AI活用の前に立ちはだかる壁の1つが、AIを構成する機械学習モデル(数理モデル)を作るためのデータ不足です。 データの量や質が不十分だと、数理モデルの構築は思うようにいきません。 そのあたりを意識した企業は、10~20年...
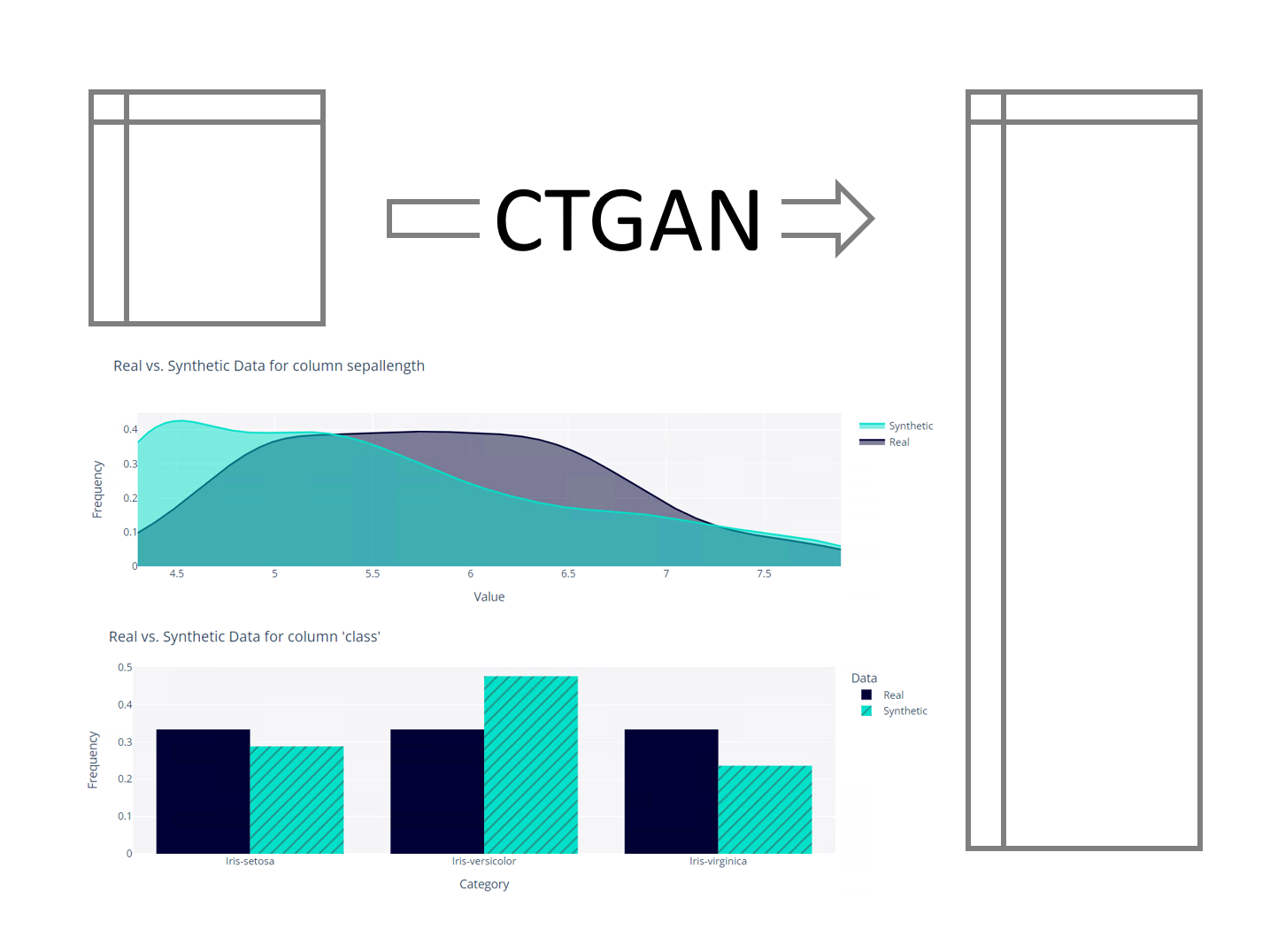
テーブルデータを生成するGANもあります。CTGAN(Conditional General Adversarial Networks)です。 あらかじめ準備されたデータをもとに、擬似的なテーブルデータを生成することがで...
