

NeuralForecastは、時系列予測の分野で革新的な変化をもたらすツールです。
前回、NeuralForecastの概要について説明しました。
深層学習によるビジネス時系列分析ツール NeuralForecast(1)– 導入編:NeuralForecastとは何か? –
今回は、NeuralForecastの基本的なインストール方法と、簡単な時系列予測の構築方法を紹介します。
Pythonを使用した実用的な例を通じて、ビジネスにおける時系列データの予測方法を理解し、実行するステップを説明します。
具体的には、比較的古典的な時系列深層学習であるRNNから、最先端の時系列トランスフォーマーであるPatchTSTまで対象にしています。
NeuralForecastのインストール
NeuralForecastのインストールは、Pythonのパッケージインデックス(PyPI)またはCondaを使用して行います。
PyPIでのインストールは以下です。
pip install neuralforecast
condaでのインストールは以下です。
conda install -c conda-forge neuralforecast
NeuralForecastで時系列予測構築例
利用するデータセット
NeuralForecastで提供されているデータセットAirPassengersDF を使います。
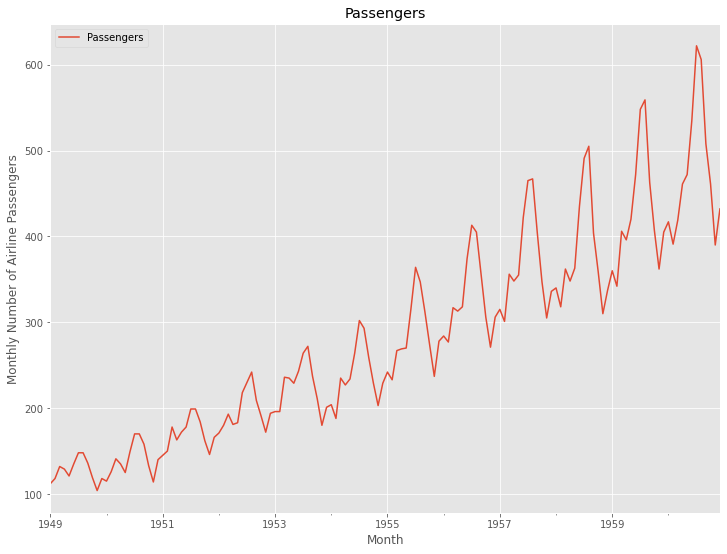
このデータセットは、航空旅客の月次数を記録したもので、時系列分析や予測モデリングの教材としてよく用いられます。特に、季節性、トレンド、その他の時系列のパターンを理解し分析するための典型的な例として扱われます。
1つのモデルで構築する(RNN)
RNNモデルで構築する乗客数を予測するモデルを検討します。学習データでモデル構築し、テストデータで検証します。
ちなみに、RNNは、時系列データやシーケンスデータを扱うのに適したニューラルネットワークです。連続するデータ間の時間的な依存関係をモデル化することができます。
先ず、必要なライブラリをインポートし、データセットを準備します。
以下、コードです。
import numpy as np
import pandas as pd
from neuralforecast import NeuralForecast
from neuralforecast.models import RNN
from neuralforecast.utils import AirPassengersDF
from sklearn.metrics import (
mean_absolute_error,
mean_absolute_percentage_error,
r2_score
)
import matplotlib.pyplot as plt
plt.style.use('ggplot') # グラフのスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ設定
plt.rcParams['font.size'] = 12 # デフォルトのフォントサイズ
plt.rcParams['axes.labelsize'] = 14 # 軸ラベルのフォントサイズ
plt.rcParams['xtick.labelsize'] = 10 # x軸ティックラベルのフォントサイズ
plt.rcParams['ytick.labelsize'] = 10 # y軸ティックラベルのフォントサイズ
plt.rcParams['legend.fontsize'] = 12 # 凡例のフォントサイズ
plt.rcParams['figure.titlesize'] = 16 # 図のタイトルのフォントサイズ
