

前回は、NumPyとPandasを使って大規模なデータを効率的に処理する方法を学びました。
数万件のデータも瞬時に集計でき、複雑な条件でフィルタリングしたり、グループごとに統計量を計算したりできるようになりました。しかし、処理したデータを数字の表として眺めているだけでは、データが語る「物語」を見逃してしまうかもしれません。
例えば、「先月の売上は前月比5%増、前年同月比では12%増」という数字を見ても、それが季節的な変動なのか、成長トレンドなのか、それとも一時的な現象なのかは判断しづらいでしょう。しかし、これを時系列グラフで表現すれば、上昇トレンドや季節パターンが一目瞭然になります。
今回は、Pythonでデータ可視化を行うための2大ライブラリ、MatplotlibとSeabornを学びます。
これらのツールを使いこなせるようになれば、複雑なデータから意味のあるパターンを発見し、説得力のあるプレゼンテーションを作成し、データに基づいた意思決定を支援できるようになります。Pythonでデータ可視化を行うための2つの強力なライブラリ、Matplotlib(マットプロットリブ)とSeaborn(シーボーン)を学びます。
Matplotlibは、Pythonでグラフを描くための最も基本的で柔軟なライブラリです。
一方、Seabornは、Matplotlibを基盤として、より美しく、より簡単に統計的なグラフを作成できるように設計されたライブラリです。
料理に例えるなら、Matplotlibが包丁や鍋などの基本調理器具で、Seabornは電子レンジや炊飯器のような便利な調理家電といえるでしょう。
Contents
Matplotlib入門:グラフ作成の基礎を学ぶ
Matplotlibの準備と日本語表示の設定
まず、Matplotlibをインポートして、基本的な設定を行いましょう。特に重要なのが日本語表示の設定です。Matplotlibは英語圏で開発されたライブラリなので、そのままでは日本語が文字化けしてしまいます。この問題を解決する最も簡単で確実な方法は、japanize-matplotlibというライブラリを使うことです。
# まず、japanize-matplotlibをインストール(初回のみ) # JupyterLabのセルで実行してください !pip install japanize-matplotlib
インストールが完了したら、ライブラリをインポートします。
# 必要なライブラリをインポート import matplotlib.pyplot as plt import japanize_matplotlib # これを追加するだけで日本語が使える! import numpy as np import pandas as pd
japanize_matplotlibをインポートするだけで、自動的に日本語フォントが設定されます。これにより、環境による違いを気にせず、どのコンピュータでも同じように日本語が表示されるようになります。
最初のグラフを描いてみよう
それでは、最もシンプルな折れ線グラフから始めましょう。1週間の気温変化を可視化してみます。
# データの準備
days = ['月', '火', '水', '木', '金', '土', '日']
temperatures = [22, 24, 21, 25, 27, 26, 23]
# グラフを作成
plt.plot(days, temperatures) # 折れ線グラフを描画
plt.title('1週間の気温変化') # タイトルを設定
plt.xlabel('曜日') # x軸のラベルを設定
plt.ylabel('気温(℃)') # y軸のラベルを設定
plt.show() # グラフを表示
以下、実行結果です。
たった数行のコードで、日本語のラベルが正しく表示されたグラフが描けました。japanize_matplotlibのおかげで、文字化けの心配をすることなく、分析に集中できます。
plt.plot()関数が実際に線を描く部分で、plt.title()、plt.xlabel()、plt.ylabel()はそれぞれタイトルと軸ラベルを設定しています。最後のplt.show()は、グラフを表示するコマンドです。
しかし、このグラフはまだシンプルすぎます。もっと見やすく、情報量の多いグラフにしてみましょう。まず、グラフのサイズと基本的な装飾を設定します。
# より詳細なグラフを作成
plt.figure(figsize=(10, 6)) # グラフのサイズを指定
# 折れ線グラフを描画(マーカーを追加)
plt.plot(
days, # x軸のデータ(曜日)
temperatures, # y軸のデータ(気温)
marker='o', # マーカーの形状(丸)
linestyle='-', # 線の種類(実線)
color='#2E86AB',# 線の色(青系)
linewidth=2, # 線の太さ
markersize=8, # マーカーのサイズ
label='気温' # 凡例のラベル
)
# グリッドを追加
plt.grid(True, alpha=0.3)
以下、実行結果です。
ここでは、marker='o'で各データポイントに丸いマーカーを追加し、color='#2E86AB'で青系の色を指定しています。linewidth=2は線の太さ、markersize=8はマーカーの大きさを調整しています。グリッド線を追加することで、値の読み取りが容易になります。
次に、タイトルや軸の設定、そして各データポイントに値を表示する処理を追加します。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# 折れ線グラフを描画(マーカーを追加)
