
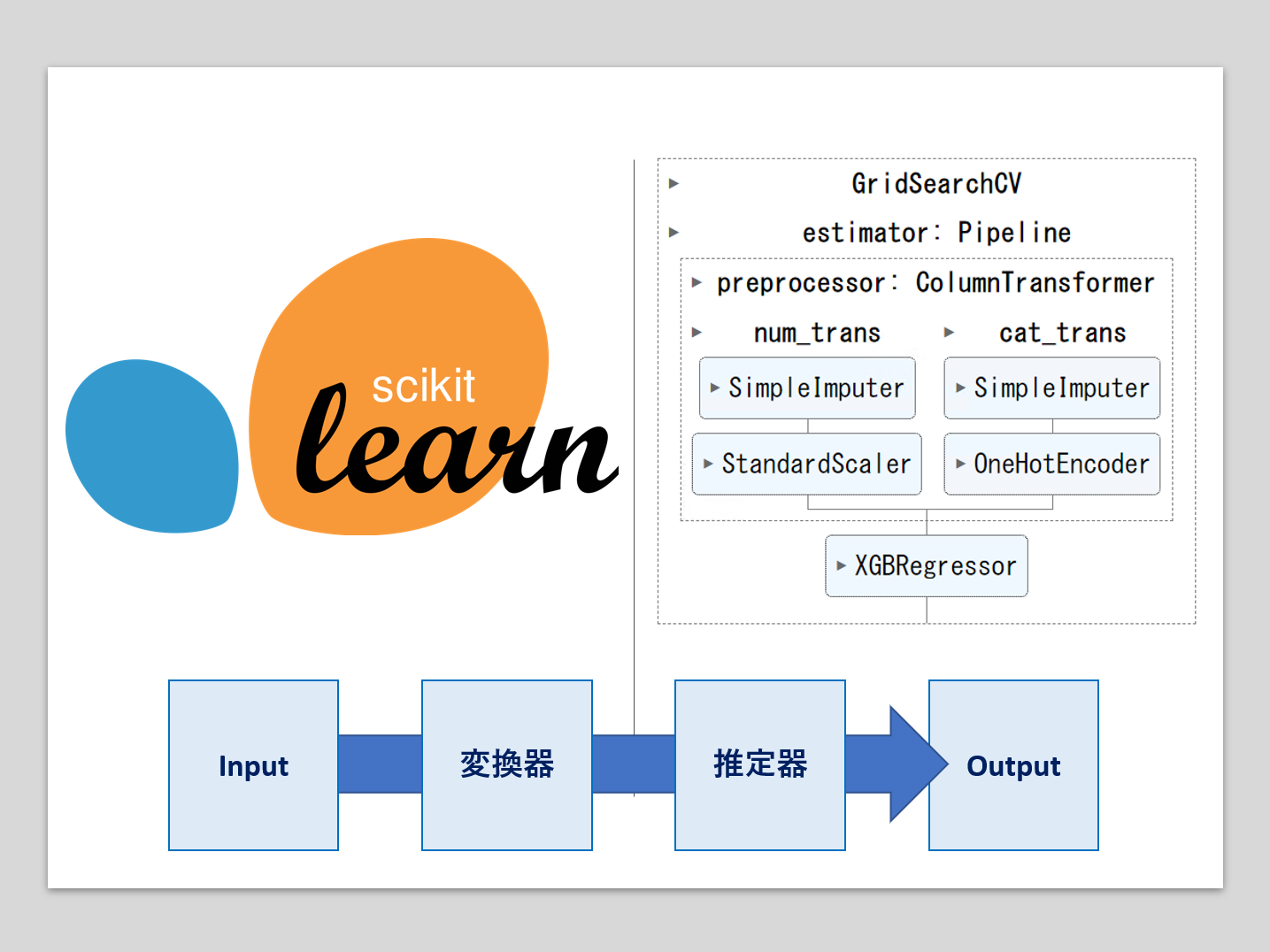
機械学習のパイプラインとは、複数の処理を直列に連結したものです。
最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。

- 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Transformor)
- 推定器:線形回帰モデルやXGBoostなどの数理モデルを使い、目的変数yの予測を実施(Estimator)
多くの場合、Inputは特徴量(説明変数)Xで、Outputは目的変数yの予測値です。
推定器(予測器)が含まれていることから分かる通り、機械学習パイプラインを作ったら、そのパイプラインを学習する必要があります。
活用するときは、学習済みのパイプラインを使います。
また、学習時に目的変数yの変換(例:正規化など)を実施することもあります。
ということで、今回は機械学習パイプラインの構成要素である「変換器と推定器」について説明します。
準備
必要なモジュールと利用するデータセットを読み込みます。
必要なモジュールの読み込み
先ず、必要なモジュールを読み込みます。
以下、コードです。
# 基本的なモジュール import numpy as np import pandas as pd # データ分割用の関数 from sklearn.model_selection import train_test_split # 評価指標 from sklearn.metrics import r2_score # ハイパーパラメータ調整 from sklearn.model_selection import GridSearchCV # パイプライン構築のための道具 from sklearn.pipeline import make_pipeline from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer # 今回、変換器として利用 from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import OneHotEncoder from sklearn.impute import SimpleImputer # 今回、推定器として利用 import xgboost as xgb
基本、scikit-learnのモジュールを中心に使いますが、推定器はXGBoostを利用します。
XGBoostはライブラリー「xgboost」をインストールしておく必要があります。まだインストールされていない方は、以下のサイトを参考にインストールして頂ければと思います。
pipでもcondaでもインストールできます。
利用するデータセットの読み込み
今回利用するデータは、DAT8コース(2015年にワシントンDCで開催されたデータサイエンスコース)のBike Sharing Demand(CSVファイル)です。
以下、コードです。
# データセットの読み込み url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/bikeshare.csv' df = pd.read_csv(url, index_col='datetime', parse_dates=True) # 特徴量(説明変数) X = df.drop(['casual','registered','count'],axis=1) # 目的変数 y = df['casual']
簡単に変数について説明します。