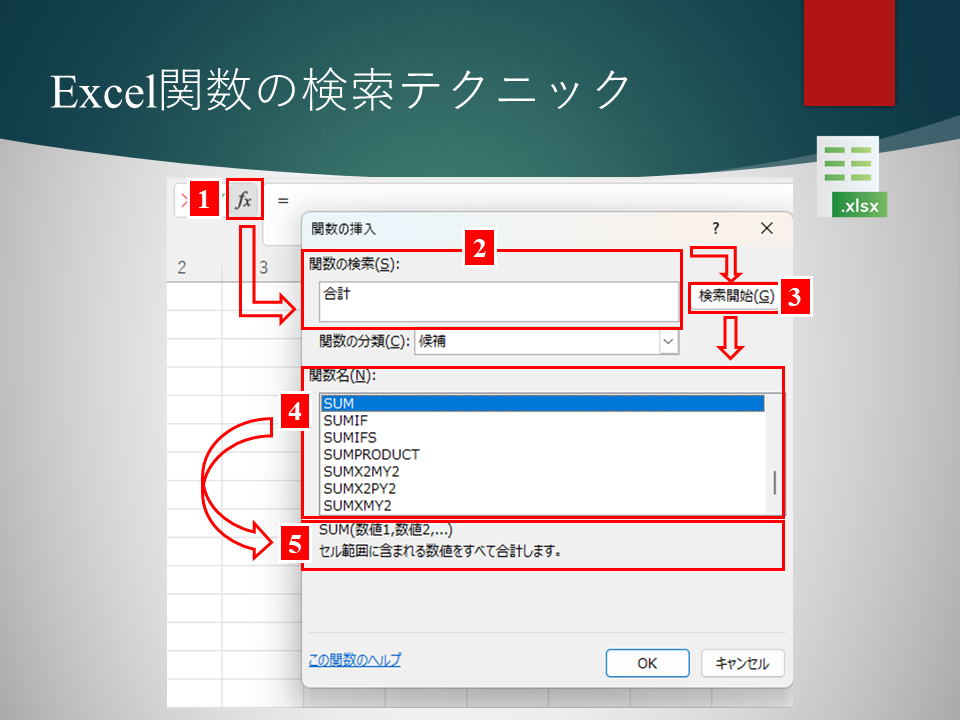
先日の記事『Excel関数にはそれぞれ構文がある』『Excel関数の引数マスターになろう』は、理解できましたでしょうか。 全てのExcel関数名も暗記し、全てのExcel関数の構文を覚えることがマストのよう...
テーブルデータを生成するGANもあります。CTGAN(Conditional General Adversarial Networks)です。 あらかじめ準備されたデータをもとに、擬似的なテーブルデータを生成することがで...
分析で利用するテーブルデータが少ないことがあります。 もう少し増やせないだろうか、と夢見ることも少なくないでしょう。 ここ最近、色々な生成AIが登場してきました。 そこで使われている技術の1つにGAN(敵対的生成ネットワ...
ビジネスの世界は、売上データをはじめ時系列データで溢れています。 売上や利益のような時系列データに対し…… もし、ある施策を実施していたら、売上や利益がどのように変化しただろうか? もし、ある施策を実施したら、売上や利益...
Jupyter AI は、JupyterLab の拡張機能で、色々なAI機能が提供されています。 その中で、データサイエンティストとして嬉しいのが、コード生成機能です。 会話しながら、Pythonコーディングを実施できま...
Jupyter AI は、JupyterLab の拡張機能で、色々なAI機能が提供されています。 その中で、データサイエンティストとして嬉しいのが、コード生成機能です。 会話しながら、Pythonコーディングを実施できま...