plt.plot(
days, # x軸のデータ(曜日)
temperatures, # y軸のデータ(気温)
marker='o', # マーカーの形状(丸)
linestyle='-', # 線の種類(実線)
color='#2E86AB',# 線の色(青系)
linewidth=2, # 線の太さ
markersize=8, # マーカーのサイズ
label='気温' # 凡例のラベル
)
# グリッドを追加
plt.grid(True, alpha=0.3)
# 各データポイントに値を表示
for i, temp in enumerate(temperatures):
plt.text(
i, # x座標
temp + 0.5, # y座標(気温の上に表示)
f'{temp}℃', # 表示するテキスト
ha='center', # 水平方向の配置(中央)
va='bottom', # 垂直方向の配置(下部)
fontsize=10 # フォントサイズ
)
# タイトルと軸ラベルを設定
plt.title('1週間の気温変化')
plt.xlabel('曜日')
plt.ylabel('気温(℃)')
# y軸の範囲を設定
plt.ylim(18, 30)
# 凡例を表示
plt.legend()
# グラフを表示
plt.show()
以下、実行結果です。
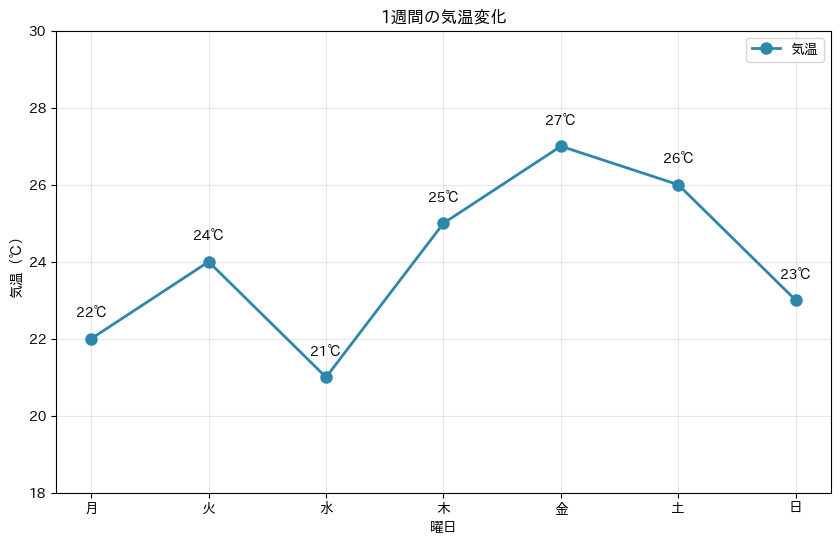
plt.text()を使って各データポイントの上に実際の温度を表示しています。ha='center'は水平方向の配置(horizontal alignment)、va='bottom'は垂直方向の配置(vertical alignment)を指定しています。これにより、グラフから正確な数値も同時に読み取れるようになりました。
様々なグラフの種類を使い分ける
データの性質によって、適切なグラフの種類は異なります。主要なグラフの種類とその使い分けを学んでいきましょう。
まず、棒グラフです。カテゴリ別の比較に最適です。
# 棒グラフ:店舗別売上の比較
stores = ['渋谷店', '新宿店', '池袋店', '品川店', '横浜店']
sales = [520, 480, 350, 420, 390]
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# 棒グラフを作成
bars = plt.bar(
stores, # x軸のデータ(店舗名)
sales, # y軸のデータ(売上)
color='#16537e', # 棒の色(濃い青)
edgecolor='black', # 枠線の色(黒)
linewidth=1 # 枠線の太さ
)
以下、実行結果です。
棒グラフの基本的な描画が完了しました。plt.bar()関数で棒グラフを作成し、colorで塗りつぶしの色、edgecolorで枠線の色を指定しています。次に、各棒の上に値を表示し、グラフの装飾を追加します。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# 棒グラフを作成
bars = plt.bar(
stores, # x軸のデータ(店舗名)
sales, # y軸のデータ(売上)
color='#16537e', # 棒の色(濃い青)
edgecolor='black', # 枠線の色(黒)
linewidth=1 # 枠線の太さ
)
# 各データポイントに値を表示
for bar, sale in zip(bars, sales):
yval = bar.get_height()
plt.text(
bar.get_x() + bar.get_width() / 2, # x座標(棒の中央)
yval + 10, # y座標(棒の上に表示)
f'{sale}円', # 表示するテキスト
ha='center', # 水平方向の配置(中央)
va='bottom', # 垂直方向の配置(下部)
fontsize=10 # フォントサイズ
)
# タイトルと軸ラベルを設定
plt.title('店舗別売上の比較')
plt.xlabel('店舗名')
plt.ylabel('売上(円)')
# y軸の範囲を設定
plt.ylim(0, 600)
# グラフを表示
plt.show()
以下、実行結果です。
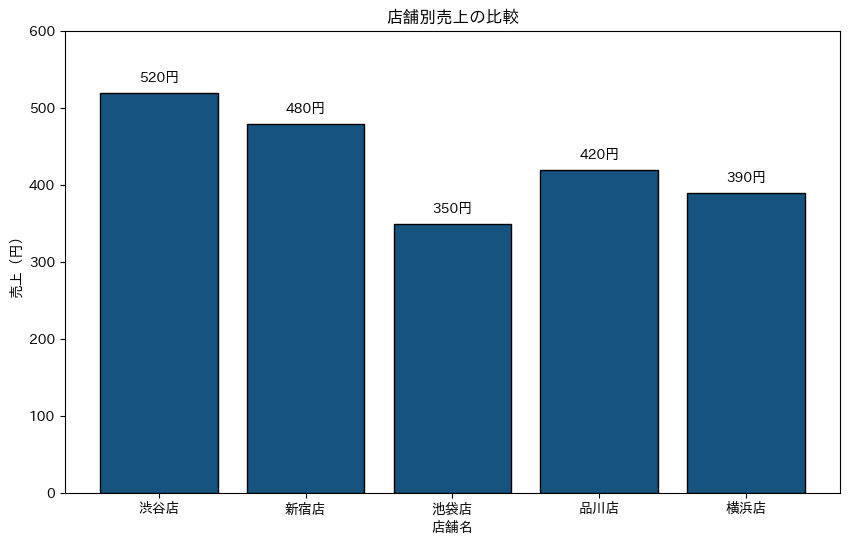
棒グラフは、異なるカテゴリの値を比較するときに非常に効果的です。人間の目は、棒の高さの違いを素早く認識できるため、どの店舗が最も売上が高いか、どの程度の差があるかが一目で分かります。
次に、円グラフを見てみましょう。全体に対する各部分の割合を示すのに適しています。
# 円グラフ:部門別予算配分
departments = ['営業部', '開発部', '人事部', '経理部', '広報部']
budgets = [35, 30, 15, 12, 8]
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4', '#FECA57']
# グラフのサイズを指定
plt.figure(figsize=(10, 8))
# 円グラフを作成
plt.pie(
budgets, # データ(予算)
labels=departments, # ラベル(部門名)
colors=colors, # 色
autopct='%1.1f%%', # パーセンテージを表示
startangle=90, # 開始角度を指定(90度から開始)
explode=[
0.05, # 営業部を突出させる
