
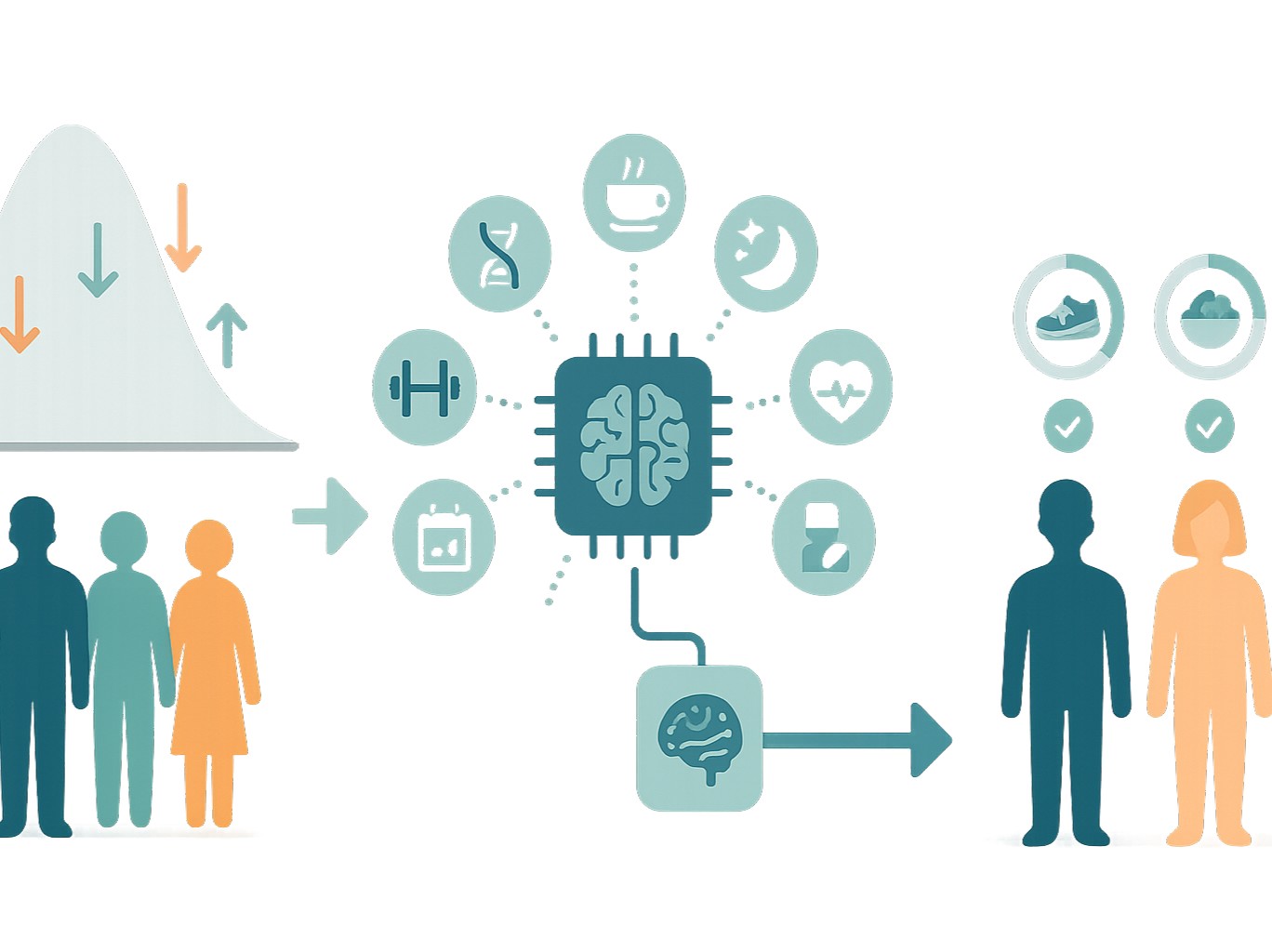
マーケティングや健康、医療の分野で、私たちはよく「平均的な効果」という言葉に出会います。
しかし、あなたは平均的な人間でしょうか?
おそらく違うはずです。
実際、販促や健康法、治療法に対する効果は、人によって驚くほど異なります。
なぜ同じ方法でも人によって結果が違うのか?
そしてその違いを事前に予測することは可能なのか?
