
データ分析や予測モデル構築などをやってみたいが……
- RやPythonだとの無料ツールはコーディングスキルがそれなりに必要になりハードルがある
- 有料ツールのSASやSPSSなどは使いやすそうだけど高額すぎる。
無料で使える使いやすさが有料級の分析ツールはないだろうか?
と言うことで、Radiantです。
Radiantは、ノーコードでビジネスデータ分析を可能にする無料で使える有料級Rパッケージです。
- その1:Radiantのインストール・起動・終了
- その2:Radiantのデータ読み込み
- その3:Radiantでデータ抽出(絞り込み)
- その4:RadiantでEDA(探索的データ分析)
- その4-1 グラフ作成
- その4-2 ピボット集計
- その4-3 記述統計量
- その5:Radiantで予測モデル構築
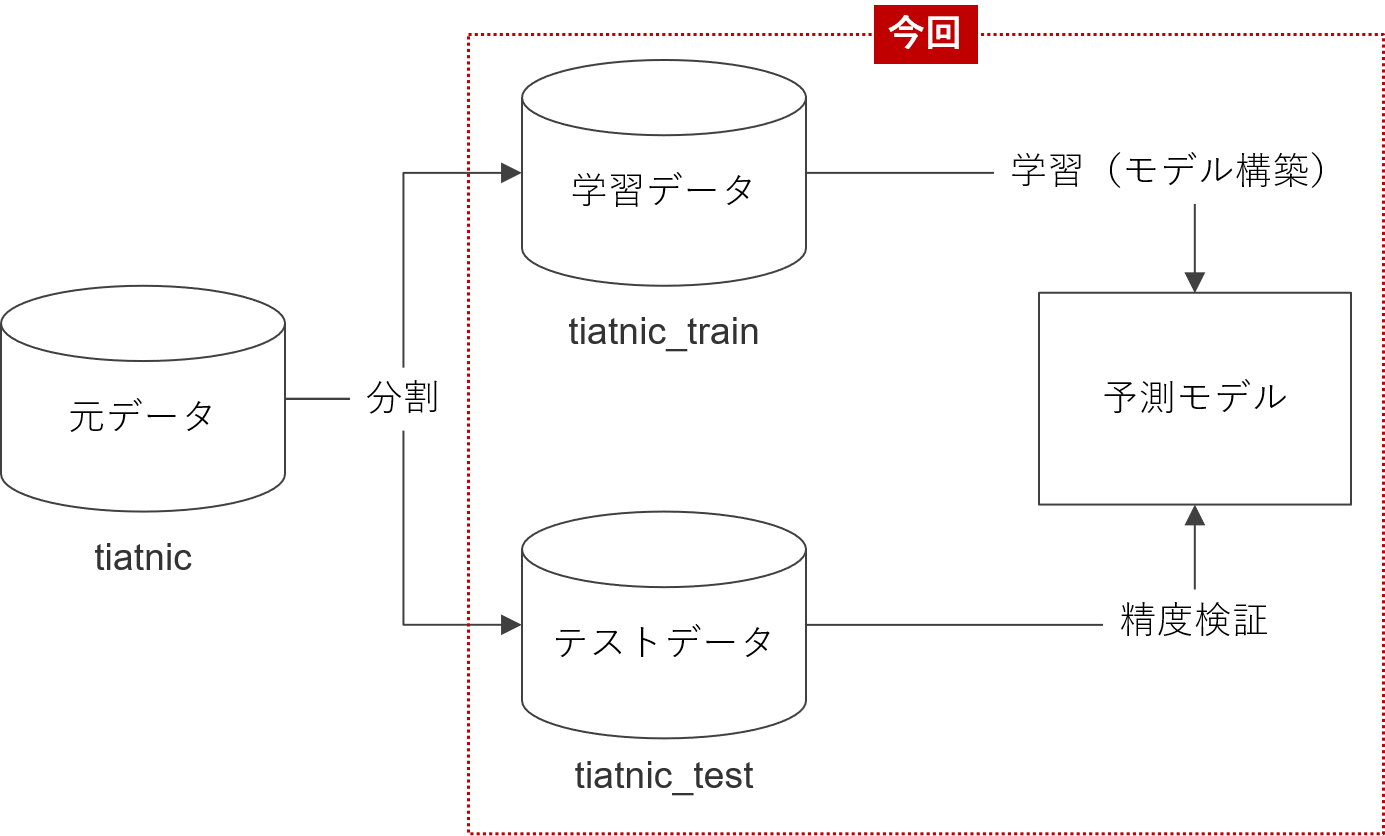
- その5-1 学習データとテストデータへの分割
- その5-2 回帰問題(線形回帰・回帰木・XGBoost)
- その5-3 分類問題(ロジスティック回帰・ランダムフォレスト・ニューラルネット) ⇒ 今回
前回は、その5-2の「回帰問題(線形回帰・回帰木・XGBoost)」について簡単に説明しました。
今回は、その5の「Radiantで予測モデル構築」の「その5-3 分類問題(ロジスティック回帰・ランダムフォレスト・ニューラルネット)」について簡単に説明します。
利用するデータ
サンプルデータは、Radiantのサンプルデータである「titanic」をそのまま使います。
- pclass:Ticket class(1 = 1st, 2 = 2nd, 3 = 3rd)
- survival:0 = No, 1 = Yes
- sex:male, female
- age:Age in years
- sibsp:Number of siblings and spouses aboard Titanic
- parch:Number of parents and children aboard the Titanic.