0, # 開発部はそのまま
0, # 人事部はそのまま
0, # 経理部はそのまま
0 # 広報部はそのまま
]
)
# グラフを表示
plt.show()
以下、実行結果です。
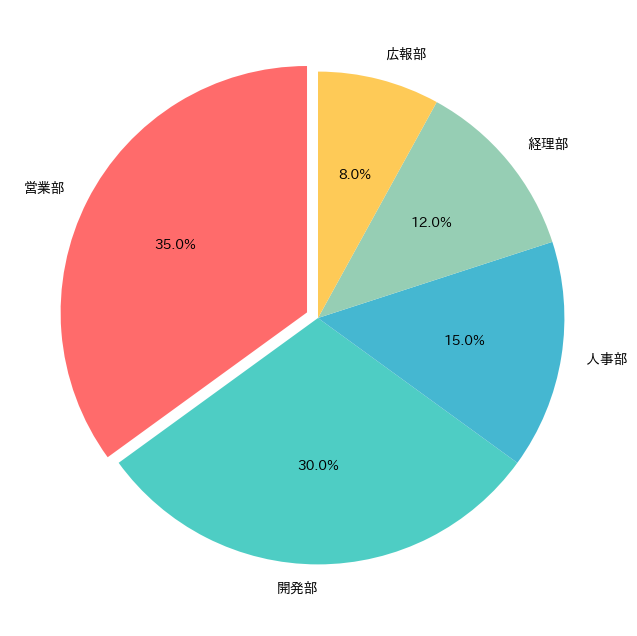
円グラフの基本的な設定を行いました。autopct='%1.1f%%'は各セクションにパーセンテージを自動的に表示する設定で、explodeパラメータで営業部のセクションを少し離して強調しています。
散布図は、2つの変数間の関係を見るのに最適です。まず、サンプルデータを生成します。
# 散布図:広告費と売上の関係
np.random.seed(42)
ad_spending = np.random.uniform(10, 100, 50) # 広告費(万円)
sales = ad_spending * 3 + np.random.normal(0, 30, 50) # 売上(万円)
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# 散布図を作成
plt.scatter(
ad_spending, # x軸のデータ(広告費)
sales, # y軸のデータ(売上)
alpha=0.6, # 透明度
s=100, # マーカーのサイズ
c='#2E86AB', # マーカーの色
edgecolors='black' # 枠線の色
)
# グラフを表示
plt.show()
以下、実行結果です。
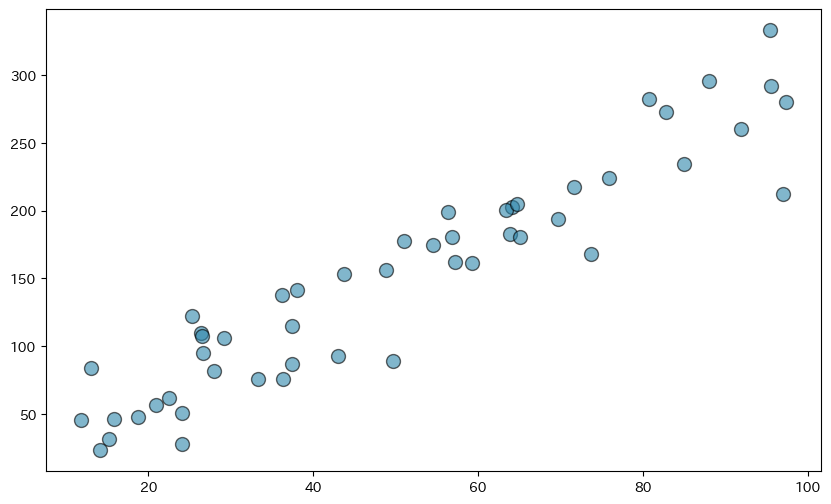
散布図の基本的なプロットができました。alpha=0.6で点を半透明にし、重なった点も見えるようにしています。次に、データの傾向を示す回帰線を追加します。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# 散布図を作成
plt.scatter(
ad_spending, # x軸のデータ(広告費)
sales, # y軸のデータ(売上)
alpha=0.6, # 透明度
s=100, # マーカーのサイズ
c='#2E86AB', # マーカーの色
edgecolors='black' # 枠線の色
)
# np.polyfitで傾向線の傾きと切片を計算
z = np.polyfit(
ad_spending, # x軸のデータ(広告費)
sales, # y軸のデータ(売上)
1 # 1次の多項式でフィット
)
# np.poly1dで多項式を作成
p = np.poly1d(z)
# 傾向線を描画
plt.plot(
ad_spending, # x軸のデータ(広告費)
p(ad_spending), # y軸のデータ(傾向線)
"r-", # 線の色と種類(赤色の実線)
alpha=0.8, # 透明度
linewidth=2, # 線の太さ
label='傾向線' # 凡例のラベル
)
# タイトルと軸ラベルを設定
plt.title('広告費と売上の関係')
plt.xlabel('広告費(万円)')
plt.ylabel('売上(万円)')
# グリッドを追加
plt.grid(True, alpha=0.3)
# 凡例を表示
plt.legend()
# グラフを表示
plt.show()
以下、実行結果です。
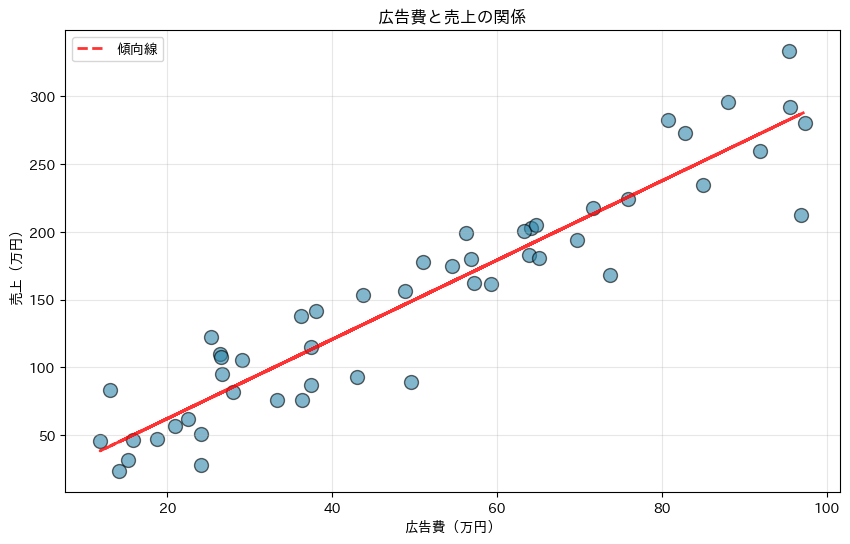
np.polyfit()で1次の回帰線を計算し、赤い破線で表示しています。散布図では、点の分布パターンから変数間の関係性を読み取ることができます。この例では、広告費が増えると売上も増える正の相関関係が見て取れます。
ヒストグラムは、データの分布を見るために使います。まず、正規分布に従うサンプルデータを生成します。
# ヒストグラム:テストの点数分布
np.random.seed(123)
scores = np.random.normal(70, 15, 200) # 平均70点、標準偏差15の正規分布
scores = np.clip(scores, 0, 100) # 0-100点の範囲に制限
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# ヒストグラムを作成
n, bins, patches = plt.hist(
scores, # データ(点数)
bins=20, # ビンの数(20個)
color='#4ECDC4', # 棒の色(水色)
edgecolor='black', # 枠線の色(黒)
alpha=0.5 # 透明度
)
# グラフを表示
plt.show()
以下、実行結果です。
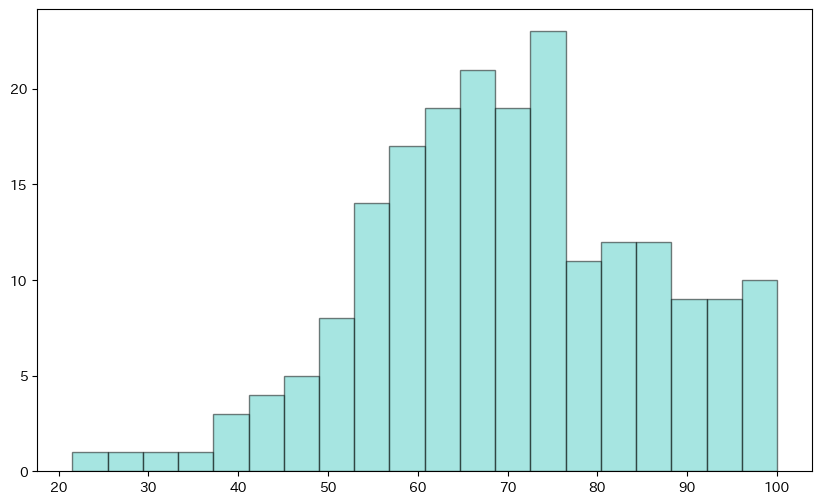
ヒストグラムの基本的な描画を行いました。bins=20で階級数を20に設定しています。
次に、平均値と中央値を縦線で表示し、分布の特徴を明確にします。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# ヒストグラムを作成
n, bins, patches = plt.hist(
scores, # データ(点数)
bins=20, # ビンの数(20個)
color='#4ECDC4', # 棒の色(水色)
edgecolor='black', # 枠線の色(黒)
alpha=0.5 # 透明度
)
# np.meanで平均値を計算
mean_score = np.mean(scores)
# 平均値を表示する垂直線を追加
plt.axvline(
mean_score, # 平均値の位置
