
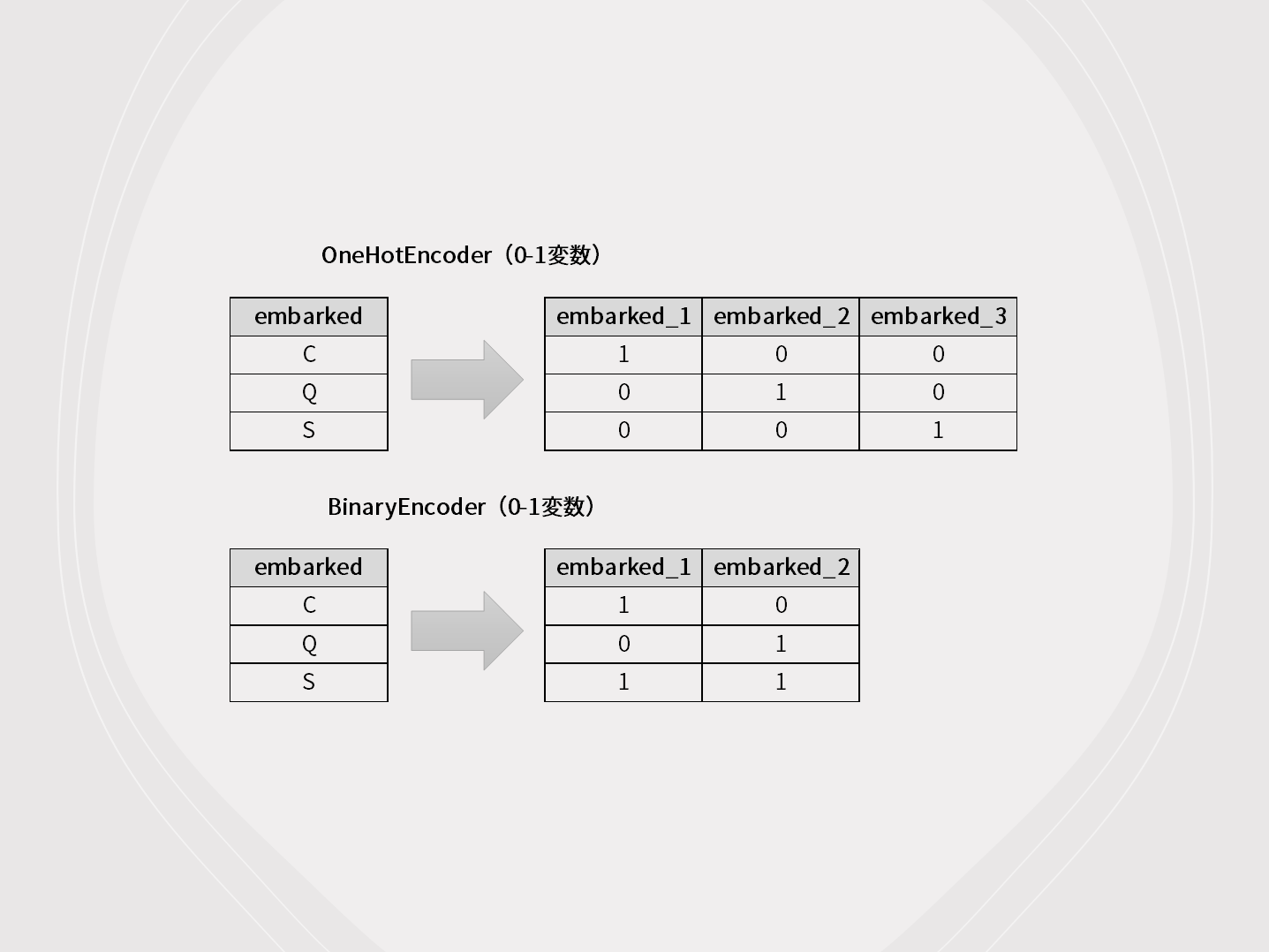
カテゴリカル変数は、数字で表現されているケースと、文字列で表現されているケースが多いです。
文字列で表現されているケースの場合、そのままモデル構築するとエラーが出ることも多いです。
そのような場合、文字列を数字にエンコード(変換)する必要があります。
そのためのPyhton パッケージが「category_encoders」です。
今回は、category_encodersの使い方とともに代表的なエンコード(変換)方法も解説していきます。
取り急ぎインストール
以下のコードでcategory_encodersをインストールできます。condaでのインストールになります。
conda install -c conda-forge category_encoders
pipでインストールする場合は、以下です。
pip install category_encoders
説明する3つのエンコード
代表的な以下の3つについて説明していきます。
- OneHotEncoder(0-1変数)
- BinaryEncoder(0-1変数)
- OrdinalEncoder(0,1,2,……)
他にも色々ありますが、この3つを押さえておけば、基本的に十分かと思います。
サンプルデータ
みんな大好きタイタニック(titanic)のデータを使います。
タイタニック(titanic)データと言っても色々ありますが、今回はScikit-learn(sklearn)のサンプルデータを使いますので、まだScikit-learn(sklearn)をインストールされていない方は、インストールしておいてください。

1912年に大西洋で氷山に衝突し沈没したタイタニック号の乗客者の生存状況に関するデータセットです。
- pclass: 旅客クラス(1=1等、2=2等、3=3等)
- name: 乗客の名前
- sex: 性別(male=男性、female=女性)
- age: 年齢
- sibsp: タイタニック号に同乗している兄弟(Siblings)や配偶者(Spouses)の数
- parch: タイタニック号に同乗している親(Parents)や子供(Children)の数
