
Python で時系列予測といえば Prophet。
しかし実務では、データ前処理やハイパーパラメータ調整、追加説明変数(外生変数)との組み合わせが欠かせません。
今回は Prophet を scikit-learn の Pipeline に組み込み、前処理→学習→予測→可視化を一気通貫で回す方法をステップごとに解説します。
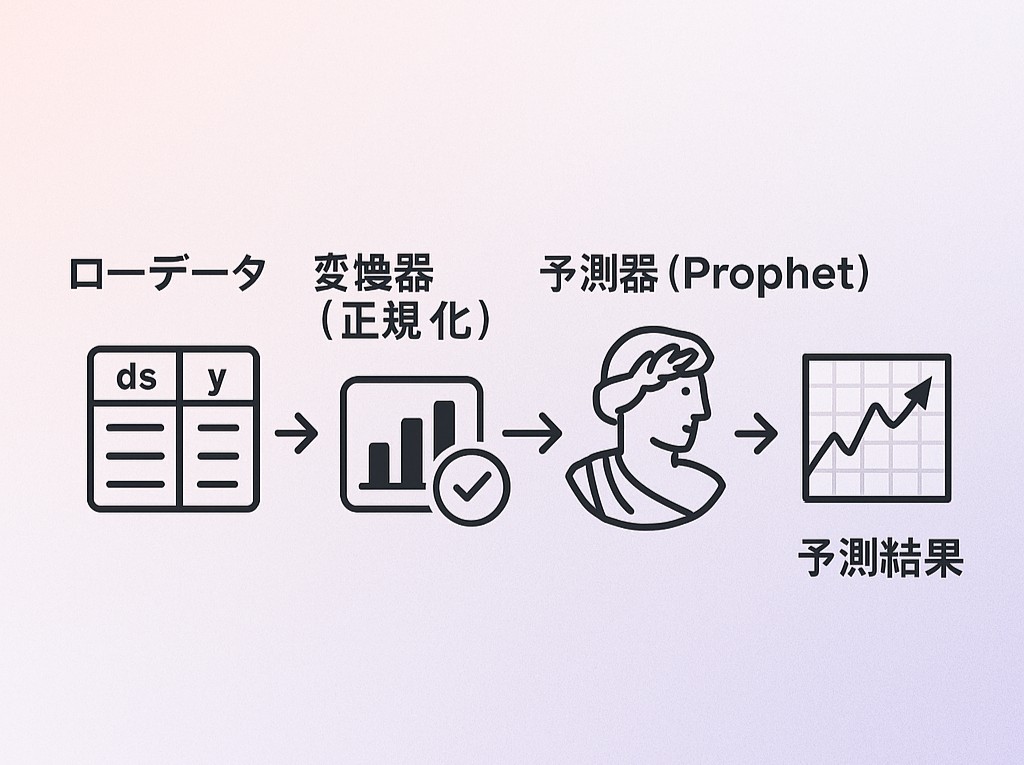
完成イメージは以下です。
ローデータ ─▶ 変換器(正規化) ─▶ 予測器(Prophet) ─▶ 予測結果
なぜ Prophet を Pipeline 化するのか?