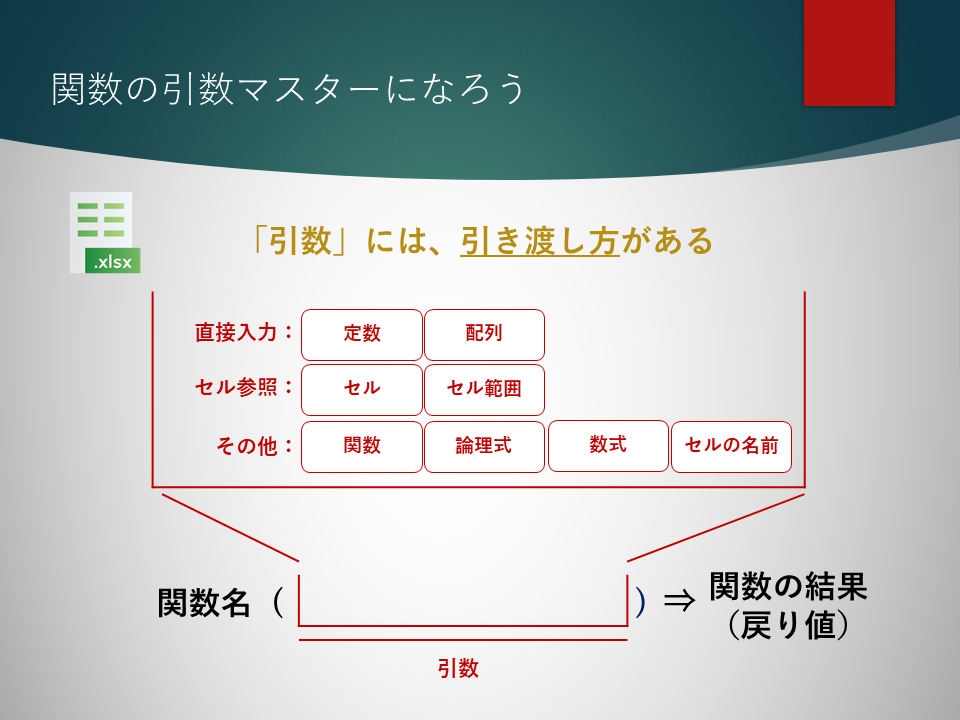
本記事では、Excel関数の引数を考える上で、2つのポイント「引き渡す値」「引き渡す方」に関して詳しく解説します。 いわゆる・・・ 「引き渡す値」=何を、「引き渡す方」=どのように です。 そもそも、Ex...
ChatGPT は優れたプログラマーでもあります。 そのため、Pythonのプログラミングするとき、ChatGPT に質問した体験をした方も多いことでしょう。 例えば、Jupyter Lab でプログラミングをしながら、...
企業は、消費者に新しい価値を提案することで、企業は市場シェアを拡大(または確保)し、全体的な売上と利益の成長を享受したいと考えています。 そのために、既存製品をリニューアルした新バージョンをリリースしたり、新しいラインナ...
