
データ分析や予測モデル構築などをやってみたいが……
- RやPythonだとの無料ツールはコーディングスキルがそれなりに必要になりハードルがある
- 有料ツールのSASやSPSSなどは使いやすそうだけど高額すぎる。
無料で使える使いやすさが有料級の分析ツールはないだろうか?
と言うことで、Radiantです。
Radiantは、ノーコードでビジネスデータ分析を可能にする無料で使える有料級Rパッケージです。
- その1:Radiantのインストール・起動・終了
- その2:Radiantのデータ読み込み
- その3:Radiantでデータ抽出(絞り込み)
- その4:RadiantでEDA(探索的データ分析)
- その4-1 グラフ作成
- その4-2 ピボット集計
- その4-3 記述統計量
- その5:Radiantで予測モデル構築
- その5-1 学習データとテストデータへの分割
- その5-2 回帰問題(線形回帰・回帰木・XGBoost) ⇒ 今回
- その5-3 分類問題(ロジスティック回帰・ランダムフォレスト・ニューラルネット)
前回は、その5-1の「学習データとテストデータへの分割」について簡単に説明しました。
ノーコードでビジネスデータ分析を可能にするRパッケージRadiantその5-1(予測モデル構築 – 学習データ・テストデータ分割)
今回は、その5の「Radiantで予測モデル構築」の「その5-2 回帰問題(線形回帰・回帰木・XGBoost)」について簡単に説明します。
利用するデータ
サンプルデータは、Radiantのサンプルデータである「diamonds」をそのまま使います。
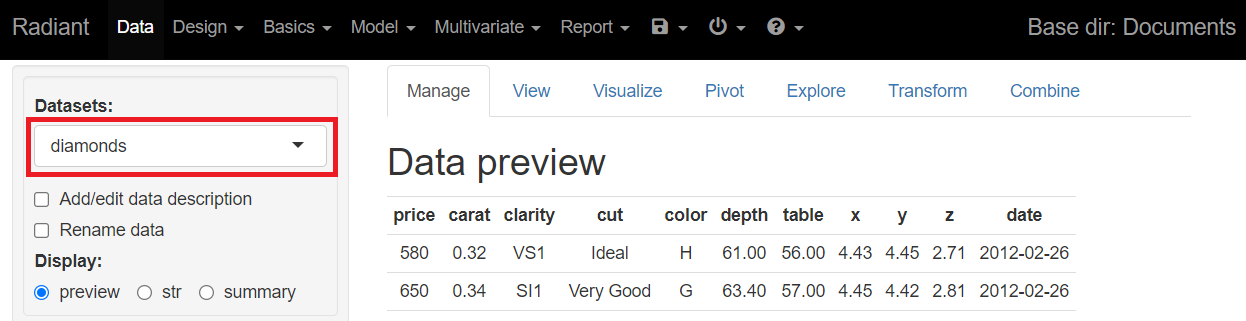
- price: price in US dollars
- carat: weight of the diamond
