

私たちの身の回りには、数字では表せないデータがたくさんあります。
たとえば「好きな食べ物は何ですか?」という質問に対する答えは、「カレー」や「パスタ」といった名前で表されるもので、平均を取ったり計算したりすることはできません。
このようなデータを、カテゴリカルデータ(質的データ)と呼びます。
では、こうしたデータから何が分かるのでしょうか。
たとえば、大学の食堂で学部ごとに好まれるメニューに違いがあるかどうかを考えてみます。
工学部はカレー、文学部はパスタといったイメージを持つ人もいるかもしれませんが、それが本当かどうかは、データで確かめる必要があります。
学部とメニューの関係を整理する方法として、まずクロス集計表があります。
ただし、表だけでは全体の関係が直感的に分かりにくいこともあります。
そこで使われるのが、コレスポンデンス分析(Correspondence Analysis:CA)です。
これは、カテゴリ同士の関係を二次元の図として表し、どの組み合わせが強く結びついているのかを一目で分かるようにする手法です。
この回では、クロス集計表から出発し、コレスポンデンス分析によってカテゴリの関係を「見える化」する考え方を紹介します。
Contents
準備:ライブラリのインストールとインポート
まずは分析に必要なPythonライブラリを読み込みましょう。
今回のポイントは prince というライブラリです。
コレスポンデンス分析を手軽に実行できる便利なパッケージで、pip install prince でインストールできます。
また、グラフ内で日本語を正しく表示するために japanize_matplotlib も使います。
以下、コードです。
# 基本ライブラリ import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import japanize_matplotlib # グラフの日本語表示に必要 # コレスポンデンス分析用 import prince
もしエラーが出た場合は、例えばpip install prince japanize_matplotlib などを実行してから再度試してみてください。
ステップ1:クロス集計表をつくる
コレスポンデンス分析の出発点はクロス集計表(分割表)です。
クロス集計表とは、2つのカテゴリ変数の組み合わせごとにデータの件数を集計した表のことです。
たとえば「学部」と「食堂で選んだメニュー」の2つのカテゴリについて、どの組み合わせが何人いたかを数えた表がクロス集計表になります。
それでは、架空のアンケート調査データを作ってみましょう。
ある大学の食堂で、4つの学部の学生に「今日選んだメニュー」を聞いた結果です。
以下、コードです。
# 学部(行)× メニュー(列)のクロス集計表を作成
data = {
'カレー': [45, 30, 25, 35],
'ラーメン': [40, 25, 20, 30],
'パスタ': [20, 35, 40, 25],
'定食': [35, 30, 25, 40],
'サラダ': [10, 30, 40, 20]
}
index = ['工学部', '経済学部', '文学部', '理学部']
cross_table = pd.DataFrame(data, index=index)
print("【クロス集計表:学部別メニュー選択(人数)】")
print(cross_table)
print(f"\n合計人数: {cross_table.values.sum()}人")
以下、実行結果です。
【クロス集計表:学部別メニュー選択(人数)】
カレー ラーメン パスタ 定食 サラダ
工学部 45 40 20 35 10
経済学部 30 25 35 30 30
