

データ分析の世界では、多様な機械学習モデルが活用されています。
そのなかでも「決定木(Decision Tree)」は、判断過程が可視化しやすく解釈性の高いモデルとして人気です。
しかし、実際に決定木を使う際、「どうやって構造を把握すればよいのか」「各ノードの意味は何か」と迷うこともあるでしょう。
今回は、Pythonライブラリ pybaobabdt を用いてバオバブ可視化と呼ばれる、決定木を直感的に「見て」、その仕組みを「理解する」方法を、簡単に解説します。
pybaobabdtとは?
機械学習において、決定木は特徴量に基づいてデータを一連の条件判定で分割し、最終的な予測や分類を導き出すモデルです。
その構造はまるでフローチャートのように視覚化できるため、どの判断基準でどのようにデータが振り分けられたのかを直感的に理解しやすいのが大きな魅力です。
特にビジネスの現場では、なぜその予測結果に至ったのかを説明可能であることが信頼性や意思決定の後押しにつながります。
しかし、scikit-learn の標準機能や graphviz を用いた可視化は、細かな設定が必要で見た目の調整に手間がかかる場合があります。
そこで登場するのが pybaobabdt です。pybaobabdt は、学習済みの scikit-learn 決定木モデルを入力するだけで、ノード内のサンプル数やクラス分布、gini 不純度などの情報を含んだ美しいグラフを自動生成します。
環境構築とインストール
以下では、Python環境は既に整っている前提で、必要なパッケージとGraphvizの導入方法を解説します。
scikit-learn がまだインストールされていない場合は、以下のコマンドで導入してください。決定木モデルの学習に必要です。
pip install scikit-learn
決定木の可視化を行う pybaobabdt は別途インストールが必要です。以下のコマンドで導入してください。
pip install pybaobabdt
pybaobabdt は内部で Graphviz を呼び出してグラフを描画します。Graphvizのインストールがされていない方は、以下の手順でシステムにインストールし、実行ファイルへのパスを通してください(特にWindows)。
| OS | インストール方法 | PATH設定例 |
|---|---|---|
| Windows | choco install graphvizさらに、公式サイト(https://graphviz.org/download/)から本体をインストール |
環境変数 PATH に C:\Program Files\Graphviz\bin を追加 |
| macOS | brew install graphvizpip install pygraphviz |
自動で /usr/local/bin に配置(通常PATH済み) |
| Ubuntu/Linux | sudo apt-get install graphviz graphviz-devpip install pygraphviz |
自動で /usr/bin に配置(通常PATH済み) |
決定木モデルの作成 〜 Irisデータセットを例に
pybaobabdt は既存の学習済みモデルを可視化するツールのため、まずは scikit-learn で決定木モデルを作成します。
ステップ1:ライブラリとデータセットの読み込み