この個人差という現実と、それを予測する技術について、今回はお話しします。
Contents
みんな違って当たり前

平均値の落とし穴
「運動プログラムで平均3kg減量!」という広告を見て始めたのに、まったく効果がなかった経験はありませんか。
実は、これはあなただけの問題ではありません。
同じ健康法でも、人によって効果が大きく異なります。
平均値というのは、全体の傾向を示す便利な指標ですが、個人にとっては時に誤解を招く数字でもあります。
100人の参加者で平均3kg減量という結果の裏には……
- 10kg痩せた人もいれば
- 全く変化がなかった人
- さらには体重が増えた人さえ
……含まれているかもしれないのです。
身近な例から学ぶ個人差
個人差をより深く理解するために、朝のコーヒーという身近な例を考えてみましょう。
同僚のAさんは一杯飲むだけでシャキッと目が覚めるのに、あなたは三杯飲んでもまだ眠い。
この違いはどこから来るのでしょうか。
実は、カフェインを分解する力は人によって生まれつき違います。
これは遺伝子レベルで決まっている体質の違いです。
さらに、毎日コーヒーを飲む習慣がある人は体が慣れてしまい、いわゆる「耐性」ができて効果を感じにくくなります。
前日の睡眠時間や朝食の有無も影響します。
空腹時にコーヒーを飲むと、カフェインが素早く吸収されて効果が強く出ることもあるのです。
運動プログラムに見る複雑な要因
運動プログラムになると、この個人差はさらに複雑になります。
ある会社の健康増進プログラムでは、同じメニューを3ヶ月実施して、5kg痩せた人もいれば、逆に1kg増えてしまった人もいました。
この差を生む要因を整理すると、まず生物学的要因があります。
若い人ほど基礎代謝が高く、じっとしていても多くのカロリーを消費します。
また、筋肉量の多い人も同様です。
次に心理社会的要因も重要です。
家族が応援してくれるか、職場のストレスレベルはどうか、運動を楽しいと感じるかといった要素が、実は結果を大きく左右するのです。
つまり、平均値だけを見て判断することには、大きなリスクが潜んでいるということです。
個人単位の効果を予測する「機械学習」という味方
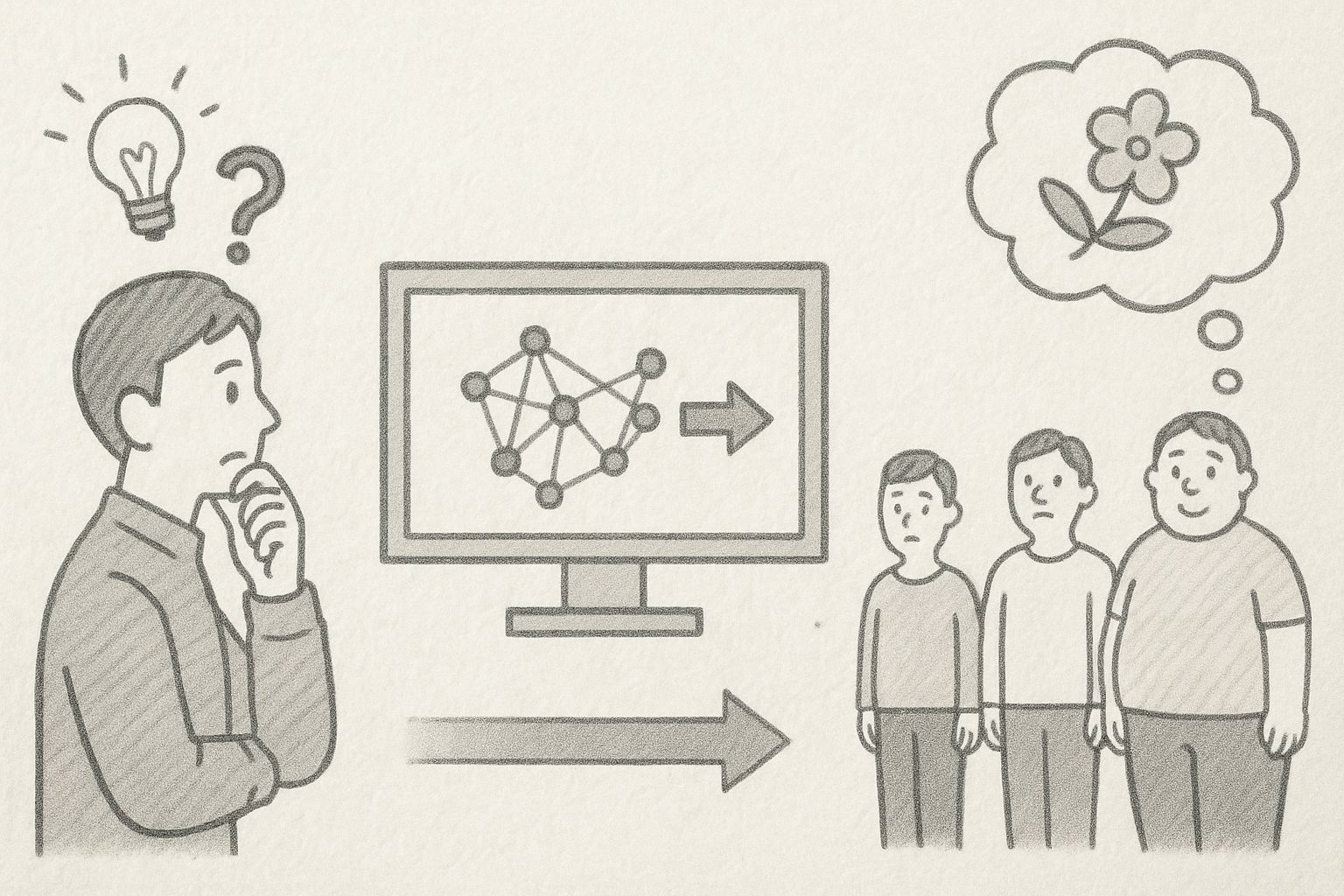
機械学習とは何か
では、事前に「自分にはこの方法が効くかどうか」を知ることはできないのでしょうか。
実は最近、機械学習という技術により、個人の特徴から効果を予測することが可能になってきました。
機械学習の仕組みを理解するには、天気予報を思い浮かべるとよいでしょう。
