
Pythonユーザの中には、Jupyter上でPythonを使う方も多いことでしょう。
Pythonを使いながらRの便利な関数を利用したい、そう思われる方も多いことでしょう。
Jupyter上でPythonを使いながら、必要なときに手軽にRを使うことができます。
Jupyterのセルに、以下のコードを記載しておくだけで、可能になります。
%load_ext rpy2.ipython
今回は、「Python RPY2を使い Jupyter上でPythonとRを混在して使う」というお話しをします。
はじめに
以下の記事と同じ操作を、%load_ext rpy2.ipythonを宣言し実施していきます。
RPY2のインストール方法や簡単な使い方も、この記事で取り上げていますので、興味のある方は一読ください。
Jupyter上のPython環境でRのスクリプトを実行する
RのスクリプトをPython上で実行するには、Jupyterの最初の方のセルで%load_ext rpy2.ipythonを宣言しておきます。
rpy2などの必要なライブラリーとともに宣言しておくといいでしょう。
以下、コードです。
import pandas as pd import numpy as np import rpy2 %load_ext rpy2.ipython
Rのスクリプトを実行するときには、以下の2種類の方法があります。
%%Rで、セル全体をR環境にする%Rで、その行だけR環境にする
セル全体をR環境にし、3×5の演算をしています。
以下、コードです。
%%R a <- 3 b <- 5 c <- a*b c
以下、実行結果です。
![]()
Rの関数を使った例も示しておきます。
以下、コードです。平均値を求めています。
%%R a <- c(1,2,3,4,5,6) result <- mean(a) print(result)
以下、実行結果です。
![]()
PythonとRとの間で、データを簡単にやり取りする方法も示します。
%R -i <Python data>で、Python上のデータをRへ渡します%R -o <R data>で、R上のデータをPythonへ渡します
以下、コードです。このセル内では、PythonとRのコードが混在しています。
a = 3 #Python b = 5 #Python %R -i a #Python->R %R -i b #Python->R %R c <- a*b #R %R -o c #R->Python print(c) #Python
以下、実行結果です。
![]()
NumPyの配列やPndasのデータフレームも同様に、PythonとRとの間で、同様のやり方で簡単にやり取りできます。