color='red', # 線の色(赤)
linestyle='--', # 線の種類(破線)
linewidth=2, # 線の太さ
label=f'平均: {mean_score:.1f}点' # 凡例のラベル
)
# np.medianで中央値を計算
median_score = np.median(scores)
# 中央値を表示する垂直線を追加
plt.axvline(
median_score, # 中央値の位置
color='orange', # 線の色(オレンジ)
linestyle='--', # 線の種類(破線)
linewidth=2, # 線の太さ
label=f'中央値: {median_score:.1f}点' # 凡例のラベル
)
# タイトルと軸ラベルを設定
plt.title('テスト点数の分布')
plt.xlabel('点数')
plt.ylabel('人数')
# 凡例を表示
plt.legend()
# y軸のグリッドを追加
plt.grid(True, axis='y', alpha=0.3)
# グラフを表示
plt.show()
以下、実行結果です。
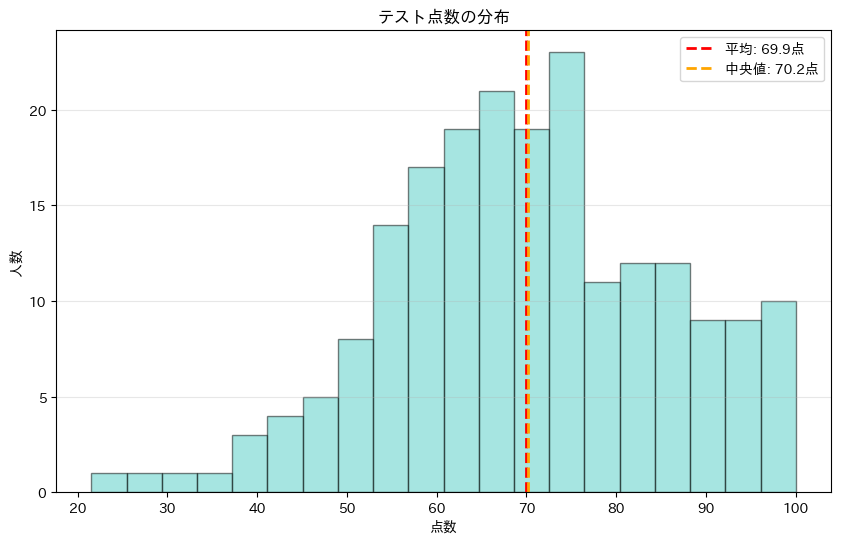
ヒストグラムを見ることで、データがどのように分布しているかが分かります。この例では、70点付近を中心とした釣鐘型の分布(正規分布)になっていることが確認できます。
複数のグラフを組み合わせる
実際のデータ分析では、複数のグラフを並べて比較したいことがよくあります。Matplotlibの`subplot`機能を使えば、複数のグラフを1つの図にまとめることができます。
まず、4つの店舗の月別売上データを準備します。
# 4つの店舗の月別売上を比較
months = ['1月', '2月', '3月', '4月', '5月', '6月']
shibuya = [520, 540, 510, 560, 580, 590]
shinjuku = [480, 490, 500, 510, 520, 540]
ikebukuro = [350, 360, 370, 380, 400, 420]
shinagawa = [420, 430, 440, 450, 460, 470]
# 2行2列のサブプロットを作成
fig, axes = plt.subplots(
2, # 行数
2, # 列数
figsize=(14, 10) # グラフのサイズ
)
# グラフのタイトルを設定
fig.suptitle('店舗別売上推移')
# グラフを表示
plt.show()
以下、実行結果です。
plt.subplots(2, 2)で2行2列のグラフ領域を作成しました。figは全体の図、axesは各グラフにアクセスするための配列です。
次に、各店舗のグラフを個別に設定し表示します。
# 2行2列のサブプロットを作成
fig, axes = plt.subplots(
2, # 行数
2, # 列数
figsize=(14, 10) # グラフのサイズ
)
# グラフのタイトルを設定
fig.suptitle('店舗別売上推移')
# 渋谷店(左上)
axes[0, 0].plot(
months, # x軸のデータ(月)
shibuya, # y軸のデータ(売上)
marker='o', # マーカーの形状(丸)
color='#FF6B6B', # 線の色(赤系)
linewidth=2 # 線の太さ
)
axes[0, 0].set_title('渋谷店', fontsize=14)
axes[0, 0].set_ylabel('売上(万円)')
axes[0, 0].grid(True, alpha=0.3)
axes[0, 0].set_ylim(300, 650)
# 新宿店(右上)
axes[0, 1].plot(
months, # x軸のデータ(月)
shinjuku, # y軸のデータ(売上)
marker='s', # マーカーの形状(四角)
color='#4ECDC4', # 線の色(水色)
linewidth=2 # 線の太さ
)
axes[0, 1].set_title('新宿店', fontsize=14)
axes[0, 1].grid(True, alpha=0.3)
axes[0, 1].set_ylim(300, 650)
# 池袋店(左下)
axes[1, 0].plot(
months, # x軸のデータ(月)
ikebukuro, # y軸のデータ(売上)
marker='^', # マーカーの形状(三角)
color='#45B7D1', # 線の色(青系)
linewidth=2 # 線の太さ
)
axes[1, 0].set_title('池袋店', fontsize=14)
axes[1, 0].set_xlabel('月')
axes[1, 0].set_ylabel('売上(万円)')
axes[1, 0].grid(True, alpha=0.3)
axes[1, 0].set_ylim(300, 650)
# 品川店(右下)
axes[1, 1].plot(
months, # x軸のデータ(月)
shinagawa, # y軸のデータ(売上)
marker='d', # マーカーの形状(菱形)
color='#96CEB4', # 線の色(緑系)
linewidth=2 # 線の太さ
)
axes[1, 1].set_title('品川店', fontsize=14)
axes[1, 1].set_xlabel('月')
axes[1, 1].grid(True, alpha=0.3)
axes[1, 1].set_ylim(300, 650)