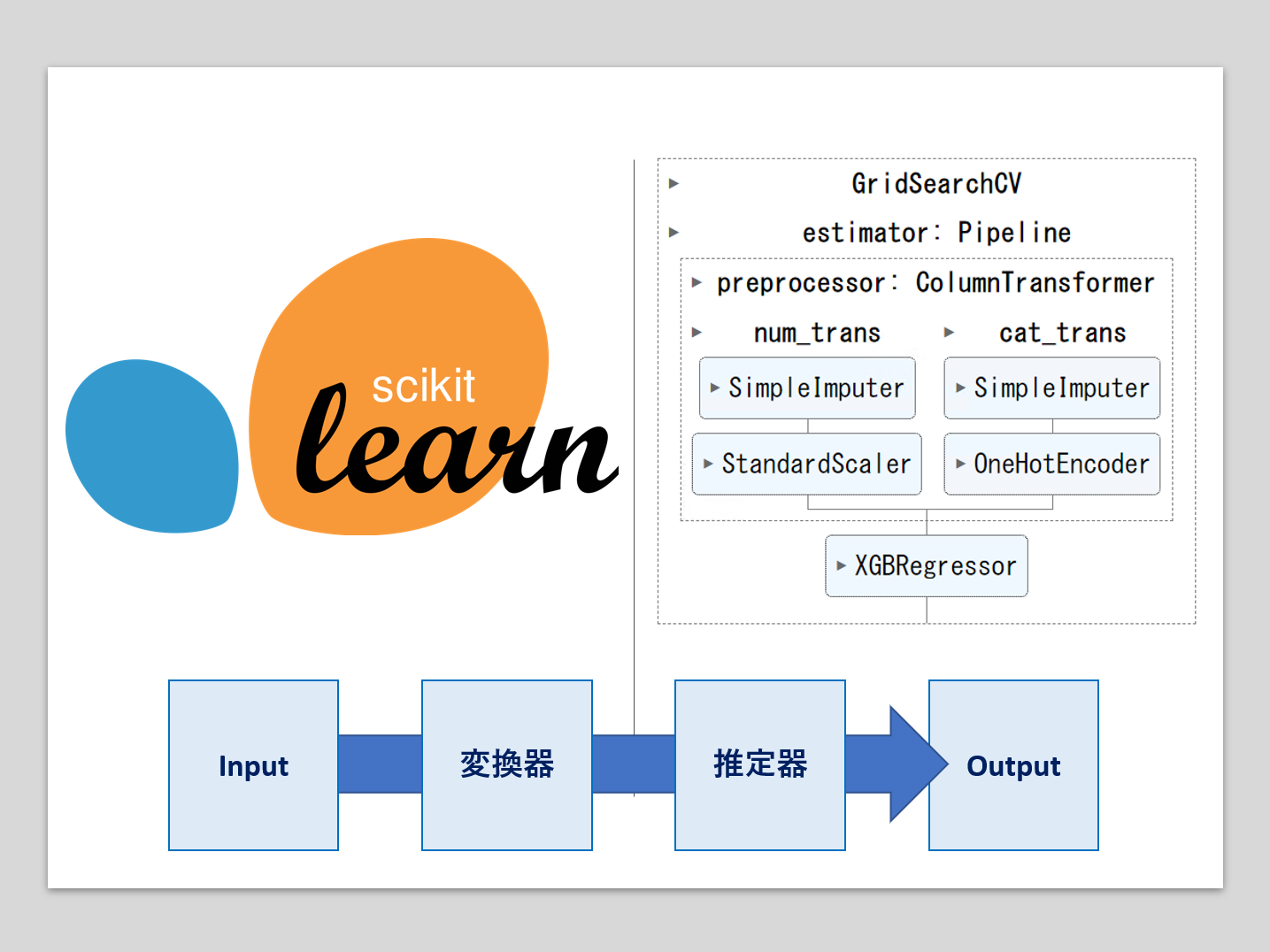
機械学習のパイプラインとは、複数の処理を直列に連結したものです。 最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Trans...
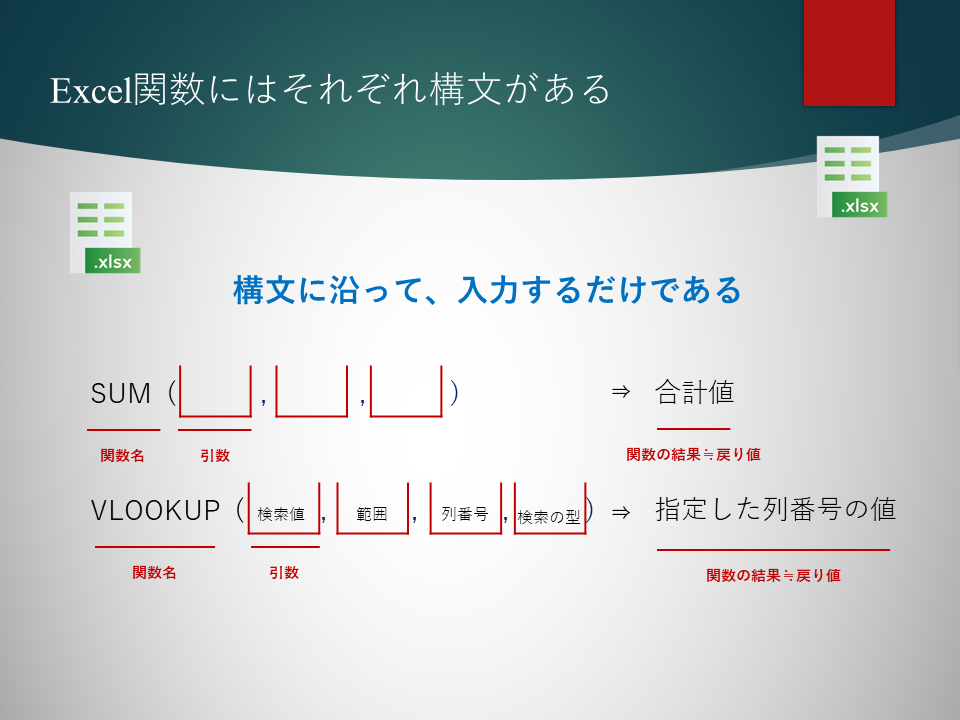
Excel関数には、それぞれ構文があります。 例えば、SUM関数、VLOOKUP関数、INDEX関数のそれぞれに、固有の構文が存在します。 構文といっても、それほど難しいものではありません。 「あぁ、そんなことか」 「そ...