Python上のデータ→Rで計算→Python上で出力
(時系列ARIMAモデル例)
Rの関数をPython上で利用する方法を、時系列のARIMAモデルの構築で説明します。
サンプルデータ
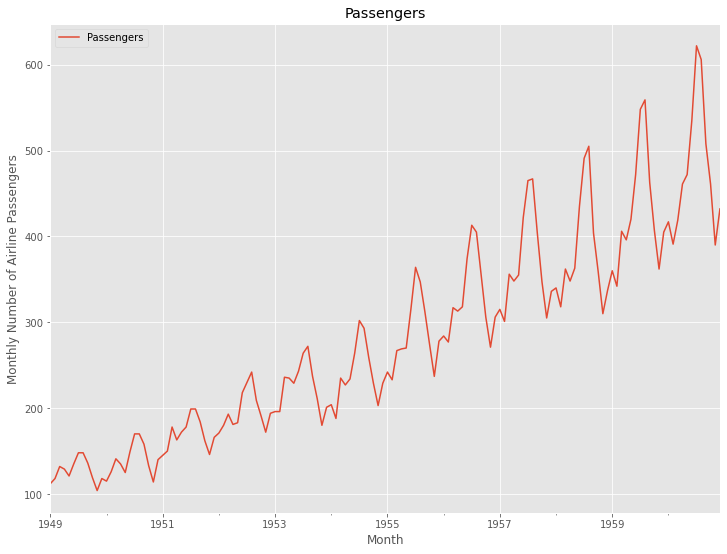
今回利用する時系列データのデータセットは、Airline Passengers(飛行機乗客数)は、Box and Jenkins (1976) の有名な時系列データです。サンプルデータとして、よく利用されます。
弊社のHPからもダウンロードできます。
弊社のHP上のURLからダウンロード
https://www.salesanalytics.co.jp/591h
必要なライブラリーの読み込み
必要なライブラリーを読み込みます。
以下、コードです。
import pandas as pd
import numpy as np
import rpy2
%load_ext rpy2.ipython
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_percentage_error
import matplotlib.pyplot as plt
plt.style.use('ggplot') #グラフのスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ設定
必要なデータの読み込み
必要なデータを読み込みます。
以下、コードです。
# データセットの読み込み
url='https://www.salesanalytics.co.jp/591h' #データセットのあるURL
df=pd.read_csv(url, #読み込むデータのURL
index_col='Month', #変数「Month」をインデックスに設定
parse_dates=True) #インデックスを日付型に設定
df.head() #確認
以下、実行結果です。
モデル構築で利用する学習データ(train)と、学習し求めた予測モデル(ARIMAモデル)の精度検証するテストデータ(test)に分けます。
後ろから12ヶ月間がテストデータで、それより前が学習データです。
以下、コードです。
# 学習データとテストデータ(直近12ヶ月間)に分割 train = df.iloc[:-12, :] #学習データ test = df.iloc[-12:, :] #テストデータ
必要なライブラリーのインストール
RもPythonと同じで、ライブラリーなどを追加でインストールすることで、機能を拡張することができます。
ARIMAモデルを自動構築する関数(auto.arima)がforecastというライブラリーの中にありますので、追加でforecastをインストールします。