- ticket: チケット番号
- fare: 旅客運賃
- cabin: 客室番号
- embarked: 出港地(C=Cherbourg:シェルブール、Q=Queenstown:クイーンズタウン、S=Southampton:サウサンプトン)
- boat: 救命ボート番号
- body: 遺体収容時の識別番号
- home.dest: 自宅または目的地
- survived:生存状況(0=死亡、1=生存)
カテゴリカル変数と数量データが混在し、カテゴリカル変数も数字のもの(survivedなど)と文字列のもの(nameなど)が混在しています。
今回使うのは、以下の文字列データのカテゴリカル変数です。
- name: 乗客の名前
- embarked: 出港地(C=Cherbourg:シェルブール、Q=Queenstown:クイーンズタウン、S=Southampton:サウサンプトン)
必要なライブラリーの読み込み
先ずは、必要なライブラリーを読み込みます。
以下、コードです。
# ライブラリーの読み込み ## 基礎ライブラリー import pandas as pd ## カテゴリカルデータのエンコーダー import category_encoders as ce ## 例で利用するデータセット from sklearn.datasets import fetch_openml
データセット読み込み
Scikit-learn(sklearn)のタイタニック(titanic)のサンプルデータを読み込みます。
以下、コードです。
# タイタニック(titanic)のデータセット
titanicXy = fetch_openml("titanic", version=1, as_frame=True, return_X_y=False).frame
どのようなデータか確認してみます。
以下、コードです。
# データセットの確認 titanicXy
以下、実行結果です。
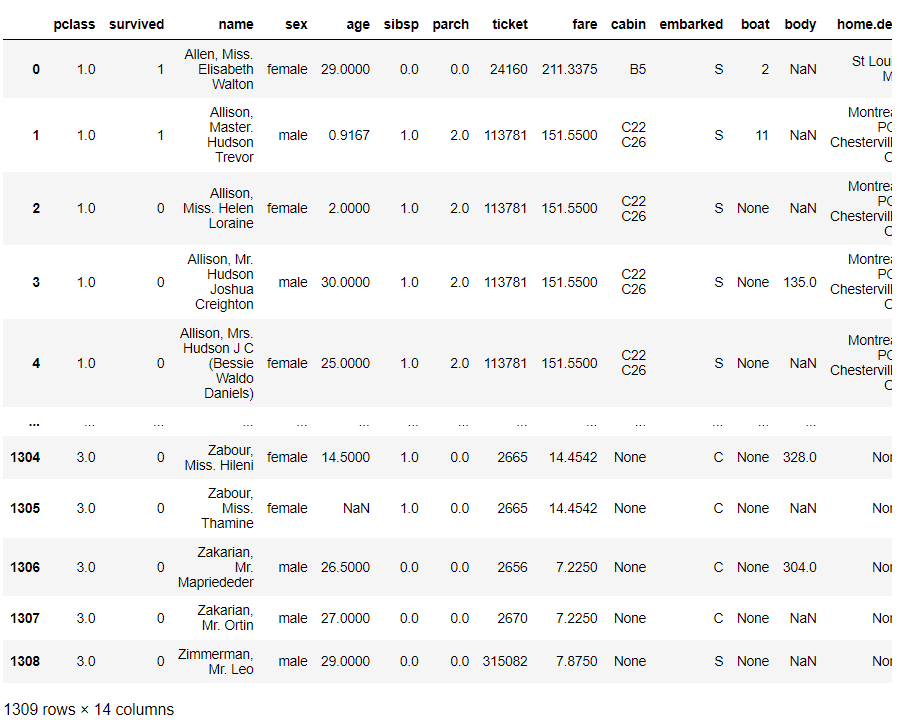
行数が1,309で列数(変数の数)が14です。
また、変数「name」「embarked」に文字列が入っていることが分かるかと思います。
各変数の状況を確認してみます。
以下、コードです。