numpy: 数値計算を行うためのライブラリ。多次元配列操作や数学関数などが含まれています。pandas: データ操作や分析のためのライブラリ。データフレームという形式でデータを扱います。neuralforecast: 時系列予測のためのライブラリ。この中からNeuralForecastクラスとRNNモデルがインポートされています。neuralforecast.utils: ここからAirPassengersDFがインポートされています。これは航空旅客数の時系列データセットを提供する可能性があります。sklearn.metrics: 機械学習モデルのパフォーマンス評価指標を提供するライブラリ。ここでは、MAE(平均絶対誤差)、MAPE(平均絶対パーセンテージ誤差)、R2スコアがインポートされています。matplotlib.pyplot: データを視覚化するためのライブラリ。グラフやチャートを作成するために使用されます。
次に、データを学習用とテスト用に分割します。
以下、コードです。
# データの準備 Y_df = AirPassengersDF Y_train_df = Y_df[Y_df.ds <= '1959-12-31'] Y_test_df = Y_df[Y_df.ds > '1959-12-31'] horizon = len(Y_test_df)
Y_dfにAirPassengersDF(航空旅客数の時系列データセット)を代入しています。Y_train_dfはY_dfから1959年12月31日までのデータをトレーニング用データセットとして選択しています。これは、特定の日付を基準にデータを分割しています。Y_test_dfはY_dfから1959年12月31日より後のデータをテスト用データセットとして選択しています。このデータはモデルのパフォーマンスを評価する際に使用されます。horizonはテストデータセットY_test_dfの長さ(データポイントの数)を示しています。これは、予測モデルが未来にどれだけ先まで予測するかを示します。
学習データで、RNNを用いて予測モデルを構築します。
以下、コードです。
# モデルのパラメータ
rnn_params = {
'input_size': 2 * horizon,
'h': horizon,
'max_steps': 50,
}
# モデルのインスタンス
rnn_model = RNN(**rnn_params)
nf = NeuralForecast(models=[rnn_model], freq='M')
# モデルの学習
nf.fit(df=Y_train_df)
- モデルのパラメータ:
rnn_paramsという辞書を作成し、RNNモデルのパラメータを設定しています。input_sizeはモデルの入力サイズを定義し、ここでは2 * horizon(horizonは以前のコードで定義されたテストデータセットの長さ)を使用しています。hは予測の水平線(予測期間)を示し、ここでもhorizonを使用しています。max_stepsはモデルのトレーニング中の最大ステップ数を設定しています。ここでは50に設定されています。
- モデルのインスタンス:
RNNクラスを使用してRNNモデルを構築しています。このとき、rnn_params辞書の内容をパラメータとして渡しています。NeuralForecastクラスを使用して、時系列予測モデルのトレーニング環境を作成しています。ここではrnn_modelをモデルとして指定し、時系列データの頻度を月次 ('M') と設定しています。
- モデルの学習:
nf.fitメソッドを使用して、トレーニングデータセットY_train_dfでRNNモデルをトレーニングしています。
テストデータの予測を行い、結果をプロットします。精度評価指標としてMAPE、MAE、R2を出力します。
以下、コードです。
# 予測の実施
Y_hat_df = nf.predict().reset_index()
Y_hat_df = Y_test_df.merge(Y_hat_df, how='left', on=['unique_id', 'ds'])
# プロット
plot_df = pd.concat([Y_train_df, Y_hat_df]).set_index('ds')
fig, ax = plt.subplots()