以下、データ項目です。
- datetime – 日時
- season
- 1 = 春
- 2 = 夏
- 3 = 秋
- 4 = 冬
- holiday – その日が休日であるかどうか
- workingday – その日が週末でも休日でもない日かどうか
- weather
- 1:晴れ、雲少ない、部分的に曇り、部分的に曇り
- 2: 霧+曇り、霧+切れ落ちた雲、霧+少ない雲、霧
- 3:小雪、小雨+雷雨+雲が散らばる、小雨+雲が散らばる
- 4:大雨+氷柱+雷雨+霧、雪+霧
- temp – 気温(摂氏)。
- atemp – 体感温度
- humidity – 相対湿度
- windspeed – 風の速さ
- casual – 非登録ユーザーによるレンタル開始数
- registered – 登録ユーザーによるレンタル開始数
- count – 総レンタル数
最後の方にある「casual」「registered」「count」が目的変数で、他が特徴量(説明変数)です。
今回は、「casual」を目的変数に設定しています。
簡単にそれぞれのデータを見てみます。
先ず、目的変数を見てみます。
以下、コードです。
print(y)
以下、実行結果です。
datetime
2011-01-01 00:00:00 3
2011-01-01 01:00:00 8
2011-01-01 02:00:00 5
2011-01-01 03:00:00 3
2011-01-01 04:00:00 0
..
2012-12-19 19:00:00 7
2012-12-19 20:00:00 10
2012-12-19 21:00:00 4
2012-12-19 22:00:00 12
2012-12-19 23:00:00 4
Name: casual, Length: 10886, dtype: int64
次に、特徴量(説明変数)を見てみます。
以下、コードです。
print(X)
以下、実行結果です。
season holiday workingday weather temp atemp \
datetime
2011-01-01 00:00:00 1 0 0 1 9.84 14.395
2011-01-01 01:00:00 1 0 0 1 9.02 13.635
2011-01-01 02:00:00 1 0 0 1 9.02 13.635
2011-01-01 03:00:00 1 0 0 1 9.84 14.395
2011-01-01 04:00:00 1 0 0 1 9.84 14.395
... ... ... ... ... ... ...
2012-12-19 19:00:00 4 0 1 1 15.58 19.695
2012-12-19 20:00:00 4 0 1 1 14.76 17.425
2012-12-19 21:00:00 4 0 1 1 13.94 15.910
2012-12-19 22:00:00 4 0 1 1 13.94 17.425
2012-12-19 23:00:00 4 0 1 1 13.12 16.665
humidity windspeed
datetime
2011-01-01 00:00:00 81 0.0000
2011-01-01 01:00:00 80 0.0000
2011-01-01 02:00:00 80 0.0000
2011-01-01 03:00:00 75 0.0000
2011-01-01 04:00:00 75 0.0000
... ... ...