# レイアウトを自動調整
plt.tight_layout()
# グラフを表示
plt.show()
以下、実行結果です。
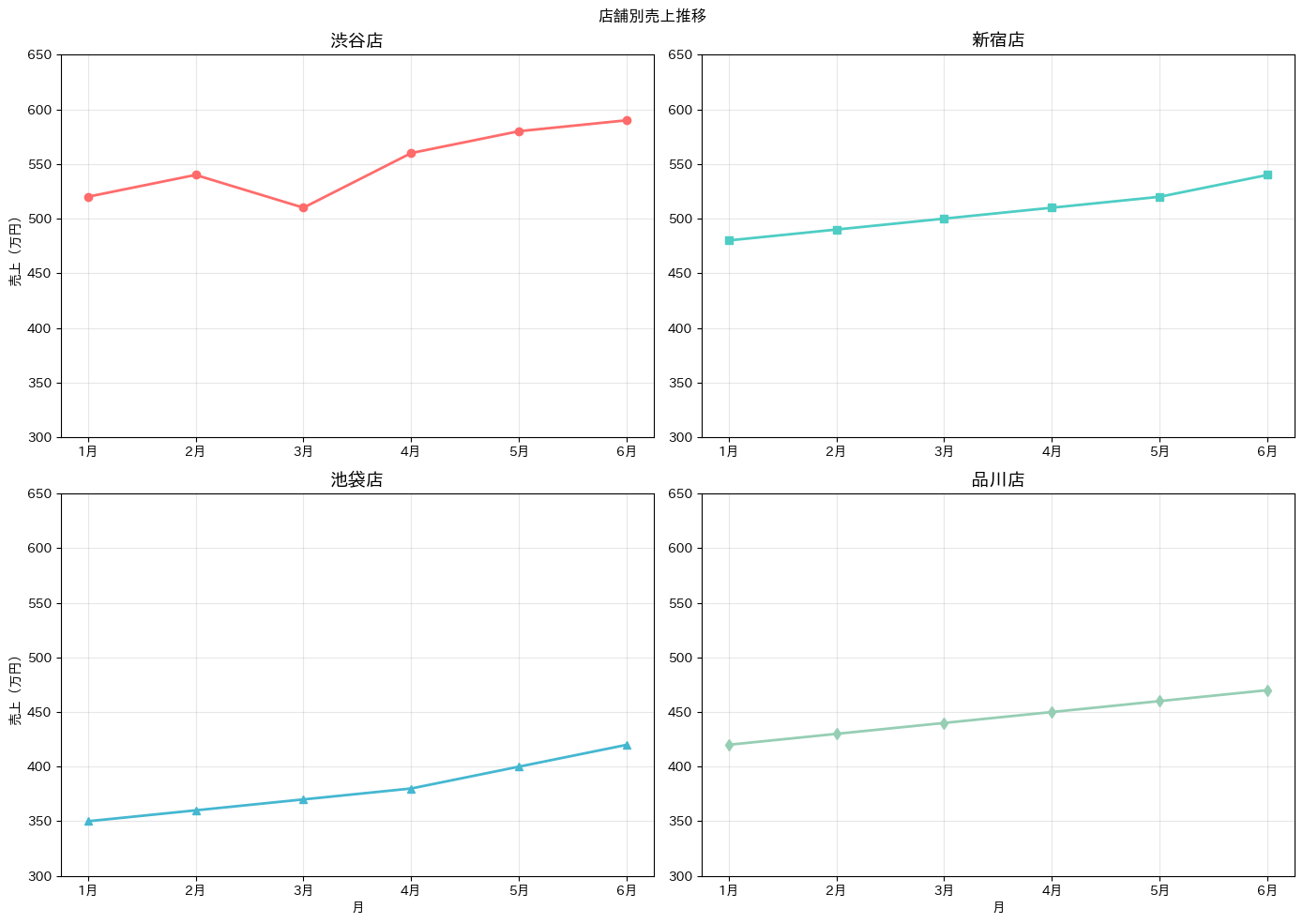
plt.tight_layout()は、グラフ同士が重ならないように自動的にレイアウトを調整する便利な関数です。
同じデータを1つのグラフにまとめて表示することもできます。
# グラフのサイズを指定
plt.figure(figsize=(12, 7))
# 各店舗の折れ線グラフを描画
plt.plot(
months, # x軸のデータ(月)
shibuya, # y軸のデータ(売上)
marker='o', # マーカーの形状(丸)
linewidth=2, # 線の太さ
label='渋谷店' # 凡例のラベル
)
plt.plot(
months, # x軸のデータ(月)
shinjuku, # y軸のデータ(売上)
marker='s', # マーカーの形状(四角)
linewidth=2, # 線の太さ
label='新宿店' # 凡例のラベル
)
plt.plot(
months, # x軸のデータ(月)
ikebukuro, # y軸のデータ(売上)
marker='^', # マーカーの形状(三角)
linewidth=2, # 線の太さ
label='池袋店' # 凡例のラベル
)
plt.plot(
months, # x軸のデータ(月)
shinagawa, # y軸のデータ(売上)
marker='d', # マーカーの形状(菱形)
linewidth=2, # 線の太さ
label='品川店' # 凡例のラベル
)
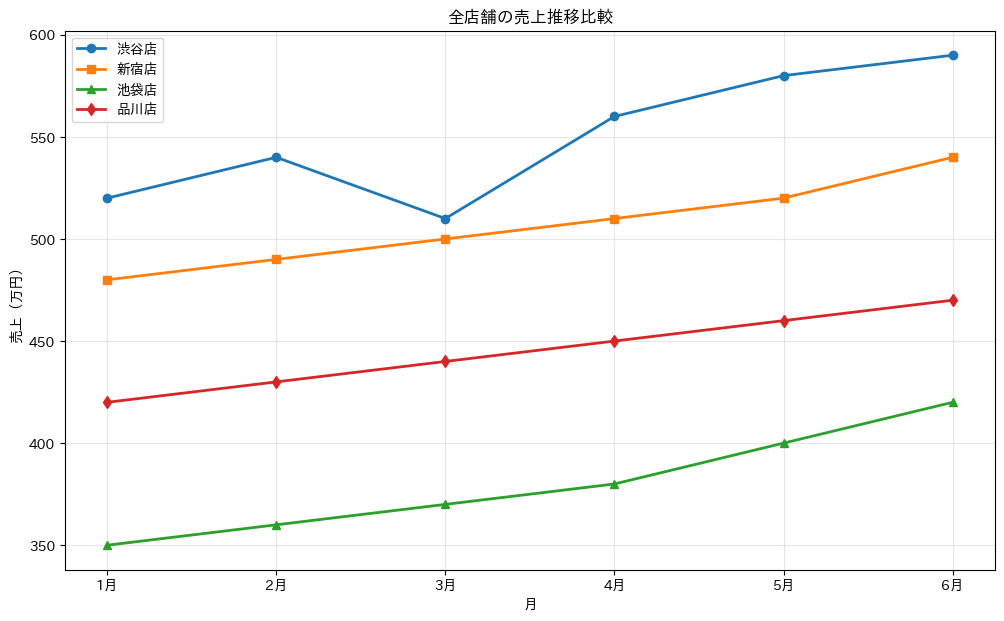
# タイトルと軸ラベルを設定
plt.title('全店舗の売上推移比較')
plt.xlabel('月')
plt.ylabel('売上(万円)')
# 凡例を表示
plt.legend(loc='upper left') # 凡例の位置を左上に設定
# グリッドを追加
plt.grid(True, alpha=0.3)
# グラフを表示
plt.show()
以下、実行結果です。
Seaborn:統計的可視化をより美しく、より簡単に
Seabornとは何か
Seabornは、Matplotlibを基盤として作られた統計的データ可視化ライブラリです。Matplotlibが「何でもできる」汎用的なツールだとすれば、Seabornは「統計的なグラフを美しく簡単に作る」ことに特化したツールです。
Seabornの主な特徴は次のとおりです。第一に、デフォルトで美しいデザインが適用されます。色使い、フォント、グリッドなどが最適化されており、特別な設定をしなくても見栄えの良いグラフが作成できます。第二に、統計的な処理が組み込まれています。例えば、信頼区間の計算や回帰線の追加などが簡単に行えます。第三に、PandasのDataFrameとの相性が良く、列名を指定するだけでグラフが描けます。
まず、Seabornをインポートして基本設定を行いましょう。`japanize_matplotlib`がインポート済みなので、Seabornでも日本語が正しく表示されます。
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np import japanize_matplotlib # Seabornでも日本語表示を有効にする
Seabornで美しいグラフを描く
まず、サンプルデータを作成して、Seabornの基本的な使い方を見ていきましょう。
# サンプルデータの作成
np.random.seed(42)
n_samples = 150
data = pd.DataFrame({
'店舗': np.random.choice(['渋谷', '新宿', '池袋'], n_samples),
'曜日': np.random.choice(['平日', '週末'], n_samples),
'売上': np.random.normal(100, 20, n_samples),
'来客数': np.random.poisson(50, n_samples),
'満足度': np.random.uniform(3, 5, n_samples)
})
基本的なデータを作成しました。次に、店舗や曜日によって売上を調整して、より現実的なデータにします。
# 売上を店舗によって調整
data.loc[data['店舗'] == '渋谷', '売上'] *= 1.2
data.loc[data['店舗'] == '池袋', '売上'] *= 0.8
# 週末の売上を増やす
data.loc[data['曜日'] == '週末', '売上'] *= 1.15
print("サンプルデータの最初の10行:")
print(data.head(10))
print(f"\nデータ総数: {len(data)}行")
以下、実行結果です。
サンプルデータの最初の10行: 店舗 曜日 売上 来客数 満足度 0 池袋 週末 77.588139 64 4.495219 1 渋谷 週末 129.111102 43 4.005441 2 池袋 週末 106.968717 39 3.464425 3 池袋 平日 60.306171 39 4.799149 4 渋谷 平日 125.459038 37 3.767782 5 渋谷 平日 151.371426 58 4.087106 6 池袋 平日 54.280268 57 4.812944 7 新宿 平日 103.692677 40 4.248476 8 池袋 平日 84.158125 53 3.233796 9 池袋 平日 92.509166 55 4.879664 データ総数: 150行