plot_df[['y', 'RNN']].plot(ax=ax, linewidth=2)
# 予測精度評価
y_true = Y_test_df['y']
y_pred = Y_hat_df['RNN']
mae = mean_absolute_error(y_true, y_pred)
mape = mean_absolute_percentage_error(y_true, y_pred)
r2 = r2_score(y_true, y_pred)
print(f"RNN Model Performance:")
print(f"MAE: {mae}")
print(f"MAPE: {mape}")
print(f"R2 Score: {r2}")
- 予測の実施:
nf.predict()を使用して、トレーニング済みのRNNモデルで予測を行います。reset_index()は予測結果のデータフレームのインデックスをリセットします。- 予測結果
Y_hat_dfとテストデータセットY_test_dfを結合します。この際、unique_idとds(日付)カラムを基準に左結合 (how='left') を行います。
- プロット:
- トレーニングデータセット
Y_train_dfと予測結果が含まれるY_hat_dfを結合し、日付 (ds) をインデックスとして設定します。 matplotlibを使用して、結合されたデータセットplot_dfから実際の値 (y) と予測値 (RNN) を折れ線グラフでプロットします。
- トレーニングデータセット
- 予測精度評価:
- テストデータセットから実際の値
y_trueと予測値y_predを取得します。 mean_absolute_error、mean_absolute_percentage_error、r2_scoreを用いて、MAE、MAPE、R2スコアを計算します。- これらのパフォーマンス指標を出力し、RNNモデルの性能を評価します。
- テストデータセットから実際の値
以下、実行結果です。
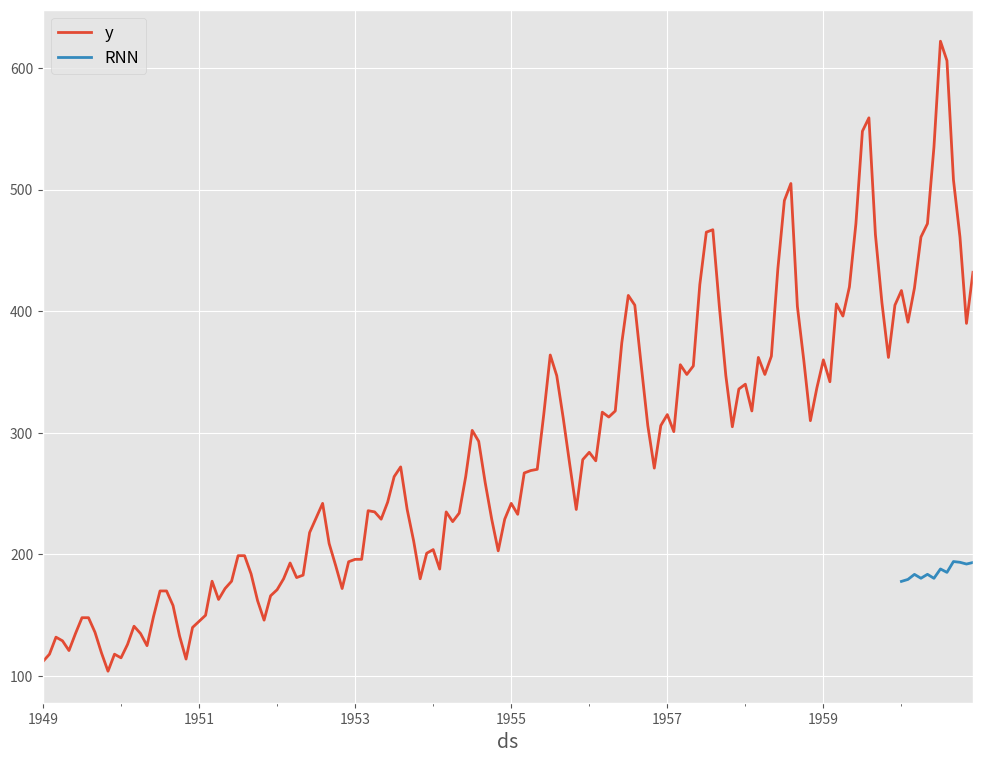
RNN Model Performance: MAE: 290.1596082051595 MAPE: 0.6006616601570595 R2 Score: -15.191620017057232
古典的なRNNでは、上手く予測できていません。一工夫必要そうです。
元の時系列データをトレンド成分や季節成分などに分解し多変量時系列データとしたり、差分処理などの時系列データ特有の前処理を実施することで、予測精度を上げることができます。
他には、他の時系列深層学習モデルで実施する、という手もあります。
複数のモデルで構築する
先ほどはRNNモデルで予測モデルを構築してみました。
ここでは、以下の複数の時系列深層学習アルゴリズム(モデルタイプ)で予測モデルを構築していきます。比較的古典的な時系列深層学習であるRNNから、最先端の時系列トランスフォーマーであるPatchTSTまで対象にしています。
| モデル | 説明 |
|---|---|
| RNN | RNNは、時系列データやシーケンスデータを扱うのに適したニューラルネットワークです。連続するデータ間の時間的な依存関係をモデル化することができます。 |
| LSTM | LSTMはRNNの一種で、長期的な依存関係をより効果的に学習できるように設計されています。これにより、RNNが通常持つ短期的な依存関係の制限を克服します。 |
| GRU | GRUはLSTMに似ていますが、より単純な構造を持っています。これにより、計算効率が向上し、小規模なデータセットでの性能が改善されることがあります。 |
| NBEATS | NBEATSは完全に接続されたフィードフォワードニューラルネットワークです。時系列データの基本的なパターンを捉えるために、基底展開法を用いています。 |
| NHITS | NHITSはNBEATSに触発されたモデルで、階層的なアプローチを取り入れています。これにより、異なる時間スケールでのパターンをより効果的に捉えることができます。 |