Prophet 単体で利用した場合の課題と、 Pipeline 化で得られるメリットです。
| 課題 | Pipeline 化で得られるメリット |
| 前処理とモデルを別ファイルで管理→コードが散らかる | 一つのオブジェクトにラップし可読性アップ |
クロスバリデーションや GridSearch が面倒 |
GridSearchCV がそのまま使える |
追加説明変数の数が増えると add_regressor を書き忘れやすい |
ラッパークラス内で自動 add_regressor |
要するに、単なるコード整理を超えて、機械学習ワークフロー全体を Prophet に適用できる点が最大の利点です。
データ準備
ここでは 3 年分のサンプルデータを生成します。ds 列に日付、reg が外生変数、y が目的変数です。
以下、コードです。
# 必要なライブラリをインポート
import numpy as np
import pandas as pd
# 乱数のシードを固定して再現性を確保
np.random.seed(0)
# データのサンプル数を設定
N = 365 * 3
# 日付データを生成(2022年1月1日からN日間のデータ)
dates = pd.date_range('2022-01-01', periods=N, freq='D')
# 外生変数を生成(線形データにランダムなノイズを加える)
reg = np.linspace(0, 10, N) + np.random.randn(N)*0.2
# 目的変数を生成(外生変数とsin、ノイズの組み合わせ)
y = 0.5*reg + np.sin(2*np.pi*np.arange(N)/365) + np.random.randn(N)*0.2
# データフレームを作成
data = pd.DataFrame({
'ds': dates, # 日付
'reg': reg, # 外生変数
'y': y # 目的変数
})
# データフレームを表示
print(data)
以下、実行結果です。
ds reg y 0 2022-01-01 0.352810 0.158356 1 2022-01-02 0.089172 0.208131 2 2022-01-03 0.214029 0.128339 3 2022-01-04 0.475601 0.359054 4 2022-01-05 0.410075 0.406491 ... ... ... ... 1090 2024-12-26 9.787605 5.057952 1091 2024-12-27 9.926357 4.847469 1092 2024-12-28 9.653957 4.602688 1093 2024-12-29 9.844197 4.680556 1094 2024-12-30 10.429915 5.226078 [1095 rows x 3 columns]
このとき、目的変数と外生変数も分割します。
# 訓練データ(train)とテストデータ(test)に分割 train, test = data.iloc[:-365], data.iloc[-365:] # 訓練データ:外生変数(X_train,)と目的変数(y_train)に分割 X_train, y_train = train.drop(columns='y'), train['y'] # テストデータ:外生変数(X_test)と目的変数(y_test)に分割 X_test, y_test = test.drop(columns='y'), test['y']
直近365データポイントをテストデータとし、それより前のデータを訓練データとしています。
変換器:StandardScaler で外生変数を正規化
変数の数値スケールの差をなくすことで、Prophet 内部の L2 正則化が均一に機能し、係数解釈も安定します。
そのための前処理を実施する変換器を作ります。
以下、コードです。
# 必要なライブラリをインポート
from sklearn.preprocessing import StandardScaler
from sklearn.base import BaseEstimator, TransformerMixin
# カスタムスケーラークラスを定義
class RegScaler(BaseEstimator, TransformerMixin):
# 初期化メソッド
def __init__(self):
# StandardScaler のインスタンスを作成
self.scaler = StandardScaler()
# スケーリング対象の列名を格納する変数を初期化
self.cols_ = None
# 学習メソッド
def fit(self, X, y=None):
# 'ds' 列以外の列名を取得して self.cols_ に格納
self.cols_ = [c for c in X.columns if c != 'ds']
# スケーリング対象の列に対して StandardScaler をフィッティング
self.scaler.fit(X[self.cols_])
return self
# 変換メソッド
def transform(self, X):
# 入力データフレームをコピー
df = X.copy()