# 各変数の確認 titanicXy.info()
以下、実行結果です。
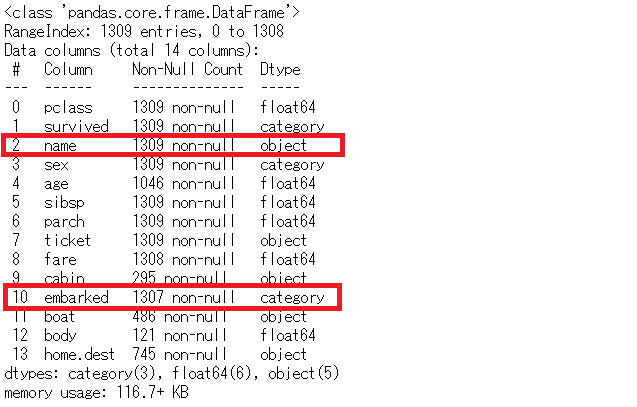
変数「name」の有効データ数は1,309です。一方、「embarked」の有効データ数は1,307で、欠測している箇所が2か所あることがわかります。
「name」と「embarked」の変数(列)だけ取り出し、欠測している行を除外したデータセットを作り、先ほどあげた3つのエンコードを実施していきます。
以下、データセットを作るコードです。
# データセット作成 titanicXy_cate = titanicXy[['name','embarked']].dropna() titanicXy_cate #確認
以下、実行結果です。
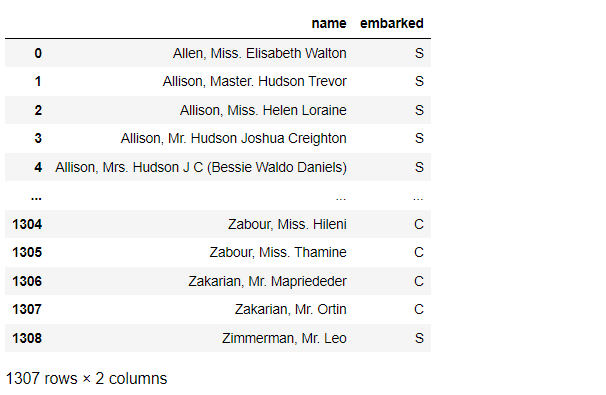
このデータセットに対し、3つのエンコードを実施していきます。
- OneHotEncoder(0-1変数)
- BinaryEncoder(0-1変数)
- OrdinalEncoder(0,1,2,……)
では、エンコード例です
OneHotEncoder(0-1変数)
OneHotEncoder(0-1変数)が実施するエンコードは、昔からある典型的なエンコードです。よくダミー変数化(0-1変数化)と呼ばれたりしているもので、カテゴリの数だけ変数を新たに作り 0 or 1の値を振っていきます。

先ず、embarkedの例です。
以下、コードです。分かりやすくするために、元のembarkedも残しています。
# OneHotEncode list_cols = ['embarked'] #対象列指定 titanicXy_cate_Encoder = ce.OneHotEncoder(cols=list_cols) titanicXy_cate_onehot = titanicXy_cate_Encoder.fit_transform(titanicXy_cate[list_cols]) #実行 pd.concat([titanicXy_cate[list_cols], titanicXy_cate_onehot], axis=1) #確認
以下、実行結果です。