- clarity: measurement of how clear the diamond
- cut: quality of the cut
- color: diamond color
- depth: total depth percentage
- table: width of top of diamond relative to widest point
- x: length in mm
- y: width in mm
- z: depth in mm
一番上の「price」が目的変数で、残りの項目が説明変数(特徴量)です。
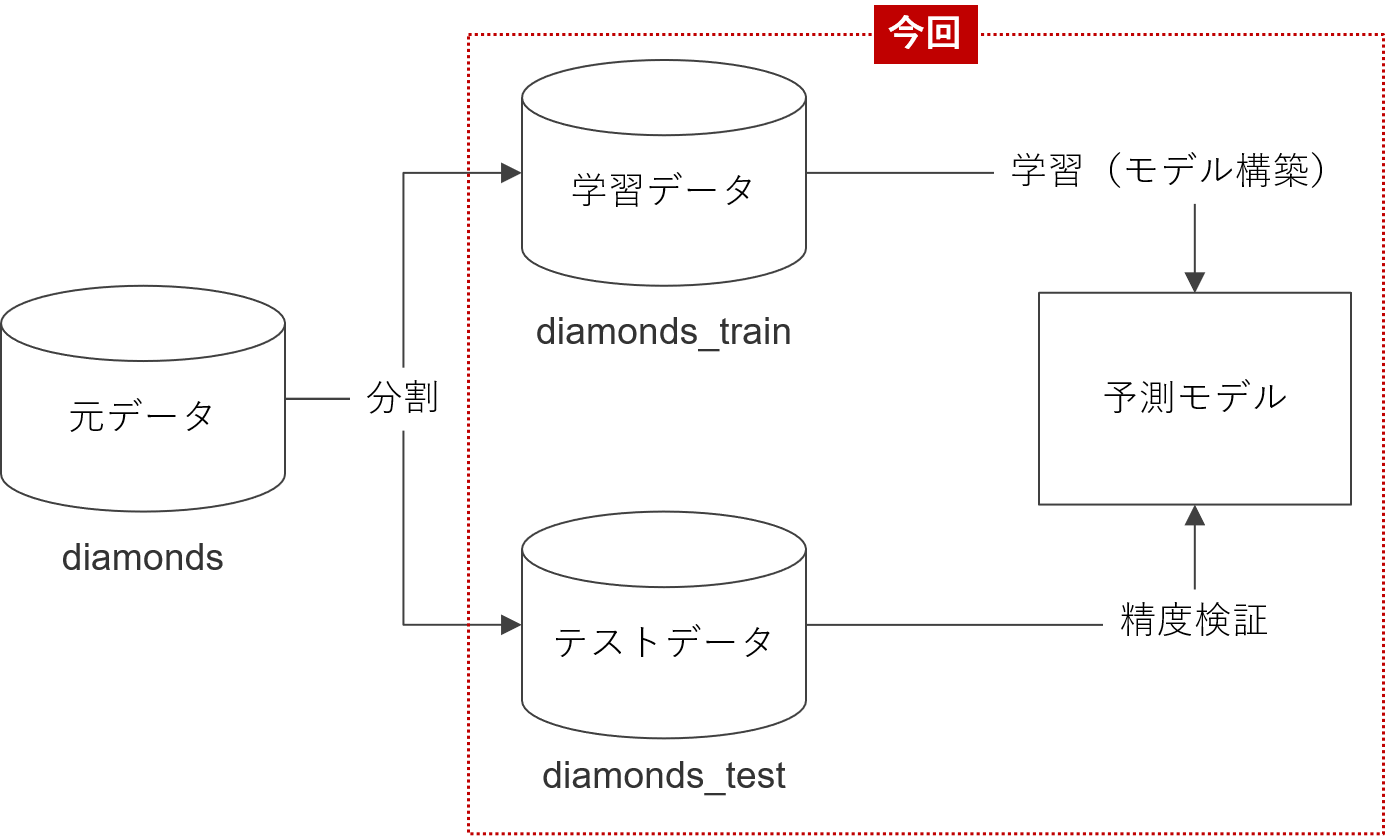
前回作成した学習データで予測モデルを構築し、テストデータで検証します。
- 学習データ:diamonds_train
- テストデータ:diamonds_test
予測モデル
今回構築する予測モデルは、以下の3つです。
- 線形回帰(重回帰)
- 回帰木
- XGBoost
評価指標
テストデータによる検証時に利用する評価指標は、以下の3つです。
| 指標名 | 略称 | 説明 |
| 決定係数 | R2 | \frac{\sum_{i=1}^n(y_i^{pred}-\overline{y^{obs}})^2}{\sum_{i=1}^n(y_i^{obs}-\overline{y^{obs}})^2}
目的変数の観測値に対する予測値の説明力を表す指標。1に近いほど良い予測である。 |
| Root Mean Squared Error | RMSE | \sqrt{\frac{1}{n}\sum_{i=1}^n(y_i^{obs}-{y_i^{pred}})^2}
誤差(実測値と観測値の差)の二乗の平均のルートをとったもの。実測値と観測値の平均はほぼ0になってしまうので、いったん二乗とっている。0に近いほど実測値と予測値の値が近く、良い予測である。 |