気象予報士は過去の膨大なデータから「こういう気圧配置で、こういう風向きのときは、翌日雨になることが多い」というパターンを知っています。
そして今日の気象条件を見て、過去の似たパターンと照らし合わせて明日の天気を予測します。
機械学習も同じ原理で動いています。
過去のデータからパターンを学習し、新しい状況でそのパターンを当てはめて予測するのです。
ただし、コンピュータは人間より遥かに多くのデータを瞬時に処理し、人間には見つけられない複雑なパターンも発見できるという強みがあります。
主な機械学習モデル
まずは土台の考え方として、個人ごとの効果は CATE(Conditional Average Treatment Effect:条件付き平均処置効果) と呼ばれます。
直感的には「あなたと似た人に対して、介入あり/なしで期待される結果の差」です。
以下は、CATEやアップリフト(効果差)を推定する代表的なモデル群です。シンプル→高度の順で並べます。
| 種類 | モデル | 考え方 | 強み | 注意 | 向いている状況 |
|---|---|---|---|---|---|
| 交互作用つき回帰 | 線形回帰/ Ridge/Lasso/Elastic Net | 交互作用で個人効果を表現 | 実装容易・高い解釈性 | ほぼ線形の仮定。非線形/高次相互作用を取り逃しやすい | 小~中規模、説明責任重視 |
| 決定木ベース | 決定木/RuleFit/CHAID | 効果が大きい条件で分割しルール抽出 | ルールで説明しやすく施策に直結 | 深い木は不安定、微小な差を拾いにくい | ルール配布・現場説明が必要な場面 |
| アップリフト学習 | Two-Model(T-Learner)、Uplift Tree/Forest | 介入群と対照群の差(効果)を直接最適化 | 「誰に効くか」をスコア化して優先度付け | データ不均衡・交絡に脆弱、評価はQini/AUUCなど専用指標 | マーケ配布最適化、ターゲティング |
| メタラーナー | S-/T-/X-/R-/DR-Learner | S:1モデルに介入フラグ/T:群別モデル/X:不均衡に強い/R/DR:二重に頑健 | 観測データ下で汎用的に強い | モデル選択・チューニングが必要 | 不均衡→X、バイアス懸念→DR など |
| 因果フォレスト | Causal Forest/GRF | RF拡張で葉ごとの効果差を安定推定 | 非線形・高次相互作用に強い、局所平均で一定の解釈性 | ハイパラ・サンプルサイズ・計算コストに敏感 | 中~大規模・多次元特徴 |