Seabornの箱ひげ図(ボックスプロット)を使って、店舗別の売上分布を見てみましょう。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# 箱ひげ図を作成
sns.boxplot(
data=data, # データフレーム
x='店舗', # x軸のデータ(店舗)
y='売上', # y軸のデータ(売上)
hue='曜日' # 曜日によるグループ分け
)
# グラフのタイトルと軸ラベルを設定
plt.title('店舗別・曜日別の売上分布')
plt.ylabel('売上(万円)')
plt.xlabel('店舗')
# グラフを表示
plt.show()
以下、実行結果です。
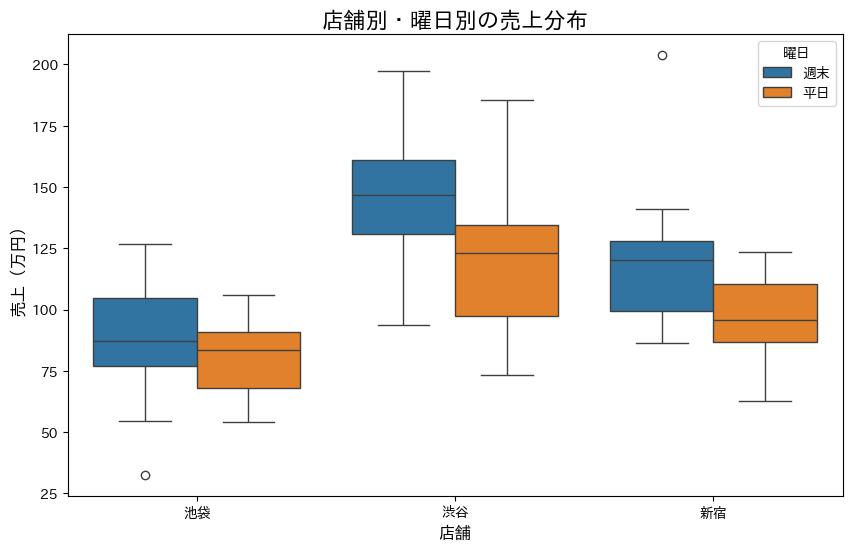
箱ひげ図は、データの分布を要約して表示する優れた方法です。箱の中央の線が中央値、箱の上端と下端が第3四分位数と第1四分位数を表し、ひげの先端が最大値と最小値(外れ値を除く)を示します。hueパラメータを使うことで、曜日による違いも同時に表現できています。
バイオリンプロットは、箱ひげ図と似ていますが、分布の形状もより詳細に表現できます。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# バイオリンプロットを作成
sns.violinplot(
data=data, # データフレーム
x='店舗', # x軸のデータ(店舗)
y='売上', # y軸のデータ(売上)
hue='曜日', # 曜日によるグループ分け
split=True # 分割して表示
)
# グラフのタイトルと軸ラベルを設定
plt.title('店舗別売上の分布(バイオリンプロット)')
plt.ylabel('売上(万円)')
plt.xlabel('店舗')
# グラフを表示
plt.show()
以下、実行結果です。
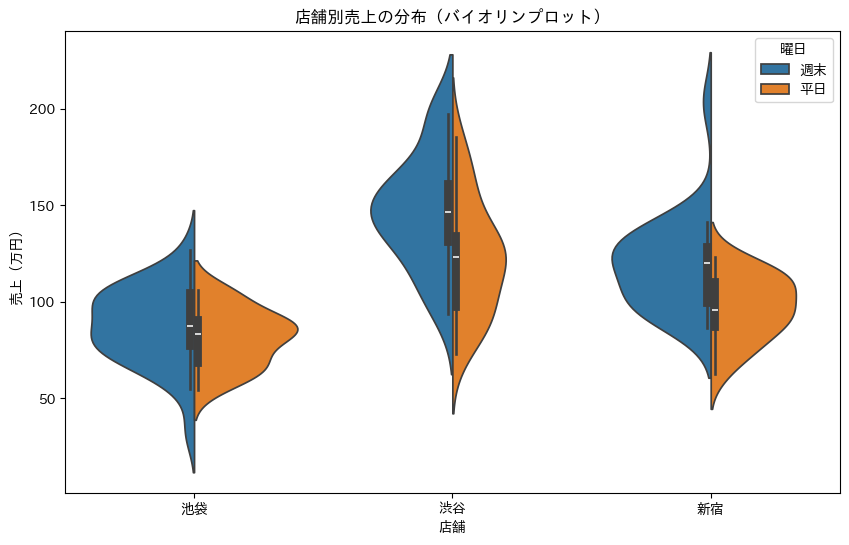
バイオリンプロットの幅は、その値でのデータの密度を表しています。幅が広い部分ほど、その値のデータが多いことを示します。split=Trueを指定すると、平日と週末を左右に分けて表示し、比較しやすくなります。
次に、2つの変数の関係を見てみましょう。散布図に回帰線を追加するのも、Seabornなら簡単です。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# 散布図と回帰線を作成
sns.regplot(
data=data, # データフレーム
x='来客数', # x軸のデータ(来客数)
y='売上', # y軸のデータ(売上)
scatter_kws={'alpha': 0.5} # 散布図の透明度
)
# グラフのタイトルと軸ラベルを設定
plt.title('来客数と売上の関係')
plt.xlabel('来客数(人)')
plt.ylabel('売上(万円)')
# グラフを表示
plt.show()
以下、実行結果です。
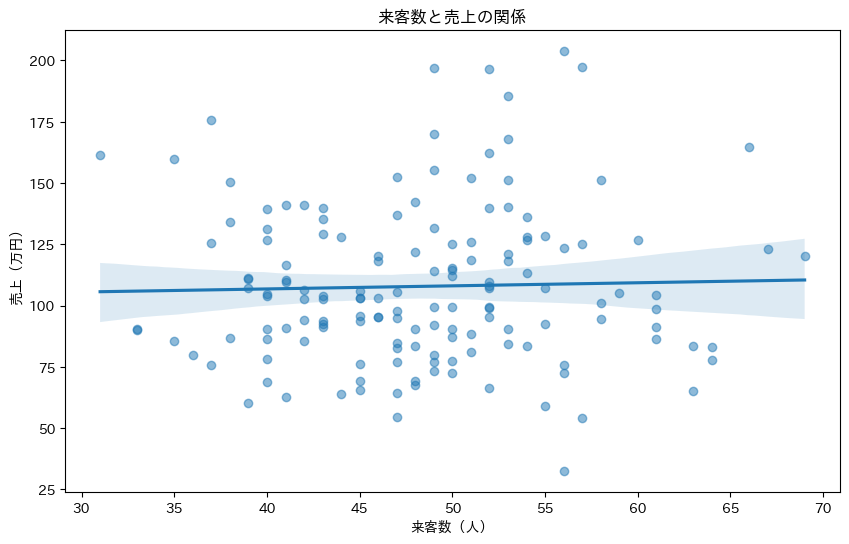
regplotは、散布図と回帰線を同時に描画します。薄い色の帯は95%信頼区間を表しています。この信頼区間により、回帰線の不確実性も視覚的に理解できます。
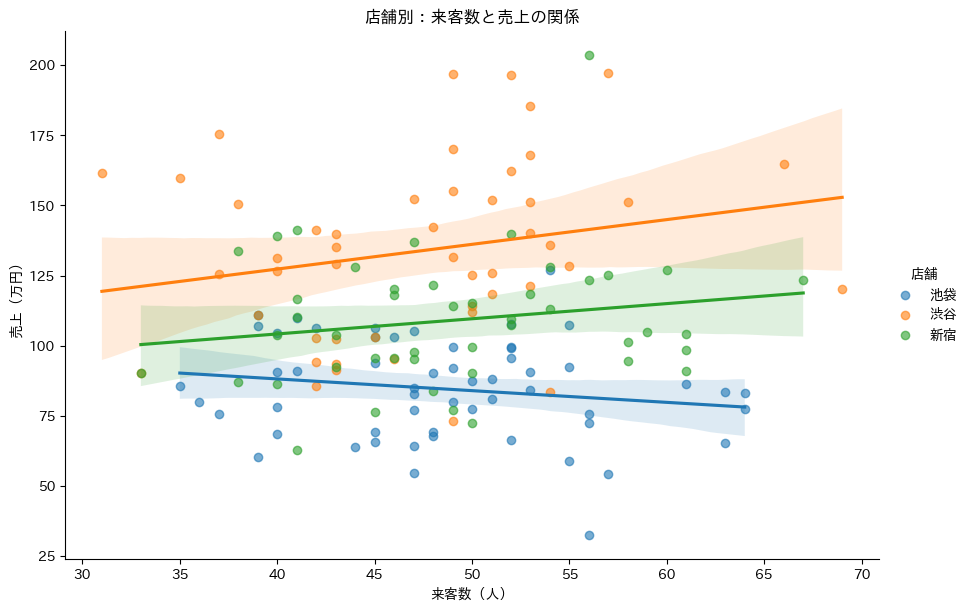
カテゴリ別に散布図を描きたい場合は、lmplotが便利です。
# 散布図と回帰線を作成
g = sns.lmplot(
data=data, # データフレーム
x='来客数', # x軸のデータ(来客数)
y='売上', # y軸のデータ(売上)
hue='店舗', # 店舗によるグループ分け
height=6, # グラフの高さ
aspect=1.5, # グラフの幅の倍率
scatter_kws={'alpha': 0.6} # 散布図の透明度
)
# 軸ラベルを設定
g.set_axis_labels(
"来客数(人)", # x軸のラベル
"売上(万円)" # y軸のラベル
)
# グラフのタイトルを設定
plt.title('店舗別:来客数と売上の関係')
# グラフを表示
plt.show()
以下、実行結果です。
ヒートマップ:相関行列を可視化する
多変量解析では、複数の変数間の相関を理解することが重要です。ヒートマップを使えば、相関行列を視覚的に理解できます。
まず、より多くの変数を持つデータセットを作成します。
# より多くの変数を持つデータを作成
np.random.seed(123)
n = 100
analysis_data = pd.DataFrame({
'売上': np.random.normal(100, 20, n),
'来客数': np.random.normal(50, 10, n),
'平均単価': np.random.normal(2000, 300, n),
'滞在時間': np.random.normal(30, 8, n),
'リピート率': np.random.uniform(0.2, 0.8, n),
'満足度': np.random.uniform(3, 5, n)
})
# 変数間にあえて相関を作る
analysis_data['売上'] = (
analysis_data['来客数']
* analysis_data['平均単価'] / 500
+ np.random.normal(0, 10, n)
)