| Mean Absolute Error | MAE | \frac{1}{n}\sum_{i=1}^n|y_i^{obs}-{y_i^{pred}}|
誤差(実測値と観測値)の絶対値の平均。誤差をそのまま平均をとるとほぼ0になってしまうので、絶対値をとっている。0に近いほど実測値と予測値の値が近く、良い予測である。 |
以下の記号を使い精度指標の説明をします。
- y_i^{obs} ・・・i番目の実測値
- y_i^{pred} ・・・i番目の予測値
- \overline{y^{obs}} ・・・実測値の平均
- n ・・・実測値・予測値の数
流れ
簡単な流れを説明します。
- Radiantを起動
- 予測モデルの学習(構築)と目的変数の予測
- 線形回帰(重回帰)
- 学習データ(diamonds_train)で予測モデルを学習(構築)
- 予測モデルでテストデータ(diamonds_test)の目的変数を予測
- 回帰木
- 学習データ(diamonds_train)で予測モデルを学習(構築)
- 予測モデルでテストデータ(diamonds_test)の目的変数を予測
- XGBoost
- 学習データ(diamonds_train)で予測モデルを学習(構築)
- 予測モデルでテストデータ(diamonds_test)の目的変数を予測
- 線形回帰(重回帰)
- 予測モデルの検証結果表示(R2、RMSE、MAE)
1. Radiantを起動
以下、コードです。
# 必要パッケージのロード library(radiant) # radiantの起動 radiant()
2. 予測モデルの学習(構築)と目的変数の予測
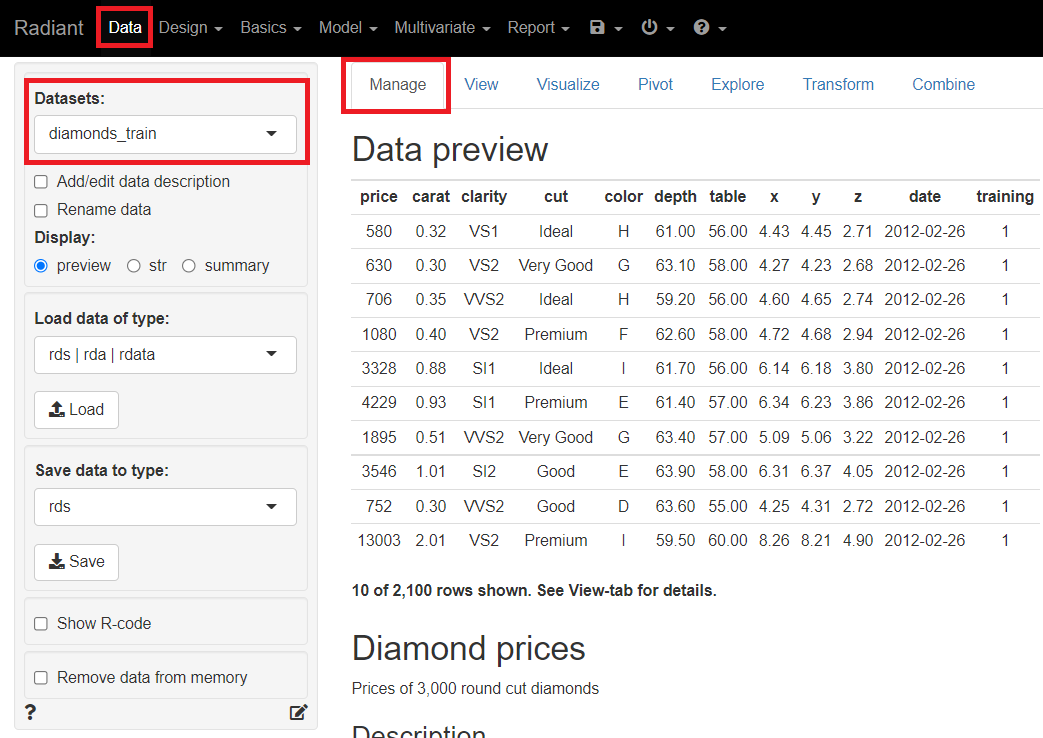
メニューから「Data」を選択し「Manage」をクリックします。左上に表示されている「Datasets」のところを「diamonds_train」にします。