文学部 25 20 40 25 40
理学部 35 30 25 40 20
合計人数: 600人
4学部 × 5メニューの表が表示されました。
たとえば「工学部でカレーを選んだ人は45人」「文学部でパスタを選んだ人は40人」といった情報が読み取れます。
しかし、こうして数字の表を眺めるだけでは、学部とメニューの間にどんな関係があるのかを直感的につかむのは意外と難しいものです。
ステップ2:ヒートマップで「色」にしてみる
数字の羅列は見づらいので、まずは定番の可視化手法であるヒートマップを試してみましょう。
ヒートマップは、値の大小を色の濃淡で表現するグラフです。
以下、コードです。
# ヒートマップの作成
plt.figure(figsize=(10, 6)) # 図のサイズを指定
sns.heatmap(
cross_table, # データフレームをヒートマップに
annot=True, # セルに値を表示
fmt='d', # 整数として表示
cmap='YlOrRd', # カラーマップ(黄色〜赤)
linewidths=0.5, # セルの区切り線の太さ
cbar_kws={'label': '人数'} # カラーバーのラベル
)
plt.title('学部別メニュー選択のヒートマップ') # タイトル
plt.xlabel('メニュー') # x軸ラベル
plt.ylabel('学部') # y軸ラベル
plt.tight_layout() # レイアウトの自動調整
plt.show() # 図を表示
以下、実行結果です。
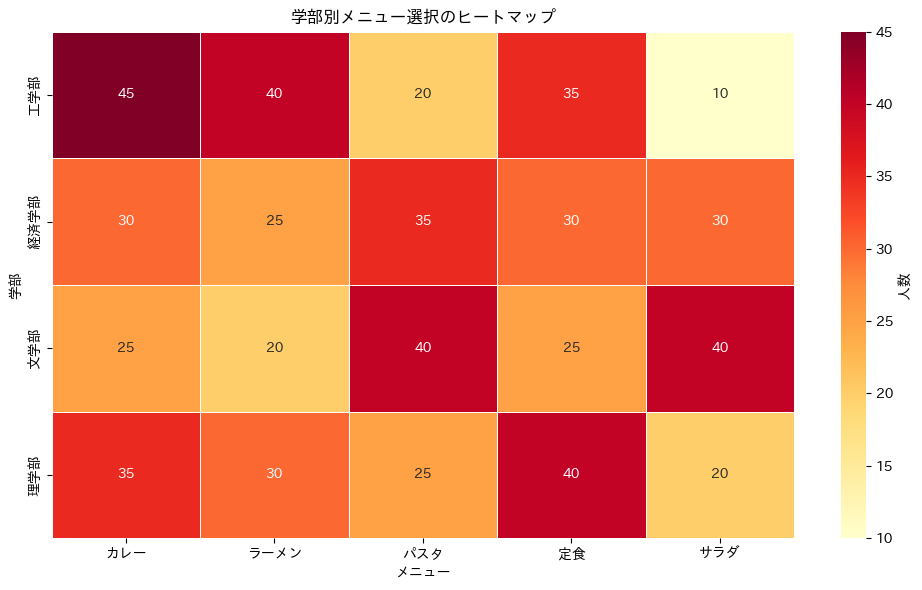
色が濃い(赤い)セルほど人数が多いことを示しています。
ぱっと見で「工学部はカレーの色が濃いな」「文学部はパスタとサラダが濃いな」といった傾向がわかります。
ヒートマップはわかりやすい可視化手法ですが、次のような疑問に答えるのは苦手です。
- どの学部とどのメニューが「近い」関係にあるのか? (工学部にとっての「カレー」と「ラーメン」、どちらがより特徴的?)
- 学部どうしの食の好みはどれくらい似ているのか? (工学部と理学部は似ている?全然違う?)
- 全体のパターンを一目で俯瞰できないか? (「こっちのグループは肉系、あっちは野菜系」みたいな大きな構造を見たい)
ヒートマップではセルを一つずつ見比べる必要があり、カテゴリが増えるほど全体像がつかみにくくなります。
ここにコレスポンデンス分析の出番があります。
ステップ3:コレスポンデンス分析で「マップ」にする
コレスポンデンス分析のアイデア
コレスポンデンス分析は、クロス集計表に出てくる行(たとえば学部)と列(たとえばメニュー)を、同じ2次元の図の上に点として配置する分析方法です。
1960年代に、フランスの統計学者ジャン=ポール・ベンゼクリによってまとめられました。
「コレスポンデンス」という言葉には「対応」という意味があり、学部とメニューのように、2つのカテゴリがどのように結びついているかを見ることが目的です。
考え方はとてもシンプルで、図の中で近くに配置された点どうしほど、関係が強いと考えます。
そのため、ある学部とあるメニューが近くに描かれていれば、「その学部の学生は、そのメニューを好む傾向がある」と読み取ることができます。
prince ライブラリでコレスポンデンス分析を実行する
それでは、実際にコレスポンデンス分析を実行してみましょう。
prince ライブラリを使えば、わずか数行で分析が完了します。
以下、コードです。
# コレスポンデンス分析のインスタンス化
ca = prince.CA(
n_components=2,
random_state=42
)