# スケーリング対象の列を変換
df[self.cols_] = self.scaler.transform(df[self.cols_])
return df
連続値の説明変数が多い場合は、このようなスケーリングをした方がいいでしょう。さらに、Log 変換や Box-Cox と組み合わせても OK です。
カテゴリ変数を含む場合は、One-Hot後にスケールするなど、パイプラインを拡張するのもいいでしょう。
予測器:ProphetRegressor を scikit-learn Estimator 化
ここでは Prophet を scikit-learn 互換にするラッパーを実装します。
以下、コードです。
# 必要なライブラリをインポート
from prophet import Prophet
from sklearn.base import RegressorMixin, BaseEstimator
# Prophetをラップするクラスを定義
class ProphetRegressor(BaseEstimator, RegressorMixin):
# 初期化メソッド
def __init__(
self,
n_changepoints=25, # 変化点の数を指定
yearly_seasonality=False, # 年次の季節性を使用するかどうか
**prophet_kwargs # その他のProphetのパラメータ
):
self.n_changepoints = n_changepoints
self.yearly_seasonality = yearly_seasonality
self.prophet_kwargs = prophet_kwargs
self.model_ = None
# 学習メソッド
def fit(self, X, y):
# 入力データをコピーして目的変数を追加
df = X.copy()
# 目的変数をデータフレームに追加
df['y'] = y
# Prophetモデルを初期化
self.model_ = Prophet(
n_changepoints=self.n_changepoints,
yearly_seasonality=self.yearly_seasonality,
**self.prophet_kwargs
)
# 外生変数をProphetモデルに追加
for col in df.columns:
if col not in ['ds', 'y']:
self.model_.add_regressor(col)
# モデルを学習
self.model_.fit(df)
return self
# 予測メソッド
def predict(self, X):
# 予測を実行
forecast = self.model_.predict(X)
# 予測結果(yhat列)を返す
return forecast['yhat'].values
変換器と予測器を一本化します。
from sklearn.pipeline import Pipeline
# パイプラインの設定
pipe = Pipeline([
('scaler', RegScaler()), # データのスケーリングを行う変換器
('prophet', ProphetRegressor()), # 時系列予測を行う予測器
])
# パイプラインのステップを確認
print(pipe.named_steps)
以下、実行結果です。
{'scaler': RegScaler(), 'prophet': ProphetRegressor()}
変換器と予測器を一本化します。
from sklearn.metrics import mean_squared_error, r2_score
# 学習(訓練データ)
pipe.fit(X_train, y_train)
# 予測(テストデータ)
y_pred = pipe.predict(X_test)
# 予測精度
## 平均二乗誤差 (MSE)
mse = mean_squared_error(y_test, y_pred)
## 決定係数 (R^2)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R^2 Score: {r2}")
以下、実行結果です。
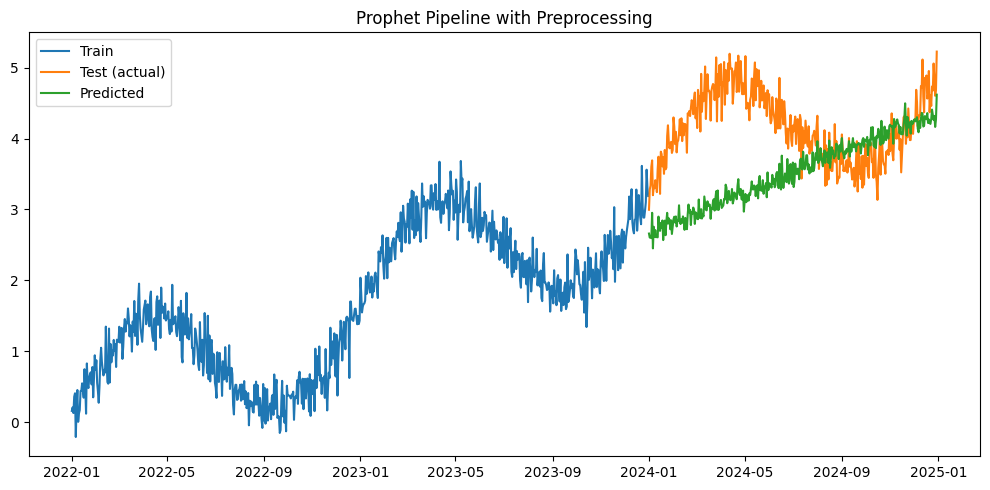
Mean Squared Error: 0.9566794540470825 R^2 Score: -3.0408605232094272
最後に、モデルの当てはまりを直感的にチェックしましょう。
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.plot(train['ds'], y_train, label='Train')
plt.plot(test['ds'], y_test, label='Test (actual)')
plt.plot(test['ds'], y_pred, label='Predicted')
plt.legend()
plt.title('Prophet Pipeline with Preprocessing')
plt.tight_layout()
plt.show()