- fare:Passenger fare
- name
- cabin:Cabin number
- embarked:Port of Embarkation(C = Cherbourg, Q = Queenstown, S = Southampton)
上から2番目の2値変数「survival」が目的変数で、「survival」「name」「cabin」以外が説明変数(特徴量)です。
前々回作成した学習データで予測モデルを構築し、テストデータで検証します。
- 学習データ:titanic_train
- テストデータ:titanic_test
予測モデル
今回構築する予測モデルは、以下の3つです。
- ロジスティック回帰
- ニューラルネットワーク(3層型)
- ランダムフォレスト
評価指標
テストデータによる検証時に利用する評価指標は、シンプルに正答率(accuracy)を今回使います。
正答率=正答数÷テストデータ数
流れ
簡単な流れを説明します。
- Radiantを起動
- 予測モデルの学習(構築)と目的変数の予測
- ロジスティック回帰
- 学習データ(titanic_train)で予測モデルを学習(構築)
- 予測モデルでテストデータ(titanic_test)の目的変数を予測
- ニューラルネットワーク(3層型)
- 学習データ(titanic_train)で予測モデルを学習(構築)
- 予測モデルでテストデータ(titanic_test)の目的変数を予測
- ランダムフォレスト
- 学習データ(titanic_train)で予測モデルを学習(構築)