| 深層学習 | TARNet/DragonNet、CEVAE | 表現学習や生成モデルで群間差・潜在交絡を補正 | 複雑・高次元データに強い | データ量・解釈性・分布シフトに注意 | 画像/テキスト等の大規模高次元 |
モデルを選ぶ際は、まずデータ規模を手がかりにします。
小~中規模のデータであれば、交互作用つき回帰やS/T/Xといった比較的軽量な方法が扱いやすい一方、十分に大きなデータがあるなら、非線形性を捉えやすい因果フォレストや深層学習系が有力です。
次に群バランスを確認します。
介入群と対照群のサイズが偏っている場合には、X-LearnerやDR-Learnerのように不均衡に強い枠組みが適しています。
さらに、現場での説明可能性を重視するなら、ルールを提示できる木系や交互作用回帰を優先し、最後に運用速度を考慮して、頻繁にスコア更新が必要な現場では計算の軽いモデルから着手するのが現実的です。
実際の活用事例
理論だけでは分かりにくいので、実際の活用例を見てみましょう。
ある大手健康保険会社は、加入者10万人の過去5年間のデータを使って、健康プログラムの効果を予測するシステムを作りました。
このシステムに含めた情報は実に多岐にわたります。
年齢、健診結果、生活習慣はもちろん、医療費の使い方のパターンまで含めました。
機械学習は、これらの膨大な情報の中から、効果に影響する重要なパターンを見つけ出したのです。
その結果はどうだったでしょうか。
プログラムの効果が最も期待できる人を特定できるようになり、限られた予算でも全体の健康改善効果が30%向上したのです。
また、運動プログラムが効きにくいと予測された人には、食事改善プログラムを勧めるなど、一人ひとりに合ったアプローチが可能になりました。
予測を賢く使うための3つのポイント
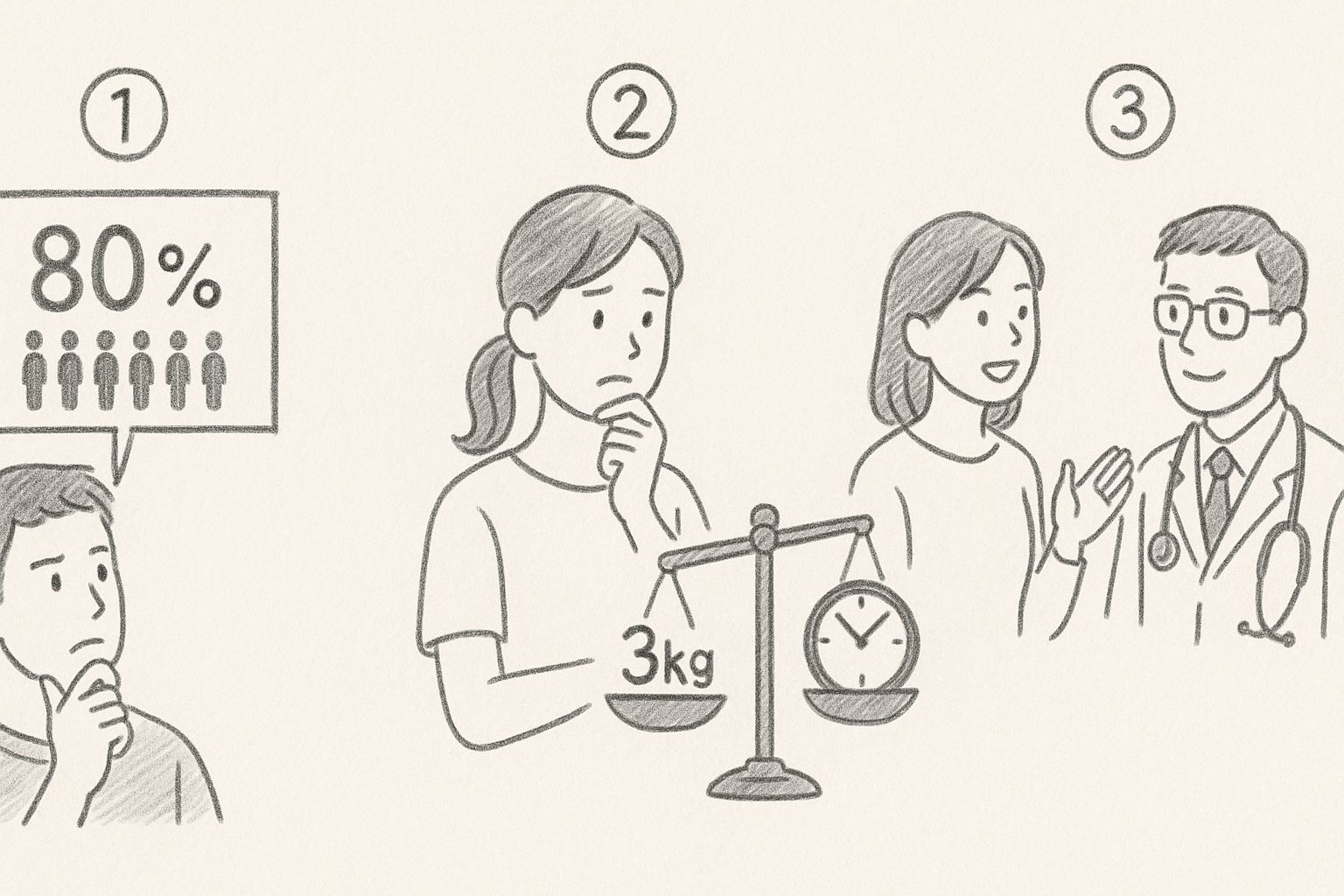
ポイント1:確率的予測の理解
機械学習の予測は強力な道具ですが、正しく使うことが大切です。
まず理解すべきは、これが確率的な予測だということです。
「効果がある確率80%」という結果を見たとき、これをどう解釈すべきでしょうか。
この数字は「あなたと似た特徴を持つ100人のうち、80人には効果があった」という意味です。
あなたがその80人に入るか、効果のない20人に入るかは、実際にやってみないと分かりません。
この不確実性を理解した上で、リスクやコスト、そして自分にとっての価値を総合的に判断することが重要です。
副作用のリスクが小さく、コストも低い介入なら、80%の成功確率は十分に試す価値があるでしょう。
ポイント2:個人の価値観との統合
予測結果はあくまで意思決定の材料の一つです。