以下、実行結果です。
実務ではProphetモデルにはたくさんのハイパーパラメータがあります。たとえば、 Changepoint 数や季節性フラグなどです。
# 必要なライブラリをインポート
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
# Prophetのハイパーパラメータを探索するためのパラメータグリッドを定義
param_grid = {
# 変化点の数は?
'prophet__n_changepoints': [10, 25, 50],
# 年次の季節性を使用するかどうか
'prophet__yearly_seasonality': [True, False],
}
# 時系列データ用の交差検証を設定
# データを5分割して交差検証を行う
tscv = TimeSeriesSplit(n_splits=5)
# グリッドサーチを実行
# パイプラインとパラメータグリッドを指定し、評価指標として負の平均絶対誤差を使用
search = GridSearchCV(
pipe, # パイプライン
param_grid, # 探索するパラメータグリッド
cv=tscv, # 時系列データ用の交差検証
scoring='neg_mean_absolute_error' # 評価指標
)
# 訓練データを用いてグリッドサーチを実行
search.fit(X_train, y_train)
# 最適なパラメータを出力
print('Best params:', search.best_params_)
以下、実行結果です。
Best params: {'prophet__n_changepoints': 10, 'prophet__yearly_seasonality': True}
# Best paramsを使用してパイプラインを再構築
best_params = search.best_params_
# パイプラインの再構築
pipe_optimized = Pipeline([
('scaler', RegScaler()),
('prophet', ProphetRegressor(
n_changepoints=best_params['prophet__n_changepoints'],
yearly_seasonality=best_params['prophet__yearly_seasonality']
)),
])
# 再構築したパイプラインで学習
pipe_optimized.fit(X_train, y_train)
# テストデータで予測
y_pred_optimized = pipe_optimized.predict(X_test)
# 予測精度の計算
mse_optimized = mean_squared_error(y_test, y_pred_optimized)
r2_optimized = r2_score(y_test, y_pred_optimized)
print(f"Optimized Mean Squared Error: {mse_optimized}")
print(f"Optimized R^2 Score: {r2_optimized}")
# グラフ化
plt.figure(figsize=(10,5))
plt.plot(train['ds'], y_train, label='Train')
plt.plot(test['ds'], y_test, label='Test (actual)')
plt.plot(test['ds'], y_pred_optimized, label='Optimized Predicted')
plt.legend()
plt.title('Optimized Prophet Pipeline with Preprocessing')
plt.tight_layout()
plt.show()
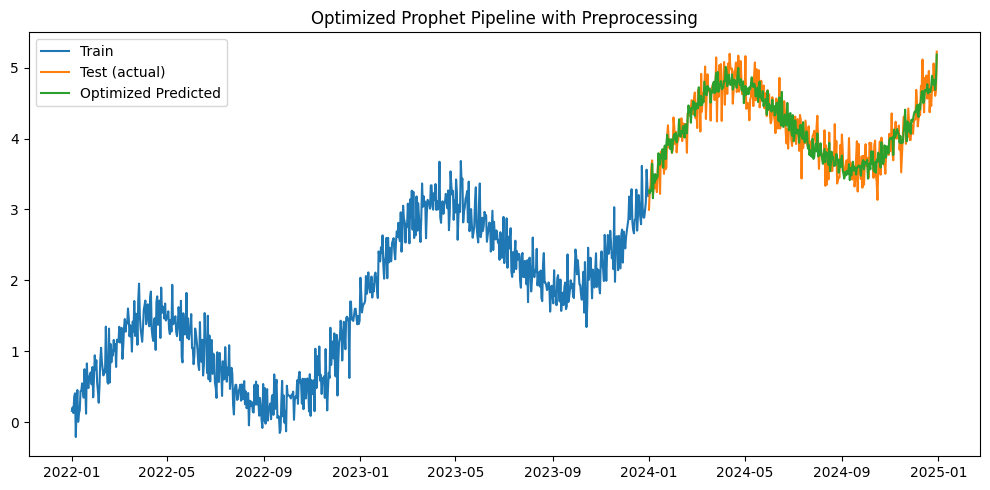
以下、実行結果です。
Optimized Mean Squared Error: 0.037226167764707864 Optimized R^2 Score: 0.8427626399684589
まとめ
パイプライン化により データ準備からモデル評価までを一本のコードで再現可能 になります。
Prophet の強みと sklearn エコシステムの柔軟性を両取りできるため、複雑な時系列プロジェクトの開発体験が大幅に向上します。
以上で、Prophet × scikit-learn Pipeline の基本からチューニングまでを駆け足で解説しました。
ぜひご自身の時系列データで試し、体験してみてください。