
前回までは、時系列データ系の数理モデル(アルゴリズム)で、時系列予測モデルを構築し予測する方法について、説明してきました。前回は、Prophetモデルを扱いました。
多くの人にとって馴染みがあるのは、時系列データ系の数理モデル(アルゴリズム)よりも、テーブルデータ系の数理モデル(アルゴリズム)の方です。
例えば、以下の数理モデル(アルゴリズム)はテーブルデータ系のものです。
- 線形回帰モデル(単回帰、重回帰、など)
- 正則化回帰モデル(Ridge回帰、Lasso回帰、など)
- 一般化線形モデル(GLMM)
- 一般化加法モデル(GAM)
- 階層線形モデル、マルチレベルモデル、一般化混合モデル
- 決定木(ディシジョンツリー)
- ランダムフォレスト
- ブースティングモデル(AdaBoost、XGBoost、LightGBMなど)
- ニューラルネットワークモデル
……などなど。
テーブルデータ系の数理モデル(アルゴリズム)を使い、時系列予測モデルを作るには、時系列特徴量を生成することで、対応できます。
今回は、テーブルデータ系モデルで時系列予測するために、時系列特徴量を生成し、テーブルデータ系の数理モデルを構築するための準備をします。
利用するデータ
今回利用する時系列データのデータセットは、Airline Passengers(飛行機乗客数)は、Box and Jenkins (1976) の有名な時系列データです。サンプルデータとして、よく利用されます。
弊社のHPからもダウンロードできます。
弊社のHP上のURLからダウンロード
https://www.salesanalytics.co.jp/591h
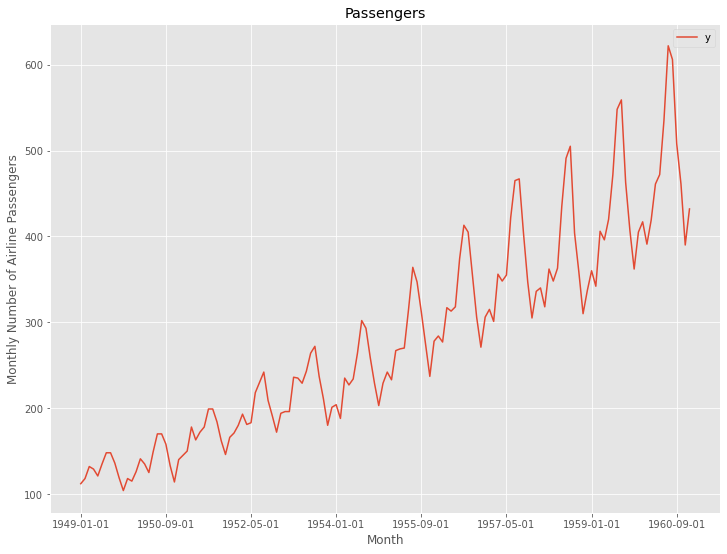
このデータは上昇トレンドと季節性(年間周期)があります。
今回生成する時系列特徴量
今回は、以下のラグ特徴量2つとローリング特徴量1つを生成します。