- 予測モデルでテストデータ(titanic_test)の目的変数を予測
- ロジスティック回帰
- 予測モデルの検証結果表示(正答率、accuracy)
1. Radiantを起動
以下、コードです。
# 必要パッケージのロード library(radiant) # radiantの起動 radiant()
2. 予測モデルの学習(構築)と目的変数の予測
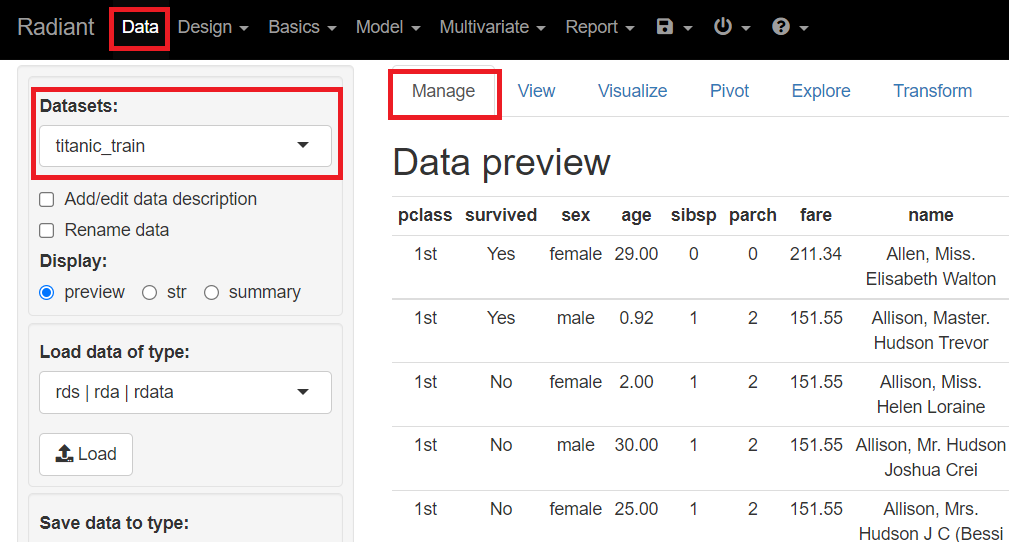
メニューから「Data」を選択し「Manage」をクリックします。左上に表示されている「Datasets」のところを「titanic_train」にします。
2-1. ロジスティック回帰
先ず、学習データ(diamonds_train)で予測モデルを学習(構築)します。
メニューから「Model」を選択し「Logistic regression(GLM)」をクリックします。
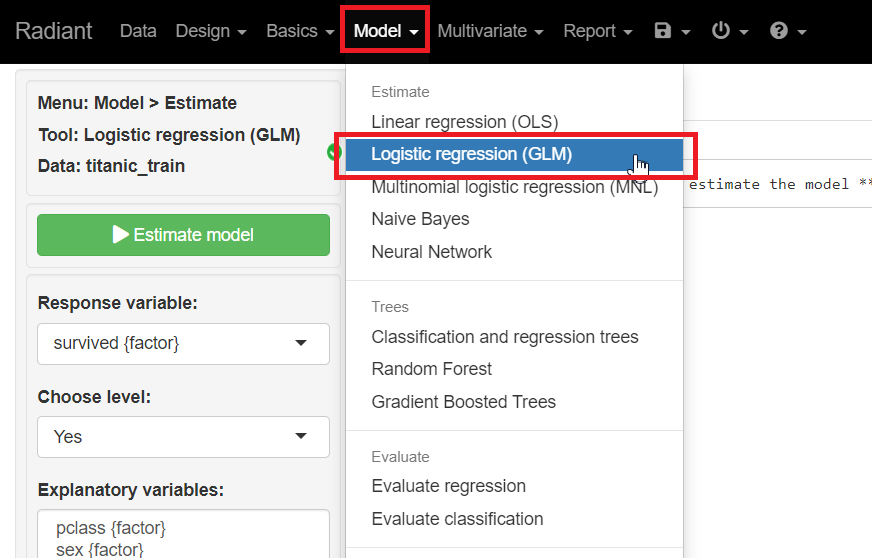
Response variables(目的変数)に「survived」、Explanatory variables(説明変数)に「pclass」「sex」「age」「sibsp」「parch」「fare」「embarked」を指定し、「Estimate model」をクリックし予測モデルを構築します。ちなみに今回は、Standarize(標準化)とRobust(ロバスト)にチェックを入れています。
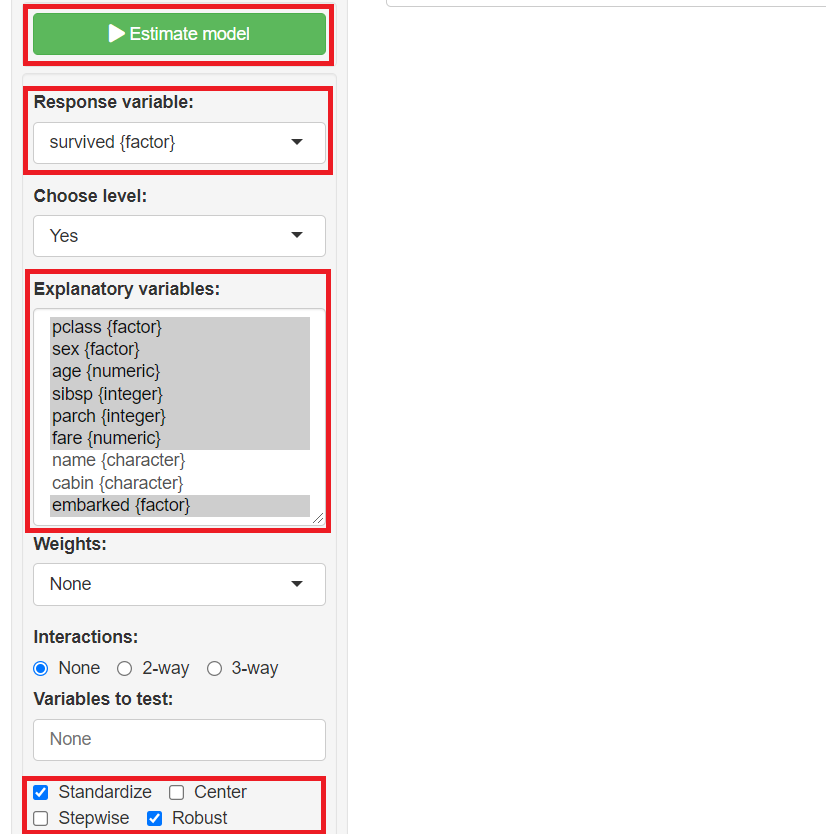