2-1. 線形回帰(重回帰)
先ず、学習データ(diamonds_train)で予測モデルを学習(構築)します。
メニューから「Model」を選択し「Linear regression(OLS)」をクリックします。
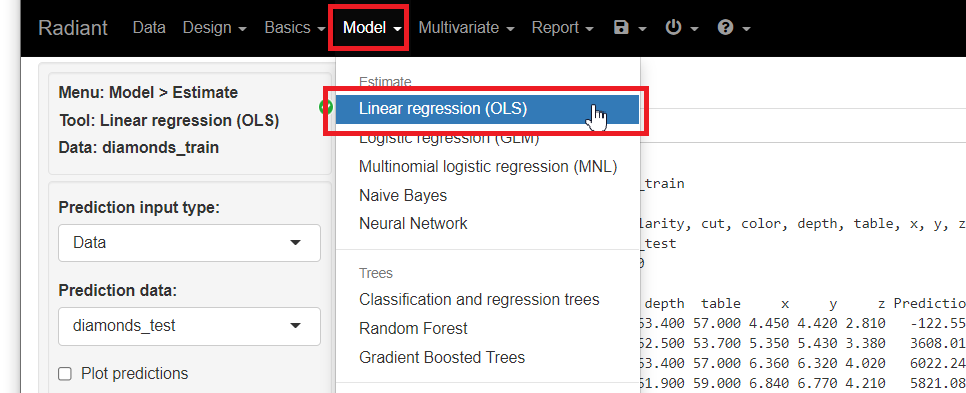
Response variables(目的変数)に「price」、Explanatory variables(説明変数)に「carat」「clarity」「cut」「color」「depth」「table」「x」「y」「z」を指定し、「Estimate model」をクリックし予測モデルを構築します。ちなみに今回は、Standarize(標準化)とRobust(ロバスト)にチェックを入れています。
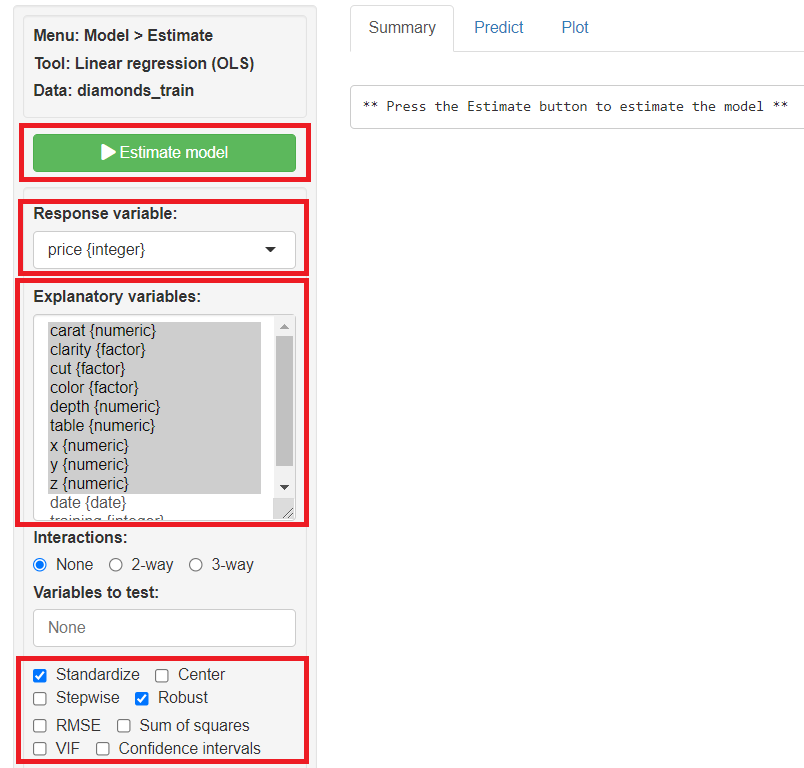
「Summary」に学習(構築)した予測モデルの概要が表示されます。
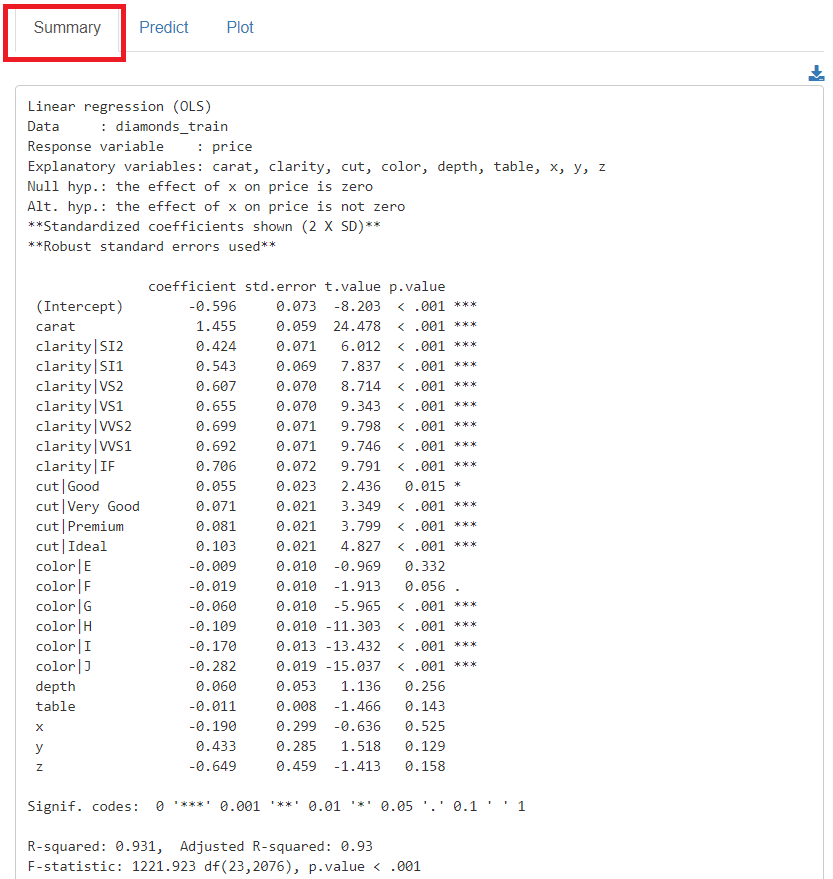
学習(構築)した予測モデルの、各説明変数の係数をグラフィカルに見てみます。
「Plot」をクリックし、左上の「Plots」に「Coefficient plot」を指定すると、各説明変数の係数をグラフ化したものが表示されます。
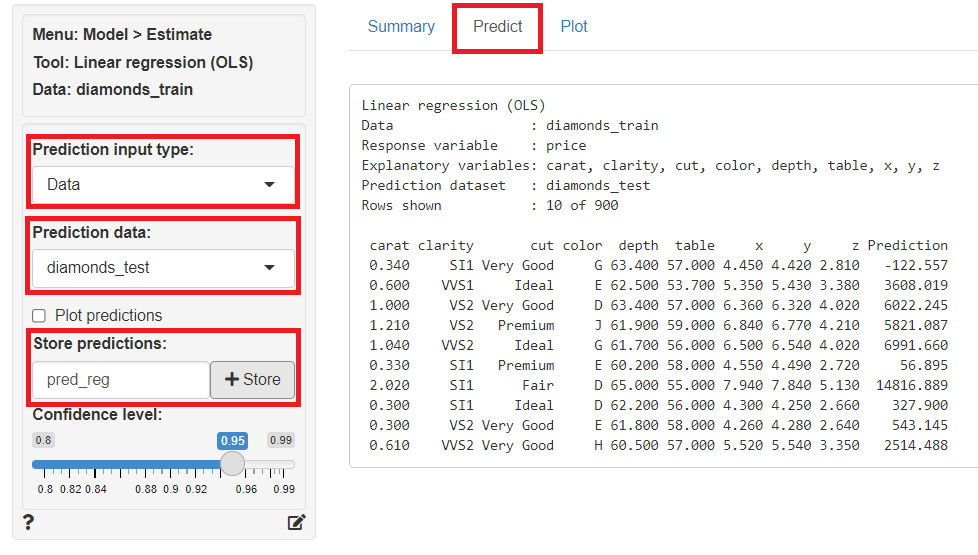
次に、予測モデルでテストデータ(diamonds_test)の目的変数を予測します。
「Predict」をクリックし、左上の「Prediction Input type」に「Data」を指定、「Prediction data」に「diamonds_test」を指定すると、テストデータ(diamonds_test)の目的変数が予測されます。予測結果は、「Store predictions」に予測結果を保存する変数名(デフォルトではpred_reg)を入力し「+Store」ボタンをクリックすると、テストデータ(diamonds_test)にその変数が追加され保存されます。
