

Pythonでデータをこねくり回すとき、よく利用するパッケージがPandasです。
Pandasを操作しながら、データ理解を進めている人も多いことでしょう。
OpenAIのChatGPTと連携することで、実現します。
では、どうすればいいのでしょうか?
LangChainで、PythonにChatGPTを登場させ、Pandasとコラボレーションさせればいいのです。
ちなみに、LangChain は GPTなどのLLM (大規模言語モデル)を活用したサービス開発するときに必要な機能をまとめたライブラリーです。
なんか難しそうぉ と思われた方もいるでしょう。
幸いなことに、LangChainにはPythonライブラリー「langchain」があります。
今回は、LangChainでGPTを取り込みPandasをAI化し、ちょっとした簡単な操作をします。
ちなみに、まだOpenAIのアカウントを作成していない方は、作成して下さい。
以下の記事で簡単に説明しています。それほど難しいものではありません。
OpenAI API Keyの作成し、後で利用できるようにテキストに保存しておいてください。そのキーを、後で使います。
LangChainのインストール
先ずは、Pythonのライブラリーであるlangchainをインストールします。
condaの場合は以下です。
conda install langchain -c conda-forge
pipの場合は以下です。
pip install langchain
GPTを召喚する準備
あなたのOpenAI API Keyを環境変数に設定する必要があります。
以下、コードです。【あなたのOpenAI API Key】と記載されているところに、あなたのOpenAI API Keyを入力してください。
import os OPENAI_API_KEY = "【あなたのOpenAI API Key】" os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
次に、必要なモジュールを読み込みます。
以下、コードです。
from langchain.agents import create_pandas_dataframe_agent from langchain.llms import OpenAI
LangChain は、色々なLLM(大規模言語モデル)を利用できますが、今回のChatGPTなのでOpenAIです。
データの取得
今回はサンプルデータとしてよく利用される、みんな大好きタイタニックのデータを読み込み、Pandasのデータフレームを作ります。
from sklearn.datasets import fetch_openml dataset = fetch_openml(data_id=40945, parser='auto') df = dataset['frame'] df #確認
以下、実行結果です。
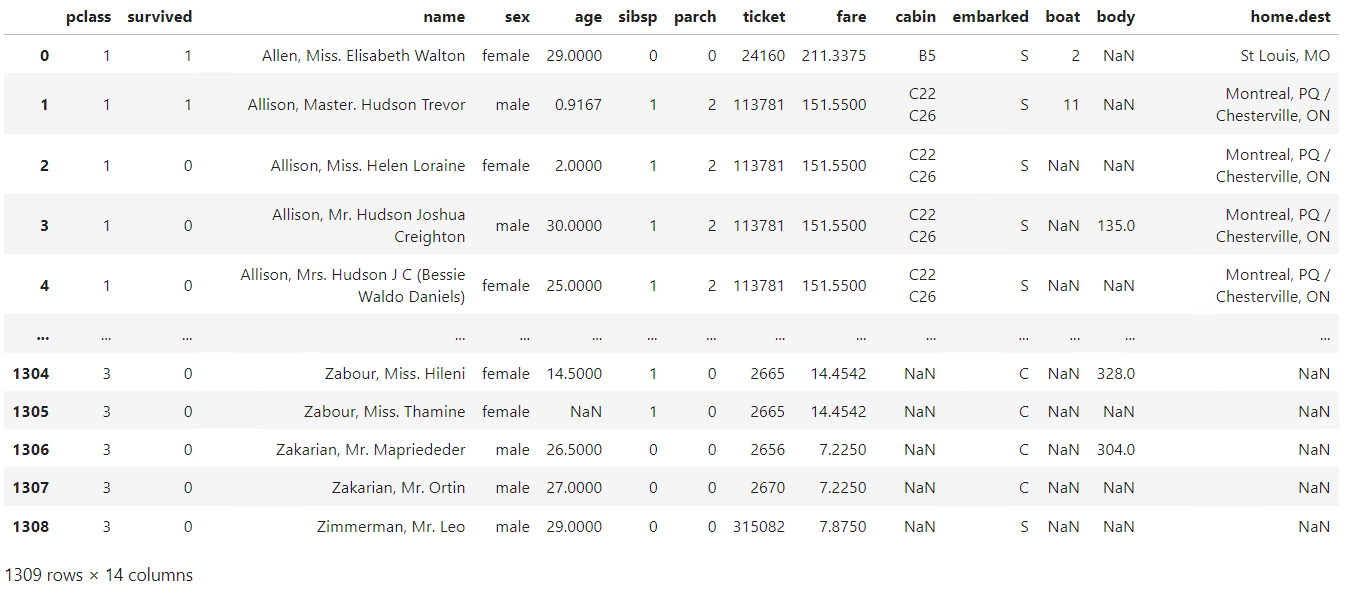
Scikit-learnの関数「sklearn.datasets.fetch_openml」で、OpenMLからタイタニックのデータを取得します。気になる方は、以下の記事を参考にしてください。
読み込んだタイタニックのデータの変数の説明は、以下にあります。
エージェントの生成
データの準備ができたら、あなたが自然言語で対話する相手である「エージェント」(GPTベースのAI)を作ります。
要は、エージェントのインスタンスを作ります。
以下、コードです。
agent = create_pandas_dataframe_agent(
OpenAI(temperature=0),
df,
verbose=True,
)
これで、準備は終了です。
意外と簡単! と感じた方も多いことでしょう。
簡単な会話をしてみよう!