コマンドプロンプト上でインストールするか、Rを立ち上げてインストールしておくことをお勧めします。
以下、コードです(※コマンドプロンプトやR上でインストールするときのコードです。)
install.packages('forecast', dependencies = TRUE)
どうしてもJupyter上でインストールしたい場合には、以下です。
from rpy2.robjects.packages import importr
utils = importr('utils')
utils.install_packages('forecast')
必要なときに、このライブラリーを読み込むことで利用することができます。
必要なライブラリーの読み込み
早速、先程インストールしたライブラリーforecastを利用したいので、読み込みます。
以下、コードです。
%%R
library('forecast')
ARIMAモデルそのものの説明は、ここでは割愛します。興味のあるかたは、以下などを参考にしてください。
ARIMAモデルの自動構築
学習データ(train)をR用の時系列データに変換します。
以下、コードです。
r_train_data = train['Passengers'].values %R -i r_train_data %R r_ts_data = ts(r_train_data, frequency=12)
このデータを使い、ARIMAモデルを自動構築していきます。
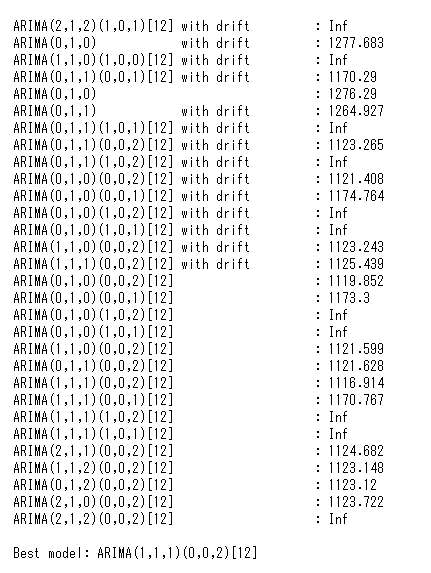
以下、コードです。
%%R arima_model <- auto.arima(r_ts_data, trace = TRUE) arima_model
以下、実行結果です。
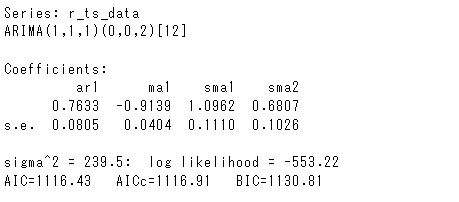
学習データの予測値(推定値)を出力してみます。
以下、コードです。
%%R arima_model$fitted
以下、実行結果です。
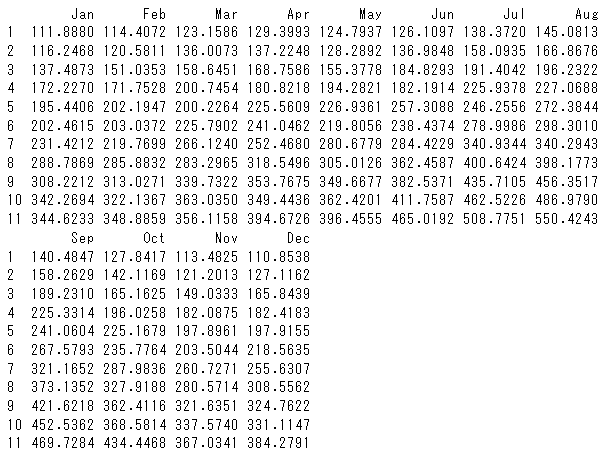
R上でデータフレームへ変換し、このデータフレームをPythonへ出力します。
以下、コードです。
%R arima_fitted <- data.frame(arima_model$fitted) %R -o arima_fitted arima_fitted
以下、実行結果です。
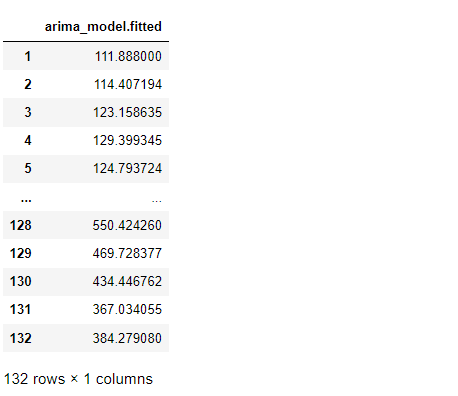
構築したARIMAモデルで予測
構築したARIMAモデルで、12ヶ月分を予測します。