2-2. 決定木
先ず、学習データ(diamonds_train)で予測モデルを学習(構築)します。
メニューから「Model」を選択し「Classification and regression trees」をクリックします。
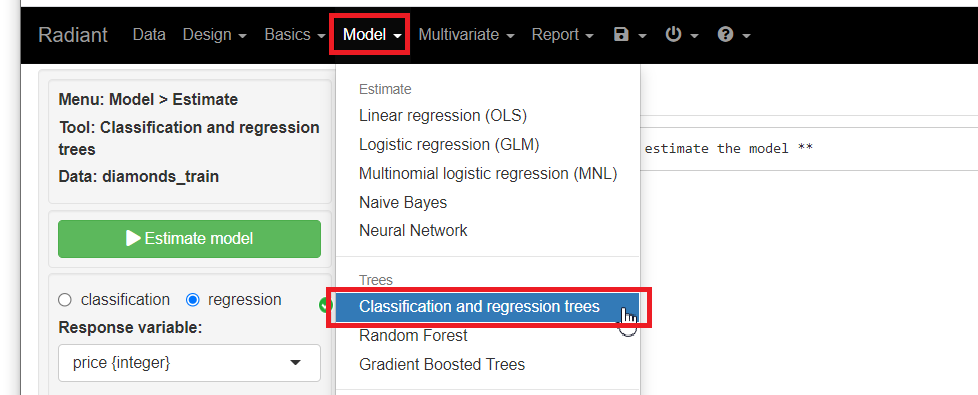
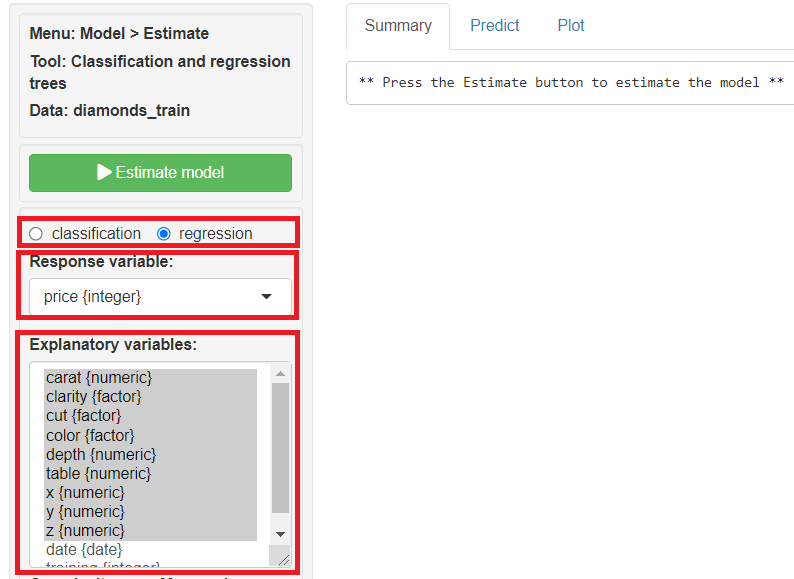
regressionにチェックを入れ、Response variables(目的変数)に「price」、Explanatory variables(説明変数)に「carat」「clarity」「cut」「color」「depth」「table」「x」「y」「z」を指定し、「Estimate model」をクリックし予測モデルを構築します。
「Summary」に学習(構築)した予測モデルの概要が表示されます。
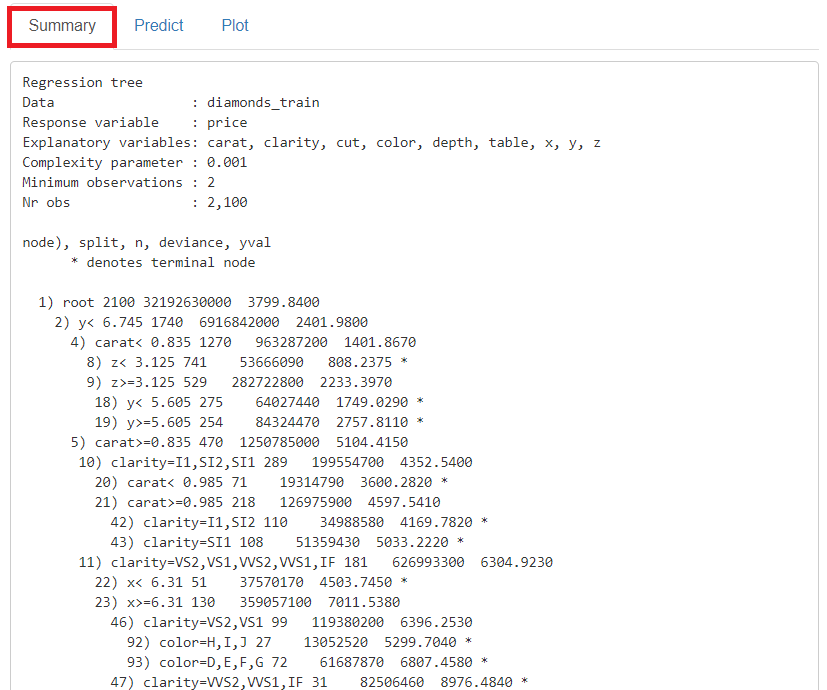
学習(構築)した予測モデルのツリーをグラフィカルに見てみます。
「Plot」をクリックし、左上の「Plots」に「Tree」を指定すると、予測モデルのツリーをグラフ化したものが表示されます。
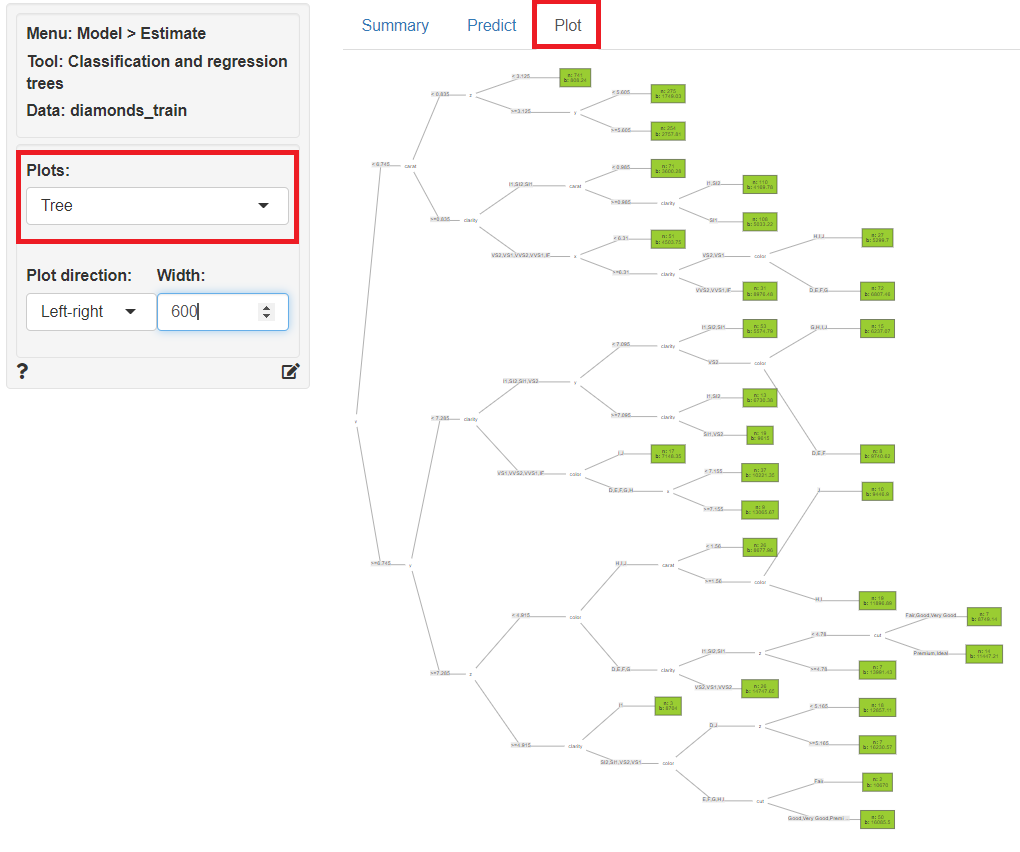
次に、予測モデルでテストデータ(diamonds_test)の目的変数を予測します。
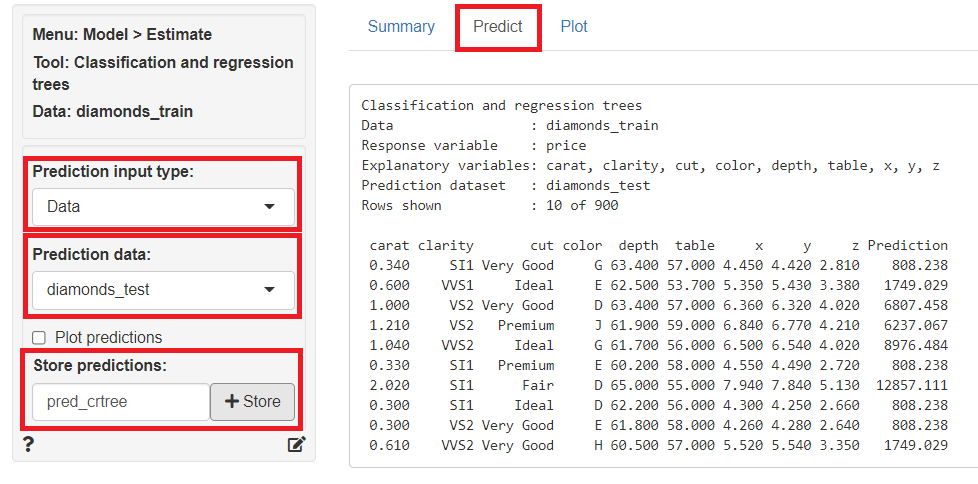