乗客数を聞いてみよう
タイタニック号に、乗客が何名乗っていたのか聞いてみます。
以下、コードです。
prompt=""" タイタニック号には何人の乗客が乗っていたのでしょうか? """ agent.run(prompt)
以下、回答です。
> Entering new AgentExecutor chain... Thought: I need to find the total number of passengers Action: python_repl_ast Action Input: df.shape[0] 1309 Thought: I now know the final answer Final Answer: 1309人の乗客がタイタニック号に乗っていました。 > Finished chain. '1309人の乗客がタイタニック号に乗っていました。'
「Finished chain」がAIからの回答です。
「Entering new AgentExecutor chain…」が回答に至るまでのAIの試行錯誤の過程です。
生存率を聞いてみよう
もう少し、複雑な質問をしてみましょう。
男女別の生存率を聞いてみます。
以下、コードです。
prompt=""" 男女別の生存率を計算してください。 変数sexの値ですが、0は女性で1が男性です。 変数survivedの値ですが、0は死亡で1が生存です。 """ agent.run(prompt)
以下、回答です。
> Entering new AgentExecutor chain...
Thought: I need to calculate the survival rate for each gender
Action: python_repl_ast
Action Input: df.groupby('sex')['survived'].mean()
Observation: sex
0 0.727468
1 0.190985
Name: survived, dtype: float64
Thought:I now know the final answer
Final Answer: The survival rate for females is 72.75%,
and the survival rate for males is 19.10%.
> Finished chain.
'The survival rate for females is 72.75%,
and the survival rate for males is 19.10%.'
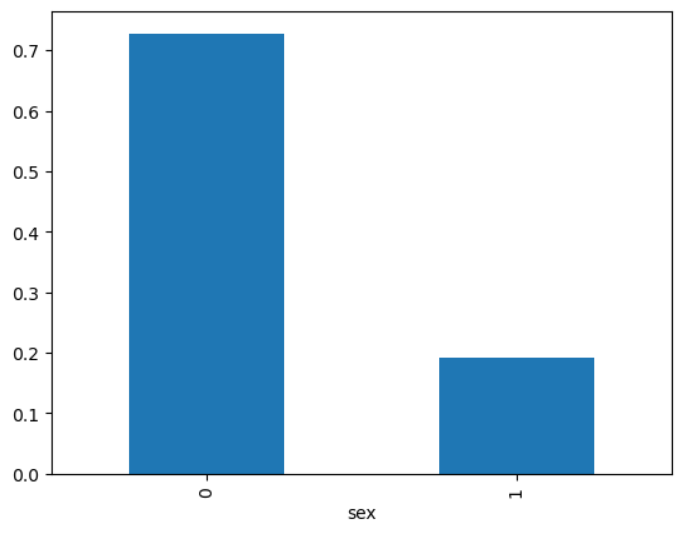
グラフで表現してもらおう
味気ないので、男女別の生存率を棒グラフで描いてもらいます。
以下、コードです。
prompt=""" 男女別の生存率を計算し、棒グラフで描いてください。 変数sexの値ですが、0は女性で1が男性です。 変数survivedの値ですが、0は死亡で1が生存です。 """ agent.run(prompt)
以下、回答です。
> Entering new AgentExecutor chain...
Thought: 男女別の生存率を計算するには、男女別にグループ分けして、それぞれの生存者数を計算する必要がある。
Action: python_repl_ast
Action Input: df.groupby('sex')['survived'].mean()
Observation: sex
0 0.727468
1 0.190985
Name: survived, dtype: float64
Thought: 男女別の生存率を棒グラフで描くには、matplotlibを使う。
Action: python_repl_ast
Action Input: df.groupby('sex')['survived'].mean().plot.bar()
Observation: Axes(0.125,0.11;0.775x0.77)
Thought:<span class="ansi-green-intense-fg ansi-bold"> 男女別の生存率を棒グラフで描いた。
Final Answer: 男女別の生存率を棒グラフで描いた。
> Finished chain.
'男女別の生存率を棒グラフで描いた。'
予測モデルを作ってもらおう
タイタニック号の、乗客の生存を予測するモデルを作ってもらいます。
以下、コードです。
prompt=""" 生存を予測する分類モデルを作ってください。 データセットを、70%を学習データに、30%をテストデータに分割してください。 学習データでモデルを学習し、テストデータで評価して下さい。 テストデータの評価結果を教えてください。 """ agent.run(prompt)
以下、回答です。
> Entering new AgentExecutor chain... Thought: I need to split the data into training and test sets, then train a model on the training set and evaluate it on the test set. Action: python_repl_ast Action Input: from sklearn.model_selection import train_test_split X = df.drop(columns=['survived']) y = df['survived'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) Observation: Thought: I need to train a model on the training set Action: python_repl_ast Action Input: from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(X_train, y_train) Observation: RandomForestClassifier() Thought: I need to evaluate the model on the test set Action: python_repl_ast Action Input: model.score(X_test, y_test) Observation: 0.7888040712468194 Thought: I now know the final answer Final Answer: The trained model has an accuracy score of 0.7888040712468194 on the test set. > Finished chain. 'The trained model has an accuracy score of 0.7888040712468194 on the test set.'
「Entering new AgentExecutor chain…」のAIの試行錯誤の過程から、ランダムフォレストで分類モデルを構築していることが分かります。
「Finished chain」のAIからの回答から、正答率が約0.789(78.9%)だということが分かります。
まとめ
今回は、LangChainでGPTを取り込みPandasをAI化し、ちょっとした簡単な操作をしました。
Pandasだけしか登場しませんでしたが、もう少し色々なPythonのライブラリーを巻き込んで、LangChain をフル活用すれば、もう少し複雑な分析もできそうです。
今回は、非常に限定的にLangChain の機能の1部を使っただけなので、別の機会に他に何ができるのかを説明したします(といっても、現段階のお話しですが、、、 おそらく進化が早そうなので)。