2012-12-19 19:00:00 50 26.0027
2012-12-19 20:00:00 57 15.0013
2012-12-19 21:00:00 61 15.0013
2012-12-19 22:00:00 61 6.0032
2012-12-19 23:00:00 66 8.9981
[10886 rows x 8 columns]
特徴量(説明変数)には、量的変数と質的変数があります。
- 量的変数:temp、atemp、humidity、windspeed
- 質的変数:season、holiday、workingday、weather
それぞれのリストを作成します。
以下、コードです。
# 量的変数 nums = ['temp','atemp','humidity','windspeed'] # 質的変数 cats = ['season','holiday','workingday','weather']
このリストを使い、特徴量Xから量的変数と質的変数を抽出してみます。
先ず、量的変数です。
以下、コードです。
print(X[nums])
以下、実行結果です。
temp atemp humidity windspeed datetime 2011-01-01 00:00:00 9.84 14.395 81 0.0000 2011-01-01 01:00:00 9.02 13.635 80 0.0000 2011-01-01 02:00:00 9.02 13.635 80 0.0000 2011-01-01 03:00:00 9.84 14.395 75 0.0000 2011-01-01 04:00:00 9.84 14.395 75 0.0000 ... ... ... ... ... 2012-12-19 19:00:00 15.58 19.695 50 26.0027 2012-12-19 20:00:00 14.76 17.425 57 15.0013 2012-12-19 21:00:00 13.94 15.910 61 15.0013 2012-12-19 22:00:00 13.94 17.425 61 6.0032 2012-12-19 23:00:00 13.12 16.665 66 8.9981 [10886 rows x 4 columns]
次に、質的変数です。
以下、コードです。
print(X[cats])
以下、実行結果です。
season holiday workingday weather datetime 2011-01-01 00:00:00 1 0 0 1 2011-01-01 01:00:00 1 0 0 1 2011-01-01 02:00:00 1 0 0 1 2011-01-01 03:00:00 1 0 0 1 2011-01-01 04:00:00 1 0 0 1 ... ... ... ... ... 2012-12-19 19:00:00 4 0 1 1 2012-12-19 20:00:00 4 0 1 1 2012-12-19 21:00:00 4 0 1 1 2012-12-19 22:00:00 4 0 1 1 2012-12-19 23:00:00 4 0 1 1 [10886 rows x 4 columns]
最後に、データセットを学習データとテストデータに分割します。
学習データでパイプラインを学習し、学習したパイプラインはテストデータで検証します。
以下、コードです。
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.3,
random_state=123
)
- X_train:学習データの特徴量(説明変数)
- X_test:テストデータの特徴量(説明変数)
- y_train:学習データの目的変数
- y_test:テストデータの目的変数
量的変数と質的変数では、処理の仕方が異なります。
そのため、先ずはそれぞれでパイプラインを構築する方法を説明し、次に量的変数と質的変数が混合した状態のパイプラインを構築する方法を説明します。
量的変数のみのケース
特徴量(説明変数)を量的変数に絞り、パイプラインを構築していきます。
パイプラインを構築する典型的な方法は次の2つです。
- make_pipelineで構築
- Pipelineで構築
make_pipelineとPipelineの違いは、変換器や推定器に名前を付けるかどうかです。
make_pipelineは名前なしで構築し、Pipelineは名前ありで構築します。名前は分かりやすいものをつけましょう。
make_pipelineで構築
パイプラインを定義します。
以下、コードです。
# パイプラインの定義
num_pipeline = make_pipeline(
SimpleImputer(strategy='mean'),
StandardScaler(),
xgb.XGBRegressor(),
)
パイプラインは……
- 変換器:SimpleImputer(strategy=’mean’)、平均値で欠測値補完
- 変換器:StandardScaler()、正規化
- 推定器:XGBoost
学習データで、パイプラインを学習します。
以下、コードです。
# パイプラインの学習 num_pipeline.fit(X_train[nums], y_train)
以下、実行結果です。

テストデータの目的変数を予測し、精度検証(R2)します。
以下、コードです。
# 目的変数yの予測 pred_y = num_pipeline.predict(X_test[nums]) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.3173416126838572
Pipelineで構築