| PatchTST | PatchTSTは、トランスフォーマーアーキテクチャを時系列データに適用したモデルです。トランスフォーマーは、長距離の依存関係を効率的にモデル化することができます。 |
先ず、必要なライブラリをインポートし、データセットを準備します。
以下、コードです。
import numpy as np
import pandas as pd
from neuralforecast import NeuralForecast
from neuralforecast.models import (
RNN,
LSTM,
GRU,
NBEATS,
NHITS,
PatchTST,
)
from neuralforecast.utils import AirPassengersDF
from sklearn.metrics import (
mean_absolute_error,
mean_absolute_percentage_error,
r2_score,
)
import matplotlib.pyplot as plt
plt.style.use('ggplot') # グラフのスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ設定
plt.rcParams['font.size'] = 12 # デフォルトのフォントサイズ
plt.rcParams['axes.labelsize'] = 14 # 軸ラベルのフォントサイズ
plt.rcParams['xtick.labelsize'] = 10 # x軸ティックラベルのフォントサイズ
plt.rcParams['ytick.labelsize'] = 10 # y軸ティックラベルのフォントサイズ
plt.rcParams['legend.fontsize'] = 12 # 凡例のフォントサイズ
plt.rcParams['figure.titlesize'] = 16 # 図のタイトルのフォントサイズ
numpy: 数値計算を行うためのライブラリ。多次元配列操作や数学関数などが含まれています。pandas: データ操作や分析のためのライブラリ。データフレームという形式でデータを扱います。neuralforecast: 時系列予測のためのライブラリ。この中からNeuralForecastクラスと時系列深層学習モデルであるRNN,LSTM,GRU,NBEATS,NHITS,PatchTSTがインポートされています。neuralforecast.utils: ここからAirPassengersDFがインポートされています。これは航空旅客数の時系列データセットを提供する可能性があります。sklearn.metrics: 機械学習モデルのパフォーマンス評価指標を提供するライブラリ。ここでは、MAE(平均絶対誤差)、MAPE(平均絶対パーセンテージ誤差)、R2スコアがインポートされています。matplotlib.pyplot: データを視覚化するためのライブラリ。グラフやチャートを作成するために使用されます。
次に、データを学習用とテスト用に分割します。
以下、コードです。
# データの準備 Y_df = AirPassengersDF Y_train_df = Y_df[Y_df.ds <= '1959-12-31'] Y_test_df = Y_df[Y_df.ds > '1959-12-31'] horizon = len(Y_test_df)
Y_dfにAirPassengersDF(航空旅客数の時系列データセット)を代入しています。Y_train_dfはY_dfから1959年12月31日までのデータをトレーニング用データセットとして選択しています。これは、特定の日付を基準にデータを分割しています。Y_test_dfはY_dfから1959年12月31日より後のデータをテスト用データセットとして選択しています。このデータはモデルのパフォーマンスを評価する際に使用されます。horizonはテストデータセットY_test_dfの長さ(データポイントの数)を示しています。これは、予測モデルが未来にどれだけ先まで予測するかを示します。