「Summary」に学習(構築)した予測モデルの概要が表示されます。
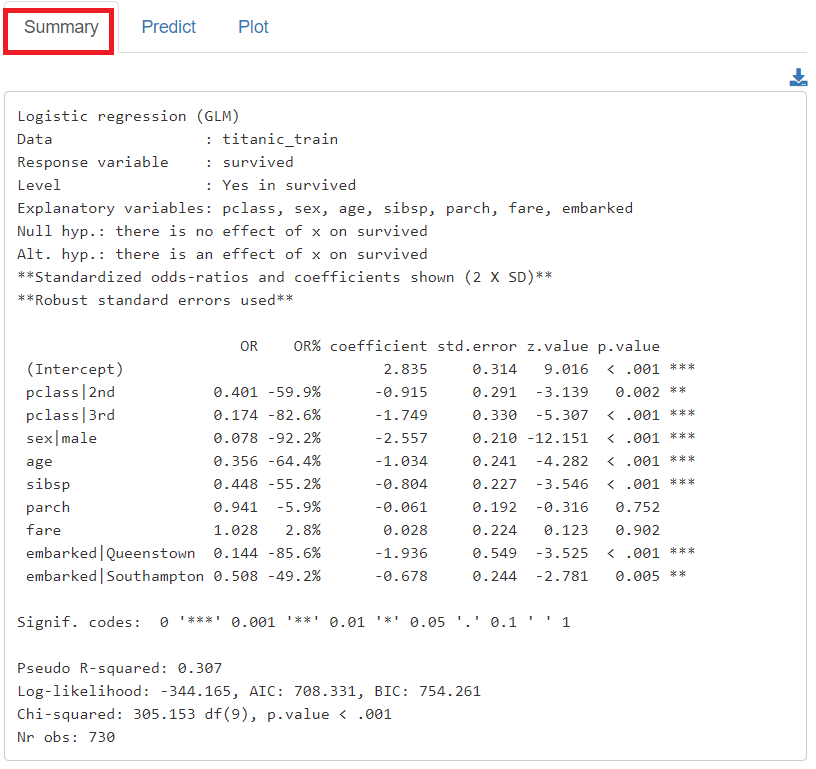
学習(構築)した予測モデルの、各説明変数の係数をグラフィカルに見てみます。
「Plot」をクリックし、左上の「Plots」に「Coefficient (OR) plot」を指定すると、各説明変数の係数をグラフ化したものが表示されます。
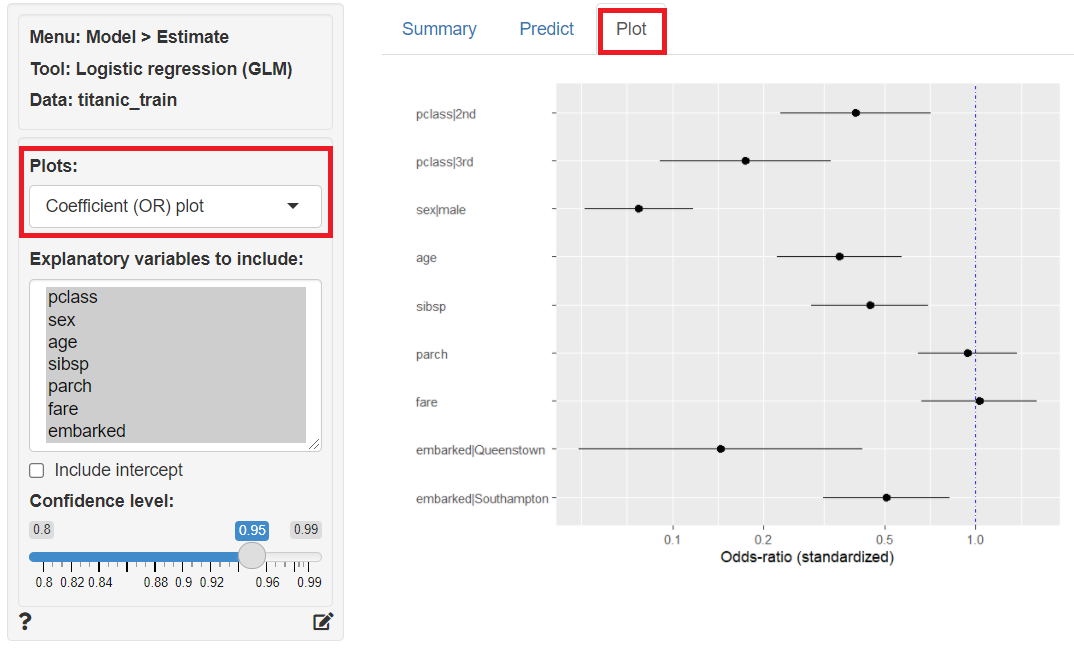
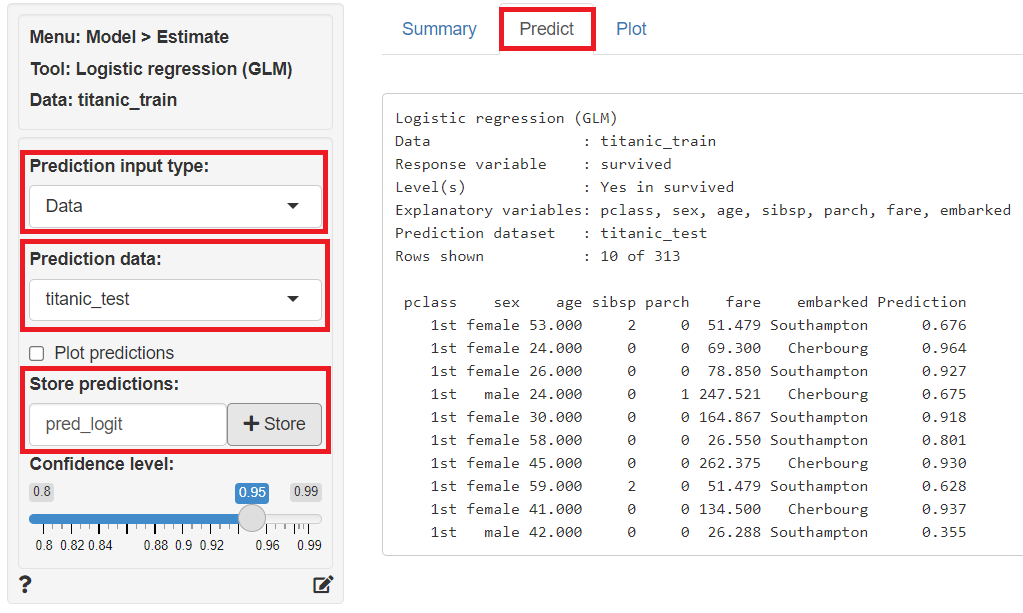
次に、予測モデルでテストデータ(titanic_test)の目的変数を予測します。
「Predict」をクリックし、左上の「Prediction Input type」に「Data」を指定、「Prediction data」に「titanic_test」を指定すると、テストデータ(titanic_test)の目的変数が予測されます。予測結果は、「Store predictions」に予測結果を保存する変数名(デフォルトではpred_logit)を入力し「+Store」ボタンをクリックすると、テストデータ(titanic_test)にその変数が追加され保存されます。
2-2. ニューラルネットワーク(3層型)
先ず、学習データ(titanic_train)で予測モデルを学習(構築)します。
メニューから「Model」を選択し「Neural Network」をクリックします。