パイプラインを定義します。先程と異なり、変換器と推定器に名前が付いています。
以下、コードです。
# パイプラインの定義
num_pipeline = Pipeline(
steps=[
("impute", SimpleImputer(strategy='mean')),
("scale", StandardScaler()),
("regressor", xgb.XGBRegressor()),
]
)
パイプラインは……
- 変換器:impute、平均値で欠測値補完
- 変換器:scale、正規化
- 推定器:regressor、XGBoost
学習データで、パイプラインを学習します。
以下、コードです。
# パイプラインの学習 num_pipeline.fit(X_train[nums], y_train)
以下、実行結果です。
テストデータの目的変数を予測し、精度検証(R2)します。
以下、コードです。
# 目的変数yの予測 pred_y = num_pipeline.predict(X_test[nums]) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.3173416126838572
質的変数のみのケース
特徴量(説明変数)を質的変数に絞り、パイプラインを構築していきます。
make_pipelineで構築
パイプラインを定義します。
以下、コードです。
# パイプラインの定義
cat_pipeline = make_pipeline(
SimpleImputer(strategy="most_frequent"),
OneHotEncoder(handle_unknown='ignore'),
xgb.XGBRegressor(),
)
パイプラインは……
- 変換器:SimpleImputer(strategy=”most_frequent”)、最頻値で欠測値補完
- 変換器:OneHotEncoder、ダミーコード化
- 推定器:XGBoost
学習データで、パイプラインを学習します。
以下、コードです。
# パイプラインの学習 cat_pipeline.fit(X_train[cats], y_train)
以下、実行結果です。

テストデータの目的変数を予測し、精度検証(R2)します。
以下、コードです。
# 目的変数yの予測 pred_y = cat_pipeline.predict(X_test[cats]) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.21600549949452696
Pipelineで構築
パイプラインを定義します。先程と異なり、変換器と推定器に名前が付いています。
以下、コードです。
# パイプラインの定義
cat_pipeline = Pipeline(
steps=[
("impute", SimpleImputer(strategy="most_frequent")),
("encode", OneHotEncoder(handle_unknown='ignore')),
("regressor", xgb.XGBRegressor()),
]
)
パイプラインは……
- 変換器:impute、最頻値で欠測値補完
- 変換器:encode、ダミーコード化
- 推定器:regressor、XGBoost
学習データで、パイプラインを学習します。
以下、コードです。
# パイプラインの学習 cat_pipeline.fit(X_train[cats], y_train)
以下、実行結果です。
テストデータの目的変数を予測し、精度検証(R2)します。
以下、コードです。
# 目的変数yの予測 pred_y = cat_pipeline.predict(X_test[cats]) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.21600549949452696
量的変数と質的変数が混合
変数によって、変換器を変えたいことがあります。
よくあるのが、量的変数と質的変数で、変換器を変えるケースです。
変換器
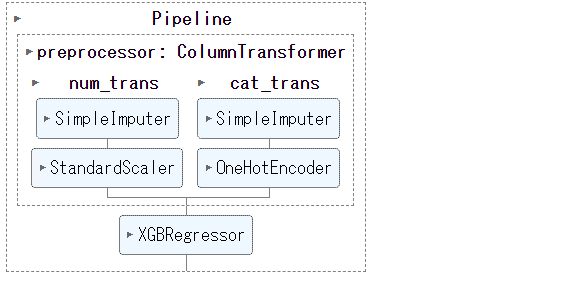
個々の変換器を定義し個々の変換器をColumnTransformerで連結し全体の変換器を完成させます。
先ず、個々の変換器を定義します。
以下、コードです。先程と異なり推定器はありません。
# 量的変数用の変換器パイプラインの定義
num_pipeline = Pipeline(
steps=[
("impute", SimpleImputer(strategy='mean')),
("scale", StandardScaler()),
]
)
# 質的変数用の変換器パイプラインの定義
cat_pipeline = Pipeline(
steps=[
("impute", SimpleImputer(strategy="most_frequent")),
("encode", OneHotEncoder(handle_unknown='ignore')),
]
)
次に、個々の変換器をColumnTransformerで連結します。
以下、コードです。
# 変換器パイプラインの定義
trans = ColumnTransformer(
transformers=[
("num_trans", num_pipeline, nums),