「Predict」をクリックし、左上の「Prediction Input type」に「Data」を指定、「Prediction data」に「diamonds_test」を指定すると、テストデータ(diamonds_test)の目的変数が予測されます。予測結果は、「Store predictions」に予測結果を保存する変数名(デフォルトではpred_crtree)を入力し「+Store」ボタンをクリックすると、テストデータ(diamonds_test)にその変数が追加され保存されます。
2-3. XGBoost
先ず、学習データ(diamonds_train)で予測モデルを学習(構築)します。
メニューから「Model」を選択し「Gradient Boosted Trees」をクリックします。
regressionにチェックを入れ、Response variables(目的変数)に「price」、Explanatory variables(説明変数)に「carat」「clarity」「cut」「color」「depth」「table」「x」「y」「z」を指定し、「Estimate model」をクリックし予測モデルを構築します。
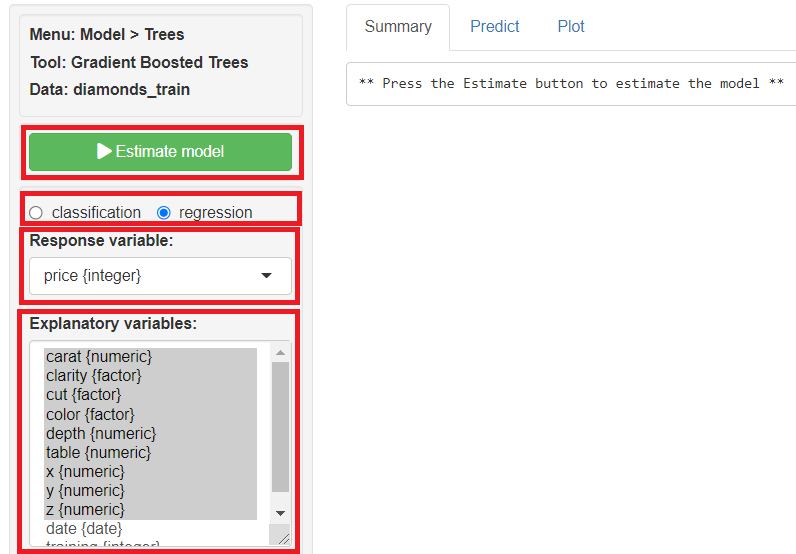
「Summary」に学習(構築)した予測モデルの概要が表示されます。
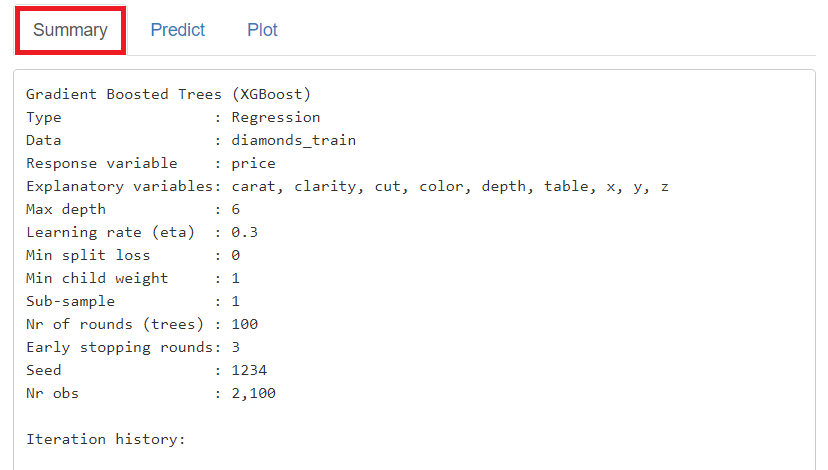
学習(構築)した予測モデルの、目的変数に対する各説明変数の重要度や目的変数と各説明変数の関係性をグラフィカルに見てみます。
「Plot」をクリックし、左上の「Plots」に「Variable Importance」を指定すると、目的変数に対する各説明変数の重要度をグラフ化したものが表示されます。
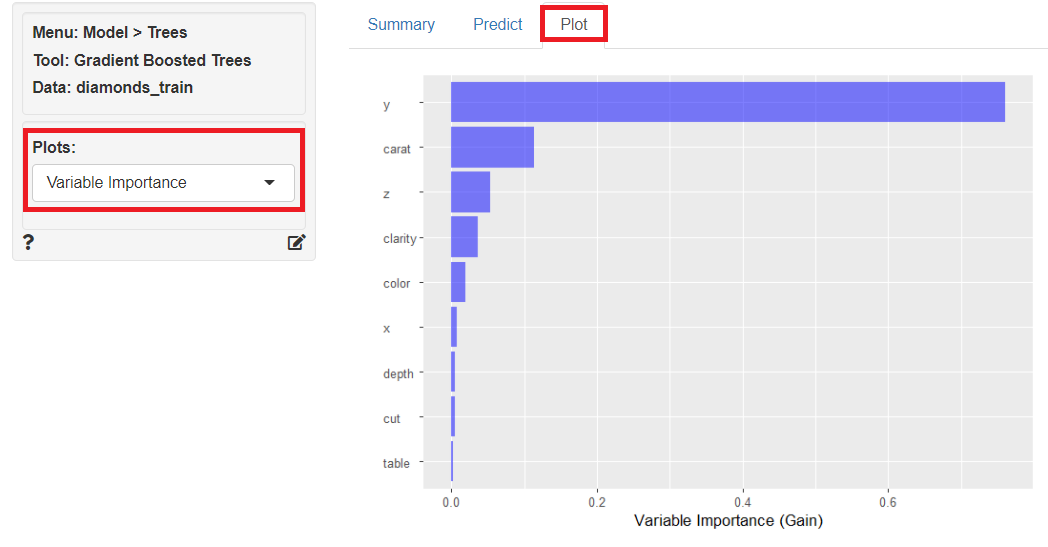
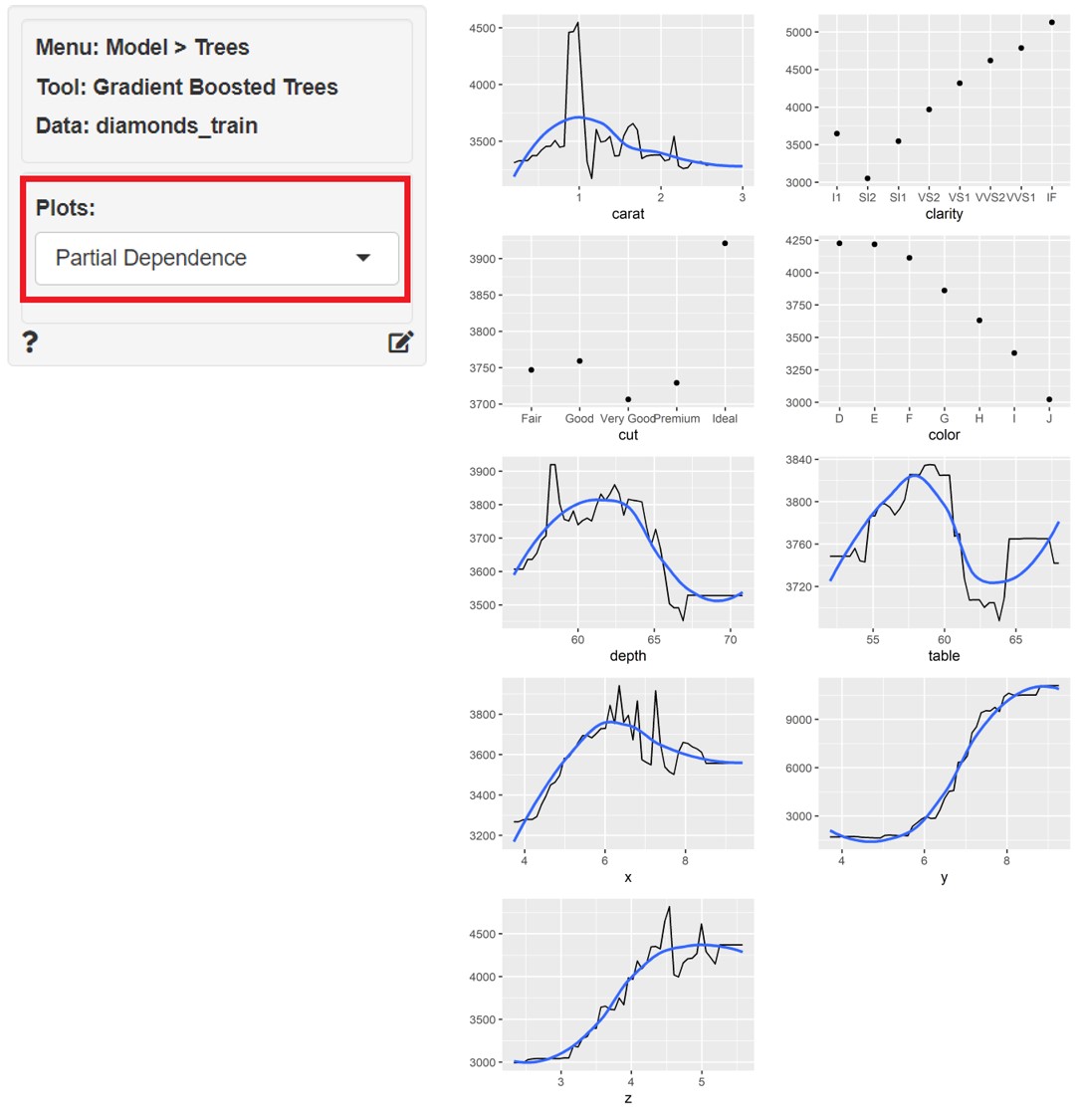