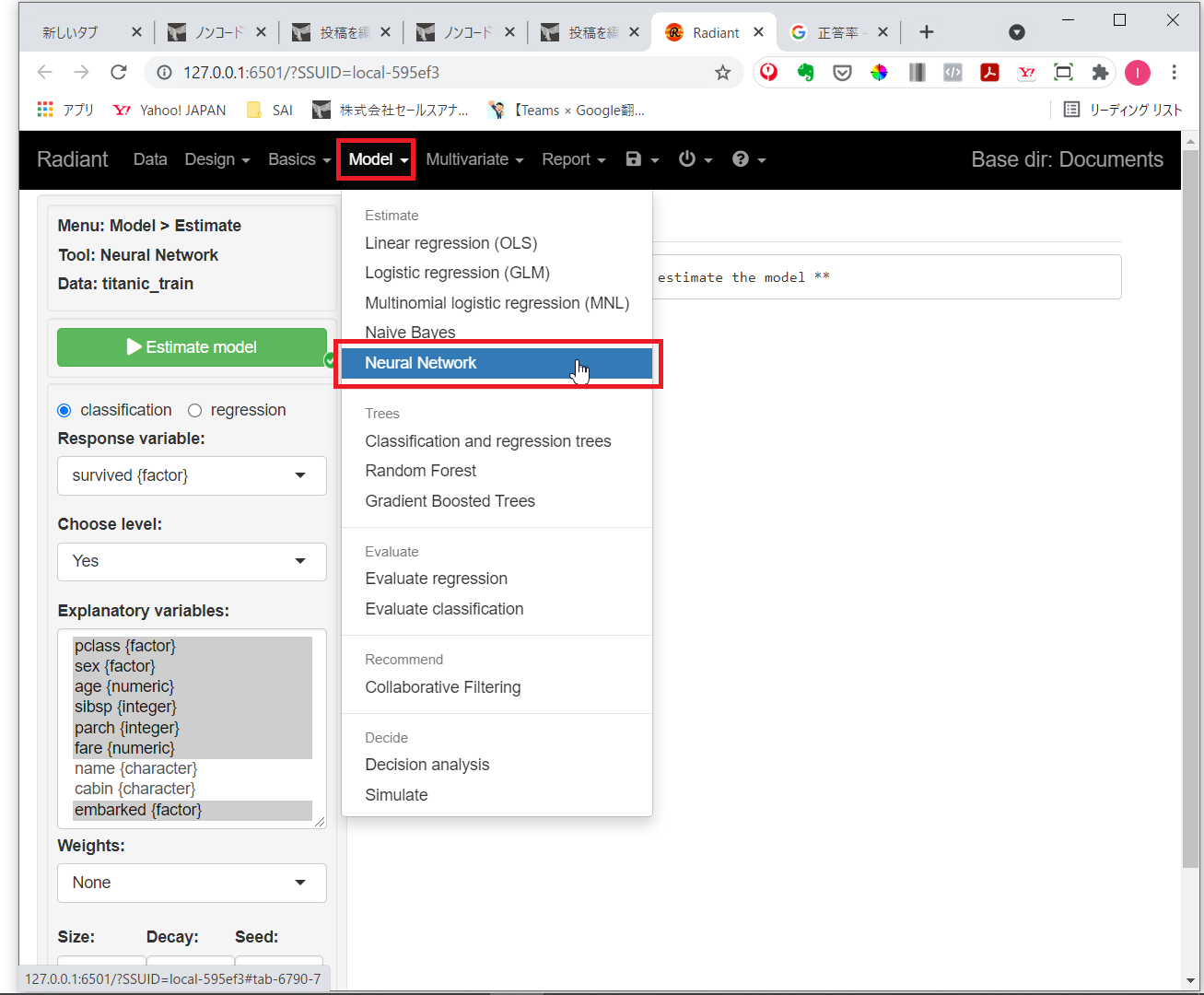
classficationにチェックを入れ、Response variables(目的変数)に「survived」、Explanatory variables(説明変数)に「pclass」「sex」「age」「sibsp」「parch」「fare」「embarked」を指定し、中間層のノードの数(「Size」)を5、「Decay」を0.05、「Estimate model」をクリックし予測モデルを構築します。
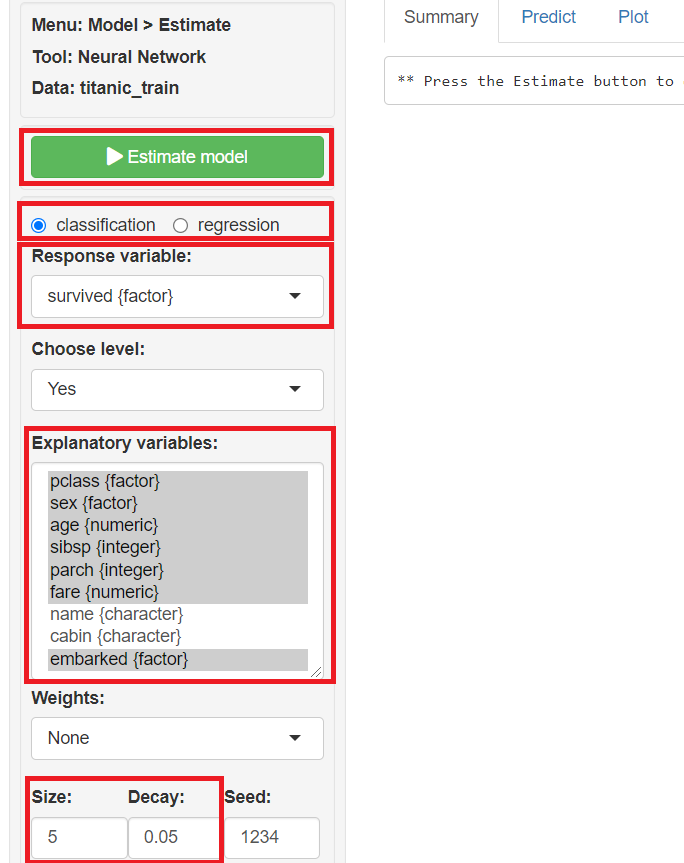
「Summary」に学習(構築)した予測モデルの概要が表示されます。
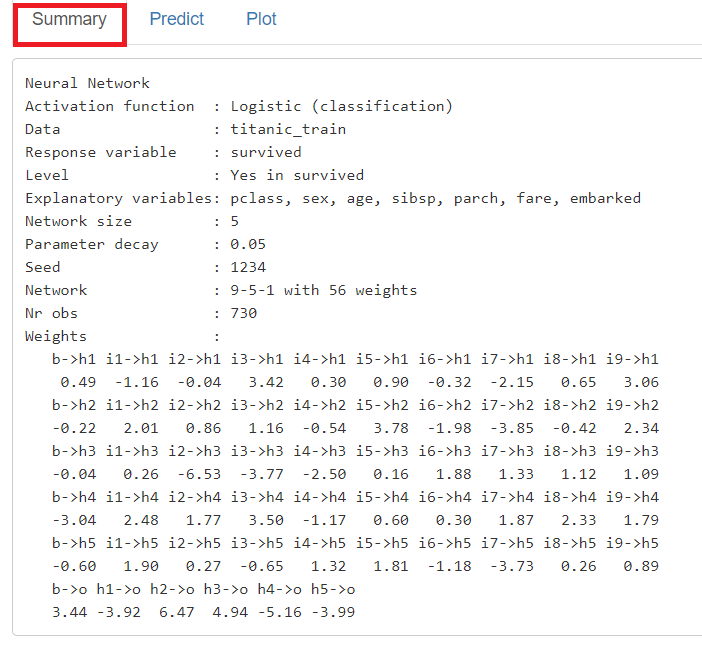
学習(構築)した予測モデルのニューラルネットワークをグラフィカルに見てみます。
「Plot」をクリックし、左上の「Plots」に「Network」を指定すると、予測モデルのニューラルネットワークを表現したグラフが表示されます。
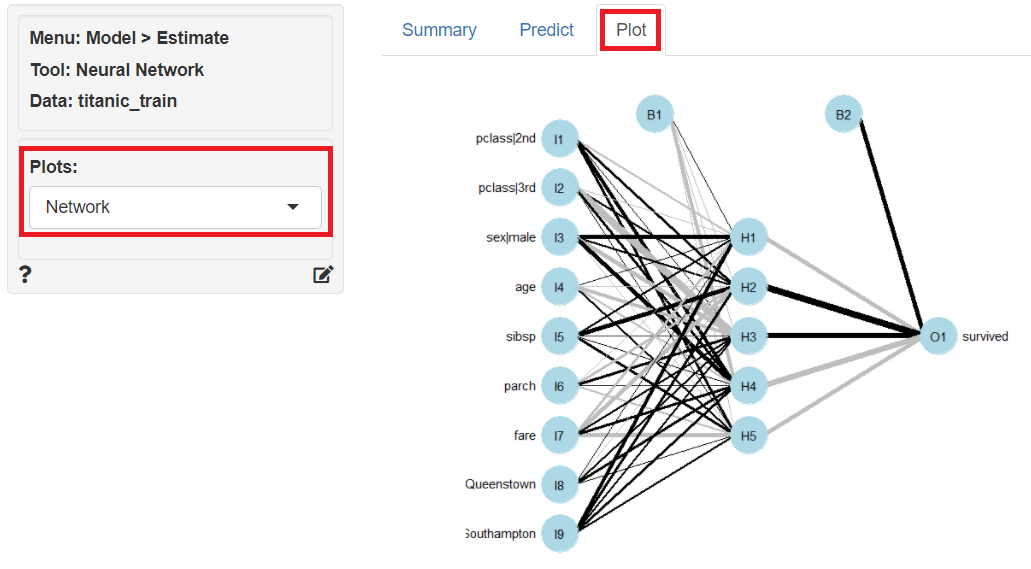
次に、予測モデルでテストデータ(titanic_test)の目的変数を予測します。
「Predict」をクリックし、左上の「Prediction Input type」に「Data」を指定、「Prediction data」に「titanic_test」を指定すると、テストデータ(titanic_test)の目的変数が予測されます。