学習データで、複数の時系列深層学習アルゴリズムを用いて予測モデルを構築します。
以下、コードです。
# 共通パラメータの定義
common_params = {
'input_size': 2 * horizon,
'h': horizon,
'max_steps': 50,
}
# モデルのインスタンス
model_types = [RNN, LSTM, GRU, NBEATS, NHITS, PatchTST]
models = [model_type(**common_params) for model_type in model_types]
nf = NeuralForecast(models=models, freq='M')
# モデルの学習
nf.fit(df=Y_train_df)
- 共通パラメータの定義:
common_paramsという名前の辞書を作成し、複数の時系列予測モデルに共通するパラメータを定義しています。input_sizeはモデルの入力サイズを設定し、2 * horizonとしています。ここでhorizonは以前に定義されたテストデータセットの長さを指します。hは予測の水平線(予測する期間の長さ)を示し、horizonの値を使用しています。max_stepsはモデルのトレーニング中の最大ステップ数を指定し、ここでは50に設定されています。
- モデルのインスタンス:
model_typesというリストを作成し、RNN, LSTM, GRU, NBEATS, NHITS, PatchTST などの異なる時系列予測モデルクラスを含めています。modelsリストを生成し、リスト内包表記を使用してmodel_typesに含まれる各モデルクラスにcommon_paramsのパラメータを適用しています。NeuralForecastクラスを使用して、複数のモデルを含む時系列予測環境を作成しています。models=modelsは構築したモデルリストを、freq='M'はデータの頻度を月次と指定しています。
- モデルの学習:
nf.fitメソッドを用いて、トレーニングデータセットY_train_dfを使用してモデルをトレーニングしています。
テストデータの予測を行い、結果をプロットします。精度評価指標としてMAPE、MAE、R2を出力します。
以下、コードです。
# 予測の実施
Y_hat_df = nf.predict().reset_index()
Y_hat_df = Y_test_df.merge(Y_hat_df, how='left', on=['unique_id', 'ds'])
# モデルのクラス名(文字列)のリストを作成
model_names = [model.__name__ for model in model_types]
# プロット
plot_df = pd.concat([Y_train_df, Y_hat_df]).set_index('ds')
fig, ax = plt.subplots(1, 1, figsize=(20, 7))
plot_df[['y'] + model_names].plot(ax=ax, linewidth=2)
# 予測精度評価関数
def calculate_performance_metrics(y_true, y_pred):
return {
'MAE': mean_absolute_error(y_true, y_pred),
'MAPE': mean_absolute_percentage_error(y_true, y_pred),
'R2 Score': r2_score(y_true, y_pred)
}
# 各モデルの予測精度評価
for model in model_names:
y_true = Y_test_df['y']
y_pred = Y_hat_df[model]
metrics = calculate_performance_metrics(y_true, y_pred)