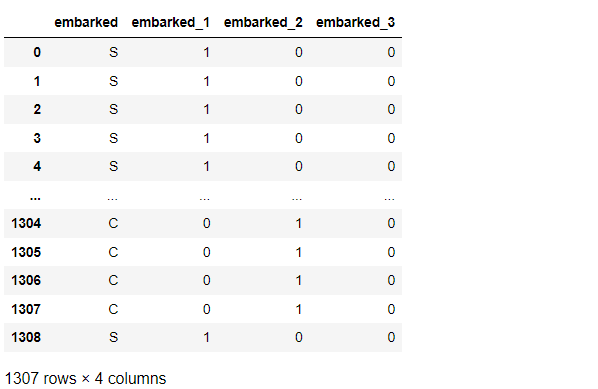
次に、nameの例です。
以下、コードです。分かりやすくするために、元のnameも残しています。
# OneHotEncode list_cols = ['name'] #対象列指定 titanicXy_cate_Encoder = ce.OneHotEncoder(cols=list_cols) titanicXy_cate_onehot = titanicXy_cate_Encoder.fit_transform(titanicXy_cate[list_cols]) #実行 pd.concat([titanicXy_cate[list_cols], titanicXy_cate_onehot], axis=1) #確認
以下、実行結果です。
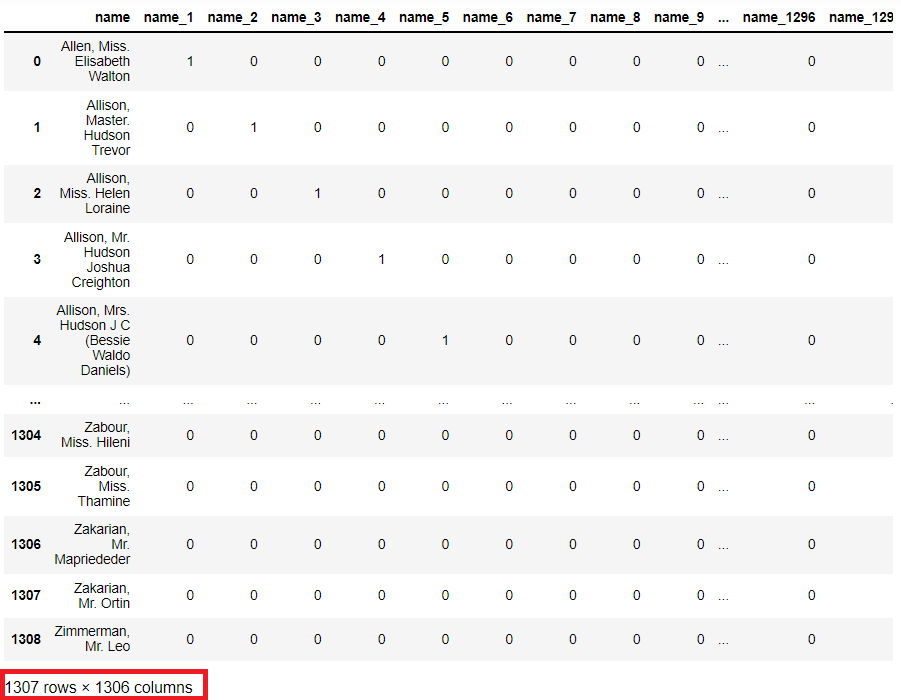
変数の数が1,306(新規に作成されたのは1,305)と、非常に多くなっています。
OneHotEncoder(0-1変数)が実施するエンコードは、昔からあるよく使われるものですが、カテゴリの数だけ変数を新たに作り 0 or 1の値を振っていくため、カテゴリの数が多い場合、新たに作成される変数が多くなるのが難点です。
新たに作成される変数が多くならないための対策として、例えば次の2つが考えれます。
- BinaryEncoder(0-1変数)
- OrdinalEncoder(0,1,2,……)
BinaryEncoder(0-1変数)は、文字通りカテゴリーを2進数表現に変換するエンコードのため、変数の数がそこそこ節約されます。
OrdinalEncoder(0,1,2,……)は、それ以上に変数の数が節約され、1変数で表現します。単に、文字列を数字に変換するだけですが……
BinaryEncoder(0-1変数)
では、カテゴリーを2進数表現に変換するBinaryEncoder(0-1変数)です。
先ず、embarkedの例です。
以下、コードです。分かりやすくするために、元のembarkedも残しています。
