準備」
Step 2は、予測モデル構築に必要なデータを準備するステップです。
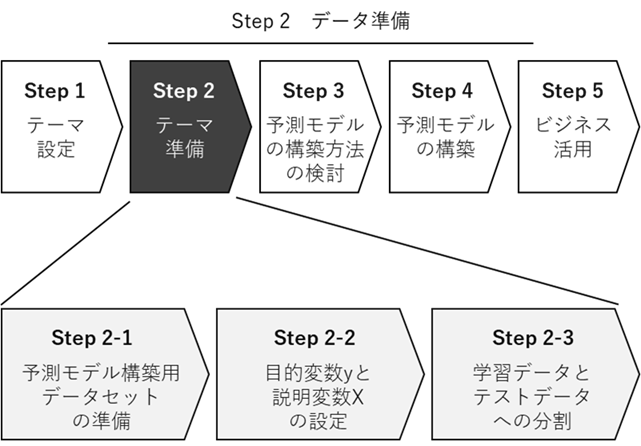
Step 2-1:予測モデル構築用データセットの準備
Step 2-1は地味に大変です。
データ統合やデータ抽出といったことや、新しい変数を作ったり逆に絞り込んだりする「特徴量エンジニアリング」(特徴量生成や特徴量選択など)を実施します。
さらに、基本統計量(平均や分散、など)の計算やグラフ化などを通した「データ理解」などが含まれます。
Step 2-2:目的変数yと説明変数Xの設定
Step 2-2では、Step 2-1で準備したデータセットの変数の中から、予測モデルの目的変数yと説明変数Xを選定します。
目的変数yが受注の金額などの量的変数の場合には「回帰問題」、目的変数yが受注の有無(1:受注、0:失注)などの質的変数の場合には「分類問題」と呼びます。
回帰問題なのか分類問題なのかで、予測モデルのタイプや評価指標などが異なりますので気をつけましょう。
Step 2-3:学習データとテストデータへの分割
Step 2-3で、Step 2-1で準備したデータセットを「学習データ」と「テストデータ」に分割します。
この「学習データ」と「テストデータ」の2つのデータセットは、次のStep 3で利用します。
もっともシンプルな分割方法は、データセットを2分割するホールドアウト法です。
時系列データの場合、通常はランダムに2分割することは許されません。時系列性(過去の目的変数や説明変数の影響)が失われることが多いからです。
よくあるのが、ある時点を境に前半を学習データと、後半をテストデータに分割する時系列ホールドアウト法です。
Step 3の「予測モデルの構築方法の検討」
予測モデルは、実務で使う前にその構築方法を検討する必要があります。
Step 3で、「学習データ」で予測モデルを学習し、学習した予測モデルを「テストデータ」で評価する、ということを実施しながら、どうすればより良い予測モデルが構築できるのかを検討していきます。
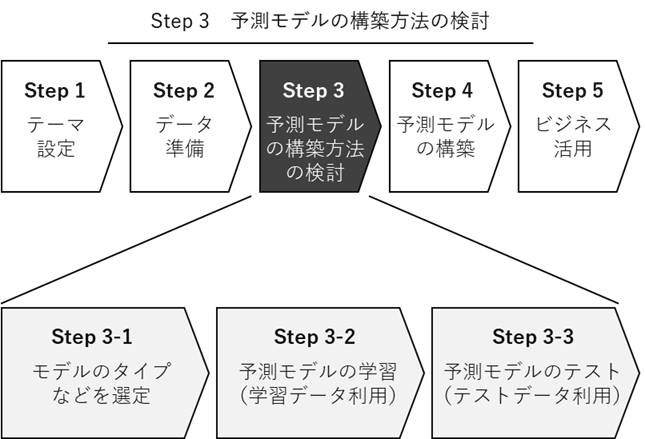
Step 3-1:モデルのタイプなどを選定
Step 3-1でモデルのタイプ(予測モデルを構築するアルゴリズム)などを選定します。
「モデルのタイプの選定」とは、どのモデルのタイプで予測モデルを構築するのかを決める、ということです。
もちろん複数選定しても問題ありません。
ちなみに、モデルのタイプ(予測モデルを構築するアルゴリズム)とは、「線形回帰」「決定木」「XGBoost」などのテーブルデータ系の数理モデルや、「ARIMA」「TBATS」「Prophet」などの時系列系の数理モデルのことです。
モデルのタイプによっては、ハイパーパラメータというものを持つことがあります。
このハイパーパラメータをどのように扱うのかも、ここで検討しておく必要があります。
- チューニングするハイパーパラメータの選定:どのハイパーパラメータをチューニングし、どのハイパーパラメータをチューニングしないのか
- ハイパーパラメータのチューニング方法:チューニングの探索範囲(値の候補)をどのようし設定し、どのような方法でチューニングするのか
Step 3-2:予測モデルの学習(学習データ利用)
Step 3-2で、「学習データ」を使い予測モデルを学習していきます。
選定したモデルが複数あれば、少なくともモデルのタイプの数だけ予測モデルを学習します。
ハイパーパラメータをチューニングする場合、最大でもそのハイパーパラメータの「値の候補」の数だけ予測モデルを学習します。
要は、たくさんの予測モデルをここで学習し作っていきます。
たくさんの予測モデルの学習を通し……
- どのモデルで予測モデルを作るのがいいのか
- どのハイパーパラメータの値がいいのか
- どの説明変数の組み合わせがいいのか
……などをここで検討します。
Step 3-3:予測モデルのテスト(テストデータ利用)
Step 3-3で、学習し構築した予測モデルをテストデータで使いテストを行い、実務で使う予測モデルを検討していきます。
このとき、通常は予測値と実測値の乖離の小さな高精度な予測モデルを選びます。
しかし、高精度な予測モデルが使えるモデルとは限りません。
例えば、1日後に出力される高精度な予測結果よりも、1分以内に出力されるまぁまぁの精度の予測結果が好まれたりします。
その辺りも念頭に入れておきましょう。
Step 4の「予測モデルの構築(全データ利用)」
予測モデルの構築方法がStep 3で固まれば、次に全てのデータを利用し予測モデルを学習し求めます。
この予測モデルをビジネス現場で活用していきます。
「全データ利用」とは、手元にあるデータすべてという意味です。
少なくとも「学習データ」と「テストデータ」の両方を使います。
さらに、新たに蓄積したデータも含まれます。
新たなデータがある程度溜まった段階で、再学習し常に予測モデルを更新していきます。
今回のまとめ
今回は、「時系列データを使った予測モデル構築の流れ」のお話しをしました。
時系列データをビジネス活用するとき、最も期待される活用方法の1つが「データで近未来を予測しこれからのビジネス活動に活かす」というものです。
これは、需要予測や受注予測、LTV予測、離反予測、故障予測などの「〇〇予測」と呼ばれることが多いです。
では、近未来を予測しビジネス活動に活かすためには、何が必要でしょうか。
当然ながら、予測モデルが必要です。
今回は、1変量の時系列データで予測モデルを構築する流れを、簡単に説明します。
- Step1:テーマ設定
- Step2:データ準備
- Step3:予測モデルの構築方法の検討
- Step4:予測モデルの構築
- Step5:ビジネス活用
時系列だからといって特別なわけではなく、よくある機械学習のモデル構築の流れと大差はありません。
ただ、学習データとテストデータに分割するホールドアウト法や、モデル選択やハイパーパラメータ調整で実施するクロスバリデーション、モデルを使った予測(未来を予測する複数先予測)などは通常のテーブルデータ系のデータと異なり時系列性を加味する必要がありますので、注意しましょう。