# コレスポンデンス分析の実行
ca = ca.fit(cross_table)
print(
"第1次元の寄与率: "
f"{ca.percentage_of_variance_[0]:.1f}%"
)
print(
"第2次元の寄与率: "
f"{ca.percentage_of_variance_[1]:.1f}%"
)
print(
"累積寄与率: "
f"{sum(ca.percentage_of_variance_[:2]):.1f}%"
)
以下、実行結果です。
第1次元の寄与率: 95.7% 第2次元の寄与率: 4.1% 累積寄与率: 99.8%
prince.CA(n_components=2) で「2次元に圧縮する」コレスポンデンス分析オブジェクトのインスタンスを作り、.fit() でクロス集計表を渡すだけです。
実行すると、各次元の寄与率が表示されます。
寄与率とは「その次元がデータの変動(情報)をどれだけ説明しているか」を表す指標で、累積寄与率が高いほど、2次元マップで元のデータをうまく要約できていることを意味します。
目安として70%以上あれば、2次元での可視化は十分信頼できるとされています。
ステップ4:行座標と列座標を確認する
コレスポンデンス分析は、行(学部)と列(メニュー)それぞれに「座標」を割り当てます。
この座標が2次元マップ上の位置になります。
まずは数値で確認してみましょう。
以下、コードです。
# 行座標(学部の座標)
row_coords = ca.row_coordinates(cross_table)
row_coords.columns = ['次元1', '次元2']
print("【行座標(学部)】")
print(row_coords.round(4))
print()
# 列座標(メニューの座標)
col_coords = ca.column_coordinates(cross_table)
col_coords.columns = ['次元1', '次元2']
print("【列座標(メニュー)】")
print(col_coords.round(4))
以下、実行結果です。
【行座標(学部)】
次元1 次元2
工学部 0.3665 -0.0595
経済学部 -0.1385 -0.0050
文学部 -0.3547 -0.0269
理学部 0.1267 0.0914
【列座標(メニュー)】
次元1 次元2
カレー 0.2155 -0.0397
ラーメン 0.2529 -0.0466
パスタ -0.2618 -0.0231
定食 0.1379 0.1027
サラダ -0.4469 0.0013
各学部・各メニューに「次元1」「次元2」の2つの値(座標)が付いています。
これらの値をそのまま散布図の x座標・y座標として使えば、コレスポンデンス分析のマップが完成します。
座標の正負にも意味があります。
次元1の値が大きい学部と大きいメニューは「同じ方向にいる=関連が強い」と読めますし、逆に正と負に分かれていれば「対照的な関係」にあることを示唆します。
ステップ5:コレスポンデンス分析マップを描く
いよいよ今回のハイライト、2次元マップの作成です。
学部(●)とメニュー(▲)を同じ平面上にプロットし、その位置関係から「どの学部がどのメニューと結びついているか」を視覚的に読み取ります。
以下、コードです。
# 図の枠(Figure)と描画領域(Axes)を作成
fig, ax = plt.subplots(figsize=(10, 8))
# 行ラベル(学部)を順番に取り出す
for i, faculty in enumerate(cross_table.index):
x, y = row_coords.iloc[i] # 学部の座標(次元1, 次元2)