予測結果は、「Store predictions」に予測結果を保存する変数名(デフォルトではpred_nn5)を入力し「+Store」ボタンをクリックすると、テストデータ(titanic_test)にその変数が追加され保存されます。
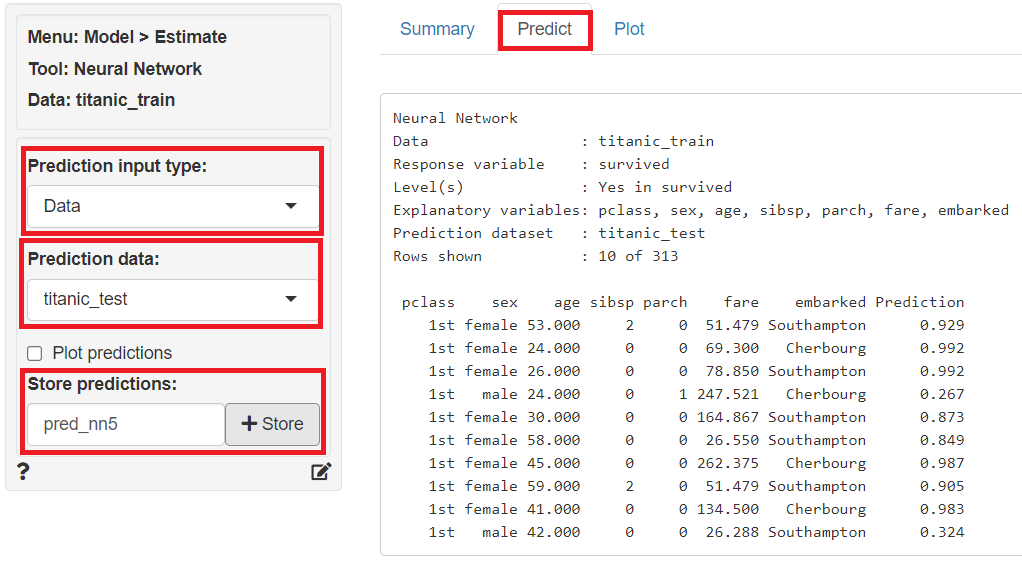
2-3. ランダムフォレスト
先ず、学習データ(titanic_train)で予測モデルを学習(構築)します。
メニューから「Model」を選択し「Random Forest」をクリックします。
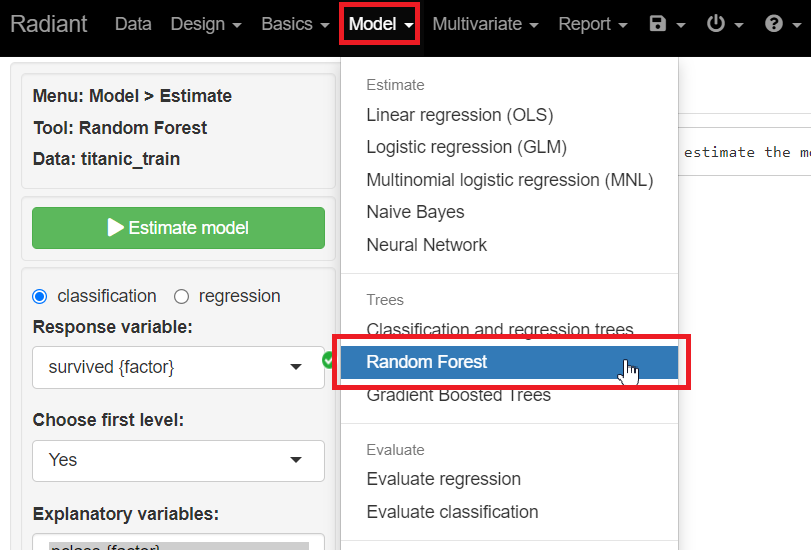
classficationにチェックを入れ、Response variables(目的変数)に「survived」、Explanatory variables(説明変数)に「pclass」「sex」「age」「sibsp」「parch」「fare」「embarked」を指定し、「Estimate model」をクリックし予測モデルを構築します。
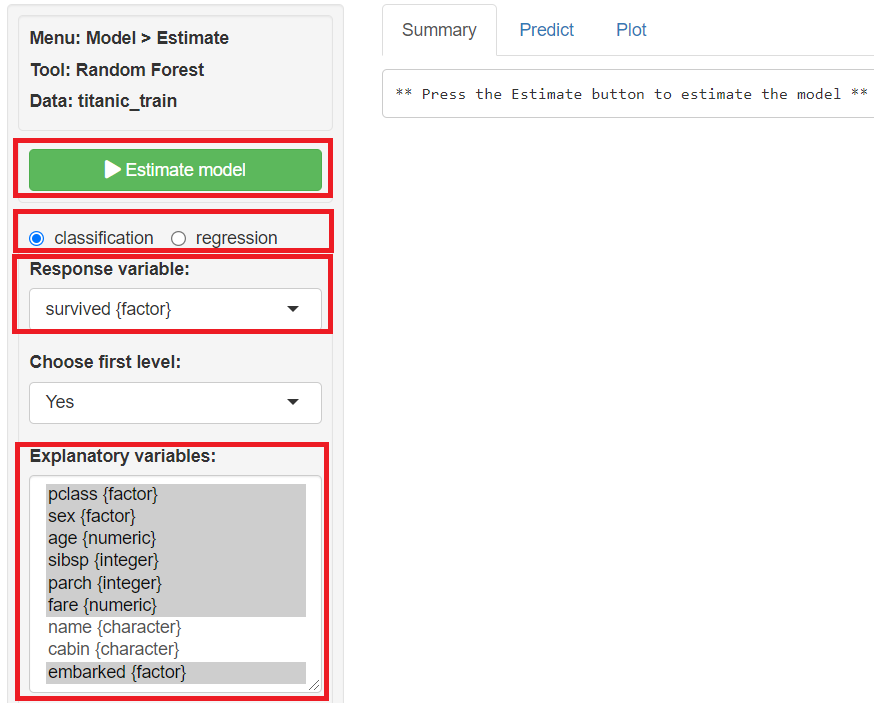
「Summary」に学習(構築)した予測モデルの概要が表示されます。
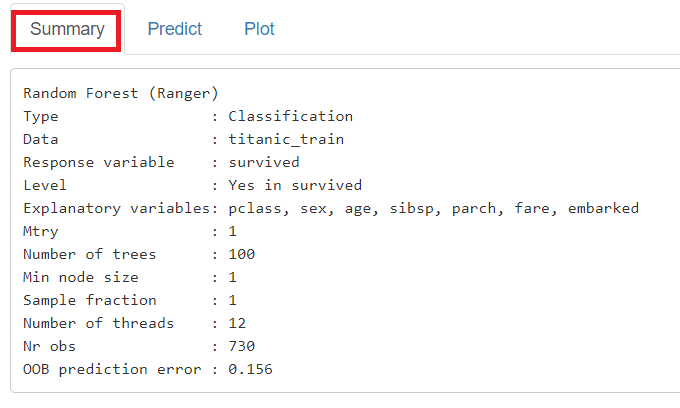
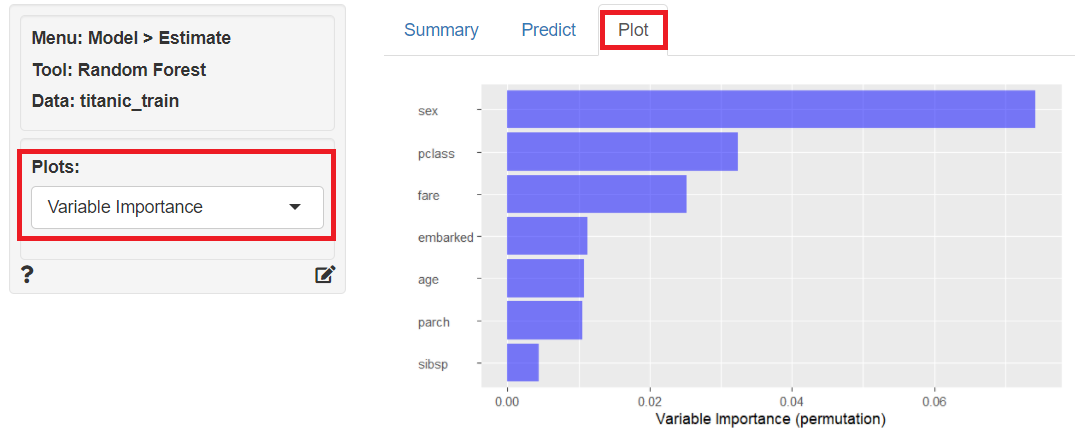
学習(構築)した予測モデルの、目的変数に対する各説明変数の重要度や目的変数と各説明変数の関係性をグラフィカルに見てみます。