- ラグ特徴量(Lag Features)
- Lag 1
- Lag 12
- ローリング特徴量(Rolling Window Features)
- window size : 12
この3つの時系列特徴量で、上昇トレンドと季節性(年間周期)を表現します。
ライブラリーとデータの読み込み
では、必要なライブラリーを読み込みます。
以下、コードです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot') #グラフのスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ設定
次に、データを読み込みます。
以下、コードです。
# データセットの読み込み
url='https://www.salesanalytics.co.jp/591h' #データセットのあるURL
df=pd.read_csv(url, #読み込むデータのURL
index_col='Month', #変数「Month」をインデックスに設定
parse_dates=True) #インデックスを日付型に設定
時系列特徴量の生成
shift関数でラグ特徴量を2つ作ります。元データと結合し新たなデータセットを生成します。
以下、コードです。
# ラグ特徴量付データセット
df_lag = pd.concat([df,
df.shift(1),
df.shift(12)
],
axis=1
)
df_lag.columns = ['y',
'ylag1',
'ylag12'
]
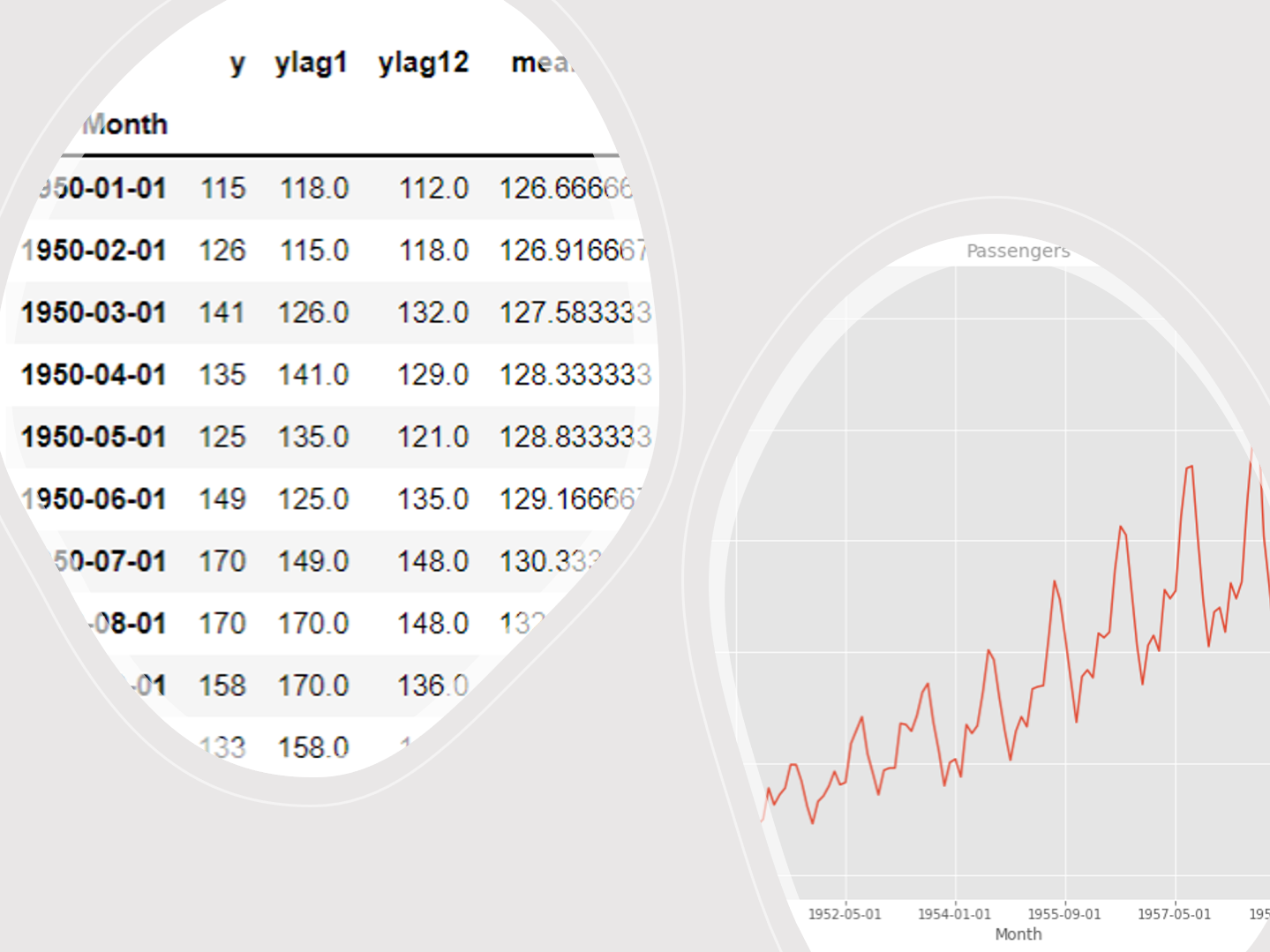
df_lag.head(20) #確認
以下、実行結果です。

次に、rolling関数でローリング特徴量を作ります。
以下、コードです。