# Decision Tree Classifier をインポート from sklearn.tree import DecisionTreeClassifier # scikit-learn の Iris データセットをインポート from sklearn.datasets import load_iris # Iris データセットの読み込み iris = load_iris() # 特徴量データ(X)とターゲット(y)を分割 X = iris.data y = iris.target
ステップ2:モデルの定義
# 決定木分類器のインスタンスを作成
model = DecisionTreeClassifier(
max_depth=3, # 決定木の最大深さ
random_state=42 # 乱数シード値
)
ステップ3:モデルの学習
# データセットを使用してモデルを学習 # X: 特徴量データ(がく片の長さ、がく片の幅、花弁の長さ、花弁の幅) # y: ターゲット変数(アヤメの品種) model.fit(X, y)
これで、pybaobabdt で可視化するための学習済みモデル model が準備できました。
決定木を「見る」 — 可視化の手順
学習済みの model オブジェクトを用いて、最初は通常の決定木の可視化、次いでバオバブ可視化していきます。
ステップ1:pybaobabdt などのインポート
# 可視化のためのライブラリをインポート import pybaobabdt from sklearn.tree import plot_tree import matplotlib.pyplot as plt
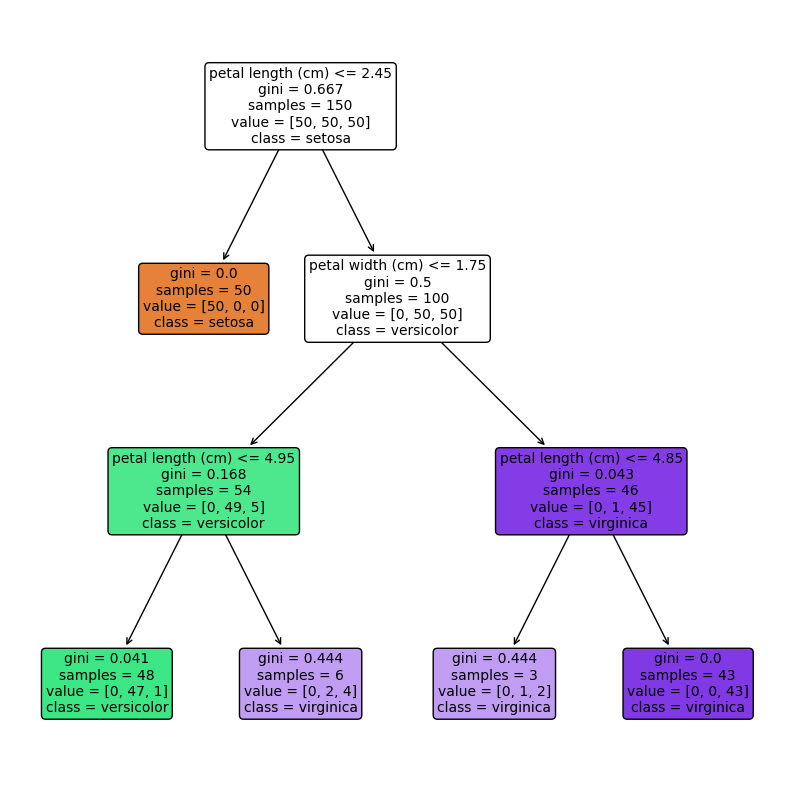
ステップ2:通常の決定木の可視化
# 決定木を可視化
result = plot_tree(
model,
feature_names=iris.feature_names, # 特徴量の名前
class_names=iris.target_names, # クラスラベル
filled=True, # ノードを色で塗りつぶす
rounded=True, # ノードを丸くする
fontsize=10, # ノードのフォントサイズ
)
以下、実行結果です。
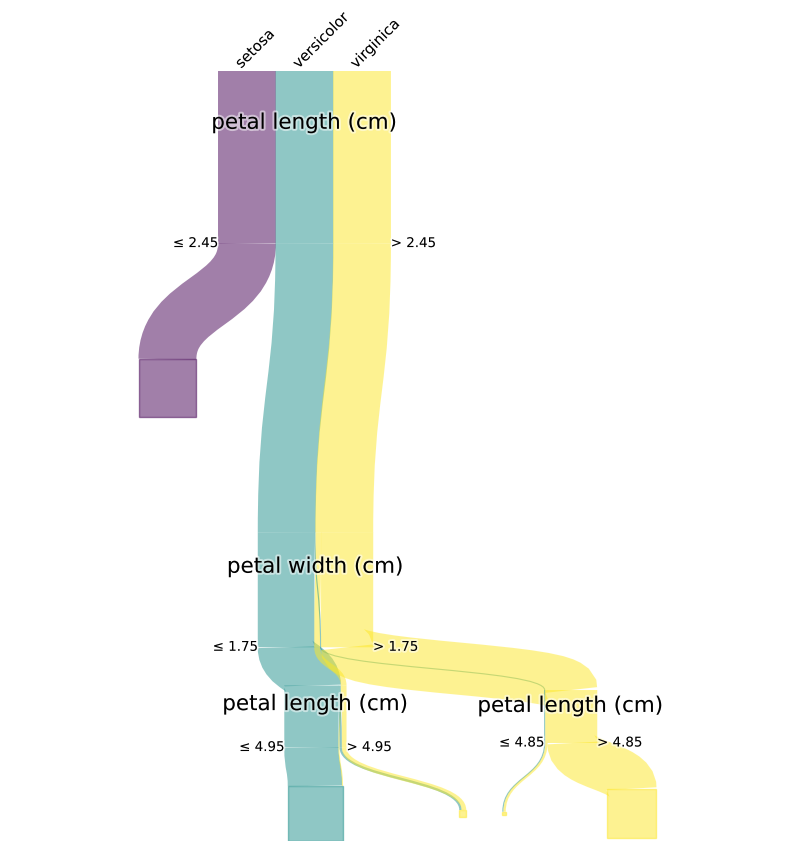
ステップ3:決定木のバオバブ可視化
# クラスラベルをバイト列に変換(文字列の場合のみ)
# pybaobabdtライブラリがバイト列形式を必要とするため
model.classes_ = [
s.encode() if isinstance(s, str)
else s
for s in iris.target_names
]
# 決定木を可視化(pybaobabdtライブラリを使用)
ax = pybaobabdt.drawTree(
model, # 学習済みの決定木モデル
size=10, # プロットのサイズ
dpi=100, # 解像度(dots per inch)
maxdepth=3, # 表示する決定木の最大深さ
features=iris.feature_names,# 特徴量の名前リスト
classes=model.classes_, # クラスラベル
)
以下、実行結果です。
まとめ
今回は、Pythonライブラリ pybaobabdt を用いて、決定木モデルの可視化の方法を解説しました。
ぜひ自身のデータセットでも試し、モデルの動作原理などの理解に役立ててみてください。
決定木の可視化は、モデルのデバッグ、改善、結果説明に大いに役立ちます。