ax.scatter(
x,
y,
s=200,
c='#2E86AB',
edgecolors='white',
linewidths=2
) # 青い丸でプロット
ax.annotate(
faculty,
(x, y),
fontsize=13,
fontweight='bold',
xytext=(10, 10),
textcoords='offset points',
color='#2E86AB'
) # 学部名のラベルを少しずらして表示
# 列ラベル(メニュー)を順番に取り出す
for i, menu in enumerate(cross_table.columns):
x, y = col_coords.iloc[i] # メニューの座標(次元1, 次元2)
ax.scatter(
x,
y,
s=200,
c='#E94F37',
marker='^',
edgecolors='white',
linewidths=2
) # 赤い三角でプロット
ax.annotate(
menu,
(x, y),
fontsize=13,
fontweight='bold',
xytext=(10, 10),
textcoords='offset points',
color='#E94F37'
) # メニュー名のラベルを少しずらして表示
# 原点の十字線
ax.axhline(
y=0,
color='gray',
linestyle='--',
linewidth=0.8
) # 横方向のゼロライン
ax.axvline(
x=0,
color='gray',
linestyle='--',
linewidth=0.8
) # 縦方向のゼロライン
# 軸ラベルに寄与率を表示
ax.set_xlabel(
f'次元1(寄与率: {ca.percentage_of_variance_[0]:.1f}%)',
fontsize=12
) # x軸ラベル
ax.set_ylabel(
f'次元2(寄与率: {ca.percentage_of_variance_[1]:.1f}%)',
fontsize=12
) # y軸ラベル
ax.set_title(
'コレスポンデンス分析マップ:学部 × メニュー',
fontsize=14
) # 図タイトル
# 凡例
from matplotlib.lines import Line2D # カスタム凡例用のLine2Dをインポート
legend_elements = [
Line2D(
[0],
[0],
marker='o',
color='w',
markerfacecolor='#2E86AB',
markersize=12,
label='学部'
),
Line2D(
[0],
[0],
marker='^',
color='w',
markerfacecolor='#E94F37',
markersize=12,
label='メニュー'
)
]
ax.legend(
handles=legend_elements,
fontsize=12,
loc='best'
) # 凡例を表示
ax.grid(True, alpha=0.3) # グリッド線を薄めに表示
plt.tight_layout() # レイアウトを自動調整
plt.show() # 図を表示
以下、実行結果です。
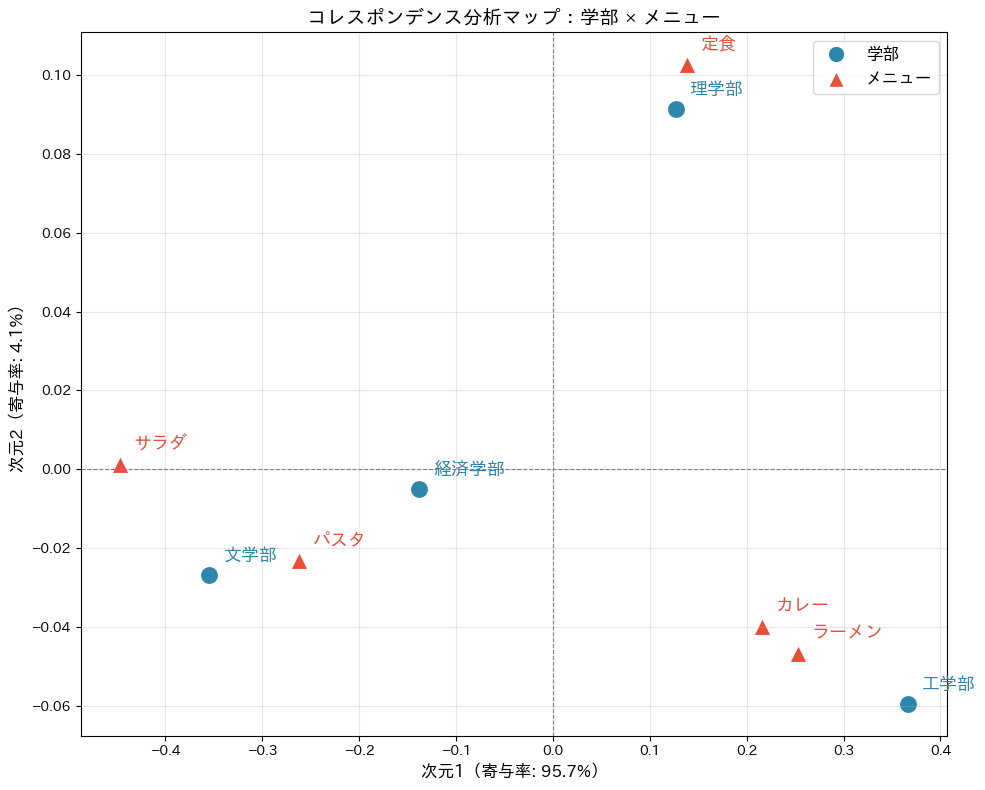
このマップこそが、コレスポンデンス分析の最大の成果物です。
ヒートマップでは20個のセルを一つずつ見比べる必要がありましたが、このマップなら一目で全体の構造を俯瞰できます。
ステップ6:マップを読む ― 「近い=関連が強い」
マップが完成したら、次はその意味を読み取ります。