print(f"Model: {model}")
print(f"MAE: {metrics['MAE']}")
print(f"MAPE: {metrics['MAPE']}")
print(f"R2 Score: {metrics['R2 Score']}")
print("\n")
- 予測の実施:
nf.predict()でトレーニングされたモデルを使用して予測を行い、その結果のインデックスをリセットしてY_hat_dfに格納します。- テストデータセット
Y_test_dfと予測結果Y_hat_dfをunique_idとds(日付)を基準に左結合しています。
- モデルのクラス名(文字列)のリスト作成:
model_typesに含まれる各モデルのクラス名を取得し、model_namesリストに格納します。
- プロット:
- トレーニングデータ
Y_train_dfと予測結果Y_hat_dfを結合し、日付dsをインデックスに設定してplot_dfに格納します。 - matplotlibを使用して、実際の値 (
y) と各モデルの予測値を折れ線グラフでプロットします。グラフのサイズは (20, 7) で、線の太さは 2 です。
- トレーニングデータ
- 予測精度評価関数:
- 実際の値と予測値に基づいて、MAE、MAPE、R2スコアを計算する関数
calculate_performance_metricsを定義します。
- 実際の値と予測値に基づいて、MAE、MAPE、R2スコアを計算する関数
- 各モデルの予測精度評価:
model_namesリストを用いて各モデルのパフォーマンスを評価します。- テストデータセットから実際の値 (
y_true) と予測値 (y_pred) を取得し、上述の関数を使用してパフォーマンス指標を計算します。 - 各モデルのMAE、MAPE、R2スコアを出力します。
以下、実行結果です。
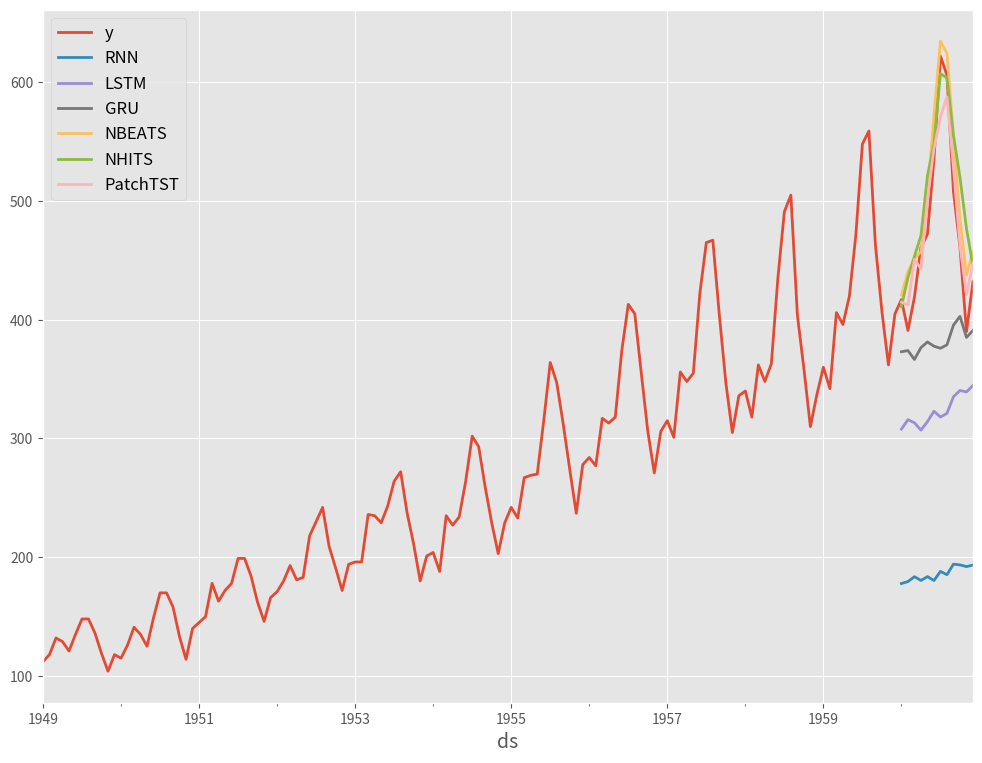
Model: RNN MAE: 290.1596082051595 MAPE: 0.6006616601570595 R2 Score: -15.191620017057232 Model: LSTM MAE: 152.82826487223306 MAPE: 0.3052812170571444 R2 Score: -4.270535668100463 Model: GRU MAE: 94.60926055908203 MAPE: 0.18068904994438215 R2 Score: -1.6311675760853523 Model: NBEATS MAE: 27.853612263997395 MAPE: 0.06133935936828425 R2 Score: 0.8174517724736398 Model: NHITS MAE: 31.74469757080078 MAPE: 0.07192646322657587 R2 Score: 0.7056125855816267 Model: PatchTST MAE: 20.82561492919922 MAPE: 0.043825312776846516 R2 Score: 0.8899272106906247
まとめ
NeuralForecastの簡易チュートリアルでは、ビジネスにおける時系列予測の実践的な適用を示しました。
Pythonを用いて、NeuralForecastをインストールし、比較的古典的な時系列深層学習であるRNNから、最先端の時系列トランスフォーマーであるPatchTSTの幾つかの時系列深層学習モデルで、AirPassengersデータセットの時系列予測を行い、その結果を視覚化しました。
このプロセスは、ビジネスにおけるデータ駆動型の意思決定をサポートし、より正確な予測を実現するための実用的な基盤を提供します。
深層学習によるビジネス時系列分析ツール NeuralForecast(3)– 時系列回帰モデルを深層学習で構築する方法 –