どの変数が重要なのかが分かったら、次に知りたいと思うのは、目的変数と各説明変数の関係性ではないでしょうか。
左上の「Plots」に「Partial Dependence」を指定すると、目的変数と各説明変数の関係性をグラフ化したものが表示されます。
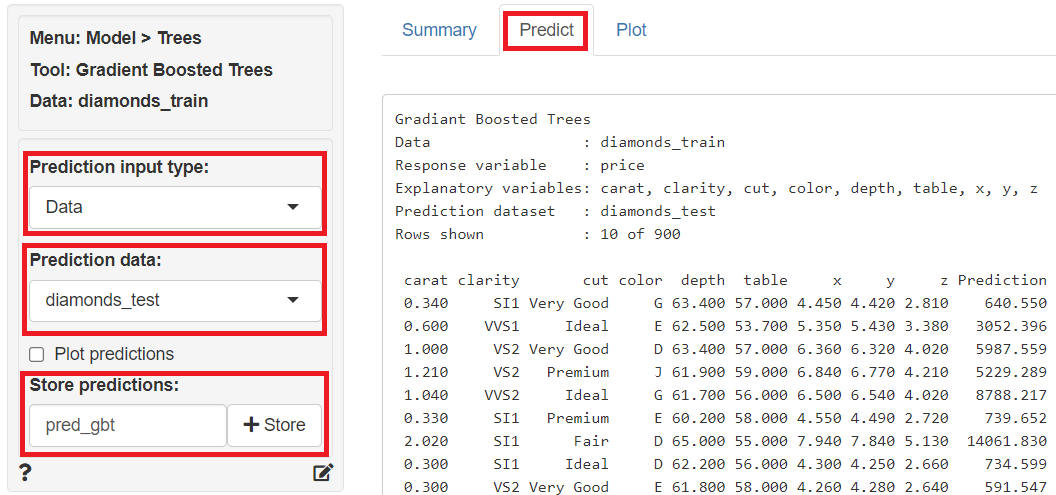
次に、予測モデルでテストデータ(diamonds_test)の目的変数を予測します。
「Predict」をクリックし、左上の「Prediction Input type」に「Data」を指定、「Prediction data」に「diamonds_test」を指定すると、テストデータ(diamonds_test)の目的変数が予測されます。予測結果は、「Store predictions」に予測結果を保存する変数名(デフォルトではpred_gbt)を入力し「+Store」ボタンをクリックすると、テストデータ(diamonds_test)にその変数が追加され保存されます。
3. 予測モデルの検証結果表示(R2、RMSE、MAE)
メニューから「Data」を選択し「Manage」をクリックします。左上に表示されている「Datasets」のところを「diamonds_test」にします。
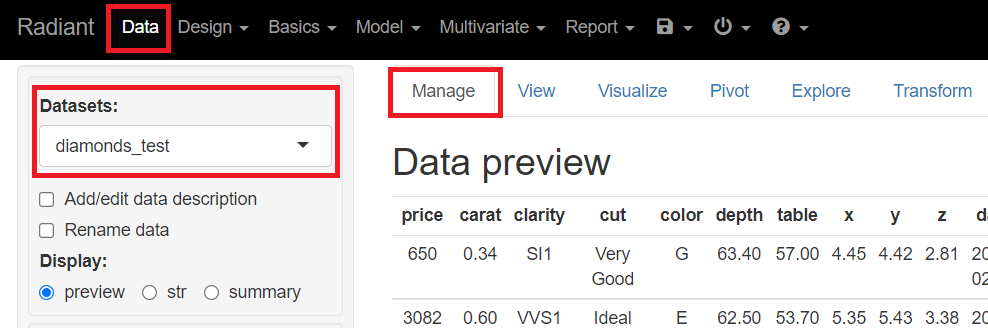
diamonds_testに、先ほど予測した値が入った変数があります。
- price:実測値
- pred_reg:線形回帰で求めた予測値
- pred_crtree:回帰木で求めた予測値
- pred_gbt:XGBoostで求めた予測値
では、目的変数の実測値(price)と予測値のギャップから予測精度を評価していきます。
メニューから「Model」を選択し「Evaluate regression」をクリックします。
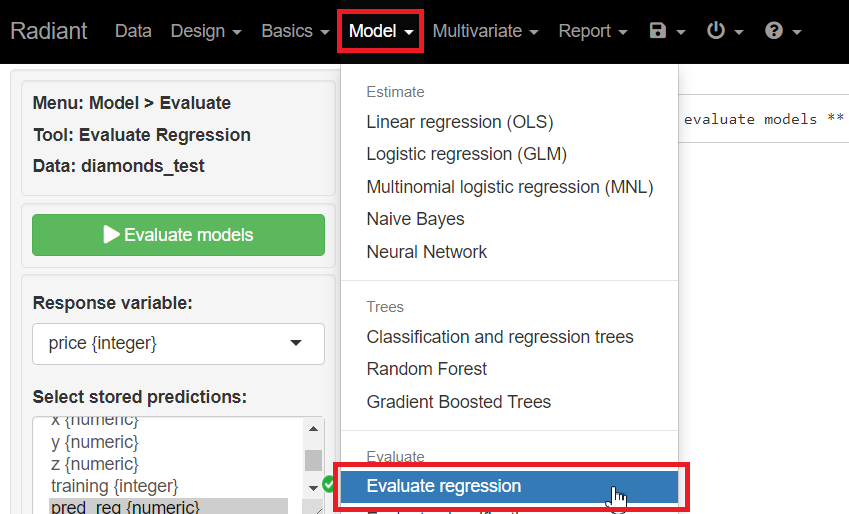