# 過去12期平均(前期まで)~ mean(t-12,…,t-2,t-1) shifted = df.shift(1) window = shifted.rolling(window=12) means12 = window.mean() means12.columns = ['means_12'] means12.head(20) #確認
以下、実行結果です。
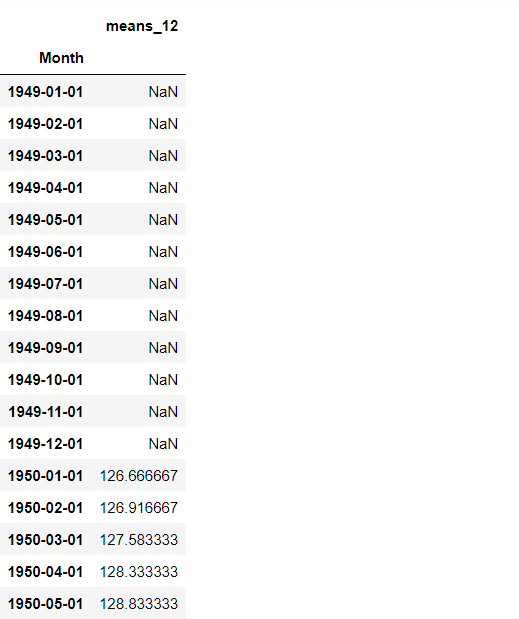
前期までの過去12期平均です。そのため、shift関数で1期ずらしたデータに対しrolling関数で特徴量を作っています。
先程生成したデータセットに、この時系列特徴量を結合します。
以下、コードです。
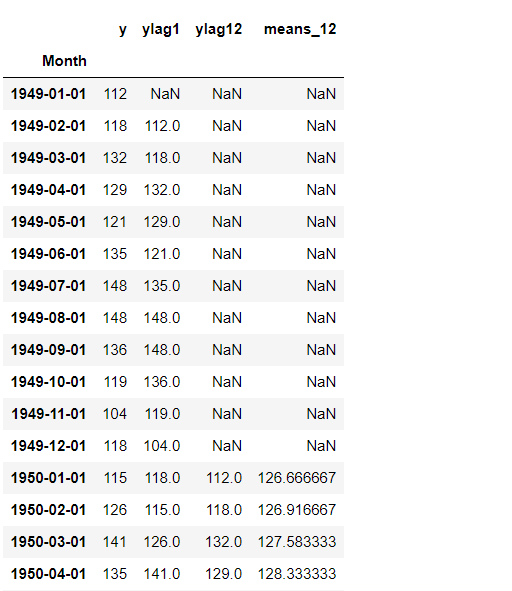
# ローリング特徴量付データセット df_lag_RW = pd.concat([df_lag,means12],axis=1) df_lag_RW.head(20) #確認
以下、実行結果です。
欠測値NaNを削除します。
以下、コードです。
# 欠損値NaNを除外 dataset = df_lag_RW.dropna() dataset.head(10) #確認
以下、実行結果です。
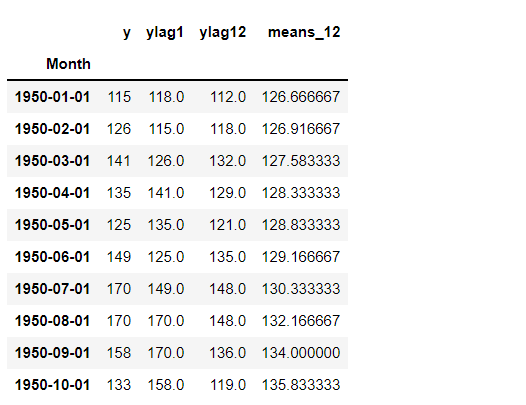
CSV出力
最後に、生成した時系列特徴量付きデータセットを、CSVファイルとして出力します。
以下、コードです。
dataset.to_csv("dataset.csv")
「dataset.csv」というファイル名にしています。
次回
今回は、テーブルデータ系モデルで時系列予測するために、時系列特徴量を生成し、テーブルデータ系の数理モデルを構築するための準備をしました。
次回は、今回作った時系列特徴量付きデータセットを使い、線形回帰系のモデルで時系列予測を実施していきます。