読み方の基本はとてもシンプルで、「近い点どうしほど関係が強い」という考え方です。
マップ上で学部とメニューが近くに配置されていれば、その学部の学生がそのメニューを選びやすい傾向があると解釈できます。
たとえば、工学部の近くにカレーやラーメンがあります。工学部の学生はボリュームのあるメニューを好むと考えられます。
マップの中心にある原点(0,0)は、全体の平均的な状態を表しています。
原点の近くにあるカテゴリは、特に強い特徴を持たず、どのグループにもよく見られる傾向を示します。
一方で、原点から離れているカテゴリほど、その特徴がはっきりしていると考えられます。
また、原点をはさんで反対側に配置されている点どうしは、対照的な関係にあります。
たとえば、一方に「工学部とカレー」があり、反対側に「文学部とパスタ」があれば、両者の食の好みはかなり異なっていることを示しています。
実際のマップを見ながら、こうした位置関係に注目することで、クロス集計表だけでは見えなかった特徴が浮かび上がってきます。
ヒートマップ vs. コレスポンデンス分析マップ ― 何が違う?
ここまでの内容をふまえて、ヒートマップとコレスポンデンス分析マップの違いを整理してみましょう。
ヒートマップは、クロス集計表のそれぞれのマス目に入っている数値、つまり「人数が多いか少ないか」を色の濃淡で確認するのに向いています。
どの学部でどのメニューが何人選ばれているのかを、直感的に把握できるのが強みです。
一方で、コレスポンデンス分析マップが得意なのは、数値そのものよりも「カテゴリ同士の関係」を見ることです。
学部どうしが似ているか、どのメニューとどの学部が結びついているかといった全体の構造を、地図のように俯瞰することができます。
カテゴリの数が増えても、位置関係として整理されるため、全体像をつかみやすい点も特徴です。
この2つは、どちらが優れているという関係ではありません。
個々の値を正確に確認したいときはヒートマップが役立ちますし、全体の傾向や関係性をまとめて理解したいときにはコレスポンデンス分析マップが力を発揮します。
目的に応じて使い分けることが、データをうまく読み解くためのポイントです。
| 観点 | ヒートマップ | コレスポンデンス分析マップ |
|---|---|---|
| 読み取れること | 各セルの値(人数)の大小 | カテゴリ間の関係性・類似性 |
| 得意なこと | 個別の値の確認 | 全体構造の俯瞰 |
| カテゴリ数が増えると | 見づらくなる | 依然として見やすい |
| 数学的な背景 | 不要 |
まとめ
今回は、コレスポンデンス分析の「なぜ必要なのか」と「何ができるのか」を簡単に説明しました。
簡単にポイントを整理しておきましょう。
クロス集計表は2つのカテゴリ変数の関係を数値でまとめた表であり、コレスポンデンス分析の出発点です。ヒートマップで色にすれば個々の値は見やすくなりますが、カテゴリ間の「距離」や「全体構造」をつかむのは苦手です。
コレスポンデンス分析は、行カテゴリ(学部)と列カテゴリ(メニュー)を同じ2次元空間にマッピングすることで、カテゴリ間の関係を直感的に可視化します。マップ上で近い点どうしは関連が強く、原点は平均を、原点から遠い点は個性の強さを表します。
prince ライブラリを使えば、わずか数行のコードで分析を実行し、マップを描くことができます。
ただし、今回は「こんなことができる!」という紹介が中心でした。
「なぜこの方法でうまくいくのか」「マップの座標はどうやって計算しているのか」といった仕組みの部分は、まだブラックボックスのままです。
次回の第2回では、コレスポンデンス分析の土台となる「期待度数」と「独立性からのズレ」という考え方を説明します。