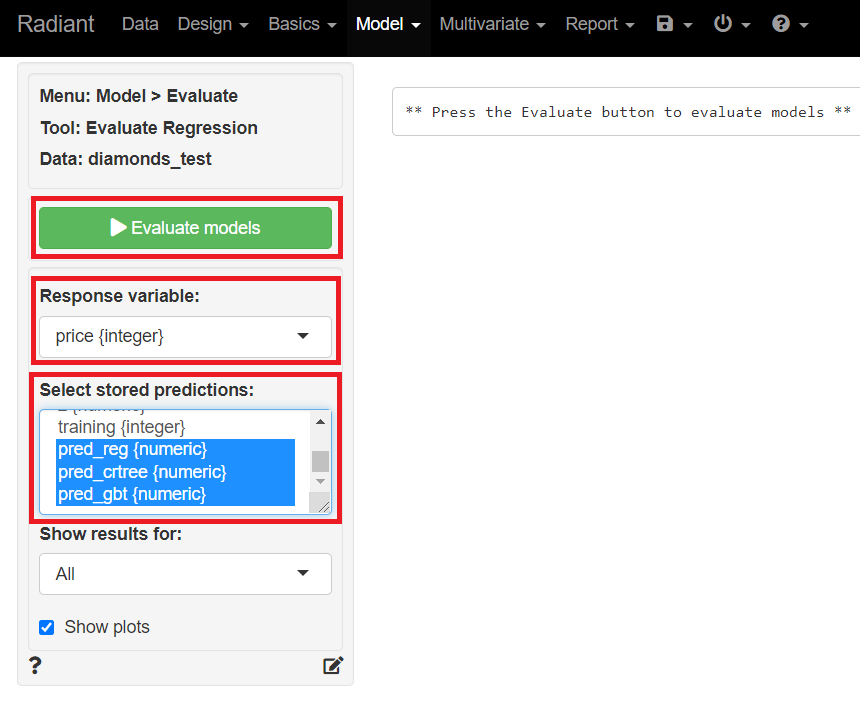
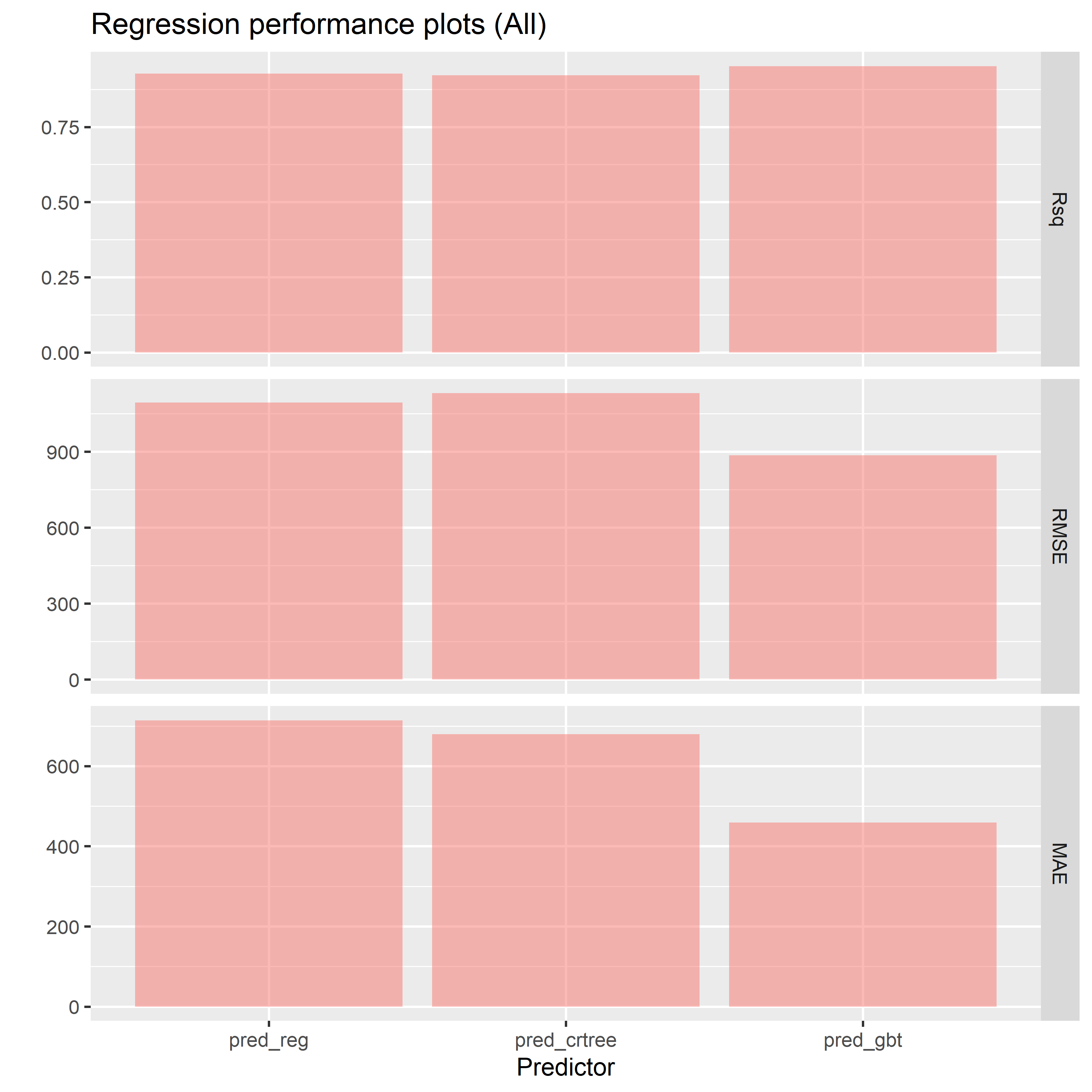
Response variables(目的変数)に「price」、Selected stored predictions(保存してある予測値の選択)に「pred_reg」「pred_crtree」「pred_gbt」を指定し、「Evaluate models」をクリックし予測精度を評価しその結果を表示させます。
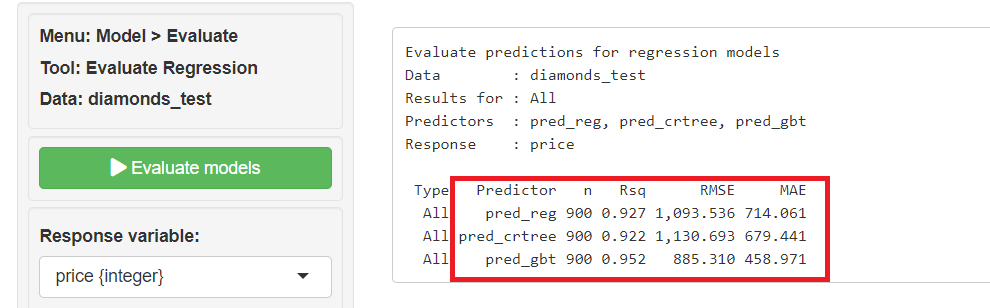
以下、R2(Rsq)とRMSE、MAEです。R2(Rsq)は値が大きいほど良く(最大1)、RMSEとMAEは値が小さいほど良い(最小0)です。
「Show plots」にチェックを入れると、以下のようなグラフも表示されます。
次回
今回は、その5の「Radiantで予測モデル構築」の「その5-2 回帰問題(線形回帰・回帰木・XGBoost)」について簡単に説明しました。
- その1:Radiantのインストール・起動・終了
- その2:Radiantのデータ読み込み
- その3:Radiantでデータ抽出(絞り込み)
- その4:RadiantでEDA(探索的データ分析)
- その4-1 グラフ作成
- その4-2 ピボット集計
- その4-3 記述統計量
- その5:Radiantで予測モデル構築
- その5-1 学習データとテストデータへの分割
- その5-2 回帰問題(線形回帰・回帰木・XGBoost)
- その5-3 分類問題(ロジスティック回帰・ランダムフォレスト・ニューラルネット) ⇒ 次回
次回は、その5の「Radiantで予測モデル構築」の「その5-3 分類問題(多項ロジスティック回帰・決定木・ニューラルネット)」について説明します。