# BinaryEncoder list_cols = ['embarked'] #対象列指定 titanicXy_cate_Encoder = ce.BinaryEncoder(cols=list_cols, drop_invariant=True) titanicXy_cate_Binary = titanicXy_cate_Encoder.fit_transform(titanicXy_cate[list_cols]) #実行 pd.concat([titanicXy_cate[list_cols], titanicXy_cate_Binary], axis=1) #確認
以下、実行結果です。
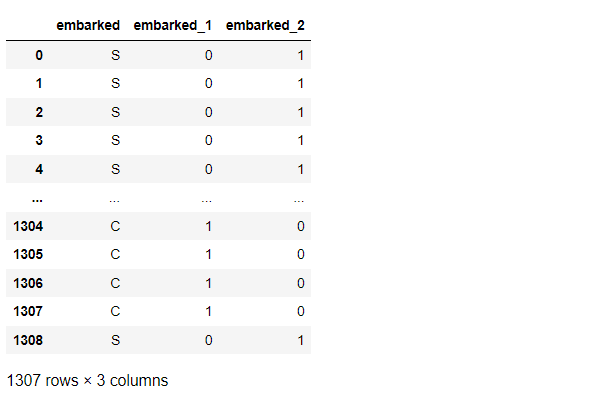
OneHotEncoder(0-1変数)の比べると、1変数少なくて済みます。
どういうことかと言うと、次のように変換しているからです。
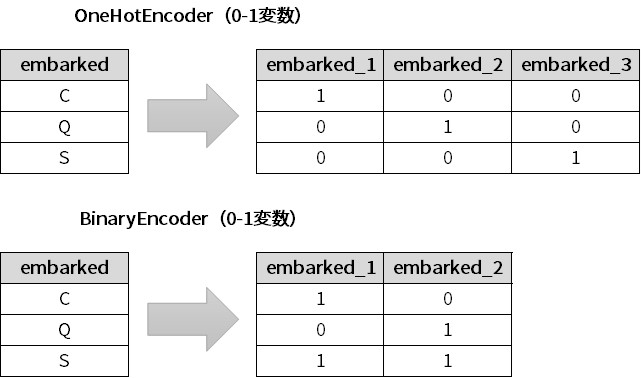
次に、nameの例です。
以下、コードです。分かりやすくするために、元のnameも残しています。
# BinaryEncoder list_cols = ['name'] #対象列指定 titanicXy_cate_Encoder = ce.BinaryEncoder(cols=list_cols, drop_invariant=True) titanicXy_cate_Binary = titanicXy_cate_Encoder.fit_transform(titanicXy_cate[list_cols]) #実行 pd.concat([titanicXy_cate[list_cols], titanicXy_cate_Binary], axis=1) #確認
以下、実行結果です。
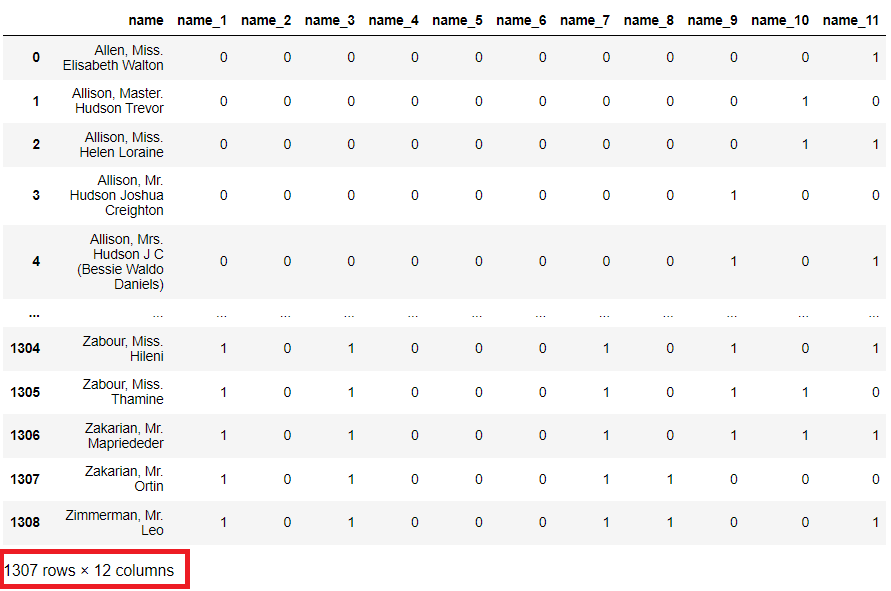
OneHotEncoder(0-1変数)では新変数1,305でしたが、BinaryEncoder(0-1変数)では新変数11とだいぶ少なくなっています。
このように、BinaryEncoder(0-1変数)は、カテゴリーの数が多いほど、変数の数の節約効果が見込めます。
OrdinalEncoder(0,1,2,……)
最後に、OrdinalEncoder(0,1,2,……)です。
こちらは順番を変えて、「name」の例から始めます。