分析で利用するテーブルデータが少ないことがあります。 もう少し増やせないだろうか、と夢見ることも少なくないでしょう。 ここ最近、色々な生成AIが登場してきました。 そこで使われている技術の1つにGAN(敵対的生成ネットワ...
ビジネス活動において、データによる因果推論の重要性は高まっています。 データによる因果推論は、データと分析に基づいた客観的な意思決定を促進し、ビジネス成果を最大化するからです。 例えば…… 効果的な意思決定と戦略の策定 ...
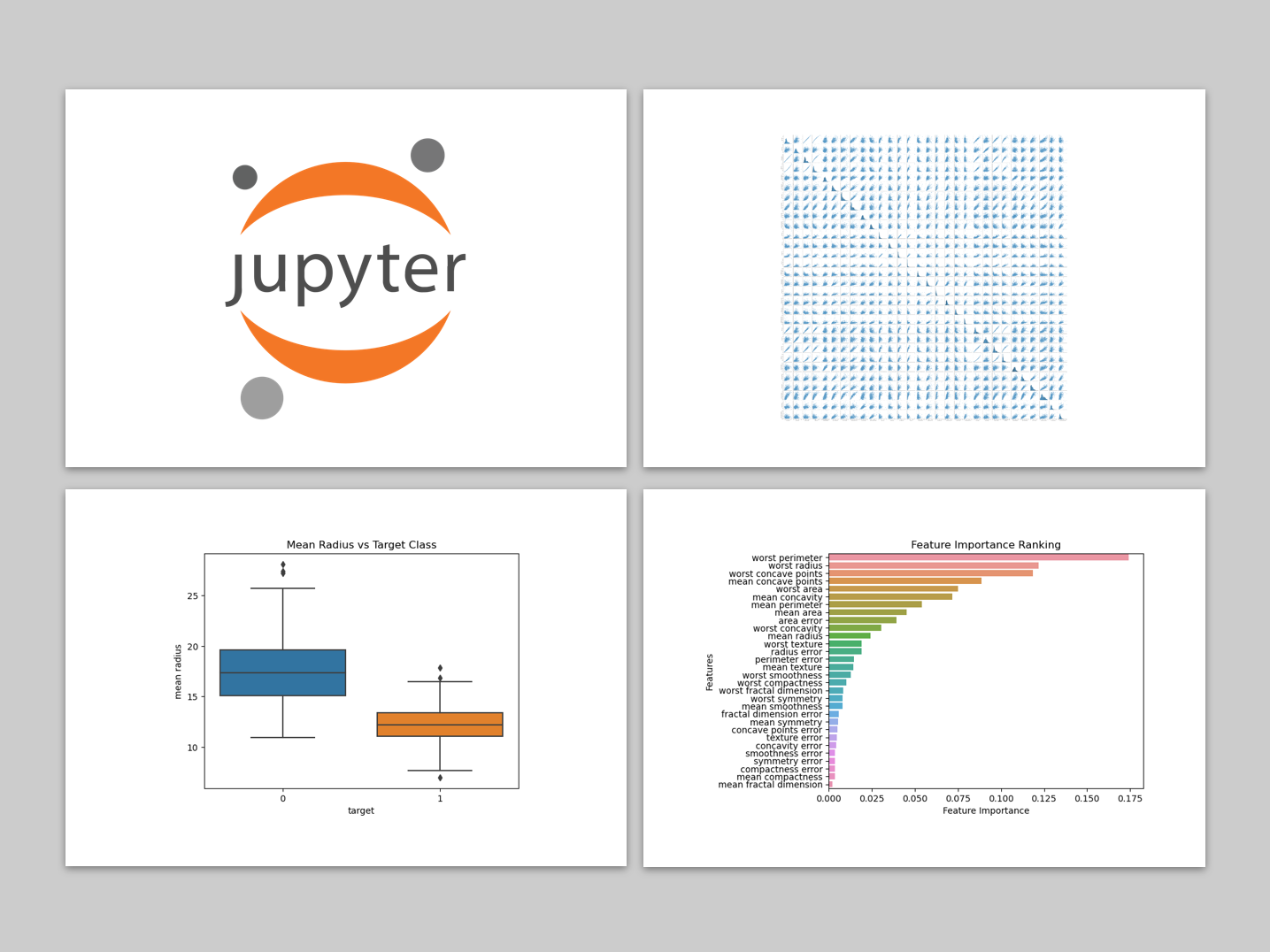
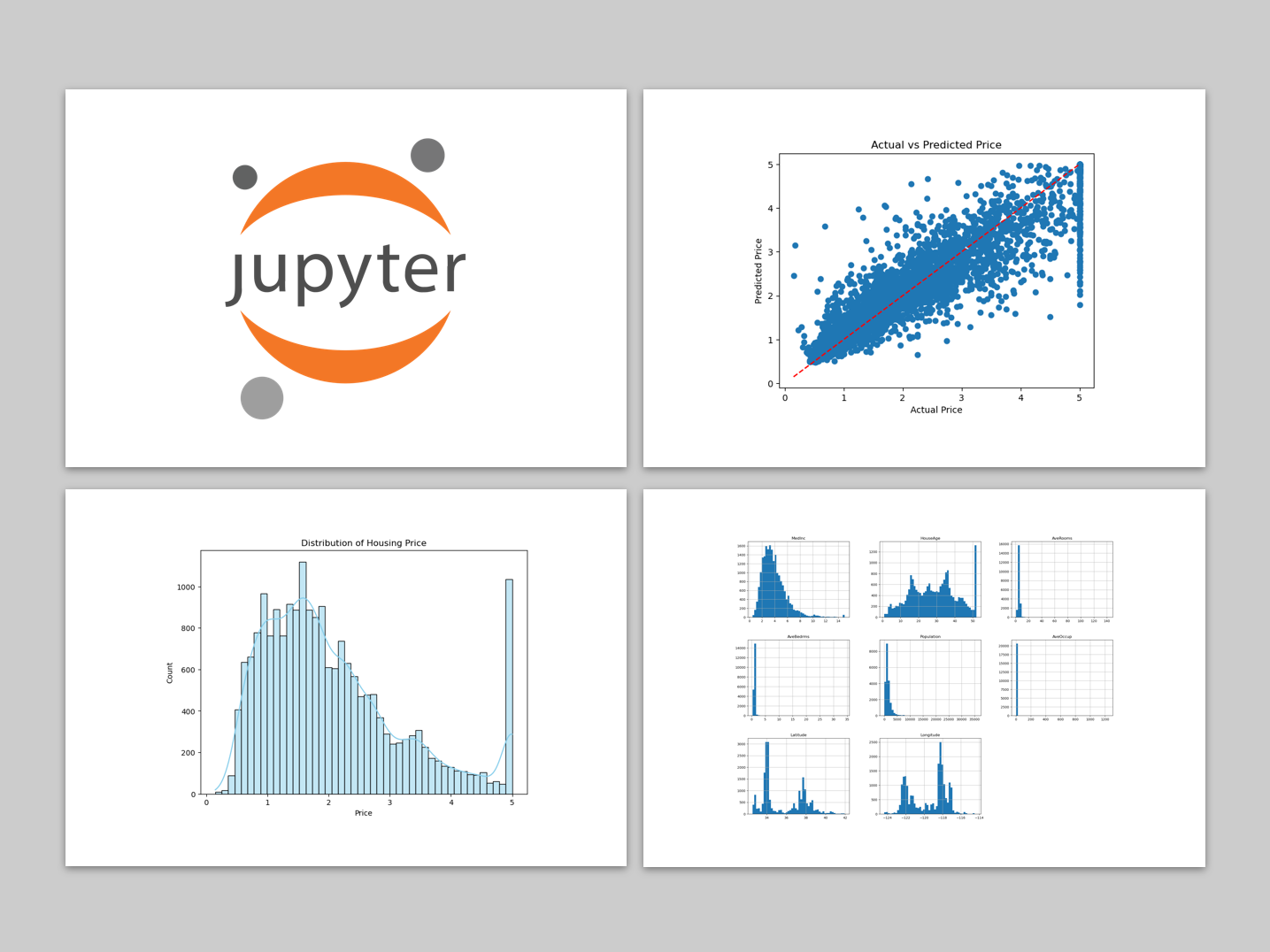
データを入手したとき、最初に実施するタスクの1つが、探索的データ分析 (EDA) です。 探索的データ分析 (EDA) は、データをより深く理解するプロセスにおける重要なタスクです。 データの大まかな概要を把握するための...