analysis_data['満足度'] = (
analysis_data['満足度']
+ analysis_data['滞在時間'] / 100
)
print("サンプルデータの最初の10行:")
print(analysis_data.head(10))
print(f"\nデータ総数: {len(analysis_data)}行")
以下、実行結果です。
サンプルデータの最初の10行:
売上 来客数 平均単価 滞在時間 リピート率 満足度
0 260.386199 56.420547 2210.993035 36.120439 0.200049 4.412627
1 109.334001 30.221121 1820.568401 23.368089 0.788358 4.126178
2 314.598146 57.122646 2660.210630 24.726790 0.729628 4.574053
3 338.744073 75.983039 2206.489079 34.888988 0.751683 4.447716
4 197.759930 49.753740 1998.107825 28.847893 0.449302 3.343565
5 197.386097 50.341421 1938.001309 40.532845 0.646769 3.469164
6 189.763325 51.795495 1974.043314 24.365263 0.327699 4.646372
7 108.347730 31.380243 1725.407879 36.004879 0.435382 4.775211
8 231.106771 54.261466 1971.439238 32.741104 0.710929 5.247289
9 154.541644 33.945903 2083.605055 28.988499 0.276567 5.043294
データ総数: 100行
相関係数行列を求めます。
# 相関行列を計算 correlation_matrix = analysis_data.corr() print(correlation_matrix)
以下、実行結果です。
売上 来客数 平均単価 滞在時間 リピート率 満足度 売上 1.000000 0.780622 0.604296 0.172950 0.122703 -0.110387 来客数 0.780622 1.000000 0.023881 0.091013 0.229924 -0.060615 平均単価 0.604296 0.023881 1.000000 0.187172 -0.095490 -0.100539 滞在時間 0.172950 0.091013 0.187172 1.000000 -0.113647 -0.033880 リピート率 0.122703 0.229924 -0.095490 -0.113647 1.000000 -0.193226 満足度 -0.110387 -0.060615 -0.100539 -0.033880 -0.193226 1.000000
相関行列をヒートマップで可視化します。
# グラフのサイズを指定
plt.figure(figsize=(10, 8))
# ヒートマップを作成
sns.heatmap(
correlation_matrix, # 相関行列
annot=True, # 数値を表示
fmt='.2f', # 小数点以下2桁で表示
cmap='coolwarm', # カラーマップ(冷暖色)
center=0, # 中央値を0に設定
square=True, # 正方形のセルにする
linewidths=1, # セル間の線の太さ
cbar_kws={'label': '相関係数'} # カラーバーのラベル
)
# タイトルを設定
plt.title('変数間の相関行列')
# グラフを表示
plt.show()
以下、実行結果です。
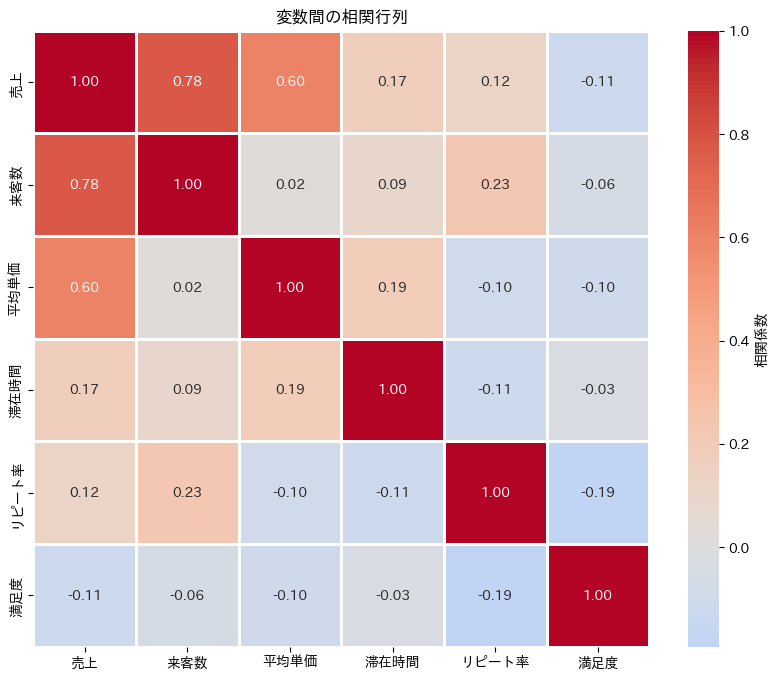
ヒートマップでは、色の濃さが相関の強さを表します。赤系の色は正の相関、青系の色は負の相関を示しています。annot=Trueにより、各セルに実際の相関係数の値が表示されます。
ペアプロット:すべての変数ペアを一度に見る
複数の変数がある場合、すべての組み合わせの散布図を見たいことがあります。Seabornのペアプロットを使えば、これが簡単に実現できます。
# 分析用のデータを準備(少し小さめのデータセット)
pair_data = analysis_data[[
'売上', '来客数', '平均単価', '満足度'
]].sample(50)
# ペアプロットを作成し、変数gに格納
g = sns.pairplot(
pair_data, # データフレーム
diag_kind='kde', # 対角線上のプロットをカーネル密度推定(KDE)で表示
plot_kws={'alpha': 0.6}, # 散布図の透明度(アルファ値)を0.6に設定
height=2.5 # 各サブプロットの高さを2.5インチに設定
)
# タイトルを設定
g.fig.suptitle(
'変数間の関係(ペアプロット)', # タイトルのテキスト
y=1.02 # タイトルの位置(y軸方向)
)
# グラフを表示
plt.show()
以下、実行結果です。
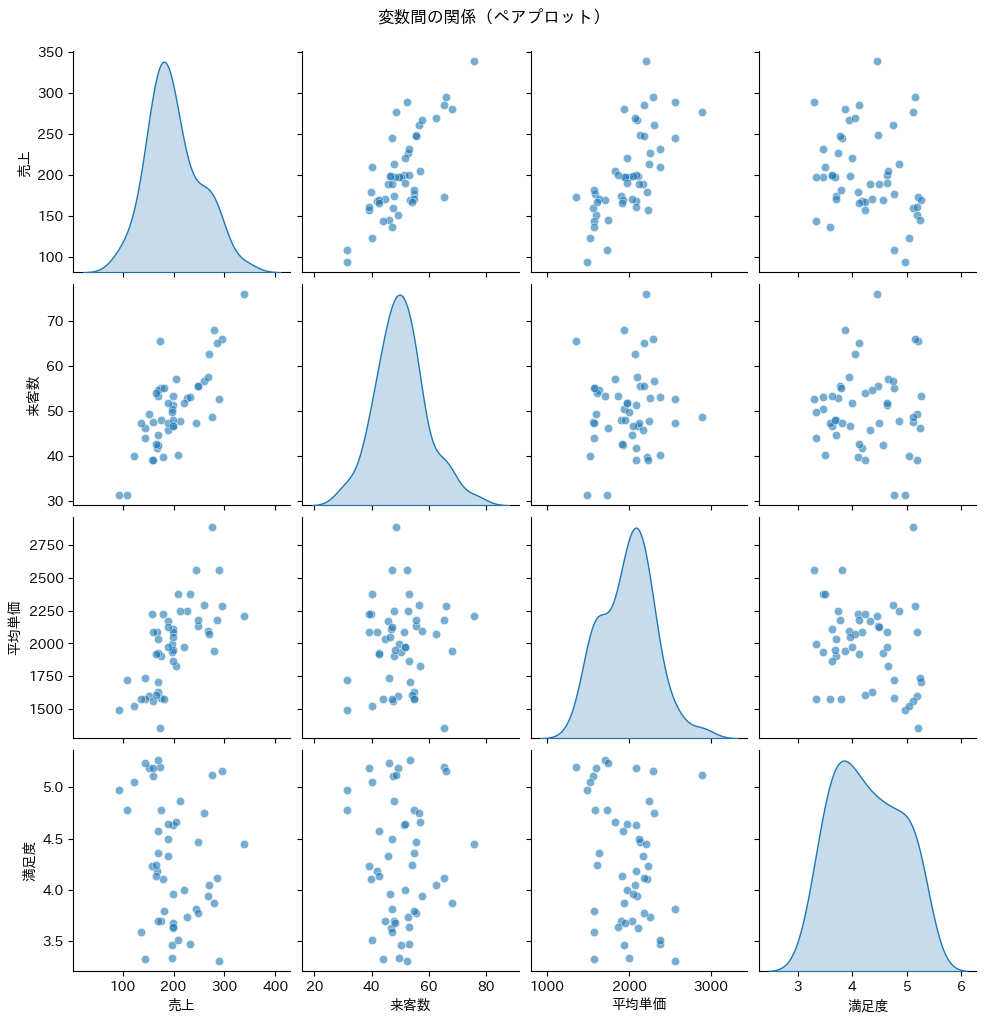
ペアプロットは、対角線上に各変数の分布(この例では密度曲線)、非対角要素に変数ペアの散布図を表示します。これにより、すべての変数間の関係を一度に確認できます。