同じ「3kg減量」という予測でも、その価値は人によって全く異なります。
健康診断で「あと3kg痩せれば薬を飲まなくて済む」と言われている人にとって、この3kgは人生を変える可能性のある重要な数字です。
一方、美容目的で「もう少し痩せたい」と思っている人にとっては、期待とは異なる結果かもしれません。
また、プログラムの実施に必要な時間や労力も考慮すべきです。
毎日1時間の運動が必要なプログラムは、効果が高くても、育児や仕事で忙しい人には現実的でないかもしれません。
予測される効果と、それを得るために必要な投資のバランスを、自分の生活に照らして考えることが大切です。
ポイント3:専門家との協働
最後に、特に医療に関わる決定では、必ず専門家にも相談することです。
機械学習は過去のデータからパターンを見つけますが、あなた個人の詳細な健康状態や最新の医学的知見をすべて反映しているわけではありません。
専門家は、予測結果と臨床経験、そしてあなたの個別の状況を総合的に判断して、最適なアドバイスを提供してくれます。
また、まれな病気や特殊な体質については、データが少ないため機械学習の予測精度が低い可能性もあります。
専門家の知識と機械学習の分析力を組み合わせることで、より良い判断ができるのです。
今回のまとめ
今回は、「個人単位で施策に対する効果を予測する」というお話しをしました。
私たちは今回、健康法の効果における個人差という現実と、それを予測する機械学習という新しい技術について見てきました。
重要なポイントを中心に簡単に振り返ります。
まず、健康法の効果に個人差があるのは当然のことです。
体質、生活習慣、心理社会的要因が複雑に絡み合って、同じ介入でも人によって全く異なる結果を生み出します。
平均値に惑わされず、この個人差の存在を認識することが、効果的な健康管理の第一歩です。
次に、機械学習技術により、個人の特徴から効果を予測することが可能になってきました。
これは天気予報のように、過去のパターンから将来を予測する技術であり、実際に医療現場でも活用され始めています。
そして最も大切なのは、この予測を「万能の答え」としてではなく「より良い意思決定のための道具」として活用することです。
確率的な予測であることを理解し、自分の価値観や生活状況と照らし合わせ、必要に応じて専門家にも相談する。
このような総合的なアプローチにより、本当に自分に合った健康法を見つけることができるでしょう。
技術の進歩により、私たちは「平均的な患者」から「個別の人間」として扱われる時代に入りつつあります。
この変化を理解し、賢く活用することで、より効果的で無駄のない健康管理が可能になるのです。