「Plot」をクリックし、左上の「Plots」に「Variable Importance」を指定すると、目的変数に対する各説明変数の重要度をグラフ化したものが表示されます。
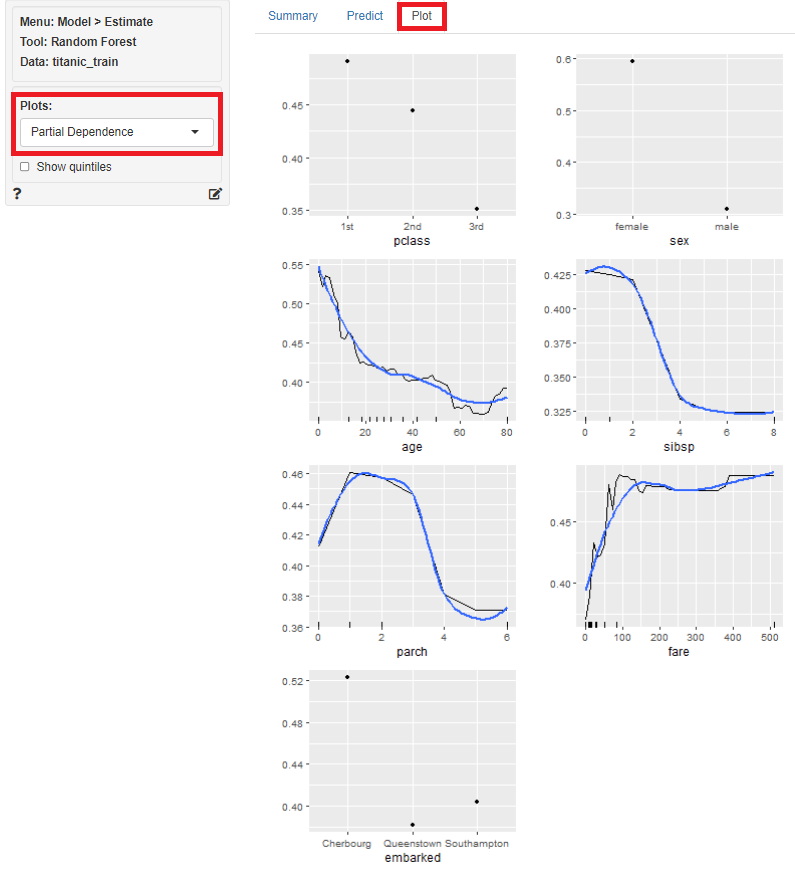
どの変数が重要なのかが分かったら、次に知りたいと思うのは、目的変数と各説明変数の関係性ではないでしょうか。
左上の「Plots」に「Partial Dependence」を指定すると、目的変数と各説明変数の関係性をグラフ化したものが表示されます。
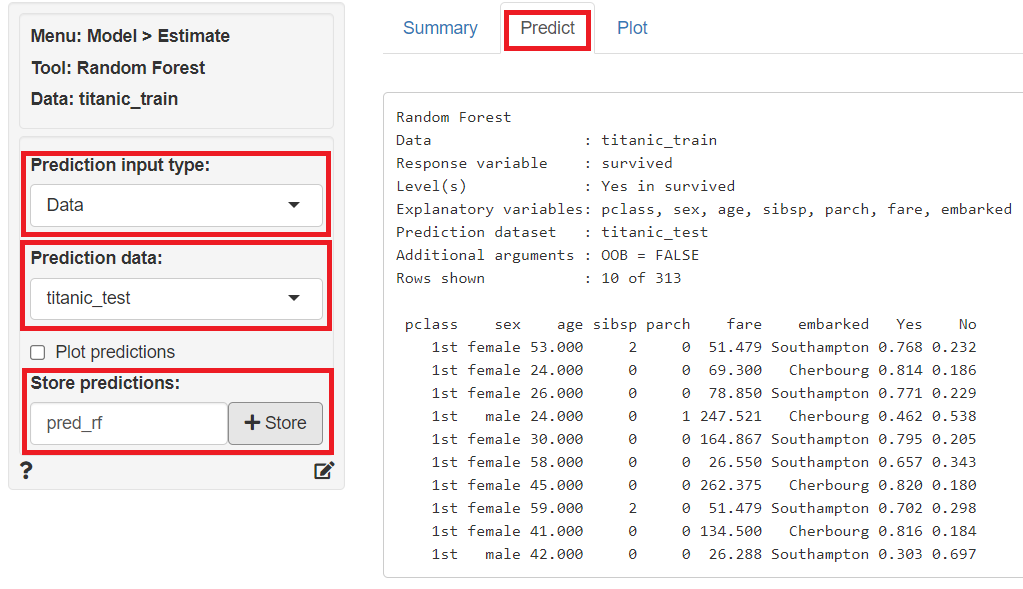
次に、予測モデルでテストデータ(titanic_test)の目的変数を予測します。
「Predict」をクリックし、左上の「Prediction Input type」に「Data」を指定、「Prediction data」に「titanic_test」を指定すると、テストデータ(titanic_test)の目的変数が予測されます。予測結果は、「Store predictions」に予測結果を保存する変数名(デフォルトではpred_rf)を入力し「+Store」ボタンをクリックすると、テストデータ(titanic_test)にその変数が追加され保存されます。
3. 予測モデルの検証結果表示(正答率、accuracy)
メニューから「Data」を選択し「Manage」をクリックします。左上に表示されている「Datasets」のところを「titanic_test」にします。