ということで、nameの例です。
以下、コードです。分かりやすくするために、元のnameも残しています。
# OrdinalEncoder list_cols = ['name'] #対象列指定 titanicXy_cate_Encoder = ce.OrdinalEncoder(cols=list_cols, drop_invariant=True) titanicXy_cate_Ordinal = titanicXy_cate_Encoder.fit_transform(titanicXy_cate[list_cols]) #実行 pd.concat([titanicXy_cate[list_cols], titanicXy_cate_Ordinal], axis=1) #確認
以下、実行結果です。
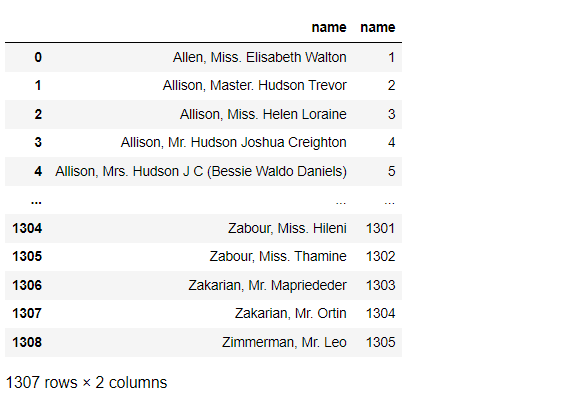
カテゴリに数字が降られていることが分かるかと思います。
次に、embarkedの例です。
以下、コードです。分かりやすくするために、元のembarkedも残しています。
# OrdinalEncoder list_cols = ['embarked'] #対象列指定 titanicXy_cate_Encoder = ce.OrdinalEncoder(cols=list_cols, drop_invariant=True) titanicXy_cate_Ordinal = titanicXy_cate_Encoder.fit_transform(titanicXy_cate[list_cols]) #実行 pd.concat([titanicXy_cate[list_cols], titanicXy_cate_Ordinal], axis=1) #確認
以下、実行結果です。
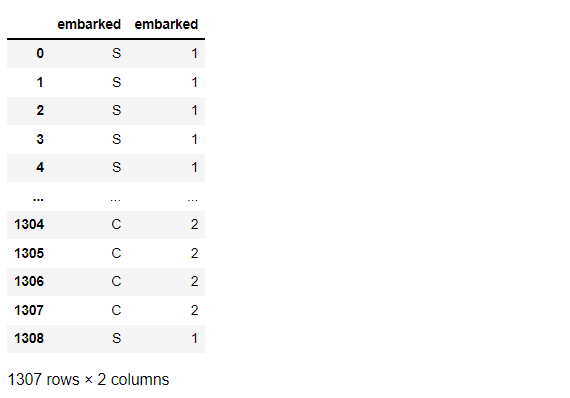
数字がどの文字列と対応しているのかは、「category_mapping」で確認することができます。
以下、コードです。見やすくするために、DataFrame型で表示しています。
pd.DataFrame(titanicXy_cate_Encoder.category_mapping[0])