カテゴリカルプロット:カテゴリ別の比較を美しく
Seabornは、カテゴリ別のデータを比較するための様々な手法を提供しています。
まず、月別・部門別のデータを作成します。
# カテゴリ別のデータを作成
np.random.seed(456)
cat_data = pd.DataFrame({
'月': np.repeat(['1月', '2月', '3月', '4月'], 30),
'部門': np.tile(np.repeat(['営業', '開発', '管理'], 10), 4),
'売上': np.random.normal(100, 20, 120)
})
# 月と部門によって売上を調整
cat_data.loc[cat_data['月'] == '4月', '売上'] *= 1.2
cat_data.loc[cat_data['部門'] == '営業', '売上'] *= 1.15
print("サンプルデータの最初の10行:")
print(cat_data.head(10))
print(f"\nデータ総数: {len(cat_data)}行")
以下、実行結果です。
サンプルデータの最初の10行:
月 部門 売上
0 1月 営業 99.633044
1 1月 営業 103.541181
2 1月 営業 129.227244
3 1月 営業 128.079922
4 1月 営業 146.061718
5 1月 営業 152.480536
6 1月 営業 121.945223
7 1月 営業 125.338113
8 1月 営業 107.046344
9 1月 営業 107.749691
データ総数: 120行
棒グラフで平均値と信頼区間を表示してみましょう。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# 棒グラフを作成
sns.barplot(
data=cat_data, # データフレーム
x='月', # x軸のデータ(月)
y='売上', # y軸のデータ(売上)
hue='部門', # 部門によるグループ分け
errorbar=('ci', 95) # 95%信頼区間を表示
)
# グラフのタイトルと軸ラベルを設定
plt.title('月別・部門別の平均売上')
plt.ylabel('売上(万円)')
plt.xlabel('月')
# 凡例を表示
plt.legend(
title='部門', # 凡例のタイトル
title_fontsize=12, # タイトルのフォントサイズ
loc='upper left' # 凡例の位置(左上)
)
# グラフを表示
plt.show()
以下、実行結果です。
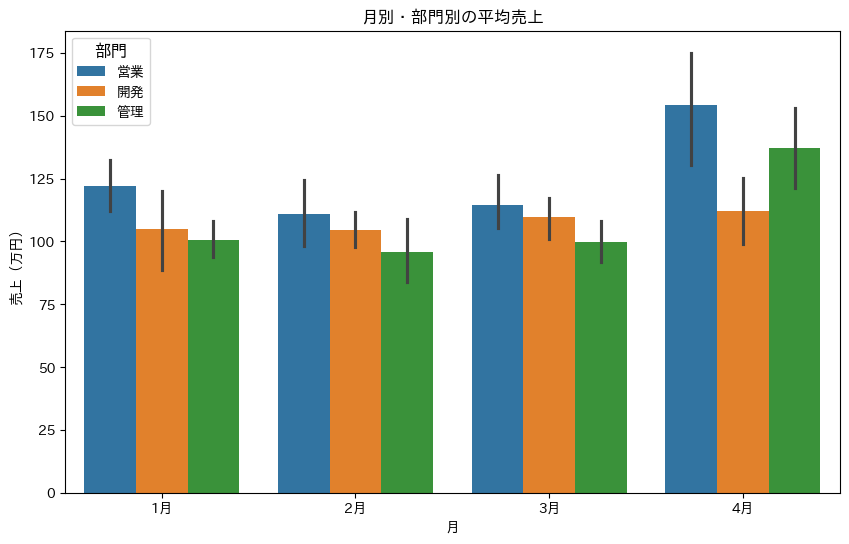
黒い線(エラーバー)は95%信頼区間を表しています。これにより、平均値の不確実性も同時に表現できます。
スウォームプロットを使うと、個々のデータポイントを重ならないように表示できます。
# グラフのサイズを指定
plt.figure(figsize=(10, 6))
# スウォームプロットを作成
sns.swarmplot(
data=cat_data, # データフレーム
x='月', # x軸のデータ(月)
y='売上', # y軸のデータ(売上)
hue='部門', # 部門によるグループ分け
dodge=True, # グループを分離して表示
size=10 # マーカーのサイズ
)
# グラフのタイトルと軸ラベルを設定
plt.title('月別・部門別の売上(全データポイント)')
plt.ylabel('売上(万円)')
plt.xlabel('月')
# 凡例を表示
plt.legend(
title='部門', # 凡例のタイトル
title_fontsize=12, # タイトルのフォントサイズ
loc='upper left' # 凡例の位置(左上)
)
# グラフを表示
plt.show()
以下、実行結果です。
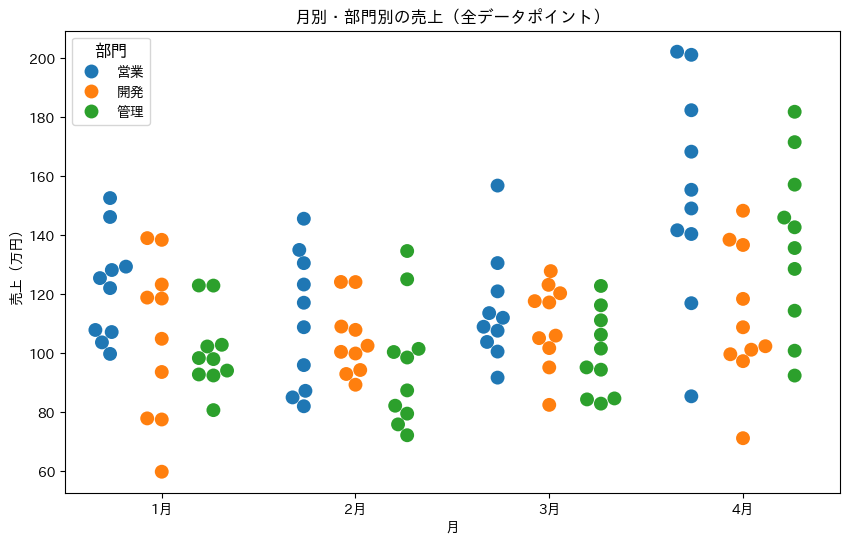
スウォームプロットでは、すべてのデータポイントが見えるため、分布の形状や外れ値の存在が明確に分かります。
まとめ
今回は、MatplotlibとSeabornを使ったデータ可視化の基本から応用まで幅広く学びました。Matplotlibで基本的なグラフ(折れ線、棒グラフ、散布図、円グラフ、ヒストグラム)の作成方法を習得し、Seabornでより洗練された統計的可視化(箱ひげ図、バイオリンプロット、ヒートマップ、ペアプロット)を実現する方法を身につけました。
特に重要なのは、japanize_matplotlibを使った日本語表示の設定方法です。これにより、文字化けを心配することなく、日本語のラベルやタイトルを含む美しいグラフを作成できるようになりました。また、複数のグラフを組み合わせて多角的にデータを分析する手法も学び、実践的なデータ分析レポートを作成できるレベルに到達しました。
データ可視化は、単にきれいなグラフを作ることが目的ではありません。それは、データの中に隠れている洞察を発見し、複雑な情報を分かりやすく伝え、より良い意思決定を促すための強力なコミュニケーション手段なのです。
これまでの3回で、Pythonの基礎文法、データ操作、そしてデータ可視化という、データ分析の基本的な要素をすべて学びました。これらのスキルを組み合わせることで、実際のビジネスデータを分析し、価値ある洞察を得ることができるようになったはずです。ぜひ、実際のデータで今回学んだ技術を試してみてください。データが語る物語を、美しいビジュアルで表現する楽しさを体感できることでしょう。