("cat_trans", cat_pipeline, cats),
],
remainder = 'drop',
)
remainderで、処理の対象外の特徴量に対する処理を指定します。
- drop:その変数を削除
- passthrough:その変数をそのまま出力
今回は、対象外の特徴量がないため、remainderの設定は必要ありませんが、念のため入れています。
今定義した変換器だけのパイプラインを使うこともできます。
以下、コードです。
# 変換器を使用 X_transformed = trans.fit_transform(X_train) print(X_transformed) #確認
以下、実行結果です。
[[ 0.57160903 0.79624767 -0.11200374 ... 0. 1. 0. ] [ 0.25560742 0.25966023 0.5664706 ... 1. 0. 0. ] [-1.008399 -1.17182991 -0.52952642 ... 0. 1. 0. ] ... [-1.21906674 -0.99296743 -1.41676209 ... 1. 0. 0. ] [-1.008399 -0.90324104 -0.05981341 ... 1. 0. 0. ] [ 0.78227677 0.61738519 1.08837394 ... 1. 0. 0. ]]
推定器と連結
今定義した変換器だけのパイプラインを、推定器(XGBoost)と連携し完成させます。
以下、コードです。
full_pipeline = Pipeline(
steps=[
("preprocessor", trans),
("regressor", xgb.XGBRegressor()),
]
)
学習データで、パイプラインを学習します。
以下、コードです。
# パイプラインの学習 full_pipeline.fit(X_train, y_train)
以下、実行結果です。
テストデータの目的変数を予測し、精度検証(R2)します。
以下、コードです。
# 目的変数yの予測 pred_y = full_pipeline.predict(X_test) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.6385551161601157
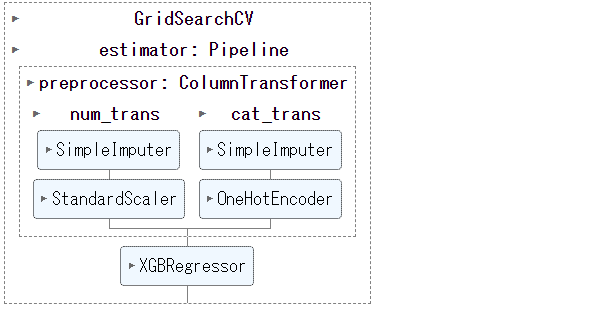
ハイパーパラメータ調整
定義したパイプラインの中には、ハイパーパラメータのある変換器や推定器があります。
今回の場合ですと、XGBoostに色々なハイパーパラメータがあります。
ハイパーパラメータの値次第で、予測精度が変化します。
そこで、パイプラインのハイパーパラメータチューニングを、グリッドサーチ(全組み合わせを探索)で行います。
先ず、ハイパーパラメータの探索範囲を定義します。
以下、コードです。
# 探索範囲
params = {
'regressor__max_depth':[2, 4, 6, 8, 10],
'regressor__n_estimators': [10, 20, 30, 40, 50, 60, 70, 80, 90],
'regressor__min_child_weight':[1, 2, 4, 6, 8, 10],
}
探索範囲を定義するとき1点注意があります。
それは、パイプライン内の変換器や推定器の名前を、探索するハイパーパラメータの頭に付けることです。
例えば、「regressor__max_depth」は、「regressor」のハイパーパラメータ「max_depth」という意味です。「:」以降は探索範囲です。
次に、グリッドサーチのインスタンスを生成し、最適なハイパーパラメータを探索します。
以下、コードです。
# インスタンス生成
gs = GridSearchCV(
full_pipeline,
params,
cv=10,
n_jobs=-1,
)
# グリッドサーチの実施
gs.fit(X_train, y_train)
以下、実行結果です。
探索範囲内で最適なハイパーパラメータを出力します。
以下、コードです。
# 最適なパラメーター print(gs.best_params_)
以下、実行結果です。
{'regressor__max_depth': 6, 'regressor__min_child_weight': 6, 'regressor__n_estimators': 60}
最適なハイパーパラメータで構築されたパイプラインは、「gs.best_estimator_」で取得できます。
この最適パイプラインを使い、テストデータの目的変数を予測し、精度検証(R2)します。
以下、コードです。
# 最適なモデル best_pipeline = gs.best_estimator_ # 目的変数yの予測 pred_y = best_pipeline.predict(X_test) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.6502792514955191
まとめ
今回は、機械学習パイプラインの構成要素である「変換器と推定器」について説明しました。
登場した変換器は、scikit-learnの中にある既存のものです。
多くは既存の変換器で十分ですが、作りたい機械学習パイプラインによっては、自作の変換器(カスタマイズ変換器)を使いたいこともあります。
次回は、自作の変換器(カスタマイズ変換器)について説明します。
scikit-learnの機械学習パイプライン入門(その2:自作関数をFunctionTransformerで変換器にする)