以下、コードです。予測結果をデータフレームに変換しています。
%%R forecasted <- forecast(arima_model, h=12, level=(95.0)) forecasted <- data.frame(forecasted)
予測結果の入ったデータフレームをPythonへ出力します。
以下、コードです。
%R -o forecasted forecasted
以下、実行結果です。
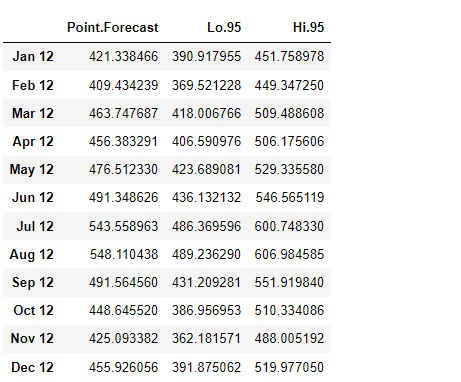
テストデータで精度検証
テストデータで精度検証します。
以下、コードです。
# テストデータで精度検証
pred = forecasted['Point.Forecast']
print('RMSE:')
print(np.sqrt(mean_squared_error(test, pred)))
print('MAE:')
print(mean_absolute_error(test, pred))
print('MAPE:')
print(mean_absolute_percentage_error(test, pred))
以下、実行結果です。

指標そのものの説明は、ここでは割愛します。興味のあるかたは、以下などを参考にしてください。
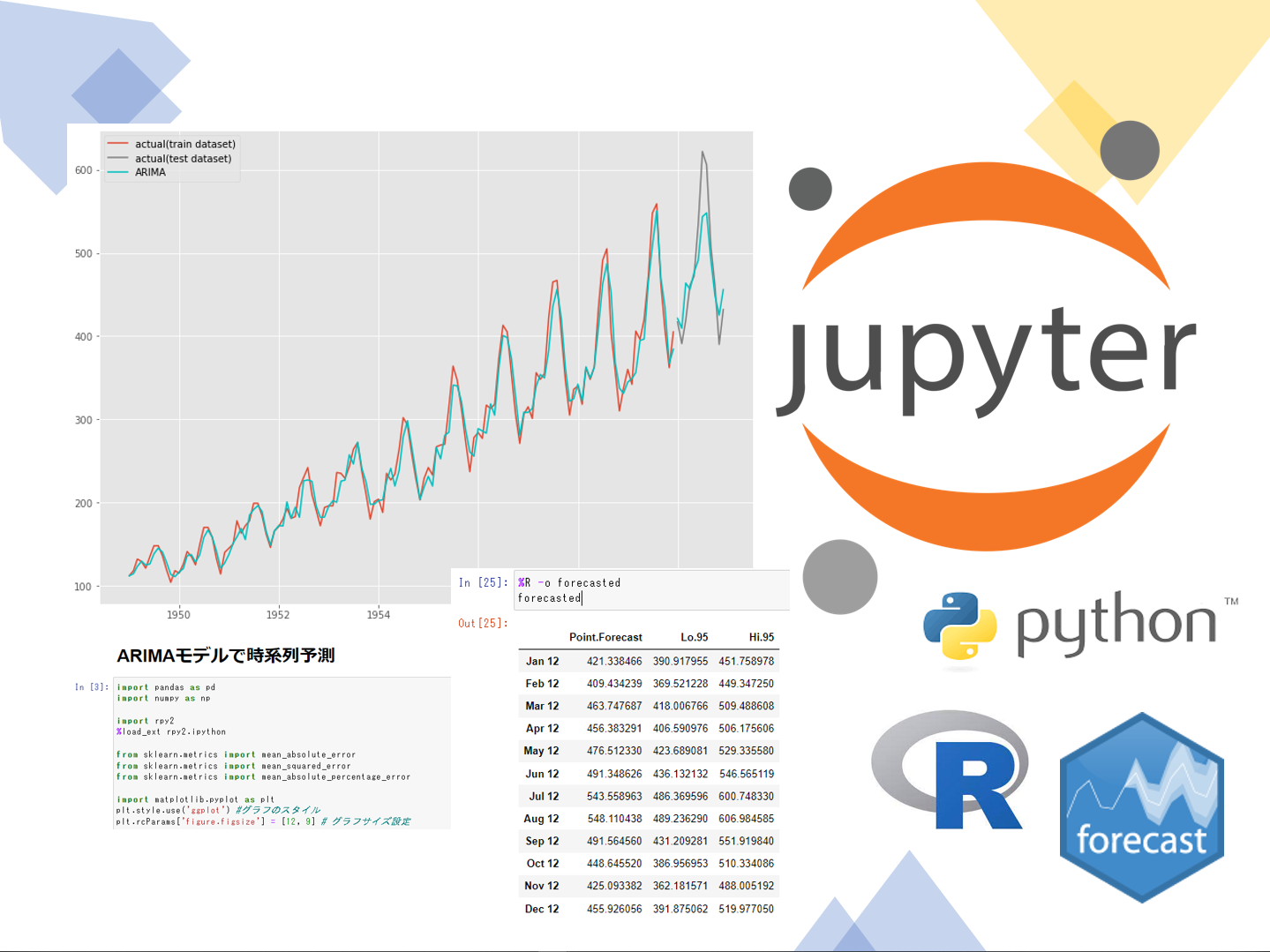
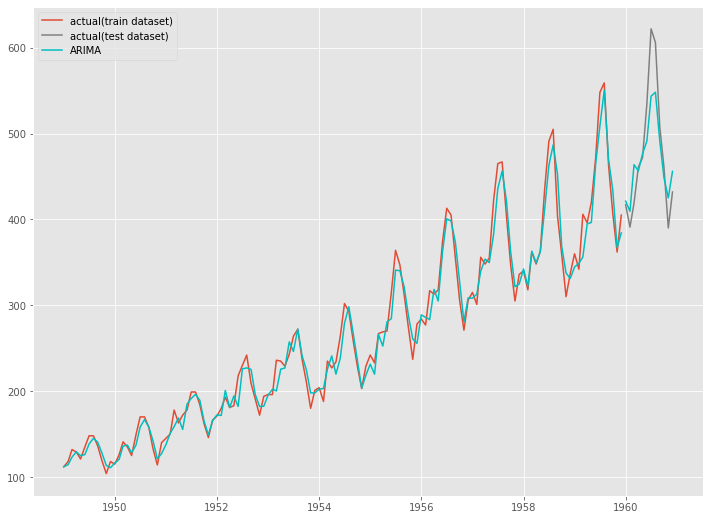
グラフをプロットし視覚的に確認します。
以下、コードです。
# グラフ化 fig, ax = plt.subplots() ax.plot(train.index, train.values, label="actual(train dataset)") ax.plot(test.index, test.values, label="actual(test dataset)", color="gray") ax.plot(train.index, arima_fitted.values, color="c") ax.plot(test.index, pred, label="ARIMA", color="c") plt.legend()
以下、実行結果です。
まとめ
今回は、「Python RPY2を使い Jupyter上でPythonとRを混在して使う」というお話しをしました。
Rのスクリプトをある程度記載できる方であれば、非常に便利な方法でしょう。
なぜならば、Jupyterのセルに、以下のコードを記載しておくだけだからです。
%load_ext rpy2.ipython
興味のある方は試してみてください。