以下、実行結果です。

特に指定していない場合、数字は適当に振られますし、数字の大小に意味はありません。数字の振り方を指定することができます。
簡単に、数字の割り振りを指定した場合のケースを説明します。
以下、数字の割り振り定義です。
level_mapping=[{'col': 'embarked',
'mapping': {None: 0,
'S': 1,
'Q': 2,
'C': 3}}]
QとCの順番を入れ替えています。
では、実行してみます。以下、コードです。
list_cols = ['embarked'] #対象列指定 titanicXy_cate_Encoder = ce.OrdinalEncoder(cols=list_cols,mapping=level_mapping) titanicXy_cate_Ordinal = titanicXy_cate_Encoder.fit_transform(titanicXy_cate[list_cols]) #実行 pd.concat([titanicXy_cate[list_cols], titanicXy_cate_Ordinal], axis=1) #確認
以下、実行結果です。
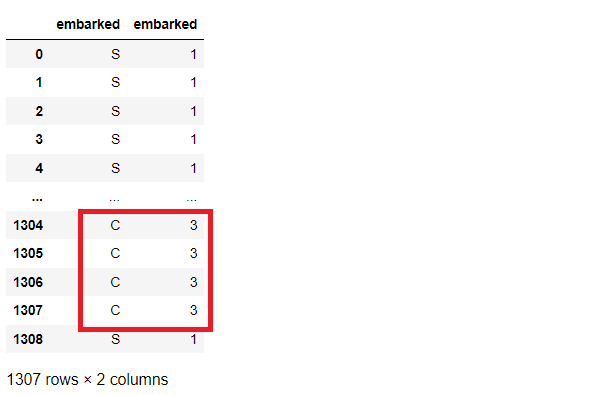
まとめ
今回は、category_encodersの使い方とともに代表的なエンコード(変換)方法も解説しました。
- OneHotEncoder(0-1変数)
- BinaryEncoder(0-1変数)
- OrdinalEncoder(0,1,2,……)
OneHotEncoder(0-1変数)は、もっともポピュラーなエンコードでしょう。
ちなみに、線形回帰モデル(重回帰など)などを構築するときに、新たに作られた変数の1つを除外する必要があります(マルチコという現象が起こるため……)。そういったことも一様認識はしておいた方がいいでしょう。最近では、回帰分析のプログラムの中で自動的に除外するものが多いですが……
OrdinalEncoder(0,1,2,……)も、ポピュラーなエンコードです。
Pythonでは、よくランダムフォレストなどの森系のアルゴリズムを利用する前に前処理の1つとして利用されます。