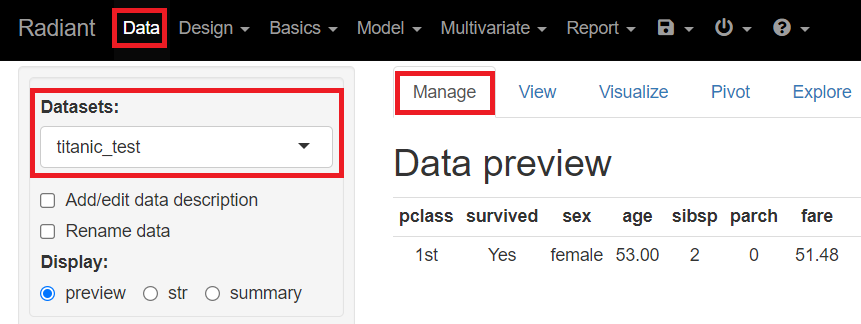
titanic_testに、先ほど予測した値が入った変数があります。
- survival:実測値
- pred_logit:ロジスティック回帰で求めた予測値
- pred_nn5:ニューラルネットワークで求めた予測値
- pred_rf:ランダムフォレストで求めた予測値
では、目的変数の実測値(survival)と予測値のギャップから予測精度を評価していきます。
メニューから「Model」を選択し「Evaluate classification」をクリックします。
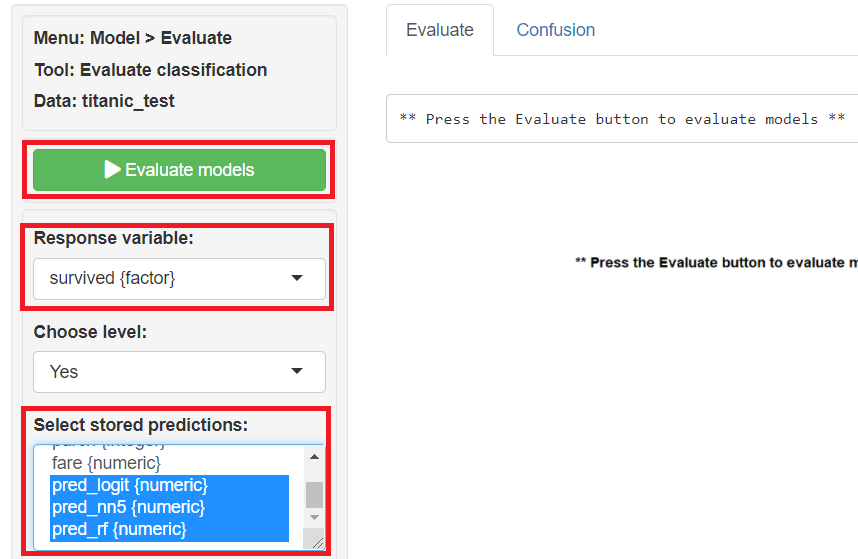
Response variables(目的変数)に「survival」、Selected stored predictions(保存してある予測値の選択)に「pred_logit」「pred_nn5」「pred_rf」を指定し、「Evaluate models」をクリックし予測精度を評価しその結果を表示させます。
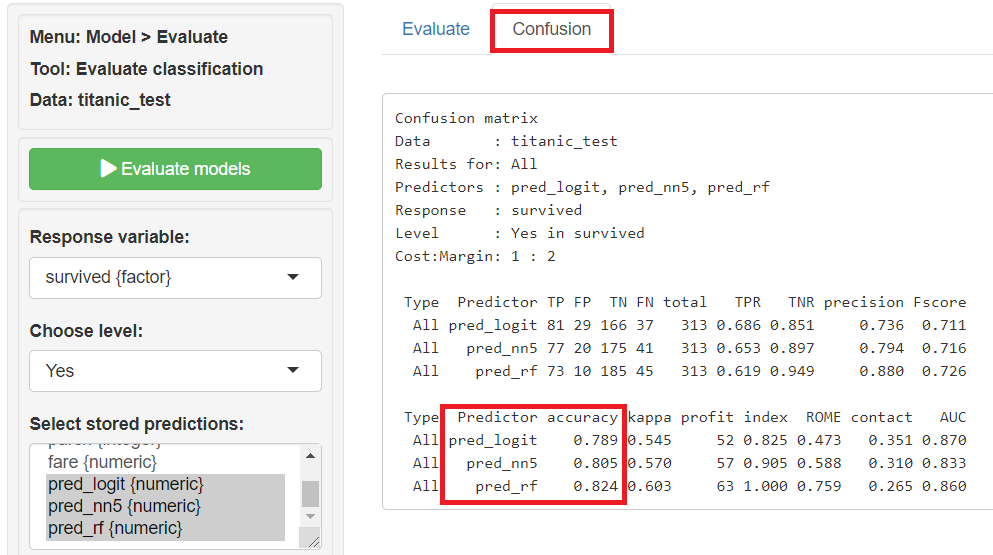
以下、正答率(accuracy)で、値が大きいほど良い(最大1)です。
まとめ
全9回を通して、ノーコードでビジネスデータ分析を可能にする、RパッケージRadiantの使い方を紹介しました。
ある程度のスキルの必要なRを、ほぼノーコードで使えるパッケージです。簡単に使えますので